Обсуждение: Reduce ProcArrayLock contention
I have been working on to analyze different ways to reduce
The idea behind second approach (GroupClear Xid) is, first try to get
the contention around ProcArrayLock. I have evaluated mainly
2 ideas, first one is to partition the ProcArrayLock (the basic idea
is to allow multiple clients (equal to number of ProcArrayLock partitions)
to perform ProcArrayEndTransaction and then wait for all of them at
GetSnapshotData time) and second one is to have a mechanism to
GroupClear the Xid during ProcArrayEndTransaction() and the second
idea clearly stands out in my tests, so I have prepared the patch for that
to further discuss here.
ProcArrayLock conditionally in ProcArrayEndTransaction(), if we get
the lock then clear the advertised XID, else set the flag (which indicates
that advertised XID needs to be clear for this proc) and push this
proc to pendingClearXidList. Except one proc, all other proc's will
wait for their Xid to be cleared. The only allowed proc will attempt the
lock acquiration, after acquring the lock, pop all of the requests off the
list using compare-and-swap, servicing each one before moving to
next proc, and clearing their Xids. After servicing all the requests
on pendingClearXidList, release the lock and once again go through
the saved pendingClearXidList and wake all the processes waiting
for their Xid to be cleared. To set the appropriate value for
ShmemVariableCache->latestCompletedXid, we need to advertise
latestXid incase proc needs to be pushed to pendingClearXidList.
the saved pendingClearXidList and wake all the processes waiting
for their Xid to be cleared. To set the appropriate value for
ShmemVariableCache->latestCompletedXid, we need to advertise
latestXid incase proc needs to be pushed to pendingClearXidList.
Attached patch implements the above idea.
Performance Data
-----------------------------
RAM - 500GB
8 sockets, 64 cores(Hyperthreaded128 threads total)
Non-default parameters
------------------------------------
max_connections = 150
shared_buffers=8GB
min_wal_size=10GB
max_wal_size=15GB
checkpoint_timeout =35min
maintenance_work_mem = 1GB
checkpoint_completion_target = 0.9
wal_buffers = 256MB
pgbench setup
------------------------
scale factor - 300
Data is on magnetic disk and WAL on ssd.
pgbench -M prepared tpc-b
Head : commit 51d0fe5d
Patch -1 : group_xid_clearing_at_trans_end_rel_v1
| Client Count/TPS | 1 | 8 | 16 | 32 | 64 | 128 |
| HEAD | 814 | 6092 | 10899 | 19926 | 23636 | 17812 |
| Patch-1 | 1086 | 6483 | 11093 | 19908 | 31220 | 28237 |
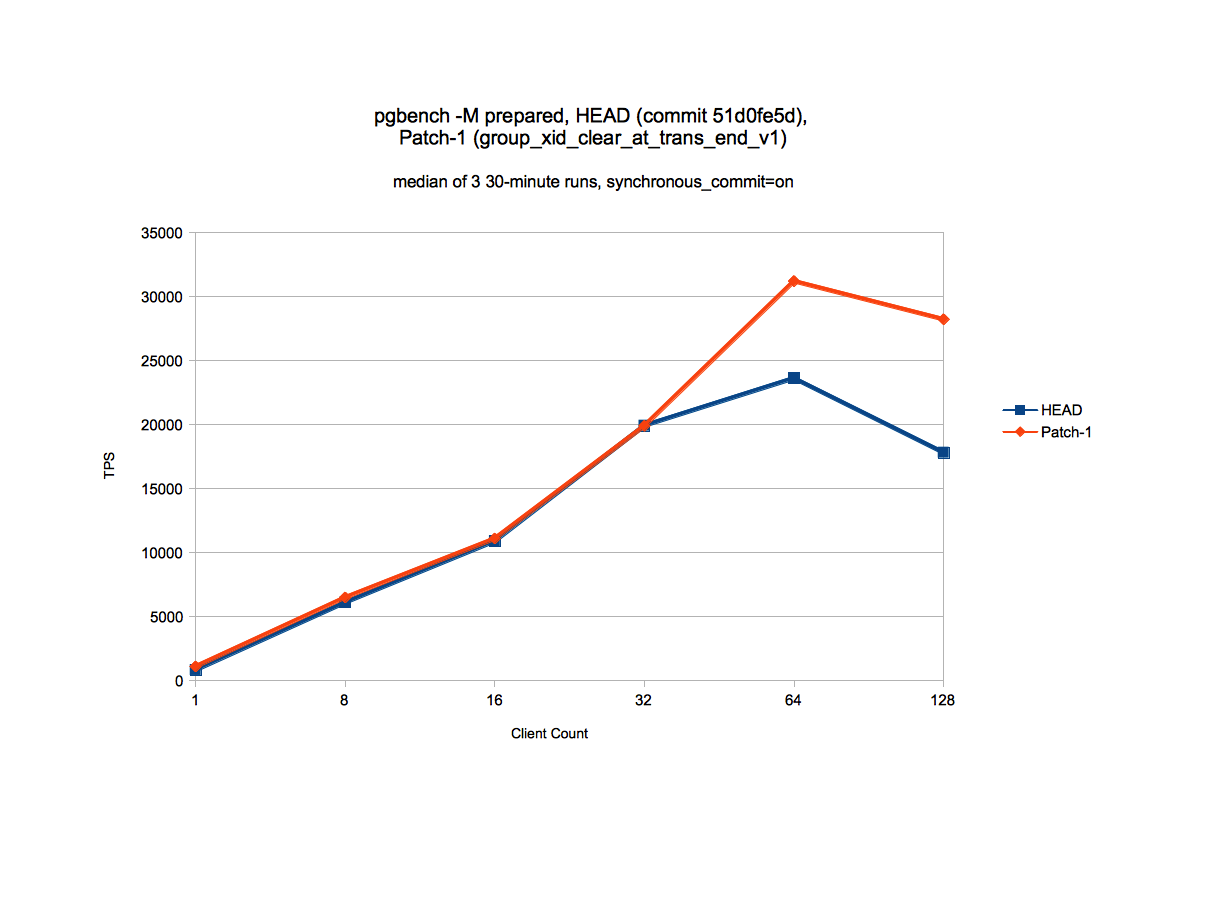
The graph for the data is attached.
Points about performance data
---------------------------------------------
1. Gives good performance improvement at or greater than 64 clients
and give somewhat moderate improvement at lower client count. The
reason is that because the contention around ProcArrayLock is mainly
seen at higher client count. I have checked that at higher client-count,
it started behaving lockless (which means performance with patch is
equivivalent to if we just comment out ProcArrayLock in
ProcArrayEndTransaction()).
2. There is some noise in this data (at 1 client count, I don't expect
much difference).
3. I have done similar tests on power-8 m/c and found similar gains.
4. The gains are visible when the data fits in shared_buffers as for other
workloads I/O starts dominating.
5. I have seen that effect of Patch is much more visible if we keep
autovacuum = off (do manual vacuum after each run) and keep
wal_writer_delay to lower value (say 20ms). I have not included that
data here, but if somebody is interested, I can do the detailed tests
against HEAD with those settings and share the results.
Here are steps used to take data (there are repeated for each reading)
--------------------------------------------------------------------------------------------------------
1. Start Server
2. dropdb postgres
3. createdb posters
4. pgbench -i -s 300 postgres
5. pgbench -c $threads -j $threads -T 1800 -M prepared postgres
6. checkpoint
7. Stop Server
Thanks to Robert Haas for having discussion (offlist) about the idea
and suggestions to improve it and also Andres Freund for having
discussion and sharing thoughts about this idea at PGCon.
Suggestions?
Вложения
{kind=link}
On 29 June 2015 at 16:27, Amit Kapila <amit.kapila16@gmail.com> wrote:
--
Thanks to Robert Haas for having discussion (offlist) about the ideaand suggestions to improve it and also Andres Freund for havingdiscussion and sharing thoughts about this idea at PGCon.
Weird. This patch is implemented exactly the way I said to implement it publicly at PgCon.
Was nobody recording the discussion at the unconference??
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On June 29, 2015 7:02:10 PM GMT+02:00, Simon Riggs <simon@2ndQuadrant.com> wrote: >On 29 June 2015 at 16:27, Amit Kapila <amit.kapila16@gmail.com> wrote: > > >> Thanks to Robert Haas for having discussion (offlist) about the idea >> and suggestions to improve it and also Andres Freund for having >> discussion and sharing thoughts about this idea at PGCon. >> > >Weird. This patch is implemented exactly the way I said to implement it >publicly at PgCon. > >Was nobody recording the discussion at the unconference?? Amit presented an earlier version of this at the in unconference? --- Please excuse brevity and formatting - I am writing this on my mobile phone.
On 29 June 2015 at 18:11, Andres Freund <andres@anarazel.de> wrote:
Forming a list, like we use for sync rep and having just a single process walk the queue was the way I suggested then and previously.
--
On June 29, 2015 7:02:10 PM GMT+02:00, Simon Riggs <simon@2ndQuadrant.com> wrote:
>On 29 June 2015 at 16:27, Amit Kapila <amit.kapila16@gmail.com> wrote:
>
>
>> Thanks to Robert Haas for having discussion (offlist) about the idea
>> and suggestions to improve it and also Andres Freund for having
>> discussion and sharing thoughts about this idea at PGCon.
>>
>
>Weird. This patch is implemented exactly the way I said to implement it
>publicly at PgCon.
>
>Was nobody recording the discussion at the unconference??
Amit presented an earlier version of this at the in unconference?
Yes, I know. And we all had a long conversation about how to do it without waking up the other procs.
Weird.
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Jun 29, 2015 at 1:22 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > Yes, I know. And we all had a long conversation about how to do it without > waking up the other procs. > > Forming a list, like we use for sync rep and having just a single process > walk the queue was the way I suggested then and previously. > > Weird. I am not sure what your point is. Are you complaining that you didn't get a design credit for this patch? If so, I think that's a bit petty. I agree that you mentioned something along these lines at PGCon, but Amit and I have been discussing this every week for over a month, so it's not as if the conversations at PGCon were the only ones, or the first. Nor is there a conspiracy to deprive Simon Riggs of credit for his ideas. I believe that you should assume good faith and take it for granted that Amit credited who he believed that he got his ideas from. The fact that you may have had similar ideas does not mean that he got his from you. It probably does mean that they are good ideas, since we are apparently all thinking in the same way. (I could provide EDB email internal emails documenting the timeline of various ideas and showing which ones happened before and after PGCon, and we could debate exactly who thought of what when. But I don't really see the point. I certainly hope that a debate over who deserves how much credit for what isn't going to overshadow the good work Amit has done on this patch.) -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Mon, Jun 29, 2015 at 10:52 PM, Simon Riggs <simon@2ndquadrant.com> wrote:
>
> On 29 June 2015 at 18:11, Andres Freund <andres@anarazel.de> wrote:
>>
>> On June 29, 2015 7:02:10 PM GMT+02:00, Simon Riggs <simon@2ndQuadrant.com> wrote:
>> >On 29 June 2015 at 16:27, Amit Kapila <amit.kapila16@gmail.com> wrote:
>> >
>> >
>> >> Thanks to Robert Haas for having discussion (offlist) about the idea
>> >> and suggestions to improve it and also Andres Freund for having
>> >> discussion and sharing thoughts about this idea at PGCon.
>> >>
>> >
>> >Weird. This patch is implemented exactly the way I said to implement it
>> >publicly at PgCon.
>> >
>> >Was nobody recording the discussion at the unconference??
>>
>> Amit presented an earlier version of this at the in unconference?
>
>
> Yes, I know. And we all had a long conversation about how to do it without waking up the other procs.
>
> Forming a list, like we use for sync rep and having just a single process walk the queue was the way I suggested then and previously.
>
>
> On 29 June 2015 at 18:11, Andres Freund <andres@anarazel.de> wrote:
>>
>> On June 29, 2015 7:02:10 PM GMT+02:00, Simon Riggs <simon@2ndQuadrant.com> wrote:
>> >On 29 June 2015 at 16:27, Amit Kapila <amit.kapila16@gmail.com> wrote:
>> >
>> >
>> >> Thanks to Robert Haas for having discussion (offlist) about the idea
>> >> and suggestions to improve it and also Andres Freund for having
>> >> discussion and sharing thoughts about this idea at PGCon.
>> >>
>> >
>> >Weird. This patch is implemented exactly the way I said to implement it
>> >publicly at PgCon.
>> >
>> >Was nobody recording the discussion at the unconference??
>>
>> Amit presented an earlier version of this at the in unconference?
>
>
> Yes, I know. And we all had a long conversation about how to do it without waking up the other procs.
>
> Forming a list, like we use for sync rep and having just a single process walk the queue was the way I suggested then and previously.
>
Yes, I remember very well about your suggestion which you have
given during Unconference and I really value that idea/suggestion.
Here, the point is that I could get chance to have in-person discussion
with Robert and Andres where they have spent more time discussing
about the problem (Robert has discussed about this much more apart
from PGCon as well), but that doesn't mean I am not thankful of the
ideas or suggestions I got from you and or others during Unconference.
Thank you for participating in the discussion and giving suggestions
and I really mean it, as I felt good about it even after wards.
Now, I would like to briefly explain how allow-one-waker idea has
helped to improve the patch as not every body here was present
in that Un-conference. The basic problem I was seeing during
initial version of patch was that I was using LWLockAcquireOrWait
call for all the clients who are not able to get ProcArrayLock
(conditionally in the first attempt) and then after waking each proc
was checking if it's XID is cleared and if not they were again try
to AcquireOrWait for ProcArrayLock, this was limiting the patch
to improve performance at somewhat moderate client count like
32 or 64 because even trying for LWLock in exclusive mode again
and again was the limiting factor (I have tried with
LWLockAcquireConditional as well instead of LWLockAcquireOrWait,
though it helped a bit but not very much). Allowing just one-client
to become kind of Group leader to clear the other proc's xid and wake
them-up and all the other proc's waiting after adding them to pendingClearXid
list has helped to reduce the bottleneck around procarraylock significantly.
On 30 June 2015 at 03:43, Robert Haas <robertmhaas@gmail.com> wrote:
--
On Mon, Jun 29, 2015 at 1:22 PM, Simon Riggs <simon@2ndquadrant.com> wrote:
> Yes, I know. And we all had a long conversation about how to do it without
> waking up the other procs.
>
> Forming a list, like we use for sync rep and having just a single process
> walk the queue was the way I suggested then and previously.
>
> Weird.
I am not sure what your point is. Are you complaining that you didn't
get a design credit for this patch? If so, I think that's a bit
petty. I agree that you mentioned something along these lines at
PGCon, but Amit and I have been discussing this every week for over a
month, so it's not as if the conversations at PGCon were the only
ones, or the first. Nor is there a conspiracy to deprive Simon Riggs
of credit for his ideas. I believe that you should assume good faith
and take it for granted that Amit credited who he believed that he got
his ideas from. The fact that you may have had similar ideas does not
mean that he got his from you. It probably does mean that they are
good ideas, since we are apparently all thinking in the same way.
Oh, I accept multiple people can have the same ideas. That happens to me a lot around here.
What I find weird is that the discussion was so intense about LWLockAcquireOrWait that when someone presented a solution there were people that didn't notice. It makes me wonder whether large group discussions are worth it.
What I find even weirder is the thought that there were another 100 people in the room and it makes me wonder whether others present had even better ideas but they don't speak up for some other reason. I guess that happens on-list all the time, its just we seldom experience the number of people watching our discussions. I wonder how many times people give good ideas and we ignore them, myself included.
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Jun 29, 2015 at 11:14 PM, Simon Riggs <simon@2ndquadrant.com> wrote: > What I find weird is that the discussion was so intense about > LWLockAcquireOrWait that when someone presented a solution there were people > that didn't notice. It makes me wonder whether large group discussions are > worth it. I didn't think of this myself, but it feels like something I could have thought of easily. -- Peter Geoghegan
On 30 June 2015 at 04:21, Amit Kapila <amit.kapila16@gmail.com> wrote:
--
Now, I would like to briefly explain how allow-one-waker idea hashelped to improve the patch as not every body here was presentin that Un-conference.
The same idea applies for marking commits in clog, for which I have been sitting on a patch for a month or so and will post now I'm done travelling.
These ideas have been around some time and are even listed on the PostgreSQL TODO:
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Tue, Jun 30, 2015 at 11:53 AM, Simon Riggs <simon@2ndquadrant.com> wrote:
>
> On 30 June 2015 at 04:21, Amit Kapila <amit.kapila16@gmail.com> wrote:
>
>>
>> Now, I would like to briefly explain how allow-one-waker idea has
>> helped to improve the patch as not every body here was present
>> in that Un-conference.
>
>
> The same idea applies for marking commits in clog, for which I have been sitting on a patch for a month or so and will post now I'm done travelling.
>
Sure and I think we might want to try something similar even
>
> On 30 June 2015 at 04:21, Amit Kapila <amit.kapila16@gmail.com> wrote:
>
>>
>> Now, I would like to briefly explain how allow-one-waker idea has
>> helped to improve the patch as not every body here was present
>> in that Un-conference.
>
>
> The same idea applies for marking commits in clog, for which I have been sitting on a patch for a month or so and will post now I'm done travelling.
>
Sure and I think we might want to try something similar even
for XLogFlush where we use LWLockAcquireOrWait for
WALWriteLock, not sure how it will workout in that case as
I/O is involved, but I think it is worth trying.
On 30 June 2015 at 07:30, Amit Kapila <amit.kapila16@gmail.com> wrote:
--
Sure and I think we might want to try something similar evenfor XLogFlush where we use LWLockAcquireOrWait forWALWriteLock, not sure how it will workout in that case asI/O is involved, but I think it is worth trying.
+1
Simon Riggs http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Mon, Jun 29, 2015 at 8:57 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
pgbench setup------------------------scale factor - 300Data is on magnetic disk and WAL on ssd.pgbench -M prepared tpc-bHead : commit 51d0fe5dPatch -1 : group_xid_clearing_at_trans_end_rel_v1
Client Count/TPS 1 8 16 32 64 128 HEAD 814 6092 10899 19926 23636 17812 Patch-1 1086 6483 11093 19908 31220 28237 The graph for the data is attached.
Numbers look impressive and definitely shows that the idea is worth pursuing. I tried patch on my laptop. Unfortunately, at least for 4 and 8 clients, I did not see any improvement. In fact, averages over 2 runs showed a slight 2-4% decline in the tps. Having said that, there is no reason to disbelieve your numbers and no much powerful machines, we might see the gains.
BTW I ran the tests with, pgbench -s 10 -c 4 -T 300
Points about performance data---------------------------------------------1. Gives good performance improvement at or greater than 64 clientsand give somewhat moderate improvement at lower client count. Thereason is that because the contention around ProcArrayLock is mainlyseen at higher client count. I have checked that at higher client-count,it started behaving lockless (which means performance with patch isequivivalent to if we just comment out ProcArrayLock inProcArrayEndTransaction()).
Well, I am not entirely sure if thats a correct way of looking at it. Sure, you would see less contention on the ProcArrayLock because the fact is that there are far fewer backends trying to acquire it. But those who don't get the lock will sleep and hence the contention is moved somewhere else, at least partially.
2. There is some noise in this data (at 1 client count, I don't expectmuch difference).3. I have done similar tests on power-8 m/c and found similar gains.
As I said, I'm not seeing benefits on my laptop (Macbook Pro, Quad core, SSD). But then I ran with much lower scale factor and much lesser number of clients.
4. The gains are visible when the data fits in shared_buffers as for otherworkloads I/O starts dominating.
Thats seems be perfectly expected.
5. I have seen that effect of Patch is much more visible if we keepautovacuum = off (do manual vacuum after each run) and keepwal_writer_delay to lower value (say 20ms).
Do you know why that happens? Is it because the contention moves somewhere else with autovacuum on?
Regarding the design itself, I've an idea that may be we can create a general purpose infrastructure to use this technique. If its useful here, I'm sure there are other places where this can be applied with similar effect.
For example, how about adding an API such as LWLockDispatchWork(lock, mode, function_ptr, data_ptr)? Here the data_ptr points to somewhere in shared memory that the function_ptr can work on once lock is available. If the lock is available in the requested mode then the function_ptr is executed with the given data_ptr and the function returns. If the lock is not available then the work is dispatched to some Q (tracked on per-lock basis?) and the process goes to sleep. Whenever the lock becomes available in the requested mode, the work is executed by some other backedn and the primary process is woken up. This will most likely happen in the LWLockRelease() path when the last holder is about to give up the lock so that it becomes available in the requested "mode". Now there is lot of handwaving here and I'm not sure if the LWLock infrastructure permits us to add something like this easily. But I thought I will put forward the idea anyways. In fact, I remember trying something of this sort a long time back, but can't recollect why I gave up on the idea. May be I did not see much benefit of the entire approach of clubbing work-pieces and doing them in a single process. But then I probably did not have access to powerful machines then to correctly measure the benefits. Hence I'm not willing to give up on the idea, especially given your test results.
BTW may be the LWLockDispatchWork() makes sense only for EXCLUSIVE locks because we tend to read from shared memory and populate local structures in READ mode and that can only happen in the primary backend itself.
Regarding the patch, the compare-and-exchange function calls that you've used would work only for 64-bit machines, right? You would need to use equivalent 32-bit calls on a 32-bit machine.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Fri, Jul 24, 2015 at 4:26 PM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote:
>
>
>
> On Mon, Jun 29, 2015 at 8:57 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>>
>>
>>
>> pgbench setup
>> ------------------------
>> scale factor - 300
>> Data is on magnetic disk and WAL on ssd.
>> pgbench -M prepared tpc-b
>>
>> Head : commit 51d0fe5d
>> Patch -1 : group_xid_clearing_at_trans_end_rel_v1
>>
>>
>> Client Count/TPS18163264128
>> HEAD814609210899199262363617812
>> Patch-11086648311093199083122028237
>>
>> The graph for the data is attached.
>>
>
> Numbers look impressive and definitely shows that the idea is worth pursuing. I tried patch on my laptop. Unfortunately, at least for 4 and 8 clients, I did not see any improvement.
>
>> Points about performance data
>> ---------------------------------------------
>> 1. Gives good performance improvement at or greater than 64 clients
>> and give somewhat moderate improvement at lower client count. The
>> reason is that because the contention around ProcArrayLock is mainly
>> seen at higher client count. I have checked that at higher client-count,
>> it started behaving lockless (which means performance with patch is
>> equivivalent to if we just comment out ProcArrayLock in
>> ProcArrayEndTransaction()).
>
>
> Well, I am not entirely sure if thats a correct way of looking at it. Sure, you would see less contention on the ProcArrayLock because the fact is that there are far fewer backends trying to acquire it.
>>
>> 4. The gains are visible when the data fits in shared_buffers as for other
>> workloads I/O starts dominating.
>
>
> Thats seems be perfectly expected.
>
>>
>> 5. I have seen that effect of Patch is much more visible if we keep
>> autovacuum = off (do manual vacuum after each run) and keep
>> wal_writer_delay to lower value (say 20ms).
>
>
> Do you know why that happens? Is it because the contention moves somewhere else with autovacuum on?
>
> Regarding the design itself, I've an idea that may be we can create a general purpose infrastructure to use this technique.
> For example, how about adding an API such as LWLockDispatchWork(lock, mode, function_ptr, data_ptr)? Here the data_ptr points to somewhere in shared memory that the function_ptr can work on once lock is available. If the lock is available in the requested mode then the function_ptr is
>
>
>
> On Mon, Jun 29, 2015 at 8:57 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>>
>>
>>
>> pgbench setup
>> ------------------------
>> scale factor - 300
>> Data is on magnetic disk and WAL on ssd.
>> pgbench -M prepared tpc-b
>>
>> Head : commit 51d0fe5d
>> Patch -1 : group_xid_clearing_at_trans_end_rel_v1
>>
>>
>> Client Count/TPS18163264128
>> HEAD814609210899199262363617812
>> Patch-11086648311093199083122028237
>>
>> The graph for the data is attached.
>>
>
> Numbers look impressive and definitely shows that the idea is worth pursuing. I tried patch on my laptop. Unfortunately, at least for 4 and 8 clients, I did not see any improvement.
>
I can't help in this because I think we need somewhat
bigger m/c to test the impact of patch.
> In fact, averages over 2 runs showed a slight 2-4% decline in the tps. Having said that, there is no reason to disbelieve your numbers and no much powerful machines, we might see the gains.
>
> BTW I ran the tests with, pgbench -s 10 -c 4 -T 300
>
>
I am not sure if this result is worth worrying to investigate as in
write tests (that too for short duration), such fluctuations can
occur and I think till we see complete results for multiple clients
(1, 4, 8 .. 64 or 128) (possible on some high end m/c), it is difficult
to draw any conclusion.
>
>> Points about performance data
>> ---------------------------------------------
>> 1. Gives good performance improvement at or greater than 64 clients
>> and give somewhat moderate improvement at lower client count. The
>> reason is that because the contention around ProcArrayLock is mainly
>> seen at higher client count. I have checked that at higher client-count,
>> it started behaving lockless (which means performance with patch is
>> equivivalent to if we just comment out ProcArrayLock in
>> ProcArrayEndTransaction()).
>
>
> Well, I am not entirely sure if thats a correct way of looking at it. Sure, you would see less contention on the ProcArrayLock because the fact is that there are far fewer backends trying to acquire it.
>
I was telling that fact even without my patch. Basically I have
tried by commenting ProcArrayLock in ProcArrayEndTransaction.
> But those who don't get the lock will sleep and hence the contention is moved somewhere else, at least partially.
>
>
Sure, if contention is reduced at one place it will move
to next lock.
>>
>> 4. The gains are visible when the data fits in shared_buffers as for other
>> workloads I/O starts dominating.
>
>
> Thats seems be perfectly expected.
>
>>
>> 5. I have seen that effect of Patch is much more visible if we keep
>> autovacuum = off (do manual vacuum after each run) and keep
>> wal_writer_delay to lower value (say 20ms).
>
>
> Do you know why that happens? Is it because the contention moves somewhere else with autovacuum on?
>
No, autovacuum generates I/O due to which sometimes there
is more variation in Write tests.
> Regarding the design itself, I've an idea that may be we can create a general purpose infrastructure to use this technique.
>
I think this could be beneficial if can comeup with
some clean interface.
> If its useful here, I'm sure there are other places where this can be applied with similar effect.
>
>
I also think so.
> For example, how about adding an API such as LWLockDispatchWork(lock, mode, function_ptr, data_ptr)? Here the data_ptr points to somewhere in shared memory that the function_ptr can work on once lock is available. If the lock is available in the requested mode then the function_ptr is
> executed with the given data_ptr and the function returns.
>
I can do something like that if others also agree with this new
API in LWLock series, but personally I don't think LWLock.c is
the right place to expose API for this work. Broadly the work
we are doing can be thought of below sub-tasks.
1. Advertise each backend's xid.
2. Push all backend's except one on global list.
3. wait till some-one wakes and check if the xid is cleared,
repeat untll the xid is clear
4. Acquire the lock
5. Pop all the backend's and clear each one's xid and used
their published xid to advance global latestCompleteXid.
6. Release Lock
7. Wake all the processes waiting for their xid to be cleared
and before waking mark that Xid of the backend is clear.
So among these only step 2 can be common among different
algorithms, other's need some work specific to each optimization.
Does any one else see a better way to provide a generic API, so
that it can be used for other places if required in future?
> If the lock is not available then the work is dispatched to some Q (tracked on per-lock basis?) and the process goes to sleep. Whenever the lock becomes available in the requested mode, the work is executed by some other backedn and the primary process is woken up. This will most likely
> happen in the LWLockRelease() path when the last holder is about to give up the lock so that it becomes available in the requested "mode".
>
I am not able to follow what you want to achieve with this,
Why is 'Q' better than the current process to perform the
work specific to whole group and does 'Q' also wait on the
current lock, if yes how?
I think this will over complicate the stuff without any real
benefit, atleast for this optimization.
>
> Regarding the patch, the compare-and-exchange function calls that you've used would work only for 64-bit machines, right? You would need to use equivalent 32-bit calls on a 32-bit machine.
>
> Regarding the patch, the compare-and-exchange function calls that you've used would work only for 64-bit machines, right? You would need to use equivalent 32-bit calls on a 32-bit machine.
>
I thought that internal API will automatically take care of it,
example for msvc it uses _InterlockedCompareExchange64
which if doesn't work on 32-bit systems or is not defined, then
we have to use 32-bit version, but I am not certain about
that fact.
Note - This patch requires some updation in src/backend/access/transam/README.
On Sat, Jul 25, 2015 at 12:42 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > I thought that internal API will automatically take care of it, > example for msvc it uses _InterlockedCompareExchange64 > which if doesn't work on 32-bit systems or is not defined, then > we have to use 32-bit version, but I am not certain about > that fact. Instead of using pg_atomic_uint64, how about using pg_atomic_uint32 and storing the pgprocno rather than the pointer directly? Then it can work the same way (and be the same size) on every platform. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sat, Jul 25, 2015 at 10:12 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>>
>
> Numbers look impressive and definitely shows that the idea is worth pursuing. I tried patch on my laptop. Unfortunately, at least for 4 and 8 clients, I did not see any improvement.>I can't help in this because I think we need somewhatbigger m/c to test the impact of patch.
I understand. IMHO it will be a good idea though to ensure that the patch does not cause regression for other setups such as a less powerful machine or while running with lower number of clients.
I was telling that fact even without my patch. Basically I havetried by commenting ProcArrayLock in ProcArrayEndTransaction.
I did not get that. You mean the TPS is same if you run with commenting out ProcArrayLock in ProcArrayEndTransaction? Is that safe to do?
> But those who don't get the lock will sleep and hence the contention is moved somewhere else, at least partially.
>Sure, if contention is reduced at one place it will moveto next lock.
What I meant was that the lock may not show up in the contention because all but one processes now sleep for their work to do be done by the group leader. So the total time spent in the critical section remains the same, but not shown in the profile. Sure, your benchmark numbers show this is still better than all processes contending for the lock.
No, autovacuum generates I/O due to which sometimes thereis more variation in Write tests.
Sure, but on an average does it still show similar improvements? Or does the test becomes IO bound and hence the bottleneck shifts somewhere else? Can you please post those numbers as well when you get chance?
I can do something like that if others also agree with this newAPI in LWLock series, but personally I don't think LWLock.c isthe right place to expose API for this work. Broadly the workwe are doing can be thought of below sub-tasks.1. Advertise each backend's xid.2. Push all backend's except one on global list.3. wait till some-one wakes and check if the xid is cleared,repeat untll the xid is clear4. Acquire the lock5. Pop all the backend's and clear each one's xid and usedtheir published xid to advance global latestCompleteXid.6. Release Lock7. Wake all the processes waiting for their xid to be clearedand before waking mark that Xid of the backend is clear.So among these only step 2 can be common among differentalgorithms, other's need some work specific to each optimization.
Right, but if we could encapsulate that work in a function that just needs to work on some shared memory, I think we can build such infrastructure. Its possible though a more elaborate infrastructure is needed that just one function pointer. For example, in this case, we also want to set the latestCompletedXid after clearing xids for all pending processes.
>> Regarding the patch, the compare-and-exchange function calls that you've used would work only for 64-bit machines, right? You would need to use equivalent 32-bit calls on a 32-bit machine.
>I thought that internal API will automatically take care of it,example for msvc it uses _InterlockedCompareExchange64which if doesn't work on 32-bit systems or is not defined, thenwe have to use 32-bit version, but I am not certain aboutthat fact.
Hmm. The pointer will be a 32-bit field on a 32-bit machine. I don't know how exchanging that with 64-bit integer be safe.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Mon, Jul 27, 2015 at 8:47 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>
> On Sat, Jul 25, 2015 at 12:42 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > I thought that internal API will automatically take care of it,
> > example for msvc it uses _InterlockedCompareExchange64
> > which if doesn't work on 32-bit systems or is not defined, then
> > we have to use 32-bit version, but I am not certain about
> > that fact.
>
> Instead of using pg_atomic_uint64, how about using pg_atomic_uint32
> and storing the pgprocno rather than the pointer directly?
>
> On Sat, Jul 25, 2015 at 12:42 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > I thought that internal API will automatically take care of it,
> > example for msvc it uses _InterlockedCompareExchange64
> > which if doesn't work on 32-bit systems or is not defined, then
> > we have to use 32-bit version, but I am not certain about
> > that fact.
>
> Instead of using pg_atomic_uint64, how about using pg_atomic_uint32
> and storing the pgprocno rather than the pointer directly?
>
Good Suggestion!
I think this can work the way you are suggesting and I am working on
same. Here I have one question, do you prefer to see the code for
this optimisation be done via some LWLock interface as Pavan is
suggesting? I am not very sure if LWLock is a good interface for this
work, but surely I can encapsulate it into different functions rather than
doing everything in ProcArrayEndTransaction.
On Wed, Jul 29, 2015 at 10:54 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Mon, Jul 27, 2015 at 8:47 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Sat, Jul 25, 2015 at 12:42 AM, Amit Kapila <amit.kapila16@gmail.com> >> wrote: >> > I thought that internal API will automatically take care of it, >> > example for msvc it uses _InterlockedCompareExchange64 >> > which if doesn't work on 32-bit systems or is not defined, then >> > we have to use 32-bit version, but I am not certain about >> > that fact. >> >> Instead of using pg_atomic_uint64, how about using pg_atomic_uint32 >> and storing the pgprocno rather than the pointer directly? >> > > Good Suggestion! > > I think this can work the way you are suggesting and I am working on > same. Here I have one question, do you prefer to see the code for > this optimisation be done via some LWLock interface as Pavan is > suggesting? I am not very sure if LWLock is a good interface for this > work, but surely I can encapsulate it into different functions rather than > doing everything in ProcArrayEndTransaction. I would try to avoid changing lwlock.c. It's pretty easy when so doing to create mechanisms that work now but make further upgrades to the general lwlock mechanism difficult. I'd like to avoid that. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2015-07-29 12:54:59 -0400, Robert Haas wrote: > I would try to avoid changing lwlock.c. It's pretty easy when so > doing to create mechanisms that work now but make further upgrades to > the general lwlock mechanism difficult. I'd like to avoid that. I'm massively doubtful that re-implementing parts of lwlock.c is the better outcome. Then you have two different infrastructures you need to improve over time.
On Wed, Jul 29, 2015 at 2:18 PM, Andres Freund <andres@anarazel.de> wrote: > On 2015-07-29 12:54:59 -0400, Robert Haas wrote: >> I would try to avoid changing lwlock.c. It's pretty easy when so >> doing to create mechanisms that work now but make further upgrades to >> the general lwlock mechanism difficult. I'd like to avoid that. > > I'm massively doubtful that re-implementing parts of lwlock.c is the > better outcome. Then you have two different infrastructures you need to > improve over time. That is also true, but I don't think we're going to be duplicating anything from lwlock.c in this case. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Jul 29, 2015 at 11:48 PM, Andres Freund <andres@anarazel.de> wrote:
>
> On 2015-07-29 12:54:59 -0400, Robert Haas wrote:
> > I would try to avoid changing lwlock.c. It's pretty easy when so
> > doing to create mechanisms that work now but make further upgrades to
> > the general lwlock mechanism difficult. I'd like to avoid that.
>
> I'm massively doubtful that re-implementing parts of lwlock.c is the
> better outcome. Then you have two different infrastructures you need to
> improve over time.
> I understand. IMHO it will be a good idea though to ensure that the patch does not cause regression for other setups such as a less powerful
>>
>>
>> I was telling that fact even without my patch. Basically I have
>> tried by commenting ProcArrayLock in ProcArrayEndTransaction.
>>
> I did not get that. You mean the TPS is same if you run with commenting out ProcArrayLock in ProcArrayEndTransaction?
>>
>>
>>
>> No, autovacuum generates I/O due to which sometimes there
>> is more variation in Write tests.
> Sure, but on an average does it still show similar improvements?
>>
>>
>>
>> So among these only step 2 can be common among different
>> algorithms, other's need some work specific to each optimization.
>>
> Right, but if we could encapsulate that work in a function that just needs to work on some shared memory, I think we can build such infrastructure.
>
>
>> >
>> > Regarding the patch, the compare-and-exchange function calls that you've used would work only for 64-bit machines, right? You would need to use equivalent 32-bit calls on a 32-bit machine.
> >
>>
>> I thought that internal API will automatically take care of it,
>> example for msvc it uses _InterlockedCompareExchange64
>> which if doesn't work on 32-bit systems or is not defined, then
>> we have to use 32-bit version, but I am not certain about
>> that fact.
>>
> Hmm. The pointer will be a 32-bit field on a 32-bit machine. I don't know how exchanging that with 64-bit integer be safe.
>
> On 2015-07-29 12:54:59 -0400, Robert Haas wrote:
> > I would try to avoid changing lwlock.c. It's pretty easy when so
> > doing to create mechanisms that work now but make further upgrades to
> > the general lwlock mechanism difficult. I'd like to avoid that.
>
> I'm massively doubtful that re-implementing parts of lwlock.c is the
> better outcome. Then you have two different infrastructures you need to
> improve over time.
I agree and modified the patch to use 32-bit atomics based on idea
suggested by Robert and didn't modify lwlock.c.
> I understand. IMHO it will be a good idea though to ensure that the patch does not cause regression for other setups such as a less powerful
> machine or while running with lower number of clients.
>
>
Okay, I have tried it on CentOS VM, but the data is totally screwed (at
same client count across 2 runs the variation is quite high ranging from 300
to 3000 tps) to make any meaning out of it. I think if you want to collect data
on less powerful m/c, then also atleast we should ensure that it is taken in
a way that we are sure that it is not due to noise and there is actual regression,
then only we can decide whether we should investigate that or not.
Can you please try taking data with attached script
(perf_pgbench_tpcb_write.sh), few things you need to change in script
based on your setup (environment variables defined in beginning of script
like PGDATA), other thing is that you need to ensure that name of binaries
for HEAD and Patch should be changed in script if you are naming them
differently. It will generate the performance data in test*.txt files. Also try
to ensure that checkpoint should be configured such that it should not
occur in-between tests, else it will be difficult to conclude the results.
Some parameters you might want to consider for the same are
checkpoint_timeout, checkpoint_completion_target, min_wal_size,
max_wal_size.
>>
>>
>> I was telling that fact even without my patch. Basically I have
>> tried by commenting ProcArrayLock in ProcArrayEndTransaction.
>>
> I did not get that. You mean the TPS is same if you run with commenting out ProcArrayLock in ProcArrayEndTransaction?
Yes, TPS is almost same as with Patch.
> Is that safe to do?
No, that is not safe. I have done that just to see what is the maximum
gain we can get by reducing the contention around ProcArrayLock.
>>
>>
>>
>> No, autovacuum generates I/O due to which sometimes there
>> is more variation in Write tests.
> Sure, but on an average does it still show similar improvements?
>
Yes, number with and without autovacuum show similar trend, it's just
that you can see somewhat better results (more performance improvement)
with autovacuum=off and do manual vacuum at end of each test.
> Or does the test becomes IO bound and hence the bottleneck shifts somewhere
> else? Can you please post those numbers as well when you get chance?
The numbers posted in initial mail or in this mail are with autovacuum =on.
>>
>>
>>
>> So among these only step 2 can be common among different
>> algorithms, other's need some work specific to each optimization.
>>
> Right, but if we could encapsulate that work in a function that just needs to work on some shared memory, I think we can build such infrastructure.
For now, I have encapsulated the code into 2 separate functions, rather
than extending LWLock.c as that could easily lead to code which might
not be used in future even though currently it sounds like that and in-future
if we need to use same technique elsewhere then we can look into it.
>
>
>> >
>> > Regarding the patch, the compare-and-exchange function calls that you've used would work only for 64-bit machines, right? You would need to use equivalent 32-bit calls on a 32-bit machine.
> >
>>
>> I thought that internal API will automatically take care of it,
>> example for msvc it uses _InterlockedCompareExchange64
>> which if doesn't work on 32-bit systems or is not defined, then
>> we have to use 32-bit version, but I am not certain about
>> that fact.
>>
> Hmm. The pointer will be a 32-bit field on a 32-bit machine. I don't know how exchanging that with 64-bit integer be safe.
>
True, but that has to be in-general taken care by 64bit atomic API's,
like in this case it should fallback to either 32-bit version of API or
something that can work on 32-bit m/c. I think fallback support
is missing as of now in 64-bit API's which we should have if we want
to use those API's, but anyway for now I have modified the patch to
use 32-bit atomics.
Performance Data with modified patch.
pgbench setup
------------------------
scale factor - 300
Data is on magnetic disk and WAL on ssd.
pgbench -M prepared tpc-b
Data is median of 3 - 30 min runs, the detailed data for
all the 3 runs is in attached document
(perf_write_procarraylock_data.ods)
Head : commit c53f7387
Patch : group_xid_clearing_at_trans_end_rel_v2
| Client_Count/Patch_ver (TPS) | 1 | 8 | 16 | 32 | 64 | 128 |
| HEAD | 972 | 6004 | 11060 | 20074 | 23839 | 17798 |
| Patch | 1005 | 6260 | 11368 | 20318 | 30775 | 30215 |
Вложения
On Fri, Jul 31, 2015 at 10:11 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Wed, Jul 29, 2015 at 11:48 PM, Andres Freund <andres@anarazel.de> wrote:
> >
> > On 2015-07-29 12:54:59 -0400, Robert Haas wrote:
> > > I would try to avoid changing lwlock.c. It's pretty easy when so
> > > doing to create mechanisms that work now but make further upgrades to
> > > the general lwlock mechanism difficult. I'd like to avoid that.
> >
> > I'm massively doubtful that re-implementing parts of lwlock.c is the
> > better outcome. Then you have two different infrastructures you need to
> > improve over time.
>
> I agree and modified the patch to use 32-bit atomics based on idea
> suggested by Robert and didn't modify lwlock.c.
While looking at patch, I found that the way it was initialising the list
>
> On Wed, Jul 29, 2015 at 11:48 PM, Andres Freund <andres@anarazel.de> wrote:
> >
> > On 2015-07-29 12:54:59 -0400, Robert Haas wrote:
> > > I would try to avoid changing lwlock.c. It's pretty easy when so
> > > doing to create mechanisms that work now but make further upgrades to
> > > the general lwlock mechanism difficult. I'd like to avoid that.
> >
> > I'm massively doubtful that re-implementing parts of lwlock.c is the
> > better outcome. Then you have two different infrastructures you need to
> > improve over time.
>
> I agree and modified the patch to use 32-bit atomics based on idea
> suggested by Robert and didn't modify lwlock.c.
While looking at patch, I found that the way it was initialising the list
to be empty was wrong, it was using pgprocno as 0 to initialise the
list, as 0 is a valid pgprocno. I think we should use a number greater
that PROCARRAY_MAXPROC (maximum number of procs in proc
array).
Apart from above fix, I have modified src/backend/access/transam/README
to include the information about the improvement this patch brings to
reduce ProcArrayLock contention.
Вложения
On Mon, Aug 3, 2015 at 8:39 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> I agree and modified the patch to use 32-bit atomics based on idea >> suggested by Robert and didn't modify lwlock.c. > > While looking at patch, I found that the way it was initialising the list > to be empty was wrong, it was using pgprocno as 0 to initialise the > list, as 0 is a valid pgprocno. I think we should use a number greater > that PROCARRAY_MAXPROC (maximum number of procs in proc > array). > > Apart from above fix, I have modified src/backend/access/transam/README > to include the information about the improvement this patch brings to > reduce ProcArrayLock contention. I spent some time looking at this patch today and found that a good deal of cleanup work seemed to be needed. Attached is a cleaned-up version which makes a number of changes: 1. I got rid of all of the typecasts. You're supposed to treat pg_atomic_u32 as a magic data type that is only manipulated via the primitives provided, not just cast back and forth between that and u32. 2. I got rid of the memory barriers. System calls are full barriers, and so are compare-and-exchange operations. Between those two facts, we should be fine without these. 3. I removed the clearXid field you added to PGPROC. Since that's just a sentinel, I used nextClearXidElem for that purpose. There doesn't seem to be a need for two fields. 4. I factored out the actual XID-clearing logic into a new function ProcArrayEndTransactionInternal instead of repeating it twice. On the flip side, I merged PushProcAndWaitForXidClear with PopProcsAndClearXids and renamed the result to ProcArrayGroupClearXid, since there seemed to be no need to separate them. 5. I renamed PROC_NOT_IN_PGPROCARRAY to INVALID_PGPROCNO, which I think is more consistent with what we do elsewhere, and made it a compile-time constant instead of a value that must be computed every time it's used. 6. I overhauled the comments and README updates. I'm not entirely happy with the name "nextClearXidElem" but apart from that I'm fairly happy with this version. We should probably test it to make sure I haven't broken anything; on a quick 3-minute pgbench test on cthulhu (128-way EDB server) with 128 clients I got 2778 tps with master and 4330 tps with this version of the patch. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Вложения
On 2015-08-04 11:29:39 -0400, Robert Haas wrote: > On Mon, Aug 3, 2015 at 8:39 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > 1. I got rid of all of the typecasts. You're supposed to treat > pg_atomic_u32 as a magic data type that is only manipulated via the > primitives provided, not just cast back and forth between that and > u32. Absolutely. Otherwise no fallbacks can work. > 2. I got rid of the memory barriers. System calls are full barriers, > and so are compare-and-exchange operations. Between those two facts, > we should be fine without these. Actually by far not all system calls are full barriers? Regards, Andres
On Tue, Aug 4, 2015 at 11:33 AM, Andres Freund <andres@anarazel.de> wrote: > On 2015-08-04 11:29:39 -0400, Robert Haas wrote: >> On Mon, Aug 3, 2015 at 8:39 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> 1. I got rid of all of the typecasts. You're supposed to treat >> pg_atomic_u32 as a magic data type that is only manipulated via the >> primitives provided, not just cast back and forth between that and >> u32. > > Absolutely. Otherwise no fallbacks can work. > >> 2. I got rid of the memory barriers. System calls are full barriers, >> and so are compare-and-exchange operations. Between those two facts, >> we should be fine without these. > > Actually by far not all system calls are full barriers? How do we know which ones are and which ones are not? I can't believe PGSemaphoreUnlock isn't a barrier. That would be cruel. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Aug 4, 2015 at 8:59 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>
> On Mon, Aug 3, 2015 at 8:39 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> >> I agree and modified the patch to use 32-bit atomics based on idea
> >> suggested by Robert and didn't modify lwlock.c.
> >
> > While looking at patch, I found that the way it was initialising the list
> > to be empty was wrong, it was using pgprocno as 0 to initialise the
> > list, as 0 is a valid pgprocno. I think we should use a number greater
> > that PROCARRAY_MAXPROC (maximum number of procs in proc
> > array).
> >
> > Apart from above fix, I have modified src/backend/access/transam/README
> > to include the information about the improvement this patch brings to
> > reduce ProcArrayLock contention.
>
> I spent some time looking at this patch today and found that a good
> deal of cleanup work seemed to be needed. Attached is a cleaned-up
> version which makes a number of changes:
>
> 1. I got rid of all of the typecasts. You're supposed to treat
> pg_atomic_u32 as a magic data type that is only manipulated via the
> primitives provided, not just cast back and forth between that and
> u32.
>
> 2. I got rid of the memory barriers. System calls are full barriers,
> and so are compare-and-exchange operations. Between those two facts,
> we should be fine without these.
>
* No barrier semantics.
*/
STATIC_IF_INLINE uint32
pg_atomic_read_u32(volatile pg_atomic_uint32 *ptr)
>
> I'm not entirely happy with the name "nextClearXidElem" but apart from
> that I'm fairly happy with this version. We should probably test it
> to make sure I haven't broken anything;
>
> On Mon, Aug 3, 2015 at 8:39 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> >> I agree and modified the patch to use 32-bit atomics based on idea
> >> suggested by Robert and didn't modify lwlock.c.
> >
> > While looking at patch, I found that the way it was initialising the list
> > to be empty was wrong, it was using pgprocno as 0 to initialise the
> > list, as 0 is a valid pgprocno. I think we should use a number greater
> > that PROCARRAY_MAXPROC (maximum number of procs in proc
> > array).
> >
> > Apart from above fix, I have modified src/backend/access/transam/README
> > to include the information about the improvement this patch brings to
> > reduce ProcArrayLock contention.
>
> I spent some time looking at this patch today and found that a good
> deal of cleanup work seemed to be needed. Attached is a cleaned-up
> version which makes a number of changes:
>
> 1. I got rid of all of the typecasts. You're supposed to treat
> pg_atomic_u32 as a magic data type that is only manipulated via the
> primitives provided, not just cast back and forth between that and
> u32.
>
> 2. I got rid of the memory barriers. System calls are full barriers,
> and so are compare-and-exchange operations. Between those two facts,
> we should be fine without these.
>
I have kept barriers based on comments on top of atomic read, refer
below code:
*/
STATIC_IF_INLINE uint32
pg_atomic_read_u32(volatile pg_atomic_uint32 *ptr)
Note - The function header comments on pg_atomic_read_u32 and
corresponding write call seems to be reversed, but that is something
separate.
>
> I'm not entirely happy with the name "nextClearXidElem" but apart from
> that I'm fairly happy with this version. We should probably test it
> to make sure I haven't broken anything;
Okay, will look into it tomorrow.
On 2015-08-04 11:43:45 -0400, Robert Haas wrote: > On Tue, Aug 4, 2015 at 11:33 AM, Andres Freund <andres@anarazel.de> wrote: > > Actually by far not all system calls are full barriers? > > How do we know which ones are and which ones are not? Good question. Reading the source code of all implementations I suppose :( E.g. gettimeofday()/clock_gettime(), getpid() on linux aren't barriers. > I can't believe PGSemaphoreUnlock isn't a barrier. That would be cruel. Yea, I think that's a pretty safe bet. I mean even if you'd implement it locklessly in the kernel, that'd still employ significant enough barriers/atomic ops itself.
On 2015-08-04 21:20:20 +0530, Amit Kapila wrote: > I have kept barriers based on comments on top of atomic read, refer > below code: > * No barrier semantics. > */ > STATIC_IF_INLINE uint32 > pg_atomic_read_u32(volatile pg_atomic_uint32 *ptr) > > Note - The function header comments on pg_atomic_read_u32 and > corresponding write call seems to be reversed, but that is something > separate. Well, the question is whether you *need* barrier semantics in that place. If you just have a retry loop around a compare/exchange there's no point in having one, it'll just cause needless slowdown due to another bus-lock.
On Tue, Aug 4, 2015 at 11:50 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > I have kept barriers based on comments on top of atomic read, refer > below code: > > * No barrier semantics. > */ > STATIC_IF_INLINE uint32 > pg_atomic_read_u32(volatile pg_atomic_uint32 *ptr) > > Note - The function header comments on pg_atomic_read_u32 and > corresponding write call seems to be reversed, but that is something > separate. That doesn't matter, because the compare-and-exchange *is* a barrier. Putting a barrier between a store and an operation that is already a barrier doesn't do anything useful. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Aug 4, 2015 at 11:29 AM, Robert Haas <robertmhaas@gmail.com> wrote: > 4. I factored out the actual XID-clearing logic into a new function > ProcArrayEndTransactionInternal instead of repeating it twice. On the > flip side, I merged PushProcAndWaitForXidClear with > PopProcsAndClearXids and renamed the result to ProcArrayGroupClearXid, > since there seemed to be no need to separate them. Thinking about this a bit more, it's probably worth sticking an "inline" designation on ProcArrayEndTransactionInternal. Keeping the time for which we hold ProcArrayLock in exclusive mode down to the absolute minimum possible number of instructions seems like a good plan. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2015-08-04 21:20:20 +0530, Amit Kapila wrote: > Note - The function header comments on pg_atomic_read_u32 and > corresponding write call seems to be reversed, but that is something > separate. Fixed, thanks for noticing.
On Tue, Aug 4, 2015 at 8:59 PM, Robert Haas <robertmhaas@gmail.com> wrote:
I spent some time looking at this patch today and found that a good
deal of cleanup work seemed to be needed. Attached is a cleaned-up
version which makes a number of changes:
I'm not entirely happy with the name "nextClearXidElem" but apart from
that I'm fairly happy with this version.
I actually even thought if we can define some macros or functions to work on atomic list of PGPROCs. What we need is:
- Atomic operation to add a PGPROC to list list and return the head of the list at the time of addition
- Atomic operation to delink a list from the head and return the head of the list at that time
- Atomic operation to remove a PGPROC from the list and return next element in the list
- An iterator to work on the list.
This will avoid code duplication when this infrastructure is used at other places. Any mistake in the sequence of read/write/cas can lead to a hard to find bug.
Having said that, it might be ok if we go with the current approach and then revisit this if and when other parts require similar logic.
Thanks,
Pavan
Pavan Deolasee http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training & Services
PostgreSQL Development, 24x7 Support, Training & Services
On Wed, Aug 5, 2015 at 8:30 AM, Pavan Deolasee <pavan.deolasee@gmail.com> wrote: > I actually even thought if we can define some macros or functions to work on > atomic list of PGPROCs. What we need is: > > - Atomic operation to add a PGPROC to list list and return the head of the > list at the time of addition > - Atomic operation to delink a list from the head and return the head of the > list at that time > - Atomic operation to remove a PGPROC from the list and return next element > in the list > - An iterator to work on the list. The third operation is unsafe because of the A-B-A problem. That's why the patch clears the whole list instead of popping an individual entry. > This will avoid code duplication when this infrastructure is used at other > places. Any mistake in the sequence of read/write/cas can lead to a hard to > find bug. > > Having said that, it might be ok if we go with the current approach and then > revisit this if and when other parts require similar logic. Yeah, I don't think we should assume this will be a generic facility. We can make it one later if needed. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Aug 4, 2015 at 8:59 PM, Robert Haas <robertmhaas@gmail.com> wrote:
I'm not entirely happy with the name "nextClearXidElem" but apart from
that I'm fairly happy with this version. We should probably test it
to make sure I haven't broken anything;
I have verified the patch and it is fine. I have tested it via manual
tests; for long pgbench tests, results are quite similar to previous
versions of patch.
Few changes, I have made in patch:
1.
+static void
+ProcArrayGroupClearXid(PGPROC *proc, TransactionId latestXid)
+{
+ volatile PROC_HDR *procglobal = ProcGlobal;
+ uint32 nextidx;
+ uint32 wakeidx;
+ int extraWaits = -1;
+
+ /* We should definitely have an XID to clear. */
+ Assert(TransactionIdIsValid(pgxact->xid));
Here Assert is using pgxact which is wrong.
2. Made ProcArrayEndTransactionInternal as inline function as
suggested by you.
Вложения
On Wed, Aug 5, 2015 at 10:59 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> On Tue, Aug 4, 2015 at 8:59 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>>
>> I'm not entirely happy with the name "nextClearXidElem" but apart from
>> that I'm fairly happy with this version. We should probably test it
>> to make sure I haven't broken anything;
>
>
> I have verified the patch and it is fine. I have tested it via manual
> tests; for long pgbench tests, results are quite similar to previous
> versions of patch.
>
> Few changes, I have made in patch:
>
> 1.
>
> +static void
>
> +ProcArrayGroupClearXid(PGPROC *proc, TransactionId latestXid)
>
> +{
>
> + volatile PROC_HDR *procglobal = ProcGlobal;
>
> + uint32 nextidx;
>
> + uint32 wakeidx;
>
> + int extraWaits = -1;
>
> +
>
> + /* We should definitely have an XID to clear. */
>
> + Assert(TransactionIdIsValid(pgxact->xid));
>
>
>
> Here Assert is using pgxact which is wrong.
>
> 2. Made ProcArrayEndTransactionInternal as inline function as
> suggested by you.
OK, committed.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Thu, Aug 6, 2015 at 9:36 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>
>
> OK, committed.
>
Thank you.
>
>
> OK, committed.
>
Thank you.
On 08/07/2015 12:41 AM, Amit Kapila wrote: > On Thu, Aug 6, 2015 at 9:36 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> >> >> OK, committed. >> > > Thank you. > Fyi, there is something in pgbench that has caused a testing regression - havn't tracked down what yet. Against 9.6 server (846f8c9483a8f31e45bf949db1721706a2765771) 9.6 pgbench: ------------ progress: 10.0 s, 53525.0 tps, lat 1.485 ms stddev 0.523 progress: 20.0 s, 15750.6 tps, lat 5.077 ms stddev 1.950 ... progress: 300.0 s, 15636.9 tps, lat 5.114 ms stddev 1.989 9.5 pgbench: ------------ progress: 10.0 s, 50119.5 tps, lat 1.587 ms stddev 0.576 progress: 20.0 s, 51413.1 tps, lat 1.555 ms stddev 0.553 ... progress: 300.0 s, 52951.6 tps, lat 1.509 ms stddev 0.657 Both done with -c 80 -j 80 -M prepared -P 10 -T 300. Just thought I would post it in this thread, because this change does help on the performance numbers compared to 9.5 :) Best regards, Jesper
On Fri, Aug 7, 2015 at 8:00 PM, Jesper Pedersen <jesper.pedersen@redhat.com> wrote:
On 08/07/2015 12:41 AM, Amit Kapila wrote:On Thu, Aug 6, 2015 at 9:36 PM, Robert Haas <robertmhaas@gmail.com> wrote:
OK, committed.
Thank you.
Fyi, there is something in pgbench that has caused a testing regression - havn't tracked down what yet.
Against 9.6 server (846f8c9483a8f31e45bf949db1721706a2765771)
9.6 pgbench:
------------
progress: 10.0 s, 53525.0 tps, lat 1.485 ms stddev 0.523
progress: 20.0 s, 15750.6 tps, lat 5.077 ms stddev 1.950
...
progress: 300.0 s, 15636.9 tps, lat 5.114 ms stddev 1.989
9.5 pgbench:
------------
progress: 10.0 s, 50119.5 tps, lat 1.587 ms stddev 0.576
progress: 20.0 s, 51413.1 tps, lat 1.555 ms stddev 0.553
...
progress: 300.0 s, 52951.6 tps, lat 1.509 ms stddev 0.657
Both done with -c 80 -j 80 -M prepared -P 10 -T 300.
I will look into it.
Could you please share some of the settings used for test like
scale_factor in pgbench and shared_buffers settings or if you
have changed any other default setting in postgresql.conf?
On 08/07/2015 10:47 AM, Amit Kapila wrote: >> Fyi, there is something in pgbench that has caused a testing regression - >> havn't tracked down what yet. >> >> Against 9.6 server (846f8c9483a8f31e45bf949db1721706a2765771) >> >> 9.6 pgbench: >> ------------ >> progress: 10.0 s, 53525.0 tps, lat 1.485 ms stddev 0.523 >> progress: 20.0 s, 15750.6 tps, lat 5.077 ms stddev 1.950 >> ... >> progress: 300.0 s, 15636.9 tps, lat 5.114 ms stddev 1.989 >> >> 9.5 pgbench: >> ------------ >> progress: 10.0 s, 50119.5 tps, lat 1.587 ms stddev 0.576 >> progress: 20.0 s, 51413.1 tps, lat 1.555 ms stddev 0.553 >> ... >> progress: 300.0 s, 52951.6 tps, lat 1.509 ms stddev 0.657 >> >> >> Both done with -c 80 -j 80 -M prepared -P 10 -T 300. >> > > I will look into it. > Could you please share some of the settings used for test like > scale_factor in pgbench and shared_buffers settings or if you > have changed any other default setting in postgresql.conf? > Compiled with export CFLAGS="-O -fno-omit-frame-pointer" && ./configure --prefix /opt/postgresql-9.6 --with-openssl --with-gssapi --enable-debug Scale factor is 3000 shared_buffers = 64GB max_prepared_transactions = 10 work_mem = 64MB maintenance_work_mem = 512MB effective_io_concurrency = 4 max_wal_size = 100GB effective_cache_size = 160GB Machine has 28C / 56T with 256Gb mem, and 2 x RAID10 (SSD) Note, that the server setup is the same in both run, just the pgbench version is changed. Latency and stddev goes up between 10.0s and 20.0s when using 9.6 pgbench. Best regards, Jesper
On 2015-08-07 20:17:28 +0530, Amit Kapila wrote: > On Fri, Aug 7, 2015 at 8:00 PM, Jesper Pedersen <jesper.pedersen@redhat.com> > wrote: > > > On 08/07/2015 12:41 AM, Amit Kapila wrote: > > > >> On Thu, Aug 6, 2015 at 9:36 PM, Robert Haas <robertmhaas@gmail.com> > >> wrote: > >> > >>> > >>> > >>> OK, committed. > >>> > >>> > >> Thank you. > >> > >> > > Fyi, there is something in pgbench that has caused a testing regression - > > havn't tracked down what yet. > > > > Against 9.6 server (846f8c9483a8f31e45bf949db1721706a2765771) > > > > 9.6 pgbench: > > ------------ > > progress: 10.0 s, 53525.0 tps, lat 1.485 ms stddev 0.523 > > progress: 20.0 s, 15750.6 tps, lat 5.077 ms stddev 1.950 > > ... > > progress: 300.0 s, 15636.9 tps, lat 5.114 ms stddev 1.989 > > > > 9.5 pgbench: > > ------------ > > progress: 10.0 s, 50119.5 tps, lat 1.587 ms stddev 0.576 > > progress: 20.0 s, 51413.1 tps, lat 1.555 ms stddev 0.553 > > ... > > progress: 300.0 s, 52951.6 tps, lat 1.509 ms stddev 0.657 > > > > > > Both done with -c 80 -j 80 -M prepared -P 10 -T 300. > > > > I will look into it. > Could you please share some of the settings used for test like > scale_factor in pgbench and shared_buffers settings or if you > have changed any other default setting in postgresql.conf? FWIW, I've seen regressions on my workstation too. I've not yet had time to investigate. Andres
On Fri, Aug 7, 2015 at 10:30 AM, Jesper Pedersen <jesper.pedersen@redhat.com> wrote: > Just thought I would post it in this thread, because this change does help > on the performance numbers compared to 9.5 :) So are you saying that the performance was already worse before this patch landed, and then this patch made it somewhat better? Or are you saying you think this patch broke it? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 08/07/2015 11:40 AM, Robert Haas wrote: > On Fri, Aug 7, 2015 at 10:30 AM, Jesper Pedersen > <jesper.pedersen@redhat.com> wrote: >> Just thought I would post it in this thread, because this change does help >> on the performance numbers compared to 9.5 :) > > So are you saying that the performance was already worse before this > patch landed, and then this patch made it somewhat better? Or are you > saying you think this patch broke it? > No, this patch helps on performance - there is an improvement in numbers between http://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=253de7e1eb9abbcf57e6c229a8a38abd6455c7de and http://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=0e141c0fbb211bdd23783afa731e3eef95c9ad7a but you will have to use a 9.5 pgbench to see it, especially with higher client counts. Best regards, Jesper
On 2015-08-07 12:49:20 -0400, Jesper Pedersen wrote: > On 08/07/2015 11:40 AM, Robert Haas wrote: > >On Fri, Aug 7, 2015 at 10:30 AM, Jesper Pedersen > ><jesper.pedersen@redhat.com> wrote: > >>Just thought I would post it in this thread, because this change does help > >>on the performance numbers compared to 9.5 :) > > > >So are you saying that the performance was already worse before this > >patch landed, and then this patch made it somewhat better? Or are you > >saying you think this patch broke it? > > > > No, this patch helps on performance - there is an improvement in numbers > between > > http://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=253de7e1eb9abbcf57e6c229a8a38abd6455c7de > > and > > http://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=0e141c0fbb211bdd23783afa731e3eef95c9ad7a > > but you will have to use a 9.5 pgbench to see it, especially with higher > client counts. This bisects down to 1bc90f7a7b7441a88e2c6d4a0e9b6f9c1499ad30 - "Remove thread-emulation support from pgbench." Andres
Hi, On 2015-08-07 19:30:46 +0200, Andres Freund wrote: > On 2015-08-07 12:49:20 -0400, Jesper Pedersen wrote: > > No, this patch helps on performance - there is an improvement in numbers > > between > > > > http://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=253de7e1eb9abbcf57e6c229a8a38abd6455c7de > > > > and > > > > http://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=0e141c0fbb211bdd23783afa731e3eef95c9ad7a > > > > but you will have to use a 9.5 pgbench to see it, especially with higher > > client counts. Hm, you were using -P X, is that right? > This bisects down to 1bc90f7a7b7441a88e2c6d4a0e9b6f9c1499ad30 - "Remove > thread-emulation support from pgbench." And the apparent reason seems to be that too much code has been removed in that commit: @@ -3650,11 +3631,7 @@ threadRun(void *arg) } /* also wake up to print the next progress report on time */ - if (progress && min_usec > 0 -#if !defined(PTHREAD_FORK_EMULATION) - && thread->tid == 0 -#endif /* !PTHREAD_FORK_EMULATION */ - ) + if (progress && min_usec > 0) { /* get current time if needed */ if (now_usec == 0) @@ -3710,7 +3687,7 @@ threadRun(void *arg) This causes all threads but thread 0 (i.e. the primary process) to busy loop around select: min_usec will be set to 0 once the first progress report interval has been reached: if (now_usec >= next_report) min_usec = 0; else if ((next_report- now_usec) < min_usec) min_usec = next_report - now_usec; but since we never actually print the progress interval in any thread but the the main process that's always true from then on: /* progress report by thread 0 for all threads */ if (progress && thread->tid == 0) { ... /* * Ensure that the next report is in the future, in case * pgbench/postgres gotstuck somewhere. */ do { next_report += (int64) progress *1000000; } while (now >= next_report); Hrmpf. Andres
On 08/07/2015 02:03 PM, Andres Freund wrote:
>>> but you will have to use a 9.5 pgbench to see it, especially with higher
>>> client counts.
>
> Hm, you were using -P X, is that right?
>
>> This bisects down to 1bc90f7a7b7441a88e2c6d4a0e9b6f9c1499ad30 - "Remove
>> thread-emulation support from pgbench."
>
> And the apparent reason seems to be that too much code has been removed
> in that commit:
>
> @@ -3650,11 +3631,7 @@ threadRun(void *arg)
> }
>
> /* also wake up to print the next progress report on time */
> - if (progress && min_usec > 0
> -#if !defined(PTHREAD_FORK_EMULATION)
> - && thread->tid == 0
> -#endif /* !PTHREAD_FORK_EMULATION */
> - )
> + if (progress && min_usec > 0)
> {
> /* get current time if needed */
> if (now_usec == 0)
> @@ -3710,7 +3687,7 @@ threadRun(void *arg)
>
>
> This causes all threads but thread 0 (i.e. the primary process) to busy
> loop around select: min_usec will be set to 0 once the first progress
> report interval has been reached:
> if (now_usec >= next_report)
> min_usec = 0;
> else if ((next_report - now_usec) < min_usec)
> min_usec = next_report - now_usec;
>
> but since we never actually print the progress interval in any thread
> but the the main process that's always true from then on:
>
> /* progress report by thread 0 for all threads */
> if (progress && thread->tid == 0)
> {
> ...
> /*
> * Ensure that the next report is in the future, in case
> * pgbench/postgres got stuck somewhere.
> */
> do
> {
> next_report += (int64) progress *1000000;
> } while (now >= next_report);
>
> Hrmpf.
>
Confirmed.
Running w/o -P x and the problem goes away.
Thanks !
Best regards, Jesper
On 2015-08-07 14:20:55 -0400, Jesper Pedersen wrote: > On 08/07/2015 02:03 PM, Andres Freund wrote: > Confirmed. > > Running w/o -P x and the problem goes away. Pushed the fix. Thanks for pointing the problem out! - Andres
Hi,
> On Wed, Aug 5, 2015 at 10:59 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> OK, committed.
I spent some time today reviewing the commited patch. So far my only
major complaint is that I think the comments are only insufficiently
documenting the approach taken:
Stuff like avoiding ABA type problems by clearling the list entirely and
it being impossible that entries end up on the list too early absolutely
needs to be documented explicitly.
I think I found a few minor correctness issues. Mostly around the fact
that we, so far, tried to use semaphores in a way that copes with
unrelated unlocks "arriving". I actually think I removed all of the
locations that caused that to happen, but I don't think we should rely
on that fact. Looking at the following two pieces of code:/* If the list was not empty, the leader will clear our XID.
*/if(nextidx != INVALID_PGPROCNO){ /* Sleep until the leader clears our XID. */ while
(pg_atomic_read_u32(&proc->nextClearXidElem)!= INVALID_PGPROCNO) { extraWaits++;
PGSemaphoreLock(&proc->sem); }
/* Fix semaphore count for any absorbed wakeups */ while (extraWaits-- > 0)
PGSemaphoreUnlock(&proc->sem); return;}
.../* * Now that we've released the lock, go back and wake everybody up. We * don't do this under the lock so as to
keeplock hold times to a * minimum. The system calls we need to perform to wake other processes * up are probably much
slowerthan the simple memory writes we did while * holding the lock. */while (wakeidx != INVALID_PGPROCNO){ PGPROC
*proc = &allProcs[wakeidx];
wakeidx = pg_atomic_read_u32(&proc->nextClearXidElem); pg_atomic_write_u32(&proc->nextClearXidElem,
INVALID_PGPROCNO);
if (proc != MyProc) PGSemaphoreUnlock(&proc->sem);}
There's a bunch of issues with those two blocks afaics:
1) The first block (in one backend) might read INVALID_PGPROCNO before ever locking the semaphore if a second backend
quicklyenough writes INVALID_PGPROCNO. That way the semaphore will be permanently out of "balance".
2) There's no memory barriers around dealing with nextClearXidElem in the first block. Afaics there needs to be a read
barrierbefore returning, otherwise it's e.g. not guaranteed that the woken up backend sees its own xid set to
InvalidTransactionId.
3) If a follower returns before the leader has actually finished woken that respective backend up we can get into
trouble:
Consider what happens if such a follower enqueues in another transaction. It is not, as far as I could find out,
guaranteedon all types of cpus that a third backend can actually see nextClearXidElem as INVALID_PGPROCNO. That'd
likelyrequire SMT/HT cores and multiple sockets. If the write to nextClearXidElem is entered into the local store
buffer(leader #1) a hyper-threaded process (leader #2) can possibly see it (store forwarding) while another backend
doesn't yet.
I think this is very unlikely to be an actual problem due to independent barriers until enqueued again, but I don't
wantto rely on it undocumentedly. It seems safer to replace + wakeidx =
pg_atomic_read_u32(&proc->nextClearXidElem); + pg_atomic_write_u32(&proc->nextClearXidElem, INVALID_PGPROCNO);
witha pg_atomic_exchange_u32().
I think to fix these ProcArrayGroupClearXid() should use a protocol
similar to lwlock.c. E.g. make the two blocks somethign like:while (wakeidx != INVALID_PGPROCNO){ PGPROC *proc =
&allProcs[wakeidx];
wakeidx = pg_atomic_read_u32(&proc->nextClearXidElem); pg_atomic_write_u32(&proc->nextClearXidElem,
INVALID_PGPROCNO);
/* ensure that all previous writes are visible before follower continues */
pg_write_barrier();
proc->lwWaiting = false;
if (proc != MyProc) PGSemaphoreUnlock(&proc->sem);}
andif (nextidx != INVALID_PGPROCNO){ Assert(!MyProc->lwWaiting);
for (;;) { /* acts as a read barrier */ PGSemaphoreLock(&MyProc->sem); if
(!MyProc->lwWaiting) break; extraWaits++; }
Assert(pg_atomic_read_u32(&proc->nextClearXidElem) == INVALID_PGPROCNO)
/* Fix semaphore count for any absorbed wakeups */ while (extraWaits-- > 0)
PGSemaphoreUnlock(&proc->sem); return;}
Going through the patch:
+/*
+ * ProcArrayGroupClearXid -- group XID clearing
+ *
+ * When we cannot immediately acquire ProcArrayLock in exclusive mode at
+ * commit time, add ourselves to a list of processes that need their XIDs
+ * cleared. The first process to add itself to the list will acquire
+ * ProcArrayLock in exclusive mode and perform ProcArrayEndTransactionInternal
+ * on behalf of all group members. This avoids a great deal of context
+ * switching when many processes are trying to commit at once, since the lock
+ * only needs to be handed from the last share-locker to one process waiting
+ * for the exclusive lock, rather than to each one in turn.
+ */
+static void
+ProcArrayGroupClearXid(PGPROC *proc, TransactionId latestXid)
+{
This comment, in my opinion, is rather misleading. If you have a
workload that primarily is slowed down due to transaction commits, this
patch doesn't actually change the number of context switches very
much. Previously all backends enqueued in the lwlock and got woken up
one-by-one. Safe backends 'jumping' the queue while a lock has been
released but the woken up backend doesn't yet run, there'll be exactly
as many context switches as today.
The difference is that only one backend has to actually acquire the
lock. So what has changed is the number of times, and the total
duration, the lock is actually held in exclusive mode.
+ /* Support for group XID clearing. */
+ volatile pg_atomic_uint32 nextClearXidElem;
+ /* First pgproc waiting for group XID clear */
+ volatile pg_atomic_uint32 nextClearXidElem;
Superfluous volatiles.
I don't think it's a good idea to use the variable name in PROC_HDR and
PGPROC, it's confusing.
How hard did you try checking whether this causes regressions? This
increases the number of atomics in the commit path a fair bit. I doubt
it's really bad, but it seems like a good idea to benchmark something
like a single full-throttle writer and a large number of readers.
Greetings,
Andres Freund
On Wed, Aug 19, 2015 at 9:09 PM, Andres Freund <andres@anarazel.de> wrote:
>
> Hi,
>
> > On Wed, Aug 5, 2015 at 10:59 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > OK, committed.
>
> I spent some time today reviewing the commited patch. So far my only
> major complaint is that I think the comments are only insufficiently
> documenting the approach taken:
> Stuff like avoiding ABA type problems by clearling the list entirely and
> it being impossible that entries end up on the list too early absolutely
> needs to be documented explicitly.
>
> I think I found a few minor correctness issues. Mostly around the fact
> that we, so far, tried to use semaphores in a way that copes with
> unrelated unlocks "arriving". I actually think I removed all of the
> locations that caused that to happen, but I don't think we should rely
> on that fact. Looking at the following two pieces of code:
> /* If the list was not empty, the leader will clear our XID. */
> if (nextidx != INVALID_PGPROCNO)
> {
> /* Sleep until the leader clears our XID. */
> while (pg_atomic_read_u32(&proc->nextClearXidElem) != INVALID_PGPROCNO)
> {
> extraWaits++;
> PGSemaphoreLock(&proc->sem);
> }
>
> /* Fix semaphore count for any absorbed wakeups */
> while (extraWaits-- > 0)
> PGSemaphoreUnlock(&proc->sem);
> return;
> }
> ...
> /*
> * Now that we've released the lock, go back and wake everybody up. We
> * don't do this under the lock so as to keep lock hold times to a
> * minimum. The system calls we need to perform to wake other processes
> * up are probably much slower than the simple memory writes we did while
> * holding the lock.
> */
> while (wakeidx != INVALID_PGPROCNO)
> {
> PGPROC *proc = &allProcs[wakeidx];
>
> wakeidx = pg_atomic_read_u32(&proc->nextClearXidElem);
> pg_atomic_write_u32(&proc->nextClearXidElem, INVALID_PGPROCNO);
>
> if (proc != MyProc)
> PGSemaphoreUnlock(&proc->sem);
> }
>
> There's a bunch of issues with those two blocks afaics:
>
> 1) The first block (in one backend) might read INVALID_PGPROCNO before
> ever locking the semaphore if a second backend quickly enough writes
> INVALID_PGPROCNO. That way the semaphore will be permanently out of
> "balance".
>
> Consider what happens if such a follower enqueues in another
> transaction. It is not, as far as I could find out, guaranteed on all
> types of cpus that a third backend can actually see nextClearXidElem
> as INVALID_PGPROCNO. That'd likely require SMT/HT cores and multiple
> sockets. If the write to nextClearXidElem is entered into the local
> store buffer (leader #1) a hyper-threaded process (leader #2) can
> possibly see it (store forwarding) while another backend doesn't
> yet.
>
> I think this is very unlikely to be an actual problem due to
> independent barriers until enqueued again, but I don't want to rely
> on it undocumentedly. It seems safer to replace
> + wakeidx = pg_atomic_read_u32(&proc->nextClearXidElem);
> + pg_atomic_write_u32(&proc->nextClearXidElem, INVALID_PGPROCNO);
> with a pg_atomic_exchange_u32().
>
>
> I think to fix these ProcArrayGroupClearXid() should use a protocol
> similar to lwlock.c. E.g. make the two blocks somethign like:
> while (wakeidx != INVALID_PGPROCNO)
> {
> PGPROC *proc = &allProcs[wakeidx];
>
> wakeidx = pg_atomic_read_u32(&proc->nextClearXidElem);
> pg_atomic_write_u32(&proc->nextClearXidElem, INVALID_PGPROCNO);
>
> /* ensure that all previous writes are visible before follower continues */
> pg_write_barrier();
>
> proc->lwWaiting = false;
>
> if (proc != MyProc)
> PGSemaphoreUnlock(&proc->sem);
> }
> and
> if (nextidx != INVALID_PGPROCNO)
> {
> Assert(!MyProc->lwWaiting);
>
> for (;;)
> {
> /* acts as a read barrier */
> PGSemaphoreLock(&MyProc->sem);
> if (!MyProc->lwWaiting)
> break;
> extraWaits++;
> }
>
> Assert(pg_atomic_read_u32(&proc->nextClearXidElem) == INVALID_PGPROCNO)
>
> /* Fix semaphore count for any absorbed wakeups */
> while (extraWaits-- > 0)
> PGSemaphoreUnlock(&proc->sem);
> return;
> }
>
> Going through the patch:
>
> +/*
> + * ProcArrayGroupClearXid -- group XID clearing
> + *
> + * When we cannot immediately acquire ProcArrayLock in exclusive mode at
> + * commit time, add ourselves to a list of processes that need their XIDs
> + * cleared. The first process to add itself to the list will acquire
> + * ProcArrayLock in exclusive mode and perform ProcArrayEndTransactionInternal
> + * on behalf of all group members. This avoids a great deal of context
> + * switching when many processes are trying to commit at once, since the lock
> + * only needs to be handed from the last share-locker to one process waiting
> + * for the exclusive lock, rather than to each one in turn.
> + */
> +static void
> +ProcArrayGroupClearXid(PGPROC *proc, TransactionId latestXid)
> +{
>
> This comment, in my opinion, is rather misleading. If you have a
> workload that primarily is slowed down due to transaction commits, this
> patch doesn't actually change the number of context switches very
> much. Previously all backends enqueued in the lwlock and got woken up
> one-by-one. Safe backends 'jumping' the queue while a lock has been
> released but the woken up backend doesn't yet run, there'll be exactly
> as many context switches as today.
>
> The difference is that only one backend has to actually acquire the
> lock. So what has changed is the number of times, and the total
> duration, the lock is actually held in exclusive mode.
>
> + /* Support for group XID clearing. */
> + volatile pg_atomic_uint32 nextClearXidElem;
>
> + /* First pgproc waiting for group XID clear */
> + volatile pg_atomic_uint32 nextClearXidElem;
>
> Superfluous volatiles.
>
> I don't think it's a good idea to use the variable name in PROC_HDR and
> PGPROC, it's confusing.
>
>
>
> How hard did you try checking whether this causes regressions? This
> increases the number of atomics in the commit path a fair bit. I doubt
> it's really bad, but it seems like a good idea to benchmark something
> like a single full-throttle writer and a large number of readers.
>
>
> Hi,
>
> > On Wed, Aug 5, 2015 at 10:59 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > OK, committed.
>
> I spent some time today reviewing the commited patch. So far my only
> major complaint is that I think the comments are only insufficiently
> documenting the approach taken:
> Stuff like avoiding ABA type problems by clearling the list entirely and
> it being impossible that entries end up on the list too early absolutely
> needs to be documented explicitly.
>
I think more comments can be added to explain such behaviour if it is
not clear via looking at current code and comments.
> I think I found a few minor correctness issues. Mostly around the fact
> that we, so far, tried to use semaphores in a way that copes with
> unrelated unlocks "arriving". I actually think I removed all of the
> locations that caused that to happen, but I don't think we should rely
> on that fact. Looking at the following two pieces of code:
> /* If the list was not empty, the leader will clear our XID. */
> if (nextidx != INVALID_PGPROCNO)
> {
> /* Sleep until the leader clears our XID. */
> while (pg_atomic_read_u32(&proc->nextClearXidElem) != INVALID_PGPROCNO)
> {
> extraWaits++;
> PGSemaphoreLock(&proc->sem);
> }
>
> /* Fix semaphore count for any absorbed wakeups */
> while (extraWaits-- > 0)
> PGSemaphoreUnlock(&proc->sem);
> return;
> }
> ...
> /*
> * Now that we've released the lock, go back and wake everybody up. We
> * don't do this under the lock so as to keep lock hold times to a
> * minimum. The system calls we need to perform to wake other processes
> * up are probably much slower than the simple memory writes we did while
> * holding the lock.
> */
> while (wakeidx != INVALID_PGPROCNO)
> {
> PGPROC *proc = &allProcs[wakeidx];
>
> wakeidx = pg_atomic_read_u32(&proc->nextClearXidElem);
> pg_atomic_write_u32(&proc->nextClearXidElem, INVALID_PGPROCNO);
>
> if (proc != MyProc)
> PGSemaphoreUnlock(&proc->sem);
> }
>
> There's a bunch of issues with those two blocks afaics:
>
> 1) The first block (in one backend) might read INVALID_PGPROCNO before
> ever locking the semaphore if a second backend quickly enough writes
> INVALID_PGPROCNO. That way the semaphore will be permanently out of
> "balance".
>
I think you are right and here we need to use something like what is
suggested below by you. Originally the code was similar to what you
have written below, but it was using a different (new) variable to achieve
what you have achieved with lwWaiting and to avoid the use of new
variable the code has been refactored in current way. I think we should
do this change (I can write a patch) unless Robert feels otherwise.
> 2) There's no memory barriers around dealing with nextClearXidElem in
> the first block. Afaics there needs to be a read barrier before
> returning, otherwise it's e.g. not guaranteed that the woken up
> backend sees its own xid set to InvalidTransactionId.
>
> 3) If a follower returns before the leader has actually finished woken
> that respective backend up we can get into trouble:
>
> the first block. Afaics there needs to be a read barrier before
> returning, otherwise it's e.g. not guaranteed that the woken up
> backend sees its own xid set to InvalidTransactionId.
>
> 3) If a follower returns before the leader has actually finished woken
> that respective backend up we can get into trouble:
>
Surely that can lead to a problem and I think the reason and fix
for this is same as first point.
> Consider what happens if such a follower enqueues in another
> transaction. It is not, as far as I could find out, guaranteed on all
> types of cpus that a third backend can actually see nextClearXidElem
> as INVALID_PGPROCNO. That'd likely require SMT/HT cores and multiple
> sockets. If the write to nextClearXidElem is entered into the local
> store buffer (leader #1) a hyper-threaded process (leader #2) can
> possibly see it (store forwarding) while another backend doesn't
> yet.
>
> I think this is very unlikely to be an actual problem due to
> independent barriers until enqueued again, but I don't want to rely
> on it undocumentedly. It seems safer to replace
> + wakeidx = pg_atomic_read_u32(&proc->nextClearXidElem);
> + pg_atomic_write_u32(&proc->nextClearXidElem, INVALID_PGPROCNO);
> with a pg_atomic_exchange_u32().
>
I didn't follow this point, if we ensure that follower can never return
before leader wakes it up, then why it will be a problem to update
nextClearXidElem like above.
>
> I think to fix these ProcArrayGroupClearXid() should use a protocol
> similar to lwlock.c. E.g. make the two blocks somethign like:
> while (wakeidx != INVALID_PGPROCNO)
> {
> PGPROC *proc = &allProcs[wakeidx];
>
> wakeidx = pg_atomic_read_u32(&proc->nextClearXidElem);
> pg_atomic_write_u32(&proc->nextClearXidElem, INVALID_PGPROCNO);
>
> /* ensure that all previous writes are visible before follower continues */
> pg_write_barrier();
>
> proc->lwWaiting = false;
>
> if (proc != MyProc)
> PGSemaphoreUnlock(&proc->sem);
> }
> and
> if (nextidx != INVALID_PGPROCNO)
> {
> Assert(!MyProc->lwWaiting);
>
> for (;;)
> {
> /* acts as a read barrier */
> PGSemaphoreLock(&MyProc->sem);
> if (!MyProc->lwWaiting)
> break;
> extraWaits++;
> }
>
> Assert(pg_atomic_read_u32(&proc->nextClearXidElem) == INVALID_PGPROCNO)
>
> /* Fix semaphore count for any absorbed wakeups */
> while (extraWaits-- > 0)
> PGSemaphoreUnlock(&proc->sem);
> return;
> }
>
> Going through the patch:
>
> +/*
> + * ProcArrayGroupClearXid -- group XID clearing
> + *
> + * When we cannot immediately acquire ProcArrayLock in exclusive mode at
> + * commit time, add ourselves to a list of processes that need their XIDs
> + * cleared. The first process to add itself to the list will acquire
> + * ProcArrayLock in exclusive mode and perform ProcArrayEndTransactionInternal
> + * on behalf of all group members. This avoids a great deal of context
> + * switching when many processes are trying to commit at once, since the lock
> + * only needs to be handed from the last share-locker to one process waiting
> + * for the exclusive lock, rather than to each one in turn.
> + */
> +static void
> +ProcArrayGroupClearXid(PGPROC *proc, TransactionId latestXid)
> +{
>
> This comment, in my opinion, is rather misleading. If you have a
> workload that primarily is slowed down due to transaction commits, this
> patch doesn't actually change the number of context switches very
> much. Previously all backends enqueued in the lwlock and got woken up
> one-by-one. Safe backends 'jumping' the queue while a lock has been
> released but the woken up backend doesn't yet run, there'll be exactly
> as many context switches as today.
>
I think this is debatable as in previous mechanism all the backends
one-by-one clears their transaction id's (which is nothing but context
switching) which lead to contention not only with read lockers
but Write lockers as well.
> The difference is that only one backend has to actually acquire the
> lock. So what has changed is the number of times, and the total
> duration, the lock is actually held in exclusive mode.
>
> + /* Support for group XID clearing. */
> + volatile pg_atomic_uint32 nextClearXidElem;
>
> + /* First pgproc waiting for group XID clear */
> + volatile pg_atomic_uint32 nextClearXidElem;
>
> Superfluous volatiles.
>
> I don't think it's a good idea to use the variable name in PROC_HDR and
> PGPROC, it's confusing.
>
What do you mean by this, are you not happy with variable name?
>
>
> How hard did you try checking whether this causes regressions? This
> increases the number of atomics in the commit path a fair bit. I doubt
> it's really bad, but it seems like a good idea to benchmark something
> like a single full-throttle writer and a large number of readers.
>
I think the case which you want to stress is when the patch doesn't
have any benefit (like single writer case) and rather increases some
instructions to execute due to atomic-ops. I think for lower
client-counts like 2,4,8, it will hardly get any benefit and execute
somewhat more instructions, but I don't see any noticable difference
in numbers. However, it is not bad to try what you are suggesting.
On Thu, Aug 20, 2015 at 3:38 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Wed, Aug 19, 2015 at 9:09 PM, Andres Freund <andres@anarazel.de> wrote:
> >
> >
> > How hard did you try checking whether this causes regressions? This
> > increases the number of atomics in the commit path a fair bit. I doubt
> > it's really bad, but it seems like a good idea to benchmark something
> > like a single full-throttle writer and a large number of readers.
> >
>
> I think the case which you want to stress is when the patch doesn't
> have any benefit (like single writer case)
>
> On Wed, Aug 19, 2015 at 9:09 PM, Andres Freund <andres@anarazel.de> wrote:
> >
> >
> > How hard did you try checking whether this causes regressions? This
> > increases the number of atomics in the commit path a fair bit. I doubt
> > it's really bad, but it seems like a good idea to benchmark something
> > like a single full-throttle writer and a large number of readers.
> >
>
> I think the case which you want to stress is when the patch doesn't
> have any benefit (like single writer case)
>
I mean to say single writer, multiple readers.
On 2015-08-20 15:38:36 +0530, Amit Kapila wrote:
> On Wed, Aug 19, 2015 at 9:09 PM, Andres Freund <andres@anarazel.de> wrote:
> > I spent some time today reviewing the commited patch. So far my only
> > major complaint is that I think the comments are only insufficiently
> > documenting the approach taken:
> > Stuff like avoiding ABA type problems by clearling the list entirely and
> > it being impossible that entries end up on the list too early absolutely
> > needs to be documented explicitly.
> >
>
> I think more comments can be added to explain such behaviour if it is
> not clear via looking at current code and comments.
It's not mentioned at all, so yes.
> I think you are right and here we need to use something like what is
> suggested below by you. Originally the code was similar to what you
> have written below, but it was using a different (new) variable to achieve
> what you have achieved with lwWaiting and to avoid the use of new
> variable the code has been refactored in current way. I think we should
> do this change (I can write a patch) unless Robert feels otherwise.
I think we can just rename lwWaiting to something more generic.
> > Consider what happens if such a follower enqueues in another
> > transaction. It is not, as far as I could find out, guaranteed on all
> > types of cpus that a third backend can actually see nextClearXidElem
> > as INVALID_PGPROCNO. That'd likely require SMT/HT cores and multiple
> > sockets. If the write to nextClearXidElem is entered into the local
> > store buffer (leader #1) a hyper-threaded process (leader #2) can
> > possibly see it (store forwarding) while another backend doesn't
> > yet.
> >
> > I think this is very unlikely to be an actual problem due to
> > independent barriers until enqueued again, but I don't want to rely
> > on it undocumentedly. It seems safer to replace
> > + wakeidx = pg_atomic_read_u32(&proc->nextClearXidElem);
> > + pg_atomic_write_u32(&proc->nextClearXidElem,
> INVALID_PGPROCNO);
> > with a pg_atomic_exchange_u32().
> >
>
> I didn't follow this point, if we ensure that follower can never return
> before leader wakes it up, then why it will be a problem to update
> nextClearXidElem like above.
Because it doesn't generally enforce that *other* backends have seen the
write as there's no memory barrier.
> > +/*
> > + * ProcArrayGroupClearXid -- group XID clearing
> > + *
> > + * When we cannot immediately acquire ProcArrayLock in exclusive mode at
> > + * commit time, add ourselves to a list of processes that need their XIDs
> > + * cleared. The first process to add itself to the list will acquire
> > + * ProcArrayLock in exclusive mode and perform
> ProcArrayEndTransactionInternal
> > + * on behalf of all group members. This avoids a great deal of context
> > + * switching when many processes are trying to commit at once, since the
> lock
> > + * only needs to be handed from the last share-locker to one process
> waiting
> > + * for the exclusive lock, rather than to each one in turn.
> > + */
> > +static void
> > +ProcArrayGroupClearXid(PGPROC *proc, TransactionId latestXid)
> > +{
> >
> > This comment, in my opinion, is rather misleading. If you have a
> > workload that primarily is slowed down due to transaction commits, this
> > patch doesn't actually change the number of context switches very
> > much. Previously all backends enqueued in the lwlock and got woken up
> > one-by-one. Safe backends 'jumping' the queue while a lock has been
> > released but the woken up backend doesn't yet run, there'll be exactly
> > as many context switches as today.
> >
>
> I think this is debatable as in previous mechanism all the backends
> one-by-one clears their transaction id's (which is nothing but context
> switching) which lead to contention not only with read lockers
> but Write lockers as well.
Huh? You can benchmark it, there's barely any change in the number of
context switches.
I am *not* saying that there's no benefit to the patch, I am saying that
context switches are the wrong explanation. Reduced contention (due to
shorter lock holding times, fewer cacheline moves etc.) is the reason
this is beneficial.
> > I don't think it's a good idea to use the variable name in PROC_HDR and
> > PGPROC, it's confusing.
> What do you mean by this, are you not happy with variable name?
Yes. I think it's a bad idea to have the same variable name in PROC_HDR
and PGPROC.
struct PGPROC
{
.../* Support for group XID clearing. */volatile pg_atomic_uint32 nextClearXidElem;
...
}
typedef struct PROC_HDR
{
.../* First pgproc waiting for group XID clear */volatile pg_atomic_uint32 nextClearXidElem;
...
}
PROC_HDR's variable imo isn't well named.
Greetings,
Andres Freund
On Wed, Aug 19, 2015 at 11:39 AM, Andres Freund <andres@anarazel.de> wrote:
> There's a bunch of issues with those two blocks afaics:
>
> 1) The first block (in one backend) might read INVALID_PGPROCNO before
> ever locking the semaphore if a second backend quickly enough writes
> INVALID_PGPROCNO. That way the semaphore will be permanently out of
> "balance".
Yes, this is a clear bug. I think the fix is to do one unconditional
PGSemaphoreLock(&proc->sem) just prior to the loop.
> 2) There's no memory barriers around dealing with nextClearXidElem in
> the first block. Afaics there needs to be a read barrier before
> returning, otherwise it's e.g. not guaranteed that the woken up
> backend sees its own xid set to InvalidTransactionId.
I can't believe it actually works like that. Surely a semaphore
operation is a full barrier. Otherwise this could fail:
P1: a = 0;
P1: PGSemaphoreLock(&P1);
P2: a = 1;
P2: PGSemaphoreUnlock(&P1);
P1: Assert(a == 1);
Do you really think that fails anywhere? I'd find that shocking. And
if it's true, then let's put the barrier in PGSemaphore(L|Unl)ock,
because everybody who uses semaphores for anything is going to have
the same problem. This is exactly what semaphore are for. I find it
extremely hard to believe that user-level code that uses OS-provided
synchronization primitives has to insert its own barriers also. I
think we can assume that if I do something and wake you up, you'll see
everything I did before waking you.
(This would of course be needed if we didn't add the PGSemaphoreLock
contemplated by the previous point, because then there'd be no
OS-level synchronization primitive in some cases. But since we have
to add that anyway I think this is is a non-issue.)
> 3) If a follower returns before the leader has actually finished woken
> that respective backend up we can get into trouble:
>
> Consider what happens if such a follower enqueues in another
> transaction. It is not, as far as I could find out, guaranteed on all
> types of cpus that a third backend can actually see nextClearXidElem
> as INVALID_PGPROCNO. That'd likely require SMT/HT cores and multiple
> sockets. If the write to nextClearXidElem is entered into the local
> store buffer (leader #1) a hyper-threaded process (leader #2) can
> possibly see it (store forwarding) while another backend doesn't
> yet.
Let's call the process that does two commits P, and it's PGPROC
structure proc. For the first commit, L1 is the leader; for the
second, L2 is the leader. The intended sequence of operations on
nextClearXidElem is:
(1) P sets proc->nextClearXidElem
(2) L1 clears proc->nextClearXidElem
(3) P sets proc->nextClearXidElem
(4) L2 clears proc->nextClearXidElem
P uses an atomic compare-and-exchange operation on
procglobal->nextClearXidElem after step (1), and L1 can't attempt step
(2) until it uses an atomic compare-and-exchange operation on
procglobal->nextClearXidElem -- that's how it finds out the identity
of P. Since a compare-and-exchange operation is a full barrier, those
two compare-and-exchange operations form a barrier pair, and (2) must
happen after (1).
Synchronization between (2) and (3) is based on the assumption that P
must do PGSemaphoreLock and L1 must do PGSemaphoreUnlock. I assume,
as noted above, that those are barriers, that they form a pair, and
thus (3) must happen after (2).
(4) must happen after (3) for the same reasons (2) must happen after (1).
So I don't see the problem. The "third backend", which I guess is L2,
doesn't need to observe proc->nextClearXidElem until P has reset it;
and procglobal->nextClearXidElem is only manipulated with atomics, so
access to that location had better be totally ordered.
> Going through the patch:
>
> +/*
> + * ProcArrayGroupClearXid -- group XID clearing
> + *
> + * When we cannot immediately acquire ProcArrayLock in exclusive mode at
> + * commit time, add ourselves to a list of processes that need their XIDs
> + * cleared. The first process to add itself to the list will acquire
> + * ProcArrayLock in exclusive mode and perform ProcArrayEndTransactionInternal
> + * on behalf of all group members. This avoids a great deal of context
> + * switching when many processes are trying to commit at once, since the lock
> + * only needs to be handed from the last share-locker to one process waiting
> + * for the exclusive lock, rather than to each one in turn.
> + */
> +static void
> +ProcArrayGroupClearXid(PGPROC *proc, TransactionId latestXid)
> +{
>
> This comment, in my opinion, is rather misleading. If you have a
> workload that primarily is slowed down due to transaction commits, this
> patch doesn't actually change the number of context switches very
> much. Previously all backends enqueued in the lwlock and got woken up
> one-by-one. Safe backends 'jumping' the queue while a lock has been
> released but the woken up backend doesn't yet run, there'll be exactly
> as many context switches as today.
>
> The difference is that only one backend has to actually acquire the
> lock. So what has changed is the number of times, and the total
> duration, the lock is actually held in exclusive mode.
I don't mind if you want to improve the phrasing of the comment. I
think my thinking was warped by versions of the patch that used
LWLockAcquireOrWait. In those versions, every time somebody
committed, all of the waiting backends woke up and fought over who got
to be leader. That was a lot less good than this approach. So the
comment *should* be pointing out that we have avoided that danger, but
it should not be making it sound like that's the advantage vs. not
having the mechanism at all.
> + /* Support for group XID clearing. */
> + volatile pg_atomic_uint32 nextClearXidElem;
>
> + /* First pgproc waiting for group XID clear */
> + volatile pg_atomic_uint32 nextClearXidElem;
>
> Superfluous volatiles.
Hmm, I thought I needed that to avoid compiler warnings, but I guess
not. And I see that lwlock.h doesn't mention volatile. So, yeah, we
can remove that.
> I don't think it's a good idea to use the variable name in PROC_HDR and
> PGPROC, it's confusing.
It made sense to me, but I don't care that much if you want to change it.
> How hard did you try checking whether this causes regressions? This
> increases the number of atomics in the commit path a fair bit. I doubt
> it's really bad, but it seems like a good idea to benchmark something
> like a single full-throttle writer and a large number of readers.
Hmm, that's an interesting point. My analysis was that it really only
increased the atomics in the cases where we otherwise would have gone
to sleep, and I figured that the extra atomics were a small price to
pay for not sleeping. One writer many readers is a good case to test,
though, because the new code will get used a lot but we'll never
actually manage a group commit. So that is worth testing.
It's worth point out, though, that your lwlock.c atomics changes have
the same effect. Before, if there were any shared lockers on an
LWLock and an exclusive-locker came along, the exclusive locker would
take and release the spinlock and go to sleep. Now, it will use CAS
to try to acquire the lock, then acquire and release the spinlock to
add itself to the wait queue, then use CAS to attempt the lock again,
and then go to sleep - unless of course the second lock acquisition
succeeds, in which case it will first acquire and release the spinlock
yet again to take itself back out of the list of waiters.
The changes we made to the clock sweep are more of the same. Instead
of taking an lwlock, sweeping the clock hand across many buffers, and
releasing the lwlock, we now perform an atomic operation for every
buffer. That's obviously "worse" in terms of the total number of
atomic operations, and if you construct a case where every backend
sweeps 10 or 20 buffers yet none of them would have contended with
each other, it might lose. But it's actually much better and more
scalable in the real world.
I think this is a pattern we'll see with atomics over and over again:
more atomic operations overall in order to reduce the length of time
for which particular resources are unavailable to other processes.
Obviously, we need to be careful about that, and we need to be
particularly careful not to regress the single-client performance,
which is one thing that I liked about this patch - if ProcArrayLock
can be taken in exclusive mode immediately, there's no difference vs.
older versions. So I think in general this is going shift pretty
smoothly from the old behavior in low client-count situations to the
group behavior in high client-count situations, but it does seem
possible that if you have say 1 writer and 100 readers you could lose.
I don't think you'll lose much, but let's test that.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On 2015-08-21 14:08:36 -0400, Robert Haas wrote: > On Wed, Aug 19, 2015 at 11:39 AM, Andres Freund <andres@anarazel.de> wrote: > > There's a bunch of issues with those two blocks afaics: > > > > 1) The first block (in one backend) might read INVALID_PGPROCNO before > > ever locking the semaphore if a second backend quickly enough writes > > INVALID_PGPROCNO. That way the semaphore will be permanently out of > > "balance". > > Yes, this is a clear bug. I think the fix is to do one unconditional > PGSemaphoreLock(&proc->sem) just prior to the loop. I don't think that fixes it it completely, see the following. > > 2) There's no memory barriers around dealing with nextClearXidElem in > > the first block. Afaics there needs to be a read barrier before > > returning, otherwise it's e.g. not guaranteed that the woken up > > backend sees its own xid set to InvalidTransactionId. > > I can't believe it actually works like that. Surely a semaphore > operation is a full barrier. Otherwise this could fail: > P1: a = 0; > P1: PGSemaphoreLock(&P1); > P2: a = 1; > P2: PGSemaphoreUnlock(&P1); > P1: Assert(a == 1); > > Do you really think that fails anywhere? No, if it's paired like that, I don't think it's allowed to fail. But, as the code stands, there's absolutely no guarantee you're not seeing something like: P1: a = 0; P1: b = 0; P1: PGSemaphoreLock(&P1); P2: a = 1; P2: PGSemaphoreUnlock(&P1); -- unrelated, as e.g. earlier by ProcSendSignal P1: Assert(a == b == 1); P2: b = 1; P2: PGSemaphoreUnlock(&P1); if the pairing is like this there's no guarantees anymore, right? Even if a and be were set before P1's assert, the thing would be allowed to fail, because the store to a or b might each be visible since there's no enforced ordering. > > 3) If a follower returns before the leader has actually finished woken > > that respective backend up we can get into trouble: ... > So I don't see the problem. Don't have time (nor spare brain capacity) to answer in detail right now. > > I don't think it's a good idea to use the variable name in PROC_HDR and > > PGPROC, it's confusing. > > It made sense to me, but I don't care that much if you want to change it. Please. > > How hard did you try checking whether this causes regressions? This > > increases the number of atomics in the commit path a fair bit. I doubt > > it's really bad, but it seems like a good idea to benchmark something > > like a single full-throttle writer and a large number of readers. > > Hmm, that's an interesting point. My analysis was that it really only > increased the atomics in the cases where we otherwise would have gone > to sleep, and I figured that the extra atomics were a small price to > pay for not sleeping. You're probably right that it won't have a big, if any, impact. Seems easy enough to test though, and it's really the only sane adversarial scenario I could come up with.. > It's worth point out, though, that your lwlock.c atomics changes have > the same effect. To some degree, yes. I tried to benchmark adversarial scenarios rather extensively because of that... I couldn't make it regress, presumably because because putting on the waitlist only "hard" contended with other exclusive lockers, not with the shared lockers which could progress. > Before, if there were any shared lockers on an LWLock and an > exclusive-locker came along, the exclusive locker would take and > release the spinlock and go to sleep. That often spun (span?) on a spinlock which continously was acquired, so it was hard to ever get that far... > The changes we made to the clock sweep are more of the same. Yea. > Instead of taking an lwlock, sweeping the clock hand across many > buffers, and releasing the lwlock, we now perform an atomic operation > for every buffer. That's obviously "worse" in terms of the total > number of atomic operations, and if you construct a case where every > backend sweeps 10 or 20 buffers yet none of them would have contended > with each other, it might lose. But it's actually much better and > more scalable in the real world. I think we probably should optimize that bit of code at some point - right now the bottleneck appear to be elsewhere though, namely all the buffer header locks which are rather likely to be in no cache at all. > I think this is a pattern we'll see with atomics over and over again: > more atomic operations overall in order to reduce the length of time > for which particular resources are unavailable to other processes. Yea, agreed. Greetings, Andres Freund
On Fri, Aug 21, 2015 at 2:31 PM, Andres Freund <andres@anarazel.de> wrote: > No, if it's paired like that, I don't think it's allowed to fail. > > But, as the code stands, there's absolutely no guarantee you're not > seeing something like: > P1: a = 0; > P1: b = 0; > P1: PGSemaphoreLock(&P1); > P2: a = 1; > P2: PGSemaphoreUnlock(&P1); -- unrelated, as e.g. earlier by ProcSendSignal > P1: Assert(a == b == 1); > P2: b = 1; > P2: PGSemaphoreUnlock(&P1); > > if the pairing is like this there's no guarantees anymore, right? Even > if a and be were set before P1's assert, the thing would be allowed to > fail, because the store to a or b might each be visible since there's no > enforced ordering. Hmm, I see your point. So I agree with your proposed fix then. That kinda sucks that we have to do all those gymnastics, though: that's a lot more complicated than what we have right now. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Aug 20, 2015 at 3:49 PM, Andres Freund <andres@anarazel.de> wrote:
>
> On 2015-08-20 15:38:36 +0530, Amit Kapila wrote:
> > On Wed, Aug 19, 2015 at 9:09 PM, Andres Freund <andres@anarazel.de> wrote:
> > > I spent some time today reviewing the commited patch. So far my only
> > > major complaint is that I think the comments are only insufficiently
> > > documenting the approach taken:
> > > Stuff like avoiding ABA type problems by clearling the list entirely and
> > > it being impossible that entries end up on the list too early absolutely
> > > needs to be documented explicitly.
> > >
> >
> > I think more comments can be added to explain such behaviour if it is
> > not clear via looking at current code and comments.
>
> It's not mentioned at all, so yes.
>
> > I think you are right and here we need to use something like what is
> > suggested below by you. Originally the code was similar to what you
> > have written below, but it was using a different (new) variable to achieve
> > what you have achieved with lwWaiting and to avoid the use of new
> > variable the code has been refactored in current way. I think we should
> > do this change (I can write a patch) unless Robert feels otherwise.
>
> I think we can just rename lwWaiting to something more generic.
>
>
> > > Consider what happens if such a follower enqueues in another
> > > transaction. It is not, as far as I could find out, guaranteed on all
> > > types of cpus that a third backend can actually see nextClearXidElem
> > > as INVALID_PGPROCNO. That'd likely require SMT/HT cores and multiple
> > > sockets. If the write to nextClearXidElem is entered into the local
> > > store buffer (leader #1) a hyper-threaded process (leader #2) can
> > > possibly see it (store forwarding) while another backend doesn't
> > > yet.
> > >
> > > I think this is very unlikely to be an actual problem due to
> > > independent barriers until enqueued again, but I don't want to rely
> > > on it undocumentedly. It seems safer to replace
> > > + wakeidx = pg_atomic_read_u32(&proc->nextClearXidElem);
> > > + pg_atomic_write_u32(&proc->nextClearXidElem,
> > INVALID_PGPROCNO);
> > > with a pg_atomic_exchange_u32().
> > >
> >
> > I didn't follow this point, if we ensure that follower can never return
> > before leader wakes it up, then why it will be a problem to update
> > nextClearXidElem like above.
>
> Because it doesn't generally enforce that *other* backends have seen the
> write as there's no memory barrier.
>
>
>
> > > I don't think it's a good idea to use the variable name in PROC_HDR and
> > > PGPROC, it's confusing.
>
> > What do you mean by this, are you not happy with variable name?
>
> Yes. I think it's a bad idea to have the same variable name in PROC_HDR
> and PGPROC.
>
> struct PGPROC
> {
> ...
> /* Support for group XID clearing. */
> volatile pg_atomic_uint32 nextClearXidElem;
> ...
> }
>
> typedef struct PROC_HDR
> {
> ...
> /* First pgproc waiting for group XID clear */
> volatile pg_atomic_uint32 nextClearXidElem;
> ...
> }
>
> PROC_HDR's variable imo isn't well named.
>
Changed the variable name in PROC_HDR.
>
> On 2015-08-20 15:38:36 +0530, Amit Kapila wrote:
> > On Wed, Aug 19, 2015 at 9:09 PM, Andres Freund <andres@anarazel.de> wrote:
> > > I spent some time today reviewing the commited patch. So far my only
> > > major complaint is that I think the comments are only insufficiently
> > > documenting the approach taken:
> > > Stuff like avoiding ABA type problems by clearling the list entirely and
> > > it being impossible that entries end up on the list too early absolutely
> > > needs to be documented explicitly.
> > >
> >
> > I think more comments can be added to explain such behaviour if it is
> > not clear via looking at current code and comments.
>
> It's not mentioned at all, so yes.
>
I have updated comments in patch as suggested by you. We can even add
a link of wiki or some other page which can explain the definition of ABA
problem or we can even explain what the problem is, but as this is a
well-known problem that can occur while implementing lock-free
data- structure, so not adding any explanation also seems okay.
> > I think you are right and here we need to use something like what is
> > suggested below by you. Originally the code was similar to what you
> > have written below, but it was using a different (new) variable to achieve
> > what you have achieved with lwWaiting and to avoid the use of new
> > variable the code has been refactored in current way. I think we should
> > do this change (I can write a patch) unless Robert feels otherwise.
>
> I think we can just rename lwWaiting to something more generic.
>
I think that can create problem considering we have to set it in
ProcArrayGroupClearXid() before adding the proc to wait list (which means
it will be set for leader as well and that can create a problem, because leader
needs to acquire LWLock and in LWLock code, lwWaiting is used).
The problem I see with setting lwWaiting after adding it to list is that leader
might have already cleared the proc by the time we try to set lwWaiting
for a follower.
For now, I have added a separate variable.
>
> > > Consider what happens if such a follower enqueues in another
> > > transaction. It is not, as far as I could find out, guaranteed on all
> > > types of cpus that a third backend can actually see nextClearXidElem
> > > as INVALID_PGPROCNO. That'd likely require SMT/HT cores and multiple
> > > sockets. If the write to nextClearXidElem is entered into the local
> > > store buffer (leader #1) a hyper-threaded process (leader #2) can
> > > possibly see it (store forwarding) while another backend doesn't
> > > yet.
> > >
> > > I think this is very unlikely to be an actual problem due to
> > > independent barriers until enqueued again, but I don't want to rely
> > > on it undocumentedly. It seems safer to replace
> > > + wakeidx = pg_atomic_read_u32(&proc->nextClearXidElem);
> > > + pg_atomic_write_u32(&proc->nextClearXidElem,
> > INVALID_PGPROCNO);
> > > with a pg_atomic_exchange_u32().
> > >
> >
> > I didn't follow this point, if we ensure that follower can never return
> > before leader wakes it up, then why it will be a problem to update
> > nextClearXidElem like above.
>
> Because it doesn't generally enforce that *other* backends have seen the
> write as there's no memory barrier.
>
After changing the code by have separate variable to indicate that the xid
is cleared and changed logic (by having barriers), I don't think this problem
can occur, can you please see the latest attached patch and let me know
if you still see this problem.
>
>
> > > I don't think it's a good idea to use the variable name in PROC_HDR and
> > > PGPROC, it's confusing.
>
> > What do you mean by this, are you not happy with variable name?
>
> Yes. I think it's a bad idea to have the same variable name in PROC_HDR
> and PGPROC.
>
> struct PGPROC
> {
> ...
> /* Support for group XID clearing. */
> volatile pg_atomic_uint32 nextClearXidElem;
> ...
> }
>
> typedef struct PROC_HDR
> {
> ...
> /* First pgproc waiting for group XID clear */
> volatile pg_atomic_uint32 nextClearXidElem;
> ...
> }
>
> PROC_HDR's variable imo isn't well named.
>
Changed the variable name in PROC_HDR.
> How hard did you try checking whether this causes regressions? This
> increases the number of atomics in the commit path a fair bit. I doubt
> it's really bad, but it seems like a good idea to benchmark something
> like a single full-throttle writer and a large number of readers.
> increases the number of atomics in the commit path a fair bit. I doubt
> it's really bad, but it seems like a good idea to benchmark something
> like a single full-throttle writer and a large number of readers.
One way to test this is run pgbench read load (with 100 client count) and
write load (tpc-b - with one client) simultaneously and check the results.
I have tried this and there is lot of variation(more than 50%) in tps in
different runs of write load, so not sure if this is the right way to
benchmark it.
Another possible way is to hack pgbench code and make one thread run
write transaction and others run read transactions.
Do you have any other ideas or any previously written test (which you are
aware of) with which this can be tested?
Вложения
On Tue, Aug 25, 2015 at 5:21 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>
> On Thu, Aug 20, 2015 at 3:49 PM, Andres Freund <andres@anarazel.de> wrote:
> > How hard did you try checking whether this causes regressions? This
> > increases the number of atomics in the commit path a fair bit. I doubt
> > it's really bad, but it seems like a good idea to benchmark something
> > like a single full-throttle writer and a large number of readers.
>
> One way to test this is run pgbench read load (with 100 client count) and
> write load (tpc-b - with one client) simultaneously and check the results.
> I have tried this and there is lot of variation(more than 50%) in tps in
> different runs of write load, so not sure if this is the right way to
> benchmark it.
>
> Another possible way is to hack pgbench code and make one thread run
> write transaction and others run read transactions.
M/c Configuration
>
> On Thu, Aug 20, 2015 at 3:49 PM, Andres Freund <andres@anarazel.de> wrote:
> > How hard did you try checking whether this causes regressions? This
> > increases the number of atomics in the commit path a fair bit. I doubt
> > it's really bad, but it seems like a good idea to benchmark something
> > like a single full-throttle writer and a large number of readers.
>
> One way to test this is run pgbench read load (with 100 client count) and
> write load (tpc-b - with one client) simultaneously and check the results.
> I have tried this and there is lot of variation(more than 50%) in tps in
> different runs of write load, so not sure if this is the right way to
> benchmark it.
>
> Another possible way is to hack pgbench code and make one thread run
> write transaction and others run read transactions.
I have hacked pgbench to achieve single-writer-multi-reader test and below
are results:
-----------------------------
IBM POWER-8 24 cores, 192 hardware threads
RAM = 492GB
IBM POWER-8 24 cores, 192 hardware threads
RAM = 492GB
Non-default parameters
------------------------------------
max_connections = 150
shared_buffers=8GB
min_wal_size=10GB
max_wal_size=15GB
checkpoint_timeout =30min
maintenance_work_mem = 1GB
checkpoint_completion_target = 0.9
wal_buffers = 256MB
Data is for 3, 15 minutes pgbench (1-Writer, 127-Readers) test runs
Without ProcArrayLock optimization-
| Commitid – 253de7e1 | |
| Client Count/No. Of Runs (tps) | 128 |
| Run-1 | 208011 |
| Run-2 | 471598 |
| Run-3 | 218295 |
With ProcArrayLock optimization -
| Commitid – 0e141c0f | |
| Client Count/No. Of Runs (tps) | 128 |
| Run-1 | 222839 |
| Run-2 | 469483 |
| Run-3 | 215791 |
It seems the test runs get dominated by I/O due to writer client which
leads to variation in performance numbers. In general, I don't see any
noticeable difference in performance with or without procarraylock
optimisation. I have tried even by turning off synchronous_commit and
fsync, but the results are quite similar.
pgbench modifications
-----------------------------------
Introduced a new type of test run with -W option which means single
writer and multi-reader, example if user has given 128 clients and 128
threads, it will use 1-Thread for Write (Update) transaction and 127 for
Select Only transaction. This works specifically for this use case as
I had no intention to make a generic test. Please note, it will work properly
if number of clients and threads input by user are same. Attached find
the pgbench patch, I have used for this test. Note that, I have used
-W option in pgbench run as mentioned in below steps.
Test steps for each Run
--------------------------------------------------------------------------------------------------------
1. Start Server
2. dropdb postgres
3. createdb posters
4. pgbench -i -s 300 postgres
5. pgbench -c $threads -j $threads -T 1800 -M prepared -W postgres
6. checkpoint
7. Stop Server
With Regards,
Amit Kapila.
EnterpriseDB: http://www.enterprisedb.com
Вложения
On Tue, Aug 25, 2015 at 7:51 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > [ new patch ] Andres pinged me about this patch today. It contained a couple of very strange whitespace anomalies, but otherwise looked OK to me, so I committed it with after fixing those issues and tweaking the comments a bit. Hopefully we are in good shape now, but if there are any remaining concerns, more review is welcome. Thanks, -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Sep 3, 2015 at 11:07 PM, Robert Haas <robertmhaas@gmail.com> wrote:
On Tue, Aug 25, 2015 at 7:51 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> [ new patch ]
Andres pinged me about this patch today. It contained a couple of
very strange whitespace anomalies, but otherwise looked OK to me, so I
committed it with after fixing those issues and tweaking the comments
a bit.
Thanks for looking into it.