Обсуждение: Hash index build performance tweak from sorting
Hash index pages are stored in sorted order, but we don't prepare the data correctly. We sort the data as the first step of a hash index build, but we forget to sort the data by hash as well as by hash bucket. This causes the normal insert path to do extra pushups to put the data in the correct sort order on each page, which wastes effort. Adding this patch makes a CREATE INDEX about 8-9% faster, on an unlogged table. Thoughts? Aside: I'm not very sure why tuplesort has private code in it dedicated to hash indexes, but it does. Even more strangely, the Tuplesortstate fixes the size of max_buckets at tuplesort_begin() time rather than tuplesort_performsort(), forcing us to estimate the number of tuples ahead of time rather than using the exact number. Next trick would be to alter the APIs to allow exact values to be used for sorting, which would allow page at a time builds. -- Simon Riggs http://www.EnterpriseDB.com/
Вложения
On Tue, Apr 19, 2022 at 3:05 AM Simon Riggs
<simon.riggs@enterprisedb.com> wrote:
>
> Hash index pages are stored in sorted order, but we don't prepare the
> data correctly.
>
> We sort the data as the first step of a hash index build, but we
> forget to sort the data by hash as well as by hash bucket.
>
I was looking into the nearby comments (Fetch hash keys and mask off
bits we don't want to sort by.) and it sounds like we purposefully
don't want to sort by the hash key. I see that this comment was
originally introduced in the below commit:
commit 4adc2f72a4ccd6e55e594aca837f09130a6af62b
Author: Tom Lane <tgl@sss.pgh.pa.us>
Date: Mon Sep 15 18:43:41 2008 +0000
Change hash indexes to store only the hash code rather than the
whole indexed
value.
But even before that, we seem to mask off the bits before comparison.
Is it that we are doing so because we want to keep the order of hash
keys in a particular bucket so such masking was required? If so, then
maybe it is okay to compare the hash keys as you are proposing once we
find that the values fall in a particular bucket. Another thing to
note is that this code was again changed in ea69a0dead but it seems to
be following the intent of the original code.
Few comments on the patch:
1. I think it is better to use DatumGetUInt32 to fetch the hash key as
the nearby code is using.
2. You may want to change the below comment in HSpool
/*
* We sort the hash keys based on the buckets they belong to. Below masks
* are used in _hash_hashkey2bucket to determine the bucket of given hash
* key.
*/
>
> Aside:
>
> I'm not very sure why tuplesort has private code in it dedicated to
> hash indexes, but it does.
>
Are you talking about
tuplesort_begin_index_hash/comparetup_index_hash? I see the
corresponding functions for btree as well in that file.
> Even more strangely, the Tuplesortstate fixes the size of max_buckets
> at tuplesort_begin() time rather than tuplesort_performsort(), forcing
> us to estimate the number of tuples ahead of time rather than using
> the exact number. Next trick would be to alter the APIs to allow exact
> values to be used for sorting, which would allow page at a time
> builds.
>
It is not clear to me what exactly you want to do here but maybe it is
a separate topic and we should discuss this separately.
--
With Regards,
Amit Kapila.
On Sat, 30 Apr 2022 at 12:12, Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Tue, Apr 19, 2022 at 3:05 AM Simon Riggs > <simon.riggs@enterprisedb.com> wrote: > > > > Hash index pages are stored in sorted order, but we don't prepare the > > data correctly. > > > > We sort the data as the first step of a hash index build, but we > > forget to sort the data by hash as well as by hash bucket. > > > > I was looking into the nearby comments (Fetch hash keys and mask off > bits we don't want to sort by.) and it sounds like we purposefully > don't want to sort by the hash key. I see that this comment was > originally introduced in the below commit: > > commit 4adc2f72a4ccd6e55e594aca837f09130a6af62b > Author: Tom Lane <tgl@sss.pgh.pa.us> > Date: Mon Sep 15 18:43:41 2008 +0000 > > Change hash indexes to store only the hash code rather than the > whole indexed > value. > > But even before that, we seem to mask off the bits before comparison. > Is it that we are doing so because we want to keep the order of hash > keys in a particular bucket so such masking was required? We need to sort by both hash bucket and hash value. Hash bucket id so we can identify the correct hash bucket to insert into. But then on each bucket/overflow page we store it sorted by hash value to make lookup faster, so inserts go faster if they are also sorted. The pages are identical with/without this patch, its just the difference between quicksort and insertion sort. > Few comments on the patch: > 1. I think it is better to use DatumGetUInt32 to fetch the hash key as > the nearby code is using. > 2. You may want to change the below comment in HSpool > /* > * We sort the hash keys based on the buckets they belong to. Below masks > * are used in _hash_hashkey2bucket to determine the bucket of given hash > * key. > */ Many thanks, will do. > > > > Aside: ... > It is not clear to me what exactly you want to do here but maybe it is > a separate topic and we should discuss this separately. Agreed, will open another thread. -- Simon Riggs http://www.EnterpriseDB.com/
On Mon, May 2, 2022 at 9:28 PM Simon Riggs <simon.riggs@enterprisedb.com> wrote: > > On Sat, 30 Apr 2022 at 12:12, Amit Kapila <amit.kapila16@gmail.com> wrote: > > > > On Tue, Apr 19, 2022 at 3:05 AM Simon Riggs > > <simon.riggs@enterprisedb.com> wrote: > > > > > > Hash index pages are stored in sorted order, but we don't prepare the > > > data correctly. > > > > > > We sort the data as the first step of a hash index build, but we > > > forget to sort the data by hash as well as by hash bucket. > > > > > > > I was looking into the nearby comments (Fetch hash keys and mask off > > bits we don't want to sort by.) and it sounds like we purposefully > > don't want to sort by the hash key. I see that this comment was > > originally introduced in the below commit: > > > > commit 4adc2f72a4ccd6e55e594aca837f09130a6af62b > > Author: Tom Lane <tgl@sss.pgh.pa.us> > > Date: Mon Sep 15 18:43:41 2008 +0000 > > > > Change hash indexes to store only the hash code rather than the > > whole indexed > > value. > > > > But even before that, we seem to mask off the bits before comparison. > > Is it that we are doing so because we want to keep the order of hash > > keys in a particular bucket so such masking was required? > > We need to sort by both hash bucket and hash value. > > Hash bucket id so we can identify the correct hash bucket to insert into. > > But then on each bucket/overflow page we store it sorted by hash value > to make lookup faster, so inserts go faster if they are also sorted. > I also think so. So, we should go with this unless someone else sees any flaw here. -- With Regards, Amit Kapila.
On Sat, 30 Apr 2022 at 12:12, Amit Kapila <amit.kapila16@gmail.com> wrote: > > Few comments on the patch: > 1. I think it is better to use DatumGetUInt32 to fetch the hash key as > the nearby code is using. > 2. You may want to change the below comment in HSpool > /* > * We sort the hash keys based on the buckets they belong to. Below masks > * are used in _hash_hashkey2bucket to determine the bucket of given hash > * key. > */ Addressed in new patch, v2. On Wed, 4 May 2022 at 11:27, Amit Kapila <amit.kapila16@gmail.com> wrote: > > So, we should go with this unless someone else sees any flaw here. Cool, thanks. -- Simon Riggs http://www.EnterpriseDB.com/
Вложения
On Tue, May 10, 2022 5:43 PM Simon Riggs <simon.riggs@enterprisedb.com> wrote: > > On Sat, 30 Apr 2022 at 12:12, Amit Kapila <amit.kapila16@gmail.com> > wrote: > > > > Few comments on the patch: > > 1. I think it is better to use DatumGetUInt32 to fetch the hash key as > > the nearby code is using. > > 2. You may want to change the below comment in HSpool > > /* > > * We sort the hash keys based on the buckets they belong to. Below > masks > > * are used in _hash_hashkey2bucket to determine the bucket of given > hash > > * key. > > */ > > Addressed in new patch, v2. > I think your changes looks reasonable. Besides, I tried this patch with Simon's script, and index creation time was about 7.5% faster after applying this patch on my machine, which looks good to me. RESULT - index creation time =================== HEAD: 9513.466 ms Patched: 8796.75 ms I ran it 10 times and got the average, and here are the configurations used in the test: shared_buffers = 2GB checkpoint_timeout = 30min max_wal_size = 20GB min_wal_size = 10GB autovacuum = off Regards, Shi yu
On Monday, May 30, 2022 4:13 PMshiy.fnst@fujitsu.com <shiy.fnst@fujitsu.com> wrote: > > On Tue, May 10, 2022 5:43 PM Simon Riggs <simon.riggs@enterprisedb.com> > wrote: > > > > On Sat, 30 Apr 2022 at 12:12, Amit Kapila <amit.kapila16@gmail.com> > > wrote: > > > > > > Few comments on the patch: > > > 1. I think it is better to use DatumGetUInt32 to fetch the hash key > > > as the nearby code is using. > > > 2. You may want to change the below comment in HSpool > > > /* > > > * We sort the hash keys based on the buckets they belong to. Below > > masks > > > * are used in _hash_hashkey2bucket to determine the bucket of given > > hash > > > * key. > > > */ > > > > Addressed in new patch, v2. > > > > I think your changes looks reasonable. +1, the changes look good to me as well. Best regards, Hou zj
Simon Riggs <simon.riggs@enterprisedb.com> writes:
> [ hash_sort_by_hash.v2.patch ]
The cfbot says this no longer applies --- probably sideswiped by
Korotkov's sorting-related commits last night.
regards, tom lane
On Wed, 27 Jul 2022 at 19:22, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Simon Riggs <simon.riggs@enterprisedb.com> writes: > > [ hash_sort_by_hash.v2.patch ] > > The cfbot says this no longer applies --- probably sideswiped by > Korotkov's sorting-related commits last night. Thanks for the nudge. New version attached. -- Simon Riggs http://www.EnterpriseDB.com/
Вложения
Simon Riggs <simon.riggs@enterprisedb.com> writes:
> Thanks for the nudge. New version attached.
I also see a speed improvement from this, so pushed (after minor comment
editing). I notice though that if I feed it random data,
---
DROP TABLE IF EXISTS hash_speed;
CREATE unlogged TABLE hash_speed (x integer);
INSERT INTO hash_speed SELECT random()*10000000 FROM
generate_series(1,10000000) x;
vacuum hash_speed;
\timing on
CREATE INDEX ON hash_speed USING hash (x);
---
then the speed improvement is only about 5% not the 7.5% I see
with your original test case. I don't have an explanation
for that, do you?
Also, it seems like we've left some money on the table by not
exploiting downstream the knowledge that this sorting happened.
During an index build, it's no longer necessary for
_hash_pgaddtup to do _hash_binsearch, and therefore also not
_hash_get_indextuple_hashkey: we could just always append the new
tuple at the end. Perhaps checking it against the last existing
tuple is worth the trouble as a bug guard, but for sure we don't
need the log2(N) comparisons that _hash_binsearch will do.
Another point that I noticed is that it's not really desirable to
use the same _hash_binsearch logic for insertions and searches.
_hash_binsearch finds the first entry with hash >= target, which
is necessary for searches, but for insertions we'd really rather
find the first entry with hash > target. As things stand, to
the extent that there are duplicate hash values we are still
performing unnecessary data motion within PageAddItem.
I've not looked into how messy these things would be to implement,
nor whether we get any noticeable speed gain thereby. But since
you've proven that cutting the PageAddItem data motion cost
yields visible savings, these things might be visible too.
At this point the cfbot will start to bleat that the patch of
record doesn't apply, so I'm going to mark the CF entry committed.
If anyone wants to produce a follow-on patch, please make a
new entry.
regards, tom lane
On Thu, 28 Jul 2022 at 19:50, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Simon Riggs <simon.riggs@enterprisedb.com> writes: > > Thanks for the nudge. New version attached. > > I also see a speed improvement from this, so pushed (after minor comment > editing). Thanks > I notice though that if I feed it random data, > > --- > DROP TABLE IF EXISTS hash_speed; > CREATE unlogged TABLE hash_speed (x integer); > INSERT INTO hash_speed SELECT random()*10000000 FROM > generate_series(1,10000000) x; > vacuum hash_speed; > \timing on > CREATE INDEX ON hash_speed USING hash (x); > --- > > then the speed improvement is only about 5% not the 7.5% I see > with your original test case. I don't have an explanation > for that, do you? No, sorry. It could be a data-based effect or a physical effect. > Also, it seems like we've left some money on the table by not > exploiting downstream the knowledge that this sorting happened. > During an index build, it's no longer necessary for > _hash_pgaddtup to do _hash_binsearch, and therefore also not > _hash_get_indextuple_hashkey: we could just always append the new > tuple at the end. Perhaps checking it against the last existing > tuple is worth the trouble as a bug guard, but for sure we don't > need the log2(N) comparisons that _hash_binsearch will do. Hmm, I had that in an earlier version of the patch, not sure why it dropped out since I wrote it last year, but then I've got lots of future WIP patches in the area of hash indexes. > Another point that I noticed is that it's not really desirable to > use the same _hash_binsearch logic for insertions and searches. > _hash_binsearch finds the first entry with hash >= target, which > is necessary for searches, but for insertions we'd really rather > find the first entry with hash > target. As things stand, to > the extent that there are duplicate hash values we are still > performing unnecessary data motion within PageAddItem. That thought is new to me, and will investigate. > I've not looked into how messy these things would be to implement, > nor whether we get any noticeable speed gain thereby. But since > you've proven that cutting the PageAddItem data motion cost > yields visible savings, these things might be visible too. It's a clear follow-on thought, so will pursue. Thanks for the nudge. > At this point the cfbot will start to bleat that the patch of > record doesn't apply, so I'm going to mark the CF entry committed. > If anyone wants to produce a follow-on patch, please make a > new entry. Will do. Thanks. -- Simon Riggs http://www.EnterpriseDB.com/
On Fri, 29 Jul 2022 at 13:49, Simon Riggs <simon.riggs@enterprisedb.com> wrote: > > On Thu, 28 Jul 2022 at 19:50, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > > > Simon Riggs <simon.riggs@enterprisedb.com> writes: > > > Thanks for the nudge. New version attached. > > > > I also see a speed improvement from this > > --- > > DROP TABLE IF EXISTS hash_speed; > > CREATE unlogged TABLE hash_speed (x integer); > > INSERT INTO hash_speed SELECT random()*10000000 FROM > > generate_series(1,10000000) x; > > vacuum hash_speed; > > \timing on > > CREATE INDEX ON hash_speed USING hash (x); > > --- > > Also, it seems like we've left some money on the table by not > > exploiting downstream the knowledge that this sorting happened. > > During an index build, it's no longer necessary for > > _hash_pgaddtup to do _hash_binsearch, and therefore also not > > _hash_get_indextuple_hashkey: we could just always append the new > > tuple at the end. Perhaps checking it against the last existing > > tuple is worth the trouble as a bug guard, but for sure we don't > > need the log2(N) comparisons that _hash_binsearch will do. > > Hmm, I had that in an earlier version of the patch, not sure why it > dropped out since I wrote it last year, but then I've got lots of > future WIP patches in the area of hash indexes. ... > > At this point the cfbot will start to bleat that the patch of > > record doesn't apply, so I'm going to mark the CF entry committed. > > If anyone wants to produce a follow-on patch, please make a > > new entry. > > Will do. Thanks. Using the above test case, I'm getting a further 4-7% improvement on already committed code with the attached patch, which follows your proposal. The patch passes info via a state object, useful to avoid API churn in later patches. Adding to CFapp again. -- Simon Riggs http://www.EnterpriseDB.com/
Вложения
On 2022-08-01 8:37 a.m., Simon Riggs wrote: > Using the above test case, I'm getting a further 4-7% improvement on > already committed code with the attached patch, which follows your > proposal. I ran two test cases: for committed patch `hash_sort_by_hash.v3.patch`, I can see about 6 ~ 7% improvement; and after appliedpatch `hash_inserted_sorted.v2.patch`, I see about ~3% improvement. All the test results are based on 10 times averageon two different machines. Best regards, -- David Software Engineer Highgo Software Inc. (Canada) www.highgo.ca
On Fri, 5 Aug 2022 at 20:46, David Zhang <david.zhang@highgo.ca> wrote: > > On 2022-08-01 8:37 a.m., Simon Riggs wrote: > > Using the above test case, I'm getting a further 4-7% improvement on > > already committed code with the attached patch, which follows your > > proposal. > > I ran two test cases: for committed patch `hash_sort_by_hash.v3.patch`, I can see about 6 ~ 7% improvement; and after appliedpatch `hash_inserted_sorted.v2.patch`, I see about ~3% improvement. All the test results are based on 10 times averageon two different machines. Thanks for testing David. It's a shame you only see 3%, but that's still worth it. -- Simon Riggs http://www.EnterpriseDB.com/
>It's a shame you only see 3%, but that's still worth it.
Hi,
I ran this test here:
DROP TABLE hash_speed;
CREATE unlogged TABLE hash_speed (x integer);
INSERT INTO hash_speed SELECT random()*10000000 FROM generate_series(1,10000000) x;
VACUUM
Timing is on.
CREATE INDEX ON hash_speed USING hash (x);
CREATE unlogged TABLE hash_speed (x integer);
INSERT INTO hash_speed SELECT random()*10000000 FROM generate_series(1,10000000) x;
VACUUM
Timing is on.
CREATE INDEX ON hash_speed USING hash (x);
head:
Time: 20526,490 ms (00:20,526)
attached patch (v3):
Time: 18810,777 ms (00:18,811)
I can see 9%, with the patch (v3) attached.
This optimization would not apply in any way also to _hash_pgaddmultitup?
regards,
Ranier Vilela
Вложения
On Tue, 2 Aug 2022 at 03:37, Simon Riggs <simon.riggs@enterprisedb.com> wrote: > Using the above test case, I'm getting a further 4-7% improvement on > already committed code with the attached patch, which follows your > proposal. > > The patch passes info via a state object, useful to avoid API churn in > later patches. Hi Simon, I took this patch for a spin and saw a 2.5% performance increase using the random INT test that Tom posted. The index took an average of 7227.47 milliseconds on master and 7045.05 with the patch applied. On making a pass of the changes, I noted down a few things. 1. In _h_spoolinit() the HSpool is allocated with palloc and then you're setting the istate field to a pointer to the HashInsertState which is allocated on the stack by the only calling function (hashbuild()). Looking at hashbuild(), it looks like the return value of _h_spoolinit is never put anywhere to make it available outside of the function, so it does not seem like there is an actual bug there. However, it just seems like a bug waiting to happen. If _h_spoolinit() is pallocing memory, then we really shouldn't be setting pointer fields in that memory to point to something on the stack. It might be nicer if the istate field in HSpool was a HashInsertStateData and _h_spoolinit() just memcpy'd the contents of that parameter. That would make HSpool 4 bytes smaller and save additional pointer dereferences in _hash_doinsert(). 2. There are quite a few casts that are not required. e.g: _hash_doinsert(rel, itup, heapRel, (HashInsertState) &istate); buildstate.spool = _h_spoolinit(heap, index, num_buckets, (HashInsertState) &insertstate); buildstate.istate = (HashInsertState) &insertstate; This is just my opinion, but I don't really see the value in having a typedef for a pointer to HashInsertStateData. I can understand that if the struct was local to a .c file, but you've got the struct and pointer typedef in the same header. I understand we often do this in the code, but I feel like we do it less often in newer code. e.g we do it in aset.c but not generation.c (which is much newer than aset.c). My personal preference would be just to name the struct HashInsertState and have no extra pointer typedefs. 3. Just a minor nitpick. Line wraps at 80 chars. You're doing this sometimes but not others. This seems just to be due to the additional function parameters that have been added. 4. I added the following Assert to _hash_pgaddtup() as I expected the itup_off to be set to the same thing before and after this change. I see the Assert is failing in the regression tests. Assert(PageGetMaxOffsetNumber(page) + 1 == _hash_binsearch(page, _hash_get_indextuple_hashkey(itup))); I think this is because _hash_binsearch() returns the offset with the first tuple with the given hashkey, so if there are duplicate hashkey values then it looks like PageAddItemExtended() will set needshuffle and memmove() the existing item(s) up one slot. I don't know this hash index building code very well, but I wonder if it's worth having another version of _hash_binsearch() that can be used to make _hash_pgaddtup() put any duplicate hashkeys after the existing ones rather than before and shuffle the others up? It sounds like that might speed up normal insertions when there are many duplicate values to hash. I wonder if this might be the reason the random INT test didn't come out as good as your original test which had unique values. The unique values test would do less shuffling during PageAddItemExtended(). If so, that implies that skipping the binary search is only part of the gains here and that not shuffling tuples accounts for quite a bit of the gain you're seeing. If so, then it would be good to not have to shuffle duplicate hashkey tuples up in the page during normal insertions as well as when building the index. In any case, it would be nice to have some way to assert that we don't accidentally pass sorted==true to _hash_pgaddtup() when there's an existing item on the page with a higher hash value. Maybe we could just look at the hash value of the last tuple on the page and ensure it's <= to the current one? 5. I think it would be nicer to move the insertstate.sorted = false; into the else branch in hashbuild(). However, you might have to do that anyway if you were to do what I mentioned in #1. David
On Wed, 21 Sept 2022 at 02:32, David Rowley <dgrowleyml@gmail.com> wrote: > > On Tue, 2 Aug 2022 at 03:37, Simon Riggs <simon.riggs@enterprisedb.com> wrote: > > Using the above test case, I'm getting a further 4-7% improvement on > > already committed code with the attached patch, which follows your > > proposal. > > > > The patch passes info via a state object, useful to avoid API churn in > > later patches. > > Hi Simon, > > I took this patch for a spin and saw a 2.5% performance increase using > the random INT test that Tom posted. The index took an average of > 7227.47 milliseconds on master and 7045.05 with the patch applied. Hi David, Thanks for tests and review. I'm just jumping on a plane, so may not respond in detail until next Mon. -- Simon Riggs http://www.EnterpriseDB.com/
On Wed, Sep 21, 2022 at 12:43:15PM +0100, Simon Riggs wrote: > Thanks for tests and review. I'm just jumping on a plane, so may not > respond in detail until next Mon. Okay. If you have time to address that by next CF, that would be interesting. For now I have marked the entry as returned with feedback. -- Michael
Вложения
On Wed, 21 Sept 2022 at 02:32, David Rowley <dgrowleyml@gmail.com> wrote: > > I took this patch for a spin and saw a 2.5% performance increase using > the random INT test that Tom posted. The index took an average of > 7227.47 milliseconds on master and 7045.05 with the patch applied. Thanks for the review, apologies for the delay in acting upon your comments. My tests show the sorted and random tests are BOTH 4.6% faster with the v3 changes using 5-test avg, but you'll be pleased to know your kit is about 15.5% faster than mine, comparing absolute execution times. > On making a pass of the changes, I noted down a few things. > 2. There are quite a few casts that are not required. e.g: > > _hash_doinsert(rel, itup, heapRel, (HashInsertState) &istate); > buildstate.spool = _h_spoolinit(heap, index, num_buckets, > (HashInsertState) &insertstate); > buildstate.istate = (HashInsertState) &insertstate; Removed > 3. Just a minor nitpick. Line wraps at 80 chars. You're doing this > sometimes but not others. This seems just to be due to the additional > function parameters that have been added. Done > 4. I added the following Assert to _hash_pgaddtup() as I expected the > itup_off to be set to the same thing before and after this change. I > see the Assert is failing in the regression tests. > > Assert(PageGetMaxOffsetNumber(page) + 1 == > _hash_binsearch(page, _hash_get_indextuple_hashkey(itup))); > > I think this is because _hash_binsearch() returns the offset with the > first tuple with the given hashkey, so if there are duplicate hashkey > values then it looks like PageAddItemExtended() will set needshuffle > and memmove() the existing item(s) up one slot. I don't know this > hash index building code very well, but I wonder if it's worth having > another version of _hash_binsearch() that can be used to make > _hash_pgaddtup() put any duplicate hashkeys after the existing ones > rather than before and shuffle the others up? It sounds like that > might speed up normal insertions when there are many duplicate values > to hash. Sounds reasonable. I tried changing src/backend/access/hash/hashinsert.c, line 307 (on patched file) from - itup_off = _hash_binsearch(page, hashkey); to + itup_off = _hash_binsearch_last(page, hashkey) + 1; since exactly such a function already exists in code. But this seems to cause a consistent ~1% regression in performance, which surprises me. Test was the random INSERT SELECT with 10E6 rows after the CREATE INDEX. Not sure what to suggest, but the above change is not included in v3. > I wonder if this might be the reason the random INT test didn't come > out as good as your original test which had unique values. The unique > values test would do less shuffling during PageAddItemExtended(). If > so, that implies that skipping the binary search is only part of the > gains here and that not shuffling tuples accounts for quite a bit of > the gain you're seeing. If so, then it would be good to not have to > shuffle duplicate hashkey tuples up in the page during normal > insertions as well as when building the index. There is still a 1.4% lead for the sorted test over the random one, in my tests. > In any case, it would be nice to have some way to assert that we don't > accidentally pass sorted==true to _hash_pgaddtup() when there's an > existing item on the page with a higher hash value. Maybe we could > just look at the hash value of the last tuple on the page and ensure > it's <= to the current one? Done > 5. I think it would be nicer to move the insertstate.sorted = false; > into the else branch in hashbuild(). However, you might have to do > that anyway if you were to do what I mentioned in #1. Done > 1. In _h_spoolinit() the HSpool is allocated with palloc and then > you're setting the istate field to a pointer to the HashInsertState > which is allocated on the stack by the only calling function > (hashbuild()). Looking at hashbuild(), it looks like the return value > of _h_spoolinit is never put anywhere to make it available outside of > the function, so it does not seem like there is an actual bug there. > However, it just seems like a bug waiting to happen. If _h_spoolinit() > is pallocing memory, then we really shouldn't be setting pointer > fields in that memory to point to something on the stack. It might be > nicer if the istate field in HSpool was a HashInsertStateData and > _h_spoolinit() just memcpy'd the contents of that parameter. That > would make HSpool 4 bytes smaller and save additional pointer > dereferences in _hash_doinsert(). > This is just my opinion, but I don't really see the value in having a > typedef for a pointer to HashInsertStateData. I can understand that if > the struct was local to a .c file, but you've got the struct and > pointer typedef in the same header. I understand we often do this in > the code, but I feel like we do it less often in newer code. e.g we do > it in aset.c but not generation.c (which is much newer than aset.c). > My personal preference would be just to name the struct > HashInsertState and have no extra pointer typedefs. Not done, but not disagreeing either, just not very comfortable actually making those changes. -- Simon Riggs http://www.EnterpriseDB.com/
Вложения
Hi,
I did some simple benchmark with v2 and v3, using the attached script,
which essentially just builds hash index on random data, with different
data types and maintenance_work_mem values. And what I see is this
(median of 10 runs):
machine data type m_w_m master v2 v3
------------------------------------------------------------
i5 bigint 128MB 9652 9402 9669
32MB 9545 9291 9535
4MB 9599 9371 9741
int 128MB 9666 9475 9676
32MB 9530 9347 9528
4MB 9595 9394 9624
text 128MB 9755 9596 9897
32MB 9711 9547 9846
4MB 9808 9744 10024
xeon bigint 128MB 10790 10555 10812
32MB 10690 10373 10579
4MB 10682 10351 10650
int 128MB 11258 10550 10712
32MB 10963 10272 10410
4MB 11152 10366 10589
text 128MB 10935 10694 10930
32MB 10822 10672 10861
4MB 10835 10684 10895
Or, relative to master:
machine data type memory v2 v3
----------------------------------------------------------
i5 bigint 128MB 97.40% 100.17%
32MB 97.34% 99.90%
4MB 97.62% 101.48%
int 128MB 98.03% 100.11%
32MB 98.08% 99.98%
4MB 97.91% 100.31%
text 128MB 98.37% 101.46%
32MB 98.32% 101.40%
4MB 99.35% 102.20%
xeon bigint 128MB 97.82% 100.20%
32MB 97.03% 98.95%
4MB 96.89% 99.70%
int 128MB 93.71% 95.15%
32MB 93.70% 94.95%
4MB 92.95% 94.95%
text 128MB 97.80% 99.96%
32MB 98.62% 100.36%
4MB 98.61% 100.55%
So to me it seems v2 performs demonstrably better, v3 is consistently
slower - not only compared to v2, but often also to master.
Attached is the script I used and the raw results - this includes also
results for logged tables - the improvement is smaller, but the
conclusions are otherwise similar.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Вложения
On Wed, 16 Nov 2022 at 17:33, Simon Riggs <simon.riggs@enterprisedb.com> wrote: > > Thanks for the review, apologies for the delay in acting upon your comments. > > My tests show the sorted and random tests are BOTH 4.6% faster with > the v3 changes using 5-test avg, but you'll be pleased to know your > kit is about 15.5% faster than mine, comparing absolute execution > times. Thanks for the updated patch. I started to look at this again and I'm starting to think that the HashInsertState struct is the wrong approach for passing along the sorted flag to _hash_doinsert(). The reason I think this is that in hashbuild() when setting buildstate.spool to NULL, you're also making the decision about what to set the sorted flag to. However, in reality, we already know what we should be passing *every* time we call _hash_doinsert(). The only place where we can pass the sorted option as true is in _h_indexbuild() when we're doing the sorted version of the index build. Trying to make that decision any sooner seems error-prone. I understand you have made HashInsertState so that we don't need to add new parameters should we ever need to pass something else along, but I'm just thinking that if we ever need to add more, then we should just reconsider this in the future. I think for today, the better option is just to add the bool sorted as a parameter to _hash_doinsert() and pass it as true in the single case where it's valid to do so. That seems less likely that we'll inherit some options from some other place after some future modification and end up passing sorted as true when it should be false. Another reason I didn't like the HashInsertState idea is that in the v3 patch there's an HashInsertState in both HashBuildState and HSpool. Because in the normal insert path (hashinsert), we've neither a HashBuildState nor an HSpool, you're having to fake up a HashInsertStateData to pass something along to _hash_doinsert() in hashinsert(). When we're building an index, in the non-sorted index build case, you're always passing the HashInsertStateData from the HashBuildState, but when we're doing the sorted index build the one from HSpool is passed. In other words, in each of the 3 calls to _hash_doinsert(), the HashInsertStateData comes from a different place. Now, I do see that you've coded hashbuild() so both versions of the HashInsertState point to the same HashInsertStateData, but I find it unacceptable programming that in _h_spoolinit() the code palloc's the memory for the HSpool and you're setting the istate field to the HashInsertStateData that's on the stack. That just seems like a great way to end up having istate pointing to junk should the HSpool ever live beyond the hashbuild() call. If we really don't want HSpool to live beyond hashbuild(), then it too should be a local variable to hashbuild() instead of being palloc'ed in _h_spoolinit(). _h_spoolinit() could just be passed a pointer to the HSpool to populate. After getting rid of the HashInsertState code and just adding bool sorted to _hash_doinsert() and _hash_pgaddtup(), the resulting patch is much more simple: v3: src/backend/access/hash/hash.c | 19 ++++++++++++++++--- src/backend/access/hash/hashinsert.c | 40 ++++++++++++++++++++++++++++++++++------ src/backend/access/hash/hashsort.c | 8 ++++++-- src/include/access/hash.h | 14 +++++++++++--- 4 files changed, 67 insertions(+), 14 deletions(-) v4: src/backend/access/hash/hash.c | 4 ++-- src/backend/access/hash/hashinsert.c | 40 ++++++++++++++++++++++++++++-------- src/backend/access/hash/hashsort.c | 3 ++- src/include/access/hash.h | 6 ++++-- 4 files changed, 40 insertions(+), 13 deletions(-) and v4 includes 7 extra lines in hashinsert.c for the Assert() I mentioned in my previous email plus a bunch of extra comments. I'd rather see this solved like v4 is doing it. David
Вложения
On Fri, 18 Nov 2022 at 03:34, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > I did some simple benchmark with v2 and v3, using the attached script, > which essentially just builds hash index on random data, with different > data types and maintenance_work_mem values. And what I see is this > (median of 10 runs): > So to me it seems v2 performs demonstrably better, v3 is consistently > slower - not only compared to v2, but often also to master. Could this just be down to code alignment changes? There does not really seem to be any fundamental differences which would explain this. David
On Wed, 23 Nov 2022 at 13:04, David Rowley <dgrowleyml@gmail.com> wrote: > After getting rid of the HashInsertState code and just adding bool > sorted to _hash_doinsert() and _hash_pgaddtup(), the resulting patch > is much more simple: Seems good to me and I wouldn't argue with any of your comments. > and v4 includes 7 extra lines in hashinsert.c for the Assert() I > mentioned in my previous email plus a bunch of extra comments. Oh, I did already include that in v3 as requested. > I'd rather see this solved like v4 is doing it. Please do. No further comments. Thanks for your help -- Simon Riggs http://www.EnterpriseDB.com/
On 11/23/22 14:07, David Rowley wrote: > On Fri, 18 Nov 2022 at 03:34, Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> I did some simple benchmark with v2 and v3, using the attached script, >> which essentially just builds hash index on random data, with different >> data types and maintenance_work_mem values. And what I see is this >> (median of 10 runs): > >> So to me it seems v2 performs demonstrably better, v3 is consistently >> slower - not only compared to v2, but often also to master. > > Could this just be down to code alignment changes? There does not > really seem to be any fundamental differences which would explain > this. > Could be, but then how do we know the speedup with v2 is not due to code alignment too? regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
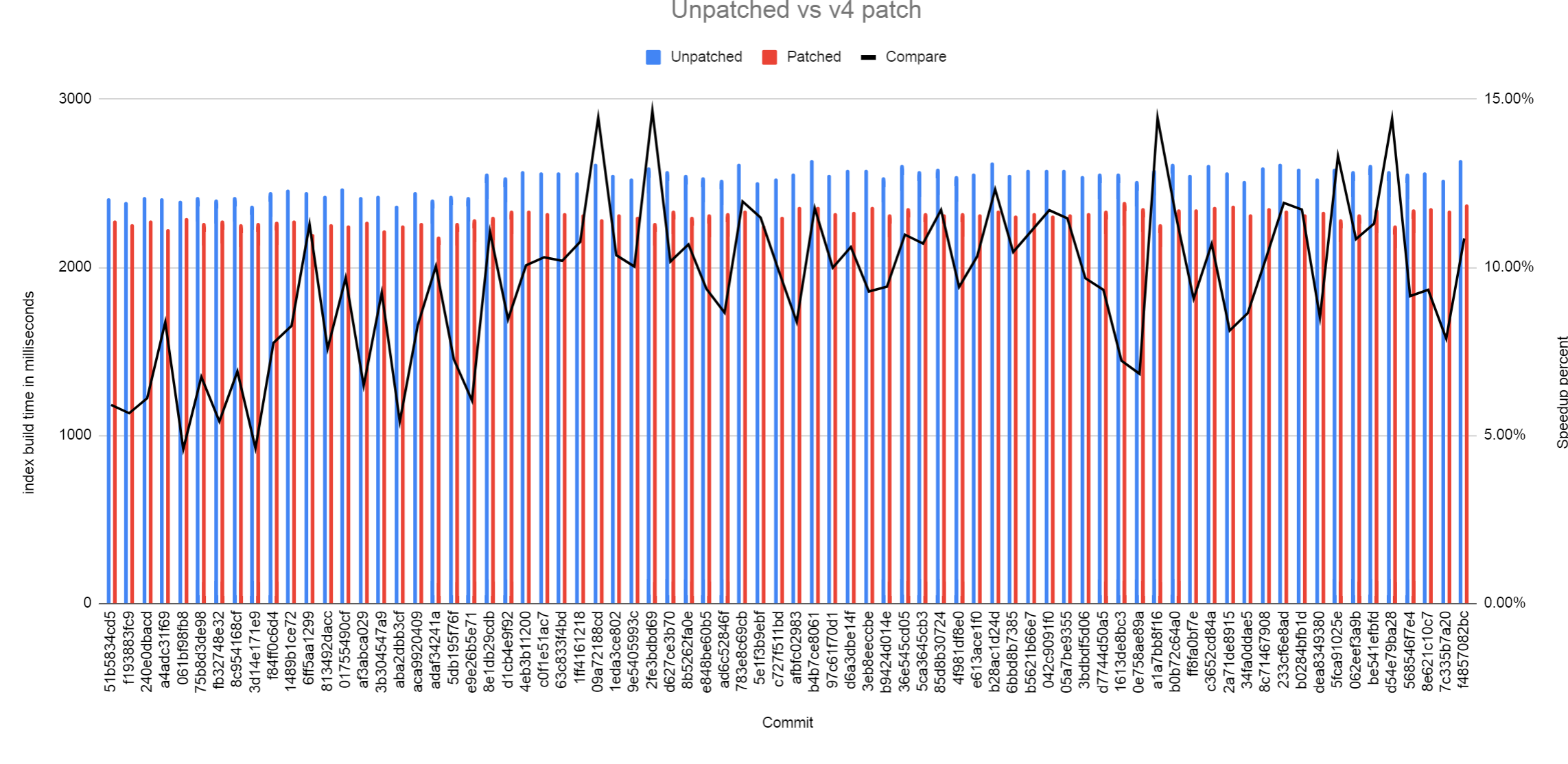
On Thu, 24 Nov 2022 at 08:08, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > >> So to me it seems v2 performs demonstrably better, v3 is consistently > >> slower - not only compared to v2, but often also to master. > > > > Could this just be down to code alignment changes? There does not > > really seem to be any fundamental differences which would explain > > this. > > > > Could be, but then how do we know the speedup with v2 is not due to code > alignment too? It's a good question. Back when I was working on 913ec71d6, I had similar problems that I saw wildly different performance gains depending on which commit I patched with. I sorted that out by just benchmarking on a bunch of different commits both patched and unpatched. I've attached a crude bash script which looks at every commit since 1st November 2022 that's changed anything in src/backend/* and runs a benchmark with and without the v4 patch. That was 76 commits when I tested. In each instance, with the test I ran, I saw between a 5 and 15% performance improvement with the v4 patch. No commit showed any performance regression. That makes me fairly happy that there's a genuine win with this patch. I've attached the script and the benchmark files along with the results and a chart. David
Вложения
{kind=link}
On Thu, 24 Nov 2022 at 02:27, Simon Riggs <simon.riggs@enterprisedb.com> wrote: > > On Wed, 23 Nov 2022 at 13:04, David Rowley <dgrowleyml@gmail.com> wrote: > > I'd rather see this solved like v4 is doing it. > > Please do. No further comments. Thanks for your help Thanks. I pushed the v4 patch with some minor comment adjustments and also renamed _hash_pgaddtup()'s new parameter to "appendtup". I felt that better reflected what the parameter does in that function. David