Обсуждение: [HACKERS] [GSOC][weekly report 9] Eliminate O(N^2) scaling from rw-conflict tracking in serializable transactions
In the last week, I focus on:
1) Continuing on optimization of skip list. Here is the new logic:
At first, I use an unordered linked list to do all inserting/searching operations.
When the number of conflicts is more than the threshold, transform the linked list into an ordered skip list.
Then all inserting/searching operations are done by the skip list.
By this way, for transactions with only a few conflicts, overhead of inserting is O(1).
the patch is attached.
It helped a little, but just a little. In the end, the skip list has the same performance of the linked list.
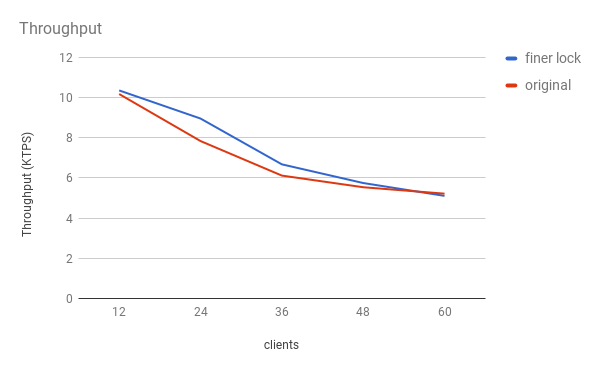
2) Studying the performance of less contention on FinishedListLock.
I found it can get benefit when the number of conflicts is medium. It is easy to understand the optimization
has no influence when conflicts are too rare. But when there are too many c onflicts, partition lock
will be the new bottleneck and the performance can't be improved. A chart is attached. This optimization
can achieve 14% speedup at most.
--
Sincerely
Вложения
{kind=link}
Mengxing Liu wrote: > In the last week, I focus on: > > > 1) Continuing on optimization of skip list. Let me state once again that I'm certainly not an expert in the predicate locks module and that I hope Kevin will chime in with more useful feedback than mine. Some random thoughts: * I wonder why did you settle on a skip list as the best optimization path for this. Did you consider other data structures? (We don't seem to have much that would be usable in shared memory, I fear.) * I wonder if a completely different approach to the finished xact maintenance problem would be helpful. For instance, inReleasePredicateLocks we call ClearOldPredicateLocks() inconditionally, and there we grab the SerializableFinishedListLocklock inconditionally for the whole duration of that routine, but perhaps it would be better toskip the whole ClearOld stuff if the SerializableFinishedListLock is not available? Find out some way to ensure that thecleanup is always called later on, but maybe skipping it once in a while improves overall performance. * the whole predicate.c stuff is written using SHM_QUEUE. I suppose SHM_QUEUE works just fine, but predicate.c was beingwritten at about the same time (or a bit earlier) than the newer ilist.c interface was being created, which I thinkhad more optimization work thrown in. Maybe it would be good for predicate.c to ditch use of SHM_QUEUE and use ilist.cinterfaces instead? We could even think about being less strict about holding exclusive lock on SerializableFinishedfor the duration of ClearOldPredicateLocks, i.e. use only a share lock and only exchange for exclusiveif a list modification is needed. -- Álvaro Herrera https://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
> From: "Alvaro Herrera" <alvherre@2ndquadrant.com> > * I wonder why did you settle on a skip list as the best optimization > path for this. Did you consider other data structures? (We don't > seem to have much that would be usable in shared memory, I fear.) > There are three typical alternative data structures: 1) unordered linked list, with O(N) searching and O(1) inserting/removing. 2) tree-like data structures, with O(log(N)) inserting/searching/removing. Skip list just likes a tree. 3) hash table , with O(1) inserting/searching. But constant is much bigger than linked list. Any data structures can be classified into one of data structures above. In PG serializable module, number of conflicts is much smaller than we excepted, which means N is small. So we should be very careful about constants before Big O notation. Sometimes O(N) complexity of linked list is faster than O(1) complexity of hash table. For example, when N is smaller than 5, HTAB is slower than SHM_QUEUE when searching an element. And in all cases, remove operation of hash table is slower than that of linked list, which would result in more serious problem: more contention on SeriliazableFinishedListLock. Skip list is better than HTAB because its remove operation has O(1) complexity. I think any other tree-like data structures won't do better. Shared memory is also the reason why I chose hash table and skip list at the beginning. It's quite difficult to develop a totally new data structure in shared memory, while there were well tested hash table and linked list code already. > * I wonder if a completely different approach to the finished xact > maintenance problem would be helpful. For instance, in > ReleasePredicateLocks we call ClearOldPredicateLocks() > inconditionally, and there we grab the SerializableFinishedListLock > lock inconditionally for the whole duration of that routine, but > perhaps it would be better to skip the whole ClearOld stuff if the > SerializableFinishedListLock is not available? Find out some way to > ensure that the cleanup is always called later on, but maybe skipping > it once in a while improves overall performance. > Yes, that sounds nice. Actually, for a special backend worker, it's OK to skip the ClearOldPredicateLocks. Because other workers will do the clean job later. I'll try it later. > * the whole predicate.c stuff is written using SHM_QUEUE. I suppose > SHM_QUEUE works just fine, but predicate.c was being written at about > the same time (or a bit earlier) than the newer ilist.c interface was > being created, which I think had more optimization work thrown in. > Maybe it would be good for predicate.c to ditch use of SHM_QUEUE and > use ilist.c interfaces instead? We could even think about being less > strict about holding exclusive lock on SerializableFinished for the > duration of ClearOldPredicateLocks, i.e. use only a share lock and > only exchange for exclusive if a list modification is needed. > I read the code in ilist.c but I didn't see too much difference with SHM_QUEUE. Anyway, I'll do a small test to compare the performance of these two data structures. > -- > Álvaro Herrera https://www.2ndQuadrant.com/ > PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services -- Sincerely Mengxing Liu
On Mon, Aug 7, 2017 at 1:51 PM, Alvaro Herrera <alvherre@2ndquadrant.com> wrote: > * the whole predicate.c stuff is written using SHM_QUEUE. I suppose > SHM_QUEUE works just fine, but predicate.c was being written at about > the same time (or a bit earlier) than the newer ilist.c interface was > being created, which I think had more optimization work thrown in. > Maybe it would be good for predicate.c to ditch use of SHM_QUEUE and > use ilist.c interfaces instead? We could even think about being less > strict about holding exclusive lock on SerializableFinished for the > duration of ClearOldPredicateLocks, i.e. use only a share lock and > only exchange for exclusive if a list modification is needed. I think we should rip SHM_QUEUE out completely and get rid of it. It doesn't make sense to have two implementations, one of which by its name is only for use in shared memory. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
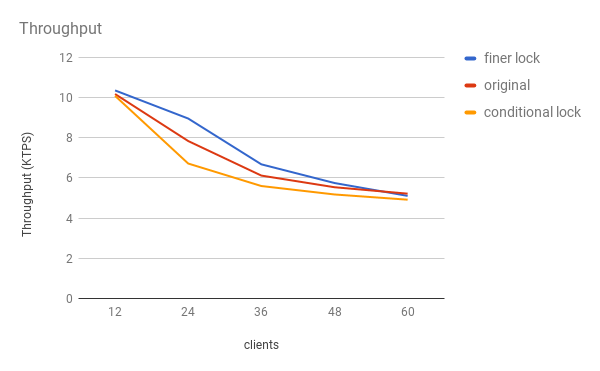
In the last week, I tried these two ideas. > -----Original Messages----- > From: "Alvaro Herrera" <alvherre@2ndquadrant.com> > Sent Time: 2017-08-08 01:51:52 (Tuesday) > * I wonder if a completely different approach to the finished xact > maintenance problem would be helpful. For instance, in > ReleasePredicateLocks we call ClearOldPredicateLocks() > inconditionally, and there we grab the SerializableFinishedListLock > lock inconditionally for the whole duration of that routine, but > perhaps it would be better to skip the whole ClearOld stuff if the > SerializableFinishedListLock is not available? Find out some way to > ensure that the cleanup is always called later on, but maybe skipping > it once in a while improves overall performance. > I implemented the idea by this way: using LWLockConditionalAcquire instead of LWLockAcquire. If the lock is held by others, just return. It's OK because the routine is used to clear old predicate locks but it doesn't matter who does the job. But we both ignored one thing: this idea doesn't speedup the releasing operation. It just avoids some processes waiting for the lock. If the function ClearOldPredicateLocks is the bottleneck, skipping doesn't help anymore. I attached the result of evaluation. This idea ( conditional lock) has the worst performance. > > * the whole predicate.c stuff is written using SHM_QUEUE. I suppose > SHM_QUEUE works just fine, but predicate.c was being written at about > the same time (or a bit earlier) than the newer ilist.c interface was > being created, which I think had more optimization work thrown in. > Maybe it would be good for predicate.c to ditch use of SHM_QUEUE and > use ilist.c interfaces instead? We could even think about being less > strict about holding exclusive lock on SerializableFinished for the > duration of ClearOldPredicateLocks, i.e. use only a share lock and > only exchange for exclusive if a list modification is needed. > I used the double linked list in ilist.c but it didn't improve the performance. I did a micro benchmark to compare the performance of SHM_QUEUE & ilist.c and didn't find any difference. So the result is reasonable. But there is a voice to get rid of SHM_QUEUE because it does not make sense to have two same implementations. What's your opinion? > -- > Álvaro Herrera https://www.2ndQuadrant.com/ > PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services -- Sincerely Mengxing Liu -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
{kind=link}