Re: pg_upgrade failing for 200+ million Large Objects
Вложения
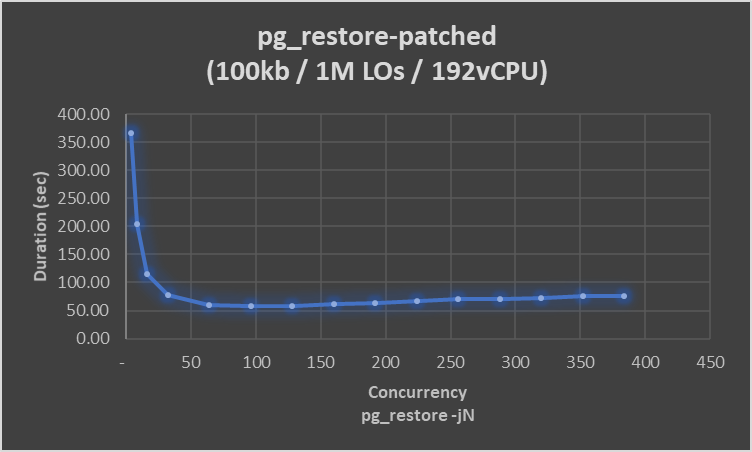
В списке pgsql-hackers по дате отправления:
Следующее
От: Bharath RupireddyДата:
Сообщение: Re: Switching XLog source from archive to streaming when primary available
В списке pgsql-hackers по дате отправления: