Обсуждение: Blocked updates and background writer performance
PG 9.4.4 (RDS)
I'm experiencing an issue when trying to update many rows in a single table (one row at a time, but parallelized across ~12 connections). The issue we see is that the writes will periodically be blocked for a duration of several minutes and then pick back up. After digging through our monitoring stack, I was able to uncover these stats which seem to allude to it being a background writer performance problem:
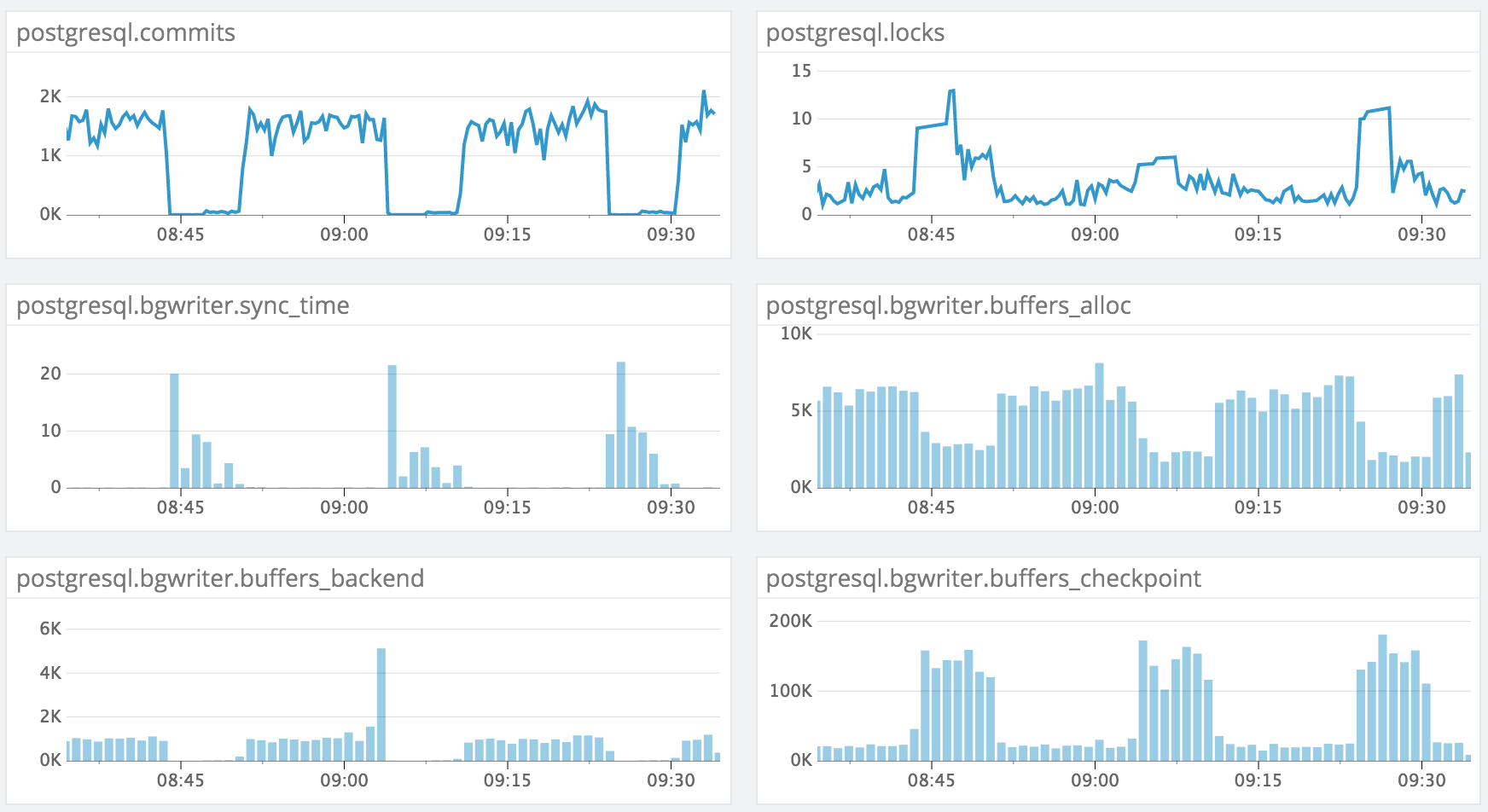
(apologies for the image)
Our settings for the background writer are pretty standard OOB (I threw in some others that I thought might be helpful, too):
name | setting | unit
-------------------------+---------+------
bgwriter_delay | 200 | ms
bgwriter_lru_maxpages | 100 |
bgwriter_lru_multiplier | 2 |
maintenance_work_mem | 65536 | kB
max_worker_processes | 8 |
work_mem | 32768 | kB
The table that is being written to contains a jsonb column with a GIN index:
Table "public.ced"
Column | Type | Modifiers
---------------+--------------------------+-----------
id | bigint | not null
created_at | timestamp with time zone |
modified_at | timestamp with time zone |
bean_version | bigint | default 0
account_id | bigint | not null
data | jsonb | not null
Indexes:
"ced_pkey" PRIMARY KEY, btree (id)
"ced_data" gin (data jsonb_path_ops)
"partition_key_idx" btree (account_id, id)
It seems to me that the background writer just can't keep up with the amount of writes that I am trying to do and freezes all the updates. What are my options to improve the background writer performance here?
thanks
--Cory
Вложения
Maybe you're not doing this.... but:
Using "data" json(b)/hstore column for all/most/many fields is an antipattern. Use 'data' ONLY for columns that you know will be dynamic.
This way you'll write less data into static-columns (no key-names overhead and better types) --> less data to disk etc (selects will also be faster).Using "data" json(b)/hstore column for all/most/many fields is an antipattern. Use 'data' ONLY for columns that you know will be dynamic.
On Tue, Jan 12, 2016 at 7:25 PM, Cory Tucker <cory.tucker@gmail.com> wrote:
PG 9.4.4 (RDS)I'm experiencing an issue when trying to update many rows in a single table (one row at a time, but parallelized across ~12 connections). The issue we see is that the writes will periodically be blocked for a duration of several minutes and then pick back up. After digging through our monitoring stack, I was able to uncover these stats which seem to allude to it being a background writer performance problem:(apologies for the image)Our settings for the background writer are pretty standard OOB (I threw in some others that I thought might be helpful, too):name | setting | unit-------------------------+---------+------bgwriter_delay | 200 | msbgwriter_lru_maxpages | 100 |bgwriter_lru_multiplier | 2 |maintenance_work_mem | 65536 | kBmax_worker_processes | 8 |work_mem | 32768 | kBThe table that is being written to contains a jsonb column with a GIN index:Table "public.ced"Column | Type | Modifiers---------------+--------------------------+-----------id | bigint | not nullcreated_at | timestamp with time zone |modified_at | timestamp with time zone |bean_version | bigint | default 0account_id | bigint | not nulldata | jsonb | not nullIndexes:"ced_pkey" PRIMARY KEY, btree (id)"ced_data" gin (data jsonb_path_ops)"partition_key_idx" btree (account_id, id)It seems to me that the background writer just can't keep up with the amount of writes that I am trying to do and freezes all the updates. What are my options to improve the background writer performance here?thanks--Cory
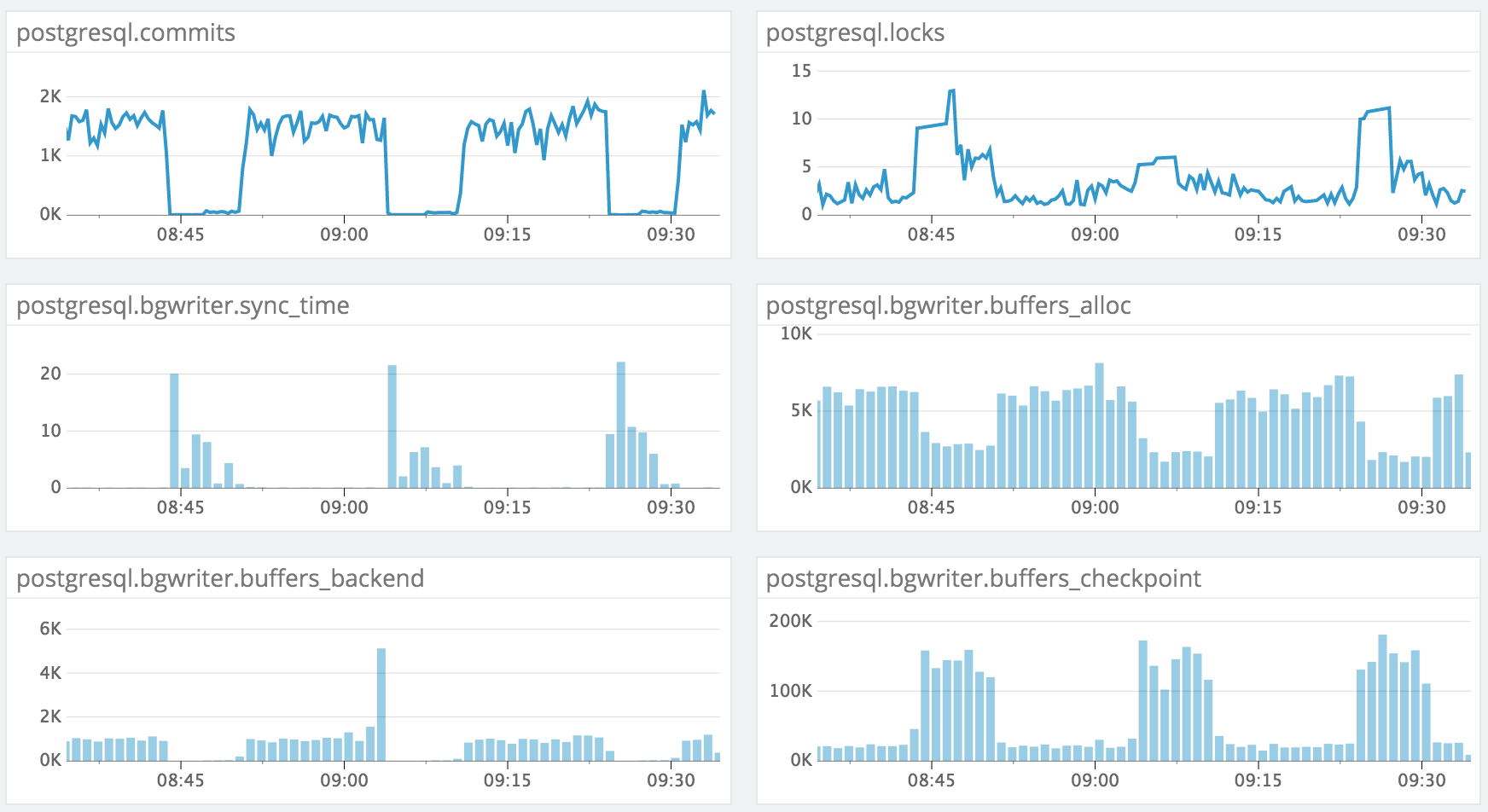
Вложения
Thanks for the reply Dorian. For the sake of argument, lets just say I'm definitely not doing what you mentioned. My question was not so much around modeling json storage as it is around tuning the background writer performance.
On Tue, Jan 12, 2016 at 2:14 PM Dorian Hoxha <dorian.hoxha@gmail.com> wrote:
Maybe you're not doing this.... but:This way you'll write less data into static-columns (no key-names overhead and better types) --> less data to disk etc (selects will also be faster).
Using "data" json(b)/hstore column for all/most/many fields is an antipattern. Use 'data' ONLY for columns that you know will be dynamic.On Tue, Jan 12, 2016 at 7:25 PM, Cory Tucker <cory.tucker@gmail.com> wrote:PG 9.4.4 (RDS)I'm experiencing an issue when trying to update many rows in a single table (one row at a time, but parallelized across ~12 connections). The issue we see is that the writes will periodically be blocked for a duration of several minutes and then pick back up. After digging through our monitoring stack, I was able to uncover these stats which seem to allude to it being a background writer performance problem:(apologies for the image)Our settings for the background writer are pretty standard OOB (I threw in some others that I thought might be helpful, too):name | setting | unit-------------------------+---------+------bgwriter_delay | 200 | msbgwriter_lru_maxpages | 100 |bgwriter_lru_multiplier | 2 |maintenance_work_mem | 65536 | kBmax_worker_processes | 8 |work_mem | 32768 | kBThe table that is being written to contains a jsonb column with a GIN index:Table "public.ced"Column | Type | Modifiers---------------+--------------------------+-----------id | bigint | not nullcreated_at | timestamp with time zone |modified_at | timestamp with time zone |bean_version | bigint | default 0account_id | bigint | not nulldata | jsonb | not nullIndexes:"ced_pkey" PRIMARY KEY, btree (id)"ced_data" gin (data jsonb_path_ops)"partition_key_idx" btree (account_id, id)It seems to me that the background writer just can't keep up with the amount of writes that I am trying to do and freezes all the updates. What are my options to improve the background writer performance here?thanks--Cory
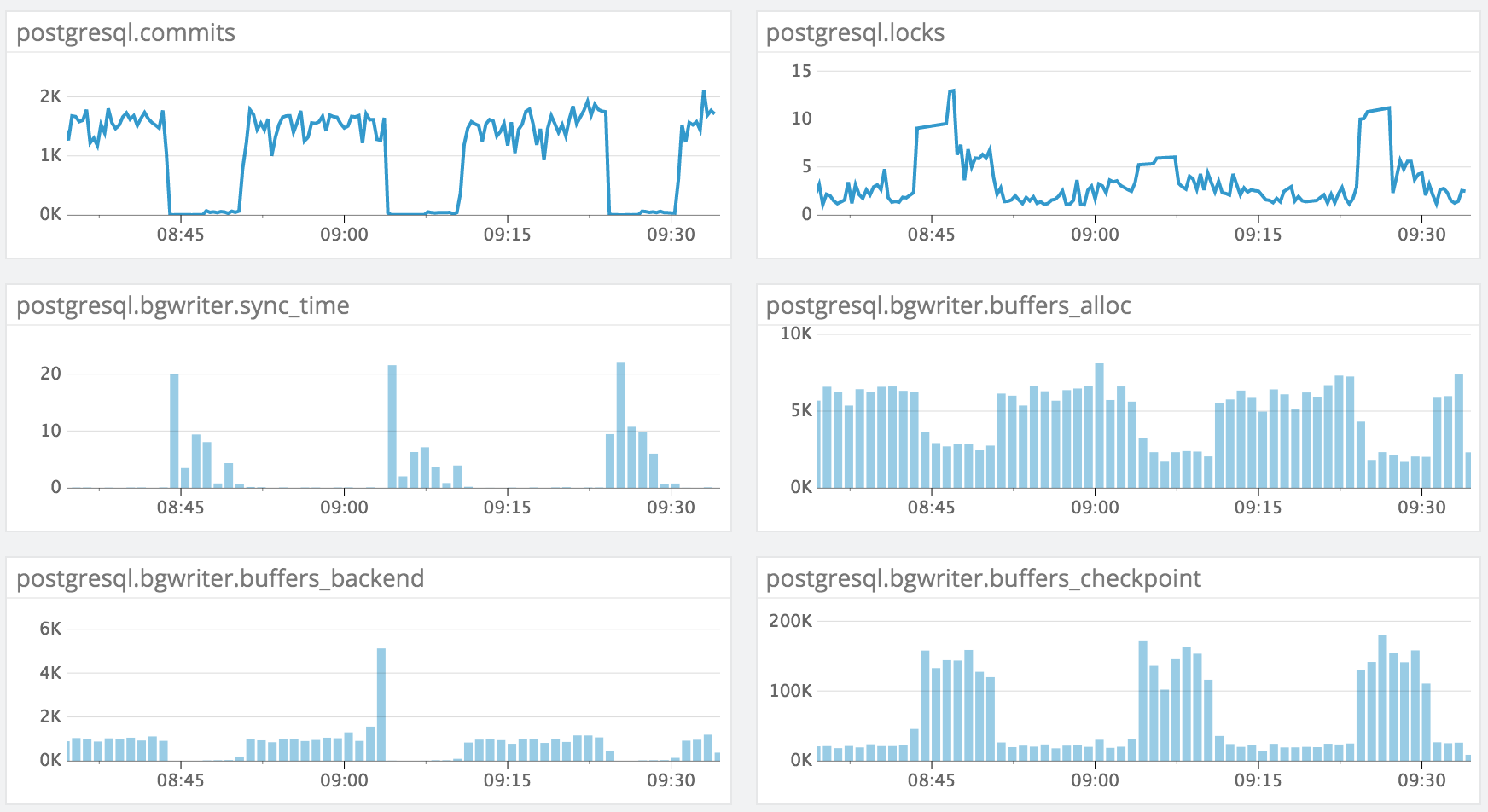
Вложения
On Tue, Jan 12, 2016 at 10:25 AM, Cory Tucker <cory.tucker@gmail.com> wrote:
PG 9.4.4 (RDS)I'm experiencing an issue when trying to update many rows in a single table (one row at a time, but parallelized across ~12 connections). The issue we see is that the writes will periodically be blocked for a duration of several minutes and then pick back up. After digging through our monitoring stack, I was able to uncover these stats which seem to allude to it being a background writer performance problem:
I'm not familiar with your monitoring stack. I assume bgwriter.sync_time refers to pg_stat_bgwriter.checkpoint_sync_time? Also, most of the stats shown will increase monotonically until the stats are reset. So it looks like our monitoring stack is either resetting stats frequently, or is implicitly doing a delta between each consecutive period for display purposes. And what are the units? bgwriter.buffers_checkpoint is presumably in buffers as the numerator, but over what period of time in the denominator?
Anyway, it looks to me like you have a checkpoint problem. The checkpoint overwhelms your IO system. The overwhelmed IO system then backs up into the bgwriter. What you see in the bgwriter is just a symptom, not the cause. The background writer is usually not very useful in recent versions of PostgreSQL, anyway. But, the same IO problem that is clogging up the background writer is also clogging up either your buffer_backend, or your WAL writes/fsyncs. And both of those will destroy your throughput.
(apologies for the image)
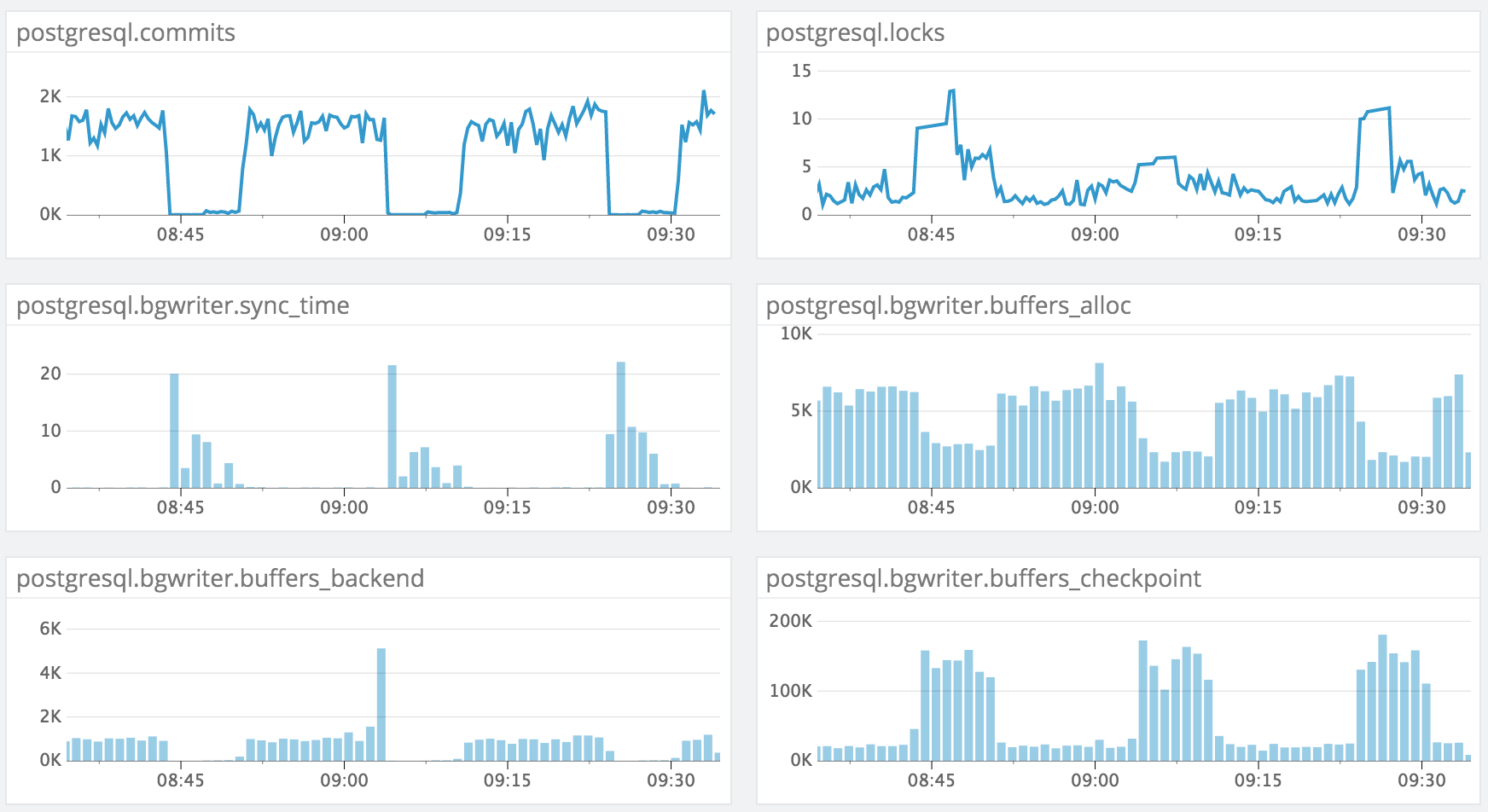
Our settings for the background writer are pretty standard OOB (I threw in some others that I thought might be helpful, too):name | setting | unit-------------------------+---------+------bgwriter_delay | 200 | msbgwriter_lru_maxpages | 100 |bgwriter_lru_multiplier | 2 |maintenance_work_mem | 65536 | kBmax_worker_processes | 8 |work_mem | 32768 | kB
What are your checkpoint settings?
Also, you should turn on log_checkpoints.
It seems to me that the background writer just can't keep up with the amount of writes that I am trying to do and freezes all the updates. What are my options to improve the background writer performance here?
You probably just need more IO throughput in general.
Cheers,
Jeff
Вложения
On Wed, Jan 13, 2016 at 11:51 AM, Jeff Janes <jeff.janes@gmail.com> wrote:
Anyway, it looks to me like you have a checkpoint problem. The checkpoint overwhelms your IO system. The overwhelmed IO system then backs up into the bgwriter. What you see in the bgwriter is just a symptom, not the cause. The background writer is usually not very useful in recent versions of PostgreSQL, anyway. But, the same IO problem that is clogging up the background writer is also clogging up either your buffer_backend, or your WAL writes/fsyncs. And both of those will destroy your throughput.
That was my intuition too. Not enough I/O available from the hardware for the workload requested.
As recommended, log your checkpoints and try tuning them to spread the load.
On Wed, Jan 13, 2016 at 9:48 AM Vick Khera <vivek@khera.org> wrote:
That was my intuition too. Not enough I/O available from the hardware for the workload requested.As recommended, log your checkpoints and try tuning them to spread the load.
Thanks guys, will turn on checkpoint logging and try to sniff this out further.