Обсуждение: Potential G2-item cycles under serializable isolation
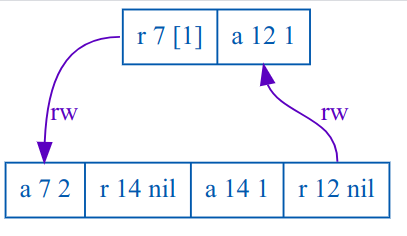
Hello everyone! First off, I'm sorry for *gestures vaguely* all of this. Second, I think I may have found a serializability violation in Postgres 12.3, involving anti-dependency cycles around row insertion. For background, my name is Kyle Kingsbury, and I test distributed database safety properties (https://jepsen.io). I started looking at Stolon + PostgreSQL this week, encountered this behavior, and managed to narrow it down to a single Postgres node without Stolon at all. Normally I test with a variety of faults (network partitions, crashes, etc.), but this behavior occurs in healthy processes without any faults. This test uses the Jepsen testing library (https://github.com/jepsen-io/jepsen) and the Elle isolation checker (https://github.com/jepsen-io/elle). If you're wondering "why would you ever do transactions like this", the Elle paper might provide some helpful background: https://arxiv.org/abs/2003.10554. We install Postgres 12.3-1.pgdg100+1 on a Debian 10 node, using the official Postgres repository at http://apt.postgresql.org/pub/repos/apt/. Each client uses its own JDBC connection, on a single thread, in a single JVM process. We use the JDBC postgres driver (org.postgresql/postgresql 42.2.12). The JDK is 1.8.0_40-b25. Logically, the test performs randomly generated transactions over a set of lists identified by integer keys. Each operation is either a read, which returns the current value of the list for a given key, or an append, which adds a unique element to the end of the list for a given key. In Postgres, we store these objects in tables like so: create table if not exists txn0 (id int not null primary key, sk int not null, val text) id is the key, and text stores comma-separated elements. sk is a secondary key, which is unused here. We create three tables like this (txn0, txn1, txn2). Records are striped across tables by hashing their key. We set the session transaction isolation level immediately after opening every connection: SET SESSION CHARACTERISTICS AS TRANSACTION ISOLATION LEVEL SERIALIZABLE ... and request SERIALIZABLE for each JDBC transaction as well. Our reads are of the form: select (val) from txn0 where id = $1 And our writes are of the form: insert into txn1 as t (id, sk, val) values ($1, $2, $3) on conflict (id) do update set val = CONCAT(t.val, ',', $4) where t.id = $5 where $1 and $5 are the key, and $2, $3, and $4 are the element we'd like to append to the list. You can try these transactions for yourself using Jepsen f47eb25. You'll need a Jepsen environment; see https://github.com/jepsen-io/jepsen#setting-up-a-jepsen-environment for details. cd jepsen/stolon lein run test-all -w append --nemesis none --max-writes-per-key 8 --node n1 --just-postgres --concurrency 50 -r 1000 Which typically produces, after about a minute, anomalies like the following: G2-item #1 Let: T1 = {:type :ok, :f :txn, :value [[:r 7 [1]] [:append 12 1]], :time 95024280, :process 5, :index 50} T2 = {:type :ok, :f :txn, :value [[:append 7 2] [:r 14 nil] [:append 14 1] [:r 12 nil]], :time 98700211, :process 6, :index 70} Then: - T1 < T2, because T1 did not observe T2's append of 2 to 7. - However, T2 < T1, because T2 observed the initial (nil) state of 12, which T1 created by appending 1: a contradiction! A dependency graph of this anomaly is attached to this email: lines marked `rw` indicate read-write anti-dependencies between specific operations in each transaction. Because there are multiple rw edges in this graph, it suggests the presence of G2-item. It is also possible, of course, that worse anomalies happened (e.g. aborted read) which caused us to incorrectly infer this causal graph, but I suspect this is not the case. You can find a full copy of this particular test run, including a history of every transaction, Postgres logs, and a pcap file containing all client-server interactions, at http://jepsen.io.s3.amazonaws.com/analyses/postgresql-12.3/20200531T215019.000-0400.zip If you'd like to look at the test code, see https://github.com/jepsen-io/jepsen/tree/f47eb25ab32529a7b66f1dfdd3b5ef2fc84ed778/stolon/src/jepsen. Specifically, setup code is here: https://github.com/jepsen-io/jepsen/blob/f47eb25ab32529a7b66f1dfdd3b5ef2fc84ed778/stolon/src/jepsen/stolon/db.clj#L200-L233 ... and the workload responsible for constructing and submitting transactions is here: https://github.com/jepsen-io/jepsen/blob/f47eb25ab32529a7b66f1dfdd3b5ef2fc84ed778/stolon/src/jepsen/stolon/append.clj#L31-L107 These anomalies appear limited to G2-item: I haven't seen G-single (read skew), cyclic information flow, aborted reads, dirty writes, etc. It also looks as if every anomaly involves a *nil* read, which suggests (and I know the bug report guidelines say not to speculate, but experience suggests this might be helpful) that there is something special about row insertion. In TiDB, for instance, we found that G2-item anomalies with `select ... for update` was linked to the fact that TiDB's lock manager couldn't lock keys which hadn't been created yet (https://jepsen.io/analyses/tidb-2.1.7#select-for-update). I don't know anything about Postgres' internals, but I hope this is of some use! Is this... known behavior? Unexpected? Are there configuration flags or client settings I should double-check? I know this is all a bit much, so I'm happy to answer any questions you might have. :-) Sincerely, --Kyle
Вложения
{kind=link}
Hi Kyle, On Sun, May 31, 2020 at 7:25 PM Kyle Kingsbury <aphyr@jepsen.io> wrote: > Our reads are of the form: > > select (val) from txn0 where id = $1 > > And our writes are of the form: > > insert into txn1 as t (id, sk, val) values ($1, $2, $3) on conflict (id) do > update set val = CONCAT(t.val, ',', $4) where t.id = $5 ON CONFLICT DO UPDATE has some novel behaviors in READ COMMITTED mode, but they're not supposed to affect SERIALIZABLE mode. > where $1 and $5 are the key, and $2, $3, and $4 are the element we'd like to > append to the list. > > You can try these transactions for yourself using Jepsen f47eb25. You'll need a > Jepsen environment; see > https://github.com/jepsen-io/jepsen#setting-up-a-jepsen-environment for details. > > cd jepsen/stolon > > lein run test-all -w append --nemesis none --max-writes-per-key 8 --node n1 > --just-postgres --concurrency 50 -r 1000 We generally like to produce tests for SSI, ON CONFLICT DO UPDATE, and anything else involving concurrent behavior using something called isolation tester: https://github.com/postgres/postgres/tree/master/src/test/isolation We may end up writing an isolation test for the issue you reported as part of an eventual fix. You might find it helpful to review some of the existing tests. > Which typically produces, after about a minute, anomalies like the following: > > G2-item #1 > Let: > T1 = {:type :ok, :f :txn, :value [[:r 7 [1]] [:append 12 1]], :time 95024280, > :process 5, :index 50} > T2 = {:type :ok, :f :txn, :value [[:append 7 2] [:r 14 nil] [:append 14 1] > [:r 12 nil]], :time 98700211, :process 6, :index 70} > > Then: > - T1 < T2, because T1 did not observe T2's append of 2 to 7. > - However, T2 < T1, because T2 observed the initial (nil) state of 12, which > T1 created by appending 1: a contradiction! Could you test Postgres 9.5? It would be nice to determine if this is a new issue, or a regression. Thanks -- Peter Geoghegan
On 5/31/20 11:04 PM, Peter Geoghegan wrote: > We generally like to produce tests for SSI, ON CONFLICT DO UPDATE, and > anything else involving concurrent behavior using something called isolation > tester: https://github.com/postgres/postgres/tree/master/src/test/isolation We > may end up writing an isolation test for the issue you reported as part of an > eventual fix. You might find it helpful to review some of the existing tests. Ah, wonderful! I don't exactly know how to plug Elle's history analysis into this, but I think it... should be possible to write down some special cases based on the histories I've seen. > Could you test Postgres 9.5? It would be nice to determine if this is > a new issue, or a regression. I'll look into that tomorrow morning! :) I, uh, backed off to running these tests at read committed (which, uh... should be SI, right?) and found what appear to be scads of SI violations, including read skew and even *internal* consistency anomalies. Read-only transactions can... apparently... see changing values of a record? Here's a single transaction which read key 21, got [1], then read key 21 again, and saw [1 2 3]: [[:r 21 [1]] [:r 20 [1 2]] [:r 20 [1 2]] [:r 21 [1 2 3]]] See http://jepsen.io.s3.amazonaws.com/analyses/postgresql-12.3/20200531T223558.000-0400.zip -- jepsen.log from 22:36:09,907 to 22:36:09,909: 2020-05-31 22:36:09,907{GMT} INFO [jepsen worker 6] jepsen.util: 6 :invoke :txn [[:r 21 nil] [:r 20 nil] [:r 20 nil] [:r 21 nil]] ... 2020-05-31 22:36:09,909{GMT} INFO [jepsen worker 6] jepsen.util: 6 :ok :txn [[:r 21 [1]] [:r 20 [1 2]] [:r 20 [1 2]] [:r 21 [1 2 3]]] You can fire up wireshark and point it at the pcap file in n1/ to double-check--try `tcp.stream eq 4`. The BEGIN statement for this transaction is at 22:36:09.908115. There are a bunch more anomalies called out in analysis.edn, if it's helpful. This looks so weird that I assume I've *got* to be doing it wrong, but trawling through the source code and pcap trace, I can't see where the mistake is. Maybe I'll have fresher eyes in the morning. :) Sincerely, --Kyle
On Sun, May 31, 2020 at 8:37 PM Kyle Kingsbury <aphyr@jepsen.io> wrote: > This looks so weird that I assume I've *got* to be doing it wrong, but trawling > through the source code and pcap trace, I can't see where the mistake is. Maybe > I'll have fresher eyes in the morning. :) READ COMMITTED starts each command within a transaction with its own snapshot, much like Oracle: https://www.postgresql.org/docs/devel/transaction-iso.html There cannot be serialization errors with READ COMMITTED mode, and in general it is a lot more permissive. Probably to the point where it isn't sensible to test with Jepsen at all. It would make sense for you to test REPEATABLE READ isolation level separately, though. It implements snapshot isolation without the added overhead of the mechanisms that prevent (or are supposed to prevent) serialization anomalies. -- Peter Geoghegan
On Sun, May 31, 2020 at 8:37 PM Kyle Kingsbury <aphyr@jepsen.io> wrote:
> This looks so weird that I assume I've *got* to be doing it wrong, but trawling
> through the source code and pcap trace, I can't see where the mistake is. Maybe
> I'll have fresher eyes in the morning. :)
READ COMMITTED starts each command within a transaction with its own
snapshot, much like Oracle:
https://www.postgresql.org/docs/devel/transaction-iso.html
There cannot be serialization errors with READ COMMITTED mode, and in
general it is a lot more permissive. Probably to the point where it
isn't sensible to test with Jepsen at all.
It would make sense for you to test REPEATABLE READ isolation level
separately, though. It implements snapshot isolation without the added
overhead of the mechanisms that prevent (or are supposed to prevent)
serialization anomalies.
--
Peter Geoghegan
On Mon, Jun 1, 2020 at 4:05 PM Kyle Kingsbury <aphyr@jepsen.io> wrote: > I'll also see about getting a version of these tests that doesn't involve ON CONFLICT, in case that's relevant. That should be interesting. I'm wondering if the read of the old value in the UPDATE case is not done with appropriate predicate locks, so we miss a graph edge?
Hi Kyle, On Sun, May 31, 2020 at 9:05 PM Kyle Kingsbury <aphyr@jepsen.io> wrote: > Oh! Gosh, yes, that DOES explain it. Somehow I had it in my head that both RU and RC mapped to SI, and RR & Serializablemapped to SSI. That's the case in YugabyteDB, but not here! It's confusing because the standard only requires that the isolation levels avoid certain read phenomena, but implementations are free to go above and beyond. For example, you can ask Postgres for READ UNCOMMITTED, but you'll get READ COMMITTED. (So RC, RR, and SI each provide distinct behavior.) > I'll also see about getting a version of these tests that doesn't involve ON CONFLICT, in case that's relevant. That would be great. It could easily be relevant. Thanks -- Peter Geoghegan
> It's confusing because the standard only requires that the isolation > levels avoid certain read phenomena, but implementations are free to > go above and beyond. For example, you can ask Postgres for READ > UNCOMMITTED, but you'll get READ COMMITTED. (So RC, RR, and SI each > provide distinct behavior.)
Right, right. I was thinking "Oh, repeatable read is incomparable with snapshot, so it must be that read committed is snapshot, and repeatable is serializable." This way around, Postgres "repeatable read" actually gives you behavior that violates repeatable read! But I understand the pragmatic rationale of "we need 3 levels, and this is the closest mapping we could get to the ANSI SQL names". :)
--Kyle
On Sun, May 31, 2020 at 9:29 PM Kyle Kingsbury <aphyr@jepsen.io> wrote: > Right, right. I was thinking "Oh, repeatable read is incomparable with snapshot, so it must be that read committed is snapshot,and repeatable is serializable." Right. We used to call snapshot isolation (i.e., the behavior we now provide under RR mode) SERIALIZABLE, which was wrong (still is in Oracle). This was how Postgres worked before the SSI feature was added back in 2011. SSI became the new SERIALIZABLE at that time. Ordinary snapshot isolation was "demoted" to being called RR mode. -- Peter Geoghegan
OK! So I've designed a variant of this test which doesn't use ON CONFLICT. Instead, we do a homebrew sort of upsert: we try to update the row in place by primary key; if we see zero records updated, we insert a new row, and if *that* fails due to the primary key conflict, we try the update again, under the theory that since we now know a copy of the row exists, we should be able to update it. https://github.com/jepsen-io/jepsen/blob/f47eb25ab32529a7b66f1dfdd3b5ef2fc84ed778/stolon/src/jepsen/stolon/append.clj#L31-L108 This isn't bulletproof; even under SERIALIZABLE, Postgres will allow a transaction to fail to update any rows, then fail to insert due to a primary key conflict--but because the primary key conflict forces a transaction abort (or rolling back to a savepoint, which negates the conflict), I think it's still serializable. The isolation docs explain this, I think. Unfortunately, I'm still seeing tons of G2-item cycles. Whatever this is, it's not related to ON CONFLICT. As a side note, I can confirm that Postgres repeatable read is definitely weaker than repeatable read--at least as formalized by Adya et al. This makes sense if you understand repeatable read to mean SI (after all, the SI paper says they're incomparable!), but the Postgres docs seem to imply Postgres is strictly *stronger* than the ANSI SQL spec, and I'm not convinced that's entirely true: https://www.postgresql.org/docs/12/transaction-iso.html > The table also shows that PostgreSQL's Repeatable Read implementation does not allow phantom reads. Stricter behavior is permitted by the SQL standard... > This is a stronger guarantee than is required by the SQL standard for this isolation level... I get the sense that the Postgres docs have already diverged from the ANSI SQL standard a bit, since SQL 92 only defines three anomalies (P1, P2, P3), and Postgres defines a fourth: "serialization anomaly". This results in a sort of weird situation: on the one hand, it's true: we don't (I think) observe P1 or P2 under Postgres Repeatable Read. On the other hand, SQL 92 says that the difference between repeatable read and serializable is *exactly* the prohibition of P3 ("phantom"). Even though all our operations are performed by primary key, we can observe a distinct difference between Postgres repeatable read and Postgres serializable. I can see two ways to reconcile this--one being that Postgres chose the anomaly interpretation of the SQL spec, and the result is... maybe internally inconsistent? Or perhaps one of the operations in this workload actually *is* a predicate operation--maybe by dint of relying on a uniqueness constraint? I'm surprised the transaction isolation docs don't say something like "Postgres repeatable read level means snapshot isolation, which is incomparable with SQL repeatable read." Then it'd be obvious that Postgres repeatable read exhibits G2-item! Weirdly, the term "snapshot isolation" doesn't show up on the page at all! --Kyle
On Tue, Jun 2, 2020 at 9:19 AM Kyle Kingsbury <aphyr@jepsen.io> wrote: > OK! So I've designed a variant of this test which doesn't use ON CONFLICT. > Instead, we do a homebrew sort of upsert: we try to update the row in place by > primary key; if we see zero records updated, we insert a new row, and if *that* > fails due to the primary key conflict, we try the update again, under the theory > that since we now know a copy of the row exists, we should be able to update it. > > https://github.com/jepsen-io/jepsen/blob/f47eb25ab32529a7b66f1dfdd3b5ef2fc84ed778/stolon/src/jepsen/stolon/append.clj#L31-L108 Thanks, but I think that this link is wrong, since you're still using ON CONFLICT. Correct me if I'm wrong, I believe that you intended to link to this: https://github.com/jepsen-io/jepsen/commit/ac4956871c8227d57d11a665e43c3d68bb7d7ec1#diff-0f5b390b5cdbd8650cf39e3c3f6f365fR31-R65 > Unfortunately, I'm still seeing tons of G2-item cycles. Whatever this is, it's > not related to ON CONFLICT. Good to have that confirmed. Obviously we'll need to do more analysis of the exact circumstances of the anomaly. That might take a while. > I get the sense that the Postgres docs have already diverged from the ANSI SQL > standard a bit, since SQL 92 only defines three anomalies (P1, P2, P3), and > Postgres defines a fourth: "serialization anomaly". > I can see two ways to reconcile this--one being that Postgres chose the anomaly > interpretation of the SQL spec, and the result is... maybe internally > inconsistent? Or perhaps one of the operations in this workload actually *is* a > predicate operation--maybe by dint of relying on a uniqueness constraint? You might find that "A Critique of ANSI SQL Isolation Levels" provides useful background information: https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/tr-95-51.pdf One section in particular may be of interest: "ANSI SQL intended to define REPEATABLE READ isolation to exclude all anomalies except Phantom. The anomaly definition of Table 1 does not achieve this goal, but the locking definition of Table 2 does. ANSI’s choice of the term Repeatable Read is doubly unfortunate: (1) repeatable reads do not give repeatable results, and (2) the industry had already used the term to mean exactly that: repeatable reads mean serializable in several products. We recommend that another term be found for this." -- Peter Geoghegan
On 6/2/20 12:50 PM, Peter Geoghegan wrote: > On Tue, Jun 2, 2020 at 9:19 AM Kyle Kingsbury <aphyr@jepsen.io> wrote: >> OK! So I've designed a variant of this test which doesn't use ON CONFLICT. >> Instead, we do a homebrew sort of upsert: we try to update the row in place by >> primary key; if we see zero records updated, we insert a new row, and if *that* >> fails due to the primary key conflict, we try the update again, under the theory >> that since we now know a copy of the row exists, we should be able to update it. >> >> https://github.com/jepsen-io/jepsen/blob/f47eb25ab32529a7b66f1dfdd3b5ef2fc84ed778/stolon/src/jepsen/stolon/append.clj#L31-L108 > Thanks, but I think that this link is wrong, since you're still using > ON CONFLICT. Correct me if I'm wrong, I believe that you intended to > link to this: Whoops, yes, that's correct. :-) > Good to have that confirmed. Obviously we'll need to do more analysis > of the exact circumstances of the anomaly. That might take a while. No worries! Is it still important that I check this behavior with 9.x as well? > You might find that "A Critique of ANSI SQL Isolation Levels" provides > useful background information: > > https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/tr-95-51.pdf This is one of my favorite papers, and precisely why I asked! > One section in particular may be of interest: > > "ANSI SQL intended to define REPEATABLE READ isolation to exclude all > anomalies except Phantom. The anomaly definition of Table 1 does not > achieve this goal, but the locking definition of Table 2 does. ANSI’s > choice of the term Repeatable Read is doubly unfortunate: (1) > repeatable reads do not give repeatable results, and (2) the industry > had already used the term to mean exactly that: repeatable reads mean > serializable in several products. We recommend that another term be > found for this." So... just to confirm, Postgres *did* go along with the anomaly interpretation, rather than the strict interpretation? It's just weird cuz, like... the Postgres docs act like SI is stronger than RR, but Berenson et al are pretty clear that's not how they see it! --Kyle
On Tue, Jun 2, 2020 at 9:58 AM Kyle Kingsbury <aphyr@jepsen.io> wrote: > No worries! Is it still important that I check this behavior with 9.x as well? I asked about 9.5 because I think that it's possible (though not particularly likely) that some of the B-Tree indexing work that went into Postgres 12 is a factor (predicate locks can be taken against individual leaf pages, and the way that that works changed slightly). SSI was verified using extensive stress tests during its initial development (by Dan Ports), so it's not inconceivable that there was some kind of subtle regression since that time. That's just a guess, but it would be nice to eliminate it as a theory. I'd be surprised if your existing test cases needed any adjustment. My guess is that this won't take long. > So... just to confirm, Postgres *did* go along with the anomaly interpretation, > rather than the strict interpretation? It's just weird cuz, like... the Postgres > docs act like SI is stronger than RR, but Berenson et al are pretty clear that's > not how they see it! I wasn't involved in the decision making process that led to that, and it's possible that those that were weren't even aware of the paper. It was necessary to shoehorn SSI/true serializability into the existing isolation levels for compatibility reasons, and those were always based on the anomaly interpretation. -- Peter Geoghegan
On Wed, Jun 3, 2020 at 4:19 AM Kyle Kingsbury <aphyr@jepsen.io> wrote: > https://github.com/jepsen-io/jepsen/blob/f47eb25ab32529a7b66f1dfdd3b5ef2fc84ed778/stolon/src/jepsen/stolon/append.clj#L31-L108 I'm looking into this, but just by the way, you said: ; OK, so first worrying thing: why can this throw duplicate key errors if ; it's executed with "if not exists"? (try (j/execute! conn [(str "create table if not exists " (table-name i) .... That's (unfortunately) a known problem under concurrency. It'd be very nice to fix that, but it's an independent problem relating to DDL (not just tables, and not just IF EXISTS DDL, but anything modifying catalogues can race in this way and miss out on "nice" error messages or the IF EXISTS no-op). Here's a good short summary: https://www.postgresql.org/message-id/CA%2BTgmoZAdYVtwBfp1FL2sMZbiHCWT4UPrzRLNnX1Nb30Ku3-gg%40mail.gmail.com
On Tue, Jun 2, 2020 at 10:24 AM Peter Geoghegan <pg@bowt.ie> wrote: > I'd be surprised if your existing test cases needed any adjustment. My > guess is that this won't take long. You said it takes about a minute in your opening e-mail; how consistent is this? I note from the Postgres logs you provided that Postgres starts accepting connections at 2020-05-31 18:50:27.580, and shows its last log message at 2020-05-31 18:51:29.781 PDT. So it's suspiciously close to *exactly* one minute. Note that autovacuum_naptime has as its default '1min'. Your workload probably generates a lot of index bloat, which may tend to cause autovacuum to want to delete whole B-Tree leaf pages, which impacts predicate locking. Could you check what happens when you reduce autovacuum_naptime to (say) '5s' in postgresql.conf? Does that change make the G2-item cycle issue manifest itself earlier? And can you discern any pattern like that yourself? It seems kind of inconvenient to run Jepsen -- I suppose I could use Docker or something like that, but I don't have experience with it. What do you think is the simplest workflow for somebody that just wants to recreate your result on a Debian system? -- Peter Geoghegan
Kyle Kingsbury wrote:
> SQL 92 says that the difference between repeatable read and serializable is
> *exactly* the prohibition of P3 ("phantom").
You're probably refering to Table-9 in SQL-92, showing
that P3 can happen under Repeatable Read and cannot happen
under Serializable.
But it doesn't say that the *only* difference between RR and Serializable
is avoiding P3. When defining P1, P2, P3, it doesn't explicitly say
that these are the only anomalies that can arise from concurrency.
The PG doc refers to the other cases as "serialization anomalies".
Compared to the manual, https://wiki.postgresql.org/wiki/Serializable
has more in-depth explanations on the specifics of PG serializable
implementation.
Best regards,
--
Daniel Vérité
PostgreSQL-powered mailer: http://www.manitou-mail.org
Twitter: @DanielVerite
> But it doesn't say that the *only* difference between RR and > Serializable is avoiding P3. When defining P1, P2, P3, it doesn't > explicitly say that these are the only anomalies that can arise from > concurrency.
Ah, yes, now I understand. I've been working with Berenson/Adya too long--I've taken their conclusions for granted. You're right: the spec comes awfully close, but doesn't say these are the *only* phenomena possible:
> The following phenomena are possible: [description of P1, P2, and > P3] > The isolation levels are different with respect to phenomena P1, P2, > and P3.
Berenson et al., in "A Critique of ANSI SQL Isolation Levels", identified this as a key challenge in interpreting the spec:
> The isolation levels are defined by the phenomena they are forbidden > to experience.
But also:
> The prominence of the table compared to this extra proviso leads to > a common misconception that disallowing the three phenomena implies > serializability.
Which led Berenson et al. to claim that the SQL spec's definitions are a.) ambiguous and b.) incomplete. They argue that the "strict" (or, in Adya, the "anomaly") interpretation is incorrect, and construct a "broad" (Adya: "preventative") interpretation in terms of a new phenomenon (P0: dirty writes), and more general forms of P1, P2, and P3. The bulk of section 3 demonstrates that the anomaly interpretations lead to weird results, and that what the ANSI spec *intended* was the preventative interpretations.
> Strict interpretations A1, A2, and A3 have unintended weaknesses. > The correct interpretations are the Broad ones. We assume in what > follows that ANSI meant to define P1, P2, and P3.
For a more concise overview of this, see Adya's thesis, section 2.3. Adya goes on to show that the preventative interpretation forbids some serializable histories, and redefines the ANSI levels again in terms of generalized, MVCC-friendly phenomena G0, G1, and G2. When I say Postgres violates repeatable read, I mean in the sense that it allows G2-item, which is prevented by Adya PL-2.99: repeatable read. See Adya 3.2.4 for his formulation of repeatable read, which *does* differ from serializability only in terms of predicate-related phenomena.
http://pmg.csail.mit.edu/papers/adya-phd.pdf
For a compact version of this argument and formalism, see Adya, Liskov, & O'Neil's "Generalized Isolation Level Definitions": http://bnrg.cs.berkeley.edu/~adj/cs262/papers/icde00.pdf.
That's why I was asking a few days ago whether Postgres had adopted the anomaly interpretation--Since Postgres implements SI, it made sense that y'all would have followed Berenson et al. in using the preventative interpretation, or Adya in using generalized definitions. But... in the Postgres docs, and your comments in this thread, it seems like y'all are going with the anomaly interpretation instead. That'd explain why there's this extra "serialization anomaly" difference between RR and serializable. That'd also explain why the Postgres docs imply RR << SI, even though Berenson et al. and Adya both say RR >><< SI.
Is... that the right way to understand things?
--Kyle
On 6/2/20 7:17 PM, Peter Geoghegan wrote: > On Tue, Jun 2, 2020 at 10:24 AM Peter Geoghegan <pg@bowt.ie> wrote: >> I'd be surprised if your existing test cases needed any adjustment. My >> guess is that this won't take long. > You said it takes about a minute in your opening e-mail; how > consistent is this? I note from the Postgres logs you provided that > Postgres starts accepting connections at 2020-05-31 18:50:27.580, and > shows its last log message at 2020-05-31 18:51:29.781 PDT. So it's > suspiciously close to *exactly* one minute. I set the test duration to 60 seconds for those runs, but it'll break in as little as 10. That's less of a sure thing though. :) > Note that > autovacuum_naptime has as its default '1min'. Your workload probably > generates a lot of index bloat, which may tend to cause autovacuum to > want to delete whole B-Tree leaf pages, which impacts predicate > locking. With the default (debian) postgresql.conf, which has autovacuum_naptime commented out (default 1min), I see anomalies at (just picking a random recent test) 8.16 seconds, 9.76 seconds, and 19.6 seconds. Another run: 28.0 seconds, 32.3 seconds. > Could you check what happens when you reduce autovacuum_naptime to > (say) '5s' in postgresql.conf? Does that change make the G2-item cycle > issue manifest itself earlier? And can you discern any pattern like > that yourself? It doesn't look like setting autovacuum_naptime makes a difference. > It seems kind of inconvenient to run Jepsen -- I suppose I could use > Docker or something like that, but I don't have experience with it. > What do you think is the simplest workflow for somebody that just > wants to recreate your result on a Debian system? I am really sorry about that--I know it's not convenient. Jepsen's built for testing whole distributed systems, and is probably a bit overkill for testing a single Postgres process. I don't have any experience with Docker, but I think Docker Compose might be a good option for a single-node system? I apologize--I *just* started writing this test against Debian Buster a few days ago, and the existing AWS Marketplace and Docker Compose environments are still on Stretch, so on top of setting up a Jepsen environment you also gotta do a Debian upgrade. :'-O I'll see about writing a version of the test that doesn't use any of the automation, so you can point it at a local postgres instance. Then all you'll need is lein and a jdk. --Kyle
On 6/2/20 7:13 PM, Thomas Munro wrote: > That's (unfortunately) a known problem under concurrency. It'd be > very nice to fix that, but it's an independent problem relating to DDL > (not just tables, and not just IF EXISTS DDL, but anything modifying > catalogues can race in this way and miss out on "nice" error messages > or the IF EXISTS no-op). Here's a good short summary: Ah, yes, this does explain it, thank you! I was a bit concerned, because I know Postgres has a reputation for having transactional DDL. I guess this part of the API isn't. :) --Kyle
> On 6/2/20 7:17 PM, Peter Geoghegan wrote: >> It seems kind of inconvenient to run Jepsen -- I suppose I could >> use Docker or something like that, but I don't have experience >> with it. What do you think is the simplest workflow for somebody >> that just wants to recreate your result on a Debian system? > > I'll see about writing a version of the test that doesn't use any of > the automation, so you can point it at a local postgres instance. > Then all you'll need is lein and a jdk.
OK, I think we're all set. With Jepsen 0ec25ec3, you should be able to run:
cd stolon;
lein run test-all -w append --max-writes-per-key 4 --concurrency 50 -r 500 --isolation serializable --time-limit 60 --nemesis none --existing-postgres --node localhost --no-ssh --postgres-user jepsen --postgres-password pw
... and it'll connect to an already-running instance of Postgres on localhost (or whatever you want to connect to) using the provided username and password. It expects a DB with the same name as the user. You'll need a JDK (1.8 or higher), and Leiningen (https://leiningen.org/), which should be pretty easy to install. :)
> Could you test Postgres 9.5? It would be nice to determine if this > is a new issue, or a regression.
I can also confirm that Postgres 9.5.22, 10.13, and 11.8 all exhibit the same G2-item anomalies as 12.3. It looks like this issue has been here a while! (Either that, or... my transactions are malformed?).
Is there additional debugging data I can get you that'd be helpful? Or if you'd like, I can hop in an IRC or whatever kind of chat/video session you'd like to help you get these Jepsen tests running.
--Kyle
Hi Kyle, On Wed, Jun 3, 2020 at 9:44 AM Kyle Kingsbury <aphyr@jepsen.io> wrote: > OK, I think we're all set. With Jepsen 0ec25ec3, you should be able to run: > > cd stolon; > > lein run test-all -w append --max-writes-per-key 4 --concurrency 50 -r 500 --isolation serializable --time-limit 60 --nemesisnone --existing-postgres --node localhost --no-ssh --postgres-user jepsen --postgres-password pw I can almost get this to work now. Thank you for accommodating me here. I still see this on Postgres 13: ***SNIP*** NFO [2020-06-03 13:00:07,120] jepsen worker 2 - jepsen.util 2 :invoke :txn [[:r 8338 nil]] INFO [2020-06-03 13:00:07,120] jepsen worker 2 - jepsen.util 2 :ok :txn [[:r 8338 [1 2]]] INFO [2020-06-03 13:00:07,123] jepsen worker 44 - jepsen.util 44 :invoke :txn [[:r 8337 nil] [:r 8336 nil]] INFO [2020-06-03 13:00:07,125] jepsen worker 44 - jepsen.util 44 :ok :txn [[:r 8337 [1 2 3]] [:r 8336 [1]]] INFO [2020-06-03 13:00:07,150] jepsen test runner - jepsen.core Run complete, writing INFO [2020-06-03 13:00:08,056] jepsen test runner - jepsen.core Analyzing... INFO [2020-06-03 13:00:13,670] clojure-agent-send-off-pool-46 - elle.txn Timing out search for :G2-item in SCC of 346 transactions INFO [2020-06-03 13:00:17,626] clojure-agent-send-off-pool-46 - elle.txn Timing out search for :G1c in SCC of 3123 transactions INFO [2020-06-03 13:00:18,841] clojure-agent-send-off-pool-46 - elle.txn Timing out search for :G-single in SCC of 685 transactions INFO [2020-06-03 13:00:20,614] clojure-agent-send-off-pool-46 - elle.txn Timing out search for :G-single-process in SCC of 1505 transactions INFO [2020-06-03 13:00:24,151] clojure-agent-send-off-pool-46 - elle.txn Timing out search for :G-single-process in SCC of 756 transactions INFO [2020-06-03 13:00:26,004] clojure-agent-send-off-pool-46 - elle.txn Timing out search for :G-single-process in SCC of 289 transactions INFO [2020-06-03 13:00:27,113] clojure-agent-send-off-pool-46 - elle.txn Timing out search for :G-single in SCC of 767 transactions INFO [2020-06-03 13:00:29,679] clojure-agent-send-off-pool-46 - elle.txn Timing out search for :G1c-realtime in SCC of 383 transactions INFO [2020-06-03 13:00:30,954] clojure-agent-send-off-pool-46 - elle.txn Timing out search for :G-nonadjacent in SCC of 152 transactions INFO [2020-06-03 13:00:34,478] clojure-agent-send-off-pool-22 - elle.viz Skipping plot of 78703 bytes INFO [2020-06-03 13:00:34,484] clojure-agent-send-off-pool-27 - elle.viz Skipping plot of 96697 bytes INFO [2020-06-03 13:00:34,650] clojure-agent-send-off-pool-45 - elle.viz Skipping plot of 97250 bytes INFO [2020-06-03 13:00:35,847] clojure-agent-send-off-pool-42 - elle.viz Skipping plot of 145419 bytes INFO [2020-06-03 13:00:35,882] clojure-agent-send-off-pool-22 - elle.viz Skipping plot of 197214 bytes INFO [2020-06-03 13:00:35,996] clojure-agent-send-off-pool-39 - elle.viz Skipping plot of 409386 bytes INFO [2020-06-03 13:00:36,166] clojure-agent-send-off-pool-52 - elle.viz Skipping plot of 894916 bytes INFO [2020-06-03 13:00:36,428] clojure-agent-send-off-pool-26 - elle.viz Skipping plot of 427866 bytes INFO [2020-06-03 13:00:36,735] clojure-agent-send-off-pool-68 - elle.viz Skipping plot of 137646 bytes INFO [2020-06-03 13:00:37,698] clojure-agent-send-off-pool-31 - elle.viz Skipping plot of 205089 bytes INFO [2020-06-03 13:00:38,251] clojure-agent-send-off-pool-31 - elle.viz Skipping plot of 81743 bytes INFO [2020-06-03 13:00:38,341] clojure-agent-send-off-pool-60 - elle.viz Skipping plot of 222988 bytes INFO [2020-06-03 13:00:38,998] clojure-agent-send-off-pool-83 - elle.viz Skipping plot of 104619 bytes INFO [2020-06-03 13:00:39,048] clojure-agent-send-off-pool-56 - elle.viz Skipping plot of 191453 bytes INFO [2020-06-03 13:00:40,142] clojure-agent-send-off-pool-20 - elle.viz Skipping plot of 85355 bytes INFO [2020-06-03 13:00:44,027] jepsen test runner - jepsen.core Analysis complete INFO [2020-06-03 13:03:04,832] jepsen results - jepsen.store Wrote /home/pg/code/jepsen/stolon/store/stolon append S (S) /20200603T125906.000-0700/results.edn WARN [2020-06-03 13:03:04,836] main - jepsen.core Test crashed! java.util.concurrent.ExecutionException: java.lang.AssertionError: Assert failed: No transaction wrote 8119 1 t2 at java.base/java.util.concurrent.FutureTask.report(FutureTask.java:122) at java.base/java.util.concurrent.FutureTask.get(FutureTask.java:191) at clojure.core$deref_future.invokeStatic(core.clj:2300) at clojure.core$future_call$reify__8439.deref(core.clj:6974) at clojure.core$deref.invokeStatic(core.clj:2320) at clojure.core$deref.invoke(core.clj:2306) ***SNIP*** > Or if you'd like, I can hop in an IRC or whatever kind of chat/video session you'd like to help you get these Jepsen testsrunning. It would probably be easier to discuss this over chat or something. I'll provide details off-list. Thanks -- Peter Geoghegan
On Wed, Jun 3, 2020 at 1:08 PM Peter Geoghegan <pg@bowt.ie> wrote:
> I can almost get this to work now. Thank you for accommodating me here.
Actually, I think that this was a simple error on my part. The
Jepsen/Elle test recipe that Kyle provided now works locally for me.
The tests actually pass, too -- at least against Postgres 13.
I don't know why Kyle doesn't see the same result. I acknowledge that
there is likely a bug here that I have yet to reproduce. My guess is
that it has something to do with the configuration -- though I need to
test earlier Postgres versions, too (Postgres 12 is what Kyle worked
against). I'm using a tuned postgresql.conf, whereas Kyle probably
didn't change many of the defaults.
Here is what I got just now:
pg@bat:~/code/jepsen/stolon$ lein run test-all -w append
--max-writes-per-key 4 --concurrency 50 -r 500 --isolation
serializable --time-limit 60 --nemesis none --existing-postgres --node
localhost --no-ssh --postgres-user jepsen --postgres-password pw
*** SNIP ***
INFO [2020-06-03 14:09:47,978] jepsen worker 33 - jepsen.stolon.append
:insert [#:next.jdbc{:update-count 1}]
INFO [2020-06-03 14:09:47,979] jepsen worker 33 - jepsen.util 133 :ok
:txn [[:r 8408 nil] [:append 8369 1] [:r 8402 [1 2 3]]]
INFO [2020-06-03 14:09:47,980] jepsen worker 15 - jepsen.util 115
:invoke :txn [[:append 8412 3]]
INFO [2020-06-03 14:09:47,981] jepsen worker 15 - jepsen.stolon.append
:update #:next.jdbc{:update-count 1}
INFO [2020-06-03 14:09:47,981] jepsen worker 15 - jepsen.util 115 :ok
:txn [[:append 8412 3]]
INFO [2020-06-03 14:09:48,012] jepsen test runner - jepsen.core Run
complete, writing
INFO [2020-06-03 14:09:48,912] jepsen test runner - jepsen.core Analyzing...
INFO [2020-06-03 14:09:51,415] jepsen test runner - jepsen.core
Analysis complete
INFO [2020-06-03 14:09:51,439] jepsen results - jepsen.store Wrote
/home/pg/code/jepsen/stolon/store/stolon append S (S)
/20200603T140847.000-0700/results.edn
INFO [2020-06-03 14:09:52,245] jepsen test runner - jepsen.core {:perf
{:latency-graph {:valid? true},
:rate-graph {:valid? true},
:valid? true},
:clock {:valid? true},
:stats
{:valid? true,
:count 30096,
:ok-count 27050,
:fail-count 2992,
:info-count 54,
:by-f
{:txn
{:valid? true,
:count 30096,
:ok-count 27050,
:fail-count 2992,
:info-count 54}}},
:exceptions {:valid? true},
:workload {:valid? true},
:valid? true}
Everything looks good! ヽ(‘ー`)ノ
# Successful tests
store/stolon append S (S) /20200603T140847.000-0700
1 successes
0 unknown
0 crashed
0 failures
--
Peter Geoghegan
On Wed, Jun 3, 2020 at 1:08 PM Peter Geoghegan <pg@bowt.ie> wrote:
> I can almost get this to work now. Thank you for accommodating me here.
Actually, I think that this was a simple error on my part. The
Jepsen/Elle test recipe that Kyle provided now works locally for me.
The tests actually pass, too -- at least against Postgres 13.
I don't know why Kyle doesn't see the same result. I acknowledge that
there is likely a bug here that I have yet to reproduce. My guess is
that it has something to do with the configuration -- though I need to
test earlier Postgres versions, too (Postgres 12 is what Kyle worked
against). I'm using a tuned postgresql.conf, whereas Kyle probably
didn't change many of the defaults.
Here is what I got just now:
pg@bat:~/code/jepsen/stolon$ lein run test-all -w append
--max-writes-per-key 4 --concurrency 50 -r 500 --isolation
serializable --time-limit 60 --nemesis none --existing-postgres --node
localhost --no-ssh --postgres-user jepsen --postgres-password pw
*** SNIP ***
INFO [2020-06-03 14:09:47,978] jepsen worker 33 - jepsen.stolon.append
:insert [#:next.jdbc{:update-count 1}]
INFO [2020-06-03 14:09:47,979] jepsen worker 33 - jepsen.util 133 :ok
:txn [[:r 8408 nil] [:append 8369 1] [:r 8402 [1 2 3]]]
INFO [2020-06-03 14:09:47,980] jepsen worker 15 - jepsen.util 115
:invoke :txn [[:append 8412 3]]
INFO [2020-06-03 14:09:47,981] jepsen worker 15 - jepsen.stolon.append
:update #:next.jdbc{:update-count 1}
INFO [2020-06-03 14:09:47,981] jepsen worker 15 - jepsen.util 115 :ok
:txn [[:append 8412 3]]
INFO [2020-06-03 14:09:48,012] jepsen test runner - jepsen.core Run
complete, writing
INFO [2020-06-03 14:09:48,912] jepsen test runner - jepsen.core Analyzing...
INFO [2020-06-03 14:09:51,415] jepsen test runner - jepsen.core
Analysis complete
INFO [2020-06-03 14:09:51,439] jepsen results - jepsen.store Wrote
/home/pg/code/jepsen/stolon/store/stolon append S (S)
/20200603T140847.000-0700/results.edn
INFO [2020-06-03 14:09:52,245] jepsen test runner - jepsen.core {:perf
{:latency-graph {:valid? true},
:rate-graph {:valid? true},
:valid? true},
:clock {:valid? true},
:stats
{:valid? true,
:count 30096,
:ok-count 27050,
:fail-count 2992,
:info-count 54,
:by-f
{:txn
{:valid? true,
:count 30096,
:ok-count 27050,
:fail-count 2992,
:info-count 54}}},
:exceptions {:valid? true},
:workload {:valid? true},
:valid? true}
Everything looks good! ヽ(‘ー`)ノ
# Successful tests
store/stolon append S (S) /20200603T140847.000-0700
1 successes
0 unknown
0 crashed
0 failures
--
Peter Geoghegan
On Wed, Jun 3, 2020 at 2:35 PM Kyle Kingsbury <aphyr@jepsen.io> wrote: > It looks like you're seeing a much higher txn success rate than I am--possibly due to your tuning? Might be worth adjusting--rate and/or --concurrency upwards I can see what I assume is the same problem (a failure/table flip and a huge graph) with "--concurrency 150 -r 10000", and with autovacuum disabled on the Postgres side (this is the same relatively tuned Postgres configuration that I used when Jepsen passed for me). It's difficult to run the tests, so it's hard to isolate without it taking a long time. BTW, the tests are kind of flappy. The Linux OOM killer just killed Java after 20 minutes or so, for example. I assume that this is to be expected with the settings cranked up like this -- the analysis will take longer and use more memory, too. Any tips on limiting that? Is there any reason to think that running the same test twice will affect the outcome of the second test? I also see this sometimes, even though I thought I fixed it earlier -- it seems to happen at random: Caused by: java.lang.AssertionError: Assert failed: No transaction wrote 8363 2 t2 The fact that Kyle saw such a high number of failed transactions, which are difficult to reproduce here seems to suggest that the issue is related to running out of shared memory for predicate locks and/or bloat (which tends to have the side effect of increasing the need for predicate locks). I continue to suspect that this is related to an edge case with predicate locks. It could be related to running out of predicate locks -- maybe an issue with the lock escalation? That would tend to increase the number of failures by quite a lot. -- Peter Geoghegan
On Wed, Jun 3, 2020 at 2:35 PM Kyle Kingsbury <aphyr@jepsen.io> wrote:
> It looks like you're seeing a much higher txn success rate than I am--possibly due to your tuning? Might be worth adjusting --rate and/or --concurrency upwards
I can see what I assume is the same problem (a failure/table flip and
a huge graph) with "--concurrency 150 -r 10000", and with autovacuum
disabled on the Postgres side (this is the same relatively tuned
Postgres configuration that I used when Jepsen passed for me). It's
difficult to run the tests, so it's hard to isolate without it taking
a long time.
BTW, the tests are kind of flappy. The Linux OOM killer just killed
Java after 20 minutes or so, for example. I assume that this is to be
expected with the settings cranked up like this -- the analysis will
take longer and use more memory, too. Any tips on limiting that? Is
there any reason to think that running the same test twice will affect
the outcome of the second test?
I also see this sometimes, even though I thought I fixed it earlier --
it seems to happen at random:
Caused by: java.lang.AssertionError: Assert failed: No transaction wrote 8363 2
t2
The fact that Kyle saw such a high number of failed transactions,
which are difficult to reproduce here seems to suggest that the issue
is related to running out of shared memory for predicate locks and/or
bloat (which tends to have the side effect of increasing the need for
predicate locks). I continue to suspect that this is related to an
edge case with predicate locks. It could be related to running out of
predicate locks -- maybe an issue with the lock escalation? That would
tend to increase the number of failures by quite a lot.
--
Peter Geoghegan
On Wed, Jun 3, 2020 at 4:26 PM Kyle Kingsbury <aphyr@jepsen.io> wrote:
> Oh this is interesting! I can say that I'm running on a 24-way Xeon with 128gb of ram, so running out of system
memorydoesn't immediately seem like a bottleneck--I'd suspect my config runs slower by dint of disks (older SSD), fs
settings,or maybe postgres tuning (this is with the stock Debian config files).
I can now get it to run fairly consistently, now that I know to
consistently truncate all three tables between runs. It doesn't always
fail, but it fails often enough. And it doesn't seem to matter that my
local Postgres is so much faster, or has fewer failures. For example,
I now see the following failure on Postgres 13:
INFO [2020-06-03 18:26:50,706] jepsen test runner - jepsen.core {:perf
{:latency-graph {:valid? true},
:rate-graph {:valid? true},
:valid? true},
:clock {:valid? true},
:stats
{:valid? true,
:count 30049,
:ok-count 26792,
:fail-count 3200,
:info-count 57,
:by-f
{:txn
{:valid? true,
:count 30049,
:ok-count 26792,
:fail-count 3200,
:info-count 57}}},
:exceptions {:valid? true},
:workload
*** SNIP ***
Kyle: Could you figure out a way of setting "prepareThreshold=0" in
JDBC (i.e. disable prepared statements), please? That would make it a
bit easier to debug.
--
Peter Geoghegan
On Sun, May 31, 2020 at 7:25 PM Kyle Kingsbury <aphyr@jepsen.io> wrote:
> Which typically produces, after about a minute, anomalies like the following:
>
> G2-item #1
> Let:
> T1 = {:type :ok, :f :txn, :value [[:r 7 [1]] [:append 12 1]], :time 95024280,
> :process 5, :index 50}
> T2 = {:type :ok, :f :txn, :value [[:append 7 2] [:r 14 nil] [:append 14 1]
> [:r 12 nil]], :time 98700211, :process 6, :index 70}
>
> Then:
> - T1 < T2, because T1 did not observe T2's append of 2 to 7.
> - However, T2 < T1, because T2 observed the initial (nil) state of 12, which
> T1 created by appending 1: a contradiction!
Is the format of these anomalies documented somewhere? How can I
determine what SQL each transaction generates from these values? It's
not obvious to me which of the three tables (which of txn0, txn1, and
txn2) are affected in each case.
--
Peter Geoghegan
On 6/3/20 10:15 PM, Peter Geoghegan wrote:
> On Sun, May 31, 2020 at 7:25 PM Kyle Kingsbury <aphyr@jepsen.io> wrote:
>> Which typically produces, after about a minute, anomalies like the following:
>>
>> G2-item #1
>> Let:
>> T1 = {:type :ok, :f :txn, :value [[:r 7 [1]] [:append 12 1]], :time 95024280,
>> :process 5, :index 50}
>> T2 = {:type :ok, :f :txn, :value [[:append 7 2] [:r 14 nil] [:append 14 1]
>> [:r 12 nil]], :time 98700211, :process 6, :index 70}
>>
>> Then:
>> - T1 < T2, because T1 did not observe T2's append of 2 to 7.
>> - However, T2 < T1, because T2 observed the initial (nil) state of 12, which
>> T1 created by appending 1: a contradiction!
>>
>> Is the format of these anomalies documented somewhere?
Unfortunately no. This is a plain-text representation emitted by Elle. You'll
also find a corresponding diagram of the cycle in `elle/g2-item/1.svg`, which
might be a bit easier to understand. The transactions themselves ({:type :ok
...}) are EDN (Clojure) data structures representing the completion operations
from Jepsen; you'll also see this format in history.edn.
>> How can I determine what SQL each transaction generates from these values? It's
>> not obvious to me which of the three tables (which of txn0, txn1, and txn2) are affected in each case.
This is a good and obvious question which I don't yet have a good answer for.
Reading the source gives you *some* idea of what SQL's being generated, but
there's some stuff being done by next.jdbc and JDBC itself, so I don't know how
to show you *exactly* what goes over the wire. A terrible way to do this is to
look at the pcap traces in wireshark--you can correlate from the timestamps in
jepsen.log, or search for the transactions which interacted with specific keys.
One option would be to add some sort of tracing thing to the test so that it
records the SQL statements it generates as extra metadata on operations. I can
look into doing that for you later on. :)
--Kyle
On 6/3/20 9:33 PM, Peter Geoghegan wrote:
> On Wed, Jun 3, 2020 at 4:26 PM Kyle Kingsbury <aphyr@jepsen.io> wrote:
>> Oh this is interesting! I can say that I'm running on a 24-way Xeon with 128gb of ram, so running out of system
memorydoesn't immediately seem like a bottleneck--I'd suspect my config runs slower by dint of disks (older SSD), fs
settings,or maybe postgres tuning (this is with the stock Debian config files).
> I can now get it to run fairly consistently, now that I know to
> consistently truncate all three tables between runs.
The test will do that automatically for you now. :)
> It doesn't always
> fail, but it fails often enough.
Hey, that's good!
> And it doesn't seem to matter that my
> local Postgres is so much faster, or has fewer failures. For example,
> I now see the following failure on Postgres 13:
>
> INFO [2020-06-03 18:26:50,706] jepsen test runner - jepsen.core {:perf
> {:latency-graph {:valid? true},
> :rate-graph {:valid? true},
> :valid? true},
> :clock {:valid? true},
> :stats
> {:valid? true,
> :count 30049,
> :ok-count 26792,
> :fail-count 3200,
> :info-count 57,
> :by-f
> {:txn
> {:valid? true,
> :count 30049,
> :ok-count 26792,
> :fail-count 3200,
> :info-count 57}}},
> :exceptions {:valid? true},
> :workload
> *** SNIP ***
Aw shucks, you left out the good part! I'm guessing the workload returned
{:valid? false} here?
> Kyle: Could you figure out a way of setting "prepareThreshold=0" in
> JDBC (i.e. disable prepared statements), please? That would make it a
> bit easier to debug.
Try out 21ae84ed: I added a --prepare-threshold option for you. :)
--Kyle
On Thu, Jun 4, 2020 at 1:35 PM Kyle Kingsbury <aphyr@jepsen.io> wrote: > >> How can I determine what SQL each transaction generates from these values? It's > >> not obvious to me which of the three tables (which of txn0, txn1, and txn2) are affected in each case. > > This is a good and obvious question which I don't yet have a good answer for. > Reading the source gives you *some* idea of what SQL's being generated, but > there's some stuff being done by next.jdbc and JDBC itself, so I don't know how > to show you *exactly* what goes over the wire. A terrible way to do this is to > look at the pcap traces in wireshark--you can correlate from the timestamps in > jepsen.log, or search for the transactions which interacted with specific keys. I'd appreciate it if you could provide this information, so I can be confident I didn't get something wrong. I don't really understand how Elle detects this G2-Item anomaly, nor how it works in general. PostgreSQL doesn't really use 2PL, even to a limited degree (unlike Oracle), so a lot of the definitions from the "Generalized Isolation Level Definitions"/Adya paper are not particularly intuitive to me. That said, I find it easy to understand why the "G2-item: Item Anti-dependency Cycles" example from the paper exhibits behavior that would be wrong for Postgres -- even in repeatable read mode. If Postgres exhibits this anomaly (in repeatable read more or serializable mode), that would be a case of a transaction reading data that isn't visible to its original transaction snapshot. The paper supposes that this could happen when another transaction (the one that updated the sum-of-salaries from the example) committed. Just being able to see the SQL executed by each of the two transactions would be compelling evidence of a serious problem, provided the details are equivalent to the sum-of-salaries example from the paper. > One option would be to add some sort of tracing thing to the test so that it > records the SQL statements it generates as extra metadata on operations. I can > look into doing that for you later on. :) If each Jepsen worker has its own connection for the duration of the test (which I guess must happen already), and each connection specified an informative and unique "application_name", it would be possible to see Jepsen's string from the Postgres logs, next to the SQL text. With prepared statements, you'd see the constants used, though not in all log messages (iirc they don't appear in error messages, but do appear in regular log messages). See: https://www.postgresql.org/docs/current/runtime-config-logging.html#GUC-LOG-LINE-PREFIX If you can't figure out how to get JDBC to accept the application_name you want to provide, then you execute a "set application_name = 'my application name';" SQL statement within each Jepsen worker instead. Do this at the start, I suppose. Whichever approach is easiest and makes sense. You might have something like this in postgresql.conf to see the "application_name" string next to each statement from the log (This will increase the log volume considerably, which should still be manageable): log_line_prefix='%p %a %l' log_statement=all (I also suggest further customizing log_line_prefix in whatever way seems most useful to you.) -- Peter Geoghegan
On 6/4/20 5:29 PM, Peter Geoghegan wrote:
> I'd appreciate it if you could provide this information, so I can be
> confident I didn't get something wrong. I don't really understand how
> Elle detects this G2-Item anomaly, nor how it works in general.
> PostgreSQL doesn't really use 2PL, even to a limited degree (unlike
> Oracle), so a lot of the definitions from the "Generalized Isolation
> Level Definitions"/Adya paper are not particularly intuitive to me.
Hopefully you shouldn't have to think about 2PL, because the generalized
phenomena are defined independently of locking--though I think the paper talks
about 2PL in order to show equivalency to the locking approaches. The gist of
the generalized definitions is about information flow--the anomalies (well, most
of them) correspond to cycles in the dependency graph between transactions. Elle
works (very loosely) by inferring this dependency graph.
I think you've probably read this already, and I know it's a *lot* to throw out
there all at once, but the Elle readme and paper might be helpful here. In
particular, section 2 of the paper ("The Adya Formalism") gives a brief overview
of what these dependencies are, and section 3 gives an intuition for how we can
infer the dependency graph.
https://github.com/jepsen-io/elle
https://github.com/jepsen-io/elle/blob/master/paper/elle.pdf
> That said, I find it easy to understand why the "G2-item: Item
> Anti-dependency Cycles" example from the paper exhibits behavior that
> would be wrong for Postgres -- even in repeatable read mode.
Yeah! My understanding is that this behavior would be incorrect either under
snapshot serializability or repeatable read, at least using the generalized
definitions. It might be OK to do this under repeatable read given the anomaly
interpretation of the ANSI SQL spec; not entirely sure.
> If
> Postgres exhibits this anomaly (in repeatable read more or
> serializable mode), that would be a case of a transaction reading data
> that isn't visible to its original transaction snapshot. The paper
> supposes that this could happen when another transaction (the one that
> updated the sum-of-salaries from the example) committed.
Yes! It's not always this obvious--G2-item encompasses any dependency cycle
between transactions such that at least one dependency involves a transaction
writing state which was not observed by some (ostensibly prior) transaction's
read. We call these "rw dependencies" in the paper, because they involve a read
which must have occurred before a write. Another way to think of G2-item is "A
transaction failed to see something that happened in its logical past".
A special case of G2-item, G-single, is commonly known as read skew. In Elle, we
tag G-single separately, so all the G2-item anomalies reported actually involve
2+ rw dependencies, not just 1+. I haven't seen G-single yet, which is
good--that means Postgres isn't violating SI, just SSI. Or, of course, the test
itself could be broken--maybe the SQL statements themselves are subtly wrong, or
our inference is incorrect.
> If each Jepsen worker has its own connection for the duration of the
> test (which I guess must happen already), and each connection
> specified an informative and unique "application_name", it would be
> possible to see Jepsen's string from the Postgres logs, next to the
> SQL text.
Give Jepsen a138843d a shot!
1553 jepsen process 27 16 LOG: execute <unnamed>: select (val) from txn0 where
sk = $1
1553 jepsen process 27 17 DETAIL: parameters: $1 = '9'
Here, "process 27" is the same as the :process field you'll see in transactions.
I'd like to be able to get a mini log of SQL statements embedded in the
operation itself, so it'd be *right there* in the anomaly explanation, but... I
haven't figured out how to scrape those side effects out of the guts of JDBC yet.
--Kyle
On Thu, Jun 4, 2020 at 3:11 PM Kyle Kingsbury <aphyr@jepsen.io> wrote:
> Give Jepsen a138843d a shot!
Giving it a go now. I'll respond to the rest of your points separately.
FYI, at commit a138843d of Jepsen I can get runs that report roughly
the same G2-item anomaly at the end, but show a warning that flies by
-- not sure if this is new or not:
NFO [2020-06-04 15:39:46,204] jepsen worker 5 - jepsen.stolon.append
not in transaction
INFO [2020-06-04 15:39:46,204] jepsen worker 12 - jepsen.util 62
:invoke :txn [[:r 5184 nil] [:r 5184 nil] [:append 5184 4]]
INFO [2020-06-04 15:39:46,204] jepsen worker 3 - jepsen.stolon.append
txn insert failed: ERROR: duplicate key value violates unique
constraint "txn0_pkey"
Detail: Key (id)=(5184) already exists.
INFO [2020-06-04 15:39:46,205] jepsen worker 5 - jepsen.stolon.append
nil insert failed: ERROR: duplicate key value violates unique
constraint "txn0_pkey"
Detail: Key (id)=(5184) already exists.
INFO [2020-06-04 15:39:46,205] jepsen worker 3 - jepsen.stolon.append
:update #:next.jdbc{:update-count 0}
INFO [2020-06-04 15:39:46,206] jepsen worker 5 - jepsen.stolon.append
:update #:next.jdbc{:update-count 1}
INFO [2020-06-04 15:39:46,206] jepsen worker 5 - jepsen.util 205 :ok
:txn [[:append 5184 3]]
WARN [2020-06-04 15:39:46,206] jepsen worker 3 - jepsen.stolon.append
Caught ex-info
clojure.lang.ExceptionInfo: throw+: {:type
:jepsen.stolon.append/homebrew-upsert-failed, :key 5184, :element 1}
at slingshot.support$stack_trace.invoke(support.clj:201)
at jepsen.stolon.append$mop_BANG_.invokeStatic(append.clj:111)
at jepsen.stolon.append$mop_BANG_.invoke(append.clj:80)
at clojure.core$partial$fn__5828.invoke(core.clj:2638)
at clojure.core$mapv$fn__8430.invoke(core.clj:6912)
at clojure.lang.PersistentVector.reduce(PersistentVector.java:343)
at clojure.core$reduce.invokeStatic(core.clj:6827)
at clojure.core$mapv.invokeStatic(core.clj:6903)
at clojure.core$mapv.invoke(core.clj:6903)
at jepsen.stolon.append.Client$fn__1987.invoke(append.clj:173)
at next.jdbc.transaction$transact_STAR_.invokeStatic(transaction.clj:39)
at next.jdbc.transaction$transact_STAR_.invoke(transaction.clj:18)
at next.jdbc.transaction$eval1805$fn__1806.invoke(transaction.clj:86)
at next.jdbc.protocols$eval1057$fn__1058$G__1048__1067.invoke(protocols.clj:57)
at next.jdbc$transact.invokeStatic(jdbc.clj:253)
at next.jdbc$transact.invoke(jdbc.clj:245)
at jepsen.stolon.append.Client.invoke_BANG_(append.clj:171)
at jepsen.client.Validate.invoke_BANG_(client.clj:66)
at jepsen.generator.interpreter.ClientWorker.invoke_BANG_(interpreter.clj:61)
at jepsen.generator.interpreter$spawn_worker$fn__9378$fn__9379.invoke(interpreter.clj:136)
at jepsen.generator.interpreter$spawn_worker$fn__9378.invoke(interpreter.clj:119)
at clojure.core$binding_conveyor_fn$fn__5739.invoke(core.clj:2030)
at clojure.lang.AFn.call(AFn.java:18)
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
at java.base/java.lang.Thread.run(Thread.java:834)
INFO [2020-06-04 15:39:46,207] jepsen worker 3 - jepsen.util 3 :info
:txn [[:r 5182 nil] [:r 5184 nil] [:append 5184 1] [:r 5182 nil]]
[:ex-info "throw+: {:type
:jepsen.stolon.append/homebrew-upsert-failed, :key 5184, :element 1}"]
INFO [2020-06-04 15:39:46,207] jepsen worker 12 - jepsen.util 62 :fail
:txn [[:r 5184 nil] [:r 5184 nil] [:append 5184 4]]
[:could-not-serialize "ERROR: could not serialize access due to
concurrent update"]
INFO [2020-06-04 15:39:46,208] jepsen worker 0 - jepsen.util 50
:invoke :txn [[:r 5185 nil]]
Is this expected? Does this matter?
--
Peter Geoghegan
On Thu, Jun 4, 2020 at 3:11 PM Kyle Kingsbury <aphyr@jepsen.io> wrote:
> Give Jepsen a138843d a shot!
Giving it a go now. I'll respond to the rest of your points separately.
FYI, at commit a138843d of Jepsen I can get runs that report roughly
the same G2-item anomaly at the end, but show a warning that flies by
-- not sure if this is new or not:
NFO [2020-06-04 15:39:46,204] jepsen worker 5 - jepsen.stolon.append
not in transaction
INFO [2020-06-04 15:39:46,204] jepsen worker 12 - jepsen.util 62
:invoke :txn [[:r 5184 nil] [:r 5184 nil] [:append 5184 4]]
INFO [2020-06-04 15:39:46,204] jepsen worker 3 - jepsen.stolon.append
txn insert failed: ERROR: duplicate key value violates unique
constraint "txn0_pkey"
Detail: Key (id)=(5184) already exists.
INFO [2020-06-04 15:39:46,205] jepsen worker 5 - jepsen.stolon.append
nil insert failed: ERROR: duplicate key value violates unique
constraint "txn0_pkey"
Detail: Key (id)=(5184) already exists.
INFO [2020-06-04 15:39:46,205] jepsen worker 3 - jepsen.stolon.append
:update #:next.jdbc{:update-count 0}
INFO [2020-06-04 15:39:46,206] jepsen worker 5 - jepsen.stolon.append
:update #:next.jdbc{:update-count 1}
INFO [2020-06-04 15:39:46,206] jepsen worker 5 - jepsen.util 205 :ok
:txn [[:append 5184 3]]
WARN [2020-06-04 15:39:46,206] jepsen worker 3 - jepsen.stolon.append
Caught ex-info
clojure.lang.ExceptionInfo: throw+: {:type
:jepsen.stolon.append/homebrew-upsert-failed, :key 5184, :element 1}
at slingshot.support$stack_trace.invoke(support.clj:201)
at jepsen.stolon.append$mop_BANG_.invokeStatic(append.clj:111)
at jepsen.stolon.append$mop_BANG_.invoke(append.clj:80)
at clojure.core$partial$fn__5828.invoke(core.clj:2638)
at clojure.core$mapv$fn__8430.invoke(core.clj:6912)
at clojure.lang.PersistentVector.reduce(PersistentVector.java:343)
at clojure.core$reduce.invokeStatic(core.clj:6827)
at clojure.core$mapv.invokeStatic(core.clj:6903)
at clojure.core$mapv.invoke(core.clj:6903)
at jepsen.stolon.append.Client$fn__1987.invoke(append.clj:173)
at next.jdbc.transaction$transact_STAR_.invokeStatic(transaction.clj:39)
at next.jdbc.transaction$transact_STAR_.invoke(transaction.clj:18)
at next.jdbc.transaction$eval1805$fn__1806.invoke(transaction.clj:86)
at next.jdbc.protocols$eval1057$fn__1058$G__1048__1067.invoke(protocols.clj:57)
at next.jdbc$transact.invokeStatic(jdbc.clj:253)
at next.jdbc$transact.invoke(jdbc.clj:245)
at jepsen.stolon.append.Client.invoke_BANG_(append.clj:171)
at jepsen.client.Validate.invoke_BANG_(client.clj:66)
at jepsen.generator.interpreter.ClientWorker.invoke_BANG_(interpreter.clj:61)
at jepsen.generator.interpreter$spawn_worker$fn__9378$fn__9379.invoke(interpreter.clj:136)
at jepsen.generator.interpreter$spawn_worker$fn__9378.invoke(interpreter.clj:119)
at clojure.core$binding_conveyor_fn$fn__5739.invoke(core.clj:2030)
at clojure.lang.AFn.call(AFn.java:18)
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
at java.base/java.lang.Thread.run(Thread.java:834)
INFO [2020-06-04 15:39:46,207] jepsen worker 3 - jepsen.util 3 :info
:txn [[:r 5182 nil] [:r 5184 nil] [:append 5184 1] [:r 5182 nil]]
[:ex-info "throw+: {:type
:jepsen.stolon.append/homebrew-upsert-failed, :key 5184, :element 1}"]
INFO [2020-06-04 15:39:46,207] jepsen worker 12 - jepsen.util 62 :fail
:txn [[:r 5184 nil] [:r 5184 nil] [:append 5184 4]]
[:could-not-serialize "ERROR: could not serialize access due to
concurrent update"]
INFO [2020-06-04 15:39:46,208] jepsen worker 0 - jepsen.util 50
:invoke :txn [[:r 5185 nil]]
Is this expected? Does this matter?
--
Peter Geoghegan
On Thu, Jun 4, 2020 at 3:52 PM Kyle Kingsbury <aphyr@jepsen.io> wrote: > Naw, that's ok. :homebrew-upsert-failed is just letting you know that we couldn't do the update-insert-update dance. Shouldn'tbe any safety impact. :-) I also notice some deadlocks when inserting -- not duplicate violations: 1591311225.473 170332 1197463 INSERT waiting 5ed97b3c.2995c jepsen process 25 LOG: process 170332 still waiting for ShareLock on transaction 1197460 after 1000.091 ms 1591311225.473 170332 1197463 INSERT waiting 5ed97b3c.2995c jepsen process 25 DETAIL: Process holding the lock: 170418. Wait queue: 170332, 170450, 170478. 1591311225.473 170332 1197463 INSERT waiting 5ed97b3c.2995c jepsen process 25 CONTEXT: while inserting index tuple (3,176) in relation "txn0_pkey" 1591311225.474 170450 1197458 INSERT waiting 5ed97b5b.299d2 jepsen process 55 LOG: process 170450 detected deadlock while waiting for ShareLock on transaction 1197460 after 1000.086 ms 1591311225.474 170450 1197458 INSERT waiting 5ed97b5b.299d2 jepsen process 55 DETAIL: Process holding the lock: 170418. Wait queue: 170332, 170478. 1591311225.474 170450 1197458 INSERT waiting 5ed97b5b.299d2 jepsen process 55 CONTEXT: while inserting index tuple (5,279) in relation "txn0_pkey" Are they expected? -- Peter Geoghegan
On Thu, Jun 4, 2020 at 3:11 PM Kyle Kingsbury <aphyr@jepsen.io> wrote: > Yes! It's not always this obvious--G2-item encompasses any dependency cycle > between transactions such that at least one dependency involves a transaction > writing state which was not observed by some (ostensibly prior) transaction's > read. We call these "rw dependencies" in the paper, because they involve a read > which must have occurred before a write. Another way to think of G2-item is "A > transaction failed to see something that happened in its logical past". Are you familiar with the paper "Serializable Snapshot Isolation in PostgreSQL"? You might find it helpful: http://vldb.org/pvldb/vol5/p1850_danrkports_vldb2012.pdf Is there a difference between "rw dependencies" as you understand the term, and what the paper calls "rw-antidependencies"? > A special case of G2-item, G-single, is commonly known as read skew. In Elle, we > tag G-single separately, so all the G2-item anomalies reported actually involve > 2+ rw dependencies, not just 1+. I haven't seen G-single yet, which is > good--that means Postgres isn't violating SI, just SSI. Or, of course, the test > itself could be broken--maybe the SQL statements themselves are subtly wrong, or > our inference is incorrect. I'm glad that you don't suspect snapshot isolation has been violated. Frankly I'd be astonished if Postgres is found to be violating SI here. Anything is possible, but if that happened then it would almost certainly be far more obvious. The way MVCC works in Postgres is relatively simple. If an xact in repeatable read mode really did return a row that wasn't visible to its snapshot, then it's probably just as likely to return two row versions for the same logical row, or zero row versions. These are symptoms of various types of data corruption that we see from time to time. Note, in particular, that violating SI cannot happen because a transaction released a lock in an index when it shouldn't have -- because we simply don't have those. (Actually, we do have something called predicate locks, but those are not at all like 2PL index value locks -- see the paper I linked to for more.) > Give Jepsen a138843d a shot! > > 1553 jepsen process 27 16 LOG: execute <unnamed>: select (val) from txn0 where > sk = $1 > > 1553 jepsen process 27 17 DETAIL: parameters: $1 = '9' Attached is: * A Jepsen failure of the kind we've been talking about * Log output from Postgres that shows all log lines with the relevant-to-failure Jepsen worker numbers, as discussed. This is interleaved based on timestamp order. Can you explain the anomaly with reference to the actual SQL queries executed in the log? Is the information that I've provided sufficient? -- Peter Geoghegan
Вложения
On Thu, Jun 4, 2020 at 5:20 PM Peter Geoghegan <pg@bowt.ie> wrote: > On Thu, Jun 4, 2020 at 3:11 PM Kyle Kingsbury <aphyr@jepsen.io> wrote: > > Yes! It's not always this obvious--G2-item encompasses any dependency cycle > > between transactions such that at least one dependency involves a transaction > > writing state which was not observed by some (ostensibly prior) transaction's > > read. We call these "rw dependencies" in the paper, because they involve a read > > which must have occurred before a write. Another way to think of G2-item is "A > > transaction failed to see something that happened in its logical past". > > Are you familiar with the paper "Serializable Snapshot Isolation in > PostgreSQL"? You might find it helpful: > > http://vldb.org/pvldb/vol5/p1850_danrkports_vldb2012.pdf > > Is there a difference between "rw dependencies" as you understand the > term, and what the paper calls "rw-antidependencies"? "3.2 Serializability Theory" has some stuff about Adya et al, but also talks about the work of Fekete et al -- apparently they built on the Adya paper (both papers share one author). Are you familiar with the Fekete paper? -- Peter Geoghegan
On 6/4/20 10:03 PM, Peter Geoghegan wrote: >> Are you familiar with the paper "Serializable Snapshot Isolation in >> PostgreSQL"? You might find it helpful: >> >> http://vldb.org/pvldb/vol5/p1850_danrkports_vldb2012.pdf It's been several years since I've read it, and it's worth revisiting. Thanks for the recommendation! Yes, I think a good way to understand Elle's G2-item is that it might be (and I'm not entirely sure about this--this was only a cursory read last night) one of the "dangerous structures" in the Postgres SSI paper. I elided this earlier to try and keep things simple, but we actually separate out cycles featuring *nonadjacent* rw edges and consider them a separate sort of anomaly in Elle, so we can distinguish between snapshot isolation and serializability more precisely. >> Is there a difference between "rw dependencies" as you understand the >> term, and what the paper calls "rw-antidependencies"? Yes, my apologies. "anti-dependency" = "rw-antidependency" = "rw dependency" = "T1 read state x1, and T2 installed state x2, such that x1 immediately precedes x2". >> "3.2 Serializability Theory" has some stuff about Adya et al, but also >> talks about the work of Fekete et al -- apparently they built on the >> Adya paper (both papers share one author). Are you familiar with the >> Fekete paper? Yes! Some of Elle's inferences are based in part on Fekete et al.'s work, and we've corresponded some during Elle's development. :) ---Kyle
On 6/4/20 8:20 PM, Peter Geoghegan wrote:
> Can you explain the anomaly with reference to the actual SQL queries
> executed in the log? Is the information that I've provided sufficient?
Elle automatically explains these anomalies, so it might be easier to interpret
with the visualization and/or interpretation of the anomaly--you'll find those
in store/latest/elle/. Looking at the data structure representation of the
anomaly, here's what I see in jepsen-failure-2.txt. I'm looking at the first
(and only) anomaly in :workload/:anomalies/:G2-item.
{:cycle
[{:type :ok,
:f :txn,
:value
[[:r 100 nil] [:append 101 1] [:r 101 [1]] [:r 96 [1 2]]],
:time 750303448,
:process 23,
:index 727}
{:type :ok,
:f :txn,
:value [[:append 100 1] [:r 99 nil] [:r 101 nil] [:append 4 4]],
:time 751922048,
:process 5,
:index 729}
{:type :ok,
:f :txn,
:value
[[:r 100 nil] [:append 101 1] [:r 101 [1]] [:r 96 [1 2]]],
:time 750303448,
:process 23,
:index 727}],
:steps
({:type :rw,
:key 100,
:value :elle.list-append/init,
:value' 1,
:a-mop-index 0,
:b-mop-index 0}
{:type :rw,
:key 101,
:value :elle.list-append/init,
:value' 1,
:a-mop-index 2,
:b-mop-index 1}),
:type :G2-item}
We have a cycle involving two transactions (:cycle)--the first transaction is
shown at the end as well to make it easier to see that it closes the loop. Let's
call them T1 (:index 727) and T2 (index :729). The first step (:steps) is an
anti-dependency: T1 read key 100 and observed the initial state ([:r 100 nil]),
but T2 appended 1 to 100, so we know T1 < T2. The second step is also an
anti-dependency: T2 read key 101 and observed the initial state ([:r 101 nil]).
Both of these transactions completed successfully (:type :ok), which means we
have two committed transactions, both of which failed to observe the other's
writes. These can't be serializable, because if we choose T1 < T2, T2 fails to
observe a write that T1 performed, and if we choose T2 < T1, T1 fails to observe
a write that T2 performed. You'll probably see something similar to this
explanation in store/latest/elle/G2-item.txt, and a corresponding diagram in
store/latest/elle/G2-item/0.svg.
Elle infers, from the presence of G2-item, that this history cannot satisfy
repeatable read (:not #{:repeatable-read}). By extension, it knows (:also-not)
that it can't be serializable, strict serializable, or strong session
serializable either.
Now, to the SQL. T1 was performed by process 23, and T2 by process 5--you've
helpfully restricted the postgres logs to just those two processes, so you're
one step ahead of me. I searched for $1 = '100' to find the read of key 100 from
process 23:
1591312493.044 171762 0 BEGIN 5ed9806c.29ef2 jepsen process 23 LOG: execute
<unnamed>: BEGIN
1591312493.044 171762 0 SELECT 5ed9806c.29ef2 jepsen process 23 DETAIL:
parameters: $1 = '100'
1591312493.044 171762 0 SELECT 5ed9806c.29ef2 jepsen process 23 LOG: execute
<unnamed>: select (val) from txn2 where sk = $1
So, process 23 begins a transaction and reads key 100 from table txn2, using the
secondary key `sk`. This is new, BTW--earlier versions of the test did every
operation by primary key; I've been making the test harder over time. That read
returns no rows: [:r 100 nil].
Process 23, at least in this log, goes on to set the session to SERIALIZABLE.
This is a bit weird, because that statement should be executed by JDBC when we
started the transaction, right? Makes me wonder if maybe the log lines are out
of order? Now that I look... these are suspiciously alphabetically ordered. If
you sorted the file, that might explain it. :)
1591312493.044 171762 0 SET 5ed9806c.29ef2 jepsen process 23 LOG: execute
<unnamed>: SET SESSION CHARACTERISTICS AS TRANSACTION ISOLATION LEVEL SERIALIZABLE
1591312493.044 171762 0 SHOW 5ed9806c.29ef2 jepsen process 23 LOG: execute
<unnamed>: SHOW TRANSACTION ISOLATION LEVEL
Next (in this sorted log, but not in reality), process 23 appends 1 to key 101,
in table txn0:
1591312493.045 171762 0 INSERT 5ed9806c.29ef2 jepsen process 23 DETAIL:
parameters: $1 = '101', $2 = '101', $3 = '1'
1591312493.045 171762 0 INSERT 5ed9806c.29ef2 jepsen process 23 LOG: execute
<unnamed>: insert into txn0 (id, sk, val) values ($1, $2, $3)
There should have been an update first, but it got sorted later in this file.
Here's the update--this must have happened first, failed, and caused process 23
to back off to an insert.
1591312493.045 171762 0 SAVEPOINT 5ed9806c.29ef2 jepsen process 23 LOG: execute
<unnamed>: savepoint upsert
1591312493.045 171762 0 UPDATE 5ed9806c.29ef2 jepsen process 23 DETAIL:
parameters: $1 = '1', $2 = '101'
1591312493.045 171762 0 UPDATE 5ed9806c.29ef2 jepsen process 23 LOG: execute
<unnamed>: update txn0 set val = CONCAT(val, ',', $1) where id = $2
Next, process 5 begins its transaction:
1591312493.046 171734 0 BEGIN 5ed9806c.29ed6 jepsen process 5 LOG: execute
<unnamed>: BEGIN
1591312493.046 171734 0 SET 5ed9806c.29ed6 jepsen process 5 LOG: execute
<unnamed>: SET SESSION CHARACTERISTICS AS TRANSACTION ISOLATION LEVEL SERIALIZABLE
1591312493.046 171734 0 SHOW 5ed9806c.29ed6 jepsen process 5 LOG: execute
<unnamed>: SHOW TRANSACTION ISOLATION LEVEL
... and tries to append 1 to key 100 by primary key `id`:
1591312493.046 171734 0 UPDATE 5ed9806c.29ed6 jepsen process 5 DETAIL:
parameters: $1 = '1', $2 = '100'
1591312493.046 171734 0 UPDATE 5ed9806c.29ed6 jepsen process 5 LOG: execute
<unnamed>: update txn2 set val = CONCAT(val, ',', $1) where id = $2
Process 23 goes on to release its upsert savepoint, and perform reads of key 101
and 96, observing [1] and [1 2] respectively, before committing. Again,
out-of-order log due to sorting.
1591312493.046 171762 1197960 COMMIT 5ed9806c.29ef2 jepsen process 23 LOG:
execute <unnamed>: COMMIT
1591312493.046 171762 1197960 RELEASE 5ed9806c.29ef2 jepsen process 23 LOG:
execute <unnamed>: release savepoint upsert
1591312493.046 171762 1197960 SELECT 5ed9806c.29ef2 jepsen process 23 DETAIL:
parameters: $1 = '101'
1591312493.046 171762 1197960 SELECT 5ed9806c.29ef2 jepsen process 23 DETAIL:
parameters: $1 = '96'
1591312493.046 171762 1197960 SELECT 5ed9806c.29ef2 jepsen process 23 LOG:
execute <unnamed>: select (val) from txn0 where id = $1
1591312493.046 171762 1197960 SELECT 5ed9806c.29ef2 jepsen process 23 LOG:
execute <unnamed>: select (val) from txn0 where sk = $1
Process 5's update affects zero rows, so it similarly backs off to an insert
statement:
1591312493.047 171734 0 INSERT 5ed9806c.29ed6 jepsen process 5 DETAIL:
parameters: $1 = '100', $2 = '100', $3 = '1'
1591312493.047 171734 0 INSERT 5ed9806c.29ed6 jepsen process 5 LOG: execute
<unnamed>: insert into txn2 (id, sk, val) values ($1, $2, $3)
1591312493.047 171734 0 SAVEPOINT 5ed9806c.29ed6 jepsen process 5 LOG: execute
<unnamed>: savepoint upsert
1591312493.047 171734 1197963 RELEASE 5ed9806c.29ed6 jepsen process 5 LOG:
execute <unnamed>: release savepoint upsert
... followed by reads of 99 and 101.
1591312493.047 171734 1197963 SELECT 5ed9806c.29ed6 jepsen process 5 DETAIL:
parameters: $1 = '101'
1591312493.047 171734 1197963 SELECT 5ed9806c.29ed6 jepsen process 5 DETAIL:
parameters: $1 = '99'
1591312493.047 171734 1197963 SELECT 5ed9806c.29ed6 jepsen process 5 LOG:
execute <unnamed>: select (val) from txn0 where sk = $1
1591312493.047 171734 1197963 SELECT 5ed9806c.29ed6 jepsen process 5 LOG:
execute <unnamed>: select (val) from txn2 where id = $1
We know the read of 101 observed no rows, which makes sense because process 5
(T2)'s transaction began during process 23's transaction, *before* the commit.
What *doesn't* make sense is...
1591312493.048 171734 1197963 COMMIT 5ed9806c.29ed6 jepsen process 5 LOG:
execute <unnamed>: COMMIT
Process 5 manages to *commit* despite the anti-dependency cycle! That's legal
under SI, but not under serializability.
Phew! I know it's a lot. Does this help?
--Kyle
After staring at a few hundred of these anomalies, I'm more confident: this problem seems to involve a transaction which fails to observe a logically prior transaction's *insert*. So far we never see a cycle involving all updates rw deps--there's always 2+ rw deps, and at least one involves the initial state. Maybe this helps narrow down the search! --Kyle
On Fri, Jun 5, 2020 at 10:00 AM Kyle Kingsbury <aphyr@jepsen.io> wrote: > After staring at a few hundred of these anomalies, I'm more confident: this > problem seems to involve a transaction which fails to observe a logically prior > transaction's *insert*. So far we never see a cycle involving all updates rw > deps--there's always 2+ rw deps, and at least one involves the initial state. > Maybe this helps narrow down the search! It wouldn't be the first time there was such an anomaly: https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=585e2a3b (You probably vaguely remember this as the bug that people were talking about at Strange loop that same year.) -- Peter Geoghegan
On Fri, Jun 5, 2020 at 6:03 AM Kyle Kingsbury <aphyr@jepsen.io> wrote: > Process 23, at least in this log, goes on to set the session to SERIALIZABLE. > This is a bit weird, because that statement should be executed by JDBC when we > started the transaction, right? Makes me wonder if maybe the log lines are out > of order? Now that I look... these are suspiciously alphabetically ordered. If > you sorted the file, that might explain it. :) I messed that up massively -- sorry. Attached is a revised version of the same thing, which fixes the accidental sorting. Just the relevant area, with the proper order. Note also that this is the log_line_prefix used: log_line_prefix='%n %p %x %i %c %a ' Why is it that process 5 updates the txn1 table at the end, having done insert/update stuff to the txn2 table earlier on in the same xact (or what appears to be the same xact)? Note that that update is the only statement from the entire sequence that affects txn1 (all other statements affect either txn0 or txn2). It's as if the homebrew upsert changed its mind about which table it's supposed to affect. I cannot speak Clojure, so I have to ask. Maybe this just demonstrates that an approach based on reading the logs like this just isn't workable. I think that this original order might still be slightly off, due to the vagaries of stdio with concurrent writes to the log file -- not sure how much that, though. I suspect that I should try a high fidelity way of capturing the original execution order. I'm thinking of something like test_decoding, which will show us a representation in LSN order, which is precisely what we want: https://www.postgresql.org/docs/devel/test-decoding.html -- Peter Geoghegan
Вложения
On Fri, Jun 5, 2020 at 12:43 PM Peter Geoghegan <pg@bowt.ie> wrote: > I suspect that I should try a high fidelity way of capturing the > original execution order. I'm thinking of something like > test_decoding I had a better idea -- use rr debugging recorder to get a recording of an entire execution: https://wiki.postgresql.org/wiki/Getting_a_stack_trace_of_a_running_PostgreSQL_backend_on_Linux/BSD#Recording_Postgres_using_rr_Record_and_Replay_Framework Attached results.edn + G2-item.txt files show the anomalies that were reported during an execution I recorded a little earlier. We can now use this as a point of reference for further debugging. One less obvious benefit of doing this is that rr makes the execution of the entire Postgres instance single threaded, so we can be sure that the log faithfully represents the order of operations during execution, within and across PostgreSQL backends -- no more uncertainty about the exact order, when each xact starts and ends, etc. (Note that I had to use rr's "chaos mode" feature to reproduce the race condition problem in the first place -- it was easy once I remembered about that option.) This useful property is pretty much self-evident from the logs, since rr includes an event number. For example, the log starts like this: [rr 316370 892] 1591388133.699-316370--0--5edaa7e5.4d3d2- LOG: starting PostgreSQL 13beta1-dc on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 9.3.0-10ubuntu2) 9.3.0, 64-bit [rr 316370 1056] 1591388133.706-316370--0--5edaa7e5.4d3d2- LOG: listening on IPv6 address "::1", port 5432 [rr 316370 1068] 1591388133.706-316370--0--5edaa7e5.4d3d2- LOG: listening on IPv4 address "127.0.0.1", port 5432 [rr 316370 1093] 1591388133.707-316370--0--5edaa7e5.4d3d2- LOG: listening on Unix socket "/tmp/.s.PGSQL.5432" [rr 316371 1303] 1591388133.716-316371--0--5edaa7e5.4d3d3- LOG: database system was shut down at 2020-06-05 13:15:18 PDT [rr 316370 1726] 1591388133.735-316370--0--5edaa7e5.4d3d2- LOG: database system is ready to accept connections [rr 316448 4190] 1591388153.592-316448--0--5edaa7f9.4d420-[unknown] LOG: connection received: host=127.0.0.1 port=41078 The second number in each log line represents an rr event number -- notice that these are strictly monotonically increasing. I don't even need a PID to be able to start an interactive debugging session during execution of a query of interest, though -- all I need is an event number (such as 4190) to reliably get an interactive debugging session. Since the entire recorded execution is actually single threaded, and because of Postgres' multi-process architecture, that information alone unambiguously identifies a particular backend/connection and query execution. I also make available the entire log that I showed the start of just now: https://drive.google.com/file/d/1YFTVChfEtzZncdjakXKpp22HKDNFoWKo/view?usp=sharing This hasn't been filtered by me this time around, so anyone playing along at home can look through everything, including the queries pertaining to the two G2-Item issues Jepsen complains about. Hopefully this helps you, Kyle. Would you mind repeating the exercise from earlier with this new log file/execution? Thanks -- Peter Geoghegan
Вложения
On 6/5/20 6:44 PM, Peter Geoghegan wrote:
> Hopefully this helps you, Kyle. Would you mind repeating the exercise
> from earlier with this new log file/execution?
Here's a quick runthrough of G2-item #0:
Let:
T1 = {:type :ok, :f :txn, :value [[:append 1468 3] [:r 1469 nil] [:append
1439 2]], :time 22408795244, :process 49, :index 10392}
T2 = {:type :ok, :f :txn, :value [[:append 1469 1] [:append 1456 2] [:r 1468
nil]], :time 22565885165, :process 45, :index 10464}
Then:
- T1 < T2, because T1 observed the initial (nil) state of 1469, which T2
created by appending 1.
- However, T2 < T1, because T2 observed the initial (nil) state of 1468,
which T1 created by appending 3: a contradiction!
Classic G2: two rw-edges, where each transaction failed to observe the other's
write. I restricted the log to just those processes:
egrep 'process (49|45)' log_rr_recording.log
I jumped to the write of 1468 with /'1468'/, then backtracked to process 45's BEGIN:
[rr 316503 580915] 1591388175.849-316503-5/231-0-SHOW-5edaa7f9.4d457-jepsen
process 45 LOG: execute <unnamed>: SHOW TRANSACTION ISOLATION LEVEL
[rr 316503 581192] 1591388175.858-316503-5/232-0-SET-5edaa7f9.4d457-jepsen
process 45 LOG: execute <unnamed>: SET SESSION CHARACTERISTICS AS TRANSACTION
ISOLATION LEVEL SERIALIZABLE
[rr 316503 581202] 1591388175.858-316503-5/233-0-BEGIN-5edaa7f9.4d457-jepsen
process 45 LOG: execute <unnamed>: BEGIN
45 tries to append 1 to 1469, but fails because it found zero rows:
[rr 316503 581206] 1591388175.859-316503-5/233-0-UPDATE-5edaa7f9.4d457-jepsen
process 45 LOG: execute <unnamed>: update txn2 set val = CONCAT(val, ',', $1)
where id = $2
1591388175.859-316503-5/233-0-UPDATE-5edaa7f9.4d457-jepsen process 45 DETAIL:
parameters: $1 = '1', $2 = '1469'
45 backs off to an insert:
[rr 316503 581222] 1591388175.859-316503-5/233-0-SAVEPOINT-5edaa7f9.4d457-jepsen
process 45 LOG: execute <unnamed>: savepoint upsert
49 jumps in to start a transaction:
[rr 316514 581232] 1591388175.860-316514-13/401-0-SHOW-5edaa7f9.4d462-jepsen
process 49 LOG: execute <unnamed>: SHOW TRANSACTION ISOLATION LEVEL
[rr 316514 581242] 1591388175.860-316514-13/402-0-SET-5edaa7f9.4d462-jepsen
process 49 LOG: execute <unnamed>: SET SESSION CHARACTERISTICS AS TRANSACTION
ISOLATION LEVEL SERIALIZABLE
[rr 316514 581256] 1591388175.860-316514-13/403-0-BEGIN-5edaa7f9.4d462-jepsen
process 49 LOG: execute <unnamed>: BEGIN
49 tries to update 1468, which also fails, and backs off to an insert:
[rr 316514 581350] 1591388175.864-316514-13/403-0-UPDATE-5edaa7f9.4d462-jepsen
process 49 LOG: execute <unnamed>: update txn1 set val = CONCAT(val, ',', $1)
where id = $2
1591388175.864-316514-13/403-0-UPDATE-5edaa7f9.4d462-jepsen process 49
DETAIL: parameters: $1 = '3', $2 = '1468'
[rr 316514 581364]
1591388175.864-316514-13/403-0-SAVEPOINT-5edaa7f9.4d462-jepsen process 49 LOG:
execute <unnamed>: savepoint upsert
[rr 316514 581374] 1591388175.865-316514-13/403-0-INSERT-5edaa7f9.4d462-jepsen
process 49 LOG: execute <unnamed>: insert into txn1 (id, sk, val) values ($1,
$2, $3)
1591388175.865-316514-13/403-0-INSERT-5edaa7f9.4d462-jepsen process 49
DETAIL: parameters: $1 = '1468', $2 = '1468', $3 = '3'
45 performs its insert of 1469:
[rr 316503 581548] 1591388175.871-316503-5/233-0-INSERT-5edaa7f9.4d457-jepsen
process 45 LOG: execute <unnamed>: insert into txn2 (id, sk, val) values ($1,
$2, $3)
1591388175.871-316503-5/233-0-INSERT-5edaa7f9.4d457-jepsen process 45 DETAIL:
parameters: $1 = '1469', $2 = '1469', $3 = '1'
[rr 316503 581562]
1591388175.872-316503-5/233-1680808-RELEASE-5edaa7f9.4d457-jepsen process 45
LOG: execute <unnamed>: release savepoint upsert
And goes on to update 1456, which also fails, so it inserts there too:
[rr 316503 581576]
1591388175.872-316503-5/233-1680808-UPDATE-5edaa7f9.4d457-jepsen process 45
LOG: execute <unnamed>: update txn0 set val = CONCAT(val, ',', $1) where id = $2
1591388175.872-316503-5/233-1680808-UPDATE-5edaa7f9.4d457-jepsen process 45
DETAIL: parameters: $1 = '2', $2 = '1456'
[rr 316503 581980]
1591388175.887-316503-5/233-1680808-SAVEPOINT-5edaa7f9.4d457-jepsen process 45
LOG: execute <unnamed>: savepoint upsert
[rr 316503 581994]
1591388175.887-316503-5/233-1680808-INSERT-5edaa7f9.4d457-jepsen process 45
LOG: execute <unnamed>: insert into txn0 (id, sk, val) values ($1, $2, $3)
1591388175.887-316503-5/233-1680808-INSERT-5edaa7f9.4d457-jepsen process 45
DETAIL: parameters: $1 = '1456', $2 = '1456', $3 = '2'
[rr 316503 582008]
1591388175.888-316503-5/233-1680808-RELEASE-5edaa7f9.4d457-jepsen process 45
LOG: execute <unnamed>: release savepoint upsert
45 reads 1468, observing 0 rows:
[rr 316503 582018]
1591388175.888-316503-5/233-1680808-SELECT-5edaa7f9.4d457-jepsen process 45
LOG: execute <unnamed>: select (val) from txn1 where id = $1
1591388175.888-316503-5/233-1680808-SELECT-5edaa7f9.4d457-jepsen process 45
DETAIL: parameters: $1 = '1468'
And 45 commits:
[rr 316503 582028]
1591388175.888-316503-5/233-1680808-COMMIT-5edaa7f9.4d457-jepsen process 45
LOG: execute <unnamed>: COMMIT
49's insert succeeded, and it goes on to read 1469, finding 0 rows as well. This
should cause the transaction to abort, because 1469 was written by a committed
transaction performed by process 45, *and* 45 didn't observe 49's writes.
[rr 316514 582409]
1591388175.902-316514-13/403-1680806-RELEASE-5edaa7f9.4d462-jepsen process 49
LOG: execute <unnamed>: release savepoint upsert
[rr 316514 582419]
1591388175.902-316514-13/403-1680806-SELECT-5edaa7f9.4d462-jepsen process 49
LOG: execute <unnamed>: select (val) from txn2 where sk = $1
1591388175.902-316514-13/403-1680806-SELECT-5edaa7f9.4d462-jepsen process 49
DETAIL: parameters: $1 = '1469'
49 goes on to append to 1439, which, again, fails and backs off to insert:
[rr 316514 583918]
1591388175.956-316514-13/403-1680806-UPDATE-5edaa7f9.4d462-jepsen process 49
LOG: execute <unnamed>: update txn0 set val = CONCAT(val, ',', $1) where id = $2
1591388175.956-316514-13/403-1680806-UPDATE-5edaa7f9.4d462-jepsen process 49
DETAIL: parameters: $1 = '2', $2 = '1439'
[rr 316514 584036]
1591388175.960-316514-13/403-1680806-SAVEPOINT-5edaa7f9.4d462-jepsen process 49
LOG: execute <unnamed>: savepoint upsert
[rr 316514 584283]
1591388175.970-316514-13/403-1680806-INSERT-5edaa7f9.4d462-jepsen process 49
LOG: execute <unnamed>: insert into txn0 (id, sk, val) values ($1, $2, $3)
1591388175.970-316514-13/403-1680806-INSERT-5edaa7f9.4d462-jepsen process 49
DETAIL: parameters: $1 = '1439', $2 = '1439', $3 = '2'[rr 316514 584299]
1591388175.971-316514-13/403-1680806-RELEASE-5edaa7f9.4d462-jepsen process 49
LOG: execute <unnamed>: release savepoint upsert
And 49 commits, resulting in a G2-item.
[rr 316514 584309]
1591388175.971-316514-13/403-1680806-COMMIT-5edaa7f9.4d462-jepsen process 49
LOG: execute <unnamed>: COMMIT
--Kyle
On Sat, Jun 6, 2020 at 5:49 AM Kyle Kingsbury <aphyr@jepsen.io> wrote:
> Here's a quick runthrough of G2-item #0:
>
> Let:
> T1 = {:type :ok, :f :txn, :value [[:append 1468 3] [:r 1469 nil] [:append
> 1439 2]], :time 22408795244, :process 49, :index 10392}
> T2 = {:type :ok, :f :txn, :value [[:append 1469 1] [:append 1456 2] [:r 1468
> nil]], :time 22565885165, :process 45, :index 10464}
>
> Then:
> - T1 < T2, because T1 observed the initial (nil) state of 1469, which T2
> created by appending 1.
> - However, T2 < T1, because T2 observed the initial (nil) state of 1468,
> which T1 created by appending 3: a contradiction!
>
> Classic G2: two rw-edges, where each transaction failed to observe the other's
> write.
Here is a restatement of the same anomaly with RR event number
annotations, to make it easy for other people to match up each
observation/modification to a query from the log file I made available
yesterday:
G2-item #0
Let:
T1 = {:type :ok, :f :txn, :value [[:append 1468 3] [:r 1469 nil]
[:append 1439 2]], :time 22408795244, :process 49, :index 10392}
T2 = {:type :ok, :f :txn, :value [[:append 1469 1] [:append 1456 2]
[:r 1468 nil]], :time 22565885165, :process 45, :index 10464}
Then:
- T1 < T2, because T1 observed the initial (nil) state of 1469 (at
RR 582419), which T2 created by appending 1 (at RR 581548).
- However, T2 < T1, because T2 observed the initial (nil) state of
1468 (at RR 582018), which T1 created by appending 3 (at RR 581374):
-- a contradiction!
Possibly silly question: Doesn't "observing the initial (nil) state"
mean that no rows were returned by a SELECT statement? For example,
doesn't that just mean that the following SELECT statement returns no
rows?:
[rr 316514 582419]
1591388175.902-316514-13/403-1680806-SELECT-5edaa7f9.4d462-jepsen
process 49 LOG: execute <unnamed>: select (val) from txn2 where sk =
$1
1591388175.902-316514-13/403-1680806-SELECT-5edaa7f9.4d462-jepsen
process 49 DETAIL: parameters: $1 = '1469'
--
Peter Geoghegan
On Sat, Jun 6, 2020 at 3:24 PM Peter Geoghegan <pg@bowt.ie> wrote: > Here is a restatement of the same anomaly with RR event number > annotations, to make it easy for other people to match up each > observation/modification to a query from the log file I made available > yesterday: Attached is a tentative bug fix. With this applied, I cannot get Jepsen/Elle to complain about a G2-Item anymore, nor any other anomaly, even after a dozen or so attempts. The regression tests pass, too. The issue seems to be that heapam's mechanism for adding a "conflict out" can get some details subtly wrong. This can happen in the event of a concurrently updated tuple where the updating xact aborts. So for each pair of transactions that committed in each G2-Item, there seemed to be a third updating transaction that aborted, messing things up. I think that the "conflict out" stuff ought to behave as if an updated tuple was never updated when it's not visible to our xact anyway. We should use the XID that created the original tuple for "conflict out" purposes -- not the (possibly aborted) updater's XID (i.e. not the HeapTupleHeaderGetUpdateXid() XID). In the example RR log that I posted the other day, the update + abort transaction was here (jepsen process 39/xid 1680826): [rr 316505 584863] 1591388175.991-316505-7/407-1680826-SELECT-5edaa7f9.4d459-jepsen process 39 LOG: execute <unnamed>: select (val) from txn0 where id = $1 1591388175.991-316505-7/407-1680826-SELECT-5edaa7f9.4d459-jepsen process 39 DETAIL: parameters: $1 = '1470' [rr 316505 584881] 1591388175.992-316505-7/0-1680826-ROLLBACK-5edaa7f9.4d459-jepsen process 39 LOG: execute <unnamed>: ROLLBACK Kyle: Shouldn't be too hard to build Postgres from source if you want to test it yourself. Either way, thanks for the report! -- Peter Geoghegan
Вложения
On Sun, Jun 7, 2020 at 7:54 PM Peter Geoghegan <pg@bowt.ie> wrote: > In the example RR log that I posted the other day, the update + abort > transaction was here (jepsen process 39/xid 1680826): > > [rr 316505 584863] > 1591388175.991-316505-7/407-1680826-SELECT-5edaa7f9.4d459-jepsen > process 39 LOG: execute <unnamed>: select (val) from txn0 where id = > $1 > 1591388175.991-316505-7/407-1680826-SELECT-5edaa7f9.4d459-jepsen > process 39 DETAIL: parameters: $1 = '1470' > [rr 316505 584881] > 1591388175.992-316505-7/0-1680826-ROLLBACK-5edaa7f9.4d459-jepsen > process 39 LOG: execute <unnamed>: ROLLBACK I mean in the case of the G2-Item that Kyle chose to focus on yesterday specifically -- G2-item #0 from the log_rr_recording.log execution. -- Peter Geoghegan
On Sun, Jun 7, 2020 at 7:54 PM Peter Geoghegan <pg@bowt.ie> wrote: > The issue seems to be that heapam's mechanism for adding a "conflict > out" can get some details subtly wrong. This can happen in the event > of a concurrently updated tuple where the updating xact aborts. So for > each pair of transactions that committed in each G2-Item, there seemed > to be a third updating transaction that aborted, messing things up. I > think that the "conflict out" stuff ought to behave as if an updated > tuple was never updated when it's not visible to our xact anyway. We > should use the XID that created the original tuple for "conflict out" > purposes -- not the (possibly aborted) updater's XID (i.e. not the > HeapTupleHeaderGetUpdateXid() XID). The functionality in question (the code from the HeapCheckForSerializableConflictOut() case statement) was originally discussed here, with the details finalized less than a week before SSI was committed in 2011: https://www.postgresql.org/message-id/flat/1296499247.11513.777.camel%40jdavis#9e407424df5f8794360b6e84de60200a It hasn't really changed since that time. Kevin, Jeff: What do you think of the fix I have proposed? Attached is a revised version, with better comments and a proper commit message. Somebody should review this patch before I proceed with commit. Thanks -- Peter Geoghegan
Вложения
On Tue, Jun 9, 2020 at 1:26 PM Peter Geoghegan <pg@bowt.ie> wrote: > The functionality in question (the code from the > HeapCheckForSerializableConflictOut() case statement) was originally > discussed here, with the details finalized less than a week before SSI > was committed in 2011: > > https://www.postgresql.org/message-id/flat/1296499247.11513.777.camel%40jdavis#9e407424df5f8794360b6e84de60200a > > It hasn't really changed since that time. Right, the only change was to move things around a bit to suport new table AMs. Speaking of which, it looks like the new comment atop CheckForSerializableConflictOut() could use some adjustment. It says "A table AM is reading a tuple that has been modified. After determining that it is visible to us, it should call this function..." but it seems the truth is a bit more complicated than that.
On Mon, Jun 8, 2020 at 7:01 PM Thomas Munro <thomas.munro@gmail.com> wrote: > Right, the only change was to move things around a bit to suport new > table AMs. Speaking of which, it looks like the new comment atop > CheckForSerializableConflictOut() could use some adjustment. It says > "A table AM is reading a tuple that has been modified. After > determining that it is visible to us, it should call this function..." > but it seems the truth is a bit more complicated than that. Right. I think that you can go ahead and change it without further input here. -- Peter Geoghegan
On Mon, Jun 8, 2020 at 7:07 PM Peter Geoghegan <pg@bowt.ie> wrote: > Right. I think that you can go ahead and change it without further input here. Also, is it necessary to have the TransactionIdEquals() tests in both HeapCheckForSerializableConflictOut() and CheckForSerializableConflictOut()? Apart from anything else, the test in HeapCheckForSerializableConflictOut() occurs before we establish the topmost XID -- it could be a subxid, in which case the test is wrong. Though it doesn't actually matter on account of the redundancy, IIUC. -- Peter Geoghegan
Hi, On 2020-06-08 18:26:01 -0700, Peter Geoghegan wrote: > On Sun, Jun 7, 2020 at 7:54 PM Peter Geoghegan <pg@bowt.ie> wrote: > > The issue seems to be that heapam's mechanism for adding a "conflict > > out" can get some details subtly wrong. This can happen in the event > > of a concurrently updated tuple where the updating xact aborts. So for > > each pair of transactions that committed in each G2-Item, there seemed > > to be a third updating transaction that aborted, messing things up. I > > think that the "conflict out" stuff ought to behave as if an updated > > tuple was never updated when it's not visible to our xact anyway. We > > should use the XID that created the original tuple for "conflict out" > > purposes -- not the (possibly aborted) updater's XID (i.e. not the > > HeapTupleHeaderGetUpdateXid() XID). > > The functionality in question (the code from the > HeapCheckForSerializableConflictOut() case statement) was originally > discussed here, with the details finalized less than a week before SSI > was committed in 2011: > > https://www.postgresql.org/message-id/flat/1296499247.11513.777.camel%40jdavis#9e407424df5f8794360b6e84de60200a > > It hasn't really changed since that time. > > Kevin, Jeff: What do you think of the fix I have proposed? Attached is > a revised version, with better comments and a proper commit message. > Somebody should review this patch before I proceed with commit. This should be testable with isolationtester, right? Greetings, Andres Freund
On Mon, Jun 8, 2020 at 7:17 PM Andres Freund <andres@anarazel.de> wrote: > This should be testable with isolationtester, right? I'll try to write an isolationtester test tomorrow. -- Peter Geoghegan
On Tue, Jun 9, 2020 at 2:12 PM Peter Geoghegan <pg@bowt.ie> wrote: > Also, is it necessary to have the TransactionIdEquals() tests in both > HeapCheckForSerializableConflictOut() and > CheckForSerializableConflictOut()? Apart from anything else, the test > in HeapCheckForSerializableConflictOut() occurs before we establish > the topmost XID -- it could be a subxid, in which case the test is > wrong. Though it doesn't actually matter on account of the redundancy, > IIUC. The double-check was present in the original commit dafaa3efb75. It seems like a pretty straightforward optimisation: SubTransGetTopmostTransaction(xid) might cause I/O so it's worth the check if you can already bail out sooner. Admittedly the recent splitting of that function made that a bit less clear.
On Mon, Jun 8, 2020 at 7:30 PM Peter Geoghegan <pg@bowt.ie> wrote: > I'll try to write an isolationtester test tomorrow. Attached is v3, which has an isolationtester test. It also fixes an assertion failure that could happen in rare cases, which was reported to me privately by Thomas. We now explicitly don't go ahead with an XID when it precedes TransactionXmin. I overstated the significance of the fact that the transaction aborts in the case that we looked at. That isn't an essential part of the anomaly. See the isolation test. -- Peter Geoghegan
Вложения
On 6/10/20 9:10 PM, Peter Geoghegan wrote: > On Mon, Jun 8, 2020 at 7:30 PM Peter Geoghegan <pg@bowt.ie> wrote: >> I'll try to write an isolationtester test tomorrow. > Attached is v3, which has an isolationtester test. > > It also fixes an assertion failure that could happen in rare cases, > which was reported to me privately by Thomas. We now explicitly don't > go ahead with an XID when it precedes TransactionXmin. Thanks so much for investigating this, Peter. And thanks to everyone else here who helped get this sorted out--y'all have done great work. :) I wanted to let you know that I've put together a draft of a report on these findings, and if you've got any comments you'd like to offer, I'd be happy to hear them, either on-list or privately. http://jepsen.io/analyses/postgresql-12.3?draft-token=Kets1Quayfs People reading this list: hi please don't leak this to twitter/HN/etc just yet, I'd like to give it a few days to settle before release. :) --Kyle
On Thu, Jun 11, 2020 at 1:10 PM Peter Geoghegan <pg@bowt.ie> wrote: > Attached is v3, which has an isolationtester test. Nice repro. We have: foo happened before bar, because it can't see bar_insert bar happened before foo, because it can't see foo_insert (!) Confirmed here that this anomaly is missed in master and detected with the patch as shown, and check-world passes. Explaining it to myself like I'm five: The tuple foo_insert was concurrently inserted *and* deleted/updated. Our coding screwed that case up. Your fix teaches the HEAPTUPLE_DELETE_IN_PROGRESS case to check if it's also an insert we can't see, and then handles it the same as non-visible HEAPTUPLE_LIVE or HEAPTUPLE_INSERT_IN_PROGRESS. That is, by taking the xmin (inserter), not the xmax (updater/deleter) for conflict-out checking. (As mentioned on IM, I wondered for a bit why it's OK that we now lack a check for conflict out to the deleter in the insert+delete case, but I think that's OK because it certainly happened after the insert committed.) Then you realised that HEAPTUPLE_RECENTLY_DEAD has no reason to be treated differently. Minor nits (already mentioned via IM but FTR): bar_first isn't necessary in the test, s/foo-insert/foo_insert/ Looks pretty good to me. Tricky problem, really excellent work.
On Thu, Jun 11, 2020 at 3:14 PM Kyle Kingsbury <aphyr@jepsen.io> wrote: > I wanted to let you know that I've put together a draft of a report on these > findings, and if you've got any comments you'd like to offer, I'd be happy to > hear them, either on-list or privately. > http://jepsen.io/analyses/postgresql-12.3?draft-token=Kets1Quayfs What do you think about this documentation update? I'm not experienced with biblioentry academic references; if someone would like to show me how this is supposed to be cited, I'm all ears.
Вложения
On Tue, Jun 9, 2020 at 2:08 PM Peter Geoghegan <pg@bowt.ie> wrote: > On Mon, Jun 8, 2020 at 7:01 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > Right, the only change was to move things around a bit to suport new > > table AMs. Speaking of which, it looks like the new comment atop > > CheckForSerializableConflictOut() could use some adjustment. It says > > "A table AM is reading a tuple that has been modified. After > > determining that it is visible to us, it should call this function..." > > but it seems the truth is a bit more complicated than that. > > Right. I think that you can go ahead and change it without further input here. It's only comments, but it'd still be good to get some review since it's essentially describing the relevant contract. Here's what I came up with.
Вложения
On 6/11/20 1:40 AM, Thomas Munro wrote: > What do you think about this documentation update? I think this is really helpful! You can go a little further if you like. Right now, SSI vs serializable and SI vs RR are both described as "differences in behavior", which kinda leaves it unclear as to how those levels are related. If you want to follow Berenson, Adya, et al.'s broad interpretation, I'd say something like "Snapshot isolation prevents some anomalies, like phantoms, which repeatable read allows. It also allows some anomalies, like G2-item (write skew), which repeatable read prevents." ... and if you like, you could follow that with a discussion of how SI, thanks to ambiguity in the ANSI specification, could also be interpreted as stronger than RR. If you stick with the strict interpretation, I'd add a note here about how readers familiar with the SI literature might be confused, and that you're diverging from Berenson et al., but your position is defensible under the spec. "Serializable Snapshot Isolation is stronger than serializability: it allows only serializable histories--and prohibits some additional histories in addition." If you wanna talk about the performance rationale, that's valid too. :) --Kyle
On Wed, Jun 10, 2020 at 8:16 PM Thomas Munro <thomas.munro@gmail.com> wrote: > Confirmed here that this anomaly is missed in master and detected with > the patch as shown, and check-world passes. > Looks pretty good to me. Tricky problem, really excellent work. Pushed a slightly refined version of v3 to all supported branches. Thanks for the review! -- Peter Geoghegan
On Thu, Jun 11, 2020 at 3:13 AM Thomas Munro <thomas.munro@gmail.com> wrote: > It's only comments, but it'd still be good to get some review since > it's essentially describing the relevant contract. Here's what I came > up with. LGTM. -- Peter Geoghegan
Hi, On 2020-06-11 17:40:55 +1200, Thomas Munro wrote: > + <para> > + The Repeatable Read isolation level is implemented using a technique > + known in academic database literature and in some other database products > + as <firstterm>Snapshot Isolation</firstterm>. Differences in behavior > + may be observed when compared with systems using other implementation > + techniques. For a full treatment, please see > + <xref linkend="berenson95"/>. > + </para> Could it be worthwhile to narrow the "differences in behaviour" bit to read-write transactions? IME the biggest reason people explicitly use RR over RC is to avoid phantom reads in read-only transactions. Seems nicer to not force users to read an academic paper to figure that out? > @@ -1726,6 +1744,13 @@ SELECT pg_advisory_lock(q.id) FROM > see a transient state that is inconsistent with any serial execution > of the transactions on the master. > </para> > + > + <para> > + Access to the system catalogs is not done using the isolation level > + of the current transaction. This has the effect that newly created > + database objects such as tables become visible to concurrent Repeatable > + Read and Serializable transactions, even though their contents does not. > + </para> > </sect1> Should it be pointed out that that's about *internal* accesses to catalogs? This could be understood to apply to a SELECT * FROM pg_class; where it actually doesn't apply? Greetings, Andres Freund
On 2020-06-11 12:30:23 -0700, Andres Freund wrote: > Hi, > > On 2020-06-11 17:40:55 +1200, Thomas Munro wrote: > > + <para> > > + The Repeatable Read isolation level is implemented using a technique > > + known in academic database literature and in some other database products > > + as <firstterm>Snapshot Isolation</firstterm>. Differences in behavior > > + may be observed when compared with systems using other implementation > > + techniques. For a full treatment, please see > > + <xref linkend="berenson95"/>. > > + </para> > > Could it be worthwhile to narrow the "differences in behaviour" bit to > read-write transactions? IME the biggest reason people explicitly use RR > over RC is to avoid phantom reads in read-only transactions. Seems nicer > to not force users to read an academic paper to figure that out? But, on second thought, it might be too difficult to phrase this concisely and correctly, given the annoying issue of SI allowing for read-only transactions to observe violations of serializability. I don't think that's a RR violation, but maybe it could be understood as being about serializability too easily?
Hi, On 2020-06-11 08:39:13 -0400, Kyle Kingsbury wrote: > On 6/11/20 1:40 AM, Thomas Munro wrote: > > What do you think about this documentation update? > > I think this is really helpful! You can go a little further if you like. > Right now, SSI vs serializable and SI vs RR are both described as > "differences in behavior", which kinda leaves it unclear as to how those > levels are related. If you want to follow Berenson, Adya, et al.'s broad > interpretation, I'd say something like > > "Snapshot isolation prevents some anomalies, like phantoms, which repeatable > read allows. It also allows some anomalies, like G2-item (write skew), which > repeatable read prevents." I think the percentage of readers that understand "G2-item" or even "write skew", but don't already know what snapshot isolation implies, is pretty close to zero. I like the idea of having a bit more detail, but I think it'd have to be worded differently to be beneficial. I'd also phrase it as "some definitions of repeatable read", but ... :). Intuitively, and that's not meant as an argument for anything, I find prohibiting write skew in something named "repeatable read" just plain odd. Leaving naming aside, I think there's good practical reasons for applications using read-committed, snapshot isolation, and serializable. It's not obvious to me that there are cases where the Berenson definition of RR is something that's desirable to use over RR/SI/S. I suspect what we really want, medium term, is some guidelines around what isolation levels are appropriate for which use-case. But that's a nontrivial thing to write, I think, and there's lot of room for disagreements... Greetings, Andres Freund
On Fri, Jun 12, 2020 at 7:30 AM Andres Freund <andres@anarazel.de> wrote: > > + Access to the system catalogs is not done using the isolation level > > + of the current transaction. This has the effect that newly created > > + database objects such as tables become visible to concurrent Repeatable > > + Read and Serializable transactions, even though their contents does not. > Should it be pointed out that that's about *internal* accesses to > catalogs? This could be understood to apply to a SELECT * FROM pg_class; > where it actually doesn't apply? Yeah. I hesitated about writing that because they don't exactly use the current isolation level in its full glory, they just use the current snapshot. Specifically, predicate locks are not taken on catalogs. That seemed a bit beyond my personal murkiness threshold for inclusion in the manual, but let me see if I can come up with the right weasel words. Attached, but also inline here for review: + <para> + Internal access to the system catalogs is not done using the isolation + level of the current transaction. This means that newly created + database objects such as tables are visible to concurrent Repeatable Read + and Serializable transactions, even though the rows they contain are not. + In contrast, queries that explicitly examine the system catalogs don't + see rows representing concurrently created database objects in the higher + isolation levels. + </para> On Fri, Jun 12, 2020 at 7:48 AM Andres Freund <andres@anarazel.de> wrote: > On 2020-06-11 12:30:23 -0700, Andres Freund wrote: > > Could it be worthwhile to narrow the "differences in behaviour" bit to > > read-write transactions? IME the biggest reason people explicitly use RR > > over RC is to avoid phantom reads in read-only transactions. Seems nicer > > to not force users to read an academic paper to figure that out? > > But, on second thought, it might be too difficult to phrase this > concisely and correctly, given the annoying issue of SI allowing for > read-only transactions to observe violations of serializability. I don't > think that's a RR violation, but maybe it could be understood as being > about serializability too easily? The goal of this new paragraph is to highlight that there is a difference between traditional System R-style RR (as assumed but not required by the SQL spec, see disputes) and SI. RC vs RR etc is covered elsewhere. I agree that it's way over the top to go into the gory details in our manual, as Kyle suggested, though; my goal here is just to flag up this key point in as few words as possible. Kyle is of course right: it might affect someone coming from another database product or database theory textbook. So, we should state the proper name of the exact technique we are using, and refer the curious to primary sources for more. Here's a new attempt at that. Attached, but I'll also just include the new paragraph here because it's short: + <para> + The Repeatable Read isolation level is implemented using a technique + known in academic database literature and in some other database products + as <firstterm>Snapshot Isolation</firstterm>. Differences in behavior + and performance may be observed when compared with systems using a more + traditional technique that permits less concurrency, and some other + systems may even offer Repeatable Read and Snapshot Isolation as distinct + isolation levels. The allowable phenomena that can be used to distinguish + the two techniques were not formalized by database researchers until after + the SQL Standard was developed, and are outside the scope of this manual. + For a full treatment, please see <xref linkend="berenson95"/>. + </para> I also tweaked the new SSI para based on Kyle's feedback, to mention performance. Kevin and Dan's paper, and plenty more papers referenced from there, cover S2PL vs SSI pretty well if you want to know more about that. So I think that external reference is the right way to go here too. + <para> + The Serializable isolation level is implemented using a technique + known in academic database literature as Serializable Snapshot Isolation, + which builds on Snapshot Isolation by adding checks for serialization + anomalies. Some differences in behavior and performance may be observed + when compared with systems using other techniques. Please see + <xref linkend="gritt2012"/> for detailed information. + </para>
Вложения
On Wed, Jun 10, 2020 at 8:14 PM Kyle Kingsbury <aphyr@jepsen.io> wrote: > I wanted to let you know that I've put together a draft of a report on these > findings, and if you've got any comments you'd like to offer, I'd be happy to > hear them, either on-list or privately. > http://jepsen.io/analyses/postgresql-12.3?draft-token=Kets1Quayfs You should mention that a fix was committed this morning: https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=5940ffb221316ab73e6fdc780dfe9a07d4221ebb You may want to draw attention to the isolation test, since it's a perfect distillation of the bug. I'm certain that it cannot be simplified any further. Note that the test involves three transactions/sessions -- not two. Elle always complained about a pair of transactions that had a cycle, which were similar to the "foo" and "bar" sessions from the test. But Elle never said anything about a third transaction (that played the role of the "trouble" transaction from the test). Of course, this makes perfect sense -- the third/"trouble" transaction *should* be totally irrelevant. Note that the UPDATE has to come from a third session/transaction for things to go awry. And note that the order of each statement has to match the order from the isolation test. For example, no problems occur if you flip the order of "trouble_update" and "bar_select" -- because that would mean that the physical tuple does not get physically updated before being examined by "bar_select". You should also specifically mention that the next upcoming minor release will be on August 13th, 2020: https://www.postgresql.org/developer/roadmap/ Users that are concerned about this bug will be able to get a new minor release with the fix by that date, at the latest. Thanks -- Peter Geoghegan
On 6/11/20 6:51 PM, Peter Geoghegan wrote: > On Wed, Jun 10, 2020 at 8:14 PM Kyle Kingsbury <aphyr@jepsen.io> wrote: >> I wanted to let you know that I've put together a draft of a report on these >> findings, and if you've got any comments you'd like to offer, I'd be happy to >> hear them, either on-list or privately. >> http://jepsen.io/analyses/postgresql-12.3?draft-token=Kets1Quayfs > You should mention that a fix was committed this morning: > > https://git.postgresql.org/gitweb/?p=postgresql.git;a=commit;h=5940ffb221316ab73e6fdc780dfe9a07d4221ebb Ah, fantastic! > You may want to draw attention to the isolation test, since it's a > perfect distillation of the bug. I'm certain that it cannot be > simplified any further. I mentioned it in the discussion, but now I can offer a direct link. Great work. :) > Note that the test involves three transactions/sessions -- not two. > Elle always complained about a pair of transactions that had a cycle, > which were similar to the "foo" and "bar" sessions from the test. But > Elle never said anything about a third transaction (that played the > role of the "trouble" transaction from the test). Of course, this > makes perfect sense -- the third/"trouble" transaction *should* be > totally irrelevant. Note that the UPDATE has to come from a third > session/transaction for things to go awry. And note that the order of > each statement has to match the order from the isolation test. For > example, no problems occur if you flip the order of "trouble_update" > and "bar_select" -- because that would mean that the physical tuple > does not get physically updated before being examined by "bar_select". Ah, thank you. I didn't quite understand this from the second patch commit message. > You should also specifically mention that the next upcoming minor > release will be on August 13th, 2020: > > https://www.postgresql.org/developer/roadmap/ > > Users that are concerned about this bug will be able to get a new > minor release with the fix by that date, at the latest. That's great news. Will do! :) --Kyle
Thomas Munro wrote: > + Access to the system catalogs is not done using the isolation level > + of the current transaction. This has the effect that newly created > + database objects such as tables become visible to concurrent Repeatable > + Read and Serializable transactions, even though their contents does not. "their contents does not" should be "their contents do not". cheers, raf
On Sat, Jun 13, 2020 at 10:11 AM raf <raf@raf.org> wrote: > "their contents does not" should be "their contents do not". Thanks. I'd already reworded that in the v2 patch, later in the thread.
On Fri, Jun 12, 2020 at 10:14 AM Thomas Munro <thomas.munro@gmail.com> wrote: > Here's a new attempt at that. Attached, but I'll also just include > the new paragraph here because it's short: Slightly improved version, bringing some wording into line with existing documentation. s/SQL Standard/SQL standard/, and explicitly referring to "locking" implementations of RR and Ser (as we do already a few paragraphs earlier, when discussing MVCC). My intention is to push this to all branches in a couple of days if there is no other feedback. I propose to treat it as a defect, because I agree that it's weird and surprising that we don't mention SI, especially considering the history of the standard levels. I mean, I guess it's basically implied by all the stuff that section says about MVCC vs traditional locking systems, and it's a super well known fact in our hacker community, but not using the standard term of art is a strange omission. In future release perhaps we could entertain ideas like accepting the name SNAPSHOT ISOLATION, and writing some more use-friendly guidance, and possibly even reference the Generalized Isolation Level Definitions stuff. I think it'd be a bad idea to stop accepting REPEATABLE READ and inconvenience our users, though; IMHO it's perfectly OK to stick with the current interpretation of the spec while also acknowledging flaws and newer thinking through this new paragraph.
Вложения
> On Fri, Jun 12, 2020 at 10:14 AM Thomas Munro <thomas.munro@gmail.com> wrote: >> Here's a new attempt at that. Attached, but I'll also just include >> the new paragraph here because it's short: > > Slightly improved version, bringing some wording into line with > existing documentation. s/SQL Standard/SQL standard/, and explicitly > referring to "locking" implementations of RR and Ser (as we do already > a few paragraphs earlier, when discussing MVCC). My intention is to > push this to all branches in a couple of days if there is no other > feedback. I propose to treat it as a defect, because I agree that > it's weird and surprising that we don't mention SI, especially > considering the history of the standard levels. I mean, I guess it's > basically implied by all the stuff that section says about MVCC vs > traditional locking systems, and it's a super well known fact in our > hacker community, but not using the standard term of art is a strange > omission. > > In future release perhaps we could entertain ideas like accepting the > name SNAPSHOT ISOLATION, and writing some more use-friendly guidance, > and possibly even reference the Generalized Isolation Level > Definitions stuff. I think it'd be a bad idea to stop accepting > REPEATABLE READ and inconvenience our users, though; IMHO it's > perfectly OK to stick with the current interpretation of the spec > while also acknowledging flaws and newer thinking through this new > paragraph. +1. Best regards, -- Tatsuo Ishii SRA OSS, Inc. Japan English: http://www.sraoss.co.jp/index_en.php Japanese:http://www.sraoss.co.jp
On Fri, Jun 12, 2020 at 9:49 PM Thomas Munro <thomas.munro@gmail.com> wrote: > Slightly improved version, bringing some wording into line with > existing documentation. s/SQL Standard/SQL standard/, and explicitly > referring to "locking" implementations of RR and Ser (as we do already > a few paragraphs earlier, when discussing MVCC). My intention is to > push this to all branches in a couple of days if there is no other > feedback. I propose to treat it as a defect, because I agree that > it's weird and surprising that we don't mention SI, especially > considering the history of the standard levels. That seems reasonable to me. The doc patch says "some other systems may even offer Repeatable Read and Snapshot Isolation as distinct isolation levels". This is true of SQL Server, which has an explicit snapshot isolation level, though possibly only because SI was retrofitted to SQL Server 2005 -- I guess that that's what you have in mind. Perhaps you should reword this a little to convey that you mean a separate isolation mode *and* an actually-distinct set of behaviors to go with it. > I mean, I guess it's > basically implied by all the stuff that section says about MVCC vs > traditional locking systems, and it's a super well known fact in our > hacker community, but not using the standard term of art is a strange > omission. Yes, it's definitely an omission. > In future release perhaps we could entertain ideas like accepting the > name SNAPSHOT ISOLATION, and writing some more use-friendly guidance, > and possibly even reference the Generalized Isolation Level > Definitions stuff. I think it'd be a bad idea to stop accepting > REPEATABLE READ and inconvenience our users, though; IMHO it's > perfectly OK to stick with the current interpretation of the spec > while also acknowledging flaws and newer thinking through this new > paragraph. Kyle made the following observation about "true" RR at one point: "If you use the broad/generalized interpretation, you can trust that a program which only accesses data by primary key, running under repeatable read, is actually serializable". However, the simple fact is that it just wouldn't be sensible for Postgres to offer an according-to-Adya REPEATABLE READ mode that isn't just an alias for SERIALIZABLE/SSI. What does the leeway that RR gives us compared to SERIALIZABLE actually buy the implementation, performance-wise? This is similar to the situation with READ UNCOMMITED and READ COMMITTED in Postgres. Even though I am sympathetic to Kyle's concerns here, and am all in favor of this documentation patch, I believe that the current naming scheme is the least-worst option. The point of using the standard names is to make it easy to understand the guarantees on offer. But we need to call the current REPEATABLE READ behavior *something*, and the closest thing that the standard has is RR. Unless we're willing to make no distinction between SSI and snapshot isolation -- which we're clearly not. Or unless we're willing to exclusively use some non-standard name instead -- which is also clearly a non-starter (though I'd be fine with an alias). Speaking of comparing behaviors across systems, the behavior that MySQL calls REPEATABLE READ mode is actually READ COMMITTED, while the behavior that DB2 calls REPEATABLE READ is actually SERIALIZABLE. The range of guarantees that you actually get are *enormous* in reality! ISTM that REPEATABLE READ is by far the most confusing and ambiguous isolation level that the standard describes. Even Elle can't tell the difference between "true" REPEATABLE READ mode and SERIALIZABLE mode; why should Postgres users be able to? -- Peter Geoghegan
On Sun, Jun 14, 2020 at 6:37 AM Peter Geoghegan <pg@bowt.ie> wrote: > That seems reasonable to me. Thanks! > The doc patch says "some other systems may even offer Repeatable Read > and Snapshot Isolation as distinct isolation levels". This is true of > SQL Server, which has an explicit snapshot isolation level, though > possibly only because SI was retrofitted to SQL Server 2005 -- I guess > that that's what you have in mind. Perhaps you should reword this a > little to convey that you mean a separate isolation mode *and* an > actually-distinct set of behaviors to go with it. Ok, changed it to "distinct isolation levels with different behavior", and pushed this. I also made the biblio entries look more like the existing examples. > Speaking of comparing behaviors across systems, the behavior that > MySQL calls REPEATABLE READ mode is actually READ COMMITTED, while the By my reading of their manual, MySQL (assuming InnoDB) uses SI for REPEATABLE READ just like us, and it's also their default level. https://dev.mysql.com/doc/refman/8.0/en/innodb-consistent-read.html > behavior that DB2 calls REPEATABLE READ is actually SERIALIZABLE. The > range of guarantees that you actually get are *enormous* in reality! > ISTM that REPEATABLE READ is by far the most confusing and ambiguous > isolation level that the standard describes. I think IBM might even have changed that between System R and DB2, so there's probably an interesting story behind that.
Thomas Munro wrote: > > Speaking of comparing behaviors across systems, the behavior that > > MySQL calls REPEATABLE READ mode is actually READ COMMITTED, while the > > By my reading of their manual, MySQL (assuming InnoDB) uses SI for > REPEATABLE READ just like us, and it's also their default level. > > https://dev.mysql.com/doc/refman/8.0/en/innodb-consistent-read.html With InnoDB, a RR transaction that just reads has the same behavior than with Postgres, in the sense that it does consistent reads across all tables. But it should be noted that when concurrent writes are involved, InnoDB does not confine the transaction to its snapshot as Postgres does. In particular, rows that a simple SELECT can't see because of RR visibility rules are found by UPDATEs or INSERTs, and are somehow incorporated into the RR transaction. If InnoDB's RR is based on Snapshot Isolation, what it does with it seems to be in violation of Snapshot Isolation as seen by postgres, so it's somewhat unfair/confusing to use the same term for both. From the user point of view, Repeatable Read in InnoDB exhibits anomalies that are not possible with Postgres' Repeatable Read. Best regards, -- Daniel Vérité PostgreSQL-powered mailer: https://www.manitou-mail.org Twitter: @DanielVerite
On 6/14/20 9:30 PM, Thomas Munro wrote: > By my reading of their manual, MySQL (assuming InnoDB) uses SI for > REPEATABLE READ just like us, and it's also their default level. > > https://dev.mysql.com/doc/refman/8.0/en/innodb-consistent-read.html That can't be right. MySQL repeatable read allows lost update, write skew, and at least some kinds of read skew: it's got to be weaker than SI and also weaker than RR. I think it's actually Monotonic Atomic View plus some read-only constraints? https://github.com/ept/hermitage <sigh> I really gotta do a report on MySQL too... --Kyle
On Mon, Jun 15, 2020 at 5:42 AM Kyle Kingsbury <aphyr@jepsen.io> wrote: > On 6/14/20 9:30 PM, Thomas Munro wrote: > > By my reading of their manual, MySQL (assuming InnoDB) uses SI for > > REPEATABLE READ just like us, and it's also their default level. > > > > https://dev.mysql.com/doc/refman/8.0/en/innodb-consistent-read.html > > That can't be right. MySQL repeatable read allows lost update, write skew, and > at least some kinds of read skew: it's got to be weaker than SI and also weaker > than RR. I think it's actually Monotonic Atomic View plus some read-only > constraints? At first glance it seemed to me that MySQL's repeatable read must be more or less the same as Postgres' repeatable read; there is only one snapshot in each case. But it's very different in reality, since updates and deletes don't use the transaction snapshot. Worst of all, you can update rows that were not visible to the transaction snapshot, thus rendering them visible (see the "Note" box in the documentation for an example of this). InnoDB won't throw a serialization error at any isolation level. I think that means that InnoDB's RR mode could "render" *some* of the rows concurrently inserted by another transaction (those that our xact happened to update) as visible, while leaving other rows inserted by that same other transaction invisible. That kind of behavior seems really hazardous to me. It almost seems safer to use RC mode, since using a new snapshot for each new statement is "more honest". Presumably RC mode doesn't exhibit the inconsistency I described -- at least all of the rows that were concurrently inserted by that other xact become visible together. -- Peter Geoghegan
On Tue, Jun 16, 2020 at 5:16 AM Peter Geoghegan <pg@bowt.ie> wrote: > At first glance it seemed to me that MySQL's repeatable read must be > more or less the same as Postgres' repeatable read; there is only one > snapshot in each case. But it's very different in reality, since > updates and deletes don't use the transaction snapshot. Worst of all, > you can update rows that were not visible to the transaction snapshot, > thus rendering them visible (see the "Note" box in the documentation > for an example of this). InnoDB won't throw a serialization error at > any isolation level. Ugh, obviously I only read the first two paragraphs of that page, which sound an *awful* lot like a description of SI (admittedly without naming it). My excuse is that I arrived on that page by following a link from https://en.wikipedia.org/wiki/Snapshot_isolation. Wikipedia is wrong. Thanks for clarifying.