Обсуждение: Make NUM_XLOGINSERT_LOCKS configurable
Dear all, I recently used benchmarksql to evaluate the performance of postgresql. I achieved nearly 20% improvement with NUM_XLOGINSERT_LOCKS changed from 8 to 16 under some cases of high concurrency. I wonder whether it is feasible to make NUM_XLOGINSERT_LOCKS a configuration parameter, so that users can get easier to optimize their postgresql performance through this setting. Thanks, Qingsong
<1111hqshj@sina.com> writes:
> I recently used benchmarksql to evaluate the performance of postgresql. I achieved nearly 20% improvement
> with NUM_XLOGINSERT_LOCKS changed from 8 to 16 under some cases of high concurrency. I wonder whether
> it is feasible to make NUM_XLOGINSERT_LOCKS a configuration parameter, so that users can get easier to optimize
> their postgresql performance through this setting.
Making it an actual GUC would carry nontrivial costs, not least that
there are hot code paths that do "foo % NUM_XLOGINSERT_LOCKS" which
would go from a mask operation to a full integer divide. We are
unlikely to consider that on the basis of an unsupported assertion
that there's a performance gain under unspecified conditions.
Even with data to justify a change, I think it'd make a lot more sense
to just raise the constant value.
regards, tom lane
On Tue, Jan 09, 2024 at 09:38:17PM -0500, Tom Lane wrote: > Making it an actual GUC would carry nontrivial costs, not least that > there are hot code paths that do "foo % NUM_XLOGINSERT_LOCKS" which > would go from a mask operation to a full integer divide. We are > unlikely to consider that on the basis of an unsupported assertion > that there's a performance gain under unspecified conditions. > > Even with data to justify a change, I think it'd make a lot more sense > to just raise the constant value. This suggestion has showed up more than once in the past, and WAL insertion is a path that can become so hot under some workloads that changing it to a GUC would not be wise from the point of view of performance. Redesigning all that to not require a set of LWLocks into something more scalable would lead to better result, whatever this design may be. -- Michael
Вложения
Michael Paquier <michael@paquier.xyz> writes:
> This suggestion has showed up more than once in the past, and WAL
> insertion is a path that can become so hot under some workloads that
> changing it to a GUC would not be wise from the point of view of
> performance. Redesigning all that to not require a set of LWLocks
> into something more scalable would lead to better result, whatever
> this design may be.
Maybe. I bet just bumping up the constant by 2X or 4X or so would get
most of the win for far less work; it's not like adding a few more
LWLocks is expensive. But we need some evidence about what to set it to.
regards, tom lane
On Wed, Jan 10, 2024 at 10:00 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Michael Paquier <michael@paquier.xyz> writes: > > This suggestion has showed up more than once in the past, and WAL > > insertion is a path that can become so hot under some workloads that > > changing it to a GUC would not be wise from the point of view of > > performance. Redesigning all that to not require a set of LWLocks > > into something more scalable would lead to better result, whatever > > this design may be. > > Maybe. I bet just bumping up the constant by 2X or 4X or so would get > most of the win for far less work; it's not like adding a few more > LWLocks is expensive. But we need some evidence about what to set it to. I previously made an attempt to improve WAL insertion performance with varying NUM_XLOGINSERT_LOCKS. IIRC, we will lose what we get by increasing insertion locks (reduction in WAL insertion lock acquisition time) to the CPU overhead of flushing the WAL in WaitXLogInsertionsToFinish as referred to by the following comment. Unfortunately, I've lost the test results, I'll run them up again and come back. /* * Number of WAL insertion locks to use. A higher value allows more insertions * to happen concurrently, but adds some CPU overhead to flushing the WAL, * which needs to iterate all the locks. */ #define NUM_XLOGINSERT_LOCKS 8 -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> writes:
> On Wed, Jan 10, 2024 at 10:00 AM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> Maybe. I bet just bumping up the constant by 2X or 4X or so would get
>> most of the win for far less work; it's not like adding a few more
>> LWLocks is expensive. But we need some evidence about what to set it to.
> I previously made an attempt to improve WAL insertion performance with
> varying NUM_XLOGINSERT_LOCKS. IIRC, we will lose what we get by
> increasing insertion locks (reduction in WAL insertion lock
> acquisition time) to the CPU overhead of flushing the WAL in
> WaitXLogInsertionsToFinish as referred to by the following comment.
Very interesting --- this is at variance with what the OP said, so
we definitely need details about the test conditions in both cases.
> Unfortunately, I've lost the test results, I'll run them up again and
> come back.
Please.
regards, tom lane
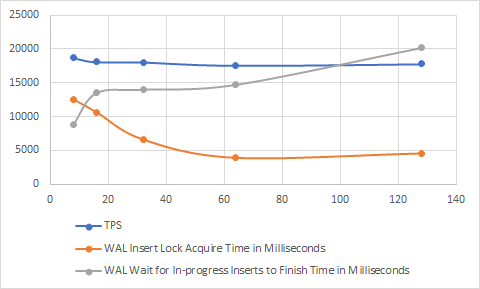
On Wed, Jan 10, 2024 at 11:43 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> writes: > > On Wed, Jan 10, 2024 at 10:00 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > >> Maybe. I bet just bumping up the constant by 2X or 4X or so would get > >> most of the win for far less work; it's not like adding a few more > >> LWLocks is expensive. But we need some evidence about what to set it to. > > > I previously made an attempt to improve WAL insertion performance with > > varying NUM_XLOGINSERT_LOCKS. IIRC, we will lose what we get by > > increasing insertion locks (reduction in WAL insertion lock > > acquisition time) to the CPU overhead of flushing the WAL in > > WaitXLogInsertionsToFinish as referred to by the following comment. > > Very interesting --- this is at variance with what the OP said, so > we definitely need details about the test conditions in both cases. > > > Unfortunately, I've lost the test results, I'll run them up again and > > come back. > > Please. Okay, I'm back with some testing. Test case: ./pgbench --initialize --scale=100 --username=ubuntu postgres ./pgbench --progress=10 --client=64 --time=300 --builtin=tpcb-like --username=ubuntu postgres Setup: ./configure --prefix=$PWD/inst/ CFLAGS="-ggdb3 -O3" > install.log && make -j 8 install > install.log 2>&1 & shared_buffers = '8GB' max_wal_size = '32GB' track_wal_io_timing = on Stats measured: I've used the attached patch to measure WAL Insert Lock Acquire Time (wal_insert_lock_acquire_time) and WAL Wait for In-progress Inserts to Finish Time (wal_wait_for_insert_to_finish_time). Results with varying NUM_XLOGINSERT_LOCKS (note that we can't allow it be more than MAX_SIMUL_LWLOCKS): Locks TPS WAL Insert Lock Acquire Time in Milliseconds WAL Wait for In-progress Inserts to Finish Time in Milliseconds 8 18669 12532 8775 16 18076 10641 13491 32 18034 6635 13997 64 17582 3937 14718 128 17782 4563 20145 Also, check the attached graph. Clearly there's an increase in the time spent in waiting for in-progress insertions to finish in WaitXLogInsertionsToFinish from 8.7 seconds to 20 seconds. Whereas, the time spent to acquire WAL insertion locks decreased from 12.5 seconds to 4.5 seconds. Overall, this hasn't resulted any improvement in TPS, in fact observed slight reduction. -- Bharath Rupireddy PostgreSQL Contributors Team RDS Open Source Databases Amazon Web Services: https://aws.amazon.com
Вложения
{kind=link}
On 1/12/24 12:32 AM, Bharath Rupireddy wrote: > Test case: > ./pgbench --initialize --scale=100 --username=ubuntu postgres > ./pgbench --progress=10 --client=64 --time=300 --builtin=tpcb-like > --username=ubuntu postgres > > Setup: > ./configure --prefix=$PWD/inst/ CFLAGS="-ggdb3 -O3" > install.log && > make -j 8 install > install.log 2>&1 & > > shared_buffers = '8GB' > max_wal_size = '32GB' > track_wal_io_timing = on > > Stats measured: > I've used the attached patch to measure WAL Insert Lock Acquire Time > (wal_insert_lock_acquire_time) and WAL Wait for In-progress Inserts > to Finish Time (wal_wait_for_insert_to_finish_time). Unfortunately this leaves the question of how frequently is WaitXLogInsertionsToFinish() being called and by whom. One possibility here is that wal_buffers is too small so backends are constantly having to write WAL data to free up buffers. -- Jim Nasby, Data Architect, Austin TX
On Fri, Jan 12, 2024 at 7:33 AM Bharath Rupireddy
<bharath.rupireddyforpostgres@gmail.com> wrote:
>
> On Wed, Jan 10, 2024 at 11:43 AM Tom Lane <tgl@sss.pgh.pa.us> wrote:
> >
> > Bharath Rupireddy <bharath.rupireddyforpostgres@gmail.com> writes:
> > > On Wed, Jan 10, 2024 at 10:00 AM Tom Lane <tgl@sss.pgh.pa.us> wrote:
> > >> Maybe. I bet just bumping up the constant by 2X or 4X or so would get
> > >> most of the win for far less work; it's not like adding a few more
> > >> LWLocks is expensive. But we need some evidence about what to set it to.
> >
> > > I previously made an attempt to improve WAL insertion performance with
> > > varying NUM_XLOGINSERT_LOCKS. IIRC, we will lose what we get by
> > > increasing insertion locks (reduction in WAL insertion lock
> > > acquisition time) to the CPU overhead of flushing the WAL in
> > > WaitXLogInsertionsToFinish as referred to by the following comment.
> >
> > Very interesting --- this is at variance with what the OP said, so
> > we definitely need details about the test conditions in both cases.
> >
> > > Unfortunately, I've lost the test results, I'll run them up again and
> > > come back.
> >
> > Please.
>
> Okay, I'm back with some testing
[..]
> Results with varying NUM_XLOGINSERT_LOCKS (note that we can't allow it
> be more than MAX_SIMUL_LWLOCKS):
> Locks TPS WAL Insert Lock Acquire Time in Milliseconds WAL
> Wait for In-progress Inserts to Finish Time in Milliseconds
> 8 18669 12532 8775
> 16 18076 10641 13491
> 32 18034 6635 13997
> 64 17582 3937 14718
> 128 17782 4563 20145
>
> Also, check the attached graph. Clearly there's an increase in the
> time spent in waiting for in-progress insertions to finish in
> WaitXLogInsertionsToFinish from 8.7 seconds to 20 seconds. Whereas,
> the time spent to acquire WAL insertion locks decreased from 12.5
> seconds to 4.5 seconds. Overall, this hasn't resulted any improvement
> in TPS, in fact observed slight reduction.
Hi, I've hastily tested using Bharath's patches too as I was thinking
it would be a fast win due to contention, however it seems that (at
least on fast NVMEs?) increasing NUM_XLOGINSERT_LOCKS doesn't seem to
help.
With pgbench -P 5 -c 32 -j 32 -T 30 and
- 64vCPU Lsv2 (AMD EPYC), on single NVMe device (with ext4) that can
do 100k RW IOPS@8kB (with fio/libaio, 4jobs)
- shared_buffers = '8GB', max_wal_size = '32GB', track_wal_io_timing = on
- maxed out wal_buffers = '256MB'
tpcb-like with synchronous_commit=off
TPS wal_insert_lock_acquire_time wal_wait_for_insert_to_finish_time
8 30393 24087 128
32 31205 968 93
tpcb-like with synchronous_commit=on
TPS wal_insert_lock_acquire_time wal_wait_for_insert_to_finish_time
8 12031 8472 10722
32 11957 1188 12563
tpcb-like with synchronous_commit=on and pgbench -c 64 -j 64
TPS wal_insert_lock_acquire_time wal_wait_for_insert_to_finish_time
8 25010 90620 68318
32 25976 18569 85319
// same, Bharath said , it shifted from insert_lock to
waiting_for_insert to finish
insertonly (largeinserts) with synchronous_commit=off (still -c 32 -j 32)
TPS wal_insert_lock_acquire_time wal_wait_for_insert_to_finish_time
8 367 19142 83
32 393 875 68
insertonly (largeinserts) with synchronous_commit=on (still -c 32 -j 32)
TPS wal_insert_lock_acquire_time wal_wait_for_insert_to_finish_time
8 329 15950 125
32 310 2177 316
insertonly was := {
create sequence s1;
create table t (id bigint, t text) partition by hash (id);
create table t_h0 partition of t FOR VALUES WITH (modulus 8, remainder 0);
create table t_h1 partition of t FOR VALUES WITH (modulus 8, remainder 1);
create table t_h2 partition of t FOR VALUES WITH (modulus 8, remainder 2);
create table t_h3 partition of t FOR VALUES WITH (modulus 8, remainder 3);
create table t_h4 partition of t FOR VALUES WITH (modulus 8, remainder 4);
create table t_h5 partition of t FOR VALUES WITH (modulus 8, remainder 5);
create table t_h6 partition of t FOR VALUES WITH (modulus 8, remainder 6);
create table t_h7 partition of t FOR VALUES WITH (modulus 8, remainder 7);
and runtime pgb:
insert into t select nextval('s1'), repeat('A', 1000) from
generate_series(1, 1000);
}
it was truncated every time, DB was checkpointed, of course it was on master.
Without more details from Qingsong it is going to be hard to explain
the boost he witnessed.
-J.