Кластер СУБД на основе физической репликации
Решение на базе физической репликации
Отказоустойчивый кластер (ОУК) – группа экземпляров PostgreSQL, объединенных в логическую группу и образующих единый ресурс.
Репликация - процесс поддержания двух (или более) баз данных в согласованном состоянии.
Потоковая репликация – репликация, при которой от ведущего сервера PostgreSQL на ведомые передается WAL. Каждый ведомый узел по журналу применяет изменения с ведущего узла.
WAL (журналы предзаписи) – метод обеспечения целостности данных посредством ведения отдельного от базы данных журнала предзаписи, в котором информация об изменениях в базе данных вносится и фиксируется перед записью в базу данных.
Узел кластера – физический сервер или виртуальная машина с установленным сервером СУБД PostgreSQL и кластерным программным обеспечением.
PiTR, Point-in-Time Recovery – вариант восстановления БД PostgreSQL на определенный момент времени, обеспечиваемый наличием полной архивной копии БД и описанием совокупности последовательных изменений применявшихся к этой базе до указанного момента.
БД – база данных.
СУБД – система управления базами данных
Общее описание
Наиболее простым и доступным способом создания отказоустойчивого кластера является использование встроенной в СУБД PostgreSQL функциональности синхронизации баз данных кластера путем автоматической передачи изменений с основного узла кластера на другие узлы (репликация).
Захват и передача изменений происходит с использованием стандартного для СУБД PostgreSQL механизма журналов предзаписи (он же используется также для восстановления согласованного состояния БД после сбоя или для восстановления резервной копии на определенный момент времени (PiTR). В случае использования этого механизма для репликации, журналы предзаписи (WAL) с основного узла кластера копируются на остальные узлы и применяются к имеющимся там репликам БД.
Достоинства и недостатки физической репликации
Как и у всякой технологии, у репликации есть свои плюсы и минусы. К преимуществам можно отнести:
- Это встроенный в СУБД механизм.
- Использование репликации несет относительно небольшие накладные расходы на использование ресурсов.
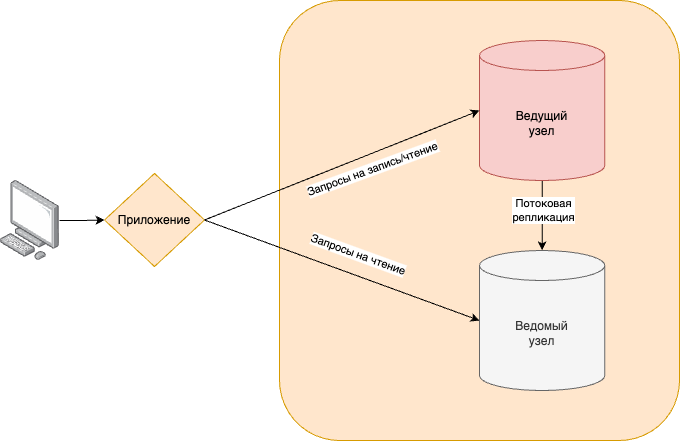
- К узлам-репликам возможно обращаться с запросами на чтение, что позволяет горизонтально масштабировать читающую нагрузку.
- Реплики возможно использовать вместо основного сервера для создания файловых бэкапов.
Недостатки:
- Репликация в PostgreSQL – исключительно однонаправленная, реплики возможно использовать только на чтение.
- Физическая репликация возможна для всего сервера целиком, нельзя выбрать объекты (базы, таблицы и пр.), которые будут реплицироваться.
- Необходимым условием для физической репликации является совпадение на ведущем и ведомых серверах архитектуры сервера, ОС и мажорной версии PostgreSQL.
- Наличие физической реплики повышает отказоустойчивость кластера, но не может быть заменой бэкапу.
- При некоторых вариантах настроек репликации сбой применения изменений на реплике может вызвать падение и/или недоступность СУБД на основном сервере.
- Без использования дополнительных самописных или сторонних обвязок (скриптов, ПО), работа с кластером на основе физической репликации может оказаться недостаточно удобной и надежной.
Кластеризация базы данных
Основная цель кластеризации базы данных – обеспечение высокой доступности данных.
Доступность характеризуется свойствами:
- Надежность – восстановление без потери данных после сбоя узла кластера СУБД.
- Отказоустойчивость – бесперебойная запись и чтение данных в случае сбоя узла кластера СУБД.
- Производительность и горизонтальная масштабируемость (по чтению) – возможность добавления новых узлов в кластер СУБД и распределение нагрузки одного узла на остальные узлы кластера СУБД.
Общая архитектура
Основной узел кластера, который может изменять данные, называется ведущим сервером. Сервер, который отслеживает изменения на ведущем, называется ведомым или резервным сервером (репликой). Резервный сервер, к которому нельзя подключаться до тех пор, пока он не будет повышен до главного, называется сервером тёплого резерва, а тот, который может принимать соединения и обрабатывать запросы на чтение, называется сервером горячего резерва.
Функционирование отказоустойчивого кластера на основе физической потоковой репликации обеспечиватся синхронизацией баз данных кластера путем автоматической передачи изменений с основного узла кластера на другие узлы (репликации). Передача изменений осуществляется с использованием журналов предзаписи (WAL).
Журнал предзаписи (WAL) — это стандартный метод обеспечения целостности данных. Основная идея WAL состоит в том, что записи об изменениях, которые должны быть внесены в файлы с данными (файлы таблиц и индексов), предварительно фиксируются в журнал (WAL) и сохраняются на постоянное устройство хранения. Сохранение записей обо всех изменениях в БД позволяет не только гарантированно восстанавливать состояние БД после сбоя, но и использовать их для синхронизации БД на других узлах кластера, путем последовательного выполнения всех новых записей WAL на ведомых серверах.
На основе встроенной в СУБД PostgreSQL функциональности могут быть реализованы несколько видов репликации - физическая и логическая, на основе трансляции WAL-журналов и потоковая. В зависимости от режима применения изменений репликация может быть асинхронной и синхронной.
Для описываемого в данном разделе кластерного решения используется физическая репликация (логическая репликация обеспечивает синхронизацию на уровне отдельных таблиц).
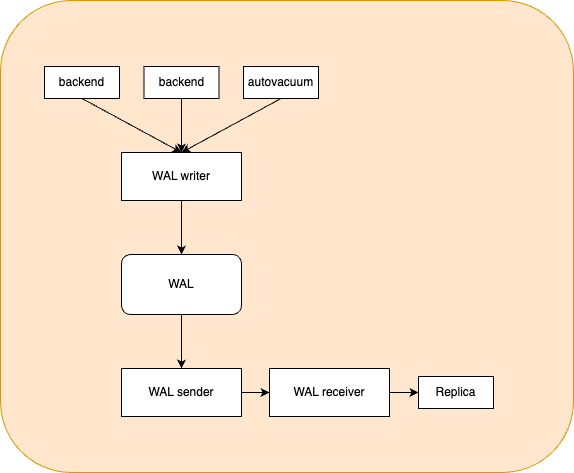
Перенос изменений может осуществляться на основе копирования и применения на резервном сервере заполненных файлов журналов предзаписи (трансляции WAL-файлов), либо с использованием потоковой репликации, при которой изменения транслируются не целыми файлами, а непосредственно отдельными записями об изменениях. Использование потоковой репликации позволяет более оперативно применять изменения и таким образом сократить лаг отставания реплики.
Непосредственно механизм потоковой репликации осуществляется процессом WAL receiver, запущенным на резервном сервере, который по сети подключается к основному. На основном сервере за отправку WAL-записей на резервный сервер, по мере их поступления, отвечает процесс WAL sender.
По умолчанию потоковая репликация в СУБД PostgreSQL функционирует в асинхронном режиме. В этом случае отправка WAL-записей на реплики происходит после того, как изменения будут применены на основном узле. Преимуществом такого способа будет быстрое подтверждение транзакций, т.к. отсутствуют ожидания, связанные с применением изменений на реплике. Недостаток в том, что при падении основного сервера часть изменений может быть утеряна, так как они не успели попасть на реплику.
Для избежания потери данных при сбое возможно настроить синхронный режим репликации. В этом случае изменения фиксируются на основном сервере только после получения от реплики подтверждения того, что запись получена и/или применена хотя бы на одной реплике. Преимущество — это более надежный способ, при котором сложнее потерять данные. Недостаток — операции выполняются медленнее, так как добавляется ожидание подтверждения от реплики.

Как и в случае с другими ОУК, эффективность и удобство использования отказоустойчивого кластера на базе физической репликации могут быть повышены добавлением пулера соединений, балансировщиков нагрузки и пр.
Создание кластера
Для создания кластера необходимо создать в БД технического пользователя, от которого будет выполняться репликация, обеспечить сетевую доступность между узлами, создать на ведомом узле копию БД с ведущего, внести некоторые связанные с репликацией изменения в настройки СУБД. Стартовать СУБД на ведомом сервере и убедиться в функционировании репликации.
Отказоустойчивость на стороне приложения
Если приложение работает с БД через библиотеку libpq, то высокую доступность БД можно обеспечить, воспользовавшись уже реализованными в библиотеке возможностями.
Библиотека поддерживает указание в строке подключения перечня серверов БД, к которым возможно подключение приложения. Заданием дополнительных параметров в строке подключения возможно гарантировать подключение к первому доступному серверу, либо к серверу, который доступен только на чтение, либо к серверу, доступному на чтение и запись.
Резервное копирование
Использование отказоустойчивых кластеров направлено на повышение доступности БД, но не может служить заменой создания резервных копий (бэкапов) для целей исключения риска потери данных. Для предотвращения вероятной потери данных при сбоях рекомендуется на регулярной основе выполнять резервное копирование.
Существует два вида резервирования: логическое и физическое.
Логическое резервирование – это выгрузка существующих объектов БД в набор команд SQL, восстанавливающих кластер (или базу данных, или отдельный объект) с нуля. Для данного решения предназначены команда copy, утилиты pg_dump и pg_dumpall.
Физическая резервная копия включает в себя копию файлов кластера и может включать некоторый набор дополнительных файлов, таких как файлы изменений между согласованными состояниями БД (дельта-файлы), последовательности WAL-файлов и пр. Физическое резервирование использует механизм восстановления после сбоев. Для управления созданием и менеджментом физических резервных копий могут использоваться такие утилиты, как pg_basebackup, pg_probackup и другие.
pg_probackup
Pg_probackup – это утилита для управления резервным копированием и восстановлением баз данных Postgres Pro и PostgreSQL. Она предназначена для регулярного создания резервных копий экземпляров БД, позволяющих восстанавливать СУБД в случае необходимости.
Организация репозитория и архива WAL
Для управления резервными копиями pg_probackup создает каталог (репозиторий) резервных копий. В этом каталоге хранятся все файлы резервных копий с дополнительной метаинформацией, а также архивы WAL, необходимые для восстановления на момент времени. В едином репозитории возможно хранение резервных копий различных экземпляров БД. pg_probackup умеет создавать самодостаточные резервные копии, включающие в себя файлы БД и набор WAL-файлов, достаточный для восстановления согласованного состояния БД. Возможно создание полных и инкрементальных резервных копий, докат БД до состояния на определенный момент времени (PiTR) с использованием архива WAL-файлов. В инкрементальном резервном копировании поддерживаются режимы страничного копирования, разностного копирования и копирования изменений. Также pg_probackup обладает гибкими возможностями по управлению хранением резервных копий.
Для предотвращения возникновения ситуации, когда ведомому серверу еще требуются те записи WAL, которые уже были удалены на ведущем, рекомендуется настроить на ведущем сервере архивирование WAL. Наличие долговременного хранилища архивов WAL позволяет докатывать изменения даже в том случае, если требующиеся журналы уже отсутствуют на основном узле кластера, либо если копирование с основного узла нежелательно.
Использование pg_probackup для бэкапирования кластеров, состоящих из нескольких узлов, дает еще несколько ощутимых преимуществ. pg_probackup позволяет создание резервных копий с одной из реплик, что исключает дополнительную нагрузку на основной сервер. При необходимости создать дополнительный узел кластера или тестовую копию БД, копирование возможно осуществить с реплики или из репозитория архивных копий.
Восстановление кластера из РК
В случае сбоя на ведущем узле кластера, повлекшего за собой неустранимое повреждение БД, как правило, первым этапом восстановления кластера является активация реплики и переключение на нее прикладной нагрузки, таким образом она становится новым ведущим узлом.
Вторым этапом будет восстановление согласованного состояния БД на остальных узлах кластера, в том числе и на бывшем ведущем, и запуск на них репликации изменений с нового ведущего.
Вернуть ведомые узлы в согласованное состояние возможно различными способами, наиболее простым будет полное пересоздание СУБД из архивной копии или непосредственно копированием с ведущего узла. При необходимости (например, при слишком большом размере БД или медленной сети), в некоторых случаях возможно избежать полного копирования базы с помощью отката части изменений утилитой pg_rewind или копирования только дельты изменений между базами утилитой pg_probackup с опцией catchup.
Мониторинг кластера
Для сбора и хранения данных мониторинга возможно использовать такие инструменты, как Prometheus или Zabbix.
Для визуализации собранных данных удобно использовать дополнительное ПО, например, Grafana. Grafana позволяет собрать и сгруппировать на одном экране набор метрик, которые в совокупности отражают какую-либо смысловую величину работы компонентов кластера.