Обсуждение: Postgres using the wrong index index
I've created a partial index that I expect the query planner to use in executing a query, but it's using another index instead. Using this other partial index results in a slower query. I'd really appreciate some help understanding why this is occurring. Thanks in advance!
Postgres Version
PostgreSQL 12.7 (Ubuntu 12.7-1.pgdg20.04+1) on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0, 64-bit
Problem Description
Here's the index I expect the planner to use:
CREATE INDEX other_events_1004175222_pim_evdef_67951aef14bc_idx ON public.other_events_1004175222 USING btree ("time", user_id) WHERE (
(user_id <= '(1080212440,9007199254740991)'::app_user_id) AND (user_id >= '(1080212440,0)'::app_user_id) AND
(
(
(type = 'click'::text) AND (library = 'web'::text) AND
(strpos(hierarchy, '#close_onborading;'::text) <> 0) AND (object IS NULL)
) OR
(
(type = 'click'::text) AND (library = 'web'::text) AND
(strpos(hierarchy, '#proceedOnboarding;'::text) <> 0) AND (object IS NULL)
)
)
);
Here's the query:
EXPLAIN (ANALYZE, VERBOSE, BUFFERS)
SELECT user_id,
"time",
0 AS event,
session_id
FROM test_yasp_events_exp_1004175222
WHERE ((test_yasp_events_exp_1004175222.user_id >=
'(1080212440,0)'::app_user_id) AND
(test_yasp_events_exp_1004175222.user_id <=
'(1080212440,9007199254740991)'::app_user_id) AND
("time" >=
'1624777200000'::bigint) AND
("time" <=
'1627369200000'::bigint) AND (
(
(type = 'click'::text) AND
(library = 'web'::text) AND
(strpos(hierarchy, '#close_onborading;'::text) <>
0) AND
(object IS NULL)) OR
(
(type = 'click'::text) AND
(library = 'web'::text) AND
(strpos(hierarchy,
'#proceedOnboarding;'::text) <>
0) AND (object IS NULL))))
Here's the plan: https://explain.depesz.com/s/uNGg
Note that the index being used is other_events_1004175222_pim_core_custom_2_8e65d072fbdd_idx, which is defined this way:
CREATE INDEX other_events_1004175222_pim_core_custom_2_8e65d072fbdd_idx ON public.other_events_1004175222 USING btree (type, "time", user_id) WHERE (
(type IS NOT NULL) AND (object IS NULL) AND
((user_id >= '(1080212440,0)'::app_user_id) AND (user_id <= '(1080212440,9007199254740991)'::app_user_id)))
You can view the definition of test_yasp_events_exp_1004175222 here. Note the child tables, other_events_1004175222, pageviews_1004175222, and sessions_1004175222 which have the following constraints:
other_events_1004175222: CHECK (object IS NULL)
pageviews_1004175222: CHECK (object IS NOT NULL AND object = 'pageview'::text)
sessions_1004175222: CHECK (object IS NOT NULL AND object = 'session'::text)
Also note that these child tables have 100s of partial indexes. You can find history on why we have things set up this way here.
Here's the table metadata for other_events_1004175222:
SELECT relname,
relpages,
reltuples,
relallvisible,
relkind,
relnatts,
relhassubclass,
reloptions,
pg_table_size(oid)
FROM pg_class
WHERE relname = 'other_events_1004175222';
Results:
--

Вложения
{kind=link}
On Tue, Aug 10, 2021 at 12:47:20PM -0400, Matt Dupree wrote: > Here's the plan: https://explain.depesz.com/s/uNGg > > Note that the index being used is Could you show the plan if you force use of the intended index ? For example by doing begin; DROP INDEX indexbeingused; explain thequery; rollback; Or: begin; UPDATE pg_index SET indisvalid=false WHERE indexrelid='indexbeingused'::regclass explain thequery; rollback; Could you show the table statistics for the time, user_id, and type columns on all 4 tables ? | SELECT (SELECT sum(x) FROM unnest(most_common_freqs) x) frac_MCV, tablename, attname, inherited, null_frac, n_distinct,array_length(most_common_vals,1) n_mcv, array_length(histogram_bounds,1) n_hist, correlation FROM pg_stats WHEREattname='...' AND tablename='...' ORDER BY 1 DESC; It might be interesting to see both query plans when index scans are disabled and bitmap scan are used instead (this might be as simple as begin; SET LOCAL enable_indexscan=off ...; rollback;); > Also note that these child tables have 100s of partial indexes. You > can find history on why we have things set up this way here > <https://heap.io/blog/running-10-million-postgresql-indexes-in-production>. I have read it before :) > SELECT relname, relpages, reltuples, relallvisible, pg_table_size(oid) > FROM pg_class WHERE relname = 'other_events_1004175222'; Could you also show the table stats for the two indexes ? One problem is that the rowcount estimate is badly off: | Index Scan using other_events_1004175222_pim_core_custom_2_8e65d072fbdd_idx on public.other_events_1004175222 (cost=0.57..1,213,327.64rows=1,854,125 width=32) (actual time=450.588..29,057.269 rows=23 loops=1) To my eyes, this looks like a typo ; it's used in the index predicate as well as the query, but maybe it's still relevant ? | #close_onborading -- Justin
Thanks for your response, Justin!
Here's the plan if we disable the custom_2 index. It uses the index I expect and it's much faster.
Here's a plan if we disable index scans. It uses both indexes and is much faster.
Here are the stats you asked for:
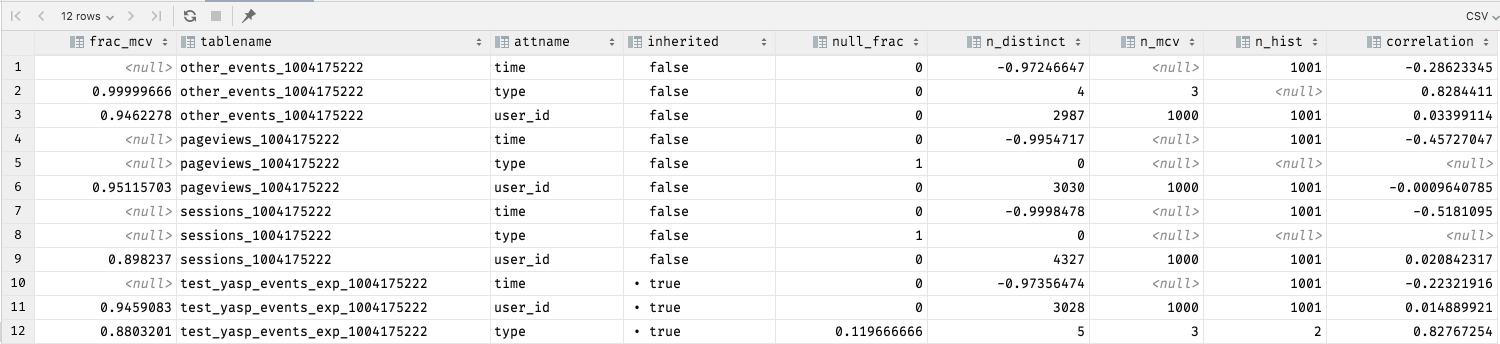
And here are the table stats for other_events_1004175222_pim_core_custom_2_8e65d072fbdd_idx and other_events_1004175222_pim_evdef_67951aef14bc_idx:
Thanks again for your help!
On Wed, Aug 11, 2021 at 8:38 AM Justin Pryzby <pryzby@telsasoft.com> wrote:
On Tue, Aug 10, 2021 at 12:47:20PM -0400, Matt Dupree wrote:
> Here's the plan: https://explain.depesz.com/s/uNGg
>
> Note that the index being used is
Could you show the plan if you force use of the intended index ?
For example by doing begin; DROP INDEX indexbeingused; explain thequery; rollback;
Or: begin; UPDATE pg_index SET indisvalid=false WHERE indexrelid='indexbeingused'::regclass explain thequery; rollback;
Could you show the table statistics for the time, user_id, and type columns on
all 4 tables ?
| SELECT (SELECT sum(x) FROM unnest(most_common_freqs) x) frac_MCV, tablename, attname, inherited, null_frac, n_distinct, array_length(most_common_vals,1) n_mcv, array_length(histogram_bounds,1) n_hist, correlation FROM pg_stats WHERE attname='...' AND tablename='...' ORDER BY 1 DESC;
It might be interesting to see both query plans when index scans are disabled
and bitmap scan are used instead (this might be as simple as begin; SET LOCAL
enable_indexscan=off ...; rollback;);
> Also note that these child tables have 100s of partial indexes. You
> can find history on why we have things set up this way here
> <https://heap.io/blog/running-10-million-postgresql-indexes-in-production>.
I have read it before :)
> SELECT relname, relpages, reltuples, relallvisible, pg_table_size(oid)
> FROM pg_class WHERE relname = 'other_events_1004175222';
Could you also show the table stats for the two indexes ?
One problem is that the rowcount estimate is badly off:
| Index Scan using other_events_1004175222_pim_core_custom_2_8e65d072fbdd_idx on public.other_events_1004175222 (cost=0.57..1,213,327.64 rows=1,854,125 width=32) (actual time=450.588..29,057.269 rows=23 loops=1)
To my eyes, this looks like a typo ; it's used in the index predicate as well
as the query, but maybe it's still relevant ?
| #close_onborading
--
Justin
--
Вложения
{kind=link}
You know that you can use pg_hint_plan extension? That way you don't have to disable indexes or set session parameters.
Regards
On 8/11/21 3:56 PM, Matt Dupree wrote:
Thanks for your response, Justin!Here's the plan if we disable the custom_2 index. It uses the index I expect and it's much faster.Here's a plan if we disable index scans. It uses both indexes and is much faster.
-- Mladen Gogala Database Consultant Tel: (347) 321-1217 https://dbwhisperer.wordpress.com
The rowcount estimate for the time column is bad for all these plans - do you know why ? You're using inheritence - have you analyzed the parent tables recently ? | Index Scan using other_events_1004175222_pim_evdef_67951aef14bc_idx on public.other_events_1004175222 (cost=0.28..1,648,877.92rows=1,858,891 width=32) (actual time=1.008..15.245 rows=23 loops=1) | Index Cond: ((other_events_1004175222."time" >= '1624777200000'::bigint) AND (other_events_1004175222."time" <= '1627369200000'::bigint)) -- Justin
Justin,
The rowcount estimate for the time column is bad for all these plans - do you
know why ? You're using inheritence - have you analyzed the parent tables
recently ?
Yes. I used ANALYZE before posting, as it's one of the "things to try" listed in the slow queries wiki. I even ran the queries immediately after analyzing. No difference. Can you say more about why the bad row estimate would cause Postgres to use the bigger index? I would expect Postgres to use the smaller index if it's over-estimating how many rows will be returned.
Mladen,
You know that you can use pg_hint_plan extension? That way you don't have to disable indexes or set session parameters.
Thanks for the tip! I didn't know you could use pg_hint_plan to force the use of certain indexes. For now, I'd like to avoid hinting and fix the underlying issue.
On Wed, Aug 11, 2021 at 11:45 PM Justin Pryzby <pryzby@telsasoft.com> wrote:
The rowcount estimate for the time column is bad for all these plans - do you
know why ? You're using inheritence - have you analyzed the parent tables
recently ?
| Index Scan using other_events_1004175222_pim_evdef_67951aef14bc_idx on public.other_events_1004175222 (cost=0.28..1,648,877.92 rows=1,858,891 width=32) (actual time=1.008..15.245 rows=23 loops=1)
| Index Cond: ((other_events_1004175222."time" >= '1624777200000'::bigint) AND (other_events_1004175222."time" <= '1627369200000'::bigint))
--
Justin
--
On Thu, Aug 12, 2021 at 09:38:45AM -0400, Matt Dupree wrote: > > The rowcount estimate for the time column is bad for all these plans - do you > > know why ? You're using inheritence - have you analyzed the parent tables recently ? > > Yes. I used ANALYZE before posting, as it's one of the "things to try" > listed in the slow queries wiki. I even ran the queries immediately after > analyzing. No difference. Can you say more about why the bad row estimate > would cause Postgres to use the bigger index? I would expect Postgres to > use the smaller index if it's over-estimating how many rows will be > returned. The overestimate is in the table's "time" column (not index) and applies to all the plans. Is either half of the AND estimated correctly? If you do a query with only ">=", and a query with only "<=", do either of them give an accurate rowcount estimate ? |Index Scan using other_events_1004175222_pim_evdef_67951aef14bc_idx on public.other_events_1004175222 (cost=0.28..1,648,877.92rows=1,858,891 width=32) (actual time=1.008..15.245 rows=23 loops=1) |Index Cond: ((other_events_1004175222."time" >= '1624777200000'::bigint) AND (other_events_1004175222."time" <= '1627369200000'::bigint)) It seems like postgres expects the scan to return a large number of matching rows, so tries to use the more selective index which includes the "type" column. But "type" is not very selective either (it has only 4 distinct values), and "time" is not the first column, so it reads a large fraction of the table, slowly. Could you check pg_stat_all_tables and be sure the last_analyzed is recent for both parent and child tables ? Could you send the histogram bounds for "time" ? SELECT tablename, attname, inherited, array_length(histogram_bounds,1), (histogram_bounds::text::text[])[1], (histogram_bounds::text::text[])[array_length(histogram_bounds,1)] FROM pg_stats ... ; -- Justin
Is either half of the AND estimated correctly? If you do a query
with only ">=", and a query with only "<=", do either of them give an accurate
rowcount estimate ?
Dropping >= results in the correct index being used. Dropping <= doesn't have this effect.
Could you send the histogram bounds for "time" ?
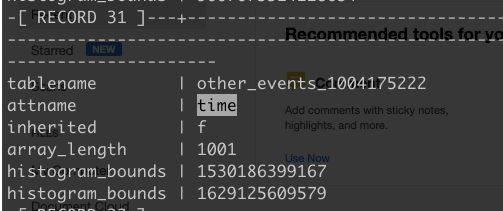
Could you check pg_stat_all_tables and be sure the last_analyzed is recent for
both parent and child tables ?
Looks like I forgot to ANALYZE the other_events partition, but Postgres is still using the wrong index either way (unless I drop >=, as mentioned above). Here are the results:

On Thu, Aug 12, 2021 at 7:20 PM Justin Pryzby <pryzby@telsasoft.com> wrote:
On Thu, Aug 12, 2021 at 09:38:45AM -0400, Matt Dupree wrote:
> > The rowcount estimate for the time column is bad for all these plans - do you
> > know why ? You're using inheritence - have you analyzed the parent tables recently ?
>
> Yes. I used ANALYZE before posting, as it's one of the "things to try"
> listed in the slow queries wiki. I even ran the queries immediately after
> analyzing. No difference. Can you say more about why the bad row estimate
> would cause Postgres to use the bigger index? I would expect Postgres to
> use the smaller index if it's over-estimating how many rows will be
> returned.
The overestimate is in the table's "time" column (not index) and applies to all
the plans. Is either half of the AND estimated correctly? If you do a query
with only ">=", and a query with only "<=", do either of them give an accurate
rowcount estimate ?
|Index Scan using other_events_1004175222_pim_evdef_67951aef14bc_idx on public.other_events_1004175222 (cost=0.28..1,648,877.92 rows=1,858,891 width=32) (actual time=1.008..15.245 rows=23 loops=1)
|Index Cond: ((other_events_1004175222."time" >= '1624777200000'::bigint) AND (other_events_1004175222."time" <= '1627369200000'::bigint))
It seems like postgres expects the scan to return a large number of matching
rows, so tries to use the more selective index which includes the "type"
column. But "type" is not very selective either (it has only 4 distinct
values), and "time" is not the first column, so it reads a large fraction of
the table, slowly.
Could you check pg_stat_all_tables and be sure the last_analyzed is recent for
both parent and child tables ?
Could you send the histogram bounds for "time" ?
SELECT tablename, attname, inherited, array_length(histogram_bounds,1), (histogram_bounds::text::text[])[1], (histogram_bounds::text::text[])[array_length(histogram_bounds,1)]
FROM pg_stats ... ;
--
Justin
--
Вложения
On Mon, Aug 16, 2021 at 11:22:44AM -0400, Matt Dupree wrote: > > Is either half of the AND estimated correctly? If you do a query > > with only ">=", and a query with only "<=", do either of them give an > > accurate rowcount estimate ? > > Dropping >= results in the correct index being used. Dropping <= doesn't > have this effect. This doesn't answer the question though: are the rowcount estimes accurate (say within 10%). It sounds like interpolating the histogram is giving a poor result, at least over that range of values. It'd be interesting to see the entire histogram. You might try increasing (or decreasing) the stats target for that column, and re-analyzing. Your histogram bounds are for ~38 months of data, and your query is for the previous month (July). $ date -d @1530186399 Thu Jun 28 06:46:39 CDT 2018 $ date -d @1629125609 Mon Aug 16 09:53:29 CDT 2021 $ date -d @1627369200 Tue Jul 27 02:00:00 CDT 2021 $ date -d @1624777200 Sun Jun 27 02:00:00 CDT 2021 The timestamp column has ndistinct near -1, similar to a continuous distribution, so I'm not sure why the estimate would be so bad. -- Justin
I increased (and decreased) the stats target for the column and re-analyzed. Didn't make a difference.
Is it possible that the row estimate is off because of a column other than time? I looked at the # of events in that time period and 1.8 million is actually a good estimate. What about the ((strpos(other_events_1004175222.hierarchy, '#close_onborading;'::text) <> 0) condition in the filter? It makes sense that Postgres wouldn't have a way to estimate how selective this condition is.
On Tue, Aug 17, 2021 at 2:52 PM Justin Pryzby <pryzby@telsasoft.com> wrote:
On Mon, Aug 16, 2021 at 11:22:44AM -0400, Matt Dupree wrote:
> > Is either half of the AND estimated correctly? If you do a query
> > with only ">=", and a query with only "<=", do either of them give an
> > accurate rowcount estimate ?
>
> Dropping >= results in the correct index being used. Dropping <= doesn't
> have this effect.
This doesn't answer the question though: are the rowcount estimes accurate (say
within 10%).
It sounds like interpolating the histogram is giving a poor result, at least
over that range of values. It'd be interesting to see the entire histogram.
You might try increasing (or decreasing) the stats target for that column, and
re-analyzing.
Your histogram bounds are for ~38 months of data, and your query is for the
previous month (July).
$ date -d @1530186399
Thu Jun 28 06:46:39 CDT 2018
$ date -d @1629125609
Mon Aug 16 09:53:29 CDT 2021
$ date -d @1627369200
Tue Jul 27 02:00:00 CDT 2021
$ date -d @1624777200
Sun Jun 27 02:00:00 CDT 2021
The timestamp column has ndistinct near -1, similar to a continuous
distribution, so I'm not sure why the estimate would be so bad.
--
Justin
--
On Mon, Aug 23, 2021 at 08:53:15PM -0400, Matt Dupree wrote: > Is it possible that the row estimate is off because of a column other than > time? I would test this by writing the simplest query that reproduces the mis-estimate. > I looked at the # of events in that time period and 1.8 million is > actually a good estimate. What about the > ((strpos(other_events_1004175222.hierarchy, '#close_onborading;'::text) <> > 0) condition in the filter? It makes sense that Postgres wouldn't have a > way to estimate how selective this condition is. The issue I see is here. I don't know where else I'd start but to understand this. | Index Scan using other_events_1004175222_pim_evdef_67951aef14bc_idx on public.other_events_1004175222 (cost=0.28..1,648,877.92ROWS=1,858,891 width=32) (actual time=1.008..15.245 ROWS=23 loops=1) | Output: other_events_1004175222.user_id, other_events_1004175222."time", other_events_1004175222.session_id | Index Cond: ((other_events_1004175222."time" >= '1624777200000'::bigint) AND (other_events_1004175222."time" <= '1627369200000'::bigint)) | Buffers: shared read=25 This has no "filter" condition, it's a "scan" node with bad over-estimate. Note that this is due to the table's column stats, not any index's stats, so every plan is affected. even though some happen to work well. The consequences of over-estimates are not as terrible as for under-estimates, but it's bad to start with inputs that are off by 10^5. -- Justin