Обсуждение: New IndexAM API controlling index vacuum strategies
Hi all,
I've started this separate thread from [1] for discussing the general
API design of index vacuum.
Summary:
* Call ambulkdelete and amvacuumcleanup even when INDEX_CLEANUP is
false, and leave it to the index AM whether or not skip them.
* Add a new index AM API amvacuumstrategy(), asking the index AM the
strategy before calling to ambulkdelete.
* Whether or not remove garbage tuples from heap depends on multiple
factors including INDEX_CLEANUP option and the answers of
amvacuumstrategy() for each index AM.
The first point is to fix the inappropriate behavior discussed on the thread[1].
The second and third points are to introduce a general framework for
future extensibility. User-visible behavior is not changed by this
change.
The new index AM API, amvacuumstrategy(), which is called before
bulkdelete() for each index and asks the index bulk-deletion strategy.
On this API, lazy vacuum asks, "Hey index X, I collected garbage heap
tuples during heap scanning, how urgent is vacuuming for you?", and
the index answers either "it's urgent" when it wants to do
bulk-deletion or "it's not urgent, I can skip it". The point of this
proposal is to isolate heap vacuum and index vacuum for each index so
that we can employ different strategies for each index. Lazy vacuum
can decide whether or not to do heap clean based on the answers from
the indexes.
By default, if all indexes answer 'yes' (meaning it will do
bulkdelete()), lazy vacuum can do heap clean. On the other hand, if
even one index answers 'no' (meaning it will not do bulkdelete()),
lazy vacuum doesn't the heap clean. Lazy vacuum would also be able to
require indexes to do bulkdelete() for some reason such as specyfing
INDEX_CLEANUP option by the user. It’s something like saying "Hey
index X, you answered not to do bulkdelete() but since heap clean is
necessary for me please don't skip bulkdelete()".
Currently, if INDEX_CLEANUP option is not set (i.g.
VACOPT_TERNARY_DEFAULT in the code), it's treated as true and will do
heap clean. But with this patch we use the default as a neutral state
('smart' mode). This neutral state could be "on" and "off" depending
on several factors including the answers of amvacuumstrategy(), the
table status, and user's request. In this context, specifying
INDEX_CLEANUP would mean making the neutral state "on" or "off" by
user's request. The table status that could influence the decision
could concretely be, for instance:
* Removing LP_DEAD accumulation due to skipping bulkdelete() for a long time.
* Making pages all-visible for index-only scan.
Also there are potential enhancements using this API:
* If bottom-up index deletion feature[2] is introduced, individual
indexes could be a different situation in terms of dead tuple
accumulation; some indexes on the table can delete its garbage index
tuples without bulkdelete(). A problem will appear that doing
bulkdelete() for such indexes would not be efficient. This problem is
solved by this proposal because we can do bulkdelete() for a subset of
indexes on the table.
* If retail index deletion feature[3] is introduced, we can make the
return value of bulkvacuumstrategy() a ternary value: "do_bulkdelete",
"do_indexscandelete", and "no".
* We probably can introduce a threshold of the number of dead tuples
to control whether or not to do index tuple bulk-deletion (like
bulkdelete() version of vacuum_cleanup_index_scale_factor). In the
case where the amount of dead tuples is slightly larger than
maitenance_work_mem the second time calling to bulkdelete will be
called with a small number of dead tuples, which is inefficient. This
problem is also solved by this proposal by allowing a subset of
indexes to skip bulkdelete() if the number of dead tuple doesn't
exceed the threshold.
I’ve attached the PoC patch for the above idea. By default, since lazy
vacuum choose the vacuum bulkdelete strategy based on answers of
amvacuumstrategy() so it can be either true or false ( although it’s
always true in the currene patch). But for amvacuumcleanup() there is
no the neutral state, lazy vacuum treats the default as true.
Comment and feedback are very welcome.
Regards,
[1] https://www.postgresql.org/message-id/20200415233848.saqp72pcjv2y6ryi%40alap3.anarazel.de
[2] https://www.postgresql.org/message-id/CAH2-Wzm%2BmaE3apHB8NOtmM%3Dp-DO65j2V5GzAWCOEEuy3JZgb2g%40mail.gmail.com
[3] https://www.postgresql.org/message-id/425db134-8bba-005c-b59d-56e50de3b41e%40postgrespro.ru
--
Masahiko Sawada
EnterpriseDB: https://www.enterprisedb.com/
Вложения
On Tue, Dec 22, 2020 at 2:54 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> I've started this separate thread from [1] for discussing the general
> API design of index vacuum.
This is a very difficult and very important problem. Clearly defining
the problem is probably the hardest part. This prototype patch seems
like a good start, though.
Private discussion between Masahiko and myself led to a shared
understanding of what the best *general* direction is for VACUUM now.
It is necessary to deal with several problems all at once here, and to
at least think about several more problems that will need to be solved
later. If anybody reading the thread initially finds it hard to see
the connection between the specific items that Masahiko has
introduced, they should note that that's *expected*.
> Summary:
>
> * Call ambulkdelete and amvacuumcleanup even when INDEX_CLEANUP is
> false, and leave it to the index AM whether or not skip them.
Makes sense. I like the way you unify INDEX_CLEANUP and the
vacuum_cleanup_index_scale_factor stuff in a way that is now quite
explicit and obvious in the code.
> The second and third points are to introduce a general framework for
> future extensibility. User-visible behavior is not changed by this
> change.
In some ways the ideas in your patch might be considered radical, or
at least novel: they introduce the idea that bloat can be a
qualitative thing. But at the same time the design is quite
conservative: these are fairly isolated changes, at least code-wise. I
am not 100% sure that this approach will be successful in
vacuumlazy.c, in the end (I'm ~95% sure). But I am 100% sure that our
collective understanding of the problems in this area will be
significantly improved by this effort. A fundamental rethink does not
necessarily require a fundamental redesign, and yet it might be just
as effective.
This is certainly what I see when testing my bottom-up index deletion
patch, which adds an incremental index deletion mechanism that merely
intervenes in a precise, isolated way. Despite my patch's simplicity,
it manages to practically eliminate an entire important *class* of
index bloat (at least once you make certain mild assumptions about the
duration of snapshots). Sometimes it is possible to solve a hard
problem by thinking about it only *slightly* differently.
This is a tantalizing possibility for VACUUM, too. I'm willing to risk
sounding grandiose if that's what it takes to get more hackers
interested in these questions. With that in mind, here is a summary of
the high level hypothesis behind this VACUUM patch:
VACUUM can and should be reimagined as a top-down mechanism that
complements various bottom-up mechanisms (including the stuff from my
deletion patch, heap pruning, and possibly an enhanced version of heap
pruning based on similar principles). This will be possible without
changing any of the fundamental invariants of the current vacuumlazy.c
design. VACUUM's problems are largely pathological behaviors of one
kind or another, that can be fixed with specific well-targeted
interventions. Workload characteristics can naturally determine how
much of the cleanup is done by VACUUM itself -- large variations are
possible within a single database, and even across indexes on the same
table.
> The new index AM API, amvacuumstrategy(), which is called before
> bulkdelete() for each index and asks the index bulk-deletion strategy.
> On this API, lazy vacuum asks, "Hey index X, I collected garbage heap
> tuples during heap scanning, how urgent is vacuuming for you?", and
> the index answers either "it's urgent" when it wants to do
> bulk-deletion or "it's not urgent, I can skip it". The point of this
> proposal is to isolate heap vacuum and index vacuum for each index so
> that we can employ different strategies for each index. Lazy vacuum
> can decide whether or not to do heap clean based on the answers from
> the indexes.
Right -- workload characteristics (plus appropriate optimizations at
the local level) make it possible that amvacuumstrategy() will give
*very* different answers from different indexes *on the same table*.
The idea that all indexes on the table are more or less equally
bloated at any given point in time is mostly wrong. Actually,
*sometimes* it really is correct! But other times it is *dramatically
wrong* -- it all depends on workload characteristics. What is likely
to be true *on average* across all tables/indexes is *irrelevant* (the
mean/average is simply not a useful concept, in fact).
The basic lazy vacuum design needs to recognize this important
difference, and other similar issues. That's the point of
amvacuumstrategy().
> Currently, if INDEX_CLEANUP option is not set (i.g.
> VACOPT_TERNARY_DEFAULT in the code), it's treated as true and will do
> heap clean. But with this patch we use the default as a neutral state
> ('smart' mode). This neutral state could be "on" and "off" depending
> on several factors including the answers of amvacuumstrategy(), the
> table status, and user's request. In this context, specifying
> INDEX_CLEANUP would mean making the neutral state "on" or "off" by
> user's request. The table status that could influence the decision
> could concretely be, for instance:
>
> * Removing LP_DEAD accumulation due to skipping bulkdelete() for a long time.
> * Making pages all-visible for index-only scan.
So you have several different kinds of back pressure - 'smart' mode
really is smart.
> Also there are potential enhancements using this API:
> * If retail index deletion feature[3] is introduced, we can make the
> return value of bulkvacuumstrategy() a ternary value: "do_bulkdelete",
> "do_indexscandelete", and "no".
Makes sense.
> * We probably can introduce a threshold of the number of dead tuples
> to control whether or not to do index tuple bulk-deletion (like
> bulkdelete() version of vacuum_cleanup_index_scale_factor). In the
> case where the amount of dead tuples is slightly larger than
> maitenance_work_mem the second time calling to bulkdelete will be
> called with a small number of dead tuples, which is inefficient. This
> problem is also solved by this proposal by allowing a subset of
> indexes to skip bulkdelete() if the number of dead tuple doesn't
> exceed the threshold.
Good idea. I bet other people can come up with other ideas a little
like this just by thinking about it. The "untangling" performed by
your patch creates many possibilities
> I’ve attached the PoC patch for the above idea. By default, since lazy
> vacuum choose the vacuum bulkdelete strategy based on answers of
> amvacuumstrategy() so it can be either true or false ( although it’s
> always true in the currene patch). But for amvacuumcleanup() there is
> no the neutral state, lazy vacuum treats the default as true.
As you said, the next question must be: How do we teach lazy vacuum to
not do what gets requested by amvacuumcleanup() when it cannot respect
the wishes of one individual indexes, for example when the
accumulation of LP_DEAD items in the heap becomes a big problem in
itself? That really could be the thing that forces full heap
vacuuming, even with several indexes.
I will need to experiment in order to improve my understanding of how
to make this cooperate with bottom-up index deletion. But that's
mostly just a question for my patch (and a relatively easy one).
--
Peter Geoghegan
On Thu, Dec 24, 2020 at 12:59 PM Peter Geoghegan <pg@bowt.ie> wrote:
>
> On Tue, Dec 22, 2020 at 2:54 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> > I've started this separate thread from [1] for discussing the general
> > API design of index vacuum.
>
> This is a very difficult and very important problem. Clearly defining
> the problem is probably the hardest part. This prototype patch seems
> like a good start, though.
>
> Private discussion between Masahiko and myself led to a shared
> understanding of what the best *general* direction is for VACUUM now.
> It is necessary to deal with several problems all at once here, and to
> at least think about several more problems that will need to be solved
> later. If anybody reading the thread initially finds it hard to see
> the connection between the specific items that Masahiko has
> introduced, they should note that that's *expected*.
>
> > Summary:
> >
> > * Call ambulkdelete and amvacuumcleanup even when INDEX_CLEANUP is
> > false, and leave it to the index AM whether or not skip them.
>
> Makes sense. I like the way you unify INDEX_CLEANUP and the
> vacuum_cleanup_index_scale_factor stuff in a way that is now quite
> explicit and obvious in the code.
>
> > The second and third points are to introduce a general framework for
> > future extensibility. User-visible behavior is not changed by this
> > change.
>
> In some ways the ideas in your patch might be considered radical, or
> at least novel: they introduce the idea that bloat can be a
> qualitative thing. But at the same time the design is quite
> conservative: these are fairly isolated changes, at least code-wise. I
> am not 100% sure that this approach will be successful in
> vacuumlazy.c, in the end (I'm ~95% sure). But I am 100% sure that our
> collective understanding of the problems in this area will be
> significantly improved by this effort. A fundamental rethink does not
> necessarily require a fundamental redesign, and yet it might be just
> as effective.
>
> This is certainly what I see when testing my bottom-up index deletion
> patch, which adds an incremental index deletion mechanism that merely
> intervenes in a precise, isolated way. Despite my patch's simplicity,
> it manages to practically eliminate an entire important *class* of
> index bloat (at least once you make certain mild assumptions about the
> duration of snapshots). Sometimes it is possible to solve a hard
> problem by thinking about it only *slightly* differently.
>
> This is a tantalizing possibility for VACUUM, too. I'm willing to risk
> sounding grandiose if that's what it takes to get more hackers
> interested in these questions. With that in mind, here is a summary of
> the high level hypothesis behind this VACUUM patch:
>
> VACUUM can and should be reimagined as a top-down mechanism that
> complements various bottom-up mechanisms (including the stuff from my
> deletion patch, heap pruning, and possibly an enhanced version of heap
> pruning based on similar principles). This will be possible without
> changing any of the fundamental invariants of the current vacuumlazy.c
> design. VACUUM's problems are largely pathological behaviors of one
> kind or another, that can be fixed with specific well-targeted
> interventions. Workload characteristics can naturally determine how
> much of the cleanup is done by VACUUM itself -- large variations are
> possible within a single database, and even across indexes on the same
> table.
Agreed.
Ideally, the bottom-up mechanism works well and reclaim almost all
garbage. VACUUM should be a feature that complements these works if
the bottom-up mechanism cannot work well for some reason, and also is
used to make sure that all collected garbage has been vacuumed. For
heaps, we already have such a mechanism: opportunistically hot-pruning
and lazy vacuum. For indexes especially btree indexes, the bottom-up
index deletion and ambulkdelete() would have a similar relationship.
>
> > The new index AM API, amvacuumstrategy(), which is called before
> > bulkdelete() for each index and asks the index bulk-deletion strategy.
> > On this API, lazy vacuum asks, "Hey index X, I collected garbage heap
> > tuples during heap scanning, how urgent is vacuuming for you?", and
> > the index answers either "it's urgent" when it wants to do
> > bulk-deletion or "it's not urgent, I can skip it". The point of this
> > proposal is to isolate heap vacuum and index vacuum for each index so
> > that we can employ different strategies for each index. Lazy vacuum
> > can decide whether or not to do heap clean based on the answers from
> > the indexes.
>
> Right -- workload characteristics (plus appropriate optimizations at
> the local level) make it possible that amvacuumstrategy() will give
> *very* different answers from different indexes *on the same table*.
> The idea that all indexes on the table are more or less equally
> bloated at any given point in time is mostly wrong. Actually,
> *sometimes* it really is correct! But other times it is *dramatically
> wrong* -- it all depends on workload characteristics. What is likely
> to be true *on average* across all tables/indexes is *irrelevant* (the
> mean/average is simply not a useful concept, in fact).
>
> The basic lazy vacuum design needs to recognize this important
> difference, and other similar issues. That's the point of
> amvacuumstrategy().
Agreed.
In terms of bloat, the characteristics of index AM also bring such
differences (e.g., btree vs. brin). With the bottom-up index deletion
feature, even btree indexes on the same table will also different to
each other.
>
> > Currently, if INDEX_CLEANUP option is not set (i.g.
> > VACOPT_TERNARY_DEFAULT in the code), it's treated as true and will do
> > heap clean. But with this patch we use the default as a neutral state
> > ('smart' mode). This neutral state could be "on" and "off" depending
> > on several factors including the answers of amvacuumstrategy(), the
> > table status, and user's request. In this context, specifying
> > INDEX_CLEANUP would mean making the neutral state "on" or "off" by
> > user's request. The table status that could influence the decision
> > could concretely be, for instance:
> >
> > * Removing LP_DEAD accumulation due to skipping bulkdelete() for a long time.
> > * Making pages all-visible for index-only scan.
>
> So you have several different kinds of back pressure - 'smart' mode
> really is smart.
>
> > Also there are potential enhancements using this API:
>
> > * If retail index deletion feature[3] is introduced, we can make the
> > return value of bulkvacuumstrategy() a ternary value: "do_bulkdelete",
> > "do_indexscandelete", and "no".
>
> Makes sense.
>
> > * We probably can introduce a threshold of the number of dead tuples
> > to control whether or not to do index tuple bulk-deletion (like
> > bulkdelete() version of vacuum_cleanup_index_scale_factor). In the
> > case where the amount of dead tuples is slightly larger than
> > maitenance_work_mem the second time calling to bulkdelete will be
> > called with a small number of dead tuples, which is inefficient. This
> > problem is also solved by this proposal by allowing a subset of
> > indexes to skip bulkdelete() if the number of dead tuple doesn't
> > exceed the threshold.
>
> Good idea. I bet other people can come up with other ideas a little
> like this just by thinking about it. The "untangling" performed by
> your patch creates many possibilities
>
> > I’ve attached the PoC patch for the above idea. By default, since lazy
> > vacuum choose the vacuum bulkdelete strategy based on answers of
> > amvacuumstrategy() so it can be either true or false ( although it’s
> > always true in the currene patch). But for amvacuumcleanup() there is
> > no the neutral state, lazy vacuum treats the default as true.
>
> As you said, the next question must be: How do we teach lazy vacuum to
> not do what gets requested by amvacuumcleanup() when it cannot respect
> the wishes of one individual indexes, for example when the
> accumulation of LP_DEAD items in the heap becomes a big problem in
> itself? That really could be the thing that forces full heap
> vacuuming, even with several indexes.
You mean requested by amvacuumstreategy(), not by amvacuumcleanup()? I
think amvacuumstrategy() affects only ambulkdelete(). But when all
ambulkdelete() were skipped by the requests by index AMs we might want
to skip amvacuumcleanup() as well.
>
> I will need to experiment in order to improve my understanding of how
> to make this cooperate with bottom-up index deletion. But that's
> mostly just a question for my patch (and a relatively easy one).
Yeah, I think we might need something like statistics about garbage
per index so that individual index can make a different decision based
on their status. For example, a btree index might want to skip
ambulkdelete() if it has a few dead index tuples in its leaf pages. It
could be on stats collector or on btree's meta page.
Regards,
--
Masahiko Sawada
EnterpriseDB: https://www.enterprisedb.com/
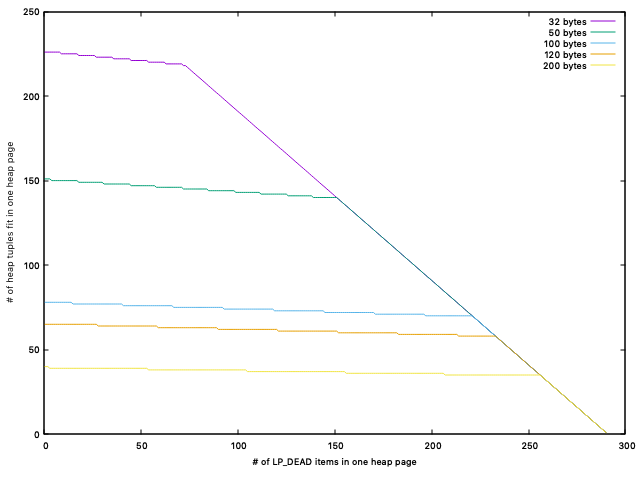
On Sun, Dec 27, 2020 at 10:55 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > As you said, the next question must be: How do we teach lazy vacuum to > > not do what gets requested by amvacuumcleanup() when it cannot respect > > the wishes of one individual indexes, for example when the > > accumulation of LP_DEAD items in the heap becomes a big problem in > > itself? That really could be the thing that forces full heap > > vacuuming, even with several indexes. > > You mean requested by amvacuumstreategy(), not by amvacuumcleanup()? I > think amvacuumstrategy() affects only ambulkdelete(). But when all > ambulkdelete() were skipped by the requests by index AMs we might want > to skip amvacuumcleanup() as well. No, I was asking about how we should decide to do a real VACUUM even (a real ambulkdelete() call) when no index asks for it because bottom-up deletion works very well in every index. Clearly we will need to eventually remove remaining LP_DEAD items from the heap at some point if nothing else happens -- eventually LP_DEAD items in the heap alone will force a traditional heap vacuum (which will still have to go through indexes that have not grown, just to be safe/avoid recycling a TID that's still in the index). Postgres heap fillfactor is 100 by default, though I believe it's 90 in another well known DB system. If you set Postgres heap fill factor to 90 you can fit a little over 200 LP_DEAD items in the "extra space" left behind in each heap page after initial bulk loading/INSERTs take place that respect our lower fill factor setting. This is about 4x the number of initial heap tuples in the pgbench_accounts table -- it's quite a lot! If we pessimistically assume that all updates are non-HOT updates, we'll still usually have enough space for each logical row to get updated several times before the heap page "overflows". Even when there is significant skew in the UPDATEs, the skew is not noticeable at the level of individual heap pages. We have a surprisingly large general capacity to temporarily "absorb" extra garbage LP_DEAD items in heap pages this way. Nobody really cared about this extra capacity very much before now, because it did not help with the big problem of index bloat that you naturally see with this workload. But that big problem may go away soon, and so this extra capacity may become important at the same time. I think that it could make sense for lazy_scan_heap() to maintain statistics about the number of LP_DEAD items remaining in each heap page (just local stack variables). From there, it can pass the statistics to the choose_vacuum_strategy() function from your patch. Perhaps choose_vacuum_strategy() will notice that the heap page with the most LP_DEAD items encountered within lazy_scan_heap() (among those encountered so far in the event of multiple index passes) has too many LP_DEAD items -- this indicates that there is a danger that some heap pages will start to "overflow" soon, which is now a problem that lazy_scan_heap() must think about. Maybe if the "extra space" left by applying heap fill factor (with settings below 100) is insufficient to fit perhaps 2/3 of the LP_DEAD items needed on the heap page that has the most LP_DEAD items (among all heap pages), we stop caring about what amvacuumstrategy()/the indexes say. So we do the right thing for the heap pages, while still mostly avoiding index vacuuming and the final heap pass. I experimented with this today, and I think that it is a good way to do it. I like the idea of choose_vacuum_strategy() understanding that heap pages that are subject to many non-HOT updates have a "natural extra capacity for LP_DEAD items" that it must care about directly (at least with non-default heap fill factor settings). My early testing shows that it will often take a surprisingly long time for the most heavily updated heap page to have more than about 100 LP_DEAD items. > > I will need to experiment in order to improve my understanding of how > > to make this cooperate with bottom-up index deletion. But that's > > mostly just a question for my patch (and a relatively easy one). > > Yeah, I think we might need something like statistics about garbage > per index so that individual index can make a different decision based > on their status. For example, a btree index might want to skip > ambulkdelete() if it has a few dead index tuples in its leaf pages. It > could be on stats collector or on btree's meta page. Right. I think that even a very conservative approach could work well. For example, maybe we teach nbtree's amvacuumstrategy() routine to ask to do a real ambulkdelete(), except in the extreme case where the index is *exactly* the same size as it was after the last VACUUM. This will happen regularly with bottom-up index deletion. Maybe that approach is a bit too conservative, though. -- Peter Geoghegan
On Sun, Dec 27, 2020 at 11:41 PM Peter Geoghegan <pg@bowt.ie> wrote: > I experimented with this today, and I think that it is a good way to > do it. I like the idea of choose_vacuum_strategy() understanding that > heap pages that are subject to many non-HOT updates have a "natural > extra capacity for LP_DEAD items" that it must care about directly (at > least with non-default heap fill factor settings). My early testing > shows that it will often take a surprisingly long time for the most > heavily updated heap page to have more than about 100 LP_DEAD items. Attached is a rough patch showing what I did here. It was applied on top of my bottom-up index deletion patch series and your poc_vacuumstrategy.patch patch. This patch was written as a quick and dirty way of simulating what I thought would work best for bottom-up index deletion for one specific benchmark/test, which was non-hot-update heavy. This consists of a variant pgbench with several indexes on pgbench_accounts (almost the same as most other bottom-up deletion benchmarks I've been running). Only one index is "logically modified" by the updates, but of course we still physically modify all indexes on every update. I set fill factor to 90 for this benchmark, which is an important factor for how your VACUUM patch works during the benchmark. This rough supplementary patch includes VACUUM logic that assumes (but doesn't check) that the table has heap fill factor set to 90 -- see my changes to choose_vacuum_strategy(). This benchmark is really about stability over time more than performance (though performance is also improved significantly). I wanted to keep both the table/heap and the logically unmodified indexes (i.e. 3 out of 4 indexes on pgbench_accounts) exactly the same size *forever*. Does this make sense? Anyway, with a 15k TPS limit on a pgbench scale 3000 DB, I see that pg_stat_database shows an almost ~28% reduction in blks_read after an overnight run for the patch series (it was 508,820,699 for the patches, 705,282,975 for the master branch). I think that the VACUUM component is responsible for some of that reduction. There were 11 VACUUMs for the patch, 7 of which did not call lazy_vacuum_heap() (these 7 VACUUM operations all only dead a btbulkdelete() call for the one problematic index on the table, named "abalance_ruin", which my supplementary patch has hard-coded knowledge of). -- Peter Geoghegan
Вложения
On Mon, Dec 28, 2020 at 4:42 PM Peter Geoghegan <pg@bowt.ie> wrote: > > On Sun, Dec 27, 2020 at 10:55 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > As you said, the next question must be: How do we teach lazy vacuum to > > > not do what gets requested by amvacuumcleanup() when it cannot respect > > > the wishes of one individual indexes, for example when the > > > accumulation of LP_DEAD items in the heap becomes a big problem in > > > itself? That really could be the thing that forces full heap > > > vacuuming, even with several indexes. > > > > You mean requested by amvacuumstreategy(), not by amvacuumcleanup()? I > > think amvacuumstrategy() affects only ambulkdelete(). But when all > > ambulkdelete() were skipped by the requests by index AMs we might want > > to skip amvacuumcleanup() as well. > > No, I was asking about how we should decide to do a real VACUUM even > (a real ambulkdelete() call) when no index asks for it because > bottom-up deletion works very well in every index. Clearly we will > need to eventually remove remaining LP_DEAD items from the heap at > some point if nothing else happens -- eventually LP_DEAD items in the > heap alone will force a traditional heap vacuum (which will still have > to go through indexes that have not grown, just to be safe/avoid > recycling a TID that's still in the index). > > Postgres heap fillfactor is 100 by default, though I believe it's 90 > in another well known DB system. If you set Postgres heap fill factor > to 90 you can fit a little over 200 LP_DEAD items in the "extra space" > left behind in each heap page after initial bulk loading/INSERTs take > place that respect our lower fill factor setting. This is about 4x the > number of initial heap tuples in the pgbench_accounts table -- it's > quite a lot! > > If we pessimistically assume that all updates are non-HOT updates, > we'll still usually have enough space for each logical row to get > updated several times before the heap page "overflows". Even when > there is significant skew in the UPDATEs, the skew is not noticeable > at the level of individual heap pages. We have a surprisingly large > general capacity to temporarily "absorb" extra garbage LP_DEAD items > in heap pages this way. Nobody really cared about this extra capacity > very much before now, because it did not help with the big problem of > index bloat that you naturally see with this workload. But that big > problem may go away soon, and so this extra capacity may become > important at the same time. > > I think that it could make sense for lazy_scan_heap() to maintain > statistics about the number of LP_DEAD items remaining in each heap > page (just local stack variables). From there, it can pass the > statistics to the choose_vacuum_strategy() function from your patch. > Perhaps choose_vacuum_strategy() will notice that the heap page with > the most LP_DEAD items encountered within lazy_scan_heap() (among > those encountered so far in the event of multiple index passes) has > too many LP_DEAD items -- this indicates that there is a danger that > some heap pages will start to "overflow" soon, which is now a problem > that lazy_scan_heap() must think about. Maybe if the "extra space" > left by applying heap fill factor (with settings below 100) is > insufficient to fit perhaps 2/3 of the LP_DEAD items needed on the > heap page that has the most LP_DEAD items (among all heap pages), we > stop caring about what amvacuumstrategy()/the indexes say. So we do > the right thing for the heap pages, while still mostly avoiding index > vacuuming and the final heap pass. Agreed. I like the idea that we calculate how many LP_DEAD items we can absorb based on the extra space left by applying the fill factor. Since there is a limit on the maximum number of line pointers in a heap page we might need to consider that limit when calculation. From another point of view, given the maximum number of heap tuple in one 8kb heap page (MaxHeapTuplesPerPage) is 291, I think how bad to store LP_DEAD items in a heap page vary depending on the tuple size. For example, suppose the tuple size is 200 we can store 40 tuples into one heap page if there is no LP_DEAD item at all. Even if there are 150 LP_DEAD items on the page, we still are able to store 37 tuples because we still can have 141 line pointers at most, which is enough number to store the maximum number of heap tuples when there are no LP_DEAD items, and we have (8192 - (4 * 150)) bytes space to store tuples (with line pointers). That is, we can think that having 150 LP_DEAD items end up causing an overflow of 3 tuples. On the other hand, suppose the tuple size is 40 we can store 204 tuples into one heap page if there is no LP_DEAD item at all. If there are 150 LP_DEAD items on the page, we are able to store 141 tuples. That is, having 150 LP_DEAD items end up causing an overflow of 63 tuples. I think the impact on the table bloat by absorbing LP_DEAD items is larger in the latter case. The larger the tuple size, the more LP_DEAD items can be absorbed in a heap page with less bad effect. Considering 32 bytes tuple, the minimum heap tuples size including the tuple header, absorbing approximately up to 70 LP_DEAD items would not affect much in terms of bloat. In other words, if a heap page has more than 70 LP_DEAD items, absorbing LP_DEAD items may become a problem of the table bloat. This threshold of 70 LP_DEAD items is a conservative value and probably would be a lower bound. If the tuple size is larger, we may be able to absorb more LP_DEAD items. FYI I've attached a graph showing how the number of LP_DEAD items on one heap page affects the maximum number of heap tuples on the same heap page. The X-axis is the number of LP_DEAD items in one heap page and the Y-axis is the number of heap tuples that can be stored on the page. The lines in the graph are heap tuple size respectively. For example, in pgbench workload, since the tuple size is about 120 bytes the page bloat accelerates if we leave more than about 230 LP_DEAD items in a heap page. > > I experimented with this today, and I think that it is a good way to > do it. I like the idea of choose_vacuum_strategy() understanding that > heap pages that are subject to many non-HOT updates have a "natural > extra capacity for LP_DEAD items" that it must care about directly (at > least with non-default heap fill factor settings). My early testing > shows that it will often take a surprisingly long time for the most > heavily updated heap page to have more than about 100 LP_DEAD items. Agreed. > > > > I will need to experiment in order to improve my understanding of how > > > to make this cooperate with bottom-up index deletion. But that's > > > mostly just a question for my patch (and a relatively easy one). > > > > Yeah, I think we might need something like statistics about garbage > > per index so that individual index can make a different decision based > > on their status. For example, a btree index might want to skip > > ambulkdelete() if it has a few dead index tuples in its leaf pages. It > > could be on stats collector or on btree's meta page. > > Right. I think that even a very conservative approach could work well. > For example, maybe we teach nbtree's amvacuumstrategy() routine to ask > to do a real ambulkdelete(), except in the extreme case where the > index is *exactly* the same size as it was after the last VACUUM. > This will happen regularly with bottom-up index deletion. Maybe that > approach is a bit too conservative, though. Agreed. Regards, -- Masahiko Sawada EnterpriseDB: https://www.enterprisedb.com/
Вложения
{kind=link}
On Tue, Dec 29, 2020 at 7:06 AM Peter Geoghegan <pg@bowt.ie> wrote:
>
> On Sun, Dec 27, 2020 at 11:41 PM Peter Geoghegan <pg@bowt.ie> wrote:
> > I experimented with this today, and I think that it is a good way to
> > do it. I like the idea of choose_vacuum_strategy() understanding that
> > heap pages that are subject to many non-HOT updates have a "natural
> > extra capacity for LP_DEAD items" that it must care about directly (at
> > least with non-default heap fill factor settings). My early testing
> > shows that it will often take a surprisingly long time for the most
> > heavily updated heap page to have more than about 100 LP_DEAD items.
>
> Attached is a rough patch showing what I did here. It was applied on
> top of my bottom-up index deletion patch series and your
> poc_vacuumstrategy.patch patch. This patch was written as a quick and
> dirty way of simulating what I thought would work best for bottom-up
> index deletion for one specific benchmark/test, which was
> non-hot-update heavy. This consists of a variant pgbench with several
> indexes on pgbench_accounts (almost the same as most other bottom-up
> deletion benchmarks I've been running). Only one index is "logically
> modified" by the updates, but of course we still physically modify all
> indexes on every update. I set fill factor to 90 for this benchmark,
> which is an important factor for how your VACUUM patch works during
> the benchmark.
>
> This rough supplementary patch includes VACUUM logic that assumes (but
> doesn't check) that the table has heap fill factor set to 90 -- see my
> changes to choose_vacuum_strategy(). This benchmark is really about
> stability over time more than performance (though performance is also
> improved significantly). I wanted to keep both the table/heap and the
> logically unmodified indexes (i.e. 3 out of 4 indexes on
> pgbench_accounts) exactly the same size *forever*.
>
> Does this make sense?
Thank you for sharing the patch. That makes sense.
+ if (!vacuum_heap)
+ {
+ if (maxdeadpage > 130 ||
+ /* Also check if maintenance_work_mem space is running out */
+ vacrelstats->dead_tuples->num_tuples >
+ vacrelstats->dead_tuples->max_tuples / 2)
+ vacuum_heap = true;
+ }
The second test checking if maintenane_work_mem space is running out
also makes sense to me. Perhaps another idea would be to compare the
number of collected garbage tuple to the total number of heap tuples
so that we do lazy_vacuum_heap() only when we’re likely to reclaim a
certain amount of garbage in the table.
>
> Anyway, with a 15k TPS limit on a pgbench scale 3000 DB, I see that
> pg_stat_database shows an almost ~28% reduction in blks_read after an
> overnight run for the patch series (it was 508,820,699 for the
> patches, 705,282,975 for the master branch). I think that the VACUUM
> component is responsible for some of that reduction. There were 11
> VACUUMs for the patch, 7 of which did not call lazy_vacuum_heap()
> (these 7 VACUUM operations all only dead a btbulkdelete() call for the
> one problematic index on the table, named "abalance_ruin", which my
> supplementary patch has hard-coded knowledge of).
That's a very good result in terms of skipping lazy_vacuum_heap(). How
much the table and indexes bloated? Also, I'm curious about that which
tests in choose_vacuum_strategy() turned vacuum_heap on: 130 test or
test if maintenance_work_mem space is running out? And what was the
impact on clearing all-visible bits?
Regards,
--
Masahiko Sawada
EnterpriseDB: https://www.enterprisedb.com/
On Mon, Dec 28, 2020 at 10:26 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > The second test checking if maintenane_work_mem space is running out > also makes sense to me. Perhaps another idea would be to compare the > number of collected garbage tuple to the total number of heap tuples > so that we do lazy_vacuum_heap() only when we’re likely to reclaim a > certain amount of garbage in the table. Right. Or to consider if this is an anti-wraparound VACUUM might be nice -- maybe we should skip index vacuuming + lazy_vacuum_heap() if and only if we're under pressure to advance datfrozenxid for the whole DB, and really need to hurry up. (I think that we could both probably think of way too many ideas like this one.) > That's a very good result in terms of skipping lazy_vacuum_heap(). How > much the table and indexes bloated? Also, I'm curious about that which > tests in choose_vacuum_strategy() turned vacuum_heap on: 130 test or > test if maintenance_work_mem space is running out? And what was the > impact on clearing all-visible bits? The pgbench_accounts heap table and 3 out of 4 of its indexes (i.e. all indexes except "abalance_ruin") had zero growth. They did not even become larger by 1 block. As I often say when talking about work in this area, this is not a quantitative difference -- it's a qualitative difference. (If they grew even a tiny amount, say by only 1 block, further growth is likely to follow.) The "abalance_ruin" index was smaller with the patch. Its size started off at 253,779 blocks with both the patch and master branch (which is very small, because of B-Tree deduplication). By the end of 2 pairs of runs for the patch (2 3 hour runs) the size grew to 502,016 blocks. But with the master branch it grew to 540,090 blocks. (For reference, the primary key on pgbench_accounts started out at 822,573 blocks.) My guess is that this would compare favorably with "magic VACUUM" [1] (I refer to a thought experiment that is useful for understanding the principles behind bottom-up index deletion). The fact that "abalance_ruin" becomes bloated probably doesn't have that much to do with MVCC versioning. In other words, I suspect that the index wouldn't be that smaller in a traditional two-phase locking database system with the same workload. Words like "bloat" and "fragmentation" have always been overloaded/ambiguous in highly confusing ways, which is why I find it useful to compare a real world workload/benchmark to some kind of theoretical ideal behavior. This test wasn't particularly sympathetic to the patch because most of the indexes (all but the PK) were useless -- they did not get used by query plans. So the final size of "abalance_ruin" (or any other index) isn't even the truly important thing IMV (the benchmark doesn't advertise the truly important thing for me). The truly important thing is that the worst case number of versions *per logical row* is tightly controlled. It doesn't necessarily matter all that much if 30% of an index's tuples are garbage, as long as the garbage tuples are evenly spread across all logical rows in the table (in practice it's pretty unlikely that that would actually happen, but it's possible in theory, and if it did happen it really wouldn't be so bad). [1] https://postgr.es/m/CAH2-Wz=rPkB5vXS7AZ+v8t3VE75v_dKGro+w4nWd64E9yiCLEQ@mail.gmail.com -- Peter Geoghegan
On Mon, Dec 28, 2020 at 11:20 PM Peter Geoghegan <pg@bowt.ie> wrote: > > That's a very good result in terms of skipping lazy_vacuum_heap(). How > > much the table and indexes bloated? Also, I'm curious about that which > > tests in choose_vacuum_strategy() turned vacuum_heap on: 130 test or > > test if maintenance_work_mem space is running out? And what was the > > impact on clearing all-visible bits? > > The pgbench_accounts heap table and 3 out of 4 of its indexes (i.e. > all indexes except "abalance_ruin") had zero growth. They did not even > become larger by 1 block. As I often say when talking about work in > this area, this is not a quantitative difference -- it's a qualitative > difference. (If they grew even a tiny amount, say by only 1 block, > further growth is likely to follow.) I forgot to say: I don't know what the exact impact was on the VM bit setting, but I doubt that it was noticeably worse for the patch. It cannot have been better, though. It's inherently almost impossible to keep most of the VM bits set for long with this workload. Perhaps VM bit setting would be improved with workloads that have some HOT updates, but as I mentioned this workload only had non-HOT updates (except in a tiny number of cases where abalance did not change, just by random luck). I also forget to say that the maintenance_work_mem test wasn't that relevant, though I believe it triggered once. maintenance_work_mem was set very high (5GB). Here is a link with more details information, in case that is interesting: https://drive.google.com/file/d/1TqpAQnqb4SMMuhehD8ELpf6Cv9A8ux2E/view?usp=sharing -- Peter Geoghegan
On Tue, Dec 29, 2020 at 3:25 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> On Tue, Dec 29, 2020 at 7:06 AM Peter Geoghegan <pg@bowt.ie> wrote:
> >
> > On Sun, Dec 27, 2020 at 11:41 PM Peter Geoghegan <pg@bowt.ie> wrote:
> > > I experimented with this today, and I think that it is a good way to
> > > do it. I like the idea of choose_vacuum_strategy() understanding that
> > > heap pages that are subject to many non-HOT updates have a "natural
> > > extra capacity for LP_DEAD items" that it must care about directly (at
> > > least with non-default heap fill factor settings). My early testing
> > > shows that it will often take a surprisingly long time for the most
> > > heavily updated heap page to have more than about 100 LP_DEAD items.
> >
> > Attached is a rough patch showing what I did here. It was applied on
> > top of my bottom-up index deletion patch series and your
> > poc_vacuumstrategy.patch patch. This patch was written as a quick and
> > dirty way of simulating what I thought would work best for bottom-up
> > index deletion for one specific benchmark/test, which was
> > non-hot-update heavy. This consists of a variant pgbench with several
> > indexes on pgbench_accounts (almost the same as most other bottom-up
> > deletion benchmarks I've been running). Only one index is "logically
> > modified" by the updates, but of course we still physically modify all
> > indexes on every update. I set fill factor to 90 for this benchmark,
> > which is an important factor for how your VACUUM patch works during
> > the benchmark.
> >
> > This rough supplementary patch includes VACUUM logic that assumes (but
> > doesn't check) that the table has heap fill factor set to 90 -- see my
> > changes to choose_vacuum_strategy(). This benchmark is really about
> > stability over time more than performance (though performance is also
> > improved significantly). I wanted to keep both the table/heap and the
> > logically unmodified indexes (i.e. 3 out of 4 indexes on
> > pgbench_accounts) exactly the same size *forever*.
> >
> > Does this make sense?
>
> Thank you for sharing the patch. That makes sense.
>
> + if (!vacuum_heap)
> + {
> + if (maxdeadpage > 130 ||
> + /* Also check if maintenance_work_mem space is running out */
> + vacrelstats->dead_tuples->num_tuples >
> + vacrelstats->dead_tuples->max_tuples / 2)
> + vacuum_heap = true;
> + }
>
> The second test checking if maintenane_work_mem space is running out
> also makes sense to me. Perhaps another idea would be to compare the
> number of collected garbage tuple to the total number of heap tuples
> so that we do lazy_vacuum_heap() only when we’re likely to reclaim a
> certain amount of garbage in the table.
>
> >
> > Anyway, with a 15k TPS limit on a pgbench scale 3000 DB, I see that
> > pg_stat_database shows an almost ~28% reduction in blks_read after an
> > overnight run for the patch series (it was 508,820,699 for the
> > patches, 705,282,975 for the master branch). I think that the VACUUM
> > component is responsible for some of that reduction. There were 11
> > VACUUMs for the patch, 7 of which did not call lazy_vacuum_heap()
> > (these 7 VACUUM operations all only dead a btbulkdelete() call for the
> > one problematic index on the table, named "abalance_ruin", which my
> > supplementary patch has hard-coded knowledge of).
>
> That's a very good result in terms of skipping lazy_vacuum_heap(). How
> much the table and indexes bloated? Also, I'm curious about that which
> tests in choose_vacuum_strategy() turned vacuum_heap on: 130 test or
> test if maintenance_work_mem space is running out? And what was the
> impact on clearing all-visible bits?
>
I merged these patches and polished it.
In the 0002 patch, we calculate how many LP_DEAD items can be
accumulated in the space on a single heap page left by fillfactor. I
increased MaxHeapTuplesPerPage so that we can accumulate LP_DEAD items
on a heap page. Because otherwise accumulating LP_DEAD items
unnecessarily constrains the number of heap tuples in a single page,
especially when small tuples, as I mentioned before. Previously, we
constrained the number of line pointers to avoid excessive
line-pointer bloat and not require an increase in the size of the work
array. However, once amvacuumstrategy stuff entered the picture,
accumulating line pointers has value. Also, we might want to store the
returned value of amvacuumstrategy so that index AM can refer to it on
index-deletion.
The 0003 patch has btree indexes skip bulk-deletion if the index
doesn't grow since last bulk-deletion. I stored the number of blocks
in the meta page but didn't implement meta page upgrading.
I've attached the draft version patches. Note that the documentation
update is still lacking.
Regards,
--
Masahiko Sawada
EnterpriseDB: https://www.enterprisedb.com/
Вложения
On Tue, Jan 5, 2021 at 10:35 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> On Tue, Dec 29, 2020 at 3:25 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> >
> > On Tue, Dec 29, 2020 at 7:06 AM Peter Geoghegan <pg@bowt.ie> wrote:
> > >
> > > On Sun, Dec 27, 2020 at 11:41 PM Peter Geoghegan <pg@bowt.ie> wrote:
> > > > I experimented with this today, and I think that it is a good way to
> > > > do it. I like the idea of choose_vacuum_strategy() understanding that
> > > > heap pages that are subject to many non-HOT updates have a "natural
> > > > extra capacity for LP_DEAD items" that it must care about directly (at
> > > > least with non-default heap fill factor settings). My early testing
> > > > shows that it will often take a surprisingly long time for the most
> > > > heavily updated heap page to have more than about 100 LP_DEAD items.
> > >
> > > Attached is a rough patch showing what I did here. It was applied on
> > > top of my bottom-up index deletion patch series and your
> > > poc_vacuumstrategy.patch patch. This patch was written as a quick and
> > > dirty way of simulating what I thought would work best for bottom-up
> > > index deletion for one specific benchmark/test, which was
> > > non-hot-update heavy. This consists of a variant pgbench with several
> > > indexes on pgbench_accounts (almost the same as most other bottom-up
> > > deletion benchmarks I've been running). Only one index is "logically
> > > modified" by the updates, but of course we still physically modify all
> > > indexes on every update. I set fill factor to 90 for this benchmark,
> > > which is an important factor for how your VACUUM patch works during
> > > the benchmark.
> > >
> > > This rough supplementary patch includes VACUUM logic that assumes (but
> > > doesn't check) that the table has heap fill factor set to 90 -- see my
> > > changes to choose_vacuum_strategy(). This benchmark is really about
> > > stability over time more than performance (though performance is also
> > > improved significantly). I wanted to keep both the table/heap and the
> > > logically unmodified indexes (i.e. 3 out of 4 indexes on
> > > pgbench_accounts) exactly the same size *forever*.
> > >
> > > Does this make sense?
> >
> > Thank you for sharing the patch. That makes sense.
> >
> > + if (!vacuum_heap)
> > + {
> > + if (maxdeadpage > 130 ||
> > + /* Also check if maintenance_work_mem space is running out */
> > + vacrelstats->dead_tuples->num_tuples >
> > + vacrelstats->dead_tuples->max_tuples / 2)
> > + vacuum_heap = true;
> > + }
> >
> > The second test checking if maintenane_work_mem space is running out
> > also makes sense to me. Perhaps another idea would be to compare the
> > number of collected garbage tuple to the total number of heap tuples
> > so that we do lazy_vacuum_heap() only when we’re likely to reclaim a
> > certain amount of garbage in the table.
> >
> > >
> > > Anyway, with a 15k TPS limit on a pgbench scale 3000 DB, I see that
> > > pg_stat_database shows an almost ~28% reduction in blks_read after an
> > > overnight run for the patch series (it was 508,820,699 for the
> > > patches, 705,282,975 for the master branch). I think that the VACUUM
> > > component is responsible for some of that reduction. There were 11
> > > VACUUMs for the patch, 7 of which did not call lazy_vacuum_heap()
> > > (these 7 VACUUM operations all only dead a btbulkdelete() call for the
> > > one problematic index on the table, named "abalance_ruin", which my
> > > supplementary patch has hard-coded knowledge of).
> >
> > That's a very good result in terms of skipping lazy_vacuum_heap(). How
> > much the table and indexes bloated? Also, I'm curious about that which
> > tests in choose_vacuum_strategy() turned vacuum_heap on: 130 test or
> > test if maintenance_work_mem space is running out? And what was the
> > impact on clearing all-visible bits?
> >
>
> I merged these patches and polished it.
>
> In the 0002 patch, we calculate how many LP_DEAD items can be
> accumulated in the space on a single heap page left by fillfactor. I
> increased MaxHeapTuplesPerPage so that we can accumulate LP_DEAD items
> on a heap page. Because otherwise accumulating LP_DEAD items
> unnecessarily constrains the number of heap tuples in a single page,
> especially when small tuples, as I mentioned before. Previously, we
> constrained the number of line pointers to avoid excessive
> line-pointer bloat and not require an increase in the size of the work
> array. However, once amvacuumstrategy stuff entered the picture,
> accumulating line pointers has value. Also, we might want to store the
> returned value of amvacuumstrategy so that index AM can refer to it on
> index-deletion.
>
> The 0003 patch has btree indexes skip bulk-deletion if the index
> doesn't grow since last bulk-deletion. I stored the number of blocks
> in the meta page but didn't implement meta page upgrading.
>
After more thought, I think that ambulkdelete needs to be able to
refer the answer to amvacuumstrategy. That way, the index can skip
bulk-deletion when lazy vacuum doesn't vacuum heap and it also doesn’t
want to do that.
I’ve attached the updated version patch that includes the following changes:
* Store the answers to amvacuumstrategy into either the local memory
or DSM (in parallel vacuum case) so that ambulkdelete can refer the
answer to amvacuumstrategy.
* Fix regression failures.
* Update the documentation and commments.
Note that 0003 patch is still PoC quality, lacking the btree meta page
version upgrade.
Regards,
--
Masahiko Sawada
EnterpriseDB: https://www.enterprisedb.com/
Вложения
On Mon, Jan 18, 2021 at 2:18 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> On Tue, Jan 5, 2021 at 10:35 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> >
> > On Tue, Dec 29, 2020 at 3:25 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> > >
> > > On Tue, Dec 29, 2020 at 7:06 AM Peter Geoghegan <pg@bowt.ie> wrote:
> > > >
> > > > On Sun, Dec 27, 2020 at 11:41 PM Peter Geoghegan <pg@bowt.ie> wrote:
> > > > > I experimented with this today, and I think that it is a good way to
> > > > > do it. I like the idea of choose_vacuum_strategy() understanding that
> > > > > heap pages that are subject to many non-HOT updates have a "natural
> > > > > extra capacity for LP_DEAD items" that it must care about directly (at
> > > > > least with non-default heap fill factor settings). My early testing
> > > > > shows that it will often take a surprisingly long time for the most
> > > > > heavily updated heap page to have more than about 100 LP_DEAD items.
> > > >
> > > > Attached is a rough patch showing what I did here. It was applied on
> > > > top of my bottom-up index deletion patch series and your
> > > > poc_vacuumstrategy.patch patch. This patch was written as a quick and
> > > > dirty way of simulating what I thought would work best for bottom-up
> > > > index deletion for one specific benchmark/test, which was
> > > > non-hot-update heavy. This consists of a variant pgbench with several
> > > > indexes on pgbench_accounts (almost the same as most other bottom-up
> > > > deletion benchmarks I've been running). Only one index is "logically
> > > > modified" by the updates, but of course we still physically modify all
> > > > indexes on every update. I set fill factor to 90 for this benchmark,
> > > > which is an important factor for how your VACUUM patch works during
> > > > the benchmark.
> > > >
> > > > This rough supplementary patch includes VACUUM logic that assumes (but
> > > > doesn't check) that the table has heap fill factor set to 90 -- see my
> > > > changes to choose_vacuum_strategy(). This benchmark is really about
> > > > stability over time more than performance (though performance is also
> > > > improved significantly). I wanted to keep both the table/heap and the
> > > > logically unmodified indexes (i.e. 3 out of 4 indexes on
> > > > pgbench_accounts) exactly the same size *forever*.
> > > >
> > > > Does this make sense?
> > >
> > > Thank you for sharing the patch. That makes sense.
> > >
> > > + if (!vacuum_heap)
> > > + {
> > > + if (maxdeadpage > 130 ||
> > > + /* Also check if maintenance_work_mem space is running out */
> > > + vacrelstats->dead_tuples->num_tuples >
> > > + vacrelstats->dead_tuples->max_tuples / 2)
> > > + vacuum_heap = true;
> > > + }
> > >
> > > The second test checking if maintenane_work_mem space is running out
> > > also makes sense to me. Perhaps another idea would be to compare the
> > > number of collected garbage tuple to the total number of heap tuples
> > > so that we do lazy_vacuum_heap() only when we’re likely to reclaim a
> > > certain amount of garbage in the table.
> > >
> > > >
> > > > Anyway, with a 15k TPS limit on a pgbench scale 3000 DB, I see that
> > > > pg_stat_database shows an almost ~28% reduction in blks_read after an
> > > > overnight run for the patch series (it was 508,820,699 for the
> > > > patches, 705,282,975 for the master branch). I think that the VACUUM
> > > > component is responsible for some of that reduction. There were 11
> > > > VACUUMs for the patch, 7 of which did not call lazy_vacuum_heap()
> > > > (these 7 VACUUM operations all only dead a btbulkdelete() call for the
> > > > one problematic index on the table, named "abalance_ruin", which my
> > > > supplementary patch has hard-coded knowledge of).
> > >
> > > That's a very good result in terms of skipping lazy_vacuum_heap(). How
> > > much the table and indexes bloated? Also, I'm curious about that which
> > > tests in choose_vacuum_strategy() turned vacuum_heap on: 130 test or
> > > test if maintenance_work_mem space is running out? And what was the
> > > impact on clearing all-visible bits?
> > >
> >
> > I merged these patches and polished it.
> >
> > In the 0002 patch, we calculate how many LP_DEAD items can be
> > accumulated in the space on a single heap page left by fillfactor. I
> > increased MaxHeapTuplesPerPage so that we can accumulate LP_DEAD items
> > on a heap page. Because otherwise accumulating LP_DEAD items
> > unnecessarily constrains the number of heap tuples in a single page,
> > especially when small tuples, as I mentioned before. Previously, we
> > constrained the number of line pointers to avoid excessive
> > line-pointer bloat and not require an increase in the size of the work
> > array. However, once amvacuumstrategy stuff entered the picture,
> > accumulating line pointers has value. Also, we might want to store the
> > returned value of amvacuumstrategy so that index AM can refer to it on
> > index-deletion.
> >
> > The 0003 patch has btree indexes skip bulk-deletion if the index
> > doesn't grow since last bulk-deletion. I stored the number of blocks
> > in the meta page but didn't implement meta page upgrading.
> >
>
> After more thought, I think that ambulkdelete needs to be able to
> refer the answer to amvacuumstrategy. That way, the index can skip
> bulk-deletion when lazy vacuum doesn't vacuum heap and it also doesn’t
> want to do that.
>
> I’ve attached the updated version patch that includes the following changes:
>
> * Store the answers to amvacuumstrategy into either the local memory
> or DSM (in parallel vacuum case) so that ambulkdelete can refer the
> answer to amvacuumstrategy.
> * Fix regression failures.
> * Update the documentation and commments.
>
> Note that 0003 patch is still PoC quality, lacking the btree meta page
> version upgrade.
Sorry, I missed 0002 patch. I've attached the patch set again.
Regards,
--
Masahiko Sawada
EDB: https://www.enterprisedb.com/
Вложения
Hi, Masahiko-san:
For v2-0001-Introduce-IndexAM-API-for-choosing-index-vacuum-s.patch :
For blvacuumstrategy():
+ if (params->index_cleanup == VACOPT_TERNARY_DISABLED)
+ return INDEX_VACUUM_STRATEGY_NONE;
+ else
+ return INDEX_VACUUM_STRATEGY_BULKDELETE;
+ return INDEX_VACUUM_STRATEGY_NONE;
+ else
+ return INDEX_VACUUM_STRATEGY_BULKDELETE;
The 'else' can be omitted.
Similar comment for ginvacuumstrategy().
For v2-0002-Choose-index-vacuum-strategy-based-on-amvacuumstr.patch :
If index_cleanup option is specified neither VACUUM command nor
storage option
storage option
I think this is what you meant (by not using passive voice):
If index_cleanup option specifies neither VACUUM command nor
storage option,
storage option,
- * integer, but you can't fit that many items on a page. 11 ought to be more
+ * integer, but you can't fit that many items on a page. 13 ought to be more
+ * integer, but you can't fit that many items on a page. 13 ought to be more
It would be nice to add a note why the number of bits is increased.
For choose_vacuum_strategy():
+ IndexVacuumStrategy ivstrat;
The variable is only used inside the loop. You can use vacrelstats->ivstrategies[i] directly and omit the variable.
+ int ndeaditems_limit = (int) ((freespace / sizeof(ItemIdData)) * 0.7);
How was the factor of 0.7 determined ? Comment below only mentioned 'safety factor' but not how it was chosen.
I also wonder if this factor should be exposed as GUC.
+ if (nworkers > 0)
+ nworkers--;
+ nworkers--;
Should log / assert be added when nworkers is <= 0 ?
+ * XXX: allowing to fill the heap page with only line pointer seems a overkill.
'a overkill' -> 'an overkill'
Cheers
On Sun, Jan 17, 2021 at 10:21 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
On Mon, Jan 18, 2021 at 2:18 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> On Tue, Jan 5, 2021 at 10:35 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> >
> > On Tue, Dec 29, 2020 at 3:25 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> > >
> > > On Tue, Dec 29, 2020 at 7:06 AM Peter Geoghegan <pg@bowt.ie> wrote:
> > > >
> > > > On Sun, Dec 27, 2020 at 11:41 PM Peter Geoghegan <pg@bowt.ie> wrote:
> > > > > I experimented with this today, and I think that it is a good way to
> > > > > do it. I like the idea of choose_vacuum_strategy() understanding that
> > > > > heap pages that are subject to many non-HOT updates have a "natural
> > > > > extra capacity for LP_DEAD items" that it must care about directly (at
> > > > > least with non-default heap fill factor settings). My early testing
> > > > > shows that it will often take a surprisingly long time for the most
> > > > > heavily updated heap page to have more than about 100 LP_DEAD items.
> > > >
> > > > Attached is a rough patch showing what I did here. It was applied on
> > > > top of my bottom-up index deletion patch series and your
> > > > poc_vacuumstrategy.patch patch. This patch was written as a quick and
> > > > dirty way of simulating what I thought would work best for bottom-up
> > > > index deletion for one specific benchmark/test, which was
> > > > non-hot-update heavy. This consists of a variant pgbench with several
> > > > indexes on pgbench_accounts (almost the same as most other bottom-up
> > > > deletion benchmarks I've been running). Only one index is "logically
> > > > modified" by the updates, but of course we still physically modify all
> > > > indexes on every update. I set fill factor to 90 for this benchmark,
> > > > which is an important factor for how your VACUUM patch works during
> > > > the benchmark.
> > > >
> > > > This rough supplementary patch includes VACUUM logic that assumes (but
> > > > doesn't check) that the table has heap fill factor set to 90 -- see my
> > > > changes to choose_vacuum_strategy(). This benchmark is really about
> > > > stability over time more than performance (though performance is also
> > > > improved significantly). I wanted to keep both the table/heap and the
> > > > logically unmodified indexes (i.e. 3 out of 4 indexes on
> > > > pgbench_accounts) exactly the same size *forever*.
> > > >
> > > > Does this make sense?
> > >
> > > Thank you for sharing the patch. That makes sense.
> > >
> > > + if (!vacuum_heap)
> > > + {
> > > + if (maxdeadpage > 130 ||
> > > + /* Also check if maintenance_work_mem space is running out */
> > > + vacrelstats->dead_tuples->num_tuples >
> > > + vacrelstats->dead_tuples->max_tuples / 2)
> > > + vacuum_heap = true;
> > > + }
> > >
> > > The second test checking if maintenane_work_mem space is running out
> > > also makes sense to me. Perhaps another idea would be to compare the
> > > number of collected garbage tuple to the total number of heap tuples
> > > so that we do lazy_vacuum_heap() only when we’re likely to reclaim a
> > > certain amount of garbage in the table.
> > >
> > > >
> > > > Anyway, with a 15k TPS limit on a pgbench scale 3000 DB, I see that
> > > > pg_stat_database shows an almost ~28% reduction in blks_read after an
> > > > overnight run for the patch series (it was 508,820,699 for the
> > > > patches, 705,282,975 for the master branch). I think that the VACUUM
> > > > component is responsible for some of that reduction. There were 11
> > > > VACUUMs for the patch, 7 of which did not call lazy_vacuum_heap()
> > > > (these 7 VACUUM operations all only dead a btbulkdelete() call for the
> > > > one problematic index on the table, named "abalance_ruin", which my
> > > > supplementary patch has hard-coded knowledge of).
> > >
> > > That's a very good result in terms of skipping lazy_vacuum_heap(). How
> > > much the table and indexes bloated? Also, I'm curious about that which
> > > tests in choose_vacuum_strategy() turned vacuum_heap on: 130 test or
> > > test if maintenance_work_mem space is running out? And what was the
> > > impact on clearing all-visible bits?
> > >
> >
> > I merged these patches and polished it.
> >
> > In the 0002 patch, we calculate how many LP_DEAD items can be
> > accumulated in the space on a single heap page left by fillfactor. I
> > increased MaxHeapTuplesPerPage so that we can accumulate LP_DEAD items
> > on a heap page. Because otherwise accumulating LP_DEAD items
> > unnecessarily constrains the number of heap tuples in a single page,
> > especially when small tuples, as I mentioned before. Previously, we
> > constrained the number of line pointers to avoid excessive
> > line-pointer bloat and not require an increase in the size of the work
> > array. However, once amvacuumstrategy stuff entered the picture,
> > accumulating line pointers has value. Also, we might want to store the
> > returned value of amvacuumstrategy so that index AM can refer to it on
> > index-deletion.
> >
> > The 0003 patch has btree indexes skip bulk-deletion if the index
> > doesn't grow since last bulk-deletion. I stored the number of blocks
> > in the meta page but didn't implement meta page upgrading.
> >
>
> After more thought, I think that ambulkdelete needs to be able to
> refer the answer to amvacuumstrategy. That way, the index can skip
> bulk-deletion when lazy vacuum doesn't vacuum heap and it also doesn’t
> want to do that.
>
> I’ve attached the updated version patch that includes the following changes:
>
> * Store the answers to amvacuumstrategy into either the local memory
> or DSM (in parallel vacuum case) so that ambulkdelete can refer the
> answer to amvacuumstrategy.
> * Fix regression failures.
> * Update the documentation and commments.
>
> Note that 0003 patch is still PoC quality, lacking the btree meta page
> version upgrade.
Sorry, I missed 0002 patch. I've attached the patch set again.
Regards,
--
Masahiko Sawada
EDB: https://www.enterprisedb.com/
On Sun, Jan 17, 2021 at 9:18 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> After more thought, I think that ambulkdelete needs to be able to
> refer the answer to amvacuumstrategy. That way, the index can skip
> bulk-deletion when lazy vacuum doesn't vacuum heap and it also doesn’t
> want to do that.
Makes sense.
BTW, your patch has bitrot already. Peter E's recent pageinspect
commit happens to conflict with this patch. It might make sense to
produce a new version that just fixes the bitrot, so that other people
don't have to deal with it each time.
> I’ve attached the updated version patch that includes the following changes:
Looks good. I'll give this version a review now. I will do a lot more
soon. I need to come up with a good benchmark for this, that I can
return to again and again during review as needed.
Some feedback on the first patch:
* Just so you know: I agree with you about handling
VACOPT_TERNARY_DISABLED in the index AM's amvacuumstrategy routine. I
think that it's better to do that there, even though this choice may
have some downsides.
* Can you add some "stub" sgml doc changes for this? Doesn't have to
be complete in any way. Just a placeholder for later, that has the
correct general "shape" to orientate the reader of the patch. It can
just be a FIXME comment, plus basic mechanical stuff -- details of the
new amvacuumstrategy_function routine and its signature.
Some feedback on the second patch:
* Why do you move around IndexVacuumStrategy in the second patch?
Looks like a rebasing oversight.
* Actually, do we really need the first and second patches to be
separate patches? I agree that the nbtree patch should be a separate
patch, but dividing the first two sets of changes doesn't seem like it
adds much. Did I miss some something?
* Is the "MAXALIGN(sizeof(ItemIdData)))" change in the definition of
MaxHeapTuplesPerPage appropriate? Here is the relevant section from
the patch:
diff --git a/src/include/access/htup_details.h
b/src/include/access/htup_details.h
index 7c62852e7f..038e7cd580 100644
--- a/src/include/access/htup_details.h
+++ b/src/include/access/htup_details.h
@@ -563,17 +563,18 @@ do { \
/*
* MaxHeapTuplesPerPage is an upper bound on the number of tuples that can
* fit on one heap page. (Note that indexes could have more, because they
- * use a smaller tuple header.) We arrive at the divisor because each tuple
- * must be maxaligned, and it must have an associated line pointer.
+ * use a smaller tuple header.) We arrive at the divisor because each line
+ * pointer must be maxaligned.
*** SNIP ***
#define MaxHeapTuplesPerPage \
- ((int) ((BLCKSZ - SizeOfPageHeaderData) / \
- (MAXALIGN(SizeofHeapTupleHeader) + sizeof(ItemIdData))))
+ ((int) ((BLCKSZ - SizeOfPageHeaderData) / (MAXALIGN(sizeof(ItemIdData)))))
It's true that ItemIdData structs (line pointers) are aligned, but
they're not MAXALIGN()'d. If they were then the on-disk size of line
pointers would generally be 8 bytes, not 4 bytes.
* Maybe it would be better if you just changed the definition such
that "MAXALIGN(SizeofHeapTupleHeader)" became "MAXIMUM_ALIGNOF", with
no other changes? (Some variant of this suggestion might be better,
not sure.)
For some reason that feels a bit safer: we still have an "imaginary
tuple header", but it's just 1 MAXALIGN() quantum now. This is still
much less than the current 3 MAXALIGN() quantums (i.e. what
MaxHeapTuplesPerPage treats as the tuple header size). Do you think
that this alternative approach will be noticeably less effective
within vacuumlazy.c?
Note that you probably understand the issue with MaxHeapTuplesPerPage
for vacuumlazy.c better than I do currently. I'm still trying to
understand your choices, and to understand what is really important
here.
* Maybe add a #define for the value 0.7? (I refer to the value used in
choose_vacuum_strategy() to calculate a "this is the number of LP_DEAD
line pointers that we consider too many" cut off point, which is to be
applied throughout lazy_scan_heap() processing.)
* I notice that your new lazy_vacuum_table_and_indexes() function is
the only place that calls lazy_vacuum_table_and_indexes(). I think
that you should merge them together -- replace the only remaining call
to lazy_vacuum_table_and_indexes() with the body of the function
itself. Having a separate lazy_vacuum_table_and_indexes() function
doesn't seem useful to me -- it doesn't actually hide complexity, and
might even be harder to maintain.
* I suggest thinking about what the last item will mean for the
reporting that currently takes place in
lazy_vacuum_table_and_indexes(), but will now go in an expanded
lazy_vacuum_table_and_indexes() -- how do we count the total number of
index scans now?
I don't actually believe that the logic needs to change, but some kind
of consolidation and streamlining seems like it might be helpful.
Maybe just a comment that says "note that all index scans might just
be no-ops because..." -- stuff like that.
* Any idea about how hard it will be to teach is_wraparound VACUUMs to
skip index cleanup automatically, based on some practical/sensible
criteria?
It would be nice to have a basic PoC for that, even if it remains a
PoC for the foreseeable future (i.e. even if it cannot be committed to
Postgres 14). This feature should definitely be something that your
patch series *enables*. I'd feel good about having covered that
question as part of this basic design work if there was a PoC. That
alone should make it 100% clear that it's easy to do (or no harder
than it should be -- it should ideally be compatible with your basic
design). The exact criteria that we use for deciding whether or not to
skip index cleanup (which probably should not just be "this VACUUM is
is_wraparound, good enough" in the final version) may need to be
debated at length on pgsql-hackers. Even still, it is "just a detail"
in the code. Whereas being *able* to do that with your design (now or
in the future) seems essential now.
> * Store the answers to amvacuumstrategy into either the local memory
> or DSM (in parallel vacuum case) so that ambulkdelete can refer the
> answer to amvacuumstrategy.
> * Fix regression failures.
> * Update the documentation and commments.
>
> Note that 0003 patch is still PoC quality, lacking the btree meta page
> version upgrade.
This patch is not the hard part, of course -- there really isn't that
much needed here compared to vacuumlazy.c. So this patch seems like
the simplest 1 out of the 3 (at least to me).
Some feedback on the third patch:
* The new btm_last_deletion_nblocks metapage field should use P_NONE
(which is 0) to indicate never having been vacuumed -- not
InvalidBlockNumber (which is 0xFFFFFFFF).
This is more idiomatic in nbtree, which is nice, but it has a very
significant practical advantage: it ensures that every heapkeyspace
nbtree index (i.e. those on recent nbtree versions) can be treated as
if it has the new btm_last_deletion_nblocks field all along, even when
it actually built on Postgres 12 or 13. This trick will let you avoid
dealing with the headache of bumping BTREE_VERSION, which is a huge
advantage.
Note that this is the same trick I used to avoid bumping BTREE_VERSION
when the btm_allequalimage field needed to be added (for the nbtree
deduplication feature added to Postgres 13).
* Forgot to do this in the third patch (think I made this same mistake
once myself):
diff --git a/contrib/pageinspect/btreefuncs.c b/contrib/pageinspect/btreefuncs.c
index 8bb180bbbe..88dfea9af3 100644
--- a/contrib/pageinspect/btreefuncs.c
+++ b/contrib/pageinspect/btreefuncs.c
@@ -653,7 +653,7 @@ bt_metap(PG_FUNCTION_ARGS)
BTMetaPageData *metad;
TupleDesc tupleDesc;
int j;
- char *values[9];
+ char *values[10];
Buffer buffer;
Page page;
HeapTuple tuple;
@@ -734,6 +734,11 @@ bt_metap(PG_FUNCTION_ARGS)
That's all I have for now...
--
Peter Geoghegan
On Tue, Jan 19, 2021 at 2:57 PM Peter Geoghegan <pg@bowt.ie> wrote: > * Maybe it would be better if you just changed the definition such > that "MAXALIGN(SizeofHeapTupleHeader)" became "MAXIMUM_ALIGNOF", with > no other changes? (Some variant of this suggestion might be better, > not sure.) > > For some reason that feels a bit safer: we still have an "imaginary > tuple header", but it's just 1 MAXALIGN() quantum now. This is still > much less than the current 3 MAXALIGN() quantums (i.e. what > MaxHeapTuplesPerPage treats as the tuple header size). Do you think > that this alternative approach will be noticeably less effective > within vacuumlazy.c? BTW, I think that increasing MaxHeapTuplesPerPage will make it necessary to consider tidbitmap.c. Comments at the top of that file say that it is assumed that MaxHeapTuplesPerPage is about 256. So there is a risk of introducing performance regressions affecting bitmap scans here. Apparently some other DB systems make the equivalent of MaxHeapTuplesPerPage dynamically configurable at the level of heap tables. It usually doesn't matter, but it can matter with on-disk bitmap indexes, where the bitmap must be encoded from raw TIDs (this must happen before the bitmap is compressed -- there must be a simple mapping from every possible TID to some bit in a bitmap first). The item offset component of each heap TID is not usually very large, so there is a trade-off between keeping the representation of bitmaps efficient and not unduly restricting the number of distinct heap tuples on each heap page. I think that there might be a similar consideration here, in tidbitmap.c (even though it's not concerned about on-disk bitmaps). -- Peter Geoghegan
On Tue, Jan 19, 2021 at 4:45 PM Peter Geoghegan <pg@bowt.ie> wrote: > BTW, I think that increasing MaxHeapTuplesPerPage will make it > necessary to consider tidbitmap.c. Comments at the top of that file > say that it is assumed that MaxHeapTuplesPerPage is about 256. So > there is a risk of introducing performance regressions affecting > bitmap scans here. More concretely, WORDS_PER_PAGE increases from 5 on the master branch to 16 with the latest version of the patch series on most platforms (while WORDS_PER_CHUNK is 4 with or without the patches). -- Peter Geoghegan
On Wed, Jan 20, 2021 at 9:45 AM Peter Geoghegan <pg@bowt.ie> wrote: > > On Tue, Jan 19, 2021 at 2:57 PM Peter Geoghegan <pg@bowt.ie> wrote: > > * Maybe it would be better if you just changed the definition such > > that "MAXALIGN(SizeofHeapTupleHeader)" became "MAXIMUM_ALIGNOF", with > > no other changes? (Some variant of this suggestion might be better, > > not sure.) > > > > For some reason that feels a bit safer: we still have an "imaginary > > tuple header", but it's just 1 MAXALIGN() quantum now. This is still > > much less than the current 3 MAXALIGN() quantums (i.e. what > > MaxHeapTuplesPerPage treats as the tuple header size). Do you think > > that this alternative approach will be noticeably less effective > > within vacuumlazy.c? > > BTW, I think that increasing MaxHeapTuplesPerPage will make it > necessary to consider tidbitmap.c. Comments at the top of that file > say that it is assumed that MaxHeapTuplesPerPage is about 256. So > there is a risk of introducing performance regressions affecting > bitmap scans here. > > Apparently some other DB systems make the equivalent of > MaxHeapTuplesPerPage dynamically configurable at the level of heap > tables. It usually doesn't matter, but it can matter with on-disk > bitmap indexes, where the bitmap must be encoded from raw TIDs (this > must happen before the bitmap is compressed -- there must be a simple > mapping from every possible TID to some bit in a bitmap first). The > item offset component of each heap TID is not usually very large, so > there is a trade-off between keeping the representation of bitmaps > efficient and not unduly restricting the number of distinct heap > tuples on each heap page. I think that there might be a similar > consideration here, in tidbitmap.c (even though it's not concerned > about on-disk bitmaps). That's a good point. With the patch, MaxHeapTuplesPerPage increased to 2042 with 8k page, and to 8186 with 32k page whereas it's currently 291 with 8k page and 1169 with 32k page. So it is likely to be a problem as you pointed out. If we change "MAXALIGN(SizeofHeapTupleHeader)" to "MAXIMUM_ALIGNOF", it's 680 with 8k patch and 2728 with 32k page, which seems much better. The purpose of increasing MaxHeapTuplesPerPage in the patch is to have a heap page accumulate more LP_DEAD line pointers. As I explained before, considering MaxHeapTuplesPerPage, we cannot calculate how many LP_DEAD line pointers can be accumulated into the space taken by fillfactor simply by ((the space taken by fillfactor) / (size of line pointer)). We need to consider both how many line pointers are available for LP_DEAD and how much space is available for LP_DEAD. For example, suppose the tuple size is 50 bytes and fillfactor is 80, each page has 1633 bytes (=(8192-24)*0.2) free space taken by fillfactor, where 408 line pointers can fit. However, if we store 250 LP_DEAD line pointers into that space, the number of tuples that can be stored on the page is only 41, although we have 6534 bytes (=(8192-24)*0.8) where 121 tuples (+line pointers) can fit because MaxHeapTuplesPerPage is 291. In this case, where the tuple size is 50 and fillfactor is 80, we can accumulate up to about 170 LP_DEAD line pointers while storing 121 tuples. Increasing MaxHeapTuplesPerPage raises this 291 limit and enables us to forget the limit when calculating the maximum number of LP_DEAD line pointers that can be accumulated on a single page. An alternative approach would be to calculate it using the average tuple's size. I think if we know the tuple size, the maximum number of LP_DEAD line pointers can be accumulated into the single page is the minimum of the following two formula: (1) MaxHeapTuplesPerPage - (((BLCKSZ - SizeOfPageHeaderData) * (fillfactor/100)) / (sizeof(ItemIdData) + tuple_size))); //how many line pointers are available for LP_DEAD? (2) ((BLCKSZ - SizeOfPageHeaderData) * ((1 - fillfactor)/100)) / sizeof(ItemIdData); //how much space is available for LP_DEAD? But I'd prefer to increase MaxHeapTuplesPerPage but not to affect the bitmap much rather than introducing a complex theory. Regards, -- Masahiko Sawada EDB: https://www.enterprisedb.com/
On Wed, Jan 20, 2021 at 7:58 AM Peter Geoghegan <pg@bowt.ie> wrote:
>
> On Sun, Jan 17, 2021 at 9:18 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> > After more thought, I think that ambulkdelete needs to be able to
> > refer the answer to amvacuumstrategy. That way, the index can skip
> > bulk-deletion when lazy vacuum doesn't vacuum heap and it also doesn’t
> > want to do that.
>
> Makes sense.
>
> BTW, your patch has bitrot already. Peter E's recent pageinspect
> commit happens to conflict with this patch. It might make sense to
> produce a new version that just fixes the bitrot, so that other people
> don't have to deal with it each time.
>
> > I’ve attached the updated version patch that includes the following changes:
>
> Looks good. I'll give this version a review now. I will do a lot more
> soon. I need to come up with a good benchmark for this, that I can
> return to again and again during review as needed.
Thank you for reviewing the patches.
>
> Some feedback on the first patch:
>
> * Just so you know: I agree with you about handling
> VACOPT_TERNARY_DISABLED in the index AM's amvacuumstrategy routine. I
> think that it's better to do that there, even though this choice may
> have some downsides.
>
> * Can you add some "stub" sgml doc changes for this? Doesn't have to
> be complete in any way. Just a placeholder for later, that has the
> correct general "shape" to orientate the reader of the patch. It can
> just be a FIXME comment, plus basic mechanical stuff -- details of the
> new amvacuumstrategy_function routine and its signature.
>
0002 patch had the doc update (I mistakenly included it to 0002
patch). Is that update what you meant?
> Some feedback on the second patch:
>
> * Why do you move around IndexVacuumStrategy in the second patch?
> Looks like a rebasing oversight.
Check.
>
> * Actually, do we really need the first and second patches to be
> separate patches? I agree that the nbtree patch should be a separate
> patch, but dividing the first two sets of changes doesn't seem like it
> adds much. Did I miss some something?
I separated the patches since I used to have separate patches when
adding other index AM options required by parallel vacuum. But I
agreed to merge the first two patches.
>
> * Is the "MAXALIGN(sizeof(ItemIdData)))" change in the definition of
> MaxHeapTuplesPerPage appropriate? Here is the relevant section from
> the patch:
>
> diff --git a/src/include/access/htup_details.h
> b/src/include/access/htup_details.h
> index 7c62852e7f..038e7cd580 100644
> --- a/src/include/access/htup_details.h
> +++ b/src/include/access/htup_details.h
> @@ -563,17 +563,18 @@ do { \
> /*
> * MaxHeapTuplesPerPage is an upper bound on the number of tuples that can
> * fit on one heap page. (Note that indexes could have more, because they
> - * use a smaller tuple header.) We arrive at the divisor because each tuple
> - * must be maxaligned, and it must have an associated line pointer.
> + * use a smaller tuple header.) We arrive at the divisor because each line
> + * pointer must be maxaligned.
> *** SNIP ***
> #define MaxHeapTuplesPerPage \
> - ((int) ((BLCKSZ - SizeOfPageHeaderData) / \
> - (MAXALIGN(SizeofHeapTupleHeader) + sizeof(ItemIdData))))
> + ((int) ((BLCKSZ - SizeOfPageHeaderData) / (MAXALIGN(sizeof(ItemIdData)))))
>
> It's true that ItemIdData structs (line pointers) are aligned, but
> they're not MAXALIGN()'d. If they were then the on-disk size of line
> pointers would generally be 8 bytes, not 4 bytes.
You're right. Will fix.
>
> * Maybe it would be better if you just changed the definition such
> that "MAXALIGN(SizeofHeapTupleHeader)" became "MAXIMUM_ALIGNOF", with
> no other changes? (Some variant of this suggestion might be better,
> not sure.)
>
> For some reason that feels a bit safer: we still have an "imaginary
> tuple header", but it's just 1 MAXALIGN() quantum now. This is still
> much less than the current 3 MAXALIGN() quantums (i.e. what
> MaxHeapTuplesPerPage treats as the tuple header size). Do you think
> that this alternative approach will be noticeably less effective
> within vacuumlazy.c?
>
> Note that you probably understand the issue with MaxHeapTuplesPerPage
> for vacuumlazy.c better than I do currently. I'm still trying to
> understand your choices, and to understand what is really important
> here.
Yeah, using MAXIMUM_ALIGNOF seems better for safety. I shared my
thoughts on the issue with MaxHeapTuplesPerPage yesterday. I think we
need to discuss how to deal with that.
>
> * Maybe add a #define for the value 0.7? (I refer to the value used in
> choose_vacuum_strategy() to calculate a "this is the number of LP_DEAD
> line pointers that we consider too many" cut off point, which is to be
> applied throughout lazy_scan_heap() processing.)
>
Agreed.
> * I notice that your new lazy_vacuum_table_and_indexes() function is
> the only place that calls lazy_vacuum_table_and_indexes(). I think
> that you should merge them together -- replace the only remaining call
> to lazy_vacuum_table_and_indexes() with the body of the function
> itself. Having a separate lazy_vacuum_table_and_indexes() function
> doesn't seem useful to me -- it doesn't actually hide complexity, and
> might even be harder to maintain.
lazy_vacuum_table_and_indexes() is called at two places: after
maintenance_work_mem run out (around L1097) and the end of
lazy_scan_heap() (around L1726). I defined this function to pack the
operations such as choosing a strategy, vacuuming indexes and
vacuuming heap. Without this function, will we end up writing the same
codes twice there?
>
> * I suggest thinking about what the last item will mean for the
> reporting that currently takes place in
> lazy_vacuum_table_and_indexes(), but will now go in an expanded
> lazy_vacuum_table_and_indexes() -- how do we count the total number of
> index scans now?
>
> I don't actually believe that the logic needs to change, but some kind
> of consolidation and streamlining seems like it might be helpful.
> Maybe just a comment that says "note that all index scans might just
> be no-ops because..." -- stuff like that.
What do you mean by the last item and what report? I think
lazy_vacuum_table_and_indexes() itself doesn't report anything and
vacrelstats->num_index_scan counts the total number of index scans.
>
> * Any idea about how hard it will be to teach is_wraparound VACUUMs to
> skip index cleanup automatically, based on some practical/sensible
> criteria?
One simple idea would be to have a to-prevent-wraparound autovacuum
worker disables index cleanup (i.g., setting VACOPT_TERNARY_DISABLED
to index_cleanup). But a downside (but not a common case) is that
since a to-prevent-wraparound vacuum is not necessarily an aggressive
vacuum, it could skip index cleanup even though it cannot move
relfrozenxid forward.
>
> It would be nice to have a basic PoC for that, even if it remains a
> PoC for the foreseeable future (i.e. even if it cannot be committed to
> Postgres 14). This feature should definitely be something that your
> patch series *enables*. I'd feel good about having covered that
> question as part of this basic design work if there was a PoC. That
> alone should make it 100% clear that it's easy to do (or no harder
> than it should be -- it should ideally be compatible with your basic
> design). The exact criteria that we use for deciding whether or not to
> skip index cleanup (which probably should not just be "this VACUUM is
> is_wraparound, good enough" in the final version) may need to be
> debated at length on pgsql-hackers. Even still, it is "just a detail"
> in the code. Whereas being *able* to do that with your design (now or
> in the future) seems essential now.
Agreed. I'll write a PoC patch for that.
>
> > * Store the answers to amvacuumstrategy into either the local memory
> > or DSM (in parallel vacuum case) so that ambulkdelete can refer the
> > answer to amvacuumstrategy.
> > * Fix regression failures.
> > * Update the documentation and commments.
> >
> > Note that 0003 patch is still PoC quality, lacking the btree meta page
> > version upgrade.
>
> This patch is not the hard part, of course -- there really isn't that
> much needed here compared to vacuumlazy.c. So this patch seems like
> the simplest 1 out of the 3 (at least to me).
>
> Some feedback on the third patch:
>
> * The new btm_last_deletion_nblocks metapage field should use P_NONE
> (which is 0) to indicate never having been vacuumed -- not
> InvalidBlockNumber (which is 0xFFFFFFFF).
>
> This is more idiomatic in nbtree, which is nice, but it has a very
> significant practical advantage: it ensures that every heapkeyspace
> nbtree index (i.e. those on recent nbtree versions) can be treated as
> if it has the new btm_last_deletion_nblocks field all along, even when
> it actually built on Postgres 12 or 13. This trick will let you avoid
> dealing with the headache of bumping BTREE_VERSION, which is a huge
> advantage.
>
> Note that this is the same trick I used to avoid bumping BTREE_VERSION
> when the btm_allequalimage field needed to be added (for the nbtree
> deduplication feature added to Postgres 13).
>
That's a nice way with a great advantage. I'll use P_NONE.
> * Forgot to do this in the third patch (think I made this same mistake
> once myself):
>
> diff --git a/contrib/pageinspect/btreefuncs.c b/contrib/pageinspect/btreefuncs.c
> index 8bb180bbbe..88dfea9af3 100644
> --- a/contrib/pageinspect/btreefuncs.c
> +++ b/contrib/pageinspect/btreefuncs.c
> @@ -653,7 +653,7 @@ bt_metap(PG_FUNCTION_ARGS)
> BTMetaPageData *metad;
> TupleDesc tupleDesc;
> int j;
> - char *values[9];
> + char *values[10];
> Buffer buffer;
> Page page;
> HeapTuple tuple;
> @@ -734,6 +734,11 @@ bt_metap(PG_FUNCTION_ARGS)
Check.
I'm updating and testing the patch. I'll submit the updated version
patches tomorrow.
Regards,
--
Masahiko Sawada
EDB: https://www.enterprisedb.com/
On Tue, Jan 19, 2021 at 2:57 PM Peter Geoghegan <pg@bowt.ie> wrote: > Looks good. I'll give this version a review now. I will do a lot more > soon. I need to come up with a good benchmark for this, that I can > return to again and again during review as needed. I performed another benchmark, similar to the last one but with the latest version (v2), and over a much longer period. Attached is a summary of the whole benchmark, and log_autovacuum output from the logs of both the master branch and the patch. This was pgbench scale 2000, 4 indexes on pgbench_accounts, and a transaction with one update and two selects. Each run was 4 hours, and we alternate between patch and master for each run, and alternate between 16 and 32 clients. There were 8 4 hour runs in total, meaning the entire set of runs took 8 * 4 hours = 32 hours (not including initial load time and a few other small things like that). I used a 10k TPS rate limit, so TPS isn't interesting here. Latency is interesting -- we see a nice improvement in latency (i.e. a reduction) for the patch (see all.summary.out). The benefits of the patch are clearly visible when I drill down and look at the details. Each pgbench_accounts autovacuum VACUUM operation can finish faster with the patch because they can often skip at least some indexes (usually the PK, sometimes 3 out of 4 indexes total). But it's more subtle than some might assume. We're skipping indexes that VACUUM actually would have deleted *some* index tuples from, which is very good. Bottom-up index deletion is usually lazy, and only occasionally very eager, so you still have plenty of "floating garbage" index tuples in most pages. And now we see VACUUM behave a little more like bottom-up index deletion -- it is lazy when that is appropriate (with indexes that really only have floating garbage that is spread diffusely throughout the index structure), and eager when that is appropriate (with indexes that get much more garbage). The benefit is not really that we're avoiding doing I/O for index vacuuming (though that is one of the smaller benefits here). The real benefit is that VACUUM is not dirtying pages, since it skips indexes when it would be "premature" to vacuum them from an efficiency point of view. This is important because we know that Postgres throughput is very often limited by page cleaning. Also, the "economics" of this new behavior make perfect sense -- obviously it's more efficient to delay garbage cleanup until the point when the same page will be modified by a backend anyway -- in the case of this benchmark via bottom-up index deletion (which deletes all garbage tuples in the leaf page at the point that it runs for a subset of pointed-to heap pages -- it's not using an oldestXmin cutoff from 30 minutes ago). So whenever we dirty a page, we now get more value per additional-page-dirtied. I believe that controlling the number of pages dirtied by VACUUM is usually much more important than reducing the amount of read I/O from VACUUM, for reasons I go into on the recent "vacuum_cost_page_miss default value and modern hardware" thread. As a further consequence of all this, VACUUM can go faster safely and sustainably (since the cost limit is not affected so much by vacuum_cost_page_miss), which has its own benefits (e.g. oldestXmin cutoff doesn't get so old towards the end). Another closely related huge improvement that we see here is that the number of FPIs generated by VACUUM can be significantly reduced. This cost is closely related to the cost of dirtying pages, but it's worth mentioning separately. You'll see some of that in the log_autovacuum log output I attached. There is an archive with much more detailed information, including dumps from most pg_stat_* views at key intervals. This has way more information than anybody is likely to want: https://drive.google.com/file/d/1OTiErELKRZmYnuJuczO2Tfcm1-cBYITd/view?usp=sharing I did notice a problem, though. I now think that the criteria for skipping an index vacuum in the third patch from the series is too conservative, and that this led to an excessive number of index vacuums with the patch. This is probably because there was a tiny number of page splits in some of the indexes that were not really supposed to grow. I believe that this is caused by ANALYZE running -- I think that it prevented bottom-up deletion from keeping a few of the hottest pages from splitting (that can take 5 or 6 seconds) at a few points over the 32 hour run. For example, the index named "tenner" grew by 9 blocks, starting out at 230,701 and ending up at 230,710 (to see this, extract the files from the archive and "diff patch.r1c16.initial_pg_relation_size.out patch.r2c32.after_pg_relation_size.out"). I now think that 0 blocks added is unnecessarily restrictive -- a small tolerance still seems like a good idea, though (let's still be somewhat conservative about it). Maybe a better criteria would be for nbtree to always proceed with index vacuuming when the index size is less than 2048 blocks (16MiB with 8KiB BLCKSZ). If an index is larger than that, then compare the last/old block count to the current block count (at the point that we decide if index vacuuming is going to go ahead) by rounding up both values to the next highest 2048 block increment. This formula is pretty arbitrary, but probably works as well as most others. It's a good iteration for the next version of the patch/further testing, at least. BTW, it would be nice if there was more instrumentation, say in the log output produced when log_autovacuum is on. That would make it easier to run these benchmarks -- I could verify my understanding of the work done for each particular av operation represented in the log. Though the default log_autovacuum log output is quite informative, it would be nice if the specifics were more obvious (maybe this could just be for the review/testing, but it might become something for users if it seems useful). -- Peter Geoghegan
Вложения
On Thu, Jan 21, 2021 at 11:24 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> On Wed, Jan 20, 2021 at 7:58 AM Peter Geoghegan <pg@bowt.ie> wrote:
> >
> > On Sun, Jan 17, 2021 at 9:18 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> > > After more thought, I think that ambulkdelete needs to be able to
> > > refer the answer to amvacuumstrategy. That way, the index can skip
> > > bulk-deletion when lazy vacuum doesn't vacuum heap and it also doesn’t
> > > want to do that.
> >
> > Makes sense.
> >
> > BTW, your patch has bitrot already. Peter E's recent pageinspect
> > commit happens to conflict with this patch. It might make sense to
> > produce a new version that just fixes the bitrot, so that other people
> > don't have to deal with it each time.
> >
> > > I’ve attached the updated version patch that includes the following changes:
> >
> > Looks good. I'll give this version a review now. I will do a lot more
> > soon. I need to come up with a good benchmark for this, that I can
> > return to again and again during review as needed.
>
> Thank you for reviewing the patches.
>
> >
> > Some feedback on the first patch:
> >
> > * Just so you know: I agree with you about handling
> > VACOPT_TERNARY_DISABLED in the index AM's amvacuumstrategy routine. I
> > think that it's better to do that there, even though this choice may
> > have some downsides.
> >
> > * Can you add some "stub" sgml doc changes for this? Doesn't have to
> > be complete in any way. Just a placeholder for later, that has the
> > correct general "shape" to orientate the reader of the patch. It can
> > just be a FIXME comment, plus basic mechanical stuff -- details of the
> > new amvacuumstrategy_function routine and its signature.
> >
>
> 0002 patch had the doc update (I mistakenly included it to 0002
> patch). Is that update what you meant?
>
> > Some feedback on the second patch:
> >
> > * Why do you move around IndexVacuumStrategy in the second patch?
> > Looks like a rebasing oversight.
>
> Check.
>
> >
> > * Actually, do we really need the first and second patches to be
> > separate patches? I agree that the nbtree patch should be a separate
> > patch, but dividing the first two sets of changes doesn't seem like it
> > adds much. Did I miss some something?
>
> I separated the patches since I used to have separate patches when
> adding other index AM options required by parallel vacuum. But I
> agreed to merge the first two patches.
>
> >
> > * Is the "MAXALIGN(sizeof(ItemIdData)))" change in the definition of
> > MaxHeapTuplesPerPage appropriate? Here is the relevant section from
> > the patch:
> >
> > diff --git a/src/include/access/htup_details.h
> > b/src/include/access/htup_details.h
> > index 7c62852e7f..038e7cd580 100644
> > --- a/src/include/access/htup_details.h
> > +++ b/src/include/access/htup_details.h
> > @@ -563,17 +563,18 @@ do { \
> > /*
> > * MaxHeapTuplesPerPage is an upper bound on the number of tuples that can
> > * fit on one heap page. (Note that indexes could have more, because they
> > - * use a smaller tuple header.) We arrive at the divisor because each tuple
> > - * must be maxaligned, and it must have an associated line pointer.
> > + * use a smaller tuple header.) We arrive at the divisor because each line
> > + * pointer must be maxaligned.
> > *** SNIP ***
> > #define MaxHeapTuplesPerPage \
> > - ((int) ((BLCKSZ - SizeOfPageHeaderData) / \
> > - (MAXALIGN(SizeofHeapTupleHeader) + sizeof(ItemIdData))))
> > + ((int) ((BLCKSZ - SizeOfPageHeaderData) / (MAXALIGN(sizeof(ItemIdData)))))
> >
> > It's true that ItemIdData structs (line pointers) are aligned, but
> > they're not MAXALIGN()'d. If they were then the on-disk size of line
> > pointers would generally be 8 bytes, not 4 bytes.
>
> You're right. Will fix.
>
> >
> > * Maybe it would be better if you just changed the definition such
> > that "MAXALIGN(SizeofHeapTupleHeader)" became "MAXIMUM_ALIGNOF", with
> > no other changes? (Some variant of this suggestion might be better,
> > not sure.)
> >
> > For some reason that feels a bit safer: we still have an "imaginary
> > tuple header", but it's just 1 MAXALIGN() quantum now. This is still
> > much less than the current 3 MAXALIGN() quantums (i.e. what
> > MaxHeapTuplesPerPage treats as the tuple header size). Do you think
> > that this alternative approach will be noticeably less effective
> > within vacuumlazy.c?
> >
> > Note that you probably understand the issue with MaxHeapTuplesPerPage
> > for vacuumlazy.c better than I do currently. I'm still trying to
> > understand your choices, and to understand what is really important
> > here.
>
> Yeah, using MAXIMUM_ALIGNOF seems better for safety. I shared my
> thoughts on the issue with MaxHeapTuplesPerPage yesterday. I think we
> need to discuss how to deal with that.
>
> >
> > * Maybe add a #define for the value 0.7? (I refer to the value used in
> > choose_vacuum_strategy() to calculate a "this is the number of LP_DEAD
> > line pointers that we consider too many" cut off point, which is to be
> > applied throughout lazy_scan_heap() processing.)
> >
>
> Agreed.
>
> > * I notice that your new lazy_vacuum_table_and_indexes() function is
> > the only place that calls lazy_vacuum_table_and_indexes(). I think
> > that you should merge them together -- replace the only remaining call
> > to lazy_vacuum_table_and_indexes() with the body of the function
> > itself. Having a separate lazy_vacuum_table_and_indexes() function
> > doesn't seem useful to me -- it doesn't actually hide complexity, and
> > might even be harder to maintain.
>
> lazy_vacuum_table_and_indexes() is called at two places: after
> maintenance_work_mem run out (around L1097) and the end of
> lazy_scan_heap() (around L1726). I defined this function to pack the
> operations such as choosing a strategy, vacuuming indexes and
> vacuuming heap. Without this function, will we end up writing the same
> codes twice there?
>
> >
> > * I suggest thinking about what the last item will mean for the
> > reporting that currently takes place in
> > lazy_vacuum_table_and_indexes(), but will now go in an expanded
> > lazy_vacuum_table_and_indexes() -- how do we count the total number of
> > index scans now?
> >
> > I don't actually believe that the logic needs to change, but some kind
> > of consolidation and streamlining seems like it might be helpful.
> > Maybe just a comment that says "note that all index scans might just
> > be no-ops because..." -- stuff like that.
>
> What do you mean by the last item and what report? I think
> lazy_vacuum_table_and_indexes() itself doesn't report anything and
> vacrelstats->num_index_scan counts the total number of index scans.
>
> >
> > * Any idea about how hard it will be to teach is_wraparound VACUUMs to
> > skip index cleanup automatically, based on some practical/sensible
> > criteria?
>
> One simple idea would be to have a to-prevent-wraparound autovacuum
> worker disables index cleanup (i.g., setting VACOPT_TERNARY_DISABLED
> to index_cleanup). But a downside (but not a common case) is that
> since a to-prevent-wraparound vacuum is not necessarily an aggressive
> vacuum, it could skip index cleanup even though it cannot move
> relfrozenxid forward.
>
> >
> > It would be nice to have a basic PoC for that, even if it remains a
> > PoC for the foreseeable future (i.e. even if it cannot be committed to
> > Postgres 14). This feature should definitely be something that your
> > patch series *enables*. I'd feel good about having covered that
> > question as part of this basic design work if there was a PoC. That
> > alone should make it 100% clear that it's easy to do (or no harder
> > than it should be -- it should ideally be compatible with your basic
> > design). The exact criteria that we use for deciding whether or not to
> > skip index cleanup (which probably should not just be "this VACUUM is
> > is_wraparound, good enough" in the final version) may need to be
> > debated at length on pgsql-hackers. Even still, it is "just a detail"
> > in the code. Whereas being *able* to do that with your design (now or
> > in the future) seems essential now.
>
> Agreed. I'll write a PoC patch for that.
>
> >
> > > * Store the answers to amvacuumstrategy into either the local memory
> > > or DSM (in parallel vacuum case) so that ambulkdelete can refer the
> > > answer to amvacuumstrategy.
> > > * Fix regression failures.
> > > * Update the documentation and commments.
> > >
> > > Note that 0003 patch is still PoC quality, lacking the btree meta page
> > > version upgrade.
> >
> > This patch is not the hard part, of course -- there really isn't that
> > much needed here compared to vacuumlazy.c. So this patch seems like
> > the simplest 1 out of the 3 (at least to me).
> >
> > Some feedback on the third patch:
> >
> > * The new btm_last_deletion_nblocks metapage field should use P_NONE
> > (which is 0) to indicate never having been vacuumed -- not
> > InvalidBlockNumber (which is 0xFFFFFFFF).
> >
> > This is more idiomatic in nbtree, which is nice, but it has a very
> > significant practical advantage: it ensures that every heapkeyspace
> > nbtree index (i.e. those on recent nbtree versions) can be treated as
> > if it has the new btm_last_deletion_nblocks field all along, even when
> > it actually built on Postgres 12 or 13. This trick will let you avoid
> > dealing with the headache of bumping BTREE_VERSION, which is a huge
> > advantage.
> >
> > Note that this is the same trick I used to avoid bumping BTREE_VERSION
> > when the btm_allequalimage field needed to be added (for the nbtree
> > deduplication feature added to Postgres 13).
> >
>
> That's a nice way with a great advantage. I'll use P_NONE.
>
> > * Forgot to do this in the third patch (think I made this same mistake
> > once myself):
> >
> > diff --git a/contrib/pageinspect/btreefuncs.c b/contrib/pageinspect/btreefuncs.c
> > index 8bb180bbbe..88dfea9af3 100644
> > --- a/contrib/pageinspect/btreefuncs.c
> > +++ b/contrib/pageinspect/btreefuncs.c
> > @@ -653,7 +653,7 @@ bt_metap(PG_FUNCTION_ARGS)
> > BTMetaPageData *metad;
> > TupleDesc tupleDesc;
> > int j;
> > - char *values[9];
> > + char *values[10];
> > Buffer buffer;
> > Page page;
> > HeapTuple tuple;
> > @@ -734,6 +734,11 @@ bt_metap(PG_FUNCTION_ARGS)
>
> Check.
>
> I'm updating and testing the patch. I'll submit the updated version
> patches tomorrow.
>
Sorry for the late.
I've attached the updated version patch that incorporated the comments
I got so far.
I merged the previous 0001 and 0002 patches. 0003 patch is now another
PoC patch that disables index cleanup automatically when autovacuum is
to prevent xid-wraparound and an aggressive vacuum.
Regards,
--
Masahiko Sawada
EDB: https://www.enterprisedb.com/
Вложения
(Please avoid top-posting on the mailing lists[1]: top-posting breaks the logic of a thread.) On Tue, Jan 19, 2021 at 12:02 AM Zhihong Yu <zyu@yugabyte.com> wrote: > > Hi, Masahiko-san: Thank you for reviewing the patch! > > For v2-0001-Introduce-IndexAM-API-for-choosing-index-vacuum-s.patch : > > For blvacuumstrategy(): > > + if (params->index_cleanup == VACOPT_TERNARY_DISABLED) > + return INDEX_VACUUM_STRATEGY_NONE; > + else > + return INDEX_VACUUM_STRATEGY_BULKDELETE; > > The 'else' can be omitted. Yes, but I'd prefer to leave it as it is because it's more readable without any performance side effect that we return BULKDELETE if index cleanup is enabled. > > Similar comment for ginvacuumstrategy(). > > For v2-0002-Choose-index-vacuum-strategy-based-on-amvacuumstr.patch : > > If index_cleanup option is specified neither VACUUM command nor > storage option > > I think this is what you meant (by not using passive voice): > > If index_cleanup option specifies neither VACUUM command nor > storage option, > > - * integer, but you can't fit that many items on a page. 11 ought to be more > + * integer, but you can't fit that many items on a page. 13 ought to be more > > It would be nice to add a note why the number of bits is increased. I think that it might be better to mention such update history in the commit log rather than in the source code. Because most readers are likely to be interested in why 12 bits for offset number is enough, rather than why this value has been increased. In the source code comment, we describe why 12 bits for offset number is enough. We can mention in the commit log that since the commit changes MaxHeapTuplesPerPage the encoding in gin posting list is also changed. What do you think? > For choose_vacuum_strategy(): > > + IndexVacuumStrategy ivstrat; > > The variable is only used inside the loop. You can use vacrelstats->ivstrategies[i] directly and omit the variable. Fixed. > > + int ndeaditems_limit = (int) ((freespace / sizeof(ItemIdData)) * 0.7); > > How was the factor of 0.7 determined ? Comment below only mentioned 'safety factor' but not how it was chosen. > I also wonder if this factor should be exposed as GUC. Fixed. > > + if (nworkers > 0) > + nworkers--; > > Should log / assert be added when nworkers is <= 0 ? Hmm I don't think so. As far as I read the code, there is no possibility that nworkers can be lower than 0 (we always increment it) and actually, the code works fine even if nworkers is a negative value. > > + * XXX: allowing to fill the heap page with only line pointer seems a overkill. > > 'a overkill' -> 'an overkill' > Fixed. The above comments are incorporated into the latest patch I just posted[2]. [1] https://en.wikipedia.org/wiki/Posting_style#Top-posting [2] https://www.postgresql.org/message-id/CAD21AoCS94vK1fs-_%3DR5J3tp2DsZPq9zdcUu2pk6fbr7BS7quA%40mail.gmail.com -- Masahiko Sawada EDB: https://www.enterprisedb.com/
On Mon, Jan 25, 2021 at 5:19 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> On Thu, Jan 21, 2021 at 11:24 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> >
> > On Wed, Jan 20, 2021 at 7:58 AM Peter Geoghegan <pg@bowt.ie> wrote:
> > >
> > > On Sun, Jan 17, 2021 at 9:18 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> > > > After more thought, I think that ambulkdelete needs to be able to
> > > > refer the answer to amvacuumstrategy. That way, the index can skip
> > > > bulk-deletion when lazy vacuum doesn't vacuum heap and it also doesn’t
> > > > want to do that.
> > >
> > > Makes sense.
> > >
> > > BTW, your patch has bitrot already. Peter E's recent pageinspect
> > > commit happens to conflict with this patch. It might make sense to
> > > produce a new version that just fixes the bitrot, so that other people
> > > don't have to deal with it each time.
> > >
> > > > I’ve attached the updated version patch that includes the following changes:
> > >
> > > Looks good. I'll give this version a review now. I will do a lot more
> > > soon. I need to come up with a good benchmark for this, that I can
> > > return to again and again during review as needed.
> >
> > Thank you for reviewing the patches.
> >
> > >
> > > Some feedback on the first patch:
> > >
> > > * Just so you know: I agree with you about handling
> > > VACOPT_TERNARY_DISABLED in the index AM's amvacuumstrategy routine. I
> > > think that it's better to do that there, even though this choice may
> > > have some downsides.
> > >
> > > * Can you add some "stub" sgml doc changes for this? Doesn't have to
> > > be complete in any way. Just a placeholder for later, that has the
> > > correct general "shape" to orientate the reader of the patch. It can
> > > just be a FIXME comment, plus basic mechanical stuff -- details of the
> > > new amvacuumstrategy_function routine and its signature.
> > >
> >
> > 0002 patch had the doc update (I mistakenly included it to 0002
> > patch). Is that update what you meant?
> >
> > > Some feedback on the second patch:
> > >
> > > * Why do you move around IndexVacuumStrategy in the second patch?
> > > Looks like a rebasing oversight.
> >
> > Check.
> >
> > >
> > > * Actually, do we really need the first and second patches to be
> > > separate patches? I agree that the nbtree patch should be a separate
> > > patch, but dividing the first two sets of changes doesn't seem like it
> > > adds much. Did I miss some something?
> >
> > I separated the patches since I used to have separate patches when
> > adding other index AM options required by parallel vacuum. But I
> > agreed to merge the first two patches.
> >
> > >
> > > * Is the "MAXALIGN(sizeof(ItemIdData)))" change in the definition of
> > > MaxHeapTuplesPerPage appropriate? Here is the relevant section from
> > > the patch:
> > >
> > > diff --git a/src/include/access/htup_details.h
> > > b/src/include/access/htup_details.h
> > > index 7c62852e7f..038e7cd580 100644
> > > --- a/src/include/access/htup_details.h
> > > +++ b/src/include/access/htup_details.h
> > > @@ -563,17 +563,18 @@ do { \
> > > /*
> > > * MaxHeapTuplesPerPage is an upper bound on the number of tuples that can
> > > * fit on one heap page. (Note that indexes could have more, because they
> > > - * use a smaller tuple header.) We arrive at the divisor because each tuple
> > > - * must be maxaligned, and it must have an associated line pointer.
> > > + * use a smaller tuple header.) We arrive at the divisor because each line
> > > + * pointer must be maxaligned.
> > > *** SNIP ***
> > > #define MaxHeapTuplesPerPage \
> > > - ((int) ((BLCKSZ - SizeOfPageHeaderData) / \
> > > - (MAXALIGN(SizeofHeapTupleHeader) + sizeof(ItemIdData))))
> > > + ((int) ((BLCKSZ - SizeOfPageHeaderData) / (MAXALIGN(sizeof(ItemIdData)))))
> > >
> > > It's true that ItemIdData structs (line pointers) are aligned, but
> > > they're not MAXALIGN()'d. If they were then the on-disk size of line
> > > pointers would generally be 8 bytes, not 4 bytes.
> >
> > You're right. Will fix.
> >
> > >
> > > * Maybe it would be better if you just changed the definition such
> > > that "MAXALIGN(SizeofHeapTupleHeader)" became "MAXIMUM_ALIGNOF", with
> > > no other changes? (Some variant of this suggestion might be better,
> > > not sure.)
> > >
> > > For some reason that feels a bit safer: we still have an "imaginary
> > > tuple header", but it's just 1 MAXALIGN() quantum now. This is still
> > > much less than the current 3 MAXALIGN() quantums (i.e. what
> > > MaxHeapTuplesPerPage treats as the tuple header size). Do you think
> > > that this alternative approach will be noticeably less effective
> > > within vacuumlazy.c?
> > >
> > > Note that you probably understand the issue with MaxHeapTuplesPerPage
> > > for vacuumlazy.c better than I do currently. I'm still trying to
> > > understand your choices, and to understand what is really important
> > > here.
> >
> > Yeah, using MAXIMUM_ALIGNOF seems better for safety. I shared my
> > thoughts on the issue with MaxHeapTuplesPerPage yesterday. I think we
> > need to discuss how to deal with that.
> >
> > >
> > > * Maybe add a #define for the value 0.7? (I refer to the value used in
> > > choose_vacuum_strategy() to calculate a "this is the number of LP_DEAD
> > > line pointers that we consider too many" cut off point, which is to be
> > > applied throughout lazy_scan_heap() processing.)
> > >
> >
> > Agreed.
> >
> > > * I notice that your new lazy_vacuum_table_and_indexes() function is
> > > the only place that calls lazy_vacuum_table_and_indexes(). I think
> > > that you should merge them together -- replace the only remaining call
> > > to lazy_vacuum_table_and_indexes() with the body of the function
> > > itself. Having a separate lazy_vacuum_table_and_indexes() function
> > > doesn't seem useful to me -- it doesn't actually hide complexity, and
> > > might even be harder to maintain.
> >
> > lazy_vacuum_table_and_indexes() is called at two places: after
> > maintenance_work_mem run out (around L1097) and the end of
> > lazy_scan_heap() (around L1726). I defined this function to pack the
> > operations such as choosing a strategy, vacuuming indexes and
> > vacuuming heap. Without this function, will we end up writing the same
> > codes twice there?
> >
> > >
> > > * I suggest thinking about what the last item will mean for the
> > > reporting that currently takes place in
> > > lazy_vacuum_table_and_indexes(), but will now go in an expanded
> > > lazy_vacuum_table_and_indexes() -- how do we count the total number of
> > > index scans now?
> > >
> > > I don't actually believe that the logic needs to change, but some kind
> > > of consolidation and streamlining seems like it might be helpful.
> > > Maybe just a comment that says "note that all index scans might just
> > > be no-ops because..." -- stuff like that.
> >
> > What do you mean by the last item and what report? I think
> > lazy_vacuum_table_and_indexes() itself doesn't report anything and
> > vacrelstats->num_index_scan counts the total number of index scans.
> >
> > >
> > > * Any idea about how hard it will be to teach is_wraparound VACUUMs to
> > > skip index cleanup automatically, based on some practical/sensible
> > > criteria?
> >
> > One simple idea would be to have a to-prevent-wraparound autovacuum
> > worker disables index cleanup (i.g., setting VACOPT_TERNARY_DISABLED
> > to index_cleanup). But a downside (but not a common case) is that
> > since a to-prevent-wraparound vacuum is not necessarily an aggressive
> > vacuum, it could skip index cleanup even though it cannot move
> > relfrozenxid forward.
> >
> > >
> > > It would be nice to have a basic PoC for that, even if it remains a
> > > PoC for the foreseeable future (i.e. even if it cannot be committed to
> > > Postgres 14). This feature should definitely be something that your
> > > patch series *enables*. I'd feel good about having covered that
> > > question as part of this basic design work if there was a PoC. That
> > > alone should make it 100% clear that it's easy to do (or no harder
> > > than it should be -- it should ideally be compatible with your basic
> > > design). The exact criteria that we use for deciding whether or not to
> > > skip index cleanup (which probably should not just be "this VACUUM is
> > > is_wraparound, good enough" in the final version) may need to be
> > > debated at length on pgsql-hackers. Even still, it is "just a detail"
> > > in the code. Whereas being *able* to do that with your design (now or
> > > in the future) seems essential now.
> >
> > Agreed. I'll write a PoC patch for that.
> >
> > >
> > > > * Store the answers to amvacuumstrategy into either the local memory
> > > > or DSM (in parallel vacuum case) so that ambulkdelete can refer the
> > > > answer to amvacuumstrategy.
> > > > * Fix regression failures.
> > > > * Update the documentation and commments.
> > > >
> > > > Note that 0003 patch is still PoC quality, lacking the btree meta page
> > > > version upgrade.
> > >
> > > This patch is not the hard part, of course -- there really isn't that
> > > much needed here compared to vacuumlazy.c. So this patch seems like
> > > the simplest 1 out of the 3 (at least to me).
> > >
> > > Some feedback on the third patch:
> > >
> > > * The new btm_last_deletion_nblocks metapage field should use P_NONE
> > > (which is 0) to indicate never having been vacuumed -- not
> > > InvalidBlockNumber (which is 0xFFFFFFFF).
> > >
> > > This is more idiomatic in nbtree, which is nice, but it has a very
> > > significant practical advantage: it ensures that every heapkeyspace
> > > nbtree index (i.e. those on recent nbtree versions) can be treated as
> > > if it has the new btm_last_deletion_nblocks field all along, even when
> > > it actually built on Postgres 12 or 13. This trick will let you avoid
> > > dealing with the headache of bumping BTREE_VERSION, which is a huge
> > > advantage.
> > >
> > > Note that this is the same trick I used to avoid bumping BTREE_VERSION
> > > when the btm_allequalimage field needed to be added (for the nbtree
> > > deduplication feature added to Postgres 13).
> > >
> >
> > That's a nice way with a great advantage. I'll use P_NONE.
> >
> > > * Forgot to do this in the third patch (think I made this same mistake
> > > once myself):
> > >
> > > diff --git a/contrib/pageinspect/btreefuncs.c b/contrib/pageinspect/btreefuncs.c
> > > index 8bb180bbbe..88dfea9af3 100644
> > > --- a/contrib/pageinspect/btreefuncs.c
> > > +++ b/contrib/pageinspect/btreefuncs.c
> > > @@ -653,7 +653,7 @@ bt_metap(PG_FUNCTION_ARGS)
> > > BTMetaPageData *metad;
> > > TupleDesc tupleDesc;
> > > int j;
> > > - char *values[9];
> > > + char *values[10];
> > > Buffer buffer;
> > > Page page;
> > > HeapTuple tuple;
> > > @@ -734,6 +734,11 @@ bt_metap(PG_FUNCTION_ARGS)
> >
> > Check.
> >
> > I'm updating and testing the patch. I'll submit the updated version
> > patches tomorrow.
> >
>
> Sorry for the late.
>
> I've attached the updated version patch that incorporated the comments
> I got so far.
>
> I merged the previous 0001 and 0002 patches. 0003 patch is now another
> PoC patch that disables index cleanup automatically when autovacuum is
> to prevent xid-wraparound and an aggressive vacuum.
Since I found some bugs in the v3 patch I attached the updated version patches.
Regards,
--
Masahiko Sawada
EDB: https://www.enterprisedb.com/
Вложения
Hi,
bq. We can mention in the commit log that since the commit changes
MaxHeapTuplesPerPage the encoding in gin posting list is also changed.
MaxHeapTuplesPerPage the encoding in gin posting list is also changed.
Yes - this is fine.
Thanks
On Mon, Jan 25, 2021 at 12:28 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
(Please avoid top-posting on the mailing lists[1]: top-posting breaks
the logic of a thread.)
On Tue, Jan 19, 2021 at 12:02 AM Zhihong Yu <zyu@yugabyte.com> wrote:
>
> Hi, Masahiko-san:
Thank you for reviewing the patch!
>
> For v2-0001-Introduce-IndexAM-API-for-choosing-index-vacuum-s.patch :
>
> For blvacuumstrategy():
>
> + if (params->index_cleanup == VACOPT_TERNARY_DISABLED)
> + return INDEX_VACUUM_STRATEGY_NONE;
> + else
> + return INDEX_VACUUM_STRATEGY_BULKDELETE;
>
> The 'else' can be omitted.
Yes, but I'd prefer to leave it as it is because it's more readable
without any performance side effect that we return BULKDELETE if index
cleanup is enabled.
>
> Similar comment for ginvacuumstrategy().
>
> For v2-0002-Choose-index-vacuum-strategy-based-on-amvacuumstr.patch :
>
> If index_cleanup option is specified neither VACUUM command nor
> storage option
>
> I think this is what you meant (by not using passive voice):
>
> If index_cleanup option specifies neither VACUUM command nor
> storage option,
>
> - * integer, but you can't fit that many items on a page. 11 ought to be more
> + * integer, but you can't fit that many items on a page. 13 ought to be more
>
> It would be nice to add a note why the number of bits is increased.
I think that it might be better to mention such update history in the
commit log rather than in the source code. Because most readers are
likely to be interested in why 12 bits for offset number is enough,
rather than why this value has been increased. In the source code
comment, we describe why 12 bits for offset number is enough. We can
mention in the commit log that since the commit changes
MaxHeapTuplesPerPage the encoding in gin posting list is also changed.
What do you think?
> For choose_vacuum_strategy():
>
> + IndexVacuumStrategy ivstrat;
>
> The variable is only used inside the loop. You can use vacrelstats->ivstrategies[i] directly and omit the variable.
Fixed.
>
> + int ndeaditems_limit = (int) ((freespace / sizeof(ItemIdData)) * 0.7);
>
> How was the factor of 0.7 determined ? Comment below only mentioned 'safety factor' but not how it was chosen.
> I also wonder if this factor should be exposed as GUC.
Fixed.
>
> + if (nworkers > 0)
> + nworkers--;
>
> Should log / assert be added when nworkers is <= 0 ?
Hmm I don't think so. As far as I read the code, there is no
possibility that nworkers can be lower than 0 (we always increment it)
and actually, the code works fine even if nworkers is a negative
value.
>
> + * XXX: allowing to fill the heap page with only line pointer seems a overkill.
>
> 'a overkill' -> 'an overkill'
>
Fixed.
The above comments are incorporated into the latest patch I just posted[2].
[1] https://en.wikipedia.org/wiki/Posting_style#Top-posting
[2] https://www.postgresql.org/message-id/CAD21AoCS94vK1fs-_%3DR5J3tp2DsZPq9zdcUu2pk6fbr7BS7quA%40mail.gmail.com
--
Masahiko Sawada
EDB: https://www.enterprisedb.com/
On Fri, Jan 22, 2021 at 2:00 PM Peter Geoghegan <pg@bowt.ie> wrote: > > On Tue, Jan 19, 2021 at 2:57 PM Peter Geoghegan <pg@bowt.ie> wrote: > > Looks good. I'll give this version a review now. I will do a lot more > > soon. I need to come up with a good benchmark for this, that I can > > return to again and again during review as needed. > > I performed another benchmark, similar to the last one but with the > latest version (v2), and over a much longer period. Attached is a > summary of the whole benchmark, and log_autovacuum output from the > logs of both the master branch and the patch. Thank you for performing the benchmark! > > This was pgbench scale 2000, 4 indexes on pgbench_accounts, and a > transaction with one update and two selects. Each run was 4 hours, and > we alternate between patch and master for each run, and alternate > between 16 and 32 clients. There were 8 4 hour runs in total, meaning > the entire set of runs took 8 * 4 hours = 32 hours (not including > initial load time and a few other small things like that). I used a > 10k TPS rate limit, so TPS isn't interesting here. Latency is > interesting -- we see a nice improvement in latency (i.e. a reduction) > for the patch (see all.summary.out). What value is set to fillfactor? > > The benefits of the patch are clearly visible when I drill down and > look at the details. Each pgbench_accounts autovacuum VACUUM operation > can finish faster with the patch because they can often skip at least > some indexes (usually the PK, sometimes 3 out of 4 indexes total). But > it's more subtle than some might assume. We're skipping indexes that > VACUUM actually would have deleted *some* index tuples from, which is > very good. Bottom-up index deletion is usually lazy, and only > occasionally very eager, so you still have plenty of "floating > garbage" index tuples in most pages. And now we see VACUUM behave a > little more like bottom-up index deletion -- it is lazy when that is > appropriate (with indexes that really only have floating garbage that > is spread diffusely throughout the index structure), and eager when > that is appropriate (with indexes that get much more garbage). That's very good. I'm happy that this patch efficiently utilizes bottom-up index deletion feature. Looking at the relation size growth, there is almost no difference between master and patched in spite of skipping some vacuums in the patched test, which is also good. > > The benefit is not really that we're avoiding doing I/O for index > vacuuming (though that is one of the smaller benefits here). The real > benefit is that VACUUM is not dirtying pages, since it skips indexes > when it would be "premature" to vacuum them from an efficiency point > of view. This is important because we know that Postgres throughput is > very often limited by page cleaning. Also, the "economics" of this new > behavior make perfect sense -- obviously it's more efficient to delay > garbage cleanup until the point when the same page will be modified by > a backend anyway -- in the case of this benchmark via bottom-up index > deletion (which deletes all garbage tuples in the leaf page at the > point that it runs for a subset of pointed-to heap pages -- it's not > using an oldestXmin cutoff from 30 minutes ago). So whenever we dirty > a page, we now get more value per additional-page-dirtied. > > I believe that controlling the number of pages dirtied by VACUUM is > usually much more important than reducing the amount of read I/O from > VACUUM, for reasons I go into on the recent "vacuum_cost_page_miss > default value and modern hardware" thread. As a further consequence of > all this, VACUUM can go faster safely and sustainably (since the cost > limit is not affected so much by vacuum_cost_page_miss), which has its > own benefits (e.g. oldestXmin cutoff doesn't get so old towards the > end). > > Another closely related huge improvement that we see here is that the > number of FPIs generated by VACUUM can be significantly reduced. This > cost is closely related to the cost of dirtying pages, but it's worth > mentioning separately. You'll see some of that in the log_autovacuum > log output I attached. Makes sense. > > There is an archive with much more detailed information, including > dumps from most pg_stat_* views at key intervals. This has way more > information than anybody is likely to want: > > https://drive.google.com/file/d/1OTiErELKRZmYnuJuczO2Tfcm1-cBYITd/view?usp=sharing > > I did notice a problem, though. I now think that the criteria for > skipping an index vacuum in the third patch from the series is too > conservative, and that this led to an excessive number of index > vacuums with the patch. Maybe that's why there are 5 autovacuum runs on pgbench_accounts in the master branch whereas there are 7 runs in the patched? > This is probably because there was a tiny > number of page splits in some of the indexes that were not really > supposed to grow. I believe that this is caused by ANALYZE running -- > I think that it prevented bottom-up deletion from keeping a few of the > hottest pages from splitting (that can take 5 or 6 seconds) at a few > points over the 32 hour run. For example, the index named "tenner" > grew by 9 blocks, starting out at 230,701 and ending up at 230,710 (to > see this, extract the files from the archive and "diff > patch.r1c16.initial_pg_relation_size.out > patch.r2c32.after_pg_relation_size.out"). > > I now think that 0 blocks added is unnecessarily restrictive -- a > small tolerance still seems like a good idea, though (let's still be > somewhat conservative about it). Agreed. > > Maybe a better criteria would be for nbtree to always proceed with > index vacuuming when the index size is less than 2048 blocks (16MiB > with 8KiB BLCKSZ). If an index is larger than that, then compare the > last/old block count to the current block count (at the point that we > decide if index vacuuming is going to go ahead) by rounding up both > values to the next highest 2048 block increment. This formula is > pretty arbitrary, but probably works as well as most others. It's a > good iteration for the next version of the patch/further testing, at > least. Also makes sense to me. The patch I recently submitted doesn't include it but I'll do that in the next version patch. Maybe the same is true for heap? I mean that skipping heap vacuum on a too-small table will not bring the benefit but bloat. I think we could proceed with heap vacuum if a table is smaller than a threshold, even if one of the indexes wanted to skip. > > BTW, it would be nice if there was more instrumentation, say in the > log output produced when log_autovacuum is on. That would make it > easier to run these benchmarks -- I could verify my understanding of > the work done for each particular av operation represented in the log. > Though the default log_autovacuum log output is quite informative, it > would be nice if the specifics were more obvious (maybe this could > just be for the review/testing, but it might become something for > users if it seems useful). Yeah, I think the following information would also be helpful: * did vacuum heap? or skipped it? * how many indexes did/didn't bulk-deletion? * time spent for each vacuum phase. etc Regards, -- Masahiko Sawada EDB: https://www.enterprisedb.com/
On Tue, Jan 26, 2021 at 10:59 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > What value is set to fillfactor? 90, same as before. > That's very good. I'm happy that this patch efficiently utilizes > bottom-up index deletion feature. Me too! > Looking at the relation size growth, there is almost no difference > between master and patched in spite of skipping some vacuums in the > patched test, which is also good. Right. Stability is everything here. Actually I think that most performance problems in Postgres are mostly about stability if you really look into it. > > I did notice a problem, though. I now think that the criteria for > > skipping an index vacuum in the third patch from the series is too > > conservative, and that this led to an excessive number of index > > vacuums with the patch. > > Maybe that's why there are 5 autovacuum runs on pgbench_accounts in > the master branch whereas there are 7 runs in the patched? Probably, but it might also be due to some other contributing factor. There is still very little growth in the size of the indexes, and the PK still has zero growth. The workload consists of 32 hours of a 10ktps workload, so I imagine that there is opportunity for some extremely rare event to happen a few times. Too tired to think about it in detail right now. It might also be related to the simple fact that only one VACUUM process may run against a table at any given time! With a big enough table, and several indexes, and reasonably aggressive av settings, it's probably almost impossible for autovacuum to "keep up" (in the exact sense that the user asks for by having certain av settings). This must be taken into account in some general way -- It's a bit tricky to interpret results here, generally speaking, because there are probably a few things like that. To me, the most important thing is that the new behavior "makes sense" in some kind of general way, that applies across a variety of workloads. It may not be possible to directly compare master and patch like this and arrive at one simple number that is fair. If we really wanted one simple benchmark number, maybe we'd have to tune the patch and master separately -- which doesn't *seem* fair. > Also makes sense to me. The patch I recently submitted doesn't include > it but I'll do that in the next version patch. Great! > Maybe the same is true for heap? I mean that skipping heap vacuum on a > too-small table will not bring the benefit but bloat. I think we could > proceed with heap vacuum if a table is smaller than a threshold, even > if one of the indexes wanted to skip. I think that you're probably right about that. It isn't a problem for v2 in practice because the bloat will reliably cause LP_DEAD line pointers to accumulate in heap pages, so you VACUUM anyway -- this is certainly what you *always* see in the small pgbench tables with the default workload. But even then -- why not be careful? I agree that there should be some kind of limit on table size that applies here -- a size at which we'll never apply any of these optimizations, no matter what. > Yeah, I think the following information would also be helpful: > > * did vacuum heap? or skipped it? > * how many indexes did/didn't bulk-deletion? > * time spent for each vacuum phase. That list looks good -- in general I don't like that log_autovacuum cannot ever have the VACUUM VERBOSE per-index output -- maybe that could be revisited soon? I remember reading your e-mail about this on a recent thread, and I imagine that you already saw the connection yourself. It'll be essential to have good instrumentation as we do more benchmarking. We're probably going to have to make subjective assessments of benchmark results, based on multiple factors. That will probably be the only practical way to assess how much better (or worse) the patch is compared to master. This patch is more about efficiency and predictability than performance per se. Which is good, because that's where most of the real world problems actually are. -- Peter Geoghegan
On Fri, Jan 29, 2021 at 5:26 PM Peter Geoghegan <pg@bowt.ie> wrote: > It'll be essential to have good instrumentation as we do more > benchmarking. We're probably going to have to make subjective > assessments of benchmark results, based on multiple factors. That will > probably be the only practical way to assess how much better (or > worse) the patch is compared to master. This patch is more about > efficiency and predictability than performance per se. Which is good, > because that's where most of the real world problems actually are. I've been thinking about how to get this patch committed for PostgreSQL 14. This will probably require cutting scope, so that the initial commit is not so ambitious. I think that "incremental VACUUM" could easily take up a lot of my time for Postgres 15, and maybe even Postgres 16. I'm starting to think that the right short term goal should not directly involve bottom-up index deletion. We should instead return to the idea of "unifying" the vacuum_cleanup_index_scale_factor feature with the INDEX_CLEANUP feature, which is kind of where this whole idea started out at. This short term goal is much more than mere refactoring. It is still a whole new user-visible feature. The patch would teach VACUUM to skip doing any real index work within both ambulkdelete() and amvacuumcleanup() in many important cases. Here is a more detailed explanation: Today we can skip all significant work in ambulkdelete() and amvacuumcleanup() when there are zero dead tuples in the table. But why is the threshold *precisely* zero? If we could treat cases that have "practically zero" dead tuples in the same way (or almost the same way) as cases with *exactly* zero dead tuple, that's still a big improvement. And it still sets an important precedent that is crucial for the wider "incremental VACUUM" project: the criteria for triggering index vacuuming becomes truly "fuzzy" for the first time. It is "fuzzy" in the sense that index vacuuming might not happen during VACUUM at all now, even when the user didn't explicitly use VACUUUM's INDEX_CLEANUP option, and even when more than *precisely* zero dead index tuples are involved (though not *much* more than zero, can't be too aggressive). That really is a big change. A recap on vacuum_cleanup_index_scale_factor, just to avoid confusion: The reader should note that this is very different to Masahiko's vacuum_cleanup_index_scale_factor project, which skips *cleanup* in VACUUM (not bulk delete), a question which only comes up when there are definitely zero dead index tuples. The unifying work I'm talking about now implies that we completely avoid scanning indexes during vacuum, even when they are known to have at least a few dead index tuples, and even when VACUUM's INDEX_CLEANUP emergency option is not in use. Which, as I just said, is a big change. Thoughts on triggering criteria for new "unified" design, ~99.9% append-only tables: Actually, in *one* sense the difference between "precisely zero" and "practically zero" here *is* small. But it's still probably going to result in skipping reading indexes during VACUUM in many important cases. Like when you must VACUUM a table that is ~99.9% append-only. In the real world things are rarely in exact discrete categories, even when we imagine that they are. It's too easy to be wrong about one tiny detail -- like one tiny UPDATE from 4 weeks ago, perhaps. Having a tiny amount of "forgiveness" here is actually a *huge* improvement on having precisely zero forgiveness. Small and big. This should help cases that get big surprising spikes due to anti-wraparound vacuums that must vacuum indexes for the first time in ages -- indexes may be vacuumed despite only having a tiny absolute number of dead tuples. I don't think that it's necessary to treat anti-wraparound vacuums as special at all (not in Postgres 14 and probably not ever), because simply considering cases where the table has "practically zero" dead tuples alone should be enough. Vacuuming a 10GB index to delete only 10 tuples simply makes no sense. It doesn't necessarily matter how we end up there, it just shouldn't happen. The ~99.9% append-only table case is likely to be important and common in the real world. We should start there for Postgres 14 because it's easier, that's all. It's not fundamentally different to what happens in workloads involving lots of bottom-up deletion -- it's just simpler, and easier to reason about. Bottom-up deletion is an important piece of the big puzzle here, but some variant of "incremental VACUUM" really would still make sense in a world where bottom-up index deletion does not exist. (In fact, I started thinking about "incremental VACUUM" before bottom-up index deletion, and didn't make any connection between them until work on bottom-up deletion had already progressed significantly.) Here is how the triggering criteria could work: maybe skipping accessing all indexes during VACUUM happens when less than 1% or 10,000 of the items from the table are to be removed by VACUUM -- whichever is greater. Of course this is just the first thing I thought of. It's a starting point for further discussion. My concerns won't be a surprise to you, Masahiko, but I'll list them for the record. The bottom-up index deletion related complexity that I want to avoid dealing with for Postgres 14 is in the following areas (areas that Masahiko's patch dealt with): * No need to teach indexes to do the amvacuumstrategy() stuff in Postgres 14 -- so no need to worry about the exact criteria used within AMs like nbtree to determine whether or not index vacuuming seems appropriate from the "selfish" perspective of one particular index. I'm concerned that factors like bulk DELETEs, that may complicate things for the amvacuumstrategy() routine -- doing something relatively simple based on the recent growth of the index might have downsides. Balancing competing considerations is hard. * No need to change MaxHeapTuplesPerPage for now, since that only really makes sense in cases that heavily involve bottom-up deletion, where we care about the *concentration* of LP_DEAD line pointers in heap pages (and not just the absolute number in the entire table), which is qualitative, not quantitative (somewhat like bottom-up deletion). The change to MaxHeapTuplesPerPage that Masahiko has proposed does make sense -- there are good reasons to increase it. Of course there are also good reasons to not do so. I'm concerned that we won't have time to think through all the possible consequences. * Since "practically zero" dead tuples from a table still isn't very many, the risk of "leaking" many deleted pages due to a known issue with INDEX_CLEANUP in nbtree [1] is much less significant. (FWIW I doubt that skipping index vacuuming is the only way that we can fail to recycle deleted pages anyway -- the FSM is not crash safe, of course, plus I think that _bt_page_recyclable() might be broken in other ways.) In short: we can cut scope and de-risk the patch for Postgres 14 by following this plan, while still avoiding unnecessary index vacuuming within VACUUM in certain important cases. The high-level goal for this patch has always been to recognize that index vacuuming is basically wasted effort in certain cases. Cutting scope here merely means addressing the relatively easy cases first, where simple triggering logic will clearly be effective. I still strongly believe in "incremental VACUUM". What do you think of cutting scope like this for Postgres 14, Masahiko? Sorry to change my mind, but I had to see the prototype to come to this decision. [1] https://www.postgresql.org/message-id/CA+TgmoYD7Xpr1DWEWWXxiw4-WC1NBJf3Rb9D2QGpVYH9ejz9fA@mail.gmail.com -- Peter Geoghegan
On Mon, Feb 1, 2021 at 7:17 PM Peter Geoghegan <pg@bowt.ie> wrote: > Here is how the triggering criteria could work: maybe skipping > accessing all indexes during VACUUM happens when less than 1% or > 10,000 of the items from the table are to be removed by VACUUM -- > whichever is greater. Of course this is just the first thing I thought > of. It's a starting point for further discussion. And now here is the second thing I thought of, which is much better: Sometimes 1% of the dead tuples in a heap relation will be spread across 90%+ of the pages. With other workloads 1% of dead tuples might be highly concentrated, and appear in no more than 1% of all heap pages. Obviously the distinction between these two cases/workloads matters a lot. And so the triggering criteria must be quantitative *and* qualitative. It should not be based on counting dead tuples, since that alone won't differentiate these two extreme cases - both of which are probably quite common (in the real world extremes are actually the normal and common case IME). I like the idea of basing it on counting *heap blocks*, not dead tuples. We can count heap blocks that have *at least* one dead tuple (of course it doesn't matter how they're dead, whether it was this VACUUM operation or some earlier opportunistic pruning). Note in particular that it should not matter if it's a heap block that has only one LP_DEAD line pointer or a heap page that is near the MaxHeapTuplesPerPage limit for the page -- we count either type of page towards the heap-page based limit used to decide if index vacuuming goes ahead for all indexes during VACUUM. This removes almost all of the issues with not setting visibility map bits reliably (another concern of mine that I forget to mention earlier), but it is still very likely to do the right thing in the "~99.9% append-only table" case I mentioned in the last email. We can be relatively aggressive (say by triggering index skipping when less than 1% of all heap pages have dead tuples). Plus the new nbtree index tuple deletion stuff is naturally very good at deleting index tuples in the event of dead tuples becoming concentrated in relatively few table blocks -- that helps too. This is true of the enhanced simple deletion mechanism (which has been taught to be clever about table block dead tuple concentrations/table layout), as well as bottom-up index deletion. -- Peter Geoghegan
вт, 2 февр. 2021 г. в 05:27, Peter Geoghegan <pg@bowt.ie>:
And now here is the second thing I thought of, which is much better:
Sometimes 1% of the dead tuples in a heap relation will be spread
across 90%+ of the pages. With other workloads 1% of dead tuples might
be highly concentrated, and appear in no more than 1% of all heap
pages. Obviously the distinction between these two cases/workloads
matters a lot. And so the triggering criteria must be quantitative
*and* qualitative. It should not be based on counting dead tuples,
since that alone won't differentiate these two extreme cases - both of
which are probably quite common (in the real world extremes are
actually the normal and common case IME).
I like the idea of basing it on counting *heap blocks*, not dead
tuples. We can count heap blocks that have *at least* one dead tuple
(of course it doesn't matter how they're dead, whether it was this
VACUUM operation or some earlier opportunistic pruning). Note in
particular that it should not matter if it's a heap block that has
only one LP_DEAD line pointer or a heap page that is near the
MaxHeapTuplesPerPage limit for the page -- we count either type of
page towards the heap-page based limit used to decide if index
vacuuming goes ahead for all indexes during VACUUM.
I really like this idea!
It resembles the approach used in bottom-up index deletion, block-based
accounting provides a better estimate for the usefulness of the operation.
I suppose that 1% threshold should be configurable as a cluster-wide GUC
and also as a table storage parameter?
Victor Yegorov
On Tue, Feb 2, 2021 at 6:28 AM Victor Yegorov <vyegorov@gmail.com> wrote: > I really like this idea! Cool! > It resembles the approach used in bottom-up index deletion, block-based > accounting provides a better estimate for the usefulness of the operation. It does resemble bottom-up index deletion, in one important general sense: it is somewhat qualitative (though *also* somewhat quantitive). This is new for vacuumlazy.c. But the idea now is to deemphasize bottom-up index deletion heavy workloads in the first version of this patch -- just to cut scope. The design I described yesterday centers around "~99.9% append-only table" workloads, where anti-wraparound vacuums that scan indexes are a big source of unnecessary work (in practice it is always anti-wraparound vacuums, simply because there will never be enough garbage to trigger a regular autovacuum run). But it now occurs to me that there is another very important case that it will also help, without making the triggering condition for index vacuuming any more complicated: it will help cases where HOT updates are expected (because all updates don't modify indexed columns). It's practically impossible for HOT updates to occur 100% of the time, even with workloads whose updates never modify indexed columns. You can clearly see this by looking at the stats from pg_stat_user_tables with a standard pgbench workload. It does get better with lower heap fill factor, but I think that HOT is never 100% effective (i.e. 100% of updates are HOT updates) in the real world -- unless maybe you set heap fillfactor as low as 50, which is very rare. HOT might well be 95% effective, or 99% effective, but it's never truly 100% effective. And so this is another important workload where the difference between "practically zero dead tuples" and "precisely zero dead tuples" *really* matters when deciding if a VACUUM operation needs to go ahead. Once again, a small difference, but also a big difference. Forgive me for repeating myself do much, but: paying attention to cost/benefit asymmetries like this one sometimes allow us to recognize an optimization that is an "excellent deal". We saw this with bottom-up index deletion. Seems good to keep an eye out for that. > I suppose that 1% threshold should be configurable as a cluster-wide GUC > and also as a table storage parameter? Possibly. I'm concerned about making any user-visible interface (say a GUC) compatible with an improved version that is smarter about bottom-up index deletion (in particular, one that can vacuum only a subset of the indexes on a table, which now seems too ambitious for Postgres 14). -- Peter Geoghegan
On Tue, Feb 2, 2021 at 12:17 PM Peter Geoghegan <pg@bowt.ie> wrote: > > On Fri, Jan 29, 2021 at 5:26 PM Peter Geoghegan <pg@bowt.ie> wrote: > > It'll be essential to have good instrumentation as we do more > > benchmarking. We're probably going to have to make subjective > > assessments of benchmark results, based on multiple factors. That will > > probably be the only practical way to assess how much better (or > > worse) the patch is compared to master. This patch is more about > > efficiency and predictability than performance per se. Which is good, > > because that's where most of the real world problems actually are. > > I've been thinking about how to get this patch committed for > PostgreSQL 14. This will probably require cutting scope, so that the > initial commit is not so ambitious. I think that "incremental VACUUM" > could easily take up a lot of my time for Postgres 15, and maybe even > Postgres 16. > > I'm starting to think that the right short term goal should not > directly involve bottom-up index deletion. We should instead return to > the idea of "unifying" the vacuum_cleanup_index_scale_factor feature > with the INDEX_CLEANUP feature, which is kind of where this whole idea > started out at. This short term goal is much more than mere > refactoring. It is still a whole new user-visible feature. The patch > would teach VACUUM to skip doing any real index work within both > ambulkdelete() and amvacuumcleanup() in many important cases. > I agree to cut the scope. I've also been thinking about the impact of this patch on users. I also think we still have a lot of things to consider. For example, we need to consider and evaluate how incremental vacuum works for larger tuples or larger fillfactor, etc, and need to discuss more on the concept of leaving LP_DEAD in the space left by fillfactor is a good idea or not. Also, we need to discuss the changes in this patch to nbtree. Since the bottom-up index deletion is a new code for PG14, in a case where there is a problem in that, this feature could make things worse since this feature uses it. Perhaps we would need some safeguard and it also needs time. From that point of view, I think it’s a good idea to introduce these features to a different major version. Given the current situation, I agreed that 2 months is too short to do all things. > Here is a more detailed explanation: > > Today we can skip all significant work in ambulkdelete() and > amvacuumcleanup() when there are zero dead tuples in the table. But > why is the threshold *precisely* zero? If we could treat cases that > have "practically zero" dead tuples in the same way (or almost the > same way) as cases with *exactly* zero dead tuple, that's still a big > improvement. And it still sets an important precedent that is crucial > for the wider "incremental VACUUM" project: the criteria for > triggering index vacuuming becomes truly "fuzzy" for the first time. > It is "fuzzy" in the sense that index vacuuming might not happen > during VACUUM at all now, even when the user didn't explicitly use > VACUUUM's INDEX_CLEANUP option, and even when more than *precisely* > zero dead index tuples are involved (though not *much* more than zero, > can't be too aggressive). That really is a big change. > > A recap on vacuum_cleanup_index_scale_factor, just to avoid confusion: > > The reader should note that this is very different to Masahiko's > vacuum_cleanup_index_scale_factor project, which skips *cleanup* in > VACUUM (not bulk delete), a question which only comes up when there > are definitely zero dead index tuples. The unifying work I'm talking > about now implies that we completely avoid scanning indexes during > vacuum, even when they are known to have at least a few dead index > tuples, and even when VACUUM's INDEX_CLEANUP emergency option is not > in use. Which, as I just said, is a big change. If vacuum skips both ambulkdelete and amvacuumcleanup in that case, I'm concerned that this could increase users who are affected by the known issue of leaking deleted pages. Currently, users who are affected by that is only users who use INDEX_CLEANUP off. But if we enable this feature by default, all users potentially are affected by that issue. > > Thoughts on triggering criteria for new "unified" design, ~99.9% > append-only tables: > > Actually, in *one* sense the difference between "precisely zero" and > "practically zero" here *is* small. But it's still probably going to > result in skipping reading indexes during VACUUM in many important > cases. Like when you must VACUUM a table that is ~99.9% append-only. > In the real world things are rarely in exact discrete categories, even > when we imagine that they are. It's too easy to be wrong about one > tiny detail -- like one tiny UPDATE from 4 weeks ago, perhaps. Having > a tiny amount of "forgiveness" here is actually a *huge* improvement > on having precisely zero forgiveness. Small and big. > > This should help cases that get big surprising spikes due to > anti-wraparound vacuums that must vacuum indexes for the first time in > ages -- indexes may be vacuumed despite only having a tiny absolute > number of dead tuples. I don't think that it's necessary to treat > anti-wraparound vacuums as special at all (not in Postgres 14 and > probably not ever), because simply considering cases where the table > has "practically zero" dead tuples alone should be enough. Vacuuming a > 10GB index to delete only 10 tuples simply makes no sense. It doesn't > necessarily matter how we end up there, it just shouldn't happen. Yeah, doing bulkdelete to delete only 10 tuples makes no sense. It also dirties caches, which is bad. To improve index tuple deletion in that case, skipping bulkdelete is also a good idea whereas the retail index deletion is also a good solution. I have thought the retail index deletion would be appropriate to this case but since some index AM cannot support it skipping index scans is a good solution anyway. Given that autovacuum won't run on a table that has only 10 dead tuples, we can think that this case is likely an anti-wraparound case. So I think that skipping all index scans during VACUUM in only anti-wraparound case (and if the table has practically zero dead tuples) could also be an option. This would reduce the opportunity to skip index scans during vacuum but reduce the risk of leaking deleted pages in nbtree. > > The ~99.9% append-only table case is likely to be important and common > in the real world. We should start there for Postgres 14 because it's > easier, that's all. It's not fundamentally different to what happens > in workloads involving lots of bottom-up deletion -- it's just > simpler, and easier to reason about. Bottom-up deletion is an > important piece of the big puzzle here, but some variant of > "incremental VACUUM" really would still make sense in a world where > bottom-up index deletion does not exist. (In fact, I started thinking > about "incremental VACUUM" before bottom-up index deletion, and didn't > make any connection between them until work on bottom-up deletion had > already progressed significantly.) > > Here is how the triggering criteria could work: maybe skipping > accessing all indexes during VACUUM happens when less than 1% or > 10,000 of the items from the table are to be removed by VACUUM -- > whichever is greater. Of course this is just the first thing I thought > of. It's a starting point for further discussion. I also prefer your second idea :) > > My concerns won't be a surprise to you, Masahiko, but I'll list them > for the record. The bottom-up index deletion related complexity that I > want to avoid dealing with for Postgres 14 is in the following areas > (areas that Masahiko's patch dealt with): > > * No need to teach indexes to do the amvacuumstrategy() stuff in > Postgres 14 -- so no need to worry about the exact criteria used > within AMs like nbtree to determine whether or not index vacuuming > seems appropriate from the "selfish" perspective of one particular > index. > > I'm concerned that factors like bulk DELETEs, that may complicate > things for the amvacuumstrategy() routine -- doing something > relatively simple based on the recent growth of the index might have > downsides. Balancing competing considerations is hard. Agreed. > > * No need to change MaxHeapTuplesPerPage for now, since that only > really makes sense in cases that heavily involve bottom-up deletion, > where we care about the *concentration* of LP_DEAD line pointers in > heap pages (and not just the absolute number in the entire table), > which is qualitative, not quantitative (somewhat like bottom-up > deletion). > > The change to MaxHeapTuplesPerPage that Masahiko has proposed does > make sense -- there are good reasons to increase it. Of course there > are also good reasons to not do so. I'm concerned that we won't have > time to think through all the possible consequences. Agreed. > > * Since "practically zero" dead tuples from a table still isn't very > many, the risk of "leaking" many deleted pages due to a known issue > with INDEX_CLEANUP in nbtree [1] is much less significant. (FWIW I > doubt that skipping index vacuuming is the only way that we can fail > to recycle deleted pages anyway -- the FSM is not crash safe, of > course, plus I think that _bt_page_recyclable() might be broken in > other ways.) As I mentioned above, I'm still concerned that the extent of users who are affected by the issue of leaking deleted pages could get expanded. Currently, we don't have a way to detect how many index pages are leaked. If there are potential cases where many deleted pages are leaked this feature would make things worse. > > In short: we can cut scope and de-risk the patch for Postgres 14 by > following this plan, while still avoiding unnecessary index vacuuming > within VACUUM in certain important cases. The high-level goal for this > patch has always been to recognize that index vacuuming is basically > wasted effort in certain cases. Cutting scope here merely means > addressing the relatively easy cases first, where simple triggering > logic will clearly be effective. I still strongly believe in > "incremental VACUUM". > > What do you think of cutting scope like this for Postgres 14, > Masahiko? Sorry to change my mind, but I had to see the prototype to > come to this decision. I agreed to cut the scope for PG14. It would be good if we could improve index vacuum while cutting cut the scope for PG14 and not expanding the extent of the impact of this issue. Regards, -- Masahiko Sawada EDB: https://www.enterprisedb.com/
On Wed, Feb 3, 2021 at 8:18 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > I'm starting to think that the right short term goal should not > > directly involve bottom-up index deletion. We should instead return to > > the idea of "unifying" the vacuum_cleanup_index_scale_factor feature > > with the INDEX_CLEANUP feature, which is kind of where this whole idea > > started out at. This short term goal is much more than mere > > refactoring. It is still a whole new user-visible feature. The patch > > would teach VACUUM to skip doing any real index work within both > > ambulkdelete() and amvacuumcleanup() in many important cases. > > > > I agree to cut the scope. I've also been thinking about the impact of > this patch on users. It's probably also true that on balance users care more about the "~99.9% append-only table" case (as well as the HOT updates workload I brought up in response to Victor on February 2) than making VACUUM very sensitive to how well bottom-up deletion is working. Yes, it's annoying that VACUUM still wastes effort on indexes where bottom-up deletion alone can do all required garbage collection. But that's not going to be a huge surprise to users. Whereas the "~99.9% append-only table" case causes huge surprises to users -- users hate this kind of thing. > If vacuum skips both ambulkdelete and amvacuumcleanup in that case, > I'm concerned that this could increase users who are affected by the > known issue of leaking deleted pages. Currently, users who are > affected by that is only users who use INDEX_CLEANUP off. But if we > enable this feature by default, all users potentially are affected by > that issue. FWIW I think that it's unfair to blame INDEX_CLEANUP for any problems in this area. The truth is that the design of the deleted-page-recycling stuff has always caused leaked pages, even with workloads that should not be challenging to the implementation in any way. See my later remarks. > To improve index tuple deletion in that case, skipping bulkdelete is > also a good idea whereas the retail index deletion is also a good > solution. I have thought the retail index deletion would be > appropriate to this case but since some index AM cannot support it > skipping index scans is a good solution anyway. The big problem with retail index tuple deletion is that it is not possible once heap pruning takes place (opportunistic pruning, or pruning performed by VACUUM). Pruning will destroy the information that retail deletion needs to find the index tuple (the column values). I think that we probably will end up using retail index tuple deletion, but it will only be one strategy among several. We'll never be able to rely on it, even within nbtree. My personal opinion is that completely eliminating VACUUM is not a useful long term goal. > > Here is how the triggering criteria could work: maybe skipping > > accessing all indexes during VACUUM happens when less than 1% or > > 10,000 of the items from the table are to be removed by VACUUM -- > > whichever is greater. Of course this is just the first thing I thought > > of. It's a starting point for further discussion. > > I also prefer your second idea :) Cool. Yeah, I always like it when the potential downside of a design is obviously low, and the potential upside is obviously very high. I am much less concerned about any uncertainty around when and how users will get the big upside. I like it when my problems are "luxury problems". :-) > As I mentioned above, I'm still concerned that the extent of users who > are affected by the issue of leaking deleted pages could get expanded. > Currently, we don't have a way to detect how many index pages are > leaked. If there are potential cases where many deleted pages are > leaked this feature would make things worse. The existing problems here were significant even before you added INDEX_CLEANUP. For example, let's say VACUUM deletes a page, and then later recycles it in the normal/correct way -- this is the simplest possible case for page deletion. The page is now in the FSM, ready to be recycled during the next page split. Or is it? Even in this case there are no guarantees! This is because _bt_getbuf() does not fully trust the FSM to give it a 100% recycle-safe page for its page split caller -- _bt_getbuf() checks the page using _bt_page_recyclable() (which is the same check that VACUUM does to decide a deleted page is now recyclable). Obviously this means that the FSM can "leak" a page, just because there happened to be no page splits before wraparound occurred (and so now _bt_page_recyclable() thinks the very old page is very new/in the future). In general the recycling stuff feels ridiculously over engineered to me. It is true that page deletion is intrinsically complicated, and is worth having -- that makes sense to me. But the complexity of the recycling stuff seems ridiculous. There is only one sensible solution: follow the example of commit 6655a7299d8 in nbtree. This commit fully fixed exactly the same problem in GiST by storing an epoch alongside the XID. This nbtree fix is even anticipated by the commit message of 6655a7299d8. I can take care of this myself for Postgres 14. > I agreed to cut the scope for PG14. It would be good if we could > improve index vacuum while cutting cut the scope for PG14 and not > expanding the extent of the impact of this issue. Great! Well, if I take care of the _bt_page_recyclable() wraparound/epoch issue in a general kind of way then AFAICT there is no added risk. -- Peter Geoghegan
On Sat, Feb 6, 2021 at 5:02 AM Peter Geoghegan <pg@bowt.ie> wrote: > > On Wed, Feb 3, 2021 at 8:18 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > I'm starting to think that the right short term goal should not > > > directly involve bottom-up index deletion. We should instead return to > > > the idea of "unifying" the vacuum_cleanup_index_scale_factor feature > > > with the INDEX_CLEANUP feature, which is kind of where this whole idea > > > started out at. This short term goal is much more than mere > > > refactoring. It is still a whole new user-visible feature. The patch > > > would teach VACUUM to skip doing any real index work within both > > > ambulkdelete() and amvacuumcleanup() in many important cases. > > > > > > > I agree to cut the scope. I've also been thinking about the impact of > > this patch on users. > > It's probably also true that on balance users care more about the > "~99.9% append-only table" case (as well as the HOT updates workload I > brought up in response to Victor on February 2) than making VACUUM > very sensitive to how well bottom-up deletion is working. Yes, it's > annoying that VACUUM still wastes effort on indexes where bottom-up > deletion alone can do all required garbage collection. But that's not > going to be a huge surprise to users. Whereas the "~99.9% append-only > table" case causes huge surprises to users -- users hate this kind of > thing. Agreed. > > > If vacuum skips both ambulkdelete and amvacuumcleanup in that case, > > I'm concerned that this could increase users who are affected by the > > known issue of leaking deleted pages. Currently, users who are > > affected by that is only users who use INDEX_CLEANUP off. But if we > > enable this feature by default, all users potentially are affected by > > that issue. > > FWIW I think that it's unfair to blame INDEX_CLEANUP for any problems > in this area. The truth is that the design of the > deleted-page-recycling stuff has always caused leaked pages, even with > workloads that should not be challenging to the implementation in any > way. See my later remarks. > > > To improve index tuple deletion in that case, skipping bulkdelete is > > also a good idea whereas the retail index deletion is also a good > > solution. I have thought the retail index deletion would be > > appropriate to this case but since some index AM cannot support it > > skipping index scans is a good solution anyway. > > The big problem with retail index tuple deletion is that it is not > possible once heap pruning takes place (opportunistic pruning, or > pruning performed by VACUUM). Pruning will destroy the information > that retail deletion needs to find the index tuple (the column > values). Right. > > I think that we probably will end up using retail index tuple > deletion, but it will only be one strategy among several. We'll never > be able to rely on it, even within nbtree. My personal opinion is that > completely eliminating VACUUM is not a useful long term goal. Totally agreed. We are not able to rely on it. It would be a good way to delete small amount index garbage tuples but the usage is limited. > > > > Here is how the triggering criteria could work: maybe skipping > > > accessing all indexes during VACUUM happens when less than 1% or > > > 10,000 of the items from the table are to be removed by VACUUM -- > > > whichever is greater. Of course this is just the first thing I thought > > > of. It's a starting point for further discussion. > > > > I also prefer your second idea :) > > Cool. Yeah, I always like it when the potential downside of a design > is obviously low, and the potential upside is obviously very high. I > am much less concerned about any uncertainty around when and how users > will get the big upside. I like it when my problems are "luxury > problems". :-) > > > As I mentioned above, I'm still concerned that the extent of users who > > are affected by the issue of leaking deleted pages could get expanded. > > Currently, we don't have a way to detect how many index pages are > > leaked. If there are potential cases where many deleted pages are > > leaked this feature would make things worse. > > The existing problems here were significant even before you added > INDEX_CLEANUP. For example, let's say VACUUM deletes a page, and then > later recycles it in the normal/correct way -- this is the simplest > possible case for page deletion. The page is now in the FSM, ready to > be recycled during the next page split. Or is it? Even in this case > there are no guarantees! This is because _bt_getbuf() does not fully > trust the FSM to give it a 100% recycle-safe page for its page split > caller -- _bt_getbuf() checks the page using _bt_page_recyclable() > (which is the same check that VACUUM does to decide a deleted page is > now recyclable). Obviously this means that the FSM can "leak" a page, > just because there happened to be no page splits before wraparound > occurred (and so now _bt_page_recyclable() thinks the very old page is > very new/in the future). > > In general the recycling stuff feels ridiculously over engineered to > me. It is true that page deletion is intrinsically complicated, and is > worth having -- that makes sense to me. But the complexity of the > recycling stuff seems ridiculous. > > There is only one sensible solution: follow the example of commit > 6655a7299d8 in nbtree. This commit fully fixed exactly the same > problem in GiST by storing an epoch alongside the XID. This nbtree fix > is even anticipated by the commit message of 6655a7299d8. I can take > care of this myself for Postgres 14. Thanks. I think that's very good if we resolve this recycling stuff first then try the new approach to skip index vacuum in more cases. That way, even if the vacuum strategy stuff took a very long time to get committed over several major versions, we would not be affected by deleted nbtree page recycling problem (at least for built-in index AMs). Also, the approach of 6655a7299d8 itself is a good improvement and seems straightforward to me. > > > I agreed to cut the scope for PG14. It would be good if we could > > improve index vacuum while cutting cut the scope for PG14 and not > > expanding the extent of the impact of this issue. > > Great! Well, if I take care of the _bt_page_recyclable() > wraparound/epoch issue in a general kind of way then AFAICT there is > no added risk. Agreed! Regards, -- Masahiko Sawada EDB: https://www.enterprisedb.com/
On Tue, Feb 9, 2021 at 6:14 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > Thanks. I think that's very good if we resolve this recycling stuff > first then try the new approach to skip index vacuum in more cases. > That way, even if the vacuum strategy stuff took a very long time to > get committed over several major versions, we would not be affected by > deleted nbtree page recycling problem (at least for built-in index > AMs). Also, the approach of 6655a7299d8 itself is a good improvement > and seems straightforward to me. I'm glad that you emphasized this issue, because I came up with a solution that turns out to not be very invasive. At the same time it has unexpected advantages, liking improving amcheck coverage for deleted pages. -- Peter Geoghegan
On Mon, Mar 15, 2021 at 12:58 PM Peter Geoghegan <pg@bowt.ie> wrote: > > I'm not comfortable with this change without adding more safety > > checks. If there's ever a case in which the HEAPTUPLE_DEAD case is hit > > and the xid needs to be frozen, we'll either cause errors or > > corruption. Yes, that's already the case with params->index_cleanup == > > DISABLED, but that's not that widely used. > > I noticed that Noah's similar 2013 patch [1] added a defensive > heap_tuple_needs_freeze() + elog(ERROR) to the HEAPTUPLE_DEAD case. I > suppose that that's roughly what you have in mind here? I'm not sure if you're arguing that there might be (either now or in the future) a legitimate case (a case not involving data corruption) where we hit HEAPTUPLE_DEAD, and find we have an XID in the tuple that needs freezing. You seem to be suggesting that even throwing an error might not be acceptable, but what better alternative is there? Did you just mean that we should throw a *better*, more specific error right there, when we handle HEAPTUPLE_DEAD? (As opposed to relying on heap_prepare_freeze_tuple() to error out instead, which is what would happen today.) That seems like the most reasonable interpretation of your words to me. That is, I think that you're saying (based in part on remarks on that other thread [1]) that you believe that fully eliminating the "tupgone = true" special case is okay in principle, but that more hardening is needed -- if it ever breaks we want to hear about it. And, while it would be better to do a much broader refactor to unite heap_prune_chain() and lazy_scan_heap(), it is not essential (because the issue is not really new, even without VACUUM (INDEX_CLEANUP OFF)/"params->index_cleanup == DISABLED"). Which is it? [1] https://www.postgresql.org/message-id/20200724165514.dnu5hr4vvgkssf5p%40alap3.anarazel.de -- Peter Geoghegan
Hi,
On 2021-03-15 12:58:33 -0700, Peter Geoghegan wrote:
> On Mon, Mar 15, 2021 at 12:21 PM Andres Freund <andres@anarazel.de> wrote:
> > It's evil sorcery. Fragile sorcery. I think Robert, Tom and me all run
> > afoul of edge cases around it in the last few years.
>
> Right, which is why I thought that I might be missing something; why
> put up with that at all for so long?
>
> > > But removing the awful "tupgone = true" special case seems to buy us a
> > > lot -- it makes unifying everything relatively straightforward. In
> > > particular, it makes it possible to delay the decision to vacuum
> > > indexes until the last moment, which seems essential to making index
> > > vacuuming optional.
> >
> > You haven't really justified, in the patch or this email, why it's OK to
> > remove the whole logic around HEAPTUPLE_DEAD part of the logic.
>
> I don't follow.
>
> > VACUUM can take a long time, and not removing space for all the
> > transactions that aborted while it wa
>
> I guess that you trailed off here. My understanding is that removing
> the special case results in practically no loss of dead tuples removed
> in practice -- so there are no practical performance considerations
> here.
>
> Have I missed something?
Forget what I said above - I had intended to remove it after dislogding
something stuck in my brain... But apparently didn't :(. Sorry.
> > I'm not comfortable with this change without adding more safety
> > checks. If there's ever a case in which the HEAPTUPLE_DEAD case is hit
> > and the xid needs to be frozen, we'll either cause errors or
> > corruption. Yes, that's already the case with params->index_cleanup ==
> > DISABLED, but that's not that widely used.
>
> I noticed that Noah's similar 2013 patch [1] added a defensive
> heap_tuple_needs_freeze() + elog(ERROR) to the HEAPTUPLE_DEAD case. I
> suppose that that's roughly what you have in mind here?
I'm not sure that's sufficient. If the case is legitimately reachable
(I'm maybe 60% is not, after staring at it for a long time, but ...),
then we can't just error out when we didn't so far.
I kinda wonder whether this case should just be handled by just gotoing
back to the start of the blkno loop, and redoing the pruning. The only
thing that makes that a bit more complicatd is that we've already
incremented vacrelstats->{scanned_pages,vacrelstats->tupcount_pages}.
We really should put the per-page work (i.e. the blkno loop body) of
lazy_scan_heap() into a separate function, same with the
too-many-dead-tuples branch.
> Comments above heap_prepare_freeze_tuple() say something about making
> sure that HTSV did not return HEAPTUPLE_DEAD...but that's already
> possible today:
>
> * It is assumed that the caller has checked the tuple with
> * HeapTupleSatisfiesVacuum() and determined that it is not HEAPTUPLE_DEAD
> * (else we should be removing the tuple, not freezing it).
>
> Does that need work too?
I'm pretty scared of the index-cleanup-disabled path, for that reason. I
think the hot path is more likely to be unproblematic, but I'd not bet
my (nonexistant) farm on it.
Greetings,
Andres Freund
Hi, On 2021-03-15 13:58:02 -0700, Peter Geoghegan wrote: > On Mon, Mar 15, 2021 at 12:58 PM Peter Geoghegan <pg@bowt.ie> wrote: > > > I'm not comfortable with this change without adding more safety > > > checks. If there's ever a case in which the HEAPTUPLE_DEAD case is hit > > > and the xid needs to be frozen, we'll either cause errors or > > > corruption. Yes, that's already the case with params->index_cleanup == > > > DISABLED, but that's not that widely used. > > > > I noticed that Noah's similar 2013 patch [1] added a defensive > > heap_tuple_needs_freeze() + elog(ERROR) to the HEAPTUPLE_DEAD case. I > > suppose that that's roughly what you have in mind here? > > I'm not sure if you're arguing that there might be (either now or in > the future) a legitimate case (a case not involving data corruption) > where we hit HEAPTUPLE_DEAD, and find we have an XID in the tuple that > needs freezing. You seem to be suggesting that even throwing an error > might not be acceptable, but what better alternative is there? Did you > just mean that we should throw a *better*, more specific error right > there, when we handle HEAPTUPLE_DEAD? (As opposed to relying on > heap_prepare_freeze_tuple() to error out instead, which is what would > happen today.) Right now (outside of the index-cleanup-disabled path), we very well may just actually successfully and correctly do the deletion? So there clearly is another option? See my email from a few minutes ago for a somewhat crude idea for how to tackle the issue differently... Greetings, Andres Freund
On Mon, Mar 15, 2021 at 4:11 PM Andres Freund <andres@anarazel.de> wrote:
> > > I'm not comfortable with this change without adding more safety
> > > checks. If there's ever a case in which the HEAPTUPLE_DEAD case is hit
> > > and the xid needs to be frozen, we'll either cause errors or
> > > corruption. Yes, that's already the case with params->index_cleanup ==
> > > DISABLED, but that's not that widely used.
> >
> > I noticed that Noah's similar 2013 patch [1] added a defensive
> > heap_tuple_needs_freeze() + elog(ERROR) to the HEAPTUPLE_DEAD case. I
> > suppose that that's roughly what you have in mind here?
>
> I'm not sure that's sufficient. If the case is legitimately reachable
> (I'm maybe 60% is not, after staring at it for a long time, but ...),
> then we can't just error out when we didn't so far.
If you're only 60% sure that the heap_tuple_needs_freeze() error thing
doesn't break anything that should work by now then it seems unlikely
that you'll ever get past 90% sure. I think that we should make a
conservative assumption that the defensive elog(ERROR) won't be
sufficient, and proceed on that basis.
> I kinda wonder whether this case should just be handled by just gotoing
> back to the start of the blkno loop, and redoing the pruning. The only
> thing that makes that a bit more complicatd is that we've already
> incremented vacrelstats->{scanned_pages,vacrelstats->tupcount_pages}.
That seems like a good solution to me -- this is a very seldom hit
path, so we can be a bit inefficient without it mattering.
It might make sense to *also* check some things (maybe using
heap_tuple_needs_freeze()) in passing, just for debugging purposes.
> We really should put the per-page work (i.e. the blkno loop body) of
> lazy_scan_heap() into a separate function, same with the
> too-many-dead-tuples branch.
+1.
BTW I've noticed that the code (and code like it) tends to confuse
things that the current VACUUM performed versus things by *some*
VACUUM (that may or may not be current one). This refactoring might be
a good opportunity to think about that as well.
> > * It is assumed that the caller has checked the tuple with
> > * HeapTupleSatisfiesVacuum() and determined that it is not HEAPTUPLE_DEAD
> > * (else we should be removing the tuple, not freezing it).
> >
> > Does that need work too?
>
> I'm pretty scared of the index-cleanup-disabled path, for that reason. I
> think the hot path is more likely to be unproblematic, but I'd not bet
> my (nonexistant) farm on it.
Well if we can solve the problem by simply doing pruning once again in
the event of a HEAPTUPLE_DEAD return value from the lazy_scan_heap()
HTSV call, then the comment becomes 100% true (which is not the case
even today).
--
Peter Geoghegan
On Wed, Mar 17, 2021 at 7:21 AM Peter Geoghegan <pg@bowt.ie> wrote: > > On Tue, Mar 16, 2021 at 6:40 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > Note that I've merged multiple existing functions in vacuumlazy.c into > > > one: the patch merges lazy_vacuum_all_indexes() and lazy_vacuum_heap() > > > into a single function named vacuum_indexes_mark_unused() > > > I agree to create a function like vacuum_indexes_mark_unused() that > > makes a decision and does index and heap vacumming accordingly. But > > what is the point of removing both lazy_vacuum_all_indexes() and > > lazy_vacuum_heap()? I think we can simply have > > vacuum_indexes_mark_unused() call those functions. I'm concerned that > > if we add additional criteria to vacuum_indexes_mark_unused() in the > > future the function will become very large. > > I agree now. I became overly excited about advertising the fact that > these two functions are logically one thing. This is important, but it > isn't necessary to go as far as actually making everything into one > function. Adding some comments would also make that point clear, but > without making vacuumlazy.c even more spaghetti-like. I'll fix it. > > > > I wonder if we can add some kind of emergency anti-wraparound vacuum > > > logic to what I have here, for Postgres 14. > > > +1 > > > > I think we can set VACOPT_TERNARY_DISABLED to > > tab->at_params.index_cleanup in table_recheck_autovac() or increase > > the thresholds used to not skipping index vacuuming. > > I was worried about the "tupgone = true" special case causing problems > when we decide to do some index vacuuming and some heap > vacuuming/LP_UNUSED-marking but then later decide to end the VACUUM. > But I now think that getting rid of "tupgone = true" gives us total > freedom to > choose what to do, including the freedom to start with index vacuuming > and then give up on it later -- even after we do some amount of > LP_UNUSED-marking (during a VACUUM with multiple index passes, perhaps > due to a low maintenance_work_mem setting). That isn't actually > special at all, because everything will be 100% decoupled. > > Whether or not it's a good idea to either not start index vacuuming or > to end it early (e.g. due to XID wraparound pressure) is a complicated > question, and the right approach will be debatable in each case/when > thinking about each issue. However, deciding on the best behavior to > address these problems should have nothing to do with implementation > details and everything to do with the costs and benefits to users. > Which now seems possible. > > A sophisticated version of the "XID wraparound pressure" > implementation could increase reliability without ever being > conservative, just by evaluating the situation regularly and being > prepared to change course when necessary -- until it is truly a matter > of shutting down new XID allocations/the server. It should be possible > to decide to end VACUUM early and advance relfrozenxid (provided we > have reached the point of finishing all required pruning and freezing, > of course). Highly agile behavior seems quite possible, even if it > takes a while to agree on a good design. Since I was thinking that always skipping index vacuuming on anti-wraparound autovacuum is legitimate, skipping index vacuuming only when we're really close to the point of going into read-only mode seems a bit conservative, but maybe a good start. I've attached a PoC patch to disable index vacuuming if the table's relfrozenxid is too older than autovacuum_freeze_max_age (older than 1.5x of autovacuum_freeze_max_age). > > > Aside from whether it's good or bad, strictly speaking, it could > > change the index AM API contract. The documentation of > > amvacuumcleanup() says: > > > > --- > > stats is whatever the last ambulkdelete call returned, or NULL if > > ambulkdelete was not called because no tuples needed to be deleted. > > --- > > > > With this change, we could pass NULL to amvacuumcleanup even though > > the index might have tuples needed to be deleted. > > I think that we should add a "Note" box to the documentation that > notes the difference here. Though FWIW my interpretation of the words > "no tuples needed to be deleted" was always "no tuples needed to be > deleted because vacuumlazy.c didn't call ambulkdelete()". After all, > VACUUM can add to tups_vacuumed through pruning inside > heap_prune_chain(). It is already possible (though only barely) to not > call ambulkdelete() for indexes (to only call amvacuumcleanup() during > cleanup) despite the fact that heap vacuuming did "delete tuples". Agreed. Regards, -- Masahiko Sawada EDB: https://www.enterprisedb.com/
Вложения
On Mon, Mar 15, 2021 at 4:11 PM Andres Freund <andres@anarazel.de> wrote:
> I kinda wonder whether this case should just be handled by just gotoing
> back to the start of the blkno loop, and redoing the pruning. The only
> thing that makes that a bit more complicatd is that we've already
> incremented vacrelstats->{scanned_pages,vacrelstats->tupcount_pages}.
>
> We really should put the per-page work (i.e. the blkno loop body) of
> lazy_scan_heap() into a separate function, same with the
> too-many-dead-tuples branch.
Attached patch series splits everything up. There is now a large patch
that removes the tupgone special case, and a second patch that
actually adds code that dynamically decides to not do index vacuuming
in cases where (for whatever reason) it doesn't seem useful.
Here are some key points about the first patch:
* Eliminates the "tupgone = true" special case by putting pruning, the
HTSV() call, as well as tuple freezing into a new, dedicated function
-- the function is prepared to restart pruning in those rare cases
where the vacuumlazy.c HTSV() call indicates that a tuple is dead.
Restarting pruning again prunes again, rendering the DEAD tuple with
storage an LP_DEAD line pointer stub.
The restart thing is based on Andres' suggestion.
This patch enables incremental VACUUM (the second patch, and likely
other variations) by allowing us to make a uniform assumption that it
is never strictly necessary to reach lazy_vacuum_all_indexes() or
lazy_vacuum_heap(). It is now possible to "end VACUUM early" while
still advancing relfrozenxid. Provided we've finished the first scan
of the heap, that should be safe.
* In principle we could visit and revisit the question of whether or
not vacuuming should continue or end early many times, as new
information comes to light. For example, maybe Masahiko's patch from
today could be taught to monitor how old relfrozenxid is again and
again, before finally giving up early when the risk of wraparound
becomes very severe -- but not before then.
* I've added three structs that replace a blizzard of local variables
we used lazy_scan_heap() with just three (three variables for each of
the three structs). I've also moved several chunks of logic to other
new functions (in addition to one that does pruning and freezing).
I think that I have the data structures roughly right here -- but I
would appreciate some feedback on that. Does this seem like the right
direction?
--
Peter Geoghegan
Вложения
On Wed, Mar 17, 2021 at 7:16 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > Since I was thinking that always skipping index vacuuming on > anti-wraparound autovacuum is legitimate, skipping index vacuuming > only when we're really close to the point of going into read-only mode > seems a bit conservative, but maybe a good start. I've attached a PoC > patch to disable index vacuuming if the table's relfrozenxid is too > older than autovacuum_freeze_max_age (older than 1.5x of > autovacuum_freeze_max_age). Most anti-wraparound VACUUMs are really not emergencies, though. So treating them as special simply because they're anti-wraparound vacuums doesn't seem like the right thing to do. I think that we should dynamically decide to do this when (antiwraparound) VACUUM has already been running for some time. We need to delay the decision until it is almost certainly true that we really have an emergency. Can you take what you have here, and make the decision dynamic? Delay it until we're done with the first heap scan? This will require rebasing on top of the patch I posted. And then adding a third patch, a little like the second patch -- but not too much like it. In the second/SKIP_VACUUM_PAGES_RATIO patch I posted today, the function two_pass_strategy() (my new name for the main entry point for calling lazy_vacuum_all_indexes() and lazy_vacuum_heap()) is only willing to perform the "skip index vacuuming" optimization when the call to two_pass_strategy() is the first call and the last call for that entire VACUUM (plus we test the number of heap blocks with LP_DEAD items using SKIP_VACUUM_PAGES_RATIO, of course). It works this way purely because I don't think that we should be aggressive when we've already run out of maintenance_work_mem. That's a bad time to apply a performance optimization. But what you're talking about now isn't a performance optimization (the mechanism is similar or the same, but the underlying reasons are totally different) -- it's a safety/availability thing. I don't think that you need to be concerned about running out of maintenance_work_mem in two_pass_strategy() when applying logic that is concerned about keeping the database online by avoiding XID wraparound. You just need to have high confidence that it is a true emergency. I think that we can be ~99% sure that we're in a real emergency by using dynamic information about how old relfrozenxid is *now*, and by rechecking a few times during VACUUM. Probably by rechecking every time we call two_pass_strategy(). I now believe that there is no fundamental correctness issue with teaching two_pass_strategy() to skip index vacuuming when we're low on memory -- it is 100% a matter of costs and benefits. The core skip-index-vacuuming mechanism is very flexible. If we can be sure that it's a real emergency, I think that we can justify behaving very aggressively (letting indexes get bloated is after all very aggressive). We just need to be 99%+ sure that continuing with vacuuming will be worse that ending vacuuming. Which seems possible by making the decision dynamic (and revisiting it at least a few times during a very long VACUUM, in case things change). -- Peter Geoghegan
On Thu, Mar 18, 2021 at 12:23 PM Peter Geoghegan <pg@bowt.ie> wrote: > > On Wed, Mar 17, 2021 at 7:16 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > Since I was thinking that always skipping index vacuuming on > > anti-wraparound autovacuum is legitimate, skipping index vacuuming > > only when we're really close to the point of going into read-only mode > > seems a bit conservative, but maybe a good start. I've attached a PoC > > patch to disable index vacuuming if the table's relfrozenxid is too > > older than autovacuum_freeze_max_age (older than 1.5x of > > autovacuum_freeze_max_age). > > Most anti-wraparound VACUUMs are really not emergencies, though. So > treating them as special simply because they're anti-wraparound > vacuums doesn't seem like the right thing to do. I think that we > should dynamically decide to do this when (antiwraparound) VACUUM has > already been running for some time. We need to delay the decision > until it is almost certainly true that we really have an emergency. That's a good idea to delay the decision until two_pass_strategy(). > > Can you take what you have here, and make the decision dynamic? Delay > it until we're done with the first heap scan? This will require > rebasing on top of the patch I posted. And then adding a third patch, > a little like the second patch -- but not too much like it. Attached the updated patch that can be applied on top of your v3 patches. Regards, -- Masahiko Sawada EDB: https://www.enterprisedb.com/
Вложения
On Wed, Mar 17, 2021 at 11:23 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > Attached the updated patch that can be applied on top of your v3 patches. Some feedback on this: * I think that we can afford to be very aggressive here, because we're checking dynamically. And we're concerned about extremes only. So an age of as high as 1 billion transactions seems like a better approach. What do you think? * I think that you need to remember that we have decided not to do any more index vacuuming, rather than calling check_index_cleanup_xid_limit() each time -- maybe store that information in a state variable. This seems like a good idea because we should try to avoid changing back to index vacuuming having decided to skip it once. Also, we need to refer to this in lazy_scan_heap(), so that we avoid index cleanup having also avoided index vacuuming. This is like the INDEX_CLEANUP = off case, which is also only for emergencies. It is not like the SKIP_VACUUM_PAGES_RATIO case, which is just an optimization. Thanks -- Peter Geoghegan
On Thu, Mar 18, 2021 at 3:41 PM Peter Geoghegan <pg@bowt.ie> wrote: > > On Wed, Mar 17, 2021 at 11:23 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > Attached the updated patch that can be applied on top of your v3 patches. > > Some feedback on this: > > * I think that we can afford to be very aggressive here, because we're > checking dynamically. And we're concerned about extremes only. So an > age of as high as 1 billion transactions seems like a better approach. > What do you think? If we have the constant threshold of 1 billion transactions, a vacuum operation might not be an anti-wraparound vacuum and even not be an aggressive vacuum, depending on autovacuum_freeze_max_age value. Given the purpose of skipping index vacuuming in this case, I think it doesn't make sense to have non-aggressive vacuum skip index vacuuming since it might not be able to advance relfrozenxid. If we have a constant threshold, 2 billion transactions, maximum value of autovacuum_freeze_max_age, seems to work. > > * I think that you need to remember that we have decided not to do any > more index vacuuming, rather than calling > check_index_cleanup_xid_limit() each time -- maybe store that > information in a state variable. > > This seems like a good idea because we should try to avoid changing > back to index vacuuming having decided to skip it once. Once decided to skip index vacuuming due to too old relfrozenxid stuff, the decision never be changed within the same vacuum operation, right? Because the relfrozenxid is advanced at the end of vacuum. > Also, we need > to refer to this in lazy_scan_heap(), so that we avoid index cleanup > having also avoided index vacuuming. This is like the INDEX_CLEANUP = > off case, which is also only for emergencies. It is not like the > SKIP_VACUUM_PAGES_RATIO case, which is just an optimization. Agreed with this point. I'll fix it in the next version patch. Regards, -- Masahiko Sawada EDB: https://www.enterprisedb.com/
On Thu, Mar 18, 2021 at 3:32 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > If we have the constant threshold of 1 billion transactions, a vacuum > operation might not be an anti-wraparound vacuum and even not be an > aggressive vacuum, depending on autovacuum_freeze_max_age value. Given > the purpose of skipping index vacuuming in this case, I think it > doesn't make sense to have non-aggressive vacuum skip index vacuuming > since it might not be able to advance relfrozenxid. If we have a > constant threshold, 2 billion transactions, maximum value of > autovacuum_freeze_max_age, seems to work. I like the idea of not making the behavior a special thing that only happens with a certain variety of VACUUM operation (non-aggressive or anti-wraparound VACUUMs). Just having a very high threshold should be enough. Even if we're not going to be able to advance relfrozenxid, we'll still finish much earlier and let a new anti-wraparound vacuum take place that will do that -- and will be able to reuse much of the work of the original VACUUM. Of course this anti-wraparound vacuum will also skip index vacuuming from the start (whereas the first VACUUM may well have done some index vacuuming before deciding to end index vacuuming to hurry with finishing). There is a risk in having the limit be too high, though. We need to give VACUUM time to reach two_pass_strategy() to notice the problem and act (maybe each call to lazy_vacuum_all_indexes() takes a long time). Also, while it's possible (any perhaps even likely) that cases that use this emergency mechanism will be able to end the VACUUM immediately (because there is enough maintenance_work_mem() to make the first call to two_pass_strategy() also the last call), that won't always be how it works. Even deciding to stop index vacuuming (and heap vacuuming) may not be enough to avert disaster if left too late -- because we may still have to do a lot of table pruning. In cases where there is not nearly enough maintenance_work_mem we will get through the table a lot faster once we decide to skip indexes, but there is some risk that even this will not be fast enough. How about 1.8 billion XIDs? That's the maximum value of autovacuum_freeze_max_age (2 billion) minus the default value (200 million). That is high enough that it seems almost impossible for this emergency mechanism to hurt rather than help. At the same time it is not so high that there isn't some remaining time to finish off work which is truly required. > > This seems like a good idea because we should try to avoid changing > > back to index vacuuming having decided to skip it once. > > Once decided to skip index vacuuming due to too old relfrozenxid > stuff, the decision never be changed within the same vacuum operation, > right? Because the relfrozenxid is advanced at the end of vacuum. I see no reason why it would be fundamentally incorrect to teach two_pass_strategy() to make new and independent decisions about doing index vacuuming on each call. I just don't think that that makes any sense to do so, practically speaking. Why would we even *want* to decide to not do index vacuuming, and then change our mind about it again (resume index vacuuming again, for later heap blocks)? That sounds a bit too much like me! There is another reason to never go back to index vacuuming: we should have an ereport() at the point that we decide to not do index vacuuming (or not do additional index vacuuming) inside two_pass_strategy(). This should deliver an unpleasant message to the DBA. The message is (in my own informal language): An emergency failsafe mechanism made VACUUM skip index vacuuming, just to avoid likely XID wraparound failure. This is not supposed to happen. Consider tuning autovacuum settings, especially if you see this message regularly. Obviously the reason to delay the decision is that we cannot easily predict how long any given VACUUM will take (or just to reach two_pass_strategy()). Nor can we really hope to understand how many XIDs will be consumed in that time. So rather than trying to understand all that, we can instead just wait until we have reliable information. It is true that the risk of waiting until it's too late to avert disaster exists (which is why 1.8 billion XIDs seems like a good threshold to me), but there is only so much we can do about that. We don't need it to be perfect, just much better. In my experience, anti-wraparound VACUUM scenarios all have an "accident chain", which is a concept from the world of aviation and safety-critical systems: https://en.wikipedia.org/wiki/Chain_of_events_(accident_analysis) They usually involve some *combination* of Postgres problems, application code problems, and DBA error. Not any one thing. I've seen problems with application code that runs DDL at scheduled intervals, which interacts badly with vacuum -- but only really on the rare occasions when freezing is required! I've also seen a buggy hand-written upsert function that artificially burned through XIDs at a furious pace. So we really want this mechanism to not rely on the system being in its typical state, if at all possible. When index vacuuming is skipped due to concerns about XID wraparound, it should really be a rare emergency that is a rare and unpleasant surprise to the DBA. Nobody should rely on this mechanism consistently. -- Peter Geoghegan
On Wed, Mar 17, 2021 at 11:23 PM Peter Geoghegan <pg@bowt.ie> wrote: > Most anti-wraparound VACUUMs are really not emergencies, though. That's true, but it's equally true that most of the time it's not necessary to wear a seatbelt to avoid personal injury. The difficulty is that it's hard to predict on which occasions it is necessary, and therefore it is advisable to do it all the time. autovacuum decides whether an emergency exists, in the first instance, by comparing age(relfrozenxid) to autovacuum_freeze_max_age, but that's problematic for at least two reasons. First, what matters is not when the vacuum starts, but when the vacuum finishes. A user who has no tables larger than 100MB can set autovacuum_freeze_max_age a lot closer to the high limit without risk of hitting it than a user who has a 10TB table. The time to run vacuum is dependent on both the size of the table and the applicable cost delay settings, none of which autovacuum knows anything about. It also knows nothing about the XID consumption rate. It's relying on the user to set autovacuum_freeze_max_age low enough that all the anti-wraparound vacuums will finish before the system crashes into a wall. Second, what happens to one table affects what happens to other tables. Even if you have perfect knowledge of your XID consumption rate and the speed at which vacuum will complete, you can't just configure autovacuum_freeze_max_age to allow exactly enough time for the vacuum to complete once it hits the threshold, unless you have one autovacuum worker per table so that the work for that table never has to wait for work on any other tables. And even then, as you mention, you have to worry about the possibility that a vacuum was already in progress on that table itself. Here again, we rely on the user to know empirically how high they can set autovacuum_freeze_max_age without cutting it too close. Now, that's not actually a good thing, because most users aren't smart enough to do that, and will either leave a gigantic safety margin that they don't need, or will leave an inadequate safety margin and take the system down. However, it means we need to be very, very careful about hard-coded thresholds like 90% of the available XID space. I do think that there is a case for triggering emergency extra safety measures when things are looking scary. One that I think would help a tremendous amount is to start ignoring the vacuum cost delay when wraparound danger (and maybe even bloat danger) starts to loom. Perhaps skipping index vacuuming is another such measure, though I suspect it would help fewer people, because in most of the cases I see, the system is throttled to use a tiny percentage of its actual hardware capability. If you're running at 1/5 of the speed of which the hardware is capable, you can only do better by skipping index cleanup if that skips more than 80% of page accesses, which could be true but probably isn't. In reality, I think we probably want both mechanisms, because they complement each other. If one can save 3X and the other 4X, the combination is a 12X improvement, which is a big deal. We might want other things, too. But ... should the thresholds for triggering these kinds of mechanisms really be hard-coded with no possibility of being configured in the field? What if we find out after the release is shipped that the mechanism works better if you make it kick in sooner, or later, or if it depends on other things about the system, which I think it almost certainly does? Thresholds that can't be changed without a recompile are bad news. That's why we have GUCs. On another note, I cannot say enough bad things about the function name two_pass_strategy(). I sincerely hope that you're not planning to create a function which is a major point of control for VACUUM whose name gives no hint that it has anything to do with vacuum. -- Robert Haas EDB: http://www.enterprisedb.com
On Thu, Mar 18, 2021 at 2:05 PM Robert Haas <robertmhaas@gmail.com> wrote: > On Wed, Mar 17, 2021 at 11:23 PM Peter Geoghegan <pg@bowt.ie> wrote: > > Most anti-wraparound VACUUMs are really not emergencies, though. > > That's true, but it's equally true that most of the time it's not > necessary to wear a seatbelt to avoid personal injury. The difficulty > is that it's hard to predict on which occasions it is necessary, and > therefore it is advisable to do it all the time. Just to be clear: This was pretty much the point I was making here -- although I guess you're making the broader point about autovacuum and freezing in general. The fact that we can *continually* reevaluate if an ongoing VACUUM is at risk of taking too long is entirely the point here. We can in principle end index vacuuming dynamically, whenever we feel like it and for whatever reasons occur to us (hopefully these are good reasons -- the point is that we get to pick and choose). We can afford to be pretty aggressive about not giving up, while still having the benefit of doing that when it *proves* necessary. Because: what are the chances of the emergency mechanism ending index vacuuming being the wrong thing to do if we only do that when the system clearly and measurably has no more than about 10% of the possible XID space to go before the system becomes unavailable for writes? What could possibly matter more than that? By making the decision dynamic, the chances of our threshold/heuristics causing the wrong behavior become negligible -- even though we're making the decision based on a tiny amount of (current, authoritative) information. The only novel risk I can think about is that somebody comes to rely on the mechanism saving the day, over and over again, rather than fixing a fixable problem. > autovacuum decides > whether an emergency exists, in the first instance, by comparing > age(relfrozenxid) to autovacuum_freeze_max_age, but that's problematic > for at least two reasons. First, what matters is not when the vacuum > starts, but when the vacuum finishes. To be fair the vacuum_set_xid_limits() mechanism that you refer to makes perfect sense. It's just totally insufficient for the reasons you say. > A user who has no tables larger > than 100MB can set autovacuum_freeze_max_age a lot closer to the high > limit without risk of hitting it than a user who has a 10TB table. The > time to run vacuum is dependent on both the size of the table and the > applicable cost delay settings, none of which autovacuum knows > anything about. It also knows nothing about the XID consumption rate. > It's relying on the user to set autovacuum_freeze_max_age low enough > that all the anti-wraparound vacuums will finish before the system > crashes into a wall. Literally nobody on earth knows what their XID burn rate is when it really matters. It might be totally out of control that one day of your life where it truly matters (e.g., due to a recent buggy code deployment, which I've seen up close). That's how emergencies work. A dynamic approach is not merely preferable. It seems essential. No top-down plan is going to be smart enough to predict that it'll take a really long time to get that one super-exclusive lock on relatively few pages. > Second, what happens to one table affects what > happens to other tables. Even if you have perfect knowledge of your > XID consumption rate and the speed at which vacuum will complete, you > can't just configure autovacuum_freeze_max_age to allow exactly enough > time for the vacuum to complete once it hits the threshold, unless you > have one autovacuum worker per table so that the work for that table > never has to wait for work on any other tables. And even then, as you > mention, you have to worry about the possibility that a vacuum was > already in progress on that table itself. Here again, we rely on the > user to know empirically how high they can set > autovacuum_freeze_max_age without cutting it too close. But the VM is a lot more useful when you effectively eliminate index vacuuming from the picture. And VACUUM has a pretty good understanding of how that works. Index vacuuming remains the achilles' heel, and I think that avoiding it in some cases has tremendous value. It has outsized importance now because we've significantly ameliorated the problems in the heap, by having the visibility map. What other factor can make VACUUM take 10x longer than usual on occasion? Autovacuum scheduling is essentially a top-down model of the needs of the system -- and one with a lot of flaws. IMV we can make the model's simplistic view of reality better by making the reality better (i.e. simpler, more tolerant of stressors) instead of making the model better. > Now, that's not actually a good thing, because most users aren't smart > enough to do that, and will either leave a gigantic safety margin that > they don't need, or will leave an inadequate safety margin and take > the system down. However, it means we need to be very, very careful > about hard-coded thresholds like 90% of the available XID space. I do > think that there is a case for triggering emergency extra safety > measures when things are looking scary. One that I think would help a > tremendous amount is to start ignoring the vacuum cost delay when > wraparound danger (and maybe even bloat danger) starts to loom. We've done a lot to ameliorate that problem in recent releases, simply by updating the defaults. > Perhaps skipping index vacuuming is another such measure, though I > suspect it would help fewer people, because in most of the cases I > see, the system is throttled to use a tiny percentage of its actual > hardware capability. If you're running at 1/5 of the speed of which > the hardware is capable, you can only do better by skipping index > cleanup if that skips more than 80% of page accesses, which could be > true but probably isn't. The proper thing for VACUUM to be throttled on these days is dirtying pages. Skipping index vacuuming and skipping the second pass over the heap will both make an enormous difference in many cases, precisely because they'll avoid dirtying nearly so many pages. Especially in the really bad cases, which are precisely where we see problems. Think about how many pages you'll dirty with a UUID-based index with regular churn from updates. Plus indexes don't have a visibility map. Whereas an append-mostly pattern is common with the largest tables. Perhaps it doesn't matter, but FWIW I think that you're drastically underestimating the extent to which index vacuuming is now the problem, in a certain important sense. I think that skipping index vacuuming and heap vacuuming (i.e. just doing the bare minimum, pruning) will in fact reduce the number of page accesses by 80% in many many cases. But I suspect it makes an even bigger difference in the cases where users are at most risk of wraparound related outages to begin with. ISTM that you're focussing too much on the everyday cases, the majority, which are not the cases where everything truly falls apart. The extremes really matter. Index vacuuming gets really slow when we're low on maintenance_work_mem -- horribly slow. Whereas that doesn't matter at all if you skip indexes. What do you think are the chances that that was a major factor in those sites that actually had an outage in the end? My intuition is that eliminating worst-case variability is the really important thing here. Heap vacuuming just doesn't have that multiplicative quality. Its costs tend to be proportionate to the workload, and stable over time. > But ... should the thresholds for triggering these kinds of mechanisms > really be hard-coded with no possibility of being configured in the > field? What if we find out after the release is shipped that the > mechanism works better if you make it kick in sooner, or later, or if > it depends on other things about the system, which I think it almost > certainly does? Thresholds that can't be changed without a recompile > are bad news. That's why we have GUCs. I'm fine with a GUC, though only for the emergency mechanism. The default really matters, though -- it shouldn't be necessary to tune (since we're trying to address a problem that many people don't know they have until it's too late). I still like 1.8 billion XIDs as the value -- I propose that that be made the default. > On another note, I cannot say enough bad things about the function > name two_pass_strategy(). I sincerely hope that you're not planning to > create a function which is a major point of control for VACUUM whose > name gives no hint that it has anything to do with vacuum. You always hate my names for things. But that's fine by me -- I'm usually not very attached to them. I'm happy to change it to whatever you prefer. FWIW, that name was intended to highlight that VACUUMs with indexes will now always use the two-pass strategy. This is not to be confused with the one-pass strategy, which is now strictly used on tables with no indexes -- this even includes the INDEX_CLEANUP=off case with the patch. -- Peter Geoghegan
On Wed, Mar 17, 2021 at 7:55 PM Peter Geoghegan <pg@bowt.ie> wrote: > Attached patch series splits everything up. There is now a large patch > that removes the tupgone special case, and a second patch that > actually adds code that dynamically decides to not do index vacuuming > in cases where (for whatever reason) it doesn't seem useful. Attached is v4. This revision of the patch series is split up into smaller pieces for easier review. There are now 3 patches in the series: 1. A refactoring patch that takes code from lazy_scan_heap() and breaks it into several new functions. Not too many changes compared to the last revision here (mostly took things out and put them in the second patch). 2. A patch to remove the tupgone case. Severa new and interesting changes here -- see below. 3. The patch to optimize VACUUM by teaching it to skip index and heap vacuuming in certain cases where we only expect a very small benefit. No changes at all in the third patch. We now go further with removing unnecessary stuff in WAL records in the second patch. We also go further with simplifying heap page vacuuming more generally. I have invented a new record that is only used by heap page vacuuming. This means that heap page pruning and heap page vacuuming no longer share the same xl_heap_clean/XLOG_HEAP2_CLEAN WAL record (which is what they do today, on master). Rather, there are two records: * XLOG_HEAP2_PRUNE/xl_heap_prune -- actually just the new name for xl_heap_clean, renamed to reflect the fact that only pruning uses it. * XLOG_HEAP2_VACUUM/xl_heap_vacuum -- this one is truly new, though it's actually just a very primitive version of xl_heap_prune -- since of course heap page vacuuming is now so much simpler. I have also taught heap page vacuuming (not pruning) that it only needs a regular exclusive buffer lock -- there is no longer any need for a super-exclusive buffer lock. And, heap vacuuming/xl_heap_vacuum records don't deal with recovery conflicts. These two changes to heap vacuuming (not pruning) are not additional performance optimizations, at least to me. I did things this way in v4 because it just made sense. We don't require index vacuuming to use super-exclusive locks [1] in any kind of standard way, nor do we require index vacuuming to generate its own recovery conflicts (pruning is assumed to take care of all that in every index AM, bar none). So why would we continue to require heap vacuuming to do either of these things now? This patch is intended to make index vacuuming and heap vacuuming very similar. Not just because it facilitates work like the work in the third patch -- it also happens to make perfect sense. [1] It's true that sometimes index vacuuming uses super-exclusive locks, but that isn't essential and is probably bad and unnecessary in the case of nbtree. Note that GiST is fine with just an exclusive lock today, to give one example, even though gistvacuumpage() is based closely on nbtree's btvacuumpage() function. -- Peter Geoghegan
Вложения
On Thu, 18 Mar 2021 at 14:37, Peter Geoghegan <pg@bowt.ie> wrote: > They usually involve some *combination* of Postgres problems, > application code problems, and DBA error. Not any one thing. I've seen > problems with application code that runs DDL at scheduled intervals, > which interacts badly with vacuum -- but only really on the rare > occasions when freezing is required! What I've seen is an application that regularly ran ANALYZE on a table. This worked fine as long as vacuums took less than the interval between analyzes (in this case 1h) but once vacuum started taking longer than that interval autovacuum would cancel it every time due to the conflicting lock. That would have just continued until the wraparound vacuum which wouldn't self-cancel except that there was also a demon running which would look for sessions stuck on a lock and kill the blocker -- which included killing the wraparound vacuum. And yes, this demon is obviously a terrible idea but of course it was meant for killing buggy user queries. It wasn't expecting to find autovacuum jobs blocking things. The real surprise for that user was that VACUUM could be blocked by things that someone would reasonably want to run regularly like ANALYZE. -- greg
On Sun, Mar 21, 2021 at 1:24 AM Greg Stark <stark@mit.edu> wrote: > What I've seen is an application that regularly ran ANALYZE on a > table. This worked fine as long as vacuums took less than the interval > between analyzes (in this case 1h) but once vacuum started taking > longer than that interval autovacuum would cancel it every time due to > the conflicting lock. > > That would have just continued until the wraparound vacuum which > wouldn't self-cancel except that there was also a demon running which > would look for sessions stuck on a lock and kill the blocker -- which > included killing the wraparound vacuum. That's a new one! Though clearly it's an example of what I described. I do agree that sometimes the primary cause is the special rules for cancellations with anti-wraparound autovacuums. > And yes, this demon is obviously a terrible idea but of course it was > meant for killing buggy user queries. It wasn't expecting to find > autovacuum jobs blocking things. The real surprise for that user was > that VACUUM could be blocked by things that someone would reasonably > want to run regularly like ANALYZE. The infrastructure from my patch to eliminate the tupgone special case (the patch that fully decouples index and heap vacuuming from pruning and freezing) ought to enable smarter autovacuum cancellations. It should be possible to make "canceling" an autovacuum worker actually instruct the worker to consider the possibility of finishing off the VACUUM operation very quickly, by simply ending index vacuuming (and heap vacuuming). It should only be necessary to cancel when that strategy won't work out, because we haven't finished all required pruning and freezing yet -- which are the only truly essential tasks of any "successful" VACUUM operation. Maybe it would only be appropriate to do something like that for anti-wraparound VACUUMs, which, as you say, don't get cancelled when they block the acquisition of a lock (which is a sensible design, though only because of the specific risk of not managing to advance relfrozenxid). There wouldn't be a question of canceling an anti-wraparound VACUUM in the conventional sense with this mechanism. It would simply instruct the anti-wraparound VACUUM to finish as quickly as possible by skipping the indexes. Naturally the implementation wouldn't really need to consider whether that meant the anti-wraparound VACUUM could end almost immediately, or some time later -- the point is that it completes ASAP. -- Peter Geoghegan
On Sat, Mar 20, 2021 at 11:05 AM Peter Geoghegan <pg@bowt.ie> wrote:
>
> On Wed, Mar 17, 2021 at 7:55 PM Peter Geoghegan <pg@bowt.ie> wrote:
> > Attached patch series splits everything up. There is now a large patch
> > that removes the tupgone special case, and a second patch that
> > actually adds code that dynamically decides to not do index vacuuming
> > in cases where (for whatever reason) it doesn't seem useful.
>
> Attached is v4. This revision of the patch series is split up into
> smaller pieces for easier review. There are now 3 patches in the
> series:
Thank you for the patches!
>
> 1. A refactoring patch that takes code from lazy_scan_heap() and
> breaks it into several new functions.
>
> Not too many changes compared to the last revision here (mostly took
> things out and put them in the second patch).
I've looked at this 0001 patch and here are some review comments:
+/*
+ * scan_prune_page() -- lazy_scan_heap() pruning and freezing.
+ *
+ * Caller must hold pin and buffer cleanup lock on the buffer.
+ *
+ * Prior to PostgreSQL 14 there were very rare cases where lazy_scan_heap()
+ * treated tuples that still had storage after pruning as DEAD. That happened
+ * when heap_page_prune() could not prune tuples that were nevertheless deemed
+ * DEAD by its own HeapTupleSatisfiesVacuum() call. This created rare hard to
+ * test cases. It meant that there was no very sharp distinction between DEAD
+ * tuples and tuples that are to be kept and be considered for freezing inside
+ * heap_prepare_freeze_tuple(). It also meant that lazy_vacuum_page() had to
+ * be prepared to remove items with storage (tuples with tuple headers) that
+ * didn't get pruned, which created a special case to handle recovery
+ * conflicts.
+ *
+ * The approach we take here now (to eliminate all of this complexity) is to
+ * simply restart pruning in these very rare cases -- cases where a concurrent
+ * abort of an xact makes our HeapTupleSatisfiesVacuum() call disagrees with
+ * what heap_page_prune() thought about the tuple only microseconds earlier.
+ *
+ * Since we might have to prune a second time here, the code is structured to
+ * use a local per-page copy of the counters that caller accumulates. We add
+ * our per-page counters to the per-VACUUM totals from caller last of all, to
+ * avoid double counting.
Those comments should be a part of 0002 patch?
---
+ pc.num_tuples += 1;
+ ps->hastup = true;
+
+ /*
+ * Each non-removable tuple must be checked to
see if it needs
+ * freezing
+ */
+ if (heap_prepare_freeze_tuple(tuple.t_data,
+
RelFrozenXid, RelMinMxid,
+
FreezeLimit, MultiXactCutoff,
+
&frozen[nfrozen],
+
&tuple_totally_frozen))
+ frozen[nfrozen++].offset = offnum;
+
+ pc.num_tuples += 1;
+ ps->hastup = true;
pc.num_tuples is incremented twice. ps->hastup = true is also duplicated.
---
In step 7, with the patch, we save the freespace of the page and do
lazy_vacuum_page(). But should it be done in reverse?
---
+static void
+two_pass_strategy(Relation onerel, LVRelStats *vacrelstats,
+ Relation *Irel,
IndexBulkDeleteResult **indstats, int nindexes,
+ LVParallelState *lps,
VacOptTernaryValue index_cleanup)
How about renaming to vacuum_two_pass_strategy() or something to clear
this function is used to vacuum?
---
+ /*
+ * skipped index vacuuming. Make log report that
lazy_vacuum_heap
+ * would've made.
+ *
+ * Don't report tups_vacuumed here because it will be
zero here in
+ * common case where there are no newly pruned LP_DEAD
items for this
+ * VACUUM. This is roughly consistent with
lazy_vacuum_heap(), and
+ * the similar !useindex ereport() at the end of
lazy_scan_heap().
+ * Note, however, that has_dead_items_pages is # of
heap pages with
+ * one or more LP_DEAD items (could be from us or from another
+ * VACUUM), not # blocks scanned.
+ */
+ ereport(elevel,
+ (errmsg("\"%s\": INDEX_CLEANUP off
forced VACUUM to not totally remove %d pruned items",
+ vacrelstats->relname,
+
vacrelstats->dead_tuples->num_tuples)));
It seems that the comment needs to be updated.
>
> 2. A patch to remove the tupgone case.
>
> Severa new and interesting changes here -- see below.
>
> 3. The patch to optimize VACUUM by teaching it to skip index and heap
> vacuuming in certain cases where we only expect a very small benefit.
I’ll review the other two patches tomorrow.
>
> We now go further with removing unnecessary stuff in WAL records in
> the second patch. We also go further with simplifying heap page
> vacuuming more generally.
>
> I have invented a new record that is only used by heap page vacuuming.
> This means that heap page pruning and heap page vacuuming no longer
> share the same xl_heap_clean/XLOG_HEAP2_CLEAN WAL record (which is
> what they do today, on master). Rather, there are two records:
>
> * XLOG_HEAP2_PRUNE/xl_heap_prune -- actually just the new name for
> xl_heap_clean, renamed to reflect the fact that only pruning uses it.
>
> * XLOG_HEAP2_VACUUM/xl_heap_vacuum -- this one is truly new, though
> it's actually just a very primitive version of xl_heap_prune -- since
> of course heap page vacuuming is now so much simpler.
I didn't look at the 0002 patch in-depth but the main difference
between those two WAL records is that XLOG_HEAP2_PRUNE has the offset
numbers of unused, redirected, and dead whereas XLOG_HEAP2_VACUUM has
only the offset numbers of unused?
Regards,
--
Masahiko Sawada
EDB: https://www.enterprisedb.com/
On Thu, Mar 18, 2021 at 9:42 PM Peter Geoghegan <pg@bowt.ie> wrote: > The fact that we can *continually* reevaluate if an ongoing VACUUM is > at risk of taking too long is entirely the point here. We can in > principle end index vacuuming dynamically, whenever we feel like it > and for whatever reasons occur to us (hopefully these are good reasons > -- the point is that we get to pick and choose). We can afford to be > pretty aggressive about not giving up, while still having the benefit > of doing that when it *proves* necessary. Because: what are the > chances of the emergency mechanism ending index vacuuming being the > wrong thing to do if we only do that when the system clearly and > measurably has no more than about 10% of the possible XID space to go > before the system becomes unavailable for writes? I agree. I was having trouble before understanding exactly what you are proposing, but this makes sense to me and I agree it's a good idea. > > But ... should the thresholds for triggering these kinds of mechanisms > > really be hard-coded with no possibility of being configured in the > > field? What if we find out after the release is shipped that the > > mechanism works better if you make it kick in sooner, or later, or if > > it depends on other things about the system, which I think it almost > > certainly does? Thresholds that can't be changed without a recompile > > are bad news. That's why we have GUCs. > > I'm fine with a GUC, though only for the emergency mechanism. The > default really matters, though -- it shouldn't be necessary to tune > (since we're trying to address a problem that many people don't know > they have until it's too late). I still like 1.8 billion XIDs as the > value -- I propose that that be made the default. I'm not 100% sure whether we need a new GUC for this or not. I think that if by default this triggers at the 90% of the hard-shutdown limit, it would be unlikely, and perhaps unreasonable, for users to want to raise the limit. However, I wonder whether some users will want to lower the limit. Would it be reasonable for someone to want to trigger this at 50% or 70% of XID exhaustion rather than waiting until things get really bad? Also, one thing that I dislike about the current system is that, from a user perspective, when something goes wrong, nothing happens for a while and then the whole system goes bananas. It seems desirable to me to find ways of gradually ratcheting up the pressure, like cranking up the effective cost limit if we can somehow figure out that we're not keeping up. If, with your mechanism, there's an abrupt point when we switch from never doing this for any table to always doing this for every table, that might not be as good as something which does this "sometimes" and then, if that isn't enough to avoid disaster, does it "more," and eventually ramps up to doing it always, if trouble continues. I don't know whether that's possible here, or what it would look like, or even whether it's appropriate at all in this particular case, so I just offer it as food for thought. > > On another note, I cannot say enough bad things about the function > > name two_pass_strategy(). I sincerely hope that you're not planning to > > create a function which is a major point of control for VACUUM whose > > name gives no hint that it has anything to do with vacuum. > > You always hate my names for things. But that's fine by me -- I'm > usually not very attached to them. I'm happy to change it to whatever > you prefer. My taste in names may be debatable, but including the subsystem name in the function name seems like a pretty bare-minimum requirement, especially when the other words in the function name could refer to just about anything. -- Robert Haas EDB: http://www.enterprisedb.com
On Mon, Mar 22, 2021 at 7:05 AM Robert Haas <robertmhaas@gmail.com> wrote: > I agree. I was having trouble before understanding exactly what you > are proposing, but this makes sense to me and I agree it's a good > idea. Our ambition is for this to be one big multi-release umbrella project, with several individual enhancements that each deliver a user-visible benefit on their own. The fact that we're talking about a few things at once is confusing, but I think that you need a "grand bargain" kind of discussion for this. I believe that it actually makes sense to do it that way, difficult though it may be. Sometimes the goal is to improve performance, other times the goal is to improve robustness. Although the distinction gets blurry at the margins. If VACUUM was infinitely fast (say because of sorcery), then performance would bee *unbeatable* -- plus we'd never have to worry about anti-wraparound vacuums not completing in time! > I'm not 100% sure whether we need a new GUC for this or not. I think > that if by default this triggers at the 90% of the hard-shutdown > limit, it would be unlikely, and perhaps unreasonable, for users to > want to raise the limit. However, I wonder whether some users will > want to lower the limit. Would it be reasonable for someone to want to > trigger this at 50% or 70% of XID exhaustion rather than waiting until > things get really bad? I wanted to avoid inventing a GUC for the mechanism in the third patch (not the emergency mechanism we're discussing right now, which was posted separately by Masahiko). I think that a GUC to control skipping index vacuuming purely because there are very few index tuples to delete in indexes will become a burden before long. In particular, we should eventually be able to vacuum some indexes but not others (on the same table) based on the local needs of each index. As I keep pointing out, bottom-up index deletion has created a situation where there can be dramatically different needs among indexes on the same table -- it can literally prevent 100% of all page splits from version churn in those indexes that are never subject to logically changes from non-HOT updates. Whereas bottom-up index deletion does nothing for any index that is logically updated, for the obvious reason -- there is now frequently a sharp qualitative difference among indexes that vacuumlazy.c currently imagines have basically the same needs. Vacuuming these remaining indexes is a cost that users will actually understand and accept, too. But that has nothing to do with the emergency mechanism we're talking about right now. I actually like your idea of making the emergency mechanism a GUC. It's equivalent to index_cleanup, except that it is continuous and dynamic (not discrete and static). The fact that this GUC expresses what VACUUM should do in terms of the age of the target table's current relfrozenxid age (and nothing else) seems like exactly the right thing. As I said before: What else could possibly matter? So I don't see any risk of such a GUC becoming a burden. I also think that it's a useful knob to be able to tune. It's also going to help a lot with testing the feature. So let's have a GUC for that. > Also, one thing that I dislike about the current system is that, from > a user perspective, when something goes wrong, nothing happens for a > while and then the whole system goes bananas. It seems desirable to me > to find ways of gradually ratcheting up the pressure, like cranking up > the effective cost limit if we can somehow figure out that we're not > keeping up. If, with your mechanism, there's an abrupt point when we > switch from never doing this for any table to always doing this for > every table, that might not be as good as something which does this > "sometimes" and then, if that isn't enough to avoid disaster, does it > "more," and eventually ramps up to doing it always, if trouble > continues. I don't know whether that's possible here, or what it would > look like, or even whether it's appropriate at all in this particular > case, so I just offer it as food for thought. That is exactly the kind of thing that some future highly evolved version of the broader incremental/dynamic VACUUM design might do. Your thoughts about the effective delay/throttling lessening as conditions change is in line with the stuff that we're thinking of doing. Though I don't believe Masahiko and I have talked about the delay stuff specifically in any of our private discussions about it. I am a big believer in the idea that we should have a variety of strategies that are applied incrementally and dynamically, in response to an immediate local need (say at the index level). VACUUM should be able to organically figure out the best strategy (or combination of strategies) itself, over time. Sometimes it will be very important to recognize that most indexes have been able to use techniques like bottom-up index deletion, and so really don't need to be vacuumed at all. Other times the cost delay stuff will matter much more. Maybe it's both together, even. The system ought to discover the best approach dynamically. There will be tremendous variation across tables and over time -- much too much for anybody to predict and understand as a practical matter. The intellectually respectable term for what I'm describing is a complex system. My work on B-Tree index bloat led me to the idea that sometimes a variety of strategies can be the real strategy. Take the example of the benchmark that Victor Yegorov performed, which consisted of a queue-based workload with deletes, inserts, and updates, plus constantly holding snapshots for multiple minutes: https://www.postgresql.org/message-id/CAGnEbogATZS1mWMVX8FzZHMXzuDEcb10AnVwwhCtXtiBpg3XLQ@mail.gmail.com Bottom-up index deletion appeared to practically eliminate index bloat here. When we only had deduplication (without bottom-up deletion) the indexes still ballooned in size. But I don't believe that that's a 100% accurate account. I think that it's more accurate to characterize what we saw there as a case where deduplication and bottom-up deletion complemented each other to great effect. If deduplication can buy you time until the next page split (by reducing the space required for recently dead but not totally dead index tuples caused by version churn), and if bottom-up index deletion can avoid page splits (by deleting now-totally-dead index tuples), then we shouldn't be too surprised to see complementary effects. Though I have to admit that I was quite surprised at how true this was in the case of Victor's benchmark -- it worked very well with the workload, without any designer predicting or understanding anything specific. -- Peter Geoghegan
On Fri, Mar 19, 2021 at 3:36 AM Peter Geoghegan <pg@bowt.ie> wrote: > > On Thu, Mar 18, 2021 at 3:32 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > If we have the constant threshold of 1 billion transactions, a vacuum > > operation might not be an anti-wraparound vacuum and even not be an > > aggressive vacuum, depending on autovacuum_freeze_max_age value. Given > > the purpose of skipping index vacuuming in this case, I think it > > doesn't make sense to have non-aggressive vacuum skip index vacuuming > > since it might not be able to advance relfrozenxid. If we have a > > constant threshold, 2 billion transactions, maximum value of > > autovacuum_freeze_max_age, seems to work. > > I like the idea of not making the behavior a special thing that only > happens with a certain variety of VACUUM operation (non-aggressive or > anti-wraparound VACUUMs). Just having a very high threshold should be > enough. > > Even if we're not going to be able to advance relfrozenxid, we'll > still finish much earlier and let a new anti-wraparound vacuum take > place that will do that -- and will be able to reuse much of the work > of the original VACUUM. Of course this anti-wraparound vacuum will > also skip index vacuuming from the start (whereas the first VACUUM may > well have done some index vacuuming before deciding to end index > vacuuming to hurry with finishing). But we're not sure when the next anti-wraparound vacuum will take place. Since the table is already vacuumed by a non-aggressive vacuum with disabling index cleanup, an autovacuum will process the table when the table gets modified enough or the table's relfrozenxid gets older than autovacuum_vacuum_max_age. If the new threshold, probably a new GUC, is much lower than autovacuum_vacuum_max_age and vacuum_freeze_table_age, the table is continuously vacuumed without advancing relfrozenxid, leading to unnecessarily index bloat. Given the new threshold is for emergency purposes (i.g., advancing relfrozenxid faster), I think it might be better to use vacuum_freeze_table_age as the lower bound of the new threshold. What do you think? Regards, -- Masahiko Sawada EDB: https://www.enterprisedb.com/
On Mon, Mar 22, 2021 at 6:41 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > But we're not sure when the next anti-wraparound vacuum will take > place. Since the table is already vacuumed by a non-aggressive vacuum > with disabling index cleanup, an autovacuum will process the table > when the table gets modified enough or the table's relfrozenxid gets > older than autovacuum_vacuum_max_age. If the new threshold, probably a > new GUC, is much lower than autovacuum_vacuum_max_age and > vacuum_freeze_table_age, the table is continuously vacuumed without > advancing relfrozenxid, leading to unnecessarily index bloat. Given > the new threshold is for emergency purposes (i.g., advancing > relfrozenxid faster), I think it might be better to use > vacuum_freeze_table_age as the lower bound of the new threshold. What > do you think? As you know, when the user sets vacuum_freeze_table_age to a value that is greater than the value of autovacuum_vacuum_max_age, the two GUCs have values that are contradictory. This contradiction is resolved inside vacuum_set_xid_limits(), which knows that it should "interpret" the value of vacuum_freeze_table_age as (autovacuum_vacuum_max_age * 0.95) to paper-over the user's error. This 0.95 behavior is documented in the user docs, though it happens silently. You seem to be concerned about a similar contradiction. In fact it's *very* similar contradiction, because this new GUC is naturally a "sibling GUC" of both vacuum_freeze_table_age and autovacuum_vacuum_max_age (the "units" are the same, though the behavior that each GUC triggers is different -- but vacuum_freeze_table_age and autovacuum_vacuum_max_age are both already *similar and different* in the same way). So perhaps the solution should be similar -- silently interpret the setting of the new GUC to resolve the contradiction. (Maybe I should say "these two new GUCs"? MultiXact variant might be needed...) This approach has the following advantages: * It follows precedent. * It establishes that the new GUC is a logical extension of the existing vacuum_freeze_table_age and autovacuum_vacuum_max_age GUCs. * The default value for the new GUC will be so much higher (say 1.8 billion XIDs) than even the default of autovacuum_vacuum_max_age that it won't disrupt anybody's existing postgresql.conf setup. * For the same reason (the big space between autovacuum_vacuum_max_age and the new GUC with default settings), you can almost set the new GUC without needing to know about autovacuum_vacuum_max_age. * The overall behavior isn't actually restrictive/paternalistic. That is, if you know what you're doing (say you're testing the feature) you can reduce all 3 sibling GUCs to 0 and get the testing behavior that you desire. What do you think? -- Peter Geoghegan
On Mon, Mar 22, 2021 at 8:28 PM Peter Geoghegan <pg@bowt.ie> wrote: > You seem to be concerned about a similar contradiction. In fact it's > *very* similar contradiction, because this new GUC is naturally a > "sibling GUC" of both vacuum_freeze_table_age and > autovacuum_vacuum_max_age (the "units" are the same, though the > behavior that each GUC triggers is different -- but > vacuum_freeze_table_age and autovacuum_vacuum_max_age are both already > *similar and different* in the same way). So perhaps the solution > should be similar -- silently interpret the setting of the new GUC to > resolve the contradiction. More concretely, maybe the new GUC is forced to be 1.05 of vacuum_freeze_table_age. Of course that scheme is a bit arbitrary -- but so is the existing 0.95 scheme. There may be some value in picking a scheme that "advertises" that all three GUCs are symmetrical, or at least related -- all three divide up the table's XID space. -- Peter Geoghegan
On Mon, Mar 22, 2021 at 8:33 PM Peter Geoghegan <pg@bowt.ie> wrote: > More concretely, maybe the new GUC is forced to be 1.05 of > vacuum_freeze_table_age. Of course that scheme is a bit arbitrary -- > but so is the existing 0.95 scheme. I meant to write 1.05 of autovacuum_vacuum_max_age. So just as vacuum_freeze_table_age cannot really be greater than 0.95 * autovacuum_vacuum_max_age, your new GUC cannot really be less than 1.05 * autovacuum_vacuum_max_age. -- Peter Geoghegan
On Tue, Mar 23, 2021 at 12:28 PM Peter Geoghegan <pg@bowt.ie> wrote: > > On Mon, Mar 22, 2021 at 6:41 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > But we're not sure when the next anti-wraparound vacuum will take > > place. Since the table is already vacuumed by a non-aggressive vacuum > > with disabling index cleanup, an autovacuum will process the table > > when the table gets modified enough or the table's relfrozenxid gets > > older than autovacuum_vacuum_max_age. If the new threshold, probably a > > new GUC, is much lower than autovacuum_vacuum_max_age and > > vacuum_freeze_table_age, the table is continuously vacuumed without > > advancing relfrozenxid, leading to unnecessarily index bloat. Given > > the new threshold is for emergency purposes (i.g., advancing > > relfrozenxid faster), I think it might be better to use > > vacuum_freeze_table_age as the lower bound of the new threshold. What > > do you think? > > As you know, when the user sets vacuum_freeze_table_age to a value > that is greater than the value of autovacuum_vacuum_max_age, the two > GUCs have values that are contradictory. This contradiction is > resolved inside vacuum_set_xid_limits(), which knows that it should > "interpret" the value of vacuum_freeze_table_age as > (autovacuum_vacuum_max_age * 0.95) to paper-over the user's error. > This 0.95 behavior is documented in the user docs, though it happens > silently. > > You seem to be concerned about a similar contradiction. In fact it's > *very* similar contradiction, because this new GUC is naturally a > "sibling GUC" of both vacuum_freeze_table_age and > autovacuum_vacuum_max_age (the "units" are the same, though the > behavior that each GUC triggers is different -- but > vacuum_freeze_table_age and autovacuum_vacuum_max_age are both already > *similar and different* in the same way). So perhaps the solution > should be similar -- silently interpret the setting of the new GUC to > resolve the contradiction. Yeah, that's exactly what I also thought. > > (Maybe I should say "these two new GUCs"? MultiXact variant might be needed...) Yes, I think we should have also for MultiXact. > > This approach has the following advantages: > > * It follows precedent. > > * It establishes that the new GUC is a logical extension of the > existing vacuum_freeze_table_age and autovacuum_vacuum_max_age GUCs. > > * The default value for the new GUC will be so much higher (say 1.8 > billion XIDs) than even the default of autovacuum_vacuum_max_age that > it won't disrupt anybody's existing postgresql.conf setup. > > * For the same reason (the big space between autovacuum_vacuum_max_age > and the new GUC with default settings), you can almost set the new GUC > without needing to know about autovacuum_vacuum_max_age. > > * The overall behavior isn't actually restrictive/paternalistic. That > is, if you know what you're doing (say you're testing the feature) you > can reduce all 3 sibling GUCs to 0 and get the testing behavior that > you desire. > > What do you think? Totally agreed. Regards, -- Masahiko Sawada EDB: https://www.enterprisedb.com/
On Tue, Mar 23, 2021 at 12:41 PM Peter Geoghegan <pg@bowt.ie> wrote: > > On Mon, Mar 22, 2021 at 8:33 PM Peter Geoghegan <pg@bowt.ie> wrote: > > More concretely, maybe the new GUC is forced to be 1.05 of > > vacuum_freeze_table_age. Of course that scheme is a bit arbitrary -- > > but so is the existing 0.95 scheme. > > I meant to write 1.05 of autovacuum_vacuum_max_age. So just as > vacuum_freeze_table_age cannot really be greater than 0.95 * > autovacuum_vacuum_max_age, your new GUC cannot really be less than > 1.05 * autovacuum_vacuum_max_age. That makes sense to me. Regards, -- Masahiko Sawada EDB: https://www.enterprisedb.com/
On Mon, Mar 22, 2021 at 10:39 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
>
> On Sat, Mar 20, 2021 at 11:05 AM Peter Geoghegan <pg@bowt.ie> wrote:
> >
> > On Wed, Mar 17, 2021 at 7:55 PM Peter Geoghegan <pg@bowt.ie> wrote:
> >
> > 2. A patch to remove the tupgone case.
> >
> > Severa new and interesting changes here -- see below.
> >
> > 3. The patch to optimize VACUUM by teaching it to skip index and heap
> > vacuuming in certain cases where we only expect a very small benefit.
>
> I’ll review the other two patches tomorrow.
Here are review comments on 0003 patch:
+ /*
+ * Check whether or not to do index vacuum and heap vacuum.
+ *
+ * We do both index vacuum and heap vacuum if more than
+ * SKIP_VACUUM_PAGES_RATIO of all heap pages have at least one LP_DEAD
+ * line pointer. This is normally a case where dead tuples on the heap
+ * are highly concentrated in relatively few heap blocks, where the
+ * index's enhanced deletion mechanism that is clever about heap block
+ * dead tuple concentrations including btree's bottom-up index deletion
+ * works well. Also, since we can clean only a few heap blocks, it would
+ * be a less negative impact in terms of visibility map update.
+ *
+ * If we skip vacuum, we just ignore the collected dead tuples. Note that
+ * vacrelstats->dead_tuples could have tuples which became dead after
+ * HOT-pruning but are not marked dead yet. We do not process them
+ * because it's a very rare condition, and the next vacuum will process
+ * them anyway.
+ */
The second paragraph is no longer true after removing the 'tupegone' case.
---
if (dead_tuples->num_tuples > 0)
two_pass_strategy(onerel, vacrelstats, Irel, indstats, nindexes,
- lps, params->index_cleanup);
+ lps, params->index_cleanup,
+ has_dead_items_pages, !calledtwopass);
Maybe we can use vacrelstats->num_index_scans instead of
calledtwopass? When calling to two_pass_strategy() at the end of
lazy_scan_heap(), if vacrelstats->num_index_scans is 0 it means this
is the first time call, which is equivalent to calledtwopass = false.
---
- params.index_cleanup = get_vacopt_ternary_value(opt);
+ {
+ if (opt->arg == NULL || strcmp(defGetString(opt), "auto") == 0)
+ params.index_cleanup = VACOPT_CLEANUP_AUTO;
+ else if (defGetBoolean(opt))
+ params.index_cleanup = VACOPT_CLEANUP_ENABLED;
+ else
+ params.index_cleanup = VACOPT_CLEANUP_DISABLED;
+ }
+ /*
+ * Set index cleanup option based on reloptions if not set to either ON or
+ * OFF. Note that an VACUUM(INDEX_CLEANUP=AUTO) command is interpreted as
+ * "prefer reloption, but if it's not set dynamically determine if index
+ * vacuuming and cleanup" takes place in vacuumlazy.c. Note also that the
+ * reloption might be explicitly set to AUTO.
+ *
+ * XXX: Do we really want that?
+ */
+ if (params->index_cleanup == VACOPT_CLEANUP_AUTO &&
+ onerel->rd_options != NULL)
+ params->index_cleanup =
+ ((StdRdOptions *) onerel->rd_options)->vacuum_index_cleanup;
Perhaps we can make INDEX_CLEANUP option a four-value option: on, off,
auto, and default? A problem with the above change would be that if
the user wants to do "auto" mode, they might need to reset
vacuum_index_cleanup reloption before executing VACUUM command. In
other words, there is no way in VACUUM command to force "auto" mode.
So I think we can add "auto" value to INDEX_CLEANUP option and ignore
the vacuum_index_cleanup reloption if that value is specified.
Are you updating also the 0003 patch? if you're focusing on 0001 and
0002 patch, I'll update the 0003 patch along with the fourth patch
(skipping index vacuum in emergency cases).
Regards,
--
Masahiko Sawada
EDB: https://www.enterprisedb.com/
On Mon, Mar 22, 2021 at 6:40 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > I've looked at this 0001 patch and here are some review comments: > + * Since we might have to prune a second time here, the code is structured to > + * use a local per-page copy of the counters that caller accumulates. We add > + * our per-page counters to the per-VACUUM totals from caller last of all, to > + * avoid double counting. > > Those comments should be a part of 0002 patch? Right -- will fix. > pc.num_tuples is incremented twice. ps->hastup = true is also duplicated. Must have been a mistake when splitting the patch up -- will fix. > --- > In step 7, with the patch, we save the freespace of the page and do > lazy_vacuum_page(). But should it be done in reverse? > How about renaming to vacuum_two_pass_strategy() or something to clear > this function is used to vacuum? Okay. I will rename it to lazy_vacuum_pruned_items(). > vacrelstats->dead_tuples->num_tuples))); > > It seems that the comment needs to be updated. Will fix. > I’ll review the other two patches tomorrow. And I'll respond to your remarks on those (which are already posted now) separately. > I didn't look at the 0002 patch in-depth but the main difference > between those two WAL records is that XLOG_HEAP2_PRUNE has the offset > numbers of unused, redirected, and dead whereas XLOG_HEAP2_VACUUM has > only the offset numbers of unused? That's one difference. Another difference is that there is no latestRemovedXid field. And there is a third difference: we no longer need a super-exclusive lock for heap page vacuuming (not pruning) with this design -- which also means that we cannot defragment the page during heap vacuuming (that's unsafe with only an exclusive lock because it physically relocates tuples with storage that somebody else may have a C pointer to that they expect to stay sane). These differences during original execution of heap page vacuum necessitate inventing a new REDO routine that does things in exactly the same way. To put it another way, heap vacuuming is now very similar to index vacuuming (both are dissimilar to heap pruning). They're very simple, and 100% a matter of freeing space in physical data structures. Clearly that's always something that we can put off if it makes sense to do so. That high level simplicity seems important to me. I always disliked the way the WAL records for vacuumlazy.c worked. Especially the XLOG_HEAP2_CLEANUP_INFO record -- that one is terrible. -- Peter Geoghegan
On Tue, Mar 23, 2021 at 4:02 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > Here are review comments on 0003 patch: Attached is a new revision, v5. It fixes bit rot caused by recent changes (your index autovacuum logging stuff). It has also been cleaned up in response to your recent review comments -- both from this email, and the other review email that I responded to separately today. > + * If we skip vacuum, we just ignore the collected dead tuples. Note that > + * vacrelstats->dead_tuples could have tuples which became dead after > + * HOT-pruning but are not marked dead yet. We do not process them > + * because it's a very rare condition, and the next vacuum will process > + * them anyway. > + */ > > The second paragraph is no longer true after removing the 'tupegone' case. Fixed. > Maybe we can use vacrelstats->num_index_scans instead of > calledtwopass? When calling to two_pass_strategy() at the end of > lazy_scan_heap(), if vacrelstats->num_index_scans is 0 it means this > is the first time call, which is equivalent to calledtwopass = false. It's true that when "vacrelstats->num_index_scans > 0" it definitely can't have been the first call. But how can we distinguish between 1.) the case where we're being called for the first time, and 2.) the case where it's the second call, but the first call actually skipped index vacuuming? When we skip index vacuuming we won't increment num_index_scans (which seems appropriate to me). For now I have added an assertion that "vacrelstats->num_index_scan == 0" at the point where we apply skipping indexes as an optimization (i.e. the point where the patch 0003- mechanism is applied). > Perhaps we can make INDEX_CLEANUP option a four-value option: on, off, > auto, and default? A problem with the above change would be that if > the user wants to do "auto" mode, they might need to reset > vacuum_index_cleanup reloption before executing VACUUM command. In > other words, there is no way in VACUUM command to force "auto" mode. > So I think we can add "auto" value to INDEX_CLEANUP option and ignore > the vacuum_index_cleanup reloption if that value is specified. I agree that this aspect definitely needs more work. I'll leave it to you to do this in a separate revision of this new 0003 patch (so no changes here from me for v5). > Are you updating also the 0003 patch? if you're focusing on 0001 and > 0002 patch, I'll update the 0003 patch along with the fourth patch > (skipping index vacuum in emergency cases). I suggest that you start integrating it with the wraparound emergency mechanism, which can become patch 0004- of the patch series. You can manage 0003- and 0004- now. You can post revisions of each of those two independently of my revisions. What do you think? I have included 0003- for now because you had review comments on it that I worked through, but you should own that, I think. I suppose that you should include the versions of 0001- and 0002- you worked off of, just for the convenience of others/to keep the CF tester happy. I don't think that I'm going to make many changes that will break your patch, except for obvious bit rot that can be fixed through fairly mechanical rebasing. Thanks -- Peter Geoghegan
Вложения
On Wed, Mar 24, 2021 at 11:44 AM Peter Geoghegan <pg@bowt.ie> wrote: > > On Tue, Mar 23, 2021 at 4:02 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > Here are review comments on 0003 patch: > > Attached is a new revision, v5. It fixes bit rot caused by recent > changes (your index autovacuum logging stuff). It has also been > cleaned up in response to your recent review comments -- both from > this email, and the other review email that I responded to separately > today. > > > + * If we skip vacuum, we just ignore the collected dead tuples. Note that > > + * vacrelstats->dead_tuples could have tuples which became dead after > > + * HOT-pruning but are not marked dead yet. We do not process them > > + * because it's a very rare condition, and the next vacuum will process > > + * them anyway. > > + */ > > > > The second paragraph is no longer true after removing the 'tupegone' case. > > Fixed. > > > Maybe we can use vacrelstats->num_index_scans instead of > > calledtwopass? When calling to two_pass_strategy() at the end of > > lazy_scan_heap(), if vacrelstats->num_index_scans is 0 it means this > > is the first time call, which is equivalent to calledtwopass = false. > > It's true that when "vacrelstats->num_index_scans > 0" it definitely > can't have been the first call. But how can we distinguish between 1.) > the case where we're being called for the first time, and 2.) the case > where it's the second call, but the first call actually skipped index > vacuuming? When we skip index vacuuming we won't increment > num_index_scans (which seems appropriate to me). In (2) case, I think we skipped index vacuuming in the first call because index_cleanup was disabled (if index_cleanup was not disabled, we didn't skip it because two_pass_strategy() is called with onecall = false). So in the second call, we skip index vacuuming for the same reason. Even with the 0004 patch (skipping index vacuuming in emergency cases), the check of XID wraparound emergency should be done before the !onecall check in two_pass_strategy() since we should skip index vacuuming in an emergency case even in the case where maintenance_work_mem runs out. Therefore, similarly, we will skip index vacuuming also in the second call. That being said, I agree that using ‘calledtwopass’ is much readable. So I’ll keep it as is. > > For now I have added an assertion that "vacrelstats->num_index_scan == > 0" at the point where we apply skipping indexes as an optimization > (i.e. the point where the patch 0003- mechanism is applied). > > > Perhaps we can make INDEX_CLEANUP option a four-value option: on, off, > > auto, and default? A problem with the above change would be that if > > the user wants to do "auto" mode, they might need to reset > > vacuum_index_cleanup reloption before executing VACUUM command. In > > other words, there is no way in VACUUM command to force "auto" mode. > > So I think we can add "auto" value to INDEX_CLEANUP option and ignore > > the vacuum_index_cleanup reloption if that value is specified. > > I agree that this aspect definitely needs more work. I'll leave it to you to > do this in a separate revision of this new 0003 patch (so no changes here > from me for v5). > > > Are you updating also the 0003 patch? if you're focusing on 0001 and > > 0002 patch, I'll update the 0003 patch along with the fourth patch > > (skipping index vacuum in emergency cases). > > I suggest that you start integrating it with the wraparound emergency > mechanism, which can become patch 0004- of the patch series. You can > manage 0003- and 0004- now. You can post revisions of each of those > two independently of my revisions. What do you think? I have included > 0003- for now because you had review comments on it that I worked > through, but you should own that, I think. > > I suppose that you should include the versions of 0001- and 0002- you > worked off of, just for the convenience of others/to keep the CF > tester happy. I don't think that I'm going to make many changes that > will break your patch, except for obvious bit rot that can be fixed > through fairly mechanical rebasing. Agreed. I was just about to post my 0004 patch based on v4 patch series. I'll update 0003 and 0004 patches based on v5 patch series you just posted, and post them including 0001 and 0002 patches. Regards, -- Masahiko Sawada EDB: https://www.enterprisedb.com/
On Wed, Mar 24, 2021 at 12:11 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Wed, Mar 24, 2021 at 11:44 AM Peter Geoghegan <pg@bowt.ie> wrote: > > > > On Tue, Mar 23, 2021 at 4:02 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > > Here are review comments on 0003 patch: > > > > Attached is a new revision, v5. It fixes bit rot caused by recent > > changes (your index autovacuum logging stuff). It has also been > > cleaned up in response to your recent review comments -- both from > > this email, and the other review email that I responded to separately > > today. > > > > > + * If we skip vacuum, we just ignore the collected dead tuples. Note that > > > + * vacrelstats->dead_tuples could have tuples which became dead after > > > + * HOT-pruning but are not marked dead yet. We do not process them > > > + * because it's a very rare condition, and the next vacuum will process > > > + * them anyway. > > > + */ > > > > > > The second paragraph is no longer true after removing the 'tupegone' case. > > > > Fixed. > > > > > Maybe we can use vacrelstats->num_index_scans instead of > > > calledtwopass? When calling to two_pass_strategy() at the end of > > > lazy_scan_heap(), if vacrelstats->num_index_scans is 0 it means this > > > is the first time call, which is equivalent to calledtwopass = false. > > > > It's true that when "vacrelstats->num_index_scans > 0" it definitely > > can't have been the first call. But how can we distinguish between 1.) > > the case where we're being called for the first time, and 2.) the case > > where it's the second call, but the first call actually skipped index > > vacuuming? When we skip index vacuuming we won't increment > > num_index_scans (which seems appropriate to me). > > In (2) case, I think we skipped index vacuuming in the first call > because index_cleanup was disabled (if index_cleanup was not disabled, > we didn't skip it because two_pass_strategy() is called with onecall = > false). So in the second call, we skip index vacuuming for the same > reason. Even with the 0004 patch (skipping index vacuuming in > emergency cases), the check of XID wraparound emergency should be done > before the !onecall check in two_pass_strategy() since we should skip > index vacuuming in an emergency case even in the case where > maintenance_work_mem runs out. Therefore, similarly, we will skip > index vacuuming also in the second call. > > That being said, I agree that using ‘calledtwopass’ is much readable. > So I’ll keep it as is. > > > > > For now I have added an assertion that "vacrelstats->num_index_scan == > > 0" at the point where we apply skipping indexes as an optimization > > (i.e. the point where the patch 0003- mechanism is applied). > > > > > Perhaps we can make INDEX_CLEANUP option a four-value option: on, off, > > > auto, and default? A problem with the above change would be that if > > > the user wants to do "auto" mode, they might need to reset > > > vacuum_index_cleanup reloption before executing VACUUM command. In > > > other words, there is no way in VACUUM command to force "auto" mode. > > > So I think we can add "auto" value to INDEX_CLEANUP option and ignore > > > the vacuum_index_cleanup reloption if that value is specified. > > > > I agree that this aspect definitely needs more work. I'll leave it to you to > > do this in a separate revision of this new 0003 patch (so no changes here > > from me for v5). > > > > > Are you updating also the 0003 patch? if you're focusing on 0001 and > > > 0002 patch, I'll update the 0003 patch along with the fourth patch > > > (skipping index vacuum in emergency cases). > > > > I suggest that you start integrating it with the wraparound emergency > > mechanism, which can become patch 0004- of the patch series. You can > > manage 0003- and 0004- now. You can post revisions of each of those > > two independently of my revisions. What do you think? I have included > > 0003- for now because you had review comments on it that I worked > > through, but you should own that, I think. > > > > I suppose that you should include the versions of 0001- and 0002- you > > worked off of, just for the convenience of others/to keep the CF > > tester happy. I don't think that I'm going to make many changes that > > will break your patch, except for obvious bit rot that can be fixed > > through fairly mechanical rebasing. > > Agreed. > > I was just about to post my 0004 patch based on v4 patch series. I'll > update 0003 and 0004 patches based on v5 patch series you just posted, > and post them including 0001 and 0002 patches. > I've attached the updated patch set (nothing changed in 0001 and 0002 patch). Regarding "auto" option, I think it would be a good start to enable the index vacuum skipping behavior by default instead of adding “auto” mode. That is, we could skip index vacuuming if INDEX_CLEANUP ON. With 0003 and 0004 patch, there are two cases where we skip index vacuuming: the garbage on heap is very concentrated and the table is at risk of XID wraparound. It seems to make sense to have both behaviors by default. If we want to have a way to force doing index vacuuming, we can add “force” option instead of adding “auto” option and having “on” mode force doing index vacuuming. Also regarding new GUC parameters, vacuum_skip_index_age and vacuum_multixact_skip_index_age, those are not autovacuum-dedicated parameter. VACUUM command also uses those parameters to skip index vacuuming dynamically. In such an emergency case, it seems appropriate to me to skip index vacuuming even in VACUUM command. And I don’t add any reloption for those two parameters. Since those parameters are unlikely to be changed from the default value, I think it don’t necessarily need to provide a way for per-table configuration. In 0001 patch, we have the following chunk: + bool skipping; + + /* Should not end up here with no indexes */ + Assert(nindexes > 0); + Assert(!IsParallelWorker()); + + /* Check whether or not to do index vacuum and heap vacuum */ + if (index_cleanup == VACOPT_TERNARY_DISABLED) + skipping = true; + else + skipping = false; Can we flip the boolean? I mean to use a positive form such as "do_vacuum". It seems to be more readable especially for the changes made in 0003 and 0004 patches. Regards, -- Masahiko Sawada EDB: https://www.enterprisedb.com/
Вложения
On Wed, Mar 24, 2021 at 6:05 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> I've attached the updated patch set (nothing changed in 0001 and 0002 patch).
Attached is v7, which takes the last two patches from your v6 and
rebases them on top of my recent work. This includes handling index
cleanup consistently in the event of an emergency. We want to do index
cleanup when the optimization case works out. It would be arbitrary to
not do index cleanup because there was 1 dead tuple instead of 0. Plus
index cleanup is actually useful in some index AMs. At the same time,
it seems like a bad idea to do cleanup in an emergency case. Note that
this includes the case where the new wraparound mechanism kicks in, as
well as the case where INDEX_CLEANUP = off. In general INDEX_CLEANUP =
off should be 100% equivalent to the emergency mechanism, except that
the decision is made dynamically instead of statically.
The two patches that you have been working on are combined into one
patch in v7 -- the last patch in the series. Maintaining two separate
patches there doesn't seem that useful.
The main change I've made in v7 is structural. There is a new patch in
the series, which is now the first. It adds more variables to the
top-level state variable used by VACUUM. We shouldn't have to pass the
same "onerel" variable and other similar variables to so many similar
functions. Plus we shouldn't rely on global state so much. That makes
the code a lot easier to understand. Another change that appears in
the first patch concerns parallel VACUUM, and how it is structured. It
is hard to know which function concerned parallel VACUUM and which is
broader than that right now. It makes it seriously hard to follow at
times. So I have consolidated those functions, and given them less
generic, more descriptive names. (In general it should be possible to
read most of the code in vacuumlazy.c without thinking about parallel
VACUUM in particular.)
I had many problems with existing function arguments that look like this:
IndexBulkDeleteResult **stats // this is a pointer to a pointer to a
IndexBulkDeleteResult.
Sometimes this exact spelling indicates: 1. "This is one particular
index's stats -- this function will have the index AM set the
statistics during ambulkdelete() and/or amvacuumcleanup()".
But at other times/with other function arguments, it indicates: 2.
"Array of stats, once for each of the heap relation's indexes".
I found the fact that both 1 and 2 appear together side by side very
confusing. It is much clearer with 0001-*, though. It establishes a
consistent singular vs plural variable naming convention. It also no
longer uses IndexBulkDeleteResult ** args for case 1 -- even the C
type system ambiguity is avoided. Any thoughts on my approach to this?
Another change in v7: We now stop applying any cost-based delay that
may be in force if and when we abandon index vacuuming to finish off
the VACUUM operation. Robert thought that that was important, and I
agree. I think that it's 100% justified, because this is a true
emergency. When the emergency mechanism (though not INDEX_CLEANUP=off)
actually kicks in, we now also have a scary WARNING. Since this
behavior only occurs when the system is definitely at very real risk
of becoming unavailable, we can justify practically any intervention
that makes it less likely that the system will become 100% unavailable
(except for anything that creates additional risk of data loss).
BTW, spotted this compiler warning in v6:
/code/postgresql/patch/build/../source/src/backend/access/heap/vacuumlazy.c:
In function ‘check_index_vacuum_xid_limit’:
/code/postgresql/patch/build/../source/src/backend/access/heap/vacuumlazy.c:2314:6:
warning: variable ‘effective_multixact_freeze_max_age’ set but not
used [-Wunused-but-set-variable]
2314 | int effective_multixact_freeze_max_age;
| ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
I think that it's just a leftover chunk of code. The variable in
question ('effective_multixact_freeze_max_age') does not appear in v7,
in any case. BTW I moved this function into vacuum.c, next to
vacuum_set_xid_limits() -- that seemed like a better place for it. But
please check this yourself.
> Regarding "auto" option, I think it would be a good start to enable
> the index vacuum skipping behavior by default instead of adding “auto”
> mode. That is, we could skip index vacuuming if INDEX_CLEANUP ON. With
> 0003 and 0004 patch, there are two cases where we skip index
> vacuuming: the garbage on heap is very concentrated and the table is
> at risk of XID wraparound. It seems to make sense to have both
> behaviors by default.
I agree. Adding a new "auto" option now seems to me to be unnecessary
complexity. Besides, switching a boolean reloption to a bool-like enum
reloption may have subtle problems.
> If we want to have a way to force doing index
> vacuuming, we can add “force” option instead of adding “auto” option
> and having “on” mode force doing index vacuuming.
It's hard to imagine anybody using the "force option". Let's not have
one. Let's not change the fact that "INDEX_CLEANUP = on" means
"default index vacuuming behavior". Let's just change the index
vacuuming behavior. If we get the details wrong, a simple reloption
will make little difference. We're already being fairly conservative
in terms of the skipping behavior, including with the
SKIP_VACUUM_PAGES_RATIO.
> Also regarding new GUC parameters, vacuum_skip_index_age and
> vacuum_multixact_skip_index_age, those are not autovacuum-dedicated
> parameter. VACUUM command also uses those parameters to skip index
> vacuuming dynamically. In such an emergency case, it seems appropriate
> to me to skip index vacuuming even in VACUUM command. And I don’t add
> any reloption for those two parameters. Since those parameters are
> unlikely to be changed from the default value, I think it don’t
> necessarily need to provide a way for per-table configuration.
+1 for all that. We already have a reloption for this behavior, more
or less -- it's called INDEX_CLEANUP.
The existing autovacuum_freeze_max_age GUC (which is highly related to
your new GUCs) is both an autovacuum GUC, and somehow also not an
autovacuum GUC at the same time. The apparent contradiction only seems
to resolve itself when you consider the perspective of DBAs and the
perspective of Postgres hackers separately.
*Every* VACUUM GUC is an autovacuum GUC when you know for sure that
the relfrozenxid is 1 billion+ XIDs in the past.
> + bool skipping;
> Can we flip the boolean? I mean to use a positive form such as
> "do_vacuum". It seems to be more readable especially for the changes
> made in 0003 and 0004 patches.
I agree that it's clearer that way around.
The code is structured this way in v7. Specifically, there are now
both do_index_vacuuming and do_index_cleanup in the per-VACUUM state
struct in patch 0002-*. These are a direct replacement for useindex.
(Though we only start caring about the do_index_cleanup field in the
final patch, 0004-*)
Thanks
--
Peter Geoghegan
Вложения
On Thu, Mar 25, 2021 at 6:58 PM Peter Geoghegan <pg@bowt.ie> wrote:
> Attached is v7, which takes the last two patches from your v6 and
> rebases them on top of my recent work.
And now here's v8, which has the following additional cleanup:
* Added useful log_autovacuum output.
This should provide DBAs with a useful tool for seeing how effective
this optimization is. But I think that they'll also end up using it to
monitor things like how effective HOT is with certain tables over
time. If regular autovacuums indicate that there is no need to do
index vacuuming, then HOT must be working well. Whereas if autovacuums
continually require index vacuuming, it might well be taken as a sign
that heap fill factor should be reduced. There are complicated reasons
why HOT might not work quite as well as expected, and having near real
time insight into it strikes me as valuable.
* Added this assertion to the patch that removes the tupgone special
case, which seems really useful to me:
@@ -2421,6 +2374,12 @@ lazy_vacuum_heap_rel(LVRelState *vacrel)
vmbuffer = InvalidBuffer;
}
+ /*
+ * We set all LP_DEAD items from the first heap pass to LP_UNUSED during
+ * the second heap pass. No more, no less.
+ */
+ Assert(vacrel->num_index_scans > 1 || tupindex == vacrel->lpdead_items);
+
ereport(elevel,
(errmsg("\"%s\": removed %d dead item identifiers in %u pages",
vacrel->relname, tupindex, vacuumed_pages),
This assertion verifies that the number of items that we have vacuumed
in a second pass of the heap precisely matches the number of LP_DEAD
items encountered in the first pass of the heap. Of course, these
LP_DEAD items are now exactly the same thing as dead_tuples array TIDs
that we vacuum/remove from indexes, before finally vacuuming/removing
them from the heap.
* A lot more polishing in the first patch, which refactors the
vacuumlazy.c state quite a bit. I now use int64 instead of double for
some of the counters, which enables various assertions, including the
one I mentioned.
The instrumentation state in vacuumlazy.c has always been a mess. I
spotted a bug in the process of cleaning it up, at this point:
/* If no indexes, make log report that lazy_vacuum_heap would've made */
if (vacuumed_pages)
ereport(elevel,
(errmsg("\"%s\": removed %.0f row versions in %u pages",
vacrelstats->relname,
tups_vacuumed, vacuumed_pages)));
This is wrong because lazy_vacuum_heap() doesn't report tups_vacuumed.
It actually reports what I'm calling lpdead_items, which can have a
very different value to tups_vacuumed/tuples_deleted.
--
Peter Geoghegan
Вложения
On Sun, Mar 28, 2021 at 9:16 PM Peter Geoghegan <pg@bowt.ie> wrote: > And now here's v8, which has the following additional cleanup: And here's v9, which has improved commit messages for the first 2 patches, and many small tweaks within all 4 patches. The most interesting change is that lazy_scan_heap() now has a fairly elaborate assertion that verifies that its idea about whether or not the page is all_visible and all_frozen is shared by heap_page_is_all_visible() -- this is a stripped down version of the logic that now lives in lazy_scan_heap(). It exists so that the second pass over the heap can set visibility map bits. -- Peter Geoghegan
Вложения
On Wed, Mar 31, 2021 at 12:01 PM Peter Geoghegan <pg@bowt.ie> wrote:
>
> On Sun, Mar 28, 2021 at 9:16 PM Peter Geoghegan <pg@bowt.ie> wrote:
> > And now here's v8, which has the following additional cleanup:
>
> And here's v9, which has improved commit messages for the first 2
> patches, and many small tweaks within all 4 patches.
>
> The most interesting change is that lazy_scan_heap() now has a fairly
> elaborate assertion that verifies that its idea about whether or not
> the page is all_visible and all_frozen is shared by
> heap_page_is_all_visible() -- this is a stripped down version of the
> logic that now lives in lazy_scan_heap(). It exists so that the second
> pass over the heap can set visibility map bits.
Thank you for updating the patches.
Both 0001 and 0002 patch refactors the whole lazy vacuum code. Can we
merge them? I basically agree with the refactoring made by 0001 patch
but I'm concerned a bit that having such a large refactoring at very
close to feature freeze could be risky. We would need more eyes to
review during stabilization.
Here are some comments on 0001 patch:
-/*
- * Macro to check if we are in a parallel vacuum. If true, we are in the
- * parallel mode and the DSM segment is initialized.
- */
-#define ParallelVacuumIsActive(lps) PointerIsValid(lps)
-
I think it's more clear to use this macro. The macro can be like this:
ParallelVacuumIsActive(vacrel) (((LVRelState) vacrel)->lps != NULL)
---
/*
- * LVDeadTuples stores the dead tuple TIDs collected during the heap scan.
- * This is allocated in the DSM segment in parallel mode and in local memory
- * in non-parallel mode.
+ * LVDeadTuples stores TIDs that are gathered during pruning/the initial heap
+ * scan. These get deleted from indexes during index vacuuming. They're then
+ * removed from the heap during a second heap pass that performs heap
+ * vacuuming.
*/
The second sentence of the removed lines still seems to be useful
information for readers?
---
- *
- * Note that vacrelstats->dead_tuples
could have tuples which
- * became dead after HOT-pruning but
are not marked dead yet.
- * We do not process them because it's
a very rare condition,
- * and the next vacuum will process them anyway.
Maybe the above comments should not be removed by 0001 patch.
---
+ /* Free resources managed by lazy_space_alloc() */
+ lazy_space_free(vacrel);
and
+/* Free space for dead tuples */
+static void
+lazy_space_free(LVRelState *vacrel)
+{
+ if (!vacrel->lps)
+ return;
+
+ /*
+ * End parallel mode before updating index statistics as we cannot write
+ * during parallel mode.
+ */
+ end_parallel_vacuum(vacrel);
Looking at the comments, I thought that this function also frees
palloc'd dead tuple space but it doesn't. It seems to more clear that
doing pfree(vacrel->dead_tuples) here or not creating
lazy_space_free().
Also, the comment for end_paralle_vacuum() looks not relevant with
this function. Maybe we can update to:
/* Exit parallel mode and free the parallel context */
---
+ if (shared_istat)
+ {
+ /* Get the space for IndexBulkDeleteResult */
+ bulkdelete_res = &(shared_istat->istat);
+
+ /*
+ * Update the pointer to the corresponding
bulk-deletion result if
+ * someone has already updated it.
+ */
+ if (shared_istat->updated && istat == NULL)
+ istat = bulkdelete_res;
+ }
(snip)
+ if (shared_istat && !shared_istat->updated && istat != NULL)
+ {
+ memcpy(bulkdelete_res, istat, sizeof(IndexBulkDeleteResult));
+ shared_istat->updated = true;
+
+ /*
+ * Now that top-level indstats[idx] points to the DSM
segment, we
+ * don't need the locally allocated results.
+ */
+ pfree(istat);
+ istat = bulkdelete_res;
+ }
+
+ return istat;
If we have parallel_process_one_index() return the address of
IndexBulkDeleteResult, we can simplify the first part above. Also, it
seems better to use a separate variable from istat to store the
result. How about the following structure?
IndexBulkDeleteResult *istat_res;
/*
* Update the pointer of the corresponding bulk-deletion result if
* someone has already updated it.
*/
if (shared_istat && shared_istat->updated && istat == NULL)
istat = shared_istat->istat;
/* Do vacuum or cleanup of the index */
if (lvshared->for_cleanup)
istat_res = lazy_cleanup_one_index(indrel, istat, ...);
else
istat_res = lazy_vacuum_one_index(indrel, istat, ...);
/*
* (snip)
*/
if (shared_istat && !shared_istat->updated && istat_res != NULL)
{
memcpy(shared_istat->istat, istat_res, sizeof(IndexBulkDeleteResult));
shared_istat->updated = true;
/* free the locally-allocated bulk-deletion result */
pfree(istat_res);
/* return the pointer to the result on the DSM segment */
return shared_istat->istat;
}
return istat_res;
Comment on 0002 patch:
+ /* This won't have changed: */
+ Assert(savefreespace && freespace == PageGetHeapFreeSpace(page));
This assertion can be false because freespace can be 0 if the page's
PD_HAS_FREE_LINES hint can wrong. Since lazy_vacuum_heap_page() fixes
it, PageGetHeapFreeSpace(page) in the assertion returns non-zero
value.
And, here are commends on 0004 patch:
+ ereport(WARNING,
+ (errmsg("abandoned index vacuuming of
table \"%s.%s.%s\" as a fail safe after %d index scans",
+ get_database_name(MyDatabaseId),
+ vacrel->relname,
+ vacrel->relname,
+ vacrel->num_index_scans),
The first vacrel->relname should be vacrel->relnamespace.
I think we can use errmsg_plural() for "X index scans" part.
---
+ ereport(elevel,
+ (errmsg("\"%s\": index scan bypassed:
%u pages from table (%.2f%% of total) have %lld dead item
identifiers",
+ vacrel->relname,
vacrel->rel_pages,
+ 100.0 *
vacrel->lpdead_item_pages / vacrel->rel_pages,
+ (long long)
vacrel->lpdead_items)));
We should use vacrel->lpdead_item_pages instead of vacrel->rel_pages
---
+ /* Stop applying cost limits from this point on */
+ VacuumCostActive = false;
+ VacuumCostBalance = 0;
+ }
I agree with the idea of disabling vacuum delay in emergency cases.
But why do we do that only in the case of the table with indexes? I
think this optimization is helpful even in the table with no indexes.
We can check the XID wraparound emergency by calling
vacuum_xid_limit_emergency() at some point to disable vacuum delay?
---
+ if (vacrel->do_index_cleanup)
+ appendStringInfo(&buf,
_("index scan bypassed:"));
+ else
+ appendStringInfo(&buf,
_("index scan bypassed due to emergency:")\
);
+ msgfmt = _(" %u pages from
table (%.2f%% of total) have %lld dead item identifiers\n");
+ }
Both vacrel->do_index_vacuuming and vacrel->do_index_cleanup can be
false also when INDEX_CLEANUP is off. So autovacuum could wrongly
report emergency if the table's vacuum_index_vacuum reloption is
false.
Regards,
--
Masahiko Sawada
EDB: https://www.enterprisedb.com/
On Mon, Mar 29, 2021 at 12:16 AM Peter Geoghegan <pg@bowt.ie> wrote: > And now here's v8, which has the following additional cleanup: I can't effectively review 0001 because it both changes the code for individual functions significantly and reorders them within the file. I think it needs to be separated into two patches, one of which makes the changes and the other of which reorders stuff. I would probably vote for just dropping the second one, since I'm not sure there's really enough value there to justify the code churn, but if we're going to do it, I think it should definitely be done separately. Here are a few comments on the parts I was able to understand: * "onerel" is a stupid naming convention that I'd rather not propagate further. It makes sense in the context of a function whose job it is to iterate over a list of relations and do something for each one. But once you're down into the code that only knows about one relation in the first place, calling that relation "onerel" rather than "rel" or "vacrel" or even "heaprel" is just confusing. Ditto for "onerelid". * Moving stuff from static variables into LVRelState seems like a great idea. Renaming it from LVRelStats seems like a good idea, too. * Setting vacrel->lps = NULL "for now" when we already did palloc0 at allocation time seems counterproductive. * The code associated with the comment block that says "Initialize state for a parallel vacuum" has been moved inside lazy_space_alloc(). That doesn't seem like an especially good choice, because no casual reader is going to expect a function called lazy_space_alloc() to be entering parallel mode and so forth as a side effect. Also, the call to lazy_space_alloc() still has a comment that says "Allocate the space for dead tuples in case parallel vacuum is not initialized." even though the ParallelVacuumIsActive() check has been removed and the function now does a lot more than allocating space. * lazy_scan_heap() removes the comment which begins "Note that vacrelstats->dead_tuples could have tuples which became dead after HOT-pruning but are not marked dead yet." But IIUC that special case is removed by a later patch, not 0001, in which case it is that patch that should be touching this comment. Regarding 0002: * It took me a while to understand why lazy_scan_new_page() and lazy_scan_empty_page() are named the way they are. I'm not sure exactly what would be better, so I am not necessarily saying I think you have to change anything, but for the record I think this naming sucks. The reason we have "lazy" in here, AFAIU, is because originally we only had old-style VACUUM FULL, and that was the good hard-working VACUUM, and what we now think of as VACUUM was the "lazy" version that didn't really do the whole job. Then we decided it was the hard-working version that actually sucked and we always wanted to be lazy (or else rewrite the table). So now we have all of these functions named "lazy" which are really just functions to do "vacuum". But, if we just did s/lazy/vacuum/g we'd be in trouble, because we use "vacuum" to mean "part of vacuum." That's actually a pretty insane thing to do, but we like terminological confusion so much that we decided to use the word vacuum not just to refer to one part of vacuum but to two different parts of vacuum. During heap vacuuming, which is the relevant thing here, we call the first part a "scan" and the second part "vacuum," hence lazy_scan_page() and lazy_vacuum_page(). For indexes, we can decide to vacuum indexes or cleanup indexes, either of which is part of our overall strategy of trying to do a VACUUM. We need some words here that are not so overloaded. If, for example, we could agree that the whole thing is vacuum and the first time we touch the heap page that's the strawberry phase and then the second time we touch it that's the rhubarb phase, then we could have vacuum_strawberry_page(), vacuum_strawberry_new_page(), vacuum_rhubarb_phase(), etc. and everything would be a lot clearer, assuming that you replaced the words "strawberry" and "rhubarb" with something actually meaningful. But that seems hard. I thought about suggesting that the word for strawberry should be "prune", but it does more than that. I thought about suggesting that either the word for strawberry or the word for rhubarb should be "cleanup," but that's another word that is already confusingly overloaded. So I don't know. * But all that having been said, it's easy to get confused and think that lazy_scan_new_page() is scanning a new page for lazy vacuum, but in fact it's the new-page handler for the scan phase of lazy vacuum, and it doesn't scan anything at all. If there's a way to avoid that kind of confusion, +1 from me. * One possibility is that maybe it's not such a great idea to put this logic in its own function. I'm rather suspicious on principle of functions that are called with a locked or pinned buffer and release the lock or pin before returning. It suggests that the abstraction is not very clean. A related problem is that, post-refactoring, the parallels between the page-is-new and page-is-empty cases are harder to spot. Both at least maybe do RecordPageWithFreeSpace(), both do UnlockReleaseBuffer(), etc. but you have to look at the subroutines to figure that out after these changes. I understand the value of keeping the main function shorter, but it doesn't help much if you have to go jump into all of the subroutines and read them anyway. * The new comment added which begins "Even if we skipped heap vacuum, ..." is good, but perhaps it could be more optimistic. It seems to me that it's not just that it *could* be worthwhile because we *could* have updated freespace, but that those things are in fact probable. * I'm not really a huge fan of comments that include step numbers, because they tend to cause future patches to have to change a bunch of comments every time somebody adds a new step, or, less commonly, removes an old one. I would suggest revising the comments you've added that say things like "Step N for block: X" to just "X". I do like the comment additions, just not the attributing of specific numbers to specific steps. * As in 0001, core logical changes are obscured by moving code and changing it in the same patch. All this logic gets moved into lazy_scan_prune() and revised at the same time. Using git diff --color-moved -w sorta works, but even then there are parts of it that are pretty hard to read, because there's a bunch of other stuff that gets rejiggered at the same time. My concentration is flagging a bit so I'm going to stop reviewing here for now. I'm not deeply opposed to any of what I've seen so far. My main criticism is that I think more thought should be given to how things are named and to separating minimal code-movement patches from other changes. Thanks, -- Robert Haas EDB: http://www.enterprisedb.com
On Wed, Mar 31, 2021 at 9:29 AM Robert Haas <robertmhaas@gmail.com> wrote: > I can't effectively review 0001 because it both changes the code for > individual functions significantly and reorders them within the file. > I think it needs to be separated into two patches, one of which makes > the changes and the other of which reorders stuff. I would probably > vote for just dropping the second one, since I'm not sure there's > really enough value there to justify the code churn, but if we're > going to do it, I think it should definitely be done separately. Thanks for the review! I'll split it up that way. I think that I need to see it both ways before deciding if I should push back on that. I will admit that I was a bit zealous in rearranging things because it seems long overdue. But I might well have gone too far with rearranging code. > * "onerel" is a stupid naming convention that I'd rather not propagate > further. It makes sense in the context of a function whose job it is > to iterate over a list of relations and do something for each one. But > once you're down into the code that only knows about one relation in > the first place, calling that relation "onerel" rather than "rel" or > "vacrel" or even "heaprel" is just confusing. Ditto for "onerelid". I agree, and can change it. Though at the cost of more diff churn. > * Moving stuff from static variables into LVRelState seems like a > great idea. Renaming it from LVRelStats seems like a good idea, too. The static variables were bad, but nowhere near as bad as the variables that are local to lazy_scan_heap(). They are currently a gigantic mess. Not that LVRelStats was much better. We have the latestRemovedXid field in LVRelStats, and dead_tuples, but *don't* have a bunch of things that really are stats (it seems to be quite random). Calling the struct LVRelStats was always dubious. > * Setting vacrel->lps = NULL "for now" when we already did palloc0 at > allocation time seems counterproductive. Okay, will fix. > * The code associated with the comment block that says "Initialize > state for a parallel vacuum" has been moved inside lazy_space_alloc(). > That doesn't seem like an especially good choice, because no casual > reader is going to expect a function called lazy_space_alloc() to be > entering parallel mode and so forth as a side effect. Also, the call > to lazy_space_alloc() still has a comment that says "Allocate the > space for dead tuples in case parallel vacuum is not initialized." > even though the ParallelVacuumIsActive() check has been removed and > the function now does a lot more than allocating space. Will fix. > * lazy_scan_heap() removes the comment which begins "Note that > vacrelstats->dead_tuples could have tuples which became dead after > HOT-pruning but are not marked dead yet." But IIUC that special case > is removed by a later patch, not 0001, in which case it is that patch > that should be touching this comment. Will fix. > Regarding 0002: > > * It took me a while to understand why lazy_scan_new_page() and > lazy_scan_empty_page() are named the way they are. I'm not sure > exactly what would be better, so I am not necessarily saying I think > you have to change anything, but for the record I think this naming > sucks. I agree -- it's dreadful. > The reason we have "lazy" in here, AFAIU, is because originally > we only had old-style VACUUM FULL, and that was the good hard-working > VACUUM, and what we now think of as VACUUM was the "lazy" version that > didn't really do the whole job. Then we decided it was the > hard-working version that actually sucked and we always wanted to be > lazy (or else rewrite the table). So now we have all of these > functions named "lazy" which are really just functions to do "vacuum". FWIW I always thought that the terminology was lifted from the world of garbage collection. There is a thing called a lazy sweep algorithm. Isn't vacuuming very much like sweeping? There are also mark-sweep garbage collection algorithms that take two passes, one phase variants, etc. In general the world of garbage collection has some ideas that might be worth pilfering for ideas. It's not all that relevant to our world, and a lot of it is totally irrelevant, but there is enough overlap for it to interest me. Though GC is such a vast and complicated world that it's difficult to know where to begin. I own a copy of the book "Garbage Collection: Algorithms for Automatic Dynamic Memory Management". Most of it goes over my head, but I have a feeling that I'll get my $20 worth at some point. > If, for example, we could agree that the whole thing is vacuum and the first > time we touch the heap page that's the strawberry phase and then the > second time we touch it that's the rhubarb phase, then we could have > vacuum_strawberry_page(), vacuum_strawberry_new_page(), > vacuum_rhubarb_phase(), etc. and everything would be a lot clearer, > assuming that you replaced the words "strawberry" and "rhubarb" with > something actually meaningful. But that seems hard. I thought about > suggesting that the word for strawberry should be "prune", but it does > more than that. I thought about suggesting that either the word for > strawberry or the word for rhubarb should be "cleanup," but that's > another word that is already confusingly overloaded. So I don't know. Maybe we should just choose a novel name that isn't exactly descriptive but is at least distinct and memorable. I think that the word for strawberry should be "prune". This isn't 100% accurate because it reduces the first phase to pruning. But it is a terminology that has verisimilitude, which is no small thing. The fact is that pruning is pretty much the point of the first phase (freezing is too, but that happens quite specifically is only considered for non-pruned items, so it doesn't undermine my point much). If we called the first/strawberry pass over the heap pruning or "the prune phase" then we'd have something much more practical and less confusing than any available alternative that I can think of. Plus it would still be fruit-based. I think that our real problem is with Rhubarb. I hate the use of the terminology "heap vacuum" in the context of the second phase/pass. Whatever terminology we use, we should frame the second phase as being mostly about recycling LP_DEAD line pointers my turning them into LP_UNUSED line pointers. We are recycling the space for "cells" that get logically freed in the first phase (both in indexes, and finally in the heap). I like the idea of framing the first phase as being concerned with the logical database, while the second phase (which includes index vacuuming and heap vacuuming) is concerned only with physical data structures (so it's much dumber than the first). That's only ~99% true today, but the third/"tupgone gone" patch will make it 100% true. > * But all that having been said, it's easy to get confused and think > that lazy_scan_new_page() is scanning a new page for lazy vacuum, but > in fact it's the new-page handler for the scan phase of lazy vacuum, > and it doesn't scan anything at all. If there's a way to avoid that > kind of confusion, +1 from me. This is another case where I need to see it the other way. > * One possibility is that maybe it's not such a great idea to put this > logic in its own function. I'm rather suspicious on principle of > functions that are called with a locked or pinned buffer and release > the lock or pin before returning. It suggests that the abstraction is > not very clean. I am sympathetic here. In fact most of those functions were added at the suggestion of Andres. I think that they're fine, but it's reasonable to wonder if we're coming out ahead by having all but one of them (lazy_scan_prune()). The reality is that they share state fairly promiscuously, so I'm not really hiding complexity. The whole idea here should be to remove inessential complexity in how we represent and consume state. However, it's totally different in the case of the one truly important function among this group of new lazy_scan_heap() functions, lazy_scan_prune(). It seems like a *huge* improvement to me. The obvious advantage of having that function is that calling that function can be considered a shorthand for "a blkno loop iteration that actually does real work". Everything else in the calling loop is essentially either preamble or postscript to lazy_scan_prune(), since we don't actually need to set VM bits, or to skip heap blocks, or to save space in the FSM. I think that that's a big difference. There is a slightly less obvious advantage, too. It's clear that the function as written actually does do a good job of reducing state-related complexity, because it effectively returns a LVPagePruneState (we pass a pointer but nothing gets initialized before the call to lazy_scan_prune()). So now it's really obvious what state is managed by pruning/freezing, and it's obvious what follows from that when we return control to lazy_scan_heap(). This ties together with my first point about pruning being the truly important piece of work. That really does hide complexity rather well, especially compared to the other new functions from the second patch. > * The new comment added which begins "Even if we skipped heap vacuum, > ..." is good, but perhaps it could be more optimistic. It seems to me > that it's not just that it *could* be worthwhile because we *could* > have updated freespace, but that those things are in fact probable. Will fix. > * I'm not really a huge fan of comments that include step numbers, > because they tend to cause future patches to have to change a bunch of > comments every time somebody adds a new step, or, less commonly, > removes an old one. I would suggest revising the comments you've added > that say things like "Step N for block: X" to just "X". I do like the > comment additions, just not the attributing of specific numbers to > specific steps. I see your point. I added the numbers because I wanted the reader to notice a parallel construction among these related high-level comments. I wanted each to act as a bullet point that frames both code and related interspersed low-level comments (without the risk of it looking like just another low-level comment). The numbers are inessential. Maybe I could do "Next step: " at the start of each comment instead. Leave it with me. > * As in 0001, core logical changes are obscured by moving code and > changing it in the same patch. All this logic gets moved into > lazy_scan_prune() and revised at the same time. Using git diff > --color-moved -w sorta works, but even then there are parts of it that > are pretty hard to read, because there's a bunch of other stuff that > gets rejiggered at the same time. Theoretically, nothing really changes until the third patch, except for the way that we do the INDEX_CLEANUP=off stuff. What you say about 0001 is understandable and not that surprising. But FWIW 0002 doesn't move code around in the same way as 0001 -- it is not nearly as mechanical. Like I said, let me see if the lazy_scan_* functions from 0002 are adding much (aside from lazy_scan_prune(), of course). To be honest they were a bit of an afterthought -- lazy_scan_prune() was my focus in 0002. I can imagine adding a lot more stuff to lazy_scan_prune() in the future too. For example, maybe we can do more freezing earlier based on whether or not we can avoid dirtying the page by not freezing. The structure of lazy_scan_prune() can do stuff like that because it gets to see the page before and after both pruning and freezing -- and with the retry stuff in 0003, it can back out of an earlier decision to not freeze as soon as it realizes the page is getting dirtied either way. Also, I think we might end up collecting more complicated information that informs our eventual decision about whether or not indexes need to be vacuumed. > My concentration is flagging a bit so I'm going to stop reviewing here > for now. I'm not deeply opposed to any of what I've seen so far. My > main criticism is that I think more thought should be given to how > things are named and to separating minimal code-movement patches from > other changes. That seems totally reasonable. Thanks again! -- Peter Geoghegan
On Wed, Mar 31, 2021 at 4:45 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote:
> Both 0001 and 0002 patch refactors the whole lazy vacuum code. Can we
> merge them? I basically agree with the refactoring made by 0001 patch
> but I'm concerned a bit that having such a large refactoring at very
> close to feature freeze could be risky. We would need more eyes to
> review during stabilization.
I think that Robert makes some related points about how we might cut
scope here. So I'll definitely do some of that, maybe all of it.
> I think it's more clear to use this macro. The macro can be like this:
>
> ParallelVacuumIsActive(vacrel) (((LVRelState) vacrel)->lps != NULL)
Yes, that might be better. I'll consider it when I get back to the
patch tomorrow.
> + * LVDeadTuples stores TIDs that are gathered during pruning/the initial heap
> + * scan. These get deleted from indexes during index vacuuming. They're then
> + * removed from the heap during a second heap pass that performs heap
> + * vacuuming.
> */
>
> The second sentence of the removed lines still seems to be useful
> information for readers?
I don't think that the stuff about shared memory was useful, really.
If we say something like this then it should be about the LVRelState
pointer, not the struct.
> - * We do not process them because it's
> a very rare condition,
> - * and the next vacuum will process them anyway.
>
> Maybe the above comments should not be removed by 0001 patch.
Right.
> Looking at the comments, I thought that this function also frees
> palloc'd dead tuple space but it doesn't. It seems to more clear that
> doing pfree(vacrel->dead_tuples) here or not creating
> lazy_space_free().
I'll need to think about this some more.
> ---
> + if (shared_istat)
> + {
> + /* Get the space for IndexBulkDeleteResult */
> + bulkdelete_res = &(shared_istat->istat);
> +
> + /*
> + * Update the pointer to the corresponding
> bulk-deletion result if
> + * someone has already updated it.
> + */
> + if (shared_istat->updated && istat == NULL)
> + istat = bulkdelete_res;
> + }
>
> (snip)
>
> + if (shared_istat && !shared_istat->updated && istat != NULL)
> + {
> + memcpy(bulkdelete_res, istat, sizeof(IndexBulkDeleteResult));
> + shared_istat->updated = true;
> +
> + /*
> + * Now that top-level indstats[idx] points to the DSM
> segment, we
> + * don't need the locally allocated results.
> + */
> + pfree(istat);
> + istat = bulkdelete_res;
> + }
> +
> + return istat;
>
> If we have parallel_process_one_index() return the address of
> IndexBulkDeleteResult, we can simplify the first part above. Also, it
> seems better to use a separate variable from istat to store the
> result. How about the following structure?
I'll try it that way and see how it goes.
> + /* This won't have changed: */
> + Assert(savefreespace && freespace == PageGetHeapFreeSpace(page));
>
> This assertion can be false because freespace can be 0 if the page's
> PD_HAS_FREE_LINES hint can wrong. Since lazy_vacuum_heap_page() fixes
> it, PageGetHeapFreeSpace(page) in the assertion returns non-zero
> value.
Good catch, I'll fix it.
> The first vacrel->relname should be vacrel->relnamespace.
Will fix.
> I think we can use errmsg_plural() for "X index scans" part.
Yeah, I think that that would be more consistent.
> We should use vacrel->lpdead_item_pages instead of vacrel->rel_pages
Will fix. I was mostly focussed on the log_autovacuum version, which
is why it looks nice already.
> ---
> + /* Stop applying cost limits from this point on */
> + VacuumCostActive = false;
> + VacuumCostBalance = 0;
> + }
>
> I agree with the idea of disabling vacuum delay in emergency cases.
> But why do we do that only in the case of the table with indexes? I
> think this optimization is helpful even in the table with no indexes.
> We can check the XID wraparound emergency by calling
> vacuum_xid_limit_emergency() at some point to disable vacuum delay?
Hmm. I see your point, but at the same time I think that the risk is
lower on a table that has no indexes. It may be true that index
vacuuming doesn't necessarily take the majority of all of the work in
lots of cases. But I think that it is true that it does when things
get very bad -- one-pass/no indexes VACUUM does not care about
maintenance_work_mem, etc.
But let me think about it...I suppose we could do it when one-pass
VACUUM considers vacuuming a range of FSM pages every
VACUUM_FSM_EVERY_PAGES. That's kind of similar to index vacuuming, in
a way -- it wouldn't be too bad to check for emergencies in the same
way there.
> Both vacrel->do_index_vacuuming and vacrel->do_index_cleanup can be
> false also when INDEX_CLEANUP is off. So autovacuum could wrongly
> report emergency if the table's vacuum_index_vacuum reloption is
> false.
Good point. I will need to account for that so that log_autovacuum's
LOG message does the right thing. Perhaps for other reasons, too.
Thanks for the review!
--
Peter Geoghegan
On Thu, Apr 1, 2021 at 9:58 AM Peter Geoghegan <pg@bowt.ie> wrote: > > On Wed, Mar 31, 2021 at 4:45 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > Both 0001 and 0002 patch refactors the whole lazy vacuum code. Can we > > merge them? I basically agree with the refactoring made by 0001 patch > > but I'm concerned a bit that having such a large refactoring at very > > close to feature freeze could be risky. We would need more eyes to > > review during stabilization. > > I think that Robert makes some related points about how we might cut > scope here. So I'll definitely do some of that, maybe all of it. > > > I think it's more clear to use this macro. The macro can be like this: > > > > ParallelVacuumIsActive(vacrel) (((LVRelState) vacrel)->lps != NULL) > > Yes, that might be better. I'll consider it when I get back to the > patch tomorrow. > > > + * LVDeadTuples stores TIDs that are gathered during pruning/the initial heap > > + * scan. These get deleted from indexes during index vacuuming. They're then > > + * removed from the heap during a second heap pass that performs heap > > + * vacuuming. > > */ > > > > The second sentence of the removed lines still seems to be useful > > information for readers? > > I don't think that the stuff about shared memory was useful, really. > If we say something like this then it should be about the LVRelState > pointer, not the struct. Understood. > > --- > > + /* Stop applying cost limits from this point on */ > > + VacuumCostActive = false; > > + VacuumCostBalance = 0; > > + } > > > > I agree with the idea of disabling vacuum delay in emergency cases. > > But why do we do that only in the case of the table with indexes? I > > think this optimization is helpful even in the table with no indexes. > > We can check the XID wraparound emergency by calling > > vacuum_xid_limit_emergency() at some point to disable vacuum delay? > > Hmm. I see your point, but at the same time I think that the risk is > lower on a table that has no indexes. It may be true that index > vacuuming doesn't necessarily take the majority of all of the work in > lots of cases. But I think that it is true that it does when things > get very bad -- one-pass/no indexes VACUUM does not care about > maintenance_work_mem, etc. Agreed. > > But let me think about it...I suppose we could do it when one-pass > VACUUM considers vacuuming a range of FSM pages every > VACUUM_FSM_EVERY_PAGES. That's kind of similar to index vacuuming, in > a way -- it wouldn't be too bad to check for emergencies in the same > way there. Yeah, I also thought that would be a good place to check for emergencies. That sounds reasonable. Regards, -- Masahiko Sawada EDB: https://www.enterprisedb.com/
On Wed, Mar 31, 2021 at 9:44 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > But let me think about it...I suppose we could do it when one-pass > > VACUUM considers vacuuming a range of FSM pages every > > VACUUM_FSM_EVERY_PAGES. That's kind of similar to index vacuuming, in > > a way -- it wouldn't be too bad to check for emergencies in the same > > way there. > > Yeah, I also thought that would be a good place to check for > emergencies. That sounds reasonable. Without offering an opinion on this particular implementation choice, +1 for the idea of trying to make the table-with-indexes and the table-without-indexes cases work in ways that will feel similar to the user. Tables without indexes are probably rare in practice, but if some behaviors are implemented for one case and not the other, it will probably be confusing. One thought here is that it might help to try to write documentation for whatever behavior you choose. If it's hard to document without weasel-words, maybe it's not the best approach. -- Robert Haas EDB: http://www.enterprisedb.com
On Thu, Apr 1, 2021 at 6:14 AM Robert Haas <robertmhaas@gmail.com> wrote: > Without offering an opinion on this particular implementation choice, > +1 for the idea of trying to make the table-with-indexes and the > table-without-indexes cases work in ways that will feel similar to the > user. Tables without indexes are probably rare in practice, but if > some behaviors are implemented for one case and not the other, it will > probably be confusing. One thought here is that it might help to try > to write documentation for whatever behavior you choose. If it's hard > to document without weasel-words, maybe it's not the best approach. I have found a way to do this that isn't too painful, a little like the VACUUM_FSM_EVERY_PAGES thing. I've also found a way to further simplify the table-without-indexes case: make it behave like a regular two-pass/has-indexes VACUUM with regard to visibility map stuff when the page doesn't need a call to lazy_vacuum_heap() (because there are no LP_DEAD items to set LP_UNUSED on the page following pruning). But when it does call lazy_vacuum_heap(), the call takes care of everything for lazy_scan_heap(), which just continues to the next page due to considering prunestate to have been "invalidated" by the call to lazy_vacuum_heap(). So there is absolutely minimal special case code for the table-without-indexes case now. BTW I removed all of the lazy_scan_heap() utility functions from the second patch in my working copy of the patch series. You were right about that -- they weren't useful. We should just have the pruning wrapper function I've called lazy_scan_prune(), not any of the others. We only need one local variable in the lazy_vacuum_heap() that isn't either the prune state set/returned by lazy_scan_prune(), or generic stuff like a Buffer variable. -- Peter Geoghegan
On Thu, Apr 1, 2021 at 8:25 PM Peter Geoghegan <pg@bowt.ie> wrote: > I've also found a way to further simplify the table-without-indexes > case: make it behave like a regular two-pass/has-indexes VACUUM with > regard to visibility map stuff when the page doesn't need a call to > lazy_vacuum_heap() (because there are no LP_DEAD items to set > LP_UNUSED on the page following pruning). But when it does call > lazy_vacuum_heap(), the call takes care of everything for > lazy_scan_heap(), which just continues to the next page due to > considering prunestate to have been "invalidated" by the call to > lazy_vacuum_heap(). So there is absolutely minimal special case code > for the table-without-indexes case now. Attached is v10, which simplifies the one-pass/table-without-indexes VACUUM as described. Other changes (some of which are directly related to the one-pass/table-without-indexes refactoring): * The second patch no longer breaks up lazy_scan_heap() into multiple functions -- we only retain the lazy_scan_prune() function, which is the one that I find very compelling. This addresses Robert's concern about the functions -- I think that it's much better this way, now that I see it. * No more diff churn in the first patch. This was another concern held by Robert, as well as by Masahiko. In general both the first and second patches are much easier to follow now. * The emergency mechanism is now able to kick in when we happen to be doing a one-pass/table-without-indexes VACUUM -- no special cases/"weasel words" are needed. * Renamed "onerel" to "rel" in the first patch, per Robert's suggestion. * Fixed various specific issues raised by Masahiko's review, particularly in the first patch and last patch in the series. Finally, there is a new patch added to the series in v10: * I now include a modified version of Matthias van de Meent's line pointer truncation patch [1]. Matthias' patch seems very much in scope here. The broader patch series establishes the principle that we can leave LP_DEAD line pointers in an unreclaimed state indefinitely, without consequence (beyond the obvious). We had better avoid line pointer bloat that cannot be reversed when VACUUM does eventually get around to doing a second pass over the heap. This is another case where it seems prudent to keep the costs understandable/linear -- page-level line pointer bloat seems like a cost that increases in a non-linear fashion, which undermines the whole idea of modelling when it's okay to skip index/heap vacuuming. (Also, line pointer bloat sucks.) Line pointer truncation doesn't happen during pruning, as it did in Matthias' original patch. In this revised version, line pointer truncation occurs during the second phase of VACUUM. There are several reasons to prefer this approach. It seems both safer and more useful that way (compared to the approach of doing line pointer truncation during pruning). It also makes intuitive sense to do it this way, at least to me -- the second pass over the heap is supposed to be for "freeing" LP_DEAD line pointers. Many workloads rely heavily on opportunistic pruning. With a workload that benefits a lot from HOT (e.g. pgbench with heap fillfactor reduced to 90), there are many LP_UNUSED line pointers, even though we may never have a VACUUM that actually performs a second heap pass (because LP_DEAD items cannot accumulate in heap pages). Prior to the HOT commit in 2007, LP_UNUSED line pointers were strictly something that VACUUM created from dead tuples. It seems to me that we should only target the latter "category" of LP_UNUSED line pointers when considering truncating the array -- we ought to leave pruning (especially opportunistic pruning that takes place outside of VACUUM) alone. (That reminds me -- the second patch now makes VACUUM VERBOSE stop reporting LP_UNUSED items, because it is so utterly misleading/confusing -- it now reports on LP_DEAD items instead, which will bring things in line with log_autovacuum output once the last patch in the series is in. This is arguably an oversight in the HOT commit made back in 2007 -- that work kind of created a second distinct category of LP_UNUSED item that really is totally different, but it didn't account for why that makes stats about LP_UNUSED items impossible to reason about.) Doing truncation during VACUUM's second heap pass this way also makes the line pointer truncation mechanism more effective. The problem with truncating the LP array during pruning is that we more or less never prune when the page is 100% (not ~99%) free of non-LP_UNUSED items -- which is actually the most compelling case for line pointer array truncation! You can see this with a workload that consists of alternating range deletions and bulk insertions that reuse the same space -- think of a queue pattern, or TPC-C's new_orders table. Under this scheme, we catch that extreme (though important) case every time -- because we consider LP_UNUSED items immediately after they become LP_UNUSED. [1] https://postgr.es/m/CAEze2WjgaQc55Y5f5CQd3L=eS5CZcff2Obxp=O6pto8-f0hC4w@mail.gmail.com -- Peter Geoghegan
Вложения
On Sun, Apr 4, 2021 at 11:00 AM Peter Geoghegan <pg@bowt.ie> wrote:
>
> On Thu, Apr 1, 2021 at 8:25 PM Peter Geoghegan <pg@bowt.ie> wrote:
> > I've also found a way to further simplify the table-without-indexes
> > case: make it behave like a regular two-pass/has-indexes VACUUM with
> > regard to visibility map stuff when the page doesn't need a call to
> > lazy_vacuum_heap() (because there are no LP_DEAD items to set
> > LP_UNUSED on the page following pruning). But when it does call
> > lazy_vacuum_heap(), the call takes care of everything for
> > lazy_scan_heap(), which just continues to the next page due to
> > considering prunestate to have been "invalidated" by the call to
> > lazy_vacuum_heap(). So there is absolutely minimal special case code
> > for the table-without-indexes case now.
>
> Attached is v10, which simplifies the one-pass/table-without-indexes
> VACUUM as described.
>
Thank you for updating the patch.
>
> * I now include a modified version of Matthias van de Meent's line
> pointer truncation patch [1].
>
> Matthias' patch seems very much in scope here. The broader patch
> series establishes the principle that we can leave LP_DEAD line
> pointers in an unreclaimed state indefinitely, without consequence
> (beyond the obvious). We had better avoid line pointer bloat that
> cannot be reversed when VACUUM does eventually get around to doing a
> second pass over the heap. This is another case where it seems prudent
> to keep the costs understandable/linear -- page-level line pointer
> bloat seems like a cost that increases in a non-linear fashion, which
> undermines the whole idea of modelling when it's okay to skip
> index/heap vacuuming. (Also, line pointer bloat sucks.)
>
> Line pointer truncation doesn't happen during pruning, as it did in
> Matthias' original patch. In this revised version, line pointer
> truncation occurs during the second phase of VACUUM. There are several
> reasons to prefer this approach. It seems both safer and more useful
> that way (compared to the approach of doing line pointer truncation
> during pruning). It also makes intuitive sense to do it this way, at
> least to me -- the second pass over the heap is supposed to be for
> "freeing" LP_DEAD line pointers.
+1
0002, 0003, and 0004 patches look good to me. 0001 and 0005 also look
good to me but I have some trivial review comments on them.
0001 patch:
/*
- * Now that stats[idx] points to the DSM segment, we
don't need the
- * locally allocated results.
+ * Now that top-level indstats[idx] points to the DSM
segment, we
+ * don't need the locally allocated results.
*/
- pfree(*stats);
- *stats = bulkdelete_res;
+ pfree(istat);
+ istat = bulkdelete_res;
Did you try the change around parallel_process_one_index() that I
suggested in the previous reply[1]? If we don't change the logic, we
need to update the above comment. Previously, we update stats[idx] in
vacuum_one_index() (renamed to parallel_process_one_index()) but with
your patch, where we update it is its caller.
---
+lazy_vacuum_all_indexes(LVRelState *vacrel)
{
- Assert(!IsParallelWorker());
- Assert(nindexes > 0);
+ Assert(vacrel->nindexes > 0);
+ Assert(TransactionIdIsNormal(vacrel->relfrozenxid));
+ Assert(MultiXactIdIsValid(vacrel->relminmxid));
and
- Assert(!IsParallelWorker());
- Assert(nindexes > 0);
+ Assert(vacrel->nindexes > 0);
We removed two Assert(!IsParallelWorker()) at two places. It seems to
me that those assertions are still valid. Do we really need to remove
them?
---
0004 patch:
src/backend/access/heap/heapam.c:638: trailing whitespace.
+ /*
I found a whitespace issue.
---
0005 patch:
+ * Caller is expected to call here before and after vacuuming each index in
+ * the case of two-pass VACUUM, or every BYPASS_EMERGENCY_MIN_PAGES blocks in
+ * the case of no-indexes/one-pass VACUUM.
I think it should be "every VACUUM_FSM_EVERY_PAGES blocks" instead of
"every BYPASS_EMERGENCY_MIN_PAGES blocks".
---
+/*
+ * Threshold that controls whether we bypass index vacuuming and heap
+ * vacuuming. When we're under the threshold they're deemed unnecessary.
+ * BYPASS_THRESHOLD_PAGES is applied as a multiplier on the table's rel_pages
+ * for those pages known to contain one or more LP_DEAD items.
+ */
+#define BYPASS_THRESHOLD_PAGES 0.02 /* i.e. 2% of rel_pages */
+
+#define BYPASS_EMERGENCY_MIN_PAGES \
+ ((BlockNumber) (((uint64) 4 * 1024 * 1024 * 1024) / BLCKSZ))
+
I think we need a description for BYPASS_EMERGENCY_MIN_PAGES.
---
for (int idx = 0; idx < vacrel->nindexes; idx++)
{
Relation indrel = vacrel->indrels[idx];
IndexBulkDeleteResult *istat = vacrel->indstats[idx];
vacrel->indstats[idx] =
lazy_vacuum_one_index(indrel, istat, vacrel->old_live_tuples,
vacrel);
+
+ if (should_speedup_failsafe(vacrel))
+ {
+ /* Wraparound emergency -- end current index scan */
+ allindexes = false;
+ break;
+ }
allindexes can be false even if we process all indexes, which is fine
with me because setting allindexes = false disables the subsequent
heap vacuuming. I think it's appropriate behavior in emergency cases.
In that sense, can we do should_speedup_failsafe() check also after
parallel index vacuuming? And we can also check it at the beginning of
lazy vacuum.
Regards,
[1] https://www.postgresql.org/message-id/CAD21AoDOWo4H6vmtLZoJ2SznMp_zOej2Kww%2BJBkVRPXs%2Bj48uw%40mail.gmail.com
--
Masahiko Sawada
EDB: https://www.enterprisedb.com/
On Sun, 4 Apr 2021 at 04:00, Peter Geoghegan <pg@bowt.ie> wrote:
>
> On Thu, Apr 1, 2021 at 8:25 PM Peter Geoghegan <pg@bowt.ie> wrote:
> > I've also found a way to further simplify the table-without-indexes
> > case: make it behave like a regular two-pass/has-indexes VACUUM with
> > regard to visibility map stuff when the page doesn't need a call to
> > lazy_vacuum_heap() (because there are no LP_DEAD items to set
> > LP_UNUSED on the page following pruning). But when it does call
> > lazy_vacuum_heap(), the call takes care of everything for
> > lazy_scan_heap(), which just continues to the next page due to
> > considering prunestate to have been "invalidated" by the call to
> > lazy_vacuum_heap(). So there is absolutely minimal special case code
> > for the table-without-indexes case now.
>
> Attached is v10, which simplifies the one-pass/table-without-indexes
> VACUUM as described.
Great!
> Other changes (some of which are directly related to the
> one-pass/table-without-indexes refactoring):
>
> * The second patch no longer breaks up lazy_scan_heap() into multiple
> functions -- we only retain the lazy_scan_prune() function, which is
> the one that I find very compelling.
>
> This addresses Robert's concern about the functions -- I think that
> it's much better this way, now that I see it.
>
> * No more diff churn in the first patch. This was another concern held
> by Robert, as well as by Masahiko.
>
> In general both the first and second patches are much easier to follow now.
>
> * The emergency mechanism is now able to kick in when we happen to be
> doing a one-pass/table-without-indexes VACUUM -- no special
> cases/"weasel words" are needed.
>
> * Renamed "onerel" to "rel" in the first patch, per Robert's suggestion.
>
> * Fixed various specific issues raised by Masahiko's review,
> particularly in the first patch and last patch in the series.
>
> Finally, there is a new patch added to the series in v10:
>
> * I now include a modified version of Matthias van de Meent's line
> pointer truncation patch [1].
Thanks for notifying. I've noticed that you've based this on v3 of
that patch, and consequently has at least one significant bug that I
fixed in v5 of that patchset:
0004:
> @@ -962,6 +962,7 @@ heap_get_root_tuples(Page page, OffsetNumber *root_offsets)
> */
> for (;;)
> {
> + Assert(OffsetNumberIsValid(nextoffnum) && nextoffnum <= maxoff);
> lp = PageGetItemId(page, nextoffnum);
>
> /* Check for broken chains */
This assertion is false, and should be a guarding if-statement. HOT
redirect pointers are not updated if the tuple they're pointing to is
vacuumed (i.e. when it was never committed) so this nextoffnum might
in a correctly working system point past maxoff.
> Line pointer truncation doesn't happen during pruning, as it did in
> Matthias' original patch. In this revised version, line pointer
> truncation occurs during the second phase of VACUUM. There are several
> reasons to prefer this approach. It seems both safer and more useful
> that way (compared to the approach of doing line pointer truncation
> during pruning). It also makes intuitive sense to do it this way, at
> least to me -- the second pass over the heap is supposed to be for
> "freeing" LP_DEAD line pointers.
Good catch for running a line pointer truncating pass at the second
pass over the heap in VACUUM, but I believe that it is also very
useful for pruning. Line pointer bloat due to excessive HOT chains
cannot be undone until the 2nd run of VACUUM happens with this patch,
which is a missed chance for all non-vacuum pruning.
> Many workloads rely heavily on opportunistic pruning. With a workload
> that benefits a lot from HOT (e.g. pgbench with heap fillfactor
> reduced to 90), there are many LP_UNUSED line pointers, even though we
> may never have a VACUUM that actually performs a second heap pass
> (because LP_DEAD items cannot accumulate in heap pages). Prior to the
> HOT commit in 2007, LP_UNUSED line pointers were strictly something
> that VACUUM created from dead tuples. It seems to me that we should
> only target the latter "category" of LP_UNUSED line pointers when
> considering truncating the array -- we ought to leave pruning
> (especially opportunistic pruning that takes place outside of VACUUM)
> alone.
What difference is there between opportunistically pruned HOT line
pointers, and VACUUMed line pointers? Truncating during pruning has
the benefit of keeping the LP array short where possible, and seeing
that truncating the LP array allows for more applied
PD_HAS_FREE_LINES-optimization, I fail to see why you wouldn't want to
truncate the LP array whenever clearing up space.
Other than those questions, some comments on the other patches:
0002:
> + appendStringInfo(&buf, _("There were %lld dead item identifiers.\n"),
> + (long long) vacrel->lpdead_item_pages);
I presume this should use vacrel->lpdead_items?.
0003:
> + * ... Aborted transactions
> + * have tuples that we can treat as DEAD without caring about where there
> + * tuple header XIDs ...
This should be '... where their tuple header XIDs...'
> +retry:
> +
> ...
> + res = HeapTupleSatisfiesVacuum(&tuple, vacrel->OldestXmin, buf);
> +
> + if (unlikely(res == HEAPTUPLE_DEAD))
> + goto retry;
In this unlikely case, you reset the tuples_deleted value that was
received earlier from heap_page_prune. This results in inaccurate
statistics, as repeated calls to heap_page_prune on the same page will
not count tuples that were deleted in a previous call.
0004:
> + * truncate to. Note that we avoid truncating the line pointer to 0 items
> + * in all cases.
> + */
Is there a specific reason that I'm not getting as to why this is necessary?
0005:
> + The default is 1.8 billion transactions. Although users can set this value
> + anywhere from zero to 2.1 billion, <command>VACUUM</command> will silently
> + adjust the effective value more than 105% of
> + <xref linkend="guc-autovacuum-freeze-max-age"/>, so that only
> + anti-wraparound autovacuums and aggressive scans have a chance to skip
> + index cleanup.
This documentation doesn't quite make it clear what its relationship
is with autovacuum_freeze_max_age. How about the following: "...
>VACUUM< will use the higher of this value and 105% of
>guc-autovacuum-freeze-max-age<, so that only ...". It's only slightly
easier to read, but at least it conveys that values lower than 105% of
autovacuum_freeze_max_age are not considered. The same can be said for
the multixact guc documentation.
With regards,
Matthias van de Meent
On Mon, Apr 5, 2021 at 4:30 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > Did you try the change around parallel_process_one_index() that I > suggested in the previous reply[1]? If we don't change the logic, we > need to update the above comment. Previously, we update stats[idx] in > vacuum_one_index() (renamed to parallel_process_one_index()) but with > your patch, where we update it is its caller. I don't know how I missed it the first time. I agree that it is a lot better that way. I did it that way in the version of the patch that I pushed just now. Thanks! Do you think that it's okay that we rely on the propagation of global state to parallel workers on Postgres 13? Don't we need something like my fixup commit 49f49def on Postgres 13 as well? At least for the EXEC_BACKEND case, I think. > We removed two Assert(!IsParallelWorker()) at two places. It seems to > me that those assertions are still valid. Do we really need to remove > them? I have restored the assertions in what became the final version. > 0004 patch: > > src/backend/access/heap/heapam.c:638: trailing whitespace. Will fix. > --- > 0005 patch: > > + * Caller is expected to call here before and after vacuuming each index in > + * the case of two-pass VACUUM, or every BYPASS_EMERGENCY_MIN_PAGES blocks in > + * the case of no-indexes/one-pass VACUUM. > > I think it should be "every VACUUM_FSM_EVERY_PAGES blocks" instead of > "every BYPASS_EMERGENCY_MIN_PAGES blocks". Will fix. > +#define BYPASS_EMERGENCY_MIN_PAGES \ > + ((BlockNumber) (((uint64) 4 * 1024 * 1024 * 1024) / BLCKSZ)) > + > > I think we need a description for BYPASS_EMERGENCY_MIN_PAGES. I agree - will fix. > allindexes can be false even if we process all indexes, which is fine > with me because setting allindexes = false disables the subsequent > heap vacuuming. I think it's appropriate behavior in emergency cases. > In that sense, can we do should_speedup_failsafe() check also after > parallel index vacuuming? And we can also check it at the beginning of > lazy vacuum. Those both seem like good ideas. Especially the one about checking right at the start. Now that the patch makes the emergency mechanism not apply a delay (not just skip index vacuuming), having a precheck at the very start makes a lot of sense. This also makes VACUUM hurry in the case where there was a dangerously slow VACUUM that happened to not be aggressive. Such a VACUUM will use the emergency mechanism but won't advance relfrozenxid, because we have to rely on the autovacuum launcher launching an anti-wraparound/aggressive autovacuum immediately afterwards. We want that second anti-wraparound VACUUM to hurry from the very start of lazy_scan_heap(). -- Peter Geoghegan
Peter Geoghegan <pg@bowt.ie> writes:
> Do you think that it's okay that we rely on the propagation of global
> state to parallel workers on Postgres 13? Don't we need something like
> my fixup commit 49f49def on Postgres 13 as well? At least for the
> EXEC_BACKEND case, I think.
Uh ... *what* propagation of global state to parallel workers? Workers
fork off from the postmaster, not from their leader process.
(I note that morepork is still failing. The other ones didn't report
in yet.)
regards, tom lane
On Tue, Apr 6, 2021 at 8:29 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > > Peter Geoghegan <pg@bowt.ie> writes: > > Do you think that it's okay that we rely on the propagation of global > > state to parallel workers on Postgres 13? Don't we need something like > > my fixup commit 49f49def on Postgres 13 as well? At least for the > > EXEC_BACKEND case, I think. > > Uh ... *what* propagation of global state to parallel workers? Workers > fork off from the postmaster, not from their leader process. Right. I think we should apply that fix on PG13 as well. Regards, -- Masahiko Sawada EDB: https://www.enterprisedb.com/
On Mon, Apr 5, 2021 at 4:29 PM Tom Lane <tgl@sss.pgh.pa.us> wrote: > Peter Geoghegan <pg@bowt.ie> writes: > > Do you think that it's okay that we rely on the propagation of global > > state to parallel workers on Postgres 13? Don't we need something like > > my fixup commit 49f49def on Postgres 13 as well? At least for the > > EXEC_BACKEND case, I think. > > Uh ... *what* propagation of global state to parallel workers? Workers > fork off from the postmaster, not from their leader process. > > (I note that morepork is still failing. The other ones didn't report > in yet.) Evidently my fixup commit 49f49def was written in way too much of a panic. I'm going to push a new fix shortly. This will make workers do their own GetAccessStrategy(BAS_VACUUM), just to get the buildfarm green. REL_13_STABLE will need to be considered separately. I still haven't figured out how this ever appeared to work for this long. The vac_strategy/bstrategy state simply wasn't propagated at all. -- Peter Geoghegan
Hi, On 2021-04-05 16:53:58 -0700, Peter Geoghegan wrote: > REL_13_STABLE will need to be considered separately. I still haven't > figured out how this ever appeared to work for this long. The > vac_strategy/bstrategy state simply wasn't propagated at all. What do you mean with "appear to work"? Isn't, in 13, the only consequence of vac_strategy not being "propagated" that we'll not use a strategy in parallel workers? Presumably that was hard to notice because most people don't run manual VACUUM with cost limits turned on. And autovacuum doesn't use parallelism. Greetings, Andres Freund
On Mon, Apr 5, 2021 at 5:00 PM Andres Freund <andres@anarazel.de> wrote: > What do you mean with "appear to work"? Isn't, in 13, the only > consequence of vac_strategy not being "propagated" that we'll not use a > strategy in parallel workers? Presumably that was hard to notice > because most people don't run manual VACUUM with cost limits turned > on. And autovacuum doesn't use parallelism. Oh yeah. "static BufferAccessStrategy vac_strategy" is guaranteed to be initialized to 0, simply because it's static and global. That explains it. -- Peter Geoghegan
On Mon, Apr 5, 2021 at 5:09 PM Peter Geoghegan <pg@bowt.ie> wrote: > Oh yeah. "static BufferAccessStrategy vac_strategy" is guaranteed to > be initialized to 0, simply because it's static and global. That > explains it. So do we need to allocate a strategy in workers now, or leave things as they are/were? I'm going to go ahead with pushing my commit to do that now, just to get the buildfarm green. It's still a bug in Postgres 13, albeit a less serious one than I first suspected. -- Peter Geoghegan
Hi, On 2021-04-05 17:18:37 -0700, Peter Geoghegan wrote: > On Mon, Apr 5, 2021 at 5:09 PM Peter Geoghegan <pg@bowt.ie> wrote: > > Oh yeah. "static BufferAccessStrategy vac_strategy" is guaranteed to > > be initialized to 0, simply because it's static and global. That > > explains it. > > So do we need to allocate a strategy in workers now, or leave things > as they are/were? > I'm going to go ahead with pushing my commit to do that now, just to > get the buildfarm green. It's still a bug in Postgres 13, albeit a > less serious one than I first suspected. Feels like a v13 bug to me, one that should be fixed. Greetings, Andres Freund
On Mon, Apr 5, 2021 at 2:44 PM Matthias van de Meent
<boekewurm+postgres@gmail.com> wrote:
> This assertion is false, and should be a guarding if-statement. HOT
> redirect pointers are not updated if the tuple they're pointing to is
> vacuumed (i.e. when it was never committed) so this nextoffnum might
> in a correctly working system point past maxoff.
I will need to go through this in detail soon.
> > Line pointer truncation doesn't happen during pruning, as it did in
> > Matthias' original patch. In this revised version, line pointer
> > truncation occurs during the second phase of VACUUM. There are several
> > reasons to prefer this approach. It seems both safer and more useful
> > that way (compared to the approach of doing line pointer truncation
> > during pruning). It also makes intuitive sense to do it this way, at
> > least to me -- the second pass over the heap is supposed to be for
> > "freeing" LP_DEAD line pointers.
>
> Good catch for running a line pointer truncating pass at the second
> pass over the heap in VACUUM, but I believe that it is also very
> useful for pruning. Line pointer bloat due to excessive HOT chains
> cannot be undone until the 2nd run of VACUUM happens with this patch,
> which is a missed chance for all non-vacuum pruning.
Maybe - I have my doubts about it having much value outside of the
more extreme cases. But let's assume that I'm wrong about that, for
the sake of argument.
The current plan is to no longer require a super-exclusive lock inside
lazy_vacuum_heap_page(), which means that we can no longer safely call
PageRepairFragmentation() at that point. This will mean that
PageRepairFragmentation() is 100% owned by pruning. And so the
question of whether or not line pointer truncation should also happen
in PageRepairFragmentation() to cover pruning is (or will be) a
totally separate question to the question of how
lazy_vacuum_heap_page() does it. Nothing stops you from independently
pursuing that as a project for Postgres 15.
> What difference is there between opportunistically pruned HOT line
> pointers, and VACUUMed line pointers?
The fact that they are physically identical to each other isn't
everything. The "life cycle" of an affected page is crucially
important.
I find that there is a lot of value in thinking about how things look
at the page level moment to moment, and even over hours and days.
Usually with a sample workload and table in mind. I already mentioned
the new_order table from TPC-C, which is characterized by continual
churn from more-or-less even amounts of range deletes and bulk inserts
over time. That seems to be the kind of workload where you see big
problems with line pointer bloat. Because there is constant churn of
unrelated logical rows (it's not a bunch of UPDATEs).
It's possible for very small effects to aggregate into large and
significant effects -- I know this from my experience with indexing.
Plus the FSM is probably not very smart about fragmentation, which
makes it even more complicated. And so it's easy to be wrong if you
predict that some seemingly insignificant extra intervention couldn't
possibly help. For that reason, I don't want to predict that you're
wrong now. It's just a question of time, and of priorities.
> Truncating during pruning has
> the benefit of keeping the LP array short where possible, and seeing
> that truncating the LP array allows for more applied
> PD_HAS_FREE_LINES-optimization, I fail to see why you wouldn't want to
> truncate the LP array whenever clearing up space.
Truncating the line pointer array is not an intrinsic good. I hesitate
to do it during pruning in the absence of clear evidence that it's
independently useful. Pruning is a very performance sensitive
operation. Much more so than VACUUM's second heap pass.
> Other than those questions, some comments on the other patches:
>
> 0002:
> > + appendStringInfo(&buf, _("There were %lld dead item identifiers.\n"),
> > + (long long) vacrel->lpdead_item_pages);
>
> I presume this should use vacrel->lpdead_items?.
It should have been, but as it happens I have decided to not do this
at all in 0002-*. Better to not report on LP_UNUSED *or* LP_DEAD items
at this point of VACUUM VERBOSE output.
> 0003:
> > + * ... Aborted transactions
> > + * have tuples that we can treat as DEAD without caring about where there
> > + * tuple header XIDs ...
>
> This should be '... where their tuple header XIDs...'
Will fix.
> > +retry:
> > +
> > ...
> > + res = HeapTupleSatisfiesVacuum(&tuple, vacrel->OldestXmin, buf);
> > +
> > + if (unlikely(res == HEAPTUPLE_DEAD))
> > + goto retry;
>
> In this unlikely case, you reset the tuples_deleted value that was
> received earlier from heap_page_prune. This results in inaccurate
> statistics, as repeated calls to heap_page_prune on the same page will
> not count tuples that were deleted in a previous call.
I don't think that it matters. The "tupgone=true" case has no test
coverage (see coverage.postgresql.org), and it would be hard to ensure
that the "res == HEAPTUPLE_DEAD" that replaces it gets coverage, for
the same reasons. Keeping the rules as simple as possible seem like a
good goal. What's more, it's absurdly unlikely that this will happen
even once. The race is very tight. Postgres will do opportunistic
pruning at almost any point, often from a SELECT, so the chances of
anybody noticing an inaccuracy from this issue in particular are
remote in the extreme.
Actually, a big problem with the tuples_deleted value surfaced by both
log_autovacuum and by VACUUM VERBOSE is that it can be wildly
different to the number of LP_DEAD items. This is commonly the case
with tables that get lots of non-HOT updates, with opportunistic
pruning kicking in a lot, with LP_DEAD items constantly accumulating.
By the time VACUUM comes around, it reports an absurdly low
tuples_deleted because it's using this what-I-pruned-just-now
definition. The opposite extreme is also possible, since there might
be far fewer LP_DEAD items when VACUUM does a lot of pruning of HOT
chains specifically.
> 0004:
> > + * truncate to. Note that we avoid truncating the line pointer to 0 items
> > + * in all cases.
> > + */
>
> Is there a specific reason that I'm not getting as to why this is necessary?
I didn't say it was strictly necessary. There is special-case handling
of PageIsEmpty() at various points, though, including within VACUUM.
It seemed worth avoiding hitting that. Perhaps I should change it to
not work that way.
> 0005:
> > + The default is 1.8 billion transactions. Although users can set this value
> > + anywhere from zero to 2.1 billion, <command>VACUUM</command> will silently
> > + adjust the effective value more than 105% of
> > + <xref linkend="guc-autovacuum-freeze-max-age"/>, so that only
> > + anti-wraparound autovacuums and aggressive scans have a chance to skip
> > + index cleanup.
>
> This documentation doesn't quite make it clear what its relationship
> is with autovacuum_freeze_max_age. How about the following: "...
> >VACUUM< will use the higher of this value and 105% of
> >guc-autovacuum-freeze-max-age<, so that only ...". It's only slightly
> easier to read, but at least it conveys that values lower than 105% of
> autovacuum_freeze_max_age are not considered. The same can be said for
> the multixact guc documentation.
This does need work too.
I'm going to push 0002- and 0003- tomorrow morning pacific time. I'll
publish a new set of patches tomorrow, once I've finished that up. The
last 2 patches will require a lot of focus to get over the line for
Postgres 14.
--
Peter Geoghegan
On Tue, 6 Apr 2021 at 05:13, Peter Geoghegan <pg@bowt.ie> wrote:
>
> On Mon, Apr 5, 2021 at 2:44 PM Matthias van de Meent
> <boekewurm+postgres@gmail.com> wrote:
> > This assertion is false, and should be a guarding if-statement. HOT
> > redirect pointers are not updated if the tuple they're pointing to is
> > vacuumed (i.e. when it was never committed) so this nextoffnum might
> > in a correctly working system point past maxoff.
>
> I will need to go through this in detail soon.
>
> > > Line pointer truncation doesn't happen during pruning, as it did in
> > > Matthias' original patch. In this revised version, line pointer
> > > truncation occurs during the second phase of VACUUM. There are several
> > > reasons to prefer this approach. It seems both safer and more useful
> > > that way (compared to the approach of doing line pointer truncation
> > > during pruning). It also makes intuitive sense to do it this way, at
> > > least to me -- the second pass over the heap is supposed to be for
> > > "freeing" LP_DEAD line pointers.
> >
> > Good catch for running a line pointer truncating pass at the second
> > pass over the heap in VACUUM, but I believe that it is also very
> > useful for pruning. Line pointer bloat due to excessive HOT chains
> > cannot be undone until the 2nd run of VACUUM happens with this patch,
> > which is a missed chance for all non-vacuum pruning.
>
> Maybe - I have my doubts about it having much value outside of the
> more extreme cases. But let's assume that I'm wrong about that, for
> the sake of argument.
>
> The current plan is to no longer require a super-exclusive lock inside
> lazy_vacuum_heap_page(), which means that we can no longer safely call
> PageRepairFragmentation() at that point. This will mean that
> PageRepairFragmentation() is 100% owned by pruning. And so the
> question of whether or not line pointer truncation should also happen
> in PageRepairFragmentation() to cover pruning is (or will be) a
> totally separate question to the question of how
> lazy_vacuum_heap_page() does it. Nothing stops you from independently
> pursuing that as a project for Postgres 15.
Ah, then I misunderstood your intentions when you mentioned including
a modified version of my patch. In which case, I agree that improving
HOT pruning is indeed out of scope.
> > What difference is there between opportunistically pruned HOT line
> > pointers, and VACUUMed line pointers?
>
> The fact that they are physically identical to each other isn't
> everything. The "life cycle" of an affected page is crucially
> important.
>
> I find that there is a lot of value in thinking about how things look
> at the page level moment to moment, and even over hours and days.
> Usually with a sample workload and table in mind. I already mentioned
> the new_order table from TPC-C, which is characterized by continual
> churn from more-or-less even amounts of range deletes and bulk inserts
> over time. That seems to be the kind of workload where you see big
> problems with line pointer bloat. Because there is constant churn of
> unrelated logical rows (it's not a bunch of UPDATEs).
>
> It's possible for very small effects to aggregate into large and
> significant effects -- I know this from my experience with indexing.
> Plus the FSM is probably not very smart about fragmentation, which
> makes it even more complicated. And so it's easy to be wrong if you
> predict that some seemingly insignificant extra intervention couldn't
> possibly help. For that reason, I don't want to predict that you're
> wrong now. It's just a question of time, and of priorities.
>
> > Truncating during pruning has
> > the benefit of keeping the LP array short where possible, and seeing
> > that truncating the LP array allows for more applied
> > PD_HAS_FREE_LINES-optimization, I fail to see why you wouldn't want to
> > truncate the LP array whenever clearing up space.
>
> Truncating the line pointer array is not an intrinsic good. I hesitate
> to do it during pruning in the absence of clear evidence that it's
> independently useful. Pruning is a very performance sensitive
> operation. Much more so than VACUUM's second heap pass.
>
> > Other than those questions, some comments on the other patches:
> >
> > 0002:
> > > + appendStringInfo(&buf, _("There were %lld dead item identifiers.\n"),
> > > + (long long) vacrel->lpdead_item_pages);
> >
> > I presume this should use vacrel->lpdead_items?.
>
> It should have been, but as it happens I have decided to not do this
> at all in 0002-*. Better to not report on LP_UNUSED *or* LP_DEAD items
> at this point of VACUUM VERBOSE output.
>
> > 0003:
> > > + * ... Aborted transactions
> > > + * have tuples that we can treat as DEAD without caring about where there
> > > + * tuple header XIDs ...
> >
> > This should be '... where their tuple header XIDs...'
>
> Will fix.
>
> > > +retry:
> > > +
> > > ...
> > > + res = HeapTupleSatisfiesVacuum(&tuple, vacrel->OldestXmin, buf);
> > > +
> > > + if (unlikely(res == HEAPTUPLE_DEAD))
> > > + goto retry;
> >
> > In this unlikely case, you reset the tuples_deleted value that was
> > received earlier from heap_page_prune. This results in inaccurate
> > statistics, as repeated calls to heap_page_prune on the same page will
> > not count tuples that were deleted in a previous call.
>
> I don't think that it matters. The "tupgone=true" case has no test
> coverage (see coverage.postgresql.org), and it would be hard to ensure
> that the "res == HEAPTUPLE_DEAD" that replaces it gets coverage, for
> the same reasons. Keeping the rules as simple as possible seem like a
> good goal. What's more, it's absurdly unlikely that this will happen
> even once. The race is very tight. Postgres will do opportunistic
> pruning at almost any point, often from a SELECT, so the chances of
> anybody noticing an inaccuracy from this issue in particular are
> remote in the extreme.
>
> Actually, a big problem with the tuples_deleted value surfaced by both
> log_autovacuum and by VACUUM VERBOSE is that it can be wildly
> different to the number of LP_DEAD items. This is commonly the case
> with tables that get lots of non-HOT updates, with opportunistic
> pruning kicking in a lot, with LP_DEAD items constantly accumulating.
> By the time VACUUM comes around, it reports an absurdly low
> tuples_deleted because it's using this what-I-pruned-just-now
> definition. The opposite extreme is also possible, since there might
> be far fewer LP_DEAD items when VACUUM does a lot of pruning of HOT
> chains specifically.
That seems reasonable as well.
> > 0004:
> > > + * truncate to. Note that we avoid truncating the line pointer to 0 items
> > > + * in all cases.
> > > + */
> >
> > Is there a specific reason that I'm not getting as to why this is necessary?
>
> I didn't say it was strictly necessary. There is special-case handling
> of PageIsEmpty() at various points, though, including within VACUUM.
> It seemed worth avoiding hitting that.
That seems reasonable.
> Perhaps I should change it to not work that way.
All cases of PageIsEmpty on heap pages seem to be optimized short-path
handling of empty pages in vacuum, so I'd say that it is better to
fully truncate the array, but I'd be fully OK with postponing that
specific change for further analysis.
> > 0005:
> > > + The default is 1.8 billion transactions. Although users can set this value
> > > + anywhere from zero to 2.1 billion, <command>VACUUM</command> will silently
> > > + adjust the effective value more than 105% of
> > > + <xref linkend="guc-autovacuum-freeze-max-age"/>, so that only
> > > + anti-wraparound autovacuums and aggressive scans have a chance to skip
> > > + index cleanup.
> >
> > This documentation doesn't quite make it clear what its relationship
> > is with autovacuum_freeze_max_age. How about the following: "...
> > >VACUUM< will use the higher of this value and 105% of
> > >guc-autovacuum-freeze-max-age<, so that only ...". It's only slightly
> > easier to read, but at least it conveys that values lower than 105% of
> > autovacuum_freeze_max_age are not considered. The same can be said for
> > the multixact guc documentation.
>
> This does need work too.
>
> I'm going to push 0002- and 0003- tomorrow morning pacific time. I'll
> publish a new set of patches tomorrow, once I've finished that up. The
> last 2 patches will require a lot of focus to get over the line for
> Postgres 14.
If you have updated patches, I'll try to check them this evening (CEST).
With regards,
Matthias van de Meent
On Tue, Apr 6, 2021 at 7:05 AM Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > If you have updated patches, I'll try to check them this evening (CEST). Here is v11, which is not too different from v10 as far as the truncation stuff goes. Masahiko should take a look at the last patch again. I renamed the GUCs to reflect the fact that we do everything possible to advance relfrozenxid in the case where the fail safe mechanism kicks in -- not just skipping index vacuuming. It also incorporates your most recent round of feedback. Thanks -- Peter Geoghegan
Вложения
On Wed, Apr 7, 2021 at 12:16 PM Peter Geoghegan <pg@bowt.ie> wrote:
>
> On Tue, Apr 6, 2021 at 7:05 AM Matthias van de Meent
> <boekewurm+postgres@gmail.com> wrote:
> > If you have updated patches, I'll try to check them this evening (CEST).
>
> Here is v11, which is not too different from v10 as far as the
> truncation stuff goes.
>
> Masahiko should take a look at the last patch again. I renamed the
> GUCs to reflect the fact that we do everything possible to advance
> relfrozenxid in the case where the fail safe mechanism kicks in -- not
> just skipping index vacuuming. It also incorporates your most recent
> round of feedback.
Thank you for updating the patches!
I've done the final round of review:
+ /*
+ * Before beginning heap scan, check if it's already necessary to apply
+ * fail safe speedup
+ */
+ should_speedup_failsafe(vacrel);
Maybe we can call it at an earlier point, for example before
lazy_space_alloc()? That way, we will not need to enable parallelism
if we know it's already an emergency situation.
---
+ msgfmt = _(" %u pages from table (%.2f%% of total) had
%lld dead item identifiers removed\n");
+
+ if (vacrel->nindexes == 0 || (vacrel->do_index_vacuuming &&
+ vacrel->num_index_scans == 0))
+ appendStringInfo(&buf, _("index scan not needed:"));
+ else if (vacrel->do_index_vacuuming &&
vacrel->num_index_scans > 0)
+ appendStringInfo(&buf, _("index scan needed:"));
+ else
+ {
+ msgfmt = _(" %u pages from table (%.2f%% of total)
have %lld dead item identifiers\n");
+
+ if (!vacrel->do_failsafe_speedup)
+ appendStringInfo(&buf, _("index scan bypassed:"));
+ else
+ appendStringInfo(&buf, _("index scan bypassed
due to emergency:"));
+ }
+ appendStringInfo(&buf, msgfmt,
+ vacrel->lpdead_item_pages,
+ 100.0 * vacrel->lpdead_item_pages /
vacrel->rel_pages,
+ (long long) vacrel->lpdead_items);
I think we can make it clean if we check vacrel->do_index_vacuuming first.
I've attached the patch that proposes the change for the above points
and can be applied on top of 0002 patch. Please feel free to adopt or
reject it.
For 0001 patch, we call PageTruncateLinePointerArray() only in the
second pass over heap. I think we should note that the second pass is
called only when we found/made LP_DEAD on the page. That is, if all
dead tuples have been marked as LP_UNUSED by HOT pruning, the page
would not be processed by the second pass, resulting in not removing
LP_UNUSED at the end of line pointer array. So think we can call it in
this case, i.g., when lpdead_items is 0 and tuples_deleted > 0 in
lazy_scan_prune().
Regards,
--
Masahiko Sawada
EDB: https://www.enterprisedb.com/
Вложения
On Tue, Apr 6, 2021 at 5:49 AM Peter Geoghegan <pg@bowt.ie> wrote: > > On Mon, Apr 5, 2021 at 5:09 PM Peter Geoghegan <pg@bowt.ie> wrote: > > Oh yeah. "static BufferAccessStrategy vac_strategy" is guaranteed to > > be initialized to 0, simply because it's static and global. That > > explains it. > > So do we need to allocate a strategy in workers now, or leave things > as they are/were? > > I'm going to go ahead with pushing my commit to do that now, just to > get the buildfarm green. It's still a bug in Postgres 13, albeit a > less serious one than I first suspected. > I have started a separate thread [1] to fix this in PG-13. [1] - https://www.postgresql.org/message-id/CAA4eK1KbmJgRV2W3BbzRnKUSrukN7SbqBBriC4RDB5KBhopkGQ%40mail.gmail.com -- With Regards, Amit Kapila.
On Wed, Apr 7, 2021 at 12:50 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > Thank you for updating the patches! > > I've done the final round of review: All of the changes from your fixup patch are clear improvements, and so I'll include them in the final commit. Thanks! > For 0001 patch, we call PageTruncateLinePointerArray() only in the > second pass over heap. I think we should note that the second pass is > called only when we found/made LP_DEAD on the page. That is, if all > dead tuples have been marked as LP_UNUSED by HOT pruning, the page > would not be processed by the second pass, resulting in not removing > LP_UNUSED at the end of line pointer array. So think we can call it in > this case, i.g., when lpdead_items is 0 and tuples_deleted > 0 in > lazy_scan_prune(). Maybe it would be beneficial to do that, but I haven't done it in the version of the patch that I just pushed. We have run out of time to consider calling PageTruncateLinePointerArray() in more places. I think that the most important thing is that we have *some* protection against line pointer bloat. -- Peter Geoghegan
On Wed, Apr 7, 2021 at 8:52 AM Peter Geoghegan <pg@bowt.ie> wrote: > All of the changes from your fixup patch are clear improvements, and > so I'll include them in the final commit. Thanks! I did change the defaults of the GUCs to 1.6 billion, though. All patches in the patch series have been pushed. Hopefully I will not be the next person to break the buildfarm today. Thanks Masahiko, and everybody else involved! -- Peter Geoghegan
On Thu, Apr 8, 2021 at 8:41 AM Peter Geoghegan <pg@bowt.ie> wrote: > > On Wed, Apr 7, 2021 at 8:52 AM Peter Geoghegan <pg@bowt.ie> wrote: > > All of the changes from your fixup patch are clear improvements, and > > so I'll include them in the final commit. Thanks! > > I did change the defaults of the GUCs to 1.6 billion, though. Okay. > > All patches in the patch series have been pushed. Hopefully I will not > be the next person to break the buildfarm today. > > Thanks Masahiko, and everybody else involved! Thank you, too! Regards, -- Masahiko Sawada EDB: https://www.enterprisedb.com/
On Thu, Apr 8, 2021 at 11:42 AM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > On Thu, Apr 8, 2021 at 8:41 AM Peter Geoghegan <pg@bowt.ie> wrote: > > > > On Wed, Apr 7, 2021 at 8:52 AM Peter Geoghegan <pg@bowt.ie> wrote: > > > All of the changes from your fixup patch are clear improvements, and > > > so I'll include them in the final commit. Thanks! I realized that when the failsafe is triggered, we don't bypass heap truncation that is performed before updating relfrozenxid. I think it's better to bypass it too. What do you think? Regards, -- Masahiko Sawada EDB: https://www.enterprisedb.com/
On Mon, Apr 12, 2021 at 11:05 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > I realized that when the failsafe is triggered, we don't bypass heap > truncation that is performed before updating relfrozenxid. I think > it's better to bypass it too. What do you think? I agree. Bypassing heap truncation is exactly the kind of thing that risks adding significant, unpredictable delay at a time when we need to advance relfrozenxid as quickly as possible. I pushed a trivial commit that makes the failsafe bypass heap truncation as well just now. Thanks -- Peter Geoghegan
On Wed, Apr 14, 2021 at 4:59 AM Peter Geoghegan <pg@bowt.ie> wrote: > > On Mon, Apr 12, 2021 at 11:05 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > > I realized that when the failsafe is triggered, we don't bypass heap > > truncation that is performed before updating relfrozenxid. I think > > it's better to bypass it too. What do you think? > > I agree. Bypassing heap truncation is exactly the kind of thing that > risks adding significant, unpredictable delay at a time when we need > to advance relfrozenxid as quickly as possible. > > I pushed a trivial commit that makes the failsafe bypass heap > truncation as well just now. Great, thanks! Regards, -- Masahiko Sawada EDB: https://www.enterprisedb.com/
Hi, On 2021-04-13 12:59:03 -0700, Peter Geoghegan wrote: > I agree. Bypassing heap truncation is exactly the kind of thing that > risks adding significant, unpredictable delay at a time when we need > to advance relfrozenxid as quickly as possible. > > I pushed a trivial commit that makes the failsafe bypass heap > truncation as well just now. I'm getting a bit bothered by the speed at which you're pushing fairly substantial behavioural for vacuum. In this case without even a warning that you're about to do so. I don't think it's that blindingly obvious that skipping truncation is the right thing to do that it doesn't need review. Consider e.g. the case that you're close to wraparound because you ran out of space for the amount of WAL VACUUM produces, previously leading to autovacuums being aborted / the server restarted. The user might then stop regular activity and try to VACUUM. Skipping the truncation might now make it harder to actually vacuum all the tables without running out of space. FWIW, I also don't like that substantial behaviour changes to how vacuum works were discussed only in a thread titled "New IndexAM API controlling index vacuum strategies". Greetings, Andres Freund
On Wed, Apr 14, 2021 at 12:33 PM Andres Freund <andres@anarazel.de> wrote: > I'm getting a bit bothered by the speed at which you're pushing fairly > substantial behavioural for vacuum. In this case without even a warning > that you're about to do so. To a large degree the failsafe is something that is written in the hope that it will never be needed. This is unlike most other things, and has its own unique risks. I think that the proper thing to do is to accept a certain amount of risk in this area. The previous status quo was *appalling*, and so it seems very unlikely that the failsafe hasn't mostly eliminated a lot of risk for users. That factor is not everything, but it should count for a lot. The only way that we're going to have total confidence in anything like this is through the experience of it mostly working over several releases. > I don't think it's that blindingly obvious that skipping truncation is > the right thing to do that it doesn't need review. Consider e.g. the > case that you're close to wraparound because you ran out of space for > the amount of WAL VACUUM produces, previously leading to autovacuums > being aborted / the server restarted. The user might then stop regular > activity and try to VACUUM. Skipping the truncation might now make it > harder to actually vacuum all the tables without running out of space. Note that the criteria for whether or not "hastup=false" for a page is slightly different in lazy_scan_prune() -- I added a comment that points this out directly (the fact that it works that way is not new, and might have originally been a happy mistake). Unlike count_nondeletable_pages(), which is used by heap truncation, lazy_scan_prune() is concerned about whether or not it's *likely to be possible* to truncate away the page by the time lazy_truncate_heap() is reached (if it is reached at all). And so it's optimistic about LP_DEAD items that it observes being removed by lazy_vacuum_heap_page() before we get to lazy_truncate_heap(). It's inherently race-prone anyway, so it might as well assume that LP_DEAD items will eventually become LP_UNUSED items later on. It follows that the chances of lazy_truncate_heap() failing to truncate anything when the failsafe has already triggered are exceptionally high -- all the LP_DEAD items are still there, and cannot be safely removed during truncation (for the usual reasons). I just went one step further than that in this recent commit. I didn't point these details out before now because (to me) this is beside the point. Which is that the failsafe is just that -- a failsafe. Anything that adds unnecessary unpredictable delay in reaching the point of advancing relfrozenxid should be avoided. (Besides, the design of should_attempt_truncation() and lazy_truncate_heap() is very far from guaranteeing that truncation will take place at the best of times.) FWIW, my intention is to try to get as much feedback about the failsafe as I possibly can -- it's hard to reason about exceptional events. I'm also happy to further discuss the specifics with you now. -- Peter Geoghegan
On Wed, Apr 14, 2021 at 5:55 PM Peter Geoghegan <pg@bowt.ie> wrote: > On Wed, Apr 14, 2021 at 12:33 PM Andres Freund <andres@anarazel.de> wrote: > > I'm getting a bit bothered by the speed at which you're pushing fairly > > substantial behavioural for vacuum. In this case without even a warning > > that you're about to do so. > > To a large degree the failsafe is something that is written in the > hope that it will never be needed. This is unlike most other things, > and has its own unique risks. > > I think that the proper thing to do is to accept a certain amount of > risk in this area. The previous status quo was *appalling*, and so it > seems very unlikely that the failsafe hasn't mostly eliminated a lot > of risk for users. That factor is not everything, but it should count > for a lot. The only way that we're going to have total confidence in > anything like this is through the experience of it mostly working over > several releases. I think this is largely missing the point Andres was making, which is that you made a significant behavior change after feature freeze without any real opportunity for discussion. More generally, you've changed a bunch of other stuff relatively quickly based on input from a relatively limited number of people. Now, it's fair to say that it's often hard to get input on things, and sometimes you have to just take your best shot and hope you're right. But in this particular case, you didn't even try to get broader participation or buy-in. That's not good. -- Robert Haas EDB: http://www.enterprisedb.com
On Wed, Apr 14, 2021 at 5:08 PM Robert Haas <robertmhaas@gmail.com> wrote: > I think this is largely missing the point Andres was making, which is > that you made a significant behavior change after feature freeze > without any real opportunity for discussion. I don't believe that it was a significant behavior change, for the reason I gave: the fact of the matter is that it's practically impossible for us to truncate the heap anyway, provided we have already decided to not vacuum (as opposed to prune) heap pages that almost certainly have some LP_DEAD items in them. Note that later heap pages are the most likely to still have some LP_DEAD items once the failsafe triggers, which are precisely the ones that will affect whether or not we can truncate the whole heap. I accept that I could have done better with the messaging. I'll try to avoid repeating that mistake in the future. > More generally, you've > changed a bunch of other stuff relatively quickly based on input from > a relatively limited number of people. Now, it's fair to say that it's > often hard to get input on things, and sometimes you have to just take > your best shot and hope you're right. I agree in general, and I agree that that's what I've done in this instance. It goes without saying, but I'll say it anyway: I accept full responsibility. > But in this particular case, you > didn't even try to get broader participation or buy-in. That's not > good. I will admit to being somewhat burned out by this project. That might have been a factor. -- Peter Geoghegan
Hi, On 2021-04-14 20:08:10 -0400, Robert Haas wrote: > On Wed, Apr 14, 2021 at 5:55 PM Peter Geoghegan <pg@bowt.ie> wrote: > > On Wed, Apr 14, 2021 at 12:33 PM Andres Freund <andres@anarazel.de> wrote: > > > I'm getting a bit bothered by the speed at which you're pushing fairly > > > substantial behavioural for vacuum. In this case without even a warning > > > that you're about to do so. > > > > To a large degree the failsafe is something that is written in the > > hope that it will never be needed. This is unlike most other things, > > and has its own unique risks. > > > > I think that the proper thing to do is to accept a certain amount of > > risk in this area. The previous status quo was *appalling*, and so it > > seems very unlikely that the failsafe hasn't mostly eliminated a lot > > of risk for users. That factor is not everything, but it should count > > for a lot. The only way that we're going to have total confidence in > > anything like this is through the experience of it mostly working over > > several releases. > > I think this is largely missing the point Andres was making, which is > that you made a significant behavior change after feature freeze > without any real opportunity for discussion. More generally, you've > changed a bunch of other stuff relatively quickly based on input from > a relatively limited number of people. Now, it's fair to say that it's > often hard to get input on things, and sometimes you have to just take > your best shot and hope you're right. But in this particular case, you > didn't even try to get broader participation or buy-in. That's not > good. Yep, that was what I was trying to get at. - Andres
Hi, On 2021-04-14 14:55:36 -0700, Peter Geoghegan wrote: > On Wed, Apr 14, 2021 at 12:33 PM Andres Freund <andres@anarazel.de> wrote: > > I'm getting a bit bothered by the speed at which you're pushing fairly > > substantial behavioural for vacuum. In this case without even a warning > > that you're about to do so. > > To a large degree the failsafe is something that is written in the > hope that it will never be needed. This is unlike most other things, > and has its own unique risks. Among them that the code is not covered by tests and is unlikely to be meaningfully exercised within the beta timeframe due to the timeframes for hitting it (hard to actually hit below a 1/2 day running extreme workloads, weeks for more realistic ones). Which means that this code has to be extra vigorously reviewed, not the opposite. Or at least tests for it should be added (pg_resetwal + autovacuum_naptime=1s or such should make that doable, or even just running a small test with lower thresholds). > I just went one step further than that in this recent commit. I didn't > point these details out before now because (to me) this is beside the > point. Which is that the failsafe is just that -- a failsafe. Anything > that adds unnecessary unpredictable delay in reaching the point of > advancing relfrozenxid should be avoided. (Besides, the design of > should_attempt_truncation() and lazy_truncate_heap() is very far from > guaranteeing that truncation will take place at the best of times.) This line of argumentation scares me. Not explained arguments, about running in conditions that we otherwise don't run in, when in exceptional circumstances. This code has a history of super subtle interactions, with quite a few data loss causing bugs due to us not forseeing some combination of circumstances. I think there are good arguments for having logic for an "emergency vacuum" mode (and also some good ones against). I'm not convinced that the current set of things that are [not] skipped in failsafe mode is the "obviously right set of things"™ but am convinced that there wasn't enough consensus building o what that set of things is. This all also would be different if it were the start of the development window, rather than the end. In my experience the big problem with vacuums in a wraparound situation isn't actually things like truncation or eventhe index scans (although they certainly can cause bad problems), but that VACUUM modifies (prune/vacuum and WAL log or just setting hint bits) a crapton of pages that don't actually need to be modified just to be able to get out of the wraparound situation. And that the overhead of writing out all those dirty pages + WAL logging causes the VACUUM to take unacceptably long. E.g. because your storage is cloud storage with a few ms of latency, and the ringbuffer + wal_buffer sizes cause so many synchronous writes that you end up with < 10MB/s of data being processed. I think there's also a clear danger in having "cliffs" where the behaviour changes appruptly once a certain threshold is reached. It's not unlikely for systems to fall over entirely over when a) autovacuum cost limiting is disabled. E.g. reaching your disk iops/throughput quota and barely being able to log into postgres anymore to kill the stuck connection causing the wraparound issue. b) No index cleanup happens anymore. E.g. a workload with a lot of bitmap index scans (which do not support killtuples) could end up a off a lot worse because index pointers to dead tuples aren't being cleaned up. In cases where an old transaction or leftover replication slot is causing the problem (together a significant percentage of wraparound situations) this situation will persist across repeated (explicit or automatic) vacuums for a table, because relfrozenxid won't actually be advanced. And this in turn might actually end up slowing resolution of the wraparound issue more than doing all the index scans. Because this is a hard cliff rather than something phasing in, it's not really possible to for a user to see this slowly getting worse and addressing the issue. Especially for a) this could be addressed by not turning off cost limiting at once, but instead have it decrease the closer you get to some limit. Greetings, Andres Freund
On Wed, Apr 14, 2021 at 6:53 PM Andres Freund <andres@anarazel.de> wrote: > > To a large degree the failsafe is something that is written in the > > hope that it will never be needed. This is unlike most other things, > > and has its own unique risks. > > Among them that the code is not covered by tests and is unlikely to be > meaningfully exercised within the beta timeframe due to the timeframes > for hitting it (hard to actually hit below a 1/2 day running extreme > workloads, weeks for more realistic ones). Which means that this code > has to be extra vigorously reviewed, not the opposite. There is test coverage for the optimization to bypass index vacuuming with very few dead tuples. Plus we can expect it to kick in very frequently. That's not as good as testing this other mechanism directly, which I agree ought to happen too. But the difference between those two cases is pretty much entirely around when and how they kick in. I have normalized the idea that index vacuuming is optional in principle, so in an important sense it is tested all the time. > Or at least > tests for it should be added (pg_resetwal + autovacuum_naptime=1s or > such should make that doable, or even just running a small test with > lower thresholds). You know what else doesn't have test coverage? Any kind of aggressive VACUUM. There is a problem with our culture around testing. I would like to address that in the scope of this project, but you know how it is. Can I take it that I'll have your support with adding those tests? > This line of argumentation scares me. Not explained arguments, about > running in conditions that we otherwise don't run in, when in > exceptional circumstances. This code has a history of super subtle > interactions, with quite a few data loss causing bugs due to us not > forseeing some combination of circumstances. I'll say it again: I was wrong to not make that clearer prior to committing the fixup. I regret that error, which probably had a lot to do with being fatigued. > I think there are good arguments for having logic for an "emergency > vacuum" mode (and also some good ones against). I'm not convinced that > the current set of things that are [not] skipped in failsafe mode is the > "obviously right set of things"™ but am convinced that there wasn't > enough consensus building o what that set of things is. This all also > would be different if it were the start of the development window, > rather than the end. I all but begged you to review the patches. Same with Robert. While the earlier patches (where almost all of the complexity is) did get review from both you and Robert (which I was grateful to receive), for whatever reason neither of you looked at the later patches in detail. (Robert said that the failsafe ought to cover single-pass/no-indexes VACUUM at one point, which did influence the design of the failsafe, but for the most part his input on the later stuff was minimal and expressed in general terms.) Of course, nothing stops us from improving the mechanism in the future. Though I maintain that the fundamental approach of finishing as quickly as possible is basically sound (short of fixing the problem directly, for example by obviating the need for freezing). > In my experience the big problem with vacuums in a wraparound situation > isn't actually things like truncation or eventhe index scans (although > they certainly can cause bad problems), but that VACUUM modifies > (prune/vacuum and WAL log or just setting hint bits) a crapton of pages > that don't actually need to be modified just to be able to get out of > the wraparound situation. Things like UUID indexes are very popular, and are likely to have an outsized impact on dirtying pages (which I agree is the real problem). Plus some people just have a ridiculous amount of indexes (e.g., the Discourse table that they pointed out as a particularly good target for deduplication had a total of 13 indexes). There is an excellent chance that stuff like that is involved in installations that actually have huge problems. The visibility map works pretty well these days -- but not for indexes. > And that the overhead of writing out all those > dirty pages + WAL logging causes the VACUUM to take unacceptably > long. E.g. because your storage is cloud storage with a few ms of > latency, and the ringbuffer + wal_buffer sizes cause so many synchronous > writes that you end up with < 10MB/s of data being processed. This is a false dichotomy. There probably is an argument for making the failsafe not do pruning that isn't strictly necessary (or something like that) in a future release. I don't see what particular significance that has for the failsafe mechanism now. The sooner we can advance relfrozenxid when it's dangerously far in the past, the better. It's true that the mechanism doesn't exploit every possible opportunity to do so. But it mostly manages to do that. > I think there's also a clear danger in having "cliffs" where the > behaviour changes appruptly once a certain threshold is reached. It's > not unlikely for systems to fall over entirely over when > > a) autovacuum cost limiting is disabled. E.g. reaching your disk > iops/throughput quota and barely being able to log into postgres > anymore to kill the stuck connection causing the wraparound issue. Let me get this straight: You're concerned that hurrying up vacuuming when we have 500 million XIDs left to burn will overwhelm the system, which would presumably have finished in time otherwise? Even though it would have to do way more work in absolute terms in the absence of the failsafe? And even though the 1.6 billion XID age that we got to before the failsafe kicked in was clearly not enough? You'd want to "play it safe", and stick with the original plan at that point? > b) No index cleanup happens anymore. E.g. a workload with a lot of > bitmap index scans (which do not support killtuples) could end up a > off a lot worse because index pointers to dead tuples aren't being > cleaned up. In cases where an old transaction or leftover replication > slot is causing the problem (together a significant percentage of > wraparound situations) this situation will persist across repeated > (explicit or automatic) vacuums for a table, because relfrozenxid > won't actually be advanced. And this in turn might actually end up > slowing resolution of the wraparound issue more than doing all the > index scans. If it's intrinsically impossible to advance relfrozenxid, then surely all bets are off. But even in this scenario it's very unlikely that we wouldn't at least do index vacuuming for those index tuples that are dead and safe to delete according to the OldestXmin cutoff. You still have 1.6 billion XIDs before the failsafe first kicks in, regardless of the issue of the OldestXmin/FreezeLimit being excessively far in the past. You're also not acknowledging the benefit of avoiding uselessly scanning the indexes again and again, which is mostly what would be happening in this scenario. Maybe VACUUM shouldn't spin like this at all, but that's not a new problem. > Because this is a hard cliff rather than something phasing in, it's not > really possible to for a user to see this slowly getting worse and > addressing the issue. Especially for a) this could be addressed by not > turning off cost limiting at once, but instead have it decrease the > closer you get to some limit. There is a lot to be said for keeping the behavior as simple as possible. You said so yourself. In any case I think that the perfect should not be the enemy of the good (or the better, at least). -- Peter Geoghegan
Hi, On 2021-04-14 19:53:29 -0700, Peter Geoghegan wrote: > > Or at least > > tests for it should be added (pg_resetwal + autovacuum_naptime=1s or > > such should make that doable, or even just running a small test with > > lower thresholds). > > You know what else doesn't have test coverage? Any kind of aggressive > VACUUM. There is a problem with our culture around testing. I would > like to address that in the scope of this project, but you know how it > is. Can I take it that I'll have your support with adding those tests? Sure! > > I think there are good arguments for having logic for an "emergency > > vacuum" mode (and also some good ones against). I'm not convinced that > > the current set of things that are [not] skipped in failsafe mode is the > > "obviously right set of things"™ but am convinced that there wasn't > > enough consensus building o what that set of things is. This all also > > would be different if it were the start of the development window, > > rather than the end. > > I all but begged you to review the patches. Same with Robert. While > the earlier patches (where almost all of the complexity is) did get > review from both you and Robert (which I was grateful to receive), for > whatever reason neither of you looked at the later patches in detail. Based on a quick scan of the thread, the first version of a patch that kind of resembles what got committed around the topic at hand seems to be https://postgr.es/m/CAH2-Wzm7Y%3D_g3FjVHv7a85AfUbuSYdggDnEqN1hodVeOctL%2BOw%40mail.gmail.com posted 2021-03-15. That's well into the last CF. The reason I didn't do further reviews for things in this thread was that I was trying really hard to get the shared memory stats patch into a committable shape - there were just not enough hours in the day. I think it's to be expected that, during the final CF, there aren't a lot of resources for reviewing patches that are substantially new. Why should these new patches have gotten priority over a much older patch set that also address significant operational issues? > > I think there's also a clear danger in having "cliffs" where the > > behaviour changes appruptly once a certain threshold is reached. It's > > not unlikely for systems to fall over entirely over when > > > > a) autovacuum cost limiting is disabled. E.g. reaching your disk > > iops/throughput quota and barely being able to log into postgres > > anymore to kill the stuck connection causing the wraparound issue. > > Let me get this straight: You're concerned that hurrying up vacuuming > when we have 500 million XIDs left to burn will overwhelm the system, > which would presumably have finished in time otherwise? > Even though it would have to do way more work in absolute terms in the > absence of the failsafe? And even though the 1.6 billion XID age that > we got to before the failsafe kicked in was clearly not enough? You'd > want to "play it safe", and stick with the original plan at that > point? It's very common for larger / busier databases to *substantially* increase autovacuum_freeze_max_age, so there won't be 1.6 billion XIDs of headroom, but a few hundred million. The cost of doing unnecessary anti-wraparound vacuums is just too great. And databases on the busier & larger side of things are precisely the ones that are more likely to hit wraparound issues (otherwise you're just not that likely to burn through that many xids). And my concern isn't really that vacuum would have finished without a problem if cost limiting hadn't been disabled, but that having multiple autovacuum workers going all out will cause problems. Like the system slowing down so much that it's hard to fix the actual root cause of the wraparound - I've seen systems with a bunch unthrottled autovacuum overwhelme the IO subsystem so much that simply opening a connection to fix the issue took 10+ minutes. Especially on systems with provisioned IO (i.e. just about all cloud storage) that's not too hard to hit. > > b) No index cleanup happens anymore. E.g. a workload with a lot of > > bitmap index scans (which do not support killtuples) could end up a > > off a lot worse because index pointers to dead tuples aren't being > > cleaned up. In cases where an old transaction or leftover replication > > slot is causing the problem (together a significant percentage of > > wraparound situations) this situation will persist across repeated > > (explicit or automatic) vacuums for a table, because relfrozenxid > > won't actually be advanced. And this in turn might actually end up > > slowing resolution of the wraparound issue more than doing all the > > index scans. > > If it's intrinsically impossible to advance relfrozenxid, then surely > all bets are off. But even in this scenario it's very unlikely that we > wouldn't at least do index vacuuming for those index tuples that are > dead and safe to delete according to the OldestXmin cutoff. You still > have 1.6 billion XIDs before the failsafe first kicks in, regardless > of the issue of the OldestXmin/FreezeLimit being excessively far in > the past. As I said above, I don't think the "1.6 billion XIDs" argument has merit, because it's so reasonable (and common) to set autovacuum_freeze_max_age to something much larger. > You're also not acknowledging the benefit of avoiding uselessly > scanning the indexes again and again, which is mostly what would be > happening in this scenario. Maybe VACUUM shouldn't spin like this at > all, but that's not a new problem. I explicitly said that there's benefits to skipping index scans? Greetings, Andres Freund
On Wed, Apr 14, 2021 at 8:38 PM Andres Freund <andres@anarazel.de> wrote: > The reason I didn't do further reviews for things in this thread was > that I was trying really hard to get the shared memory stats patch into > a committable shape - there were just not enough hours in the day. I > think it's to be expected that, during the final CF, there aren't a lot > of resources for reviewing patches that are substantially new. Why > should these new patches have gotten priority over a much older patch > set that also address significant operational issues? We're all doing our best. > It's very common for larger / busier databases to *substantially* > increase autovacuum_freeze_max_age, so there won't be 1.6 billion XIDs > of headroom, but a few hundred million. The cost of doing unnecessary > anti-wraparound vacuums is just too great. And databases on the busier & > larger side of things are precisely the ones that are more likely to hit > wraparound issues (otherwise you're just not that likely to burn through > that many xids). I think that this was once true, but is now much less common, mostly due to the freeze map stuff in 9.6. And due a general recognition that the *risk* of increasing them is just too great (a risk that we can hope was diminished by the failsafe, incidentally). As an example of this, Christophe Pettus had a Damascene conversion when it came to increasing autovacuum_freeze_max_age aggressively, which we explains here: https://thebuild.com/blog/2019/02/08/do-not-change-autovacuum-age-settings/ In short, he went from regularly advising clients to increase autovacuum_freeze_max_age to telling them to specifically advising them to never touch them. Even if we assume that I'm 100% wrong about autovacuum_freeze_max_age, it's still true that the vacuum_failsafe_age GUC is interpreted with reference to autovacuum_freeze_max_age -- it will always be interpreted as if it was set to 105% of whatever the current value of autovacuum_freeze_max_age happens to be (so it's symmetric with the freeze_table_age GUC and its 95% behavior). So it's never completely unreasonable in the sense that it directly clashes with an existing autovacuum_freeze_max_age setting from before the upgrade. Of course this doesn't mean that there couldn't possibly be any problems with the new mechanism clashing with autovacuum_freeze_max_age in some unforeseen way. But, the worst that can happen is that a user that is sophisticated enough to very aggressively increase autovacuum_freeze_max_age upgrades to Postgres 14, and then finds that index vacuuming is sometimes skipped. Which they'll see lots of annoying and scary messages about if they ever look in the logs. I think that that's an acceptable price to pay to protect the majority of less sophisticated users. > And my concern isn't really that vacuum would have finished without a > problem if cost limiting hadn't been disabled, but that having multiple > autovacuum workers going all out will cause problems. Like the system > slowing down so much that it's hard to fix the actual root cause of the > wraparound - I've seen systems with a bunch unthrottled autovacuum > overwhelme the IO subsystem so much that simply opening a connection to > fix the issue took 10+ minutes. Especially on systems with provisioned > IO (i.e. just about all cloud storage) that's not too hard to hit. I don't think that it's reasonable to expect an intervention like this to perfectly eliminate all risk, while at the same time never introducing any new theoretical risks. (Especially while also being simple and obviously correct.) > > If it's intrinsically impossible to advance relfrozenxid, then surely > > all bets are off. But even in this scenario it's very unlikely that we > > wouldn't at least do index vacuuming for those index tuples that are > > dead and safe to delete according to the OldestXmin cutoff. You still > > have 1.6 billion XIDs before the failsafe first kicks in, regardless > > of the issue of the OldestXmin/FreezeLimit being excessively far in > > the past. > > As I said above, I don't think the "1.6 billion XIDs" argument has > merit, because it's so reasonable (and common) to set > autovacuum_freeze_max_age to something much larger. No merit? Really? Not even a teeny, tiny, microscopic little bit of merit? You're sure? As I said, we handle the case where autovacuum_freeze_max_age is set to something larger than vacuum_failsafe_age is a straightforward and pretty sensible way. I am curious, though: what autovacuum_freeze_max_age setting is "much higher" than 1.6 billion, but somehow also not extremely ill-advised and dangerous? What number is that, precisely? Apparently this is common, but I must confess that it's the first I've heard about it. -- Peter Geoghegan
Hi, On 2021-04-14 21:30:29 -0700, Peter Geoghegan wrote: > I think that this was once true, but is now much less common, mostly > due to the freeze map stuff in 9.6. And due a general recognition that > the *risk* of increasing them is just too great (a risk that we can > hope was diminished by the failsafe, incidentally). As an example of > this, Christophe Pettus had a Damascene conversion when it came to > increasing autovacuum_freeze_max_age aggressively, which we explains > here: > > https://thebuild.com/blog/2019/02/08/do-not-change-autovacuum-age-settings/ Not at all convinced. The issue of needing to modify a lot of all-visible pages again to freeze them is big enough to let it be a problem even after the freeze map. Yes, there's workloads where it's much less of a problem, but not all the time. > As I said, we handle the case where autovacuum_freeze_max_age is set > to something larger than vacuum_failsafe_age is a straightforward and > pretty sensible way. I am curious, though: what > autovacuum_freeze_max_age setting is "much higher" than 1.6 billion, > but somehow also not extremely ill-advised and dangerous? What number > is that, precisely? Apparently this is common, but I must confess that > it's the first I've heard about it. I didn't intend to say that the autovacuum_freeze_max_age would be set much higher than 1.6 billion, just that that the headroom would be much less. I've set it, and seen it set, to 1.5-1.8bio without problems, while reducing overhead substantially. Greetings, Andres Freund
On Thu, Apr 15, 2021 at 5:12 PM Andres Freund <andres@anarazel.de> wrote: > > https://thebuild.com/blog/2019/02/08/do-not-change-autovacuum-age-settings/ > > Not at all convinced. The issue of needing to modify a lot of > all-visible pages again to freeze them is big enough to let it be a > problem even after the freeze map. Yes, there's workloads where it's > much less of a problem, but not all the time. Not convinced of what? I only claimed that it was much less common. Many users live in fear of the extreme worst case of the database no longer being able to accept writes. That is a very powerful fear. > > As I said, we handle the case where autovacuum_freeze_max_age is set > > to something larger than vacuum_failsafe_age is a straightforward and > > pretty sensible way. I am curious, though: what > > autovacuum_freeze_max_age setting is "much higher" than 1.6 billion, > > but somehow also not extremely ill-advised and dangerous? What number > > is that, precisely? Apparently this is common, but I must confess that > > it's the first I've heard about it. > > I didn't intend to say that the autovacuum_freeze_max_age would be set > much higher than 1.6 billion, just that that the headroom would be much > less. I've set it, and seen it set, to 1.5-1.8bio without problems, > while reducing overhead substantially. Okay, that makes way more sense. (Though I still think that a autovacuum_freeze_max_age beyond 1 billion is highly dubious.) Let's say you set autovacuum_freeze_max_age to 1.8 billion (and you really know what you're doing). This puts you in a pretty select group of Postgres users -- the kind of select group that might be expected to pay very close attention to the compatibility section of the release notes. In any case it makes the failsafe kick in when relfrozenxid age is 1.89 billion. Is that so bad? In fact, isn't this feature actually pretty great for this select cohort of Postgres users that live dangerously? Now it's far safer to live on the edge (perhaps with some additional tuning that ought to be easy for this elite group of users). -- Peter Geoghegan