Re: WIP: Upper planner pathification
| От | Tom Lane |
|---|---|
| Тема | Re: WIP: Upper planner pathification |
| Дата | |
| Msg-id | 21211.1457201365@sss.pgh.pa.us обсуждение исходный текст |
| Ответ на | Re: WIP: Upper planner pathification (Tom Lane <tgl@sss.pgh.pa.us>) |
| Ответы |
Re: WIP: Upper planner pathification
(Greg Stark <stark@mit.edu>)
Re: WIP: Upper planner pathification (Tom Lane <tgl@sss.pgh.pa.us>) |
| Список | pgsql-hackers |
I wrote:
> Robert Haas <robertmhaas@gmail.com> writes:
>> One idea might be to run a whole bunch of queries and record all of
>> the planning times, and then run them all again and compare somehow.
>> Maybe the regression tests, for example.
> That sounds like something we could do pretty easily, though interpreting
> the results might be nontrivial.
I spent some time on this project. I modified the code to log the runtime
of standard_planner along with decompiled text of the passed-in query
tree. I then ran the regression tests ten times with cassert-off builds
of both current HEAD and HEAD+pathification patch, and grouped all the
numbers for log entries with identical texts. (FYI, there are around
10000 distinguishable queries in the current tests, most planned only
once or twice, but some as many as 2900 times.) I had intended to look
at the averages within each group, but that was awfully noisy; I ended up
looking at the minimum times, after discarding a few groups with
particularly awful standard deviations. I theorize that a substantial
part of the variation in the runtime depends on whether catalog entries
consulted by the planner have been sucked into syscache or not, and thus
that using the minimum is a reasonable way to eliminate cache-loading
effects, which surely ought not be considered in this comparison.
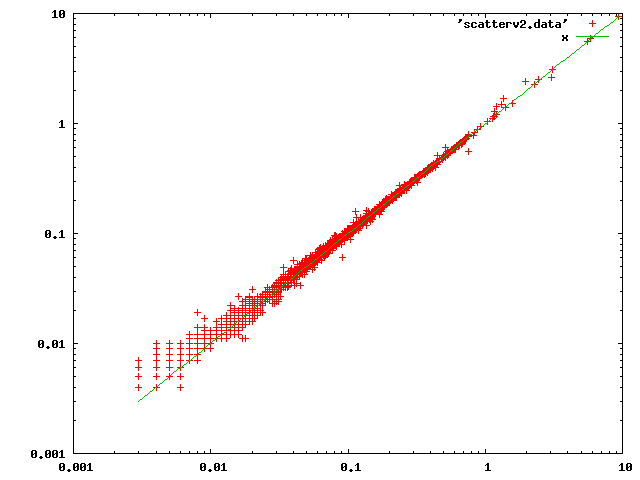
Here is a scatter plot, on log axes, of planning times in milliseconds
with HEAD (x axis) vs those with patch (y axis):
The most noticeable thing about that is that the worst percentage-wise
cases appear near the bottom end of the range. And indeed inspection
of individual entries showed that trivial cases like
SELECT (ROW(1, 2) < ROW(1, 3)) AS "true"
were hurting the most percentage-wise. After some study I decided that
the only thing that could explain that was the two rounds of
construct-an-upper-rel-and-add-paths-to-it happening in grouping_planner.
I was able to get rid of one of them by discarding the notion of
UPPERREL_INITIAL altogether, and instead having the code apply the desired
tlist in-place, like this:
sub_target = make_subplanTargetList(root, tlist,
&groupColIdx);
/*
* Forcibly apply that tlist to all the Paths for the scan/join rel.
*
* In principle we should re-run set_cheapest() here to identify the
* cheapest path, but it seems unlikely that adding the same tlist
* eval costs to all the paths would change that, so we don't bother.
* Instead, just assume that the cheapest-startup and cheapest-total
* paths remain so. (There should be no parameterized paths anymore,
* so we needn't worry about updating cheapest_parameterized_paths.)
*/
foreach(lc, current_rel->pathlist)
{
Path *subpath = (Path *) lfirst(lc);
Path *path;
Assert(subpath->param_info == NULL);
path = apply_projection_to_path(root, current_rel,
subpath, sub_target);
/* If we had to add a Result, path is different from subpath */
if (path != subpath)
{
lfirst(lc) = path;
if (subpath == current_rel->cheapest_startup_path)
current_rel->cheapest_startup_path = path;
if (subpath == current_rel->cheapest_total_path)
current_rel->cheapest_total_path = path;
}
}
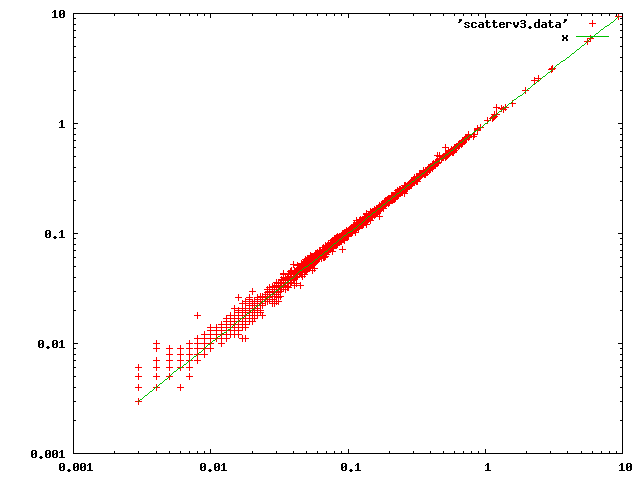
With that fixed, the scatter plot looks like:
There might be some other things we could do to provide a fast-path for
particularly trivial cases. But on the whole I think this plot shows that
there's no systematic problem, and indeed not really a lot of change at
all.
I won't bother to repost the modified patch right now, but will spend some
time filling in the missing pieces first.
regards, tom lane
Вложения
В списке pgsql-hackers по дате отправления: