Обсуждение: Parallel CREATE INDEX for GIN indexes
Hi,
In PG17 we shall have parallel CREATE INDEX for BRIN indexes, and back
when working on that I was thinking how difficult would it be to do
something similar to do that for other index types, like GIN. I even had
that on my list of ideas to pitch to potential contributors, as I was
fairly sure it's doable and reasonably isolated / well-defined.
However, I was not aware of any takers, so a couple days ago on a slow
weekend I took a stab at it. And yes, it's doable - attached is a fairly
complete, tested and polished version of the feature, I think. It turned
out to be a bit more complex than I expected, for reasons that I'll get
into when discussing the patches.
First, let's talk about the benefits - how much faster is that than the
single-process build we have for GIN indexes? I do have a table with the
archive of all our mailing lists - it's ~1.5M messages, table is ~21GB
(raw dump is about 28GB). This does include simple text data (message
body), JSONB (headers) and tsvector (full-text on message body).
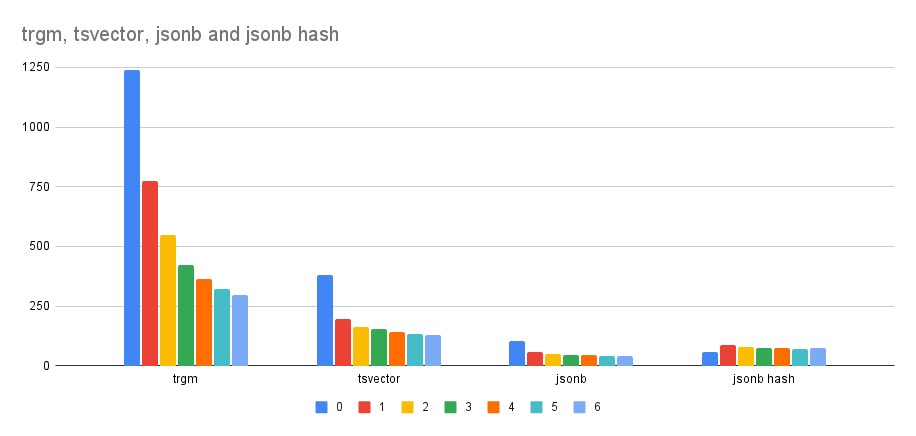
If I do CREATE index with different number of workers (0 means serial
build), I get this timings (in seconds):
workers trgm tsvector jsonb jsonb (hash)
-----------------------------------------------------
0 1240 378 104 57
1 773 196 59 85
2 548 163 51 78
3 423 153 45 75
4 362 142 43 75
5 323 134 40 70
6 295 130 39 73
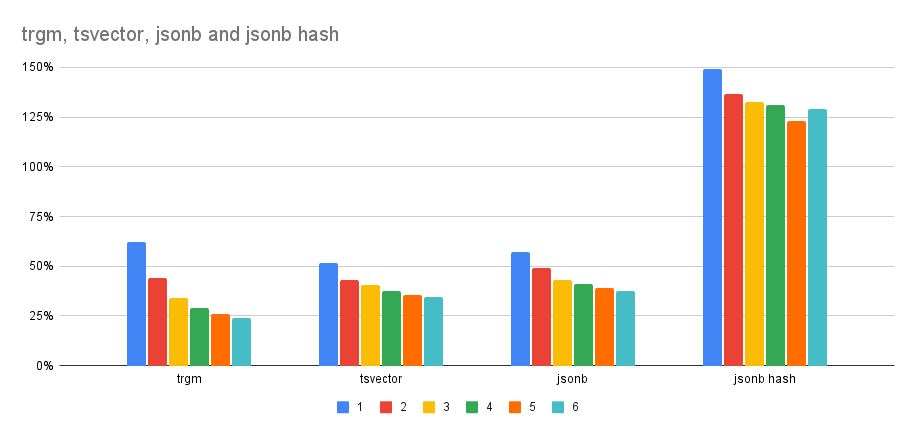
Perhaps an easier to understand result is this table with relative
timing compared to serial build:
workers trgm tsvector jsonb jsonb (hash)
-----------------------------------------------------
1 62% 52% 57% 149%
2 44% 43% 49% 136%
3 34% 40% 43% 132%
4 29% 38% 41% 131%
5 26% 35% 39% 123%
6 24% 34% 38% 129%
This shows the benefits are pretty nice, depending on the opclass. For
most indexes it's maybe ~3-4x faster, which is nice, and I don't think
it's possible to do much better - the actual index inserts can happen
from a single process only, which is the main limit.
For some of the opclasses it can regress (like the jsonb_path_ops). I
don't think that's a major issue. Or more precisely, I'm not surprised
by it. It'd be nice to be able to disable the parallel builds in these
cases somehow, but I haven't thought about that.
I do plan to do some tests with btree_gin, but I don't expect that to
behave significantly differently.
There are small variations in the index size, when built in the serial
way and the parallel way. It's generally within ~5-10%, and I believe
it's due to the serial build adding the TIDs incrementally, while the
build adds them in much larger chunks (possibly even in one chunk with
all the TIDs for the key). I believe the same size variation can happen
if the index gets built in a different way, e.g. by inserting the data
in a different order, etc. I did a number of tests to check if the index
produces the correct results, and I haven't found any issues. So I think
this is OK, and neither a problem nor an advantage of the patch.
Now, let's talk about the code - the series has 7 patches, with 6
non-trivial parts doing changes in focused and easier to understand
pieces (I hope so).
1) v20240502-0001-Allow-parallel-create-for-GIN-indexes.patch
This is the initial feature, adding the "basic" version, implemented as
pretty much 1:1 copy of the BRIN parallel build and minimal changes to
make it work for GIN (mostly about how to store intermediate results).
The basic idea is that the workers do the regular build, but instead of
flushing the data into the index after hitting the memory limit, it gets
written into a shared tuplesort and sorted by the index key. And the
leader then reads this sorted data, accumulates the TID for a given key
and inserts that into the index in one go.
2) v20240502-0002-Use-mergesort-in-the-leader-process.patch
The approach implemented by 0001 works, but there's a little bit of
issue - if there are many distinct keys (e.g. for trigrams that can
happen very easily), the workers will hit the memory limit with only
very short TID lists for most keys. For serial build that means merging
the data into a lot of random places, and in parallel build it means the
leader will have to merge a lot of tiny lists from many sorted rows.
Which can be quite annoying and expensive, because the leader does so
using qsort() in the serial part. It'd be better to ensure most of the
sorting happens in the workers, and the leader can do a mergesort. But
the mergesort must not happen too often - merging many small lists is
not cheaper than a single qsort (especially when the lists overlap).
So this patch changes the workers to process the data in two phases. The
first works as before, but the data is flushed into a local tuplesort.
And then each workers sorts the results it produced, and combines them
into results with much larger TID lists, and those results are written
to the shared tuplesort. So the leader only gets very few lists to
combine for a given key - usually just one list per worker.
3) v20240502-0003-Remove-the-explicit-pg_qsort-in-workers.patch
In 0002 the workers still do an explicit qsort() on the TID list before
writing the data into the shared tuplesort. But we can do better - the
workers can do a merge sort too. To help with this, we add the first TID
to the tuplesort tuple, and sort by that too - it helps the workers to
process the data in an order that allows simple concatenation instead of
the full mergesort.
Note: There's a non-obvious issue due to parallel scans always being
"sync scans", which may lead to very "wide" TID ranges when the scan
wraps around. More about that later.
4) v20240502-0004-Compress-TID-lists-before-writing-tuples-t.patch
The parallel build passes data between processes using temporary files,
which means it may need significant amount of disk space. For BRIN this
was not a major concern, because the summaries tend to be pretty small.
But for GIN that's not the case, and the two-phase processing introduced
by 0002 make it worse, because the worker essentially creates another
copy of the intermediate data. It does not need to copy the key, so
maybe it's not exactly 2x the space requirement, but in the worst case
it's not far from that.
But there's a simple way how to improve this - the TID lists tend to be
very compressible, and GIN already implements a very light-weight TID
compression, so this patch does just that - when building the tuple to
be written into the tuplesort, we just compress the TIDs.
5) v20240502-0005-Collect-and-print-compression-stats.patch
This patch simply collects some statistics about the compression, to
show how much it reduces the amounts of data in the various phases. The
data I've seen so far usually show ~75% compression in the first phase,
and ~30% compression in the second phase.
That is, in the first phase we save ~25% of space, in the second phase
we save ~70% of space. An example of the log messages from this patch,
for one worker (of two) in the trigram phase says:
LOG: _gin_parallel_scan_and_build raw 10158870494 compressed 7519211584
ratio 74.02%
LOG: _gin_process_worker_data raw 4593563782 compressed 1314800758
ratio 28.62%
Put differently, a single-phase version without compression (as in 0001)
would need ~10GB of disk space per worker. With compression, we need
only about ~8.8GB for both phases (or ~7.5GB for the first phase alone).
I do think these numbers look pretty good. The numbers are different for
other opclasses (trigrams are rather extreme in how much space they
need), but the overall behavior is the same.
6) v20240502-0006-Enforce-memory-limit-when-combining-tuples.patch
Until this part, there's no limit on memory used by combining results
for a single index key - it'll simply use as much memory as needed to
combine all the TID lists. Which may not be a huge issue because each
TID is only 6B, and we can accumulate a lot of those in a couple MB. And
a parallel CREATE INDEX usually runs with a fairly significant values of
maintenance_work_mem (in fact it requires it to even allow parallel).
But still, there should be some memory limit.
It however is not as simple as dumping current state into the index,
because the TID lists produced by the workers may overlap, so the tail
of the list may still receive TIDs from some future TID list. And that's
a problem because ginEntryInsert() expects to receive TIDs in order, and
if that's not the case it may fail with "could not split GIN page".
But we already have the first TID for each sort tuple (and we consider
it when sorting the data), and this is useful for deducing how far we
can flush the data, and keep just the minimal part of the TID list that
may change by merging.
So this patch implements that - it introduces the concept of "freezing"
the head of the TID list up to "first TID" from the next tuple, and uses
that to write data into index if needed because of memory limit.
We don't want to do that too often, so it only happens if we hit the
memory limit and there's at least a certain number (1024) of TIDs.
7) v20240502-0007-Detect-wrap-around-in-parallel-callback.patch
There's one more efficiency problem - the parallel scans are required to
be synchronized, i.e. the scan may start half-way through the table, and
then wrap around. Which however means the TID list will have a very wide
range of TID values, essentially the min and max of for the key.
Without 0006 this would cause frequent failures of the index build, with
the error I already mentioned:
ERROR: could not split GIN page; all old items didn't fit
tracking the "safe" TID horizon addresses that. But there's still an
issue with efficiency - having such a wide TID list forces the mergesort
to actually walk the lists, because this wide list overlaps with every
other list produced by the worker. And that's much more expensive than
just simply concatenating them, which is what happens without the wrap
around (because in that case the worker produces non-overlapping lists).
One way to fix this would be to allow parallel scans to not be sync
scans, but that seems fairly tricky and I'm not sure if that can be
done. The BRIN parallel build had a similar issue, and it was just
simpler to deal with this in the build code.
So 0007 does something similar - it tracks if the TID value goes
backward in the callback, and if it does it dumps the state into the
tuplesort before processing the first tuple from the beginning of the
table. Which means we end up with two separate "narrow" TID list, not
one very wide one.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Вложения
- gin-parallel-absolute.png
- gin-parallel-relative.png
- v20240502-0001-Allow-parallel-create-for-GIN-indexes.patch
- v20240502-0002-Use-mergesort-in-the-leader-process.patch
- v20240502-0003-Remove-the-explicit-pg_qsort-in-workers.patch
- v20240502-0004-Compress-TID-lists-before-writing-tuples-t.patch
- v20240502-0005-Collect-and-print-compression-stats.patch
- v20240502-0006-Enforce-memory-limit-when-combining-tuples.patch
- v20240502-0007-Detect-wrap-around-in-parallel-callback.patch
{kind=link}
{kind=link}
On Thu, 2 May 2024 at 17:19, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > Hi, > > In PG17 we shall have parallel CREATE INDEX for BRIN indexes, and back > when working on that I was thinking how difficult would it be to do > something similar to do that for other index types, like GIN. I even had > that on my list of ideas to pitch to potential contributors, as I was > fairly sure it's doable and reasonably isolated / well-defined. > > However, I was not aware of any takers, so a couple days ago on a slow > weekend I took a stab at it. And yes, it's doable - attached is a fairly > complete, tested and polished version of the feature, I think. It turned > out to be a bit more complex than I expected, for reasons that I'll get > into when discussing the patches. This is great. I've been thinking about approximately the same issue recently, too, but haven't had time to discuss/implement any of this yet. I think some solutions may even be portable to the btree parallel build: it also has key deduplication (though to a much smaller degree) and could benefit from deduplication during the scan/ssup load phase, rather than only during insertion. > First, let's talk about the benefits - how much faster is that than the > single-process build we have for GIN indexes? I do have a table with the > archive of all our mailing lists - it's ~1.5M messages, table is ~21GB > (raw dump is about 28GB). This does include simple text data (message > body), JSONB (headers) and tsvector (full-text on message body). Sidenote: Did you include the tsvector in the table to reduce time spent during index creation? I would have used an expression in the index definition, rather than a direct column. > If I do CREATE index with different number of workers (0 means serial > build), I get this timings (in seconds): [...] > This shows the benefits are pretty nice, depending on the opclass. For > most indexes it's maybe ~3-4x faster, which is nice, and I don't think > it's possible to do much better - the actual index inserts can happen > from a single process only, which is the main limit. Can we really not insert with multiple processes? It seems to me that GIN could be very suitable for that purpose, with its clear double tree structure distinction that should result in few buffer conflicts if different backends work on known-to-be-very-different keys. We'd probably need multiple read heads on the shared tuplesort, and a way to join the generated top-level subtrees, but I don't think that is impossible. Maybe it's work for later effort though. Have you tested and/or benchmarked this with multi-column GIN indexes? > For some of the opclasses it can regress (like the jsonb_path_ops). I > don't think that's a major issue. Or more precisely, I'm not surprised > by it. It'd be nice to be able to disable the parallel builds in these > cases somehow, but I haven't thought about that. Do you know why it regresses? > I do plan to do some tests with btree_gin, but I don't expect that to > behave significantly differently. > > There are small variations in the index size, when built in the serial > way and the parallel way. It's generally within ~5-10%, and I believe > it's due to the serial build adding the TIDs incrementally, while the > build adds them in much larger chunks (possibly even in one chunk with > all the TIDs for the key). I assume that was '[...] while the [parallel] build adds them [...]', right? > I believe the same size variation can happen > if the index gets built in a different way, e.g. by inserting the data > in a different order, etc. I did a number of tests to check if the index > produces the correct results, and I haven't found any issues. So I think > this is OK, and neither a problem nor an advantage of the patch. > > > Now, let's talk about the code - the series has 7 patches, with 6 > non-trivial parts doing changes in focused and easier to understand > pieces (I hope so). The following comments are generally based on the descriptions; I haven't really looked much at the patches yet except to validate some assumptions. > 1) v20240502-0001-Allow-parallel-create-for-GIN-indexes.patch > > This is the initial feature, adding the "basic" version, implemented as > pretty much 1:1 copy of the BRIN parallel build and minimal changes to > make it work for GIN (mostly about how to store intermediate results). > > The basic idea is that the workers do the regular build, but instead of > flushing the data into the index after hitting the memory limit, it gets > written into a shared tuplesort and sorted by the index key. And the > leader then reads this sorted data, accumulates the TID for a given key > and inserts that into the index in one go. In the code, GIN insertions are still basically single btree insertions, all starting from the top (but with many same-valued tuples at once). Now that we have a tuplesort with the full table's data, couldn't the code be adapted to do more efficient btree loading, such as that seen in the nbtree code, where the rightmost pages are cached and filled sequentially without requiring repeated searches down the tree? I suspect we can gain a lot of time there. I don't need you to do that, but what's your opinion on this? > 2) v20240502-0002-Use-mergesort-in-the-leader-process.patch > > The approach implemented by 0001 works, but there's a little bit of > issue - if there are many distinct keys (e.g. for trigrams that can > happen very easily), the workers will hit the memory limit with only > very short TID lists for most keys. For serial build that means merging > the data into a lot of random places, and in parallel build it means the > leader will have to merge a lot of tiny lists from many sorted rows. > > Which can be quite annoying and expensive, because the leader does so > using qsort() in the serial part. It'd be better to ensure most of the > sorting happens in the workers, and the leader can do a mergesort. But > the mergesort must not happen too often - merging many small lists is > not cheaper than a single qsort (especially when the lists overlap). > > So this patch changes the workers to process the data in two phases. The > first works as before, but the data is flushed into a local tuplesort. > And then each workers sorts the results it produced, and combines them > into results with much larger TID lists, and those results are written > to the shared tuplesort. So the leader only gets very few lists to > combine for a given key - usually just one list per worker. Hmm, I was hoping we could implement the merging inside the tuplesort itself during its own flush phase, as it could save significantly on IO, and could help other users of tuplesort with deduplication, too. > 3) v20240502-0003-Remove-the-explicit-pg_qsort-in-workers.patch > > In 0002 the workers still do an explicit qsort() on the TID list before > writing the data into the shared tuplesort. But we can do better - the > workers can do a merge sort too. To help with this, we add the first TID > to the tuplesort tuple, and sort by that too - it helps the workers to > process the data in an order that allows simple concatenation instead of > the full mergesort. > > Note: There's a non-obvious issue due to parallel scans always being > "sync scans", which may lead to very "wide" TID ranges when the scan > wraps around. More about that later. As this note seems to imply, this seems to have a strong assumption that data received in parallel workers is always in TID order, with one optional wraparound. Non-HEAP TAMs may break with this assumption, so what's the plan on that? > 4) v20240502-0004-Compress-TID-lists-before-writing-tuples-t.patch > > The parallel build passes data between processes using temporary files, > which means it may need significant amount of disk space. For BRIN this > was not a major concern, because the summaries tend to be pretty small. > > But for GIN that's not the case, and the two-phase processing introduced > by 0002 make it worse, because the worker essentially creates another > copy of the intermediate data. It does not need to copy the key, so > maybe it's not exactly 2x the space requirement, but in the worst case > it's not far from that. > > But there's a simple way how to improve this - the TID lists tend to be > very compressible, and GIN already implements a very light-weight TID > compression, so this patch does just that - when building the tuple to > be written into the tuplesort, we just compress the TIDs. See note on 0002: Could we do this in the tuplesort writeback, rather than by moving the data around multiple times? [...] > So 0007 does something similar - it tracks if the TID value goes > backward in the callback, and if it does it dumps the state into the > tuplesort before processing the first tuple from the beginning of the > table. Which means we end up with two separate "narrow" TID list, not > one very wide one. See note above: We may still need a merge phase, just to make sure we handle all TAM parallel scans correctly, even if that merge join phase wouldn't get hit in vanilla PostgreSQL. Kind regards, Matthias van de Meent Neon (https://neon.tech)
On 5/2/24 19:12, Matthias van de Meent wrote: > On Thu, 2 May 2024 at 17:19, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: >> >> Hi, >> >> In PG17 we shall have parallel CREATE INDEX for BRIN indexes, and back >> when working on that I was thinking how difficult would it be to do >> something similar to do that for other index types, like GIN. I even had >> that on my list of ideas to pitch to potential contributors, as I was >> fairly sure it's doable and reasonably isolated / well-defined. >> >> However, I was not aware of any takers, so a couple days ago on a slow >> weekend I took a stab at it. And yes, it's doable - attached is a fairly >> complete, tested and polished version of the feature, I think. It turned >> out to be a bit more complex than I expected, for reasons that I'll get >> into when discussing the patches. > > This is great. I've been thinking about approximately the same issue > recently, too, but haven't had time to discuss/implement any of this > yet. I think some solutions may even be portable to the btree parallel > build: it also has key deduplication (though to a much smaller degree) > and could benefit from deduplication during the scan/ssup load phase, > rather than only during insertion. > Perhaps, although I'm not that familiar with the details of btree builds, and I haven't thought about it when working on this over the past couple days. >> First, let's talk about the benefits - how much faster is that than the >> single-process build we have for GIN indexes? I do have a table with the >> archive of all our mailing lists - it's ~1.5M messages, table is ~21GB >> (raw dump is about 28GB). This does include simple text data (message >> body), JSONB (headers) and tsvector (full-text on message body). > > Sidenote: Did you include the tsvector in the table to reduce time > spent during index creation? I would have used an expression in the > index definition, rather than a direct column. > Yes, it's a materialized column, not computed during index creation. >> If I do CREATE index with different number of workers (0 means serial >> build), I get this timings (in seconds): > > [...] > >> This shows the benefits are pretty nice, depending on the opclass. For >> most indexes it's maybe ~3-4x faster, which is nice, and I don't think >> it's possible to do much better - the actual index inserts can happen >> from a single process only, which is the main limit. > > Can we really not insert with multiple processes? It seems to me that > GIN could be very suitable for that purpose, with its clear double > tree structure distinction that should result in few buffer conflicts > if different backends work on known-to-be-very-different keys. > We'd probably need multiple read heads on the shared tuplesort, and a > way to join the generated top-level subtrees, but I don't think that > is impossible. Maybe it's work for later effort though. > Maybe, but I took it as a restriction and it seemed too difficult to relax (or at least I assume that). > Have you tested and/or benchmarked this with multi-column GIN indexes? > I did test that, and I'm not aware of any bugs/issues. Performance-wise it depends on which opclasses are used by the columns - if you take the speedup for each of them independently, the speedup for the whole index is roughly the average of that. >> For some of the opclasses it can regress (like the jsonb_path_ops). I >> don't think that's a major issue. Or more precisely, I'm not surprised >> by it. It'd be nice to be able to disable the parallel builds in these >> cases somehow, but I haven't thought about that. > > Do you know why it regresses? > No, but one thing that stands out is that the index is much smaller than the other columns/opclasses, and the compression does not save much (only about 5% for both phases). So I assume it's the overhead of writing writing and reading a bunch of GB of data without really gaining much from doing that. >> I do plan to do some tests with btree_gin, but I don't expect that to >> behave significantly differently. >> >> There are small variations in the index size, when built in the serial >> way and the parallel way. It's generally within ~5-10%, and I believe >> it's due to the serial build adding the TIDs incrementally, while the >> build adds them in much larger chunks (possibly even in one chunk with >> all the TIDs for the key). > > I assume that was '[...] while the [parallel] build adds them [...]', right? > Right. The parallel build adds them in larger chunks. >> I believe the same size variation can happen >> if the index gets built in a different way, e.g. by inserting the data >> in a different order, etc. I did a number of tests to check if the index >> produces the correct results, and I haven't found any issues. So I think >> this is OK, and neither a problem nor an advantage of the patch. >> >> >> Now, let's talk about the code - the series has 7 patches, with 6 >> non-trivial parts doing changes in focused and easier to understand >> pieces (I hope so). > > The following comments are generally based on the descriptions; I > haven't really looked much at the patches yet except to validate some > assumptions. > OK >> 1) v20240502-0001-Allow-parallel-create-for-GIN-indexes.patch >> >> This is the initial feature, adding the "basic" version, implemented as >> pretty much 1:1 copy of the BRIN parallel build and minimal changes to >> make it work for GIN (mostly about how to store intermediate results). >> >> The basic idea is that the workers do the regular build, but instead of >> flushing the data into the index after hitting the memory limit, it gets >> written into a shared tuplesort and sorted by the index key. And the >> leader then reads this sorted data, accumulates the TID for a given key >> and inserts that into the index in one go. > > In the code, GIN insertions are still basically single btree > insertions, all starting from the top (but with many same-valued > tuples at once). Now that we have a tuplesort with the full table's > data, couldn't the code be adapted to do more efficient btree loading, > such as that seen in the nbtree code, where the rightmost pages are > cached and filled sequentially without requiring repeated searches > down the tree? I suspect we can gain a lot of time there. > > I don't need you to do that, but what's your opinion on this? > I have no idea. I started working on this with only very basic idea of how GIN works / is structured, so I simply leveraged the existing callback and massaged it to work in the parallel case too. >> 2) v20240502-0002-Use-mergesort-in-the-leader-process.patch >> >> The approach implemented by 0001 works, but there's a little bit of >> issue - if there are many distinct keys (e.g. for trigrams that can >> happen very easily), the workers will hit the memory limit with only >> very short TID lists for most keys. For serial build that means merging >> the data into a lot of random places, and in parallel build it means the >> leader will have to merge a lot of tiny lists from many sorted rows. >> >> Which can be quite annoying and expensive, because the leader does so >> using qsort() in the serial part. It'd be better to ensure most of the >> sorting happens in the workers, and the leader can do a mergesort. But >> the mergesort must not happen too often - merging many small lists is >> not cheaper than a single qsort (especially when the lists overlap). >> >> So this patch changes the workers to process the data in two phases. The >> first works as before, but the data is flushed into a local tuplesort. >> And then each workers sorts the results it produced, and combines them >> into results with much larger TID lists, and those results are written >> to the shared tuplesort. So the leader only gets very few lists to >> combine for a given key - usually just one list per worker. > > Hmm, I was hoping we could implement the merging inside the tuplesort > itself during its own flush phase, as it could save significantly on > IO, and could help other users of tuplesort with deduplication, too. > Would that happen in the worker or leader process? Because my goal was to do the expensive part in the worker, because that's what helps with the parallelization. >> 3) v20240502-0003-Remove-the-explicit-pg_qsort-in-workers.patch >> >> In 0002 the workers still do an explicit qsort() on the TID list before >> writing the data into the shared tuplesort. But we can do better - the >> workers can do a merge sort too. To help with this, we add the first TID >> to the tuplesort tuple, and sort by that too - it helps the workers to >> process the data in an order that allows simple concatenation instead of >> the full mergesort. >> >> Note: There's a non-obvious issue due to parallel scans always being >> "sync scans", which may lead to very "wide" TID ranges when the scan >> wraps around. More about that later. > > As this note seems to imply, this seems to have a strong assumption > that data received in parallel workers is always in TID order, with > one optional wraparound. Non-HEAP TAMs may break with this assumption, > so what's the plan on that? > Well, that would break the serial build too, right? Anyway, the way this patch works can be extended to deal with that by actually sorting the TIDs when serializing the tuplestore tuple. The consequence of that is the combining will be more expensive, because it'll require a proper mergesort, instead of just appending the lists. >> 4) v20240502-0004-Compress-TID-lists-before-writing-tuples-t.patch >> >> The parallel build passes data between processes using temporary files, >> which means it may need significant amount of disk space. For BRIN this >> was not a major concern, because the summaries tend to be pretty small. >> >> But for GIN that's not the case, and the two-phase processing introduced >> by 0002 make it worse, because the worker essentially creates another >> copy of the intermediate data. It does not need to copy the key, so >> maybe it's not exactly 2x the space requirement, but in the worst case >> it's not far from that. >> >> But there's a simple way how to improve this - the TID lists tend to be >> very compressible, and GIN already implements a very light-weight TID >> compression, so this patch does just that - when building the tuple to >> be written into the tuplesort, we just compress the TIDs. > > See note on 0002: Could we do this in the tuplesort writeback, rather > than by moving the data around multiple times? > No idea, I've never done that ... > [...] >> So 0007 does something similar - it tracks if the TID value goes >> backward in the callback, and if it does it dumps the state into the >> tuplesort before processing the first tuple from the beginning of the >> table. Which means we end up with two separate "narrow" TID list, not >> one very wide one. > > See note above: We may still need a merge phase, just to make sure we > handle all TAM parallel scans correctly, even if that merge join phase > wouldn't get hit in vanilla PostgreSQL. > Well, yeah. But in fact the parallel code already does that, while the existing serial code may fail with the "data don't fit" error. The parallel code will do the mergesort correctly, and only emit TIDs that we know are safe to write to the index (i.e. no future TIDs will go before the "TID horizon"). But the serial build has nothing like that - it will sort the TIDs that fit into the memory limit, but it also relies on not processing data out of order (and disables sync scans to not have wrap around issues). But if the TAM does something funny, this may break. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi, Here's a slightly improved version, fixing a couple bugs in handling byval/byref values, causing issues on 32-bit machines (but not only). And also a couple compiler warnings about string formatting. Other than that, no changes. -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Вложения
- v20240505-0001-Allow-parallel-create-for-GIN-indexes.patch
- v20240505-0002-Use-mergesort-in-the-leader-process.patch
- v20240505-0003-Remove-the-explicit-pg_qsort-in-workers.patch
- v20240505-0004-Compress-TID-lists-before-writing-tuples-t.patch
- v20240505-0005-Collect-and-print-compression-stats.patch
- v20240505-0006-Enforce-memory-limit-when-combining-tuples.patch
- v20240505-0007-Detect-wrap-around-in-parallel-callback.patch
Hello Tomas, >>> 2) v20240502-0002-Use-mergesort-in-the-leader-process.patch >>> >>> The approach implemented by 0001 works, but there's a little bit of >>> issue - if there are many distinct keys (e.g. for trigrams that can >>> happen very easily), the workers will hit the memory limit with only >>> very short TID lists for most keys. For serial build that means merging >>> the data into a lot of random places, and in parallel build it means the >>> leader will have to merge a lot of tiny lists from many sorted rows. >>> >>> Which can be quite annoying and expensive, because the leader does so >>> using qsort() in the serial part. It'd be better to ensure most of the >>> sorting happens in the workers, and the leader can do a mergesort. But >>> the mergesort must not happen too often - merging many small lists is >>> not cheaper than a single qsort (especially when the lists overlap). >>> >>> So this patch changes the workers to process the data in two phases. The >>> first works as before, but the data is flushed into a local tuplesort. >>> And then each workers sorts the results it produced, and combines them >>> into results with much larger TID lists, and those results are written >>> to the shared tuplesort. So the leader only gets very few lists to >>> combine for a given key - usually just one list per worker. >> >> Hmm, I was hoping we could implement the merging inside the tuplesort >> itself during its own flush phase, as it could save significantly on >> IO, and could help other users of tuplesort with deduplication, too. >> > > Would that happen in the worker or leader process? Because my goal was > to do the expensive part in the worker, because that's what helps with > the parallelization. I guess both of you are talking about worker process, if here are something in my mind: *btbuild* also let the WORKER dump the tuples into Sharedsort struct and let the LEADER merge them directly. I think this aim of this design is it is potential to save a mergeruns. In the current patch, worker dump to local tuplesort and mergeruns it and then leader run the merges again. I admit the goal of this patch is reasonable, but I'm feeling we need to adapt this way conditionally somehow. and if we find the way, we can apply it to btbuild as well. -- Best Regards Andy Fan
Tomas Vondra <tomas.vondra@enterprisedb.com> writes: > 3) v20240502-0003-Remove-the-explicit-pg_qsort-in-workers.patch > > In 0002 the workers still do an explicit qsort() on the TID list before > writing the data into the shared tuplesort. But we can do better - the > workers can do a merge sort too. To help with this, we add the first TID > to the tuplesort tuple, and sort by that too - it helps the workers to > process the data in an order that allows simple concatenation instead of > the full mergesort. > > Note: There's a non-obvious issue due to parallel scans always being > "sync scans", which may lead to very "wide" TID ranges when the scan > wraps around. More about that later. This is really amazing. > 7) v20240502-0007-Detect-wrap-around-in-parallel-callback.patch > > There's one more efficiency problem - the parallel scans are required to > be synchronized, i.e. the scan may start half-way through the table, and > then wrap around. Which however means the TID list will have a very wide > range of TID values, essentially the min and max of for the key. > > Without 0006 this would cause frequent failures of the index build, with > the error I already mentioned: > > ERROR: could not split GIN page; all old items didn't fit I have two questions here and both of them are generall gin index questions rather than the patch here. 1. What does the "wrap around" mean in the "the scan may start half-way through the table, and then wrap around". Searching "wrap" in gin/README gets nothing. 2. I can't understand the below error. > ERROR: could not split GIN page; all old items didn't fit When the posting list is too long, we have posting tree strategy. so in which sistuation we could get this ERROR. > issue with efficiency - having such a wide TID list forces the mergesort > to actually walk the lists, because this wide list overlaps with every > other list produced by the worker. If we split the blocks among worker 1-block by 1-block, we will have a serious issue like here. If we can have N-block by N-block, and N-block is somehow fill the work_mem which makes the dedicated temp file, we can make things much better, can we? -- Best Regards Andy Fan
On 5/9/24 12:14, Andy Fan wrote:
>
> Tomas Vondra <tomas.vondra@enterprisedb.com> writes:
>
>> 3) v20240502-0003-Remove-the-explicit-pg_qsort-in-workers.patch
>>
>> In 0002 the workers still do an explicit qsort() on the TID list before
>> writing the data into the shared tuplesort. But we can do better - the
>> workers can do a merge sort too. To help with this, we add the first TID
>> to the tuplesort tuple, and sort by that too - it helps the workers to
>> process the data in an order that allows simple concatenation instead of
>> the full mergesort.
>>
>> Note: There's a non-obvious issue due to parallel scans always being
>> "sync scans", which may lead to very "wide" TID ranges when the scan
>> wraps around. More about that later.
>
> This is really amazing.
>
>> 7) v20240502-0007-Detect-wrap-around-in-parallel-callback.patch
>>
>> There's one more efficiency problem - the parallel scans are required to
>> be synchronized, i.e. the scan may start half-way through the table, and
>> then wrap around. Which however means the TID list will have a very wide
>> range of TID values, essentially the min and max of for the key.
>>
>> Without 0006 this would cause frequent failures of the index build, with
>> the error I already mentioned:
>>
>> ERROR: could not split GIN page; all old items didn't fit
>
> I have two questions here and both of them are generall gin index questions
> rather than the patch here.
>
> 1. What does the "wrap around" mean in the "the scan may start half-way
> through the table, and then wrap around". Searching "wrap" in
> gin/README gets nothing.
>
The "wrap around" is about the scan used to read data from the table
when building the index. A "sync scan" may start e.g. at TID (1000,0)
and read till the end of the table, and then wraps and returns the
remaining part at the beginning of the table for blocks 0-999.
This means the callback would not see a monotonically increasing
sequence of TIDs.
Which is why the serial build disables sync scans, allowing simply
appending values to the sorted list, and even with regular flushes of
data into the index we can simply append data to the posting lists.
> 2. I can't understand the below error.
>
>> ERROR: could not split GIN page; all old items didn't fit
>
> When the posting list is too long, we have posting tree strategy. so in
> which sistuation we could get this ERROR.
>
AFAICS the index build relies on the assumption that we only append data
to the TID list on a leaf page, and when the page gets split, the "old"
part will always fit. Which may not be true, if there was a wrap around
and we're adding low TID values to the list on the leaf page.
FWIW the error in dataBeginPlaceToPageLeaf looks like this:
if (!append || ItemPointerCompare(&maxOldItem, &remaining) >= 0)
elog(ERROR, "could not split GIN page; all old items didn't fit");
It can fail simply because of the !append part.
I'm not sure why dataBeginPlaceToPageLeaf() relies on this assumption,
or with GIN details in general, and I haven't found any explanation. But
AFAIK this is why the serial build disables sync scans.
>> issue with efficiency - having such a wide TID list forces the mergesort
>> to actually walk the lists, because this wide list overlaps with every
>> other list produced by the worker.
>
> If we split the blocks among worker 1-block by 1-block, we will have a
> serious issue like here. If we can have N-block by N-block, and N-block
> is somehow fill the work_mem which makes the dedicated temp file, we
> can make things much better, can we?
>
I don't understand the question. The blocks are distributed to workers
by the parallel table scan, and it certainly does not do that block by
block. But even it it did, that's not a problem for this code.
The problem is that if the scan wraps around, then one of the TID lists
for a given worker will have the min TID and max TID, so it will overlap
with every other TID list for the same key in that worker. And when the
worker does the merging, this list will force a "full" merge sort for
all TID lists (for that key), which is very expensive.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On 5/9/24 11:44, Andy Fan wrote: > > Hello Tomas, > >>>> 2) v20240502-0002-Use-mergesort-in-the-leader-process.patch >>>> >>>> The approach implemented by 0001 works, but there's a little bit of >>>> issue - if there are many distinct keys (e.g. for trigrams that can >>>> happen very easily), the workers will hit the memory limit with only >>>> very short TID lists for most keys. For serial build that means merging >>>> the data into a lot of random places, and in parallel build it means the >>>> leader will have to merge a lot of tiny lists from many sorted rows. >>>> >>>> Which can be quite annoying and expensive, because the leader does so >>>> using qsort() in the serial part. It'd be better to ensure most of the >>>> sorting happens in the workers, and the leader can do a mergesort. But >>>> the mergesort must not happen too often - merging many small lists is >>>> not cheaper than a single qsort (especially when the lists overlap). >>>> >>>> So this patch changes the workers to process the data in two phases. The >>>> first works as before, but the data is flushed into a local tuplesort. >>>> And then each workers sorts the results it produced, and combines them >>>> into results with much larger TID lists, and those results are written >>>> to the shared tuplesort. So the leader only gets very few lists to >>>> combine for a given key - usually just one list per worker. >>> >>> Hmm, I was hoping we could implement the merging inside the tuplesort >>> itself during its own flush phase, as it could save significantly on >>> IO, and could help other users of tuplesort with deduplication, too. >>> >> >> Would that happen in the worker or leader process? Because my goal was >> to do the expensive part in the worker, because that's what helps with >> the parallelization. > > I guess both of you are talking about worker process, if here are > something in my mind: > > *btbuild* also let the WORKER dump the tuples into Sharedsort struct > and let the LEADER merge them directly. I think this aim of this design > is it is potential to save a mergeruns. In the current patch, worker dump > to local tuplesort and mergeruns it and then leader run the merges > again. I admit the goal of this patch is reasonable, but I'm feeling we > need to adapt this way conditionally somehow. and if we find the way, we > can apply it to btbuild as well. > I'm a bit confused about what you're proposing here, or how is that related to what this patch is doing and/or to the what Matthias mentioned in his e-mail from last week. Let me explain the relevant part of the patch, and how I understand the improvement suggested by Matthias. The patch does the work in three phases: 1) Worker gets data from table, split that into index items and add those into a "private" tuplesort, and finally sorts that. So a worker may see a key many times, with different TIDs, so the tuplesort may contain many items for the same key, with distinct TID lists: key1: 1, 2, 3, 4 key1: 5, 6, 7 key1: 8, 9, 10 key2: 1, 2, 3 ... 2) Worker reads the sorted data, and combines TIDs for the same key into larger TID lists, depending on work_mem etc. and writes the result into a shared tuplesort. So the worker may write this: key1: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 key2: 1, 2, 3 3) Leader reads this, combines TID lists from all workers (using a higher memory limit, probably), and writes the result into the index. The step (2) is optional - it would work without it. But it helps, as it moves a potentially expensive sort into the workers (and thus the parallel part of the build), and it also makes it cheaper, because in a single worker the lists do not overlap and thus can be simply appended. Which in the leader is not the case, forcing an expensive mergesort. The trouble with (2) is that it "just copies" data from one tuplesort into another, increasing the disk space requirements. In an extreme case, when nothing can be combined, it pretty much doubles the amount of disk space, and makes the build longer. What I think Matthias is suggesting, is that this "TID list merging" could be done directly as part of the tuplesort in step (1). So instead of just moving the "sort tuples" from the appropriate runs, it could also do an optional step of combining the tuples and writing this combined tuple into the tuplesort result (for that worker). Matthias also mentioned this might be useful when building btree indexes with key deduplication. AFAICS this might work, although it probably requires for the "combined" tuple to be smaller than the sum of the combined tuples (in order to fit into the space). But at least in the GIN build in the workers this is likely true, because the TID lists do not overlap (and thus not hurting the compressibility). That being said, I still see this more as an optimization than something required for the patch, and I don't think I'll have time to work on this anytime soon. The patch is not extremely complex, but it's not trivial either. But if someone wants to take a stab at extending tuplesort to allow this, I won't object ... regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 5/2/24 20:22, Tomas Vondra wrote:
>>
>>> For some of the opclasses it can regress (like the jsonb_path_ops). I
>>> don't think that's a major issue. Or more precisely, I'm not surprised
>>> by it. It'd be nice to be able to disable the parallel builds in these
>>> cases somehow, but I haven't thought about that.
>>
>> Do you know why it regresses?
>>
>
> No, but one thing that stands out is that the index is much smaller than
> the other columns/opclasses, and the compression does not save much
> (only about 5% for both phases). So I assume it's the overhead of
> writing writing and reading a bunch of GB of data without really gaining
> much from doing that.
>
I finally got to look into this regression, but I think I must have done
something wrong before because I can't reproduce it. This is the timings
I get now, if I rerun the benchmark:
workers trgm tsvector jsonb jsonb (hash)
-------------------------------------------------------
0 1225 404 104 56
1 772 180 57 60
2 549 143 47 52
3 426 127 43 50
4 364 116 40 48
5 323 111 38 46
6 292 111 37 45
and the speedup, relative to serial build:
workers trgm tsvector jsonb jsonb (hash)
--------------------------------------------------------
1 63% 45% 54% 108%
2 45% 35% 45% 94%
3 35% 31% 41% 89%
4 30% 29% 38% 86%
5 26% 28% 37% 83%
6 24% 28% 35% 81%
So there's a small regression for the jsonb_path_ops opclass, but only
with one worker. After that, it gets a bit faster than serial build.
While not a great speedup, it's far better than the earlier results that
showed maybe 40% regression.
I don't know what I did wrong before - maybe I had a build with an extra
debug info or something like that? No idea why would that affect only
one of the opclasses. But this time I made doubly sure the results are
correct etc.
Anyway, I'm fairly happy with these results. I don't think it's
surprising there are cases where parallel build does not help much.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Thu, 9 May 2024 at 15:13, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > Let me explain the relevant part of the patch, and how I understand the > improvement suggested by Matthias. The patch does the work in three phases: > > > 1) Worker gets data from table, split that into index items and add > those into a "private" tuplesort, and finally sorts that. So a worker > may see a key many times, with different TIDs, so the tuplesort may > contain many items for the same key, with distinct TID lists: > > key1: 1, 2, 3, 4 > key1: 5, 6, 7 > key1: 8, 9, 10 > key2: 1, 2, 3 > ... This step is actually split in several components/phases, too. As opposed to btree, which directly puts each tuple's data into the tuplesort, this GIN approach actually buffers the tuples in memory to generate these TID lists for data keys, and flushes these pairs of Key + TID list into the tuplesort when its own memory limit is exceeded. That means we essentially double the memory used for this data: One GIN deform buffer, and one in-memory sort buffer in the tuplesort. This is fine for now, but feels duplicative, hence my "let's allow tuplesort to merge the key+TID pairs into pairs of key+TID list" comment. > The trouble with (2) is that it "just copies" data from one tuplesort > into another, increasing the disk space requirements. In an extreme > case, when nothing can be combined, it pretty much doubles the amount of > disk space, and makes the build longer. > > What I think Matthias is suggesting, is that this "TID list merging" > could be done directly as part of the tuplesort in step (1). So instead > of just moving the "sort tuples" from the appropriate runs, it could > also do an optional step of combining the tuples and writing this > combined tuple into the tuplesort result (for that worker). Yes, but with a slightly more extensive approach than that even, see above. > Matthias also mentioned this might be useful when building btree indexes > with key deduplication. > > AFAICS this might work, although it probably requires for the "combined" > tuple to be smaller than the sum of the combined tuples (in order to fit > into the space). *must not be larger than the sum; not "must be smaller than the sum" [^0]. For btree tuples with posting lists this is guaranteed to be true: The added size of a btree tuple with a posting list (containing at least 2 values) vs one without is the maxaligned size of 2 TIDs, or 16 bytes (12 on 32-bit systems). The smallest btree tuple with data is also 16 bytes (or 12 bytes on 32-bit systems), so this works out nicely. > But at least in the GIN build in the workers this is > likely true, because the TID lists do not overlap (and thus not hurting > the compressibility). > > That being said, I still see this more as an optimization than something > required for the patch, Agreed. > and I don't think I'll have time to work on this > anytime soon. The patch is not extremely complex, but it's not trivial > either. But if someone wants to take a stab at extending tuplesort to > allow this, I won't object ... Same here: While I do have some ideas on where and how to implement this, I'm not planning on working on that soon. Kind regards, Matthias van de Meent [^0] There's some overhead in the tuplesort serialization too, so there is some leeway there, too.
On 5/9/24 17:51, Matthias van de Meent wrote: > On Thu, 9 May 2024 at 15:13, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: >> Let me explain the relevant part of the patch, and how I understand the >> improvement suggested by Matthias. The patch does the work in three phases: >> >> >> 1) Worker gets data from table, split that into index items and add >> those into a "private" tuplesort, and finally sorts that. So a worker >> may see a key many times, with different TIDs, so the tuplesort may >> contain many items for the same key, with distinct TID lists: >> >> key1: 1, 2, 3, 4 >> key1: 5, 6, 7 >> key1: 8, 9, 10 >> key2: 1, 2, 3 >> ... > > This step is actually split in several components/phases, too. > As opposed to btree, which directly puts each tuple's data into the > tuplesort, this GIN approach actually buffers the tuples in memory to > generate these TID lists for data keys, and flushes these pairs of Key > + TID list into the tuplesort when its own memory limit is exceeded. > That means we essentially double the memory used for this data: One > GIN deform buffer, and one in-memory sort buffer in the tuplesort. > This is fine for now, but feels duplicative, hence my "let's allow > tuplesort to merge the key+TID pairs into pairs of key+TID list" > comment. > True, although the "GIN deform buffer" (flushed by the callback if using too much memory) likely does most of the merging already. If it only happened in the tuplesort merge, we'd likely have far more tuples and overhead associated with that. So we certainly won't get rid of either of these things. You're right the memory limits are a bit unclear, and need more thought. I certainly have not thought very much about not using more than the specified maintenance_work_mem amount. This includes the planner code determining the number of workers to use - right now it simply does the same thing as for btree/brin, i.e. assumes each workers uses 32MB of memory and checks how many workers fit into maintenance_work_mem. That was a bit bogus even for BRIN, because BRIN sorts only summaries, which is typically tiny - perhaps a couple kB, much less than 32MB. But it's still just one sort, and some opclasses may be much larger (like bloom, for example). So I just went with it. But for GIN it's more complicated, because we have two tuplesorts (not sure if both can use the memory at the same time) and the GIN deform buffer. Which probably means we need to have a per-worker allowance considering all these buffers. >> The trouble with (2) is that it "just copies" data from one tuplesort >> into another, increasing the disk space requirements. In an extreme >> case, when nothing can be combined, it pretty much doubles the amount of >> disk space, and makes the build longer. >> >> What I think Matthias is suggesting, is that this "TID list merging" >> could be done directly as part of the tuplesort in step (1). So instead >> of just moving the "sort tuples" from the appropriate runs, it could >> also do an optional step of combining the tuples and writing this >> combined tuple into the tuplesort result (for that worker). > > Yes, but with a slightly more extensive approach than that even, see above. > >> Matthias also mentioned this might be useful when building btree indexes >> with key deduplication. >> >> AFAICS this might work, although it probably requires for the "combined" >> tuple to be smaller than the sum of the combined tuples (in order to fit >> into the space). > > *must not be larger than the sum; not "must be smaller than the sum" [^0]. Yeah, I wrote that wrong. > For btree tuples with posting lists this is guaranteed to be true: The > added size of a btree tuple with a posting list (containing at least 2 > values) vs one without is the maxaligned size of 2 TIDs, or 16 bytes > (12 on 32-bit systems). The smallest btree tuple with data is also 16 > bytes (or 12 bytes on 32-bit systems), so this works out nicely. > >> But at least in the GIN build in the workers this is >> likely true, because the TID lists do not overlap (and thus not hurting >> the compressibility). >> >> That being said, I still see this more as an optimization than something >> required for the patch, > > Agreed. > OK >> and I don't think I'll have time to work on this >> anytime soon. The patch is not extremely complex, but it's not trivial >> either. But if someone wants to take a stab at extending tuplesort to >> allow this, I won't object ... > > Same here: While I do have some ideas on where and how to implement > this, I'm not planning on working on that soon. > Understood. I don't have a very good intuition on how significant the benefit could be, which is one of the reasons why I have not prioritized this very much. I did a quick experiment, to measure how expensive it is to build the second worker tuplesort - for the pg_trgm index build with 2 workers, it takes ~30seconds. The index build takes ~550s in total, so 30s is ~5%. If we eliminated all of this work we'd save this, but in reality some of it will still be necessary. Perhaps it's more significant for other indexes / slower storage, but it does not seem like a *must have* for v1. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Tomas Vondra <tomas.vondra@enterprisedb.com> writes: >> I guess both of you are talking about worker process, if here are >> something in my mind: >> >> *btbuild* also let the WORKER dump the tuples into Sharedsort struct >> and let the LEADER merge them directly. I think this aim of this design >> is it is potential to save a mergeruns. In the current patch, worker dump >> to local tuplesort and mergeruns it and then leader run the merges >> again. I admit the goal of this patch is reasonable, but I'm feeling we >> need to adapt this way conditionally somehow. and if we find the way, we >> can apply it to btbuild as well. >> > > I'm a bit confused about what you're proposing here, or how is that > related to what this patch is doing and/or to the what Matthias > mentioned in his e-mail from last week. > > Let me explain the relevant part of the patch, and how I understand the > improvement suggested by Matthias. The patch does the work in three phases: What's in my mind is: 1. WORKER-1 Tempfile 1: key1: 1 key3: 2 ... Tempfile 2: key5: 3 key7: 4 ... 2. WORKER-2 Tempfile 1: Key2: 1 Key6: 2 ... Tempfile 2: Key3: 3 Key6: 4 .. In the above example: if we do the the merge in LEADER, only 1 mergerun is needed. reading 4 tempfile 8 tuples in total and write 8 tuples. If we adds another mergerun into WORKER, the result will be: WORKER1: reading 2 tempfile 4 tuples and write 1 tempfile (called X) 4 tuples. WORKER2: reading 2 tempfile 4 tuples and write 1 tempfile (called Y) 4 tuples. LEADER: reading 2 tempfiles (X & Y) including 8 tuples and write it into final tempfile. So the intermedia result X & Y requires some extra effort. so I think the "extra mergerun in worker" is *not always* a win, and my proposal is if we need to distinguish the cases in which one we should add the "extra mergerun in worker" step. > The trouble with (2) is that it "just copies" data from one tuplesort > into another, increasing the disk space requirements. In an extreme > case, when nothing can be combined, it pretty much doubles the amount of > disk space, and makes the build longer. This sounds like the same question as I talk above, However my proposal is to distinguish which cost is bigger between "the cost saving from merging TIDs in WORKERS" and "cost paid because of the extra copy", then we do that only when we are sure we can benefits from it, but I know it is hard and not sure if it is doable. > What I think Matthias is suggesting, is that this "TID list merging" > could be done directly as part of the tuplesort in step (1). So instead > of just moving the "sort tuples" from the appropriate runs, it could > also do an optional step of combining the tuples and writing this > combined tuple into the tuplesort result (for that worker). OK, I get it now. So we talked about lots of merge so far at different stage and for different sets of tuples. 1. "GIN deform buffer" did the TIDs merge for the same key for the tuples in one "deform buffer" batch, as what the current master is doing. 2. "in memory buffer sort" stage, currently there is no TID merge so far and Matthias suggest that. 3. Merge the TIDs for the same keys in LEADER vs in WORKER first + LEADER then. this is what your 0002 commit does now and I raised some concerns as above. > Matthias also mentioned this might be useful when building btree indexes > with key deduplication. > AFAICS this might work, although it probably requires for the "combined" > tuple to be smaller than the sum of the combined tuples (in order to fit > into the space). But at least in the GIN build in the workers this is > likely true, because the TID lists do not overlap (and thus not hurting > the compressibility). > > That being said, I still see this more as an optimization than something > required for the patch, If GIN deform buffer is big enough (like greater than the in memory buffer sort) shall we have any gain because of this, since the scope is the tuples in in-memory-buffer-sort. > and I don't think I'll have time to work on this > anytime soon. The patch is not extremely complex, but it's not trivial > either. But if someone wants to take a stab at extending tuplesort to > allow this, I won't object ... Agree with this. I am more interested with understanding the whole design and the scope to fix in this patch, and then I can do some code review and testing, as for now, I still in the "understanding design and scope" stage. If I'm too slow about this patch, please feel free to commit it any time and I don't expect I can find any valueable improvement and bugs. I probably needs another 1 ~ 2 weeks to study this patch. -- Best Regards Andy Fan
On 5/10/24 07:53, Andy Fan wrote: > > Tomas Vondra <tomas.vondra@enterprisedb.com> writes: > >>> I guess both of you are talking about worker process, if here are >>> something in my mind: >>> >>> *btbuild* also let the WORKER dump the tuples into Sharedsort struct >>> and let the LEADER merge them directly. I think this aim of this design >>> is it is potential to save a mergeruns. In the current patch, worker dump >>> to local tuplesort and mergeruns it and then leader run the merges >>> again. I admit the goal of this patch is reasonable, but I'm feeling we >>> need to adapt this way conditionally somehow. and if we find the way, we >>> can apply it to btbuild as well. >>> >> >> I'm a bit confused about what you're proposing here, or how is that >> related to what this patch is doing and/or to the what Matthias >> mentioned in his e-mail from last week. >> >> Let me explain the relevant part of the patch, and how I understand the >> improvement suggested by Matthias. The patch does the work in three phases: > > What's in my mind is: > > 1. WORKER-1 > > Tempfile 1: > > key1: 1 > key3: 2 > ... > > Tempfile 2: > > key5: 3 > key7: 4 > ... > > 2. WORKER-2 > > Tempfile 1: > > Key2: 1 > Key6: 2 > ... > > Tempfile 2: > Key3: 3 > Key6: 4 > .. > > In the above example: if we do the the merge in LEADER, only 1 mergerun > is needed. reading 4 tempfile 8 tuples in total and write 8 tuples. > > If we adds another mergerun into WORKER, the result will be: > > WORKER1: reading 2 tempfile 4 tuples and write 1 tempfile (called X) 4 > tuples. > WORKER2: reading 2 tempfile 4 tuples and write 1 tempfile (called Y) 4 > tuples. > > LEADER: reading 2 tempfiles (X & Y) including 8 tuples and write it > into final tempfile. > > So the intermedia result X & Y requires some extra effort. so I think > the "extra mergerun in worker" is *not always* a win, and my proposal is > if we need to distinguish the cases in which one we should add the > "extra mergerun in worker" step. > The thing you're forgetting is that the mergesort in the worker is *always* a simple append, because the lists are guaranteed to be non-overlapping, so it's very cheap. The lists from different workers are however very likely to overlap, and hence a "full" mergesort is needed, which is way more expensive. And not only that - without the intermediate merge, there will be very many of those lists the leader would have to merge. If we do the append-only merges in the workers first, we still need to merge them in the leader, of course, but we have few lists to merge (only about one per worker). Of course, this means extra I/O on the intermediate tuplesort, and it's not difficult to imagine cases with no benefit, or perhaps even a regression. For example, if the keys are unique, the in-worker merge step can't really do anything. But that seems quite unlikely IMHO. Also, if this overhead was really significant, we would not see the nice speedups I measured during testing. >> The trouble with (2) is that it "just copies" data from one tuplesort >> into another, increasing the disk space requirements. In an extreme >> case, when nothing can be combined, it pretty much doubles the amount of >> disk space, and makes the build longer. > > This sounds like the same question as I talk above, However my proposal > is to distinguish which cost is bigger between "the cost saving from > merging TIDs in WORKERS" and "cost paid because of the extra copy", > then we do that only when we are sure we can benefits from it, but I > know it is hard and not sure if it is doable. > Yeah. I'm not against picking the right execution strategy during the index build, but it's going to be difficult, because we really don't have the information to make a reliable decision. We can't even use the per-column stats, because it does not say much about the keys extracted by GIN, I think. And we need to do the decision at the very beginning, before we write the first batch of data either to the local or shared tuplesort. But maybe we could wait until we need to flush the first batch of data (in the callback), and make the decision then? In principle, if we only flush once at the end, the intermediate sort is not needed at all (fairy unlikely for large data sets, though). Well, in principle, maybe we could even start writing into the local tuplesort, and then "rethink" after a while and switch to the shared one. We'd still need to copy data we've already written to the local tuplesort, but hopefully that'd be just a fraction compared to doing that for the whole table. >> What I think Matthias is suggesting, is that this "TID list merging" >> could be done directly as part of the tuplesort in step (1). So instead >> of just moving the "sort tuples" from the appropriate runs, it could >> also do an optional step of combining the tuples and writing this >> combined tuple into the tuplesort result (for that worker). > > OK, I get it now. So we talked about lots of merge so far at different > stage and for different sets of tuples. > > 1. "GIN deform buffer" did the TIDs merge for the same key for the tuples > in one "deform buffer" batch, as what the current master is doing. > > 2. "in memory buffer sort" stage, currently there is no TID merge so > far and Matthias suggest that. > > 3. Merge the TIDs for the same keys in LEADER vs in WORKER first + > LEADER then. this is what your 0002 commit does now and I raised some > concerns as above. > OK >> Matthias also mentioned this might be useful when building btree indexes >> with key deduplication. > >> AFAICS this might work, although it probably requires for the "combined" >> tuple to be smaller than the sum of the combined tuples (in order to fit >> into the space). But at least in the GIN build in the workers this is >> likely true, because the TID lists do not overlap (and thus not hurting >> the compressibility). >> >> That being said, I still see this more as an optimization than something >> required for the patch, > > If GIN deform buffer is big enough (like greater than the in memory > buffer sort) shall we have any gain because of this, since the > scope is the tuples in in-memory-buffer-sort. > I don't think this is very likely. The only case when the GIN deform tuple is "big enough" is when we don't need to flush in the callback, but that is going to happen only for "small" tables. And for those we should not really do parallel builds. And even if we do, the overhead would be pretty insignificant. >> and I don't think I'll have time to work on this >> anytime soon. The patch is not extremely complex, but it's not trivial >> either. But if someone wants to take a stab at extending tuplesort to >> allow this, I won't object ... > > Agree with this. I am more interested with understanding the whole > design and the scope to fix in this patch, and then I can do some code > review and testing, as for now, I still in the "understanding design and > scope" stage. If I'm too slow about this patch, please feel free to > commit it any time and I don't expect I can find any valueable > improvement and bugs. I probably needs another 1 ~ 2 weeks to study > this patch. > Sure, happy to discuss and answer questions. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Tomas Vondra <tomas.vondra@enterprisedb.com> writes: >>> 7) v20240502-0007-Detect-wrap-around-in-parallel-callback.patch >>> >>> There's one more efficiency problem - the parallel scans are required to >>> be synchronized, i.e. the scan may start half-way through the table, and >>> then wrap around. Which however means the TID list will have a very wide >>> range of TID values, essentially the min and max of for the key. >> >> I have two questions here and both of them are generall gin index questions >> rather than the patch here. >> >> 1. What does the "wrap around" mean in the "the scan may start half-way >> through the table, and then wrap around". Searching "wrap" in >> gin/README gets nothing. >> > > The "wrap around" is about the scan used to read data from the table > when building the index. A "sync scan" may start e.g. at TID (1000,0) > and read till the end of the table, and then wraps and returns the > remaining part at the beginning of the table for blocks 0-999. > > This means the callback would not see a monotonically increasing > sequence of TIDs. > > Which is why the serial build disables sync scans, allowing simply > appending values to the sorted list, and even with regular flushes of > data into the index we can simply append data to the posting lists. Thanks for the hints, I know the sync strategy comes from syncscan.c now. >>> Without 0006 this would cause frequent failures of the index build, with >>> the error I already mentioned: >>> >>> ERROR: could not split GIN page; all old items didn't fit >> 2. I can't understand the below error. >> >>> ERROR: could not split GIN page; all old items didn't fit > if (!append || ItemPointerCompare(&maxOldItem, &remaining) >= 0) > elog(ERROR, "could not split GIN page; all old items didn't fit"); > > It can fail simply because of the !append part. Got it, Thanks! >> If we split the blocks among worker 1-block by 1-block, we will have a >> serious issue like here. If we can have N-block by N-block, and N-block >> is somehow fill the work_mem which makes the dedicated temp file, we >> can make things much better, can we? > I don't understand the question. The blocks are distributed to workers > by the parallel table scan, and it certainly does not do that block by > block. But even it it did, that's not a problem for this code. OK, I get ParallelBlockTableScanWorkerData.phsw_chunk_size is designed for this. > The problem is that if the scan wraps around, then one of the TID lists > for a given worker will have the min TID and max TID, so it will overlap > with every other TID list for the same key in that worker. And when the > worker does the merging, this list will force a "full" merge sort for > all TID lists (for that key), which is very expensive. OK. Thanks for all the answers, they are pretty instructive! -- Best Regards Andy Fan
On 5/13/24 10:19, Andy Fan wrote: > > Tomas Vondra <tomas.vondra@enterprisedb.com> writes: > >> ... >> >> I don't understand the question. The blocks are distributed to workers >> by the parallel table scan, and it certainly does not do that block by >> block. But even it it did, that's not a problem for this code. > > OK, I get ParallelBlockTableScanWorkerData.phsw_chunk_size is designed > for this. > >> The problem is that if the scan wraps around, then one of the TID lists >> for a given worker will have the min TID and max TID, so it will overlap >> with every other TID list for the same key in that worker. And when the >> worker does the merging, this list will force a "full" merge sort for >> all TID lists (for that key), which is very expensive. > > OK. > > Thanks for all the answers, they are pretty instructive! > Thanks for the questions, it forces me to articulate the arguments more clearly. I guess it'd be good to put some of this into a README or at least a comment at the beginning of gininsert.c or somewhere close. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi Tomas,
I have completed my first round of review, generally it looks good to
me, more testing need to be done in the next days. Here are some tiny
comments from my side, just FYI.
1. Comments about GinBuildState.bs_leader looks not good for me.
/*
* bs_leader is only present when a parallel index build is performed, and
* only in the leader process. (Actually, only the leader process has a
* GinBuildState.)
*/
GinLeader *bs_leader;
In the worker function _gin_parallel_build_main:
initGinState(&buildstate.ginstate, indexRel); is called, and the
following members in workers at least: buildstate.funcCtx,
buildstate.accum and so on. So is the comment "only the leader process
has a GinBuildState" correct?
2. progress argument is not used?
_gin_parallel_scan_and_build(GinBuildState *state,
GinShared *ginshared, Sharedsort *sharedsort,
Relation heap, Relation index,
int sortmem, bool progress)
3. In function tuplesort_begin_index_gin, comments about nKeys takes me
some time to think about why 1 is correct(rather than
IndexRelationGetNumberOfKeyAttributes) and what does the "only the index
key" means.
base->nKeys = 1; /* Only the index key */
finally I think it is because gin index stores each attribute value into
an individual index entry for a multi-column index, so each index entry
has only 1 key. So we can comment it as the following?
"Gin Index stores the value of each attribute into different index entry
for mutli-column index, so each index entry has only 1 key all the
time." This probably makes it easier to understand.
4. GinBuffer: The comment "Similar purpose to BuildAccumulator, but much
simpler." makes me think why do we need a simpler but
similar structure, After some thoughts, they are similar at accumulating
TIDs only. GinBuffer is designed for "same key value" (hence
GinBufferCanAddKey). so IMO, the first comment is good enough and the 2
comments introduce confuses for green hand and is potential to remove
it.
/*
* State used to combine accumulate TIDs from multiple GinTuples for the same
* key value.
*
* XXX Similar purpose to BuildAccumulator, but much simpler.
*/
typedef struct GinBuffer
5. GinBuffer: ginMergeItemPointers always allocate new memory for the
new items and hence we have to pfree old memory each time. However it is
not necessary in some places, for example the new items can be appended
to Buffer->items (and this should be a common case). So could we
pre-allocate some spaces for items and reduce the number of pfree/palloc
and save some TID items copy in the desired case?
6. GinTuple.ItemPointerData first; /* first TID in the array */
is ItemPointerData.ip_blkid good enough for its purpose? If so, we can
save the memory for OffsetNumber for each GinTuple.
Item 5) and 6) needs some coding and testing. If it is OK to do, I'd
like to take it as an exercise in this area. (also including the item
1~4.)
--
Best Regards
Andy Fan
Hi Andy, Thanks for the review. Here's an updated patch series, addressing most of the points you've raised - I've kept them in "fixup" patches for now, should be merged into 0001. More detailed responses below. On 5/28/24 11:29, Andy Fan wrote: > > Hi Tomas, > > I have completed my first round of review, generally it looks good to > me, more testing need to be done in the next days. Here are some tiny > comments from my side, just FYI. > > 1. Comments about GinBuildState.bs_leader looks not good for me. > > /* > * bs_leader is only present when a parallel index build is performed, and > * only in the leader process. (Actually, only the leader process has a > * GinBuildState.) > */ > GinLeader *bs_leader; > > In the worker function _gin_parallel_build_main: > initGinState(&buildstate.ginstate, indexRel); is called, and the > following members in workers at least: buildstate.funcCtx, > buildstate.accum and so on. So is the comment "only the leader process > has a GinBuildState" correct? > Yeah, this is misleading. I don't remember what exactly was my reasoning for this wording, I've removed the comment. > 2. progress argument is not used? > _gin_parallel_scan_and_build(GinBuildState *state, > GinShared *ginshared, Sharedsort *sharedsort, > Relation heap, Relation index, > int sortmem, bool progress) > I've modified the code to use the progress flag, but now that I look at it I'm a bit unsure I understand the purpose of this. I've modeled this after what the btree does, and I see that there are two places calling _bt_parallel_scan_and_sort: 1) _bt_leader_participate_as_worker: progress=true 2) _bt_parallel_build_main: progress=false Isn't that a bit weird? AFAIU the progress will be updated only by the leader, but will that progress be correct? And doesn't that means the if the leader does not participate as a worker, the progress won't be updated? FWIW The parallel BRIN code has the same issue - it's not using the progress flag in _brin_parallel_scan_and_build. > > 3. In function tuplesort_begin_index_gin, comments about nKeys takes me > some time to think about why 1 is correct(rather than > IndexRelationGetNumberOfKeyAttributes) and what does the "only the index > key" means. > > base->nKeys = 1; /* Only the index key */ > > finally I think it is because gin index stores each attribute value into > an individual index entry for a multi-column index, so each index entry > has only 1 key. So we can comment it as the following? > > "Gin Index stores the value of each attribute into different index entry > for mutli-column index, so each index entry has only 1 key all the > time." This probably makes it easier to understand. > OK, I see what you mean. The other tuplesort_begin_ functions nearby have similar comments, but you're right GIN is a bit special in that it "splits" multi-column indexes into individual index entries. I've added a comment (hopefully) clarifying this. > > 4. GinBuffer: The comment "Similar purpose to BuildAccumulator, but much > simpler." makes me think why do we need a simpler but > similar structure, After some thoughts, they are similar at accumulating > TIDs only. GinBuffer is designed for "same key value" (hence > GinBufferCanAddKey). so IMO, the first comment is good enough and the 2 > comments introduce confuses for green hand and is potential to remove > it. > > /* > * State used to combine accumulate TIDs from multiple GinTuples for the same > * key value. > * > * XXX Similar purpose to BuildAccumulator, but much simpler. > */ > typedef struct GinBuffer > I've updated the comment explaining the differences a bit clearer. > > 5. GinBuffer: ginMergeItemPointers always allocate new memory for the > new items and hence we have to pfree old memory each time. However it is > not necessary in some places, for example the new items can be appended > to Buffer->items (and this should be a common case). So could we > pre-allocate some spaces for items and reduce the number of pfree/palloc > and save some TID items copy in the desired case? > Perhaps, but that seems rather independent of this patch. Also, I'm not sure how much would this optimization matter in practice. The merge should happens fairly rarely, when we decide to store the TIDs into the index. And then it's also subject to the caching built into the memory contexts, limiting the malloc costs. We'll still pay for the memcpy, of course. Anyway, it's an optimization that would affect existing callers of ginMergeItemPointers. I don't plan to tweak this in this patch. > 6. GinTuple.ItemPointerData first; /* first TID in the array */ > > is ItemPointerData.ip_blkid good enough for its purpose? If so, we can > save the memory for OffsetNumber for each GinTuple. > > Item 5) and 6) needs some coding and testing. If it is OK to do, I'd > like to take it as an exercise in this area. (also including the item > 1~4.) > It might save 2 bytes in the struct, but that's negligible compared to the memory usage overall (we only keep one GinTuple, but many TIDs and so on), and we allocate the space in power-of-2 pattern anyway (which means the 2B won't matter). Moreover, using just the block number would make it harder to compare the TIDs (now we can just call ItemPointerCompare). regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Вложения
- v20240619-0001-Allow-parallel-create-for-GIN-indexes.patch
- v20240619-0002-fixup-pass-progress-flag.patch
- v20240619-0003-fixup-remove-inaccurate-comment.patch
- v20240619-0004-fixup-clarify-tuplesort_begin_index_gin.patch
- v20240619-0005-fixup-clarify-GinBuffer-comment.patch
- v20240619-0006-Use-mergesort-in-the-leader-process.patch
- v20240619-0007-Remove-the-explicit-pg_qsort-in-workers.patch
- v20240619-0008-Compress-TID-lists-before-writing-tuples-t.patch
- v20240619-0009-Collect-and-print-compression-stats.patch
- v20240619-0010-Enforce-memory-limit-when-combining-tuples.patch
- v20240619-0011-Detect-wrap-around-in-parallel-callback.patch
Here's a cleaned up patch series, merging the fixup patches into 0001. I've also removed the memset() from ginInsertBAEntry(). This was meant to fix valgrind reports, but I believe this was just a symptom of incorrect handling of byref data types, which was fixed in 2024/05/02 patch version. The other thing I did is cleanup of FIXME and XXX comments. There were a couple stale/obsolete comments, discussing issues that have been already fixed (like the scan wrapping around). A couple things to fix remain, but all of them are minor. And there's also a couple XXX comments, often describing thing that is then done in one of the following patches. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Вложения
- v20240620-0001-Allow-parallel-create-for-GIN-indexes.patch
- v20240620-0002-Use-mergesort-in-the-leader-process.patch
- v20240620-0003-Remove-the-explicit-pg_qsort-in-workers.patch
- v20240620-0004-Compress-TID-lists-before-writing-tuples-t.patch
- v20240620-0005-Collect-and-print-compression-stats.patch
- v20240620-0006-Enforce-memory-limit-when-combining-tuples.patch
- v20240620-0007-Detect-wrap-around-in-parallel-callback.patch
Here's a bit more cleaned up version, clarifying a lot of comments, removing a bunch of obsolete comments, or comments speculating about possible solutions, that sort of thing. I've also removed couple more XXX comments, etc. The main change however is that the sorting no longer relies on memcmp() to compare the values. I did that because it was enough for the initial WIP patches, and it worked till now - but the comments explained this may not be a good idea if the data type allows the same value to have multiple binary representations, or something like that. I don't have a practical example to show an issue, but I guess if using memcmp() was safe we'd be doing it in a bunch of places already, and AFAIK we're not. And even if it happened to be OK, this is a probably not the place where to start doing it. So I've switched this to use the regular data-type comparisons, with SortSupport etc. There's a bit more cleanup remaining and testing needed, but I'm not aware of any bugs. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Вложения
- v20240624-0001-Allow-parallel-create-for-GIN-indexes.patch
- v20240624-0002-Use-mergesort-in-the-leader-process.patch
- v20240624-0003-Remove-the-explicit-pg_qsort-in-workers.patch
- v20240624-0004-Compress-TID-lists-before-writing-tuples-t.patch
- v20240624-0005-Collect-and-print-compression-stats.patch
- v20240624-0006-Enforce-memory-limit-when-combining-tuples.patch
- v20240624-0007-Detect-wrap-around-in-parallel-callback.patch