Обсуждение: pgtune + configurations with 9.3
Greetings all,
I'm trying to wrap my head around updating my configuration files, which have been probably fairly static since before 8.4.
I've got some beefy hardware but have some tables that are over 57GB raw and end up at 140GB size after indexes are applied. One index creation took 7 hours today. So it's time to dive in and see where i'm lacking and what I should be tweaking.
I looked at pgtune again today and the numbers it's spitting out took me back, they are huge. From all historical conversations and attempts a few of these larger numbers netted reduced performance vs better performance (but that was on older versions of Postgres).
So I come here today to seek out some type of affirmation that these numbers look good and I should look at putting them into my config, staged and or in one fell swoop.
I will start at the same time migrating my config to the latest 9.3 template...
Postgres Version: 9.3.4, Slony 2.1.3 (migrating to 2.2).
CentOS 6.x, 2.6.32-431.5.1.el6.x86_64
Big HP Boxen.
32 core, 256GB of Ram DB is roughly 175GB in size but many tables are hundreds of millions of rows.
The pgtune configurations that were spit out based on the information above;
max_connections = 300
shared_buffers = 64GB
effective_cache_size = 192GB
work_mem = 223696kB
maintenance_work_mem = 2GB
checkpoint_segments = 32
checkpoint_completion_target = 0.7
wal_buffers = 16MB
default_statistics_target = 100
my current configuration:
max_connections = 300
shared_buffers = 2000MB
effective_cache_size = 7GB
work_mem = 6GB
maintenance_work_mem = 10GB <-- bumped this to try to get my reindexes done
checkpoint_segments = 100
#wal_buffers = 64kB
#default_statistics_target = 10
Here is my complete configuration (This is my slon slave server, so fsync is off and archive is off, but on my primary fsync=on and archive=on).
listen_addresses = '*'
max_connections = 300
shared_buffers = 2000MB
max_prepared_transactions = 0
work_mem = 6GB
maintenance_work_mem = 10GB
fsync = off
checkpoint_segments = 100
checkpoint_timeout = 10min
checkpoint_warning = 3600s
wal_level archive
archive_mode = off
archive_command = 'tar -czvpf /pg_archives/%f.tgz %p'
archive_timeout = 10min
random_page_cost = 2.0
effective_cache_size = 7GB
log_destination = 'stderr'
logging_collector = on
log_directory = '/data/logs'
log_filename = 'pgsql-%m-%d.log'
log_truncate_on_rotation = on
log_rotation_age = 1d
log_min_messages = info
log_min_duration_statement = 15s
log_line_prefix = '%t %d %u %r %p %m'
log_lock_waits = on
log_timezone = 'US/Pacific'
autovacuum_max_workers = 3
autovacuum_vacuum_threshold = 1000
autovacuum_analyze_threshold = 2000
datestyle = 'iso, mdy'
timezone = 'US/Pacific'
lc_messages = 'en_US.UTF-8'
lc_monetary = 'en_US.UTF-8'
lc_numeric = 'en_US.UTF-8'
lc_time = 'en_US.UTF-8'
deadlock_timeout = 5s
Also while it doesn't matter in 9.3 anymore apparently my sysctl.conf has
kernel.shmmax = 68719476736
kernel.shmall = 4294967296
And PGTune recommended;
kernel.shmmax=137438953472
kernel.shmall=33554432
Also of note in my sysctl.conf config:
vm.zone_reclaim_mode = 0
vm.swappiness = 10
Thanks for the assistance, watching these index creations crawl along when you know you have so many more compute cycles to provide makes one go crazy.'
Tory
Tory M Blue wrote: > I've got some beefy hardware but have some tables that are over 57GB raw and end up at 140GB size > after indexes are applied. One index creation took 7 hours today. So it's time to dive in and see > where i'm lacking and what I should be tweaking. > > I looked at pgtune again today and the numbers it's spitting out took me back, they are huge. From all > historical conversations and attempts a few of these larger numbers netted reduced performance vs > better performance (but that was on older versions of Postgres). > > So I come here today to seek out some type of affirmation that these numbers look good and I should > look at putting them into my config, staged and or in one fell swoop. > > I will start at the same time migrating my config to the latest 9.3 template... > > Postgres Version: 9.3.4, Slony 2.1.3 (migrating to 2.2). > CentOS 6.x, 2.6.32-431.5.1.el6.x86_64 > Big HP Boxen. > > 32 core, 256GB of Ram DB is roughly 175GB in size but many tables are hundreds of millions of rows. > > The pgtune configurations that were spit out based on the information above; > > max_connections = 300 That's a lot, but equals what you currently have. It is probably ok, but can have repercussions if used with large work_mem: Every backend can allocate that much memory, maybe even several times for a complicated query. > shared_buffers = 64GB That seems a bit on the large side. I would start with something like 4GB and run (realistic) performance tests, doubling the value each time. See where you come out best. You can use the pg_buffercache contrib to see how your shared buffers are used. > effective_cache_size = 192GB That should be all the memory in the machine that is available to PostgreSQL, so on an exclusive database machine it could be even higher. > work_mem = 223696kB That looks ok, but performance testing wouldn't harm. Ideally you log temporary file creation and have this parameter big enough so that normal queries don't need temp files, but low enough so that the file system cache still has some RAM left. > maintenance_work_mem = 2GB That's particularly helpful for your problem, index creation. > checkpoint_segments = 32 Check. You want checkpoints to be time triggered, so don't be afraid to go higher if you get warnings unless a very short restore time is of paramount importance. > checkpoint_completion_target = 0.7 Check. > wal_buffers = 16MB That's fine too, although with 9.3 you might as well leave it default. With that much RAM it will be autotuned to the maximum anyway. > default_statistics_target = 100 That's the default value. Increase only if you get bad plans because of insufficient statistics. Yours, Laurenz Albe
On 10/29/2014 11:49 PM, Tory M Blue wrote: > I looked at pgtune again today and the numbers it's spitting out took me > back, they are huge. From all historical conversations and attempts a few > of these larger numbers netted reduced performance vs better performance > (but that was on older versions of Postgres). Yeah, pgTune is pretty badly out of date. It's been on my TODO list, as I'm sure it has been on Greg's. -- Josh Berkus PostgreSQL Experts Inc. http://pgexperts.com
> Yeah, pgTune is pretty badly out of date. It's been on my TODO list, as > I'm sure it has been on Greg's. Yeah. And unfortunately the recommendations it gives have been spreading. Take a look at the online version: http://pgtune.leopard.in.ua/ I entered a pretty typical 92GB system, and it recommended 23GB of shared buffers. I tried to tell the author the performanceguidelines have since changed, but it didn't help. ______________________________________________ See http://www.peak6.com/email_disclaimer/ for terms and conditions related to this email
Fri, 7 Nov 2014 14:13:20 +0000 от Shaun Thomas <sthomas@optionshouse.com>: >> Yeah, pgTune is pretty badly out of date. It's been on my TODO list, as >> I'm sure it has been on Greg's. > >Yeah. And unfortunately the recommendations it gives have been spreading. Take a look at the online version: > >http://pgtune.leopard.in.ua/ > >I entered a pretty typical 92GB system, and it recommended 23GB of shared buffers. I tried to tell the author the performanceguidelines have since changed, but it didn't help. > > >______________________________________________ > >See http://www.peak6.com/email_disclaimer/ for terms and conditions related to this email > > >-- >Sent via pgsql-performance mailing list (pgsql-performance@postgresql.org) >To make changes to your subscription: >http://www.postgresql.org/mailpref/pgsql-performance Hello, author of http://pgtune.leopard.in.ua/ is here. I think everyone can do pull request to it. Old one take 25% for shared_buffers and 75% for effective_cache_size. I thinkI can even add selector with version of postgresql (9.0 - 9.4) and in this case change formulas for 9.4 (for example). But I don't know what type of calculation should be in this case. Does we have in some place this information? Or someonecan provide it? Because this generator should be valid for most users. Thanks. --- Alexey Vasiliev
Alexey, The issue is that the 1/4 memory suggestion hasn't been a recommendation in quite a while. Now that much larger amounts ofRAM are readily available, tests have been finding out that more than 8GB of RAM in shared_buffers has diminishing or evenworse returns. This is true for any version. Further, since PostgreSQL manages its own memory, and the Linux Kernel alsomanages various caches, there's significant risk of storing the same memory both in shared_buffers, and in file cache. There are other tweaks the tool probably needs, but I think this, more than anything else, needs to be updated. Until PGsolves the issue of double-buffering (which is somewhat in progress since they're somewhat involved with the Linux kerneldevs) you can actually give it too much memory. ______________________________________________ See http://www.peak6.com/email_disclaimer/ for terms and conditions related to this email
Fri, 14 Nov 2014 16:28:16 +0000 от Shaun Thomas <sthomas@optionshouse.com>: > Alexey, > > The issue is that the 1/4 memory suggestion hasn't been a recommendation in quite a while. Now that much larger amountsof RAM are readily available, tests have been finding out that more than 8GB of RAM in shared_buffers has diminishingor even worse returns. This is true for any version. Further, since PostgreSQL manages its own memory, and theLinux Kernel also manages various caches, there's significant risk of storing the same memory both in shared_buffers,and in file cache. > > There are other tweaks the tool probably needs, but I think this, more than anything else, needs to be updated. Until PGsolves the issue of double-buffering (which is somewhat in progress since they're somewhat involved with the Linux kerneldevs) you can actually give it too much memory. > > > ______________________________________________ > > See http://www.peak6.com/email_disclaimer/ for terms and conditions related to this email > > > -- > Sent via pgsql-performance mailing list (pgsql-performance@postgresql.org) > To make changes to your subscription: > http://www.postgresql.org/mailpref/pgsql-performance > Several months ago I asked question in this channel "Why shared_buffers max is 8GB?". Many persons said, what this is apocrypha,what 8GB is maximum value for shared_buffers. This is archive of this chat: http://www.postgresql.org/message-id/1395836511.796897979@f327.i.mail.ru What is why so hard to understand what to do with pgtune calculation. -- Alexey Vasiliev
Alexey, The issue is not that 8GB is the maximum. You *can* set it higher. What I'm saying, and I'm not alone in this, is that settingit higher can actually decrease performance for various reasons. Setting it to 25% of memory on a system with 512GBof RAM for instance, would be tantamount to disaster. A checkpoint with a setting that high could overwhelm pretty muchany disk controller and end up completely ruining DB performance. And that's just *one* of the drawbacks. ______________________________________________ See http://www.peak6.com/email_disclaimer/ for terms and conditions related to this email
Fri, 14 Nov 2014 17:06:54 +0000 от Shaun Thomas <sthomas@optionshouse.com>: > Alexey, > > The issue is not that 8GB is the maximum. You *can* set it higher. What I'm saying, and I'm not alone in this, is thatsetting it higher can actually decrease performance for various reasons. Setting it to 25% of memory on a system with512GB of RAM for instance, would be tantamount to disaster. A checkpoint with a setting that high could overwhelm prettymuch any disk controller and end up completely ruining DB performance. And that's just *one* of the drawbacks. > > > > ______________________________________________ > > See http://www.peak6.com/email_disclaimer/ for terms and conditions related to this email > > > -- > Sent via pgsql-performance mailing list (pgsql-performance@postgresql.org) > To make changes to your subscription: > http://www.postgresql.org/mailpref/pgsql-performance > Ok. Just need to know what think another developers about this - should pgtune care about this case? Because I am not sure,what users with 512GB will use pgtune. -- Alexey Vasiliev
On 15/11/14 06:06, Shaun Thomas wrote: > Alexey, > > The issue is not that 8GB is the maximum. You *can* set it higher. What I'm saying, and I'm not alone in this, is thatsetting it higher can actually decrease performance for various reasons. Setting it to 25% of memory on a system with512GB of RAM for instance, would be tantamount to disaster. A checkpoint with a setting that high could overwhelm prettymuch any disk controller and end up completely ruining DB performance. And that's just *one* of the drawbacks. > It is probably time to revisit this 8GB limit with some benchmarking. We don't really have a hard and fast rule that is known to be correct, and that makes Alexey's job really difficult. Informally folk (including myself at times) have suggested: min(ram/4, 8GB) as the 'rule of thumb' for setting shared_buffers. However I was recently benchmarking a machine with a lot of ram (1TB) and entirely SSD storage [1], and that seemed quite happy with 50GB of shared buffers (better performance than with 8GB). Now shared_buffers was not the variable we were concentrating on so I didn't get too carried away and try much bigger than about 100GB - but this seems like a good thing to come out with some numbers for i.e pgbench read write and read only tps vs shared_buffers 1 -> 100 GB in size. Cheers Mark [1] I may be in a position to benchmark the machines these replaced at some not to distant time. These are the previous generation (0.5TB ram, 32 cores and all SSD storage) but probably still good for this test.
On 11/14/14, 5:00 PM, Mark Kirkwood wrote: > > as the 'rule of thumb' for setting shared_buffers. However I was recently benchmarking a machine with a lot of ram (1TB)and entirely SSD storage [1], and that seemed quite happy with 50GB of shared buffers (better performance than with8GB). Now shared_buffers was not the variable we were concentrating on so I didn't get too carried away and try muchbigger than about 100GB - but this seems like a good thing to come out with some numbers for i.e pgbench read write andread only tps vs shared_buffers 1 -> 100 GB in size. What PG version? One of the huge issues with large shared_buffers is the immense overhead you end up with for running the clock sweep, andon most systems that overhead is born by every backend individually. You will only see that overhead if your databaseis larger than shared bufers, because you only pay it when you need to evict a buffer. I suspect you'd actually needa database at least 2x > shared_buffers for it to really start showing up. > [1] I may be in a position to benchmark the machines these replaced at some not to distant time. These are the previousgeneration (0.5TB ram, 32 cores and all SSD storage) but probably still good for this test. Awesome! If there's possibility of developers getting direct access, I suspect folks on -hackers would be interested. Ifnot but you're willing to run tests for folks, they'd still be interested. :) -- Jim Nasby, Data Architect, Blue Treble Consulting Data in Trouble? Get it in Treble! http://BlueTreble.com
On 15/11/14 15:08, Jim Nasby wrote: > On 11/14/14, 5:00 PM, Mark Kirkwood wrote: >> >> as the 'rule of thumb' for setting shared_buffers. However I was >> recently benchmarking a machine with a lot of ram (1TB) and entirely >> SSD storage [1], and that seemed quite happy with 50GB of shared >> buffers (better performance than with 8GB). Now shared_buffers was not >> the variable we were concentrating on so I didn't get too carried away >> and try much bigger than about 100GB - but this seems like a good >> thing to come out with some numbers for i.e pgbench read write and >> read only tps vs shared_buffers 1 -> 100 GB in size. > > What PG version? > > One of the huge issues with large shared_buffers is the immense overhead > you end up with for running the clock sweep, and on most systems that > overhead is born by every backend individually. You will only see that > overhead if your database is larger than shared bufers, because you only > pay it when you need to evict a buffer. I suspect you'd actually need a > database at least 2x > shared_buffers for it to really start showing up. > That was 9.4 beta1 and2. A variety of db sizes were tried, some just fitting inside shared_buffers and some a bit over 2x larger, and one variant where we sized the db to 600GB, and used 4,8 and 50GB shared_buffers (50 was the best by a small margin...and certainly no worse). Now we were mainly looking at 60 core performance issues (see thread "60 core performance with 9.3"), and possibly some detrimental effects of larger shared_buffers may have been masked by this - but performance was certainly not hurt with larger shared_buffers. regards Mark
On 15 November 2014 02:10, Alexey Vasiliev <leopard_ne@inbox.ru> wrote: > Ok. Just need to know what think another developers about this - should pgtune care about this case? Because I am not sure,what users with 512GB will use pgtune. pgtune should certainly care about working with large amounts of RAM. Best practice does not stop at 32GB of RAM, but instead becomes more and more important. I am not interested in edge cases or unusual configurations. I am interested in setting decent defaults to provide a good starting point to administrators on all sizes of hardware. I use pgtune to configure automatically deployed cloud instances. My goal is to prepare instances that have been tuned according to best practice for standard types of load. Administrators will ideally not need to tweak anything themselves, but at a minimum have been provided with a good starting point. pgtune does a great job of this, apart from the insanely high shared_buffers. At the moment I run pgtune, and then must reduce shared_buffers to 8GB if pgtune tried to select a higher value. The values it is currently choosing on higher RAM boxes are not best practice and quite wrong. The work_mem settings also seem to be very high, but so far have not posed a problem and may well be correct. I'm trusting pgtune here rather than my outdated guesses. -- Stuart Bishop <stuart@stuartbishop.net> http://www.stuartbishop.net/
On 15 November 2014 06:00, Mark Kirkwood <mark.kirkwood@catalyst.net.nz> wrote: > It is probably time to revisit this 8GB limit with some benchmarking. We > don't really have a hard and fast rule that is known to be correct, and that > makes Alexey's job really difficult. Informally folk (including myself at > times) have suggested: > > min(ram/4, 8GB) > > as the 'rule of thumb' for setting shared_buffers. However I was recently It would be nice to have more benchmarking and improve the rule of thumb. I do, however, believe this is orthogonal to fixing pgtune which I think should be using the current rule of thumb (which is overwhelmingly min(ram/4, 8GB) as you suggest). > benchmarking a machine with a lot of ram (1TB) and entirely SSD storage [1], > and that seemed quite happy with 50GB of shared buffers (better performance > than with 8GB). Now shared_buffers was not the variable we were > concentrating on so I didn't get too carried away and try much bigger than > about 100GB - but this seems like a good thing to come out with some numbers > for i.e pgbench read write and read only tps vs shared_buffers 1 -> 100 GB > in size. I've always thought the shared_buffers setting would need to factor in things like CPU speed and memory access, since the rational for the 8GB cap has always been the cost to scan the data structures. And the kernel would factor in too, since the PG specific algorithms are in competition with the generic OS algorithms. And size of the hot set, since this gets pinned in shared_buffers. Urgh, so many variables. -- Stuart Bishop <stuart@stuartbishop.net> http://www.stuartbishop.net/
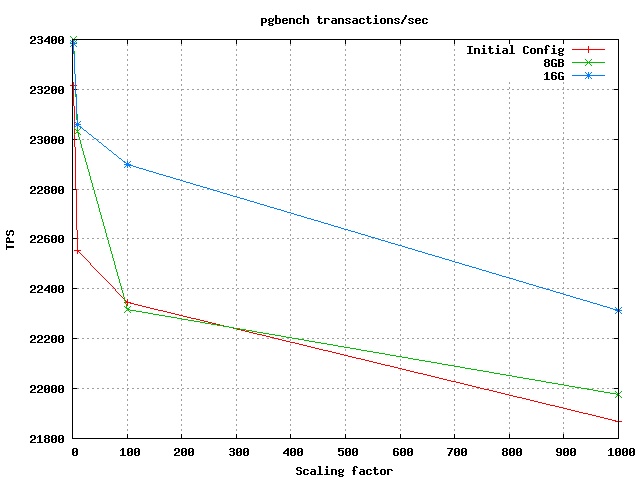
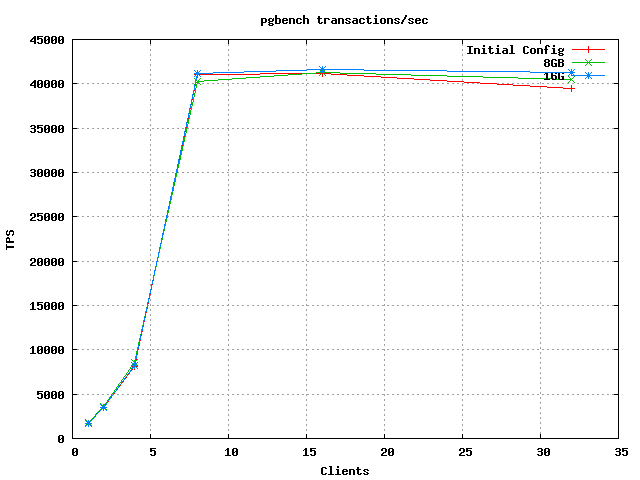
I have done some tests using pgbench-tools with different configurations on our new server with 768G RAM and it seems for our purpose 32G shared_buffers would give the best results.
RegardsJohann
On 17 November 2014 at 07:17, Stuart Bishop <stuart@stuartbishop.net> wrote:
On 15 November 2014 06:00, Mark Kirkwood <mark.kirkwood@catalyst.net.nz> wrote:
> It is probably time to revisit this 8GB limit with some benchmarking. We
> don't really have a hard and fast rule that is known to be correct, and that
> makes Alexey's job really difficult. Informally folk (including myself at
> times) have suggested:
>
> min(ram/4, 8GB)
>
> as the 'rule of thumb' for setting shared_buffers. However I was recently
It would be nice to have more benchmarking and improve the rule of
thumb. I do, however, believe this is orthogonal to fixing pgtune
which I think should be using the current rule of thumb (which is
overwhelmingly min(ram/4, 8GB) as you suggest).
> benchmarking a machine with a lot of ram (1TB) and entirely SSD storage [1],
> and that seemed quite happy with 50GB of shared buffers (better performance
> than with 8GB). Now shared_buffers was not the variable we were
> concentrating on so I didn't get too carried away and try much bigger than
> about 100GB - but this seems like a good thing to come out with some numbers
> for i.e pgbench read write and read only tps vs shared_buffers 1 -> 100 GB
> in size.
I've always thought the shared_buffers setting would need to factor in
things like CPU speed and memory access, since the rational for the
8GB cap has always been the cost to scan the data structures. And the
kernel would factor in too, since the PG specific algorithms are in
competition with the generic OS algorithms. And size of the hot set,
since this gets pinned in shared_buffers. Urgh, so many variables.
--
Stuart Bishop <stuart@stuartbishop.net>
http://www.stuartbishop.net/--
Sent via pgsql-performance mailing list (pgsql-performance@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-performance
--
Because experiencing your loyal love is better than life itself,
my lips will praise you. (Psalm 63:3)
my lips will praise you. (Psalm 63:3)
Hello Greame,
The server:
# See Gregory Smith: High Performans Postgresql 9.0 pages 81,82 for the next lines
vm.swappiness=0
vm.overcommit_memory=2
vm.dirty_ratio = 2
vm.dirty_background_ratio=1
# Maximum shared segment size in bytes
kernel.shmmax = 406622322688
# Maximum number of shared memory segments in pages
kernel.shmall = 99273028
It's probably helpful if everyone sharing this information can post their measurement process / settings and the results as completely as possible, for comparison and reference.
Apologies. I have only changed one parameter in postgresql.conf for the tests and that was shared_buffers:
shared_buffers = 32GB # min 128k
shared_preload_libraries = 'auto_explain' # (change requires restart)
vacuum_cost_delay = 5 # 0-100 milliseconds
wal_sync_method = open_sync # the default is the first option
wal_buffers = -1 # min 32kB, -1 sets based on shared_buffers
checkpoint_completion_target = 0.9 # checkpoint target duration, 0.0 - 1.0
checkpoint_warning = 30s # 0 disables
default_statistics_target = 100 # range 1-10000
log_line_prefix = '%t ' # special values:
log_statement = 'all' # none, ddl, mod, all
log_timezone = 'localtime'
autovacuum_vacuum_scale_factor = 0.1 # fraction of table size before vacuum
autovacuum_vacuum_cost_delay = 5ms # default vacuum cost delay for
datestyle = 'iso, dmy'
timezone = 'localtime'
lc_messages = 'en_ZA.UTF-8' # locale for system error message
lc_monetary = 'en_ZA.UTF-8' # locale for monetary formatting
lc_numeric = 'en_ZA.UTF-8' # locale for number formatting
lc_time = 'en_ZA.UTF-8' # locale for time formatting
default_text_search_config = 'pg_catalog.english'
auto_explain.log_min_duration = '6s' # Gregory Smith page 180
effective_cache_size = 512GB # pgtune wizard 2014-09-25
work_mem = 4608MB # pgtune wizard 2014-09-25
checkpoint_segments = 16 # pgtune wizard 2014-09-25
max_connections = 80 # pgtune wizard 2014-09-25
shared_buffers = 32GB # min 128k
shared_preload_libraries = 'auto_explain' # (change requires restart)
vacuum_cost_delay = 5 # 0-100 milliseconds
wal_sync_method = open_sync # the default is the first option
wal_buffers = -1 # min 32kB, -1 sets based on shared_buffers
checkpoint_completion_target = 0.9 # checkpoint target duration, 0.0 - 1.0
checkpoint_warning = 30s # 0 disables
default_statistics_target = 100 # range 1-10000
log_line_prefix = '%t ' # special values:
log_statement = 'all' # none, ddl, mod, all
log_timezone = 'localtime'
autovacuum_vacuum_scale_factor = 0.1 # fraction of table size before vacuum
autovacuum_vacuum_cost_delay = 5ms # default vacuum cost delay for
datestyle = 'iso, dmy'
timezone = 'localtime'
lc_messages = 'en_ZA.UTF-8' # locale for system error message
lc_monetary = 'en_ZA.UTF-8' # locale for monetary formatting
lc_numeric = 'en_ZA.UTF-8' # locale for number formatting
lc_time = 'en_ZA.UTF-8' # locale for time formatting
default_text_search_config = 'pg_catalog.english'
auto_explain.log_min_duration = '6s' # Gregory Smith page 180
effective_cache_size = 512GB # pgtune wizard 2014-09-25
work_mem = 4608MB # pgtune wizard 2014-09-25
checkpoint_segments = 16 # pgtune wizard 2014-09-25
max_connections = 80 # pgtune wizard 2014-09-25
And pgbench-tools - the default configuration:
BASEDIR=`pwd`
PGBENCHBIN=`which pgbench`
TESTDIR="tests"
SKIPINIT=0
TABBED=0
OSDATA=1
TESTHOST=localhost
TESTUSER=`whoami`
TESTPORT=5432
TESTDB=pgbench
RESULTHOST="$TESTHOST"
RESULTUSER="$TESTUSER"
RESULTPORT="$TESTPORT"
RESULTDB=results
MAX_WORKERS=""
SCRIPT="select.sql"
SCALES="1 10 100 1000"
SETCLIENTS="1 2 4 8 16 32"
SETTIMES=3
RUNTIME=60
TOTTRANS=""
SETRATES=""
BASEDIR=`pwd`
PGBENCHBIN=`which pgbench`
TESTDIR="tests"
SKIPINIT=0
TABBED=0
OSDATA=1
TESTHOST=localhost
TESTUSER=`whoami`
TESTPORT=5432
TESTDB=pgbench
RESULTHOST="$TESTHOST"
RESULTUSER="$TESTUSER"
RESULTPORT="$TESTPORT"
RESULTDB=results
MAX_WORKERS=""
SCRIPT="select.sql"
SCALES="1 10 100 1000"
SETCLIENTS="1 2 4 8 16 32"
SETTIMES=3
RUNTIME=60
TOTTRANS=""
SETRATES=""
# See Gregory Smith: High Performans Postgresql 9.0 pages 81,82 for the next lines
vm.swappiness=0
vm.overcommit_memory=2
vm.dirty_ratio = 2
vm.dirty_background_ratio=1
# Maximum shared segment size in bytes
kernel.shmmax = 406622322688
# Maximum number of shared memory segments in pages
kernel.shmall = 99273028
$ free
total used free shared buffers cached
Mem: 794184164 792406416 1777748 0 123676 788079892
-/+ buffers/cache: 4202848 789981316
Swap: 7906300 0 7906300
total used free shared buffers cached
Mem: 794184164 792406416 1777748 0 123676 788079892
-/+ buffers/cache: 4202848 789981316
Swap: 7906300 0 7906300
I have attached the resulting graphs.
Regards
Johann
Johann
--
Because experiencing your loyal love is better than life itself,
my lips will praise you. (Psalm 63:3)
my lips will praise you. (Psalm 63:3)
Вложения
{kind=link}
{kind=link}
Another apology:
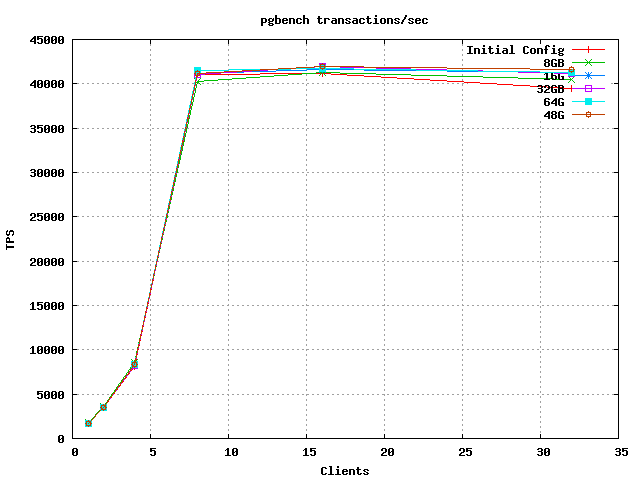
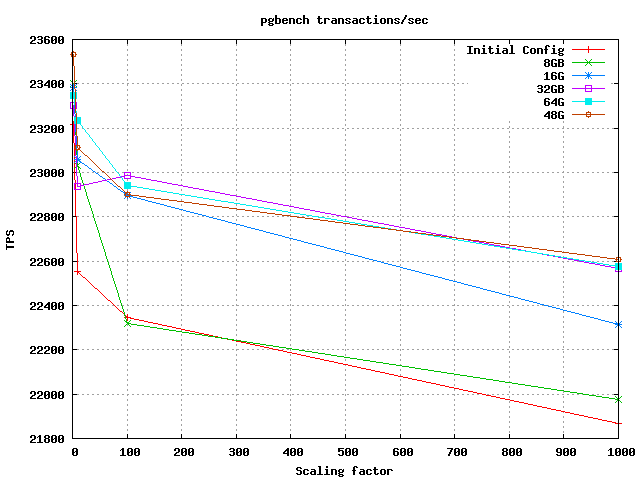
My pg_version is 9.3 On 26 November 2014 at 15:34, Johann Spies <johann.spies@gmail.com> wrote:
Hello Greame,The server:It's probably helpful if everyone sharing this information can post their measurement process / settings and the results as completely as possible, for comparison and reference.Apologies. I have only changed one parameter in postgresql.conf for the tests and that was shared_buffers:
shared_buffers = 32GB # min 128k
shared_preload_libraries = 'auto_explain' # (change requires restart)
vacuum_cost_delay = 5 # 0-100 milliseconds
wal_sync_method = open_sync # the default is the first option
wal_buffers = -1 # min 32kB, -1 sets based on shared_buffers
checkpoint_completion_target = 0.9 # checkpoint target duration, 0.0 - 1.0
checkpoint_warning = 30s # 0 disables
default_statistics_target = 100 # range 1-10000
log_line_prefix = '%t ' # special values:
log_statement = 'all' # none, ddl, mod, all
log_timezone = 'localtime'
autovacuum_vacuum_scale_factor = 0.1 # fraction of table size before vacuum
autovacuum_vacuum_cost_delay = 5ms # default vacuum cost delay for
datestyle = 'iso, dmy'
timezone = 'localtime'
lc_messages = 'en_ZA.UTF-8' # locale for system error message
lc_monetary = 'en_ZA.UTF-8' # locale for monetary formatting
lc_numeric = 'en_ZA.UTF-8' # locale for number formatting
lc_time = 'en_ZA.UTF-8' # locale for time formatting
default_text_search_config = 'pg_catalog.english'
auto_explain.log_min_duration = '6s' # Gregory Smith page 180
effective_cache_size = 512GB # pgtune wizard 2014-09-25
work_mem = 4608MB # pgtune wizard 2014-09-25
checkpoint_segments = 16 # pgtune wizard 2014-09-25
max_connections = 80 # pgtune wizard 2014-09-25And pgbench-tools - the default configuration:
BASEDIR=`pwd`
PGBENCHBIN=`which pgbench`
TESTDIR="tests"
SKIPINIT=0
TABBED=0
OSDATA=1
TESTHOST=localhost
TESTUSER=`whoami`
TESTPORT=5432
TESTDB=pgbench
RESULTHOST="$TESTHOST"
RESULTUSER="$TESTUSER"
RESULTPORT="$TESTPORT"
RESULTDB=results
MAX_WORKERS=""
SCRIPT="select.sql"
SCALES="1 10 100 1000"
SETCLIENTS="1 2 4 8 16 32"
SETTIMES=3
RUNTIME=60
TOTTRANS=""
SETRATES=""
# See Gregory Smith: High Performans Postgresql 9.0 pages 81,82 for the next lines
vm.swappiness=0
vm.overcommit_memory=2
vm.dirty_ratio = 2
vm.dirty_background_ratio=1
# Maximum shared segment size in bytes
kernel.shmmax = 406622322688
# Maximum number of shared memory segments in pages
kernel.shmall = 99273028$ free
total used free shared buffers cached
Mem: 794184164 792406416 1777748 0 123676 788079892
-/+ buffers/cache: 4202848 789981316
Swap: 7906300 0 7906300I have attached the resulting graphs.Regards
Johann--Because experiencing your loyal love is better than life itself,
my lips will praise you. (Psalm 63:3)
--
Because experiencing your loyal love is better than life itself,
my lips will praise you. (Psalm 63:3)
my lips will praise you. (Psalm 63:3)
{kind=link}
{kind=link}