Обсуждение: analyze foreign tables
1. manually run analyze on each foreign table in each database that points to the host table
On Tue, 2023-08-01 at 09:47 -0400, richard coleman wrote: > In PostgreSQL foreign tables are not automatically analyzed and analyze must be > specifically called on each table. In the case of sharing tables between > PostgreSQL clusters, there is the use_remote_estimate foreign server option. > > In some of our multi terabyte databases, manually running analyze on all of > the foreign tables can take more than a day. This is per database containing > the foreign schema. Since we have certain large schema that we have centrally > located and share to all of our other database clusters, this really adds up. > > use_remote_estimate isn't really a solution as it adds way too much overhead > and processing time to every query run. > > Since these tables are being continuously analyzed in the database that hosts > the data, is there some way that they statistics could be easily passed through > the foreign server mechanism to the remote database that's calling the query? > > Unless I'm missing something we can either: > 1. manually run analyze on each foreign table in each database that points to > the host table > 2. set use_remote_estimate = true which will cause PostgreSQL to re-obtain > statistics on a per query basis. > > What I am hoping for is either: > 1. pass through the results of analyze from the source database to the one > where the foreign query is being run > 2. add the ability to automatically run analyze on foreign tables just as they > are currently run on local tables. > > Of the two, #1 would seem to be the easiest and least wasteful of resources. Unfortunately, both your wishes don't look feasible: - Transferring table statistics would mean that PostgreSQL understands statistics from other server versions. This is complicated, and we have decided not to do this for pg_upgrade, so I don't think we'll try to do it here. - Autoanalyzing foreign tables would mean that we have some idea how much data has changed on the remote server. How should we do that? What I can imagine is that instead of reading the complete remote table during ANALYZE, PostgreSQL applies TABLESAMPLE to fetch only part. That could be a workable enhancement. Yours, Laurenz Albe
On Tue, 2023-08-01 at 09:47 -0400, richard coleman wrote:
> In PostgreSQL foreign tables are not automatically analyzed and analyze must be
> specifically called on each table. In the case of sharing tables between
> PostgreSQL clusters, there is the use_remote_estimate foreign server option.
>
> In some of our multi terabyte databases, manually running analyze on all of
> the foreign tables can take more than a day. This is per database containing
> the foreign schema. Since we have certain large schema that we have centrally
> located and share to all of our other database clusters, this really adds up.
>
> use_remote_estimate isn't really a solution as it adds way too much overhead
> and processing time to every query run.
>
> Since these tables are being continuously analyzed in the database that hosts
> the data, is there some way that they statistics could be easily passed through
> the foreign server mechanism to the remote database that's calling the query?
>
> Unless I'm missing something we can either:
> 1. manually run analyze on each foreign table in each database that points to
> the host table
> 2. set use_remote_estimate = true which will cause PostgreSQL to re-obtain
> statistics on a per query basis.
>
> What I am hoping for is either:
> 1. pass through the results of analyze from the source database to the one
> where the foreign query is being run
> 2. add the ability to automatically run analyze on foreign tables just as they
> are currently run on local tables.
>
> Of the two, #1 would seem to be the easiest and least wasteful of resources.
Unfortunately, both your wishes don't look feasible:
- Transferring table statistics would mean that PostgreSQL understands statistics
from other server versions. This is complicated, and we have decided not to
do this for pg_upgrade, so I don't think we'll try to do it here.
- Autoanalyzing foreign tables would mean that we have some idea how much data
has changed on the remote server. How should we do that?
What I can imagine is that instead of reading the complete remote table during
ANALYZE, PostgreSQL applies TABLESAMPLE to fetch only part. That could be a
workable enhancement.
Yours,
Laurenz Albe
I just do it like this per table. Might not solve your exact issue, but another option. You can scale down the analyze factor to something very small like 0.00000001
-- Find current setting (this is at database level)
select * from pg_settings where name in ('autovacuum','autovacuum_analyze_scale_factor','autovacuum_analyze_threshold','autovacuum_vacuum_scale_factor');
select current_setting('autovacuum_vacuum_scale_factor') as "analyze_scale_factor",current_setting('autovacuum_vacuum_threshold') as "vacuum_threshold";
select current_setting('autovacuum_analyze_scale_factor') as "analyze_scale_factor", current_setting('autovacuum_analyze_threshold') as "analyze_threshold";
-- Note: The smaller number = more aggressive = vacuum more frequence
-- Current:
-- autovacuum_analyze_scale_factor = 0.05 ---> 0.002
-- autovacuum_vacuum_scale_factor = 0.1 ---> 0.001
-- Fine Tune at table level = ALTER TABLE mytable SET (autovacuum_analyze_scale_factor = 0.02);
ALTER TABLE your_schema.your_table SET (autovacuum_enabled = true,autovacuum_analyze_scale_factor = 0.002,autovacuum_vacuum_scale_factor = 0.001);
-- Put it back to use global setting
ALTER TABLE your_schema.your_table RESET (autovacuum_enabled,autovacuum_analyze_scale_factor,autovacuum_vacuum_scale_factor);
From: richard coleman <rcoleman.ascentgl@gmail.com>
Sent: Tuesday, August 1, 2023 9:36 AM
To: Laurenz Albe <laurenz.albe@cybertec.at>
Cc: Pgsql-admin <pgsql-admin@lists.postgresql.org>
Subject: [EXTERNAL] Re: analyze foreign tables
Laurenz,
Thanks for taking the time to respond.
Right now I'm stuck with cronning a script to manually run analyze on every foreign table in every database, which in our case is most of them.
Would it be possible to transfer table statistics between the same version of PostgreSQL, ex: source is pg15, target is pg15?
Otherwise, anything that can be done to speed this up would be very helpful.
Thanks again,
rik.
On Tue, Aug 1, 2023 at 12:16 PM Laurenz Albe <laurenz.albe@cybertec.at> wrote:
On Tue, 2023-08-01 at 09:47 -0400, richard coleman wrote:
> In PostgreSQL foreign tables are not automatically analyzed and analyze must be
> specifically called on each table. In the case of sharing tables between
> PostgreSQL clusters, there is the use_remote_estimate foreign server option.
>
> In some of our multi terabyte databases, manually running analyze on all of
> the foreign tables can take more than a day. This is per database containing
> the foreign schema. Since we have certain large schema that we have centrally
> located and share to all of our other database clusters, this really adds up.
>
> use_remote_estimate isn't really a solution as it adds way too much overhead
> and processing time to every query run.
>
> Since these tables are being continuously analyzed in the database that hosts
> the data, is there some way that they statistics could be easily passed through
> the foreign server mechanism to the remote database that's calling the query?
>
> Unless I'm missing something we can either:
> 1. manually run analyze on each foreign table in each database that points to
> the host table
> 2. set use_remote_estimate = true which will cause PostgreSQL to re-obtain
> statistics on a per query basis.
>
> What I am hoping for is either:
> 1. pass through the results of analyze from the source database to the one
> where the foreign query is being run
> 2. add the ability to automatically run analyze on foreign tables just as they
> are currently run on local tables.
>
> Of the two, #1 would seem to be the easiest and least wasteful of resources.
Unfortunately, both your wishes don't look feasible:
- Transferring table statistics would mean that PostgreSQL understands statistics
from other server versions. This is complicated, and we have decided not to
do this for pg_upgrade, so I don't think we'll try to do it here.
- Autoanalyzing foreign tables would mean that we have some idea how much data
has changed on the remote server. How should we do that?
What I can imagine is that instead of reading the complete remote table during
ANALYZE, PostgreSQL applies TABLESAMPLE to fetch only part. That could be a
workable enhancement.
Yours,
Laurenz Albe
I just do it like this per table. Might not solve your exact issue, but another option. You can scale down the analyze factor to something very small like 0.00000001
-- Find current setting (this is at database level)
select * from pg_settings where name in ('autovacuum','autovacuum_analyze_scale_factor','autovacuum_analyze_threshold','autovacuum_vacuum_scale_factor');
select current_setting('autovacuum_vacuum_scale_factor') as "analyze_scale_factor",current_setting('autovacuum_vacuum_threshold') as "vacuum_threshold";
select current_setting('autovacuum_analyze_scale_factor') as "analyze_scale_factor", current_setting('autovacuum_analyze_threshold') as "analyze_threshold";
-- Note: The smaller number = more aggressive = vacuum more frequence
-- Current:
-- autovacuum_analyze_scale_factor = 0.05 ---> 0.002
-- autovacuum_vacuum_scale_factor = 0.1 ---> 0.001
-- Fine Tune at table level = ALTER TABLE mytable SET (autovacuum_analyze_scale_factor = 0.02);
ALTER TABLE your_schema.your_table SET (autovacuum_enabled = true,autovacuum_analyze_scale_factor = 0.002,autovacuum_vacuum_scale_factor = 0.001);
-- Put it back to use global setting
ALTER TABLE your_schema.your_table RESET (autovacuum_enabled,autovacuum_analyze_scale_factor,autovacuum_vacuum_scale_factor);
From: richard coleman <rcoleman.ascentgl@gmail.com>
Sent: Tuesday, August 1, 2023 9:36 AM
To: Laurenz Albe <laurenz.albe@cybertec.at>
Cc: Pgsql-admin <pgsql-admin@lists.postgresql.org>
Subject: [EXTERNAL] Re: analyze foreign tables
Laurenz,
Thanks for taking the time to respond.
Right now I'm stuck with cronning a script to manually run analyze on every foreign table in every database, which in our case is most of them.
Would it be possible to transfer table statistics between the same version of PostgreSQL, ex: source is pg15, target is pg15?
Otherwise, anything that can be done to speed this up would be very helpful.
Thanks again,
rik.
On Tue, Aug 1, 2023 at 12:16 PM Laurenz Albe <laurenz.albe@cybertec.at> wrote:
On Tue, 2023-08-01 at 09:47 -0400, richard coleman wrote:
> In PostgreSQL foreign tables are not automatically analyzed and analyze must be
> specifically called on each table. In the case of sharing tables between
> PostgreSQL clusters, there is the use_remote_estimate foreign server option.
>
> In some of our multi terabyte databases, manually running analyze on all of
> the foreign tables can take more than a day. This is per database containing
> the foreign schema. Since we have certain large schema that we have centrally
> located and share to all of our other database clusters, this really adds up.
>
> use_remote_estimate isn't really a solution as it adds way too much overhead
> and processing time to every query run.
>
> Since these tables are being continuously analyzed in the database that hosts
> the data, is there some way that they statistics could be easily passed through
> the foreign server mechanism to the remote database that's calling the query?
>
> Unless I'm missing something we can either:
> 1. manually run analyze on each foreign table in each database that points to
> the host table
> 2. set use_remote_estimate = true which will cause PostgreSQL to re-obtain
> statistics on a per query basis.
>
> What I am hoping for is either:
> 1. pass through the results of analyze from the source database to the one
> where the foreign query is being run
> 2. add the ability to automatically run analyze on foreign tables just as they
> are currently run on local tables.
>
> Of the two, #1 would seem to be the easiest and least wasteful of resources.
Unfortunately, both your wishes don't look feasible:
- Transferring table statistics would mean that PostgreSQL understands statistics
from other server versions. This is complicated, and we have decided not to
do this for pg_upgrade, so I don't think we'll try to do it here.
- Autoanalyzing foreign tables would mean that we have some idea how much data
has changed on the remote server. How should we do that?
What I can imagine is that instead of reading the complete remote table during
ANALYZE, PostgreSQL applies TABLESAMPLE to fetch only part. That could be a
workable enhancement.
Yours,
Laurenz Albe
On Tue, 2023-08-01 at 12:36 -0400, richard coleman wrote: > Would it be possible to transfer table statistics between the same version > of PostgreSQL, ex: source is pg15, target is pg15? There is no support for that. If you know what you are doing, you might be able to mess with the catalog tables, but you would probably need server C code for that, since you cannot normally write to an "anyarray". I wouldn't recommend to go that way. > Otherwise, anything that can be done to speed this up would be very helpful. Run the ANALYZE in many parallel sessions. I cannot think of anything smarter. Yours, Laurenz Albe
On Tue, 2023-08-01 at 12:36 -0400, richard coleman wrote:
> Would it be possible to transfer table statistics between the same version
> of PostgreSQL, ex: source is pg15, target is pg15?
There is no support for that.
If you know what you are doing, you might be able to mess with the catalog tables,
but you would probably need server C code for that, since you cannot normally
write to an "anyarray".
I wouldn't recommend to go that way.
> Otherwise, anything that can be done to speed this up would be very helpful.
Run the ANALYZE in many parallel sessions. I cannot think of anything smarter.
Yours,
Laurenz Albe
Hi All,
I’ve a user defined data type as :
CREATE TYPE uibackend."_operation" (
INPUT = array_in,
OUTPUT = array_out,
RECEIVE = array_recv,
SEND = array_send,
ANALYZE = array_typanalyze,
ALIGNMENT = 4,
STORAGE = any,
CATEGORY = A,
ELEMENT = uibackend.operation,
DELIMITER = ',');
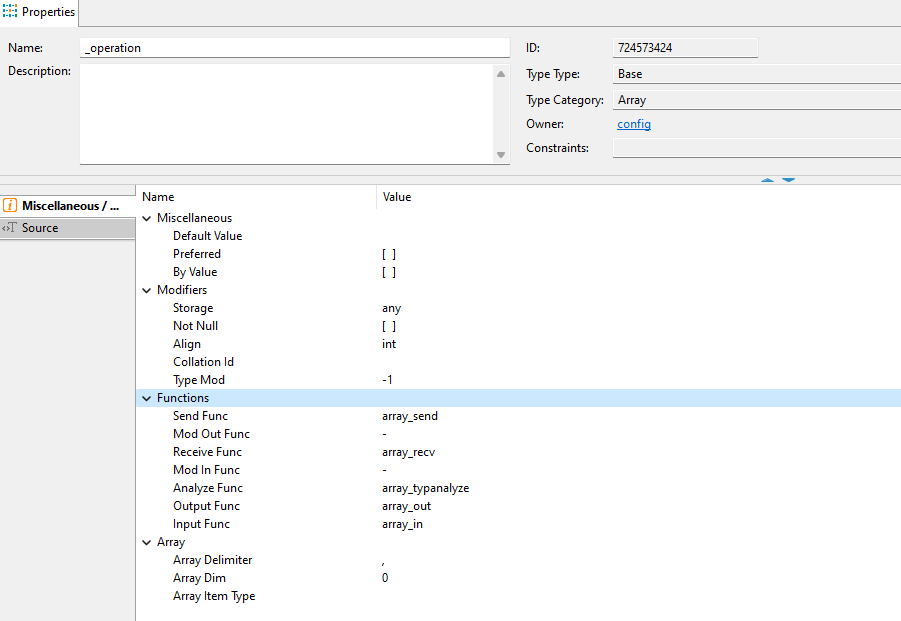
I’ve a table : 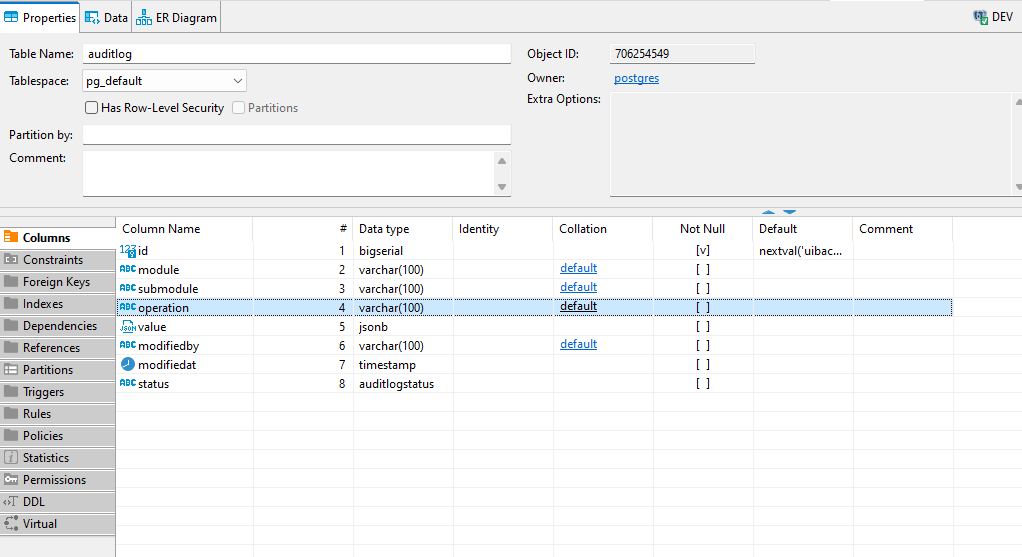
And its DDL is :
CREATE TABLE uibackend.auditlog (
id bigserial NOT NULL,
"module" varchar(100) NULL,
submodule varchar(100) NULL,
operation varchar(100) NULL,
value jsonb NULL,
modifiedby varchar(100) NULL,
modifiedat timestamp NULL,
status uibackend.auditlogstatus NULL,
CONSTRAINT auditlog_pkey PRIMARY KEY (id)
);
Now I want to change the data type of the column operation to operation data type(which is user defined)
as
ALTER TABLE uibackend.auditlog ALTER COLUMN operation TYPE operation USING operation::operation;
But I’ve been facing issues like this :
uibackend=> ALTER TABLE uibackend.auditlog ALTER COLUMN operation TYPE operation using (operation)::operation;
ERROR: cannot cast type real to operation
LINE 1: ... COLUMN operation TYPE operation using (operation)::operatio...
^
uibackend=> ALTER TABLE uibackend.auditlog ALTER COLUMN operation TYPE operation using (_operation)::operation;
ERROR: column "_operation" does not exist
LINE 1: ...tlog ALTER COLUMN operation TYPE operation using (_operation...
^
HINT: Perhaps you meant to reference the column "auditlog.operation".
uibackend=>
uibackend=> ALTER TABLE uibackend.auditlog ALTER COLUMN operation TYPE uibackend.operation;
ERROR: column "operation" cannot be cast automatically to type operation
HINT: You might need to specify "USING operation::operation".
uibackend=> ALTER TABLE uibackend.auditlog ALTER COLUMN operation TYPE uibackend.operation USING operation::operation;
ERROR: cannot cast type real to operation
LINE 1: ...operation TYPE uibackend.operation USING operation::operatio...
^
uibackend=> ALTER TABLE uibackend.auditlog ALTER COLUMN operation TYPE uibackend.operation USING uibackend.operation::operation;
ERROR: missing FROM-clause entry for table "uibackend"
LINE 1: ...R COLUMN operation TYPE uibackend.operation USING uibackend....
^
uibackend=> ALTER TABLE uibackend.auditlog ALTER COLUMN operation TYPE uibackend.operation USING uibackend.operation::uibackend.operation;
ERROR: missing FROM-clause entry for table "uibackend"
LINE 1: ...R COLUMN operation TYPE uibackend.operation USING uibackend....
^
uibackend=> ALTER TABLE uibackend.auditlog ALTER COLUMN operation TYPE uibackend.operation USING operation::uibackend.operation;
ERROR: cannot cast type real to operation
LINE 1: ...operation TYPE uibackend.operation USING operation::uibacken...
^
uibackend=> ALTER TABLE uibackend.auditlog ALTER COLUMN operation TYPE uibackend.operation USING operation::uibackend.operation;
ERROR: cannot cast type real to operation
LINE 1: ...operation TYPE uibackend.operation USING operation::uibacken...
^
uibackend=>
uibackend=>
uibackend=> ALTER TABLE uibackend.auditlog ALTER COLUMN operation TYPE uibackend.operation USING operation::uibackend.operation;^C
uibackend=>
uibackend=> ALTER TABLE table_name auditlog ALTER COLUMN operation set data type uibackend.operation us
uibackend=> ALTER TABLE table_name auditlog ALTER COLUMN operation set data type uibackend.operation using operation::operation;
ERROR: syntax error at or near "auditlog"
LINE 1: ALTER TABLE table_name auditlog ALTER COLUMN operation set d...
^
uibackend=> ALTER TABLE table_name uibackend.auditlog ALTER COLUMN operation set data type uibackend.operation;
ERROR: syntax error at or near "uibackend"
LINE 1: ALTER TABLE table_name uibackend.auditlog ALTER COLUMN opera...
^
uibackend=> ALTER TABLE uibackend.auditlog ALTER COLUMN operation set data type uibackend.operation;
ERROR: column "operation" cannot be cast automatically to type operation
HINT: You might need to specify "USING operation::operation".
uibackend=> ALTER TABLE uibackend.auditlog ALTER COLUMN operation set data type uibackend.operation using operation::operation;
ERROR: cannot cast type real to operation
LINE 1: ... set data type uibackend.operation using operation::operatio...
^
uibackend=>
uibackend=> ALTER TABLE uibackend.auditlog ALTER COLUMN operation set data type uibackend.operation using (operation)::operation;
ERROR: cannot cast type real to operation
LINE 1: ...et data type uibackend.operation using (operation)::operatio...
^
uibackend=>
uibackend=> ALTER TABLE uibackend.auditlog ALTER COLUMN operation set data type uibackend.operation using (operation)::text;
ERROR: result of USING clause for column "operation" cannot be cast automatically to type operation
HINT: You might need to add an explicit cast.
uibackend=> ALTER TABLE uibackend.auditlog ALTER COLUMN operation set data type uibackend.operation using operation::text;
ERROR: result of USING clause for column "operation" cannot be cast automatically to type operation
HINT: You might need to add an explicit cast.
uibackend=> ALTER TABLE uibackend.auditlog ALTER COLUMN operation set data type uibackend.operation using auditlog.operation::text;
ERROR: result of USING clause for column "operation" cannot be cast automatically to type operation
HINT: You might need to add an explicit cast.
uibackend=> ALTER TABLE uibackend.auditlog ALTER COLUMN operation set data type uibackend.operation using (operation());
ERROR: function operation() does not exist
LINE 1: ...peration set data type uibackend.operation using (operation(...
^
HINT: No function matches the given name and argument types. You might need to add explicit type casts.
uibackend=> ALTER TABLE uibackend.auditlog ALTER COLUMN operation set data type uibackend.operation using (operation);
ERROR: result of USING clause for column "operation" cannot be cast automatically to type operation
HINT: You might need to add an explicit cast.
uibackend=> set search_path to uibackend;
SET
uibackend=> alter table auditlog alter COLUMN operation type operation using operation::operation;
ERROR: cannot cast type real to operation
LINE 1: ...er COLUMN operation type operation using operation::operatio...
^
uibackend=> alter table auditlog alter COLUMN operation type operation using operation::uibackend._operation;
ERROR: cannot cast type real to operation[]
LINE 1: ...er COLUMN operation type operation using operation::uibacken...
^
uibackend=> alter table auditlog alter COLUMN operation type operation using (operation)::uibackend._operation;
ERROR: cannot cast type real to operation[]
LINE 1: ... COLUMN operation type operation using (operation)::uibacken...
^
uibackend=> alter table auditlog alter COLUMN operation type operation using CA
uibackend=> alter table auditlog alter COLUMN operation type operation using CAST(operation as operation);
ERROR: cannot cast type real to operation
LINE 1: ...itlog alter COLUMN operation type operation using CAST(opera...
^
uibackend=> alter table auditlog alter COLUMN operation type operation using CAST(operation as uibackend.operation);
ERROR: cannot cast type real to operation
LINE 1: ...itlog alter COLUMN operation type operation using CAST(opera...
^
uibackend=> alter table auditlog alter COLUMN operation type operation using operation::text;
ERROR: result of USING clause for column "operation" cannot be cast automatically to type operation
HINT: You might need to add an explicit cast.
uibackend=> alter table auditlog alter COLUMN operation set data type operation using operation::text;
ERROR: result of USING clause for column "operation" cannot be cast automatically to type operation
HINT: You might need to add an explicit cast.
uibackend=> alter table auditlog alter COLUMN operation set data type operation using (operation)::text;
ERROR: result of USING clause for column "operation" cannot be cast automatically to type operation
HINT: You might need to add an explicit cast.
uibackend=> alter table auditlog alter COLUMN operation type operation using CAST('operation' as uibackend.operation);
ERROR: invalid input value for enum operation: "operation"
LINE 1: ... alter COLUMN operation type operation using CAST('operation...
^
uibackend=> alter table auditlog alter COLUMN operation type operation using CAST('operation' as uibackend._operation);
ERROR: malformed array literal: "operation"
LINE 1: ... alter COLUMN operation type operation using CAST('operation...
^
DETAIL: Array value must start with "{" or dimension information.
uibackend=> alter table auditlog alter COLUMN operation type operation using CAST{'operation' as uibackend._operation};
ERROR: syntax error at or near "{"
LINE 1: ...g alter COLUMN operation type operation using CAST{'operatio...
^
uibackend=> alter table auditlog alter COLUMN operation type operation using CAST({'operation'} as uibackend._operation);
ERROR: syntax error at or near "{"
LINE 1: ... alter COLUMN operation type operation using CAST({'operatio...
^
uibackend=> alter table auditlog alter COLUMN operation type operation using CAST({'operation'} as operation);
ERROR: syntax error at or near "{"
LINE 1: ... alter COLUMN operation type operation using CAST({'operatio...
^
uibackend=> alter table auditlog alter COLUMN operation type operation using CAST('operation' as uibackend._operation);
ERROR: malformed array literal: "operation"
LINE 1: ... alter COLUMN operation type operation using CAST('operation...
^
DETAIL: Array value must start with "{" or dimension information.
uibackend=> alter table auditlog alter COLUMN operation type operation using CAST({operation} as uibackend._operation);
ERROR: syntax error at or near "{"
LINE 1: ... alter COLUMN operation type operation using CAST({operation...
^
uibackend=>
uibackend=> alter table auditlog alter COLUMN operation type operation using CAST('operation{}' as uibackend._operation);
ERROR: malformed array literal: "operation{}"
LINE 1: ... alter COLUMN operation type operation using CAST('operation...
^
DETAIL: Array value must start with "{" or dimension information.
uibackend=>
Any suggestions how to modify the column ?
PS: I had to paste this lengthy log because I wanted you all know that I’ve tried these many ways to change the data type in vain.
Regards,
Pratz
Вложения
Hi All,
I’ve a user defined data type as :
CREATE TYPE uibackend."_operation" (
Hi All,
I’ve a user defined data type as :
CREATE TYPE uibackend."_operation" (
On Wed, Aug 2, 2023 at 9:24 AM Phani Prathyush Somayajula <phani.somayajula@pragmaticplay.com> wrote:Hi All,
I’ve a user defined data type as :
CREATE TYPE uibackend."_operation" (
If you find yourself writing user-space code that uses "_{data type}" you are doing something wrong. That implementation detail is not something that is exposed to the user. If you want to deal with arrays of a type you say: {data type}[]So casting some random text column to an array of operation is simply:operation_text_col::operation[]And you can get rid of the above CREATE TYPE command altogether.David J.
On Tue, 2023-08-01 at 09:47 -0400, richard coleman wrote: > In PostgreSQL foreign tables are not automatically analyzed and analyze must be > specifically called on each table. In the case of sharing tables between PostgreSQL > clusters, there is the use_remote_estimate foreign server option. > > In some of our multi terabyte databases, manually running analyze on all of the > foreign tables can take more than a day. This is per database containing the > foreign schema. Since we have certain large schema that we have centrally located > and share to all of our other database clusters, this really adds up. I just saw that PostgreSQL v16 uses remote sampling for ANALYZE on foreign tables. This is governed by the option "analyze_sampling" on the foreign table or the foreign server, and the default value "auto" should be just what you need. Yours, Laurenz Albe
On Tue, 2023-08-01 at 09:47 -0400, richard coleman wrote:
> In PostgreSQL foreign tables are not automatically analyzed and analyze must be
> specifically called on each table. In the case of sharing tables between PostgreSQL
> clusters, there is the use_remote_estimate foreign server option.
>
> In some of our multi terabyte databases, manually running analyze on all of the
> foreign tables can take more than a day. This is per database containing the
> foreign schema. Since we have certain large schema that we have centrally located
> and share to all of our other database clusters, this really adds up.
I just saw that PostgreSQL v16 uses remote sampling for ANALYZE on foreign tables.
This is governed by the option "analyze_sampling" on the foreign table or the foreign
server, and the default value "auto" should be just what you need.
Yours,
Laurenz Albe
use_remote_estimate isn't really a solution as it adds way too much overhead and processing time to every query run.
Since these tables are being continuously analyzed in the database that hosts the data, is there some way that they statistics could be easily passed through the foreign server mechanism to the remote database that's calling the query?
What I am hoping for is either:
2. add the ability to automatically run analyze on foreign tables just as they are currently run on local tables.
On Tue, Aug 1, 2023 at 9:47 AM richard coleman <rcoleman.ascentgl@gmail.com> wrote:use_remote_estimate isn't really a solution as it adds way too much overhead and processing time to every query run.Maybe this is the thing which should be addressed. Can you quantify what you see here? How much overhead is being added for each query? Is this principally processing time, or network latency?Since these tables are being continuously analyzed in the database that hosts the data, is there some way that they statistics could be easily passed through the foreign server mechanism to the remote database that's calling the query?Since FDW can cross version boundaries, it is hard to see how this would work. Maybe something could be done for the special case of where the versions match. I think collations/encoding would be a problem, though.What I am hoping for is either:2. add the ability to automatically run analyze on foreign tables just as they are currently run on local tables.That wouldn't work because communication is always initiated on the wrong side. But it should be fairly easy to script something outside of the database which would connect to both, and poll the "foreign" pg_stat_all_tables.last_autovacuum and initiate a local ANALYZE for each table which was recently autoanalyzed on the foreign side.Cheers,Jeff
On Tue, 2023-08-01 at 09:47 -0400, richard coleman wrote:
> In PostgreSQL foreign tables are not automatically analyzed and analyze must be
> specifically called on each table. In the case of sharing tables between PostgreSQL
> clusters, there is the use_remote_estimate foreign server option.
>
> In some of our multi terabyte databases, manually running analyze on all of the
> foreign tables can take more than a day. This is per database containing the
> foreign schema. Since we have certain large schema that we have centrally located
> and share to all of our other database clusters, this really adds up.
I just saw that PostgreSQL v16 uses remote sampling for ANALYZE on foreign tables.
This is governed by the option "analyze_sampling" on the foreign table or the foreign
server, and the default value "auto" should be just what you need.