Обсуждение: POC: Lock updated tuples in tuple_update() and tuple_delete()
Hackers, When working in the read committed transaction isolation mode (default), we have the following sequence of actions when tuple_update() or tuple_delete() find concurrently updated tuple. 1. tuple_update()/tuple_delete() returns TM_Updated 2. tuple_lock() 3. Re-evaluate plan qual (recheck if we still need to update/delete and calculate the new tuple for update) 4. tuple_update()/tuple_delete() (this time should be successful, since we've previously locked the tuple). I wonder if we should merge steps 1 and 2. We could save some efforts already done during tuple_update()/tuple_delete() for locking the tuple. In heap table access method, we've to start tuple_lock() with the first tuple in the chain, but tuple_update()/tuple_delete() already visited it. For undo-based table access methods, tuple_update()/tuple_delete() should start from the last version, why don't place the tuple lock immediately once a concurrent update is detected. I think this patch should have some performance benefits on high concurrency. Also, the patch simplifies code in nodeModifyTable.c getting rid of the nested case. I also get rid of extra table_tuple_fetch_row_version() in ExecUpdate. Why re-fetch the old tuple, when it should be exactly the same tuple we've just locked. I'm going to check the performance impact. Thoughts and feedback are welcome. ------ Regards, Alexander Korotkov
Вложения
Hi Alexander,
> Thoughts and feedback are welcome.
I took some preliminary look at the patch. I'm going to need more time
to meditate on the proposed changes and to figure out the performance
impact.
So far I just wanted to let you know that the patch applied OK for me
and passed all the tests. The `else` branch here seems to be redundant
here:
+ if (!updated)
+ {
+ /* Should not encounter speculative tuple on recheck */
+ Assert(!HeapTupleHeaderIsSpeculative(tuple->t_data));
- ReleaseBuffer(buffer);
+ ReleaseBuffer(buffer);
+ }
+ else
+ {
+ updated = false;
+ }
Also I wish there were a little bit more comments since some of the
proposed changes are not that straightforward.
--
Best regards,
Aleksander Alekseev
Hi again,
> + if (!updated)
> + {
> + /* Should not encounter speculative tuple on recheck */
> + Assert(!HeapTupleHeaderIsSpeculative(tuple->t_data));
> - ReleaseBuffer(buffer);
> + ReleaseBuffer(buffer);
> + }
> + else
> + {
> + updated = false;
> + }
OK, I got confused here. I suggest changing the if(!...) { .. } else {
.. } code to if() { .. } else { .. } here.
--
Best regards,
Aleksander Alekseev
Hi Alexander,
> I'm going to need more time to meditate on the proposed changes and to figure out the performance impact.
OK, turned out this patch is slightly more complicated than I
initially thought, but I think I managed to get some vague
understanding of what's going on.
I tried to reproduce the case with concurrently updated tuples you
described on the current `master` branch. I created a new table:
```
CREATE TABLE phonebook(
"id" SERIAL PRIMARY KEY NOT NULL,
"name" NAME NOT NULL,
"phone" INT NOT NULL);
INSERT INTO phonebook ("name", "phone")
VALUES ('Alice', 123), ('Bob', 456), ('Charlie', 789);
```
Then I opened two sessions and attached them with LLDB. I did:
```
(lldb) b heapam_tuple_update
(lldb) c
```
... in both cases because I wanted to see two calls (steps 2 and 4) to
heapam_tuple_update() and check the return values.
Then I did:
```
session1 =# BEGIN;
session2 =# BEGIN;
session1 =# UPDATE phonebook SET name = 'Alex' WHERE name = 'Alice';
```
This update succeeds and I see heapam_tuple_update() returning TM_Ok.
```
session2 =# UPDATE phonebook SET name = 'Alfred' WHERE name = 'Alice';
```
This update hangs on a lock.
```
session1 =# COMMIT;
```
Now session2 unfreezes and returns 'UPDATE 0'. table_tuple_update()
was called once and returned TM_Updated. Also session2 sees an updated
tuple now. So apparently the visibility check (step 3) didn't pass.
At this point I'm slightly confused. I don't see where a performance
improvement is expected, considering that session2 gets blocked until
session1 commits.
Could you please walk me through here? Am I using the right test case
or maybe you had another one in mind? Which steps do you consider
expensive and expect to be mitigated by the patch?
--
Best regards,
Aleksander Alekseev
Hi Aleksander!
Thank you for your efforts reviewing this patch.
On Thu, Jul 7, 2022 at 12:43 PM Aleksander Alekseev
<aleksander@timescale.com> wrote:
> > I'm going to need more time to meditate on the proposed changes and to figure out the performance impact.
>
> OK, turned out this patch is slightly more complicated than I
> initially thought, but I think I managed to get some vague
> understanding of what's going on.
>
> I tried to reproduce the case with concurrently updated tuples you
> described on the current `master` branch. I created a new table:
>
> ```
> CREATE TABLE phonebook(
> "id" SERIAL PRIMARY KEY NOT NULL,
> "name" NAME NOT NULL,
> "phone" INT NOT NULL);
>
> INSERT INTO phonebook ("name", "phone")
> VALUES ('Alice', 123), ('Bob', 456), ('Charlie', 789);
> ```
>
> Then I opened two sessions and attached them with LLDB. I did:
>
> ```
> (lldb) b heapam_tuple_update
> (lldb) c
> ```
>
> ... in both cases because I wanted to see two calls (steps 2 and 4) to
> heapam_tuple_update() and check the return values.
>
> Then I did:
>
> ```
> session1 =# BEGIN;
> session2 =# BEGIN;
> session1 =# UPDATE phonebook SET name = 'Alex' WHERE name = 'Alice';
> ```
>
> This update succeeds and I see heapam_tuple_update() returning TM_Ok.
>
> ```
> session2 =# UPDATE phonebook SET name = 'Alfred' WHERE name = 'Alice';
> ```
>
> This update hangs on a lock.
>
> ```
> session1 =# COMMIT;
> ```
>
> Now session2 unfreezes and returns 'UPDATE 0'. table_tuple_update()
> was called once and returned TM_Updated. Also session2 sees an updated
> tuple now. So apparently the visibility check (step 3) didn't pass.
Yes. But it's not exactly a visibility check. Session2 re-evaluates
WHERE condition on the most recent row version (bypassing snapshot).
WHERE condition is not true anymore, thus the row is not upated.
> At this point I'm slightly confused. I don't see where a performance
> improvement is expected, considering that session2 gets blocked until
> session1 commits.
>
> Could you please walk me through here? Am I using the right test case
> or maybe you had another one in mind? Which steps do you consider
> expensive and expect to be mitigated by the patch?
This patch is not intended to change some high-level logic. On the
high level transaction, which updated the row, still holding a lock on
it until finished. The possible positive performance impact I expect
from doing the work of two calls tuple_update() and tuple_lock() in
the one call of tuple_update(). If we do this in one call, we can
save some efforts, for instance lock the same buffer once not twice.
------
Regards,
Alexander Korotkov
Hi, hackers!
--
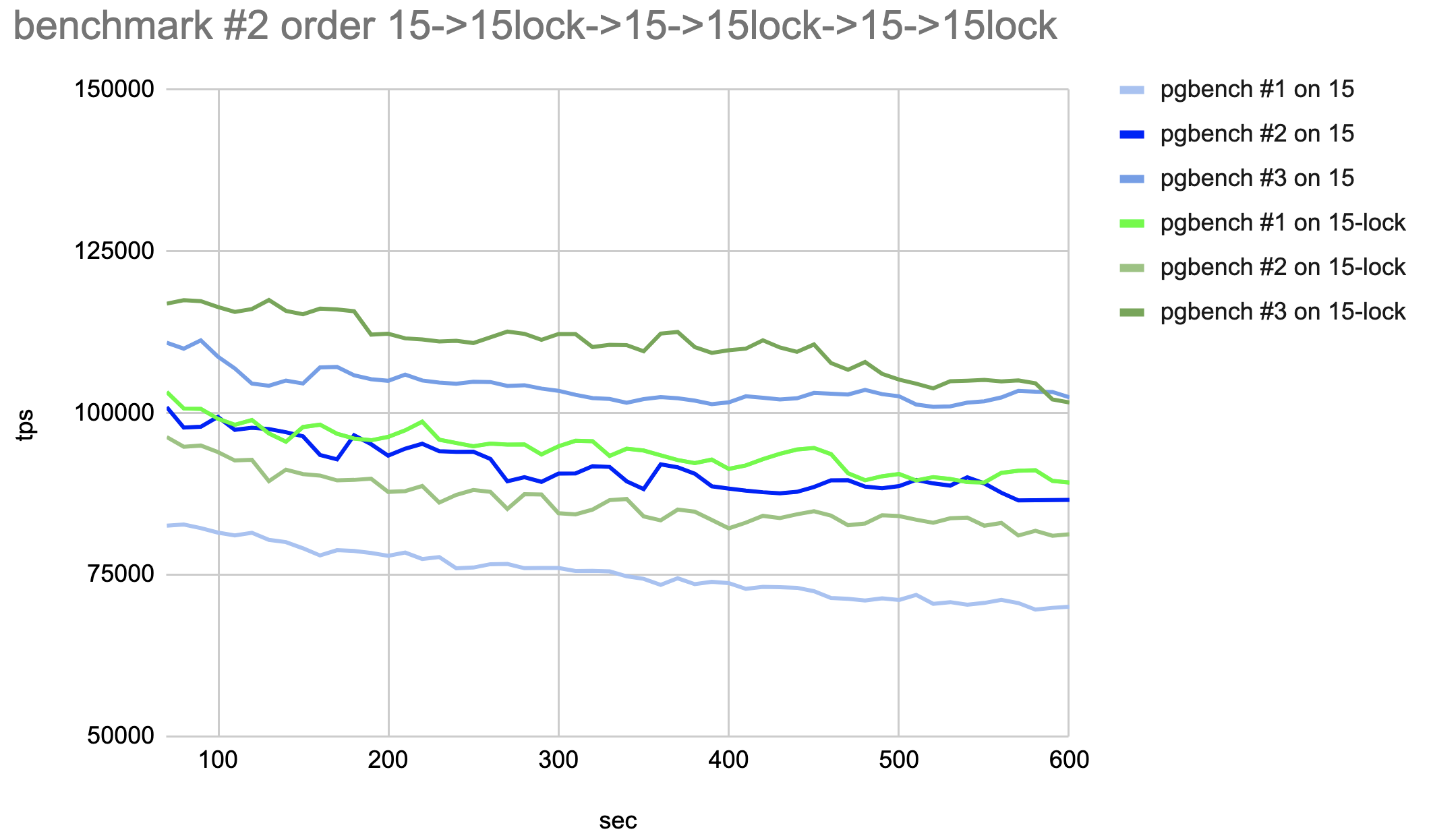
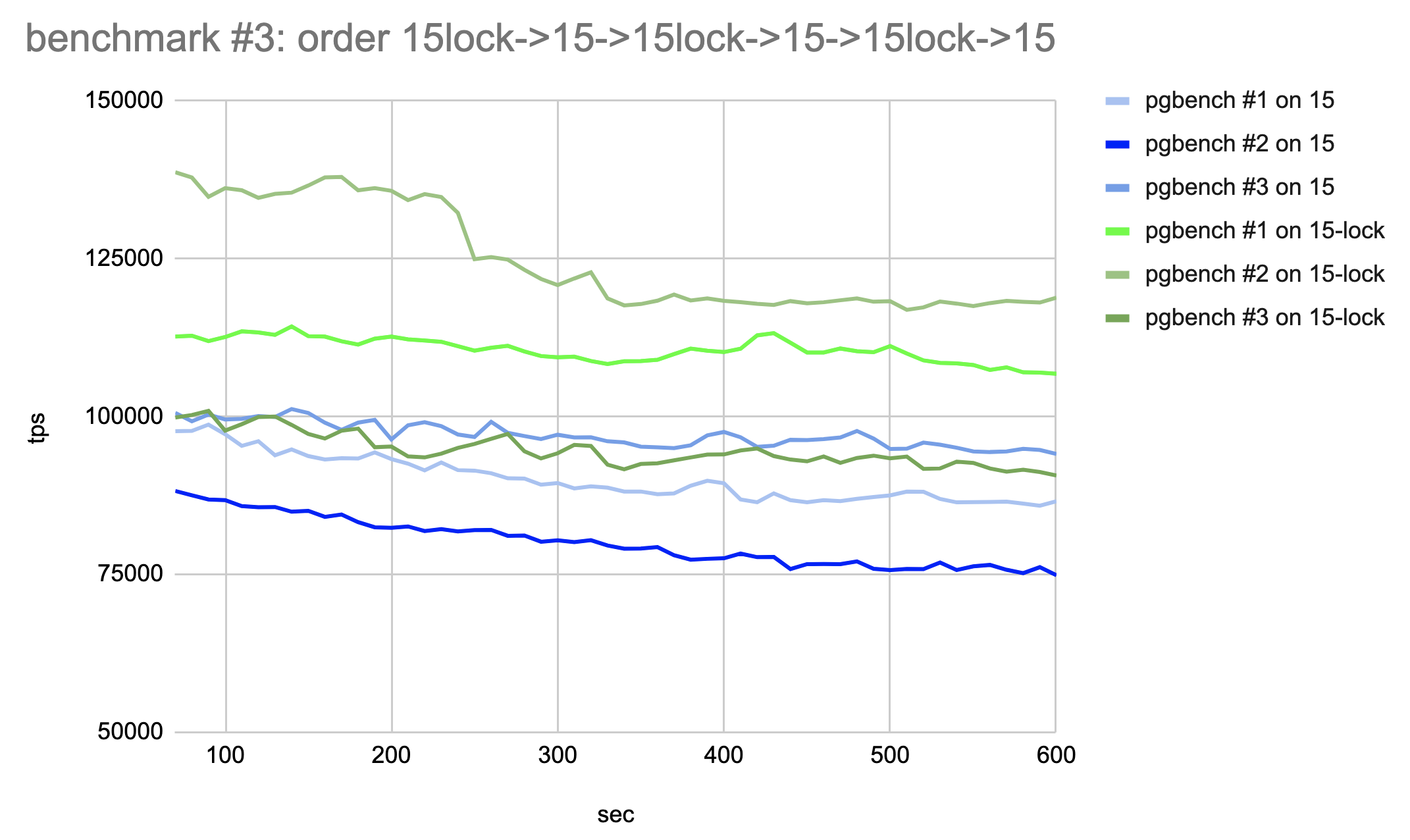
I ran the following benchmark on master branch (15) vs patch (15-lock):
On the 36-vcore AWS server, I've run an UPDATE-only pgbench script with 50 connections on pgbench_tellers with 100 rows. The idea was to introduce as much as possible concurrency for updates but avoid much clients being in a wait state.
Indexes were not built to avoid index-update-related delays.
Done 2 runs each consisting of 6 series of updates (1st run: master-patch-master-patch-master-patch, 2nd run patch-master-patch-master-patch-master)
Each series started a fresh server and did VACUUM FULL to avoid bloating heap relation after the previous series to affect the current. It collected data for 10 minutes with first-minute data being dropped.
Disk-related operations were suppressed where possible (WAL, fsync etc.)
postgresql.conf:
fsync = off
autovacuum = off
full_page_writes = off
max_worker_processes = 99
max_parallel_workers = 99
max_connections = 100
shared_buffers = 4096MB
work_mem = 50MB
Attached are pictures of 2 runs, shell script, and SQL script that were running.
According to htop all 36-cores were loaded to ~94% in each series
I'm not sure how to interpret the results. Seems like a TPS difference between runs is significant, with average performance with lock-patch (15lock) seeming a little bit faster than the master (15).
Could someone try to repeat this on another server? What do you think?
Best regards,
Pavel Borisov,
Pavel Borisov,
Supabase, https://supabase.com/
Вложения
{kind=link}
{kind=link}
Hi, Pavel! On Fri, Jul 29, 2022 at 11:12 AM Pavel Borisov <pashkin.elfe@gmail.com> wrote: > I ran the following benchmark on master branch (15) vs patch (15-lock): > > On the 36-vcore AWS server, I've run an UPDATE-only pgbench script with 50 connections on pgbench_tellers with 100 rows.The idea was to introduce as much as possible concurrency for updates but avoid much clients being in a wait state. > Indexes were not built to avoid index-update-related delays. > Done 2 runs each consisting of 6 series of updates (1st run: master-patch-master-patch-master-patch, 2nd run patch-master-patch-master-patch-master) > Each series started a fresh server and did VACUUM FULL to avoid bloating heap relation after the previous series to affectthe current. It collected data for 10 minutes with first-minute data being dropped. > Disk-related operations were suppressed where possible (WAL, fsync etc.) > > postgresql.conf: > fsync = off > autovacuum = off > full_page_writes = off > max_worker_processes = 99 > max_parallel_workers = 99 > max_connections = 100 > shared_buffers = 4096MB > work_mem = 50MB > > Attached are pictures of 2 runs, shell script, and SQL script that were running. > According to htop all 36-cores were loaded to ~94% in each series > > I'm not sure how to interpret the results. Seems like a TPS difference between runs is significant, with average performancewith lock-patch (15lock) seeming a little bit faster than the master (15). > > Could someone try to repeat this on another server? What do you think? Thank you for your benchmarks. The TPS variation is high, and run order heavily affects the result. Nevertheless, I think there is a small but noticeable positive effect of the patch. I'll continue working on the patch bringing it into more acceptable shape. ------ Regards, Alexander Korotkov
On Fri, 1 Jul 2022 at 16:49, Alexander Korotkov <aekorotkov@gmail.com> wrote: > > Hackers, > > When working in the read committed transaction isolation mode > (default), we have the following sequence of actions when > tuple_update() or tuple_delete() find concurrently updated tuple. > > 1. tuple_update()/tuple_delete() returns TM_Updated > 2. tuple_lock() > 3. Re-evaluate plan qual (recheck if we still need to update/delete > and calculate the new tuple for update) > 4. tuple_update()/tuple_delete() (this time should be successful, > since we've previously locked the tuple). > > I wonder if we should merge steps 1 and 2. We could save some efforts > already done during tuple_update()/tuple_delete() for locking the > tuple. In heap table access method, we've to start tuple_lock() with > the first tuple in the chain, but tuple_update()/tuple_delete() > already visited it. For undo-based table access methods, > tuple_update()/tuple_delete() should start from the last version, why > don't place the tuple lock immediately once a concurrent update is > detected. I think this patch should have some performance benefits on > high concurrency. > > Also, the patch simplifies code in nodeModifyTable.c getting rid of > the nested case. I also get rid of extra > table_tuple_fetch_row_version() in ExecUpdate. Why re-fetch the old > tuple, when it should be exactly the same tuple we've just locked. > > I'm going to check the performance impact. Thoughts and feedback are welcome. The patch does not apply on top of HEAD as in [1], please post a rebased patch: === Applying patches on top of PostgreSQL commit ID eb5ad4ff05fd382ac98cab60b82f7fd6ce4cfeb8 === === applying patch ./0001-Lock-updated-tuples-in-tuple_update-and-tuple_del-v1.patch patching file src/backend/executor/nodeModifyTable.c ... Hunk #3 FAILED at 1376. ... 1 out of 15 hunks FAILED -- saving rejects to file src/backend/executor/nodeModifyTable.c.rej [1] - http://cfbot.cputube.org/patch_41_4099.log Regards, Vignesh
Hi, Vignesh! On Wed, 4 Jan 2023 at 12:41, vignesh C <vignesh21@gmail.com> wrote: > > On Fri, 1 Jul 2022 at 16:49, Alexander Korotkov <aekorotkov@gmail.com> wrote: > > > > Hackers, > > > > When working in the read committed transaction isolation mode > > (default), we have the following sequence of actions when > > tuple_update() or tuple_delete() find concurrently updated tuple. > > > > 1. tuple_update()/tuple_delete() returns TM_Updated > > 2. tuple_lock() > > 3. Re-evaluate plan qual (recheck if we still need to update/delete > > and calculate the new tuple for update) > > 4. tuple_update()/tuple_delete() (this time should be successful, > > since we've previously locked the tuple). > > > > I wonder if we should merge steps 1 and 2. We could save some efforts > > already done during tuple_update()/tuple_delete() for locking the > > tuple. In heap table access method, we've to start tuple_lock() with > > the first tuple in the chain, but tuple_update()/tuple_delete() > > already visited it. For undo-based table access methods, > > tuple_update()/tuple_delete() should start from the last version, why > > don't place the tuple lock immediately once a concurrent update is > > detected. I think this patch should have some performance benefits on > > high concurrency. > > > > Also, the patch simplifies code in nodeModifyTable.c getting rid of > > the nested case. I also get rid of extra > > table_tuple_fetch_row_version() in ExecUpdate. Why re-fetch the old > > tuple, when it should be exactly the same tuple we've just locked. > > > > I'm going to check the performance impact. Thoughts and feedback are welcome. > > The patch does not apply on top of HEAD as in [1], please post a rebased patch: > === Applying patches on top of PostgreSQL commit ID > eb5ad4ff05fd382ac98cab60b82f7fd6ce4cfeb8 === > === applying patch > ./0001-Lock-updated-tuples-in-tuple_update-and-tuple_del-v1.patch > patching file src/backend/executor/nodeModifyTable.c > ... > Hunk #3 FAILED at 1376. > ... > 1 out of 15 hunks FAILED -- saving rejects to file > src/backend/executor/nodeModifyTable.c.rej > > [1] - http://cfbot.cputube.org/patch_41_4099.log The rebased patch is attached. It's just a change in formatting, no changes in code though. Regards, Pavel Borisov, Supabase.
Вложения
On Wed, 4 Jan 2023 at 12:52, Pavel Borisov <pashkin.elfe@gmail.com> wrote: > > Hi, Vignesh! > > On Wed, 4 Jan 2023 at 12:41, vignesh C <vignesh21@gmail.com> wrote: > > > > On Fri, 1 Jul 2022 at 16:49, Alexander Korotkov <aekorotkov@gmail.com> wrote: > > > > > > Hackers, > > > > > > When working in the read committed transaction isolation mode > > > (default), we have the following sequence of actions when > > > tuple_update() or tuple_delete() find concurrently updated tuple. > > > > > > 1. tuple_update()/tuple_delete() returns TM_Updated > > > 2. tuple_lock() > > > 3. Re-evaluate plan qual (recheck if we still need to update/delete > > > and calculate the new tuple for update) > > > 4. tuple_update()/tuple_delete() (this time should be successful, > > > since we've previously locked the tuple). > > > > > > I wonder if we should merge steps 1 and 2. We could save some efforts > > > already done during tuple_update()/tuple_delete() for locking the > > > tuple. In heap table access method, we've to start tuple_lock() with > > > the first tuple in the chain, but tuple_update()/tuple_delete() > > > already visited it. For undo-based table access methods, > > > tuple_update()/tuple_delete() should start from the last version, why > > > don't place the tuple lock immediately once a concurrent update is > > > detected. I think this patch should have some performance benefits on > > > high concurrency. > > > > > > Also, the patch simplifies code in nodeModifyTable.c getting rid of > > > the nested case. I also get rid of extra > > > table_tuple_fetch_row_version() in ExecUpdate. Why re-fetch the old > > > tuple, when it should be exactly the same tuple we've just locked. > > > > > > I'm going to check the performance impact. Thoughts and feedback are welcome. > > > > The patch does not apply on top of HEAD as in [1], please post a rebased patch: > > === Applying patches on top of PostgreSQL commit ID > > eb5ad4ff05fd382ac98cab60b82f7fd6ce4cfeb8 === > > === applying patch > > ./0001-Lock-updated-tuples-in-tuple_update-and-tuple_del-v1.patch > > patching file src/backend/executor/nodeModifyTable.c > > ... > > Hunk #3 FAILED at 1376. > > ... > > 1 out of 15 hunks FAILED -- saving rejects to file > > src/backend/executor/nodeModifyTable.c.rej > > > > [1] - http://cfbot.cputube.org/patch_41_4099.log > > The rebased patch is attached. It's just a change in formatting, no > changes in code though. One more update of a patchset to avoid compiler warnings. Regards, Pavel Borisov
Вложения
Hi, Pavel! On Wed, Jan 4, 2023 at 3:43 PM Pavel Borisov <pashkin.elfe@gmail.com> wrote: > On Wed, 4 Jan 2023 at 12:52, Pavel Borisov <pashkin.elfe@gmail.com> wrote: > > On Wed, 4 Jan 2023 at 12:41, vignesh C <vignesh21@gmail.com> wrote: > > > > > > On Fri, 1 Jul 2022 at 16:49, Alexander Korotkov <aekorotkov@gmail.com> wrote: > > > > > > > > Hackers, > > > > > > > > When working in the read committed transaction isolation mode > > > > (default), we have the following sequence of actions when > > > > tuple_update() or tuple_delete() find concurrently updated tuple. > > > > > > > > 1. tuple_update()/tuple_delete() returns TM_Updated > > > > 2. tuple_lock() > > > > 3. Re-evaluate plan qual (recheck if we still need to update/delete > > > > and calculate the new tuple for update) > > > > 4. tuple_update()/tuple_delete() (this time should be successful, > > > > since we've previously locked the tuple). > > > > > > > > I wonder if we should merge steps 1 and 2. We could save some efforts > > > > already done during tuple_update()/tuple_delete() for locking the > > > > tuple. In heap table access method, we've to start tuple_lock() with > > > > the first tuple in the chain, but tuple_update()/tuple_delete() > > > > already visited it. For undo-based table access methods, > > > > tuple_update()/tuple_delete() should start from the last version, why > > > > don't place the tuple lock immediately once a concurrent update is > > > > detected. I think this patch should have some performance benefits on > > > > high concurrency. > > > > > > > > Also, the patch simplifies code in nodeModifyTable.c getting rid of > > > > the nested case. I also get rid of extra > > > > table_tuple_fetch_row_version() in ExecUpdate. Why re-fetch the old > > > > tuple, when it should be exactly the same tuple we've just locked. > > > > > > > > I'm going to check the performance impact. Thoughts and feedback are welcome. > > > > > > The patch does not apply on top of HEAD as in [1], please post a rebased patch: > > > === Applying patches on top of PostgreSQL commit ID > > > eb5ad4ff05fd382ac98cab60b82f7fd6ce4cfeb8 === > > > === applying patch > > > ./0001-Lock-updated-tuples-in-tuple_update-and-tuple_del-v1.patch > > > patching file src/backend/executor/nodeModifyTable.c > > > ... > > > Hunk #3 FAILED at 1376. > > > ... > > > 1 out of 15 hunks FAILED -- saving rejects to file > > > src/backend/executor/nodeModifyTable.c.rej > > > > > > [1] - http://cfbot.cputube.org/patch_41_4099.log > > > > The rebased patch is attached. It's just a change in formatting, no > > changes in code though. > > One more update of a patchset to avoid compiler warnings. Thank you for your help. I'm going to provide the revised version of patch with comments and commit message in the next couple of days. ------ Regards, Alexander Korotkov
On Wed, Jan 4, 2023 at 5:05 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: > On Wed, Jan 4, 2023 at 3:43 PM Pavel Borisov <pashkin.elfe@gmail.com> wrote: > > One more update of a patchset to avoid compiler warnings. > > Thank you for your help. I'm going to provide the revised version of > patch with comments and commit message in the next couple of days. The revised patch is attached. It contains describing commit message, comments and some minor code improvements. ------ Regards, Alexander Korotkov
Вложения
Hi, Alexander! On Thu, 5 Jan 2023 at 15:11, Alexander Korotkov <aekorotkov@gmail.com> wrote: > > On Wed, Jan 4, 2023 at 5:05 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: > > On Wed, Jan 4, 2023 at 3:43 PM Pavel Borisov <pashkin.elfe@gmail.com> wrote: > > > One more update of a patchset to avoid compiler warnings. > > > > Thank you for your help. I'm going to provide the revised version of > > patch with comments and commit message in the next couple of days. > > The revised patch is attached. It contains describing commit message, > comments and some minor code improvements. I've looked through the patch once again. It seems in a nice state to be committed. I also noticed that in tableam level and NodeModifyTable function calls we have a one-to-one correspondence between *lockedSlot и bool lockUpdated, but no checks on this in case something changes in the code in the future. I'd propose combining these variables to remain free from these checks. See v5 of a patch. Tests are successfully passed. Besides, the new version has only some minor changes in the comments and the commit message. Kind regards, Pavel Borisov, Supabase.
Вложения
On Fri, Jan 6, 2023 at 4:46 AM Pavel Borisov <pashkin.elfe@gmail.com> wrote:
Hi, Alexander!
On Thu, 5 Jan 2023 at 15:11, Alexander Korotkov <aekorotkov@gmail.com> wrote:
>
> On Wed, Jan 4, 2023 at 5:05 PM Alexander Korotkov <aekorotkov@gmail.com> wrote:
> > On Wed, Jan 4, 2023 at 3:43 PM Pavel Borisov <pashkin.elfe@gmail.com> wrote:
> > > One more update of a patchset to avoid compiler warnings.
> >
> > Thank you for your help. I'm going to provide the revised version of
> > patch with comments and commit message in the next couple of days.
>
> The revised patch is attached. It contains describing commit message,
> comments and some minor code improvements.
I've looked through the patch once again. It seems in a nice state to
be committed.
I also noticed that in tableam level and NodeModifyTable function
calls we have a one-to-one correspondence between *lockedSlot и bool
lockUpdated, but no checks on this in case something changes in the
code in the future. I'd propose combining these variables to remain
free from these checks. See v5 of a patch. Tests are successfully
passed.
Besides, the new version has only some minor changes in the comments
and the commit message.
Kind regards,
Pavel Borisov,
Supabase.
It looks good, and the greater the concurrency the greater the benefit will be. Just a few minor suggestions regarding comments.
"ExecDeleteAct() have already locked the old tuple for us", change "have" to "has".
The comments in heapam_tuple_delete() and heapam_tuple_update() might be a little clearer with something like:
"If the tuple has been concurrently updated, get lock already so that on
retry it will succeed, provided that the caller asked to do this by
providing a lockedSlot."
retry it will succeed, provided that the caller asked to do this by
providing a lockedSlot."
Also, not too important, but perhaps better clarify in the commit message that the repeated work is driven by ExecUpdate and ExecDelete and can happen multiple times depending on the concurrency.
Best Regards,
Mason
Hi, Mason! Thank you very much for your review. On Sun, Jan 8, 2023 at 9:33 PM Mason Sharp <masonlists@gmail.com> wrote: > On Fri, Jan 6, 2023 at 4:46 AM Pavel Borisov <pashkin.elfe@gmail.com> wrote: >> Besides, the new version has only some minor changes in the comments >> and the commit message. > It looks good, and the greater the concurrency the greater the benefit will be. Just a few minor suggestions regardingcomments. > > "ExecDeleteAct() have already locked the old tuple for us", change "have" to "has". > > The comments in heapam_tuple_delete() and heapam_tuple_update() might be a little clearer with something like: > > "If the tuple has been concurrently updated, get lock already so that on > retry it will succeed, provided that the caller asked to do this by > providing a lockedSlot." Thank you. These changes are incorporated into v6 of the patch. > Also, not too important, but perhaps better clarify in the commit message that the repeated work is driven by ExecUpdateand ExecDelete and can happen multiple times depending on the concurrency. Hmm... It can't happen arbitrary number of times. If tuple was concurrently updated, the we lock it. Once we lock, nobody can change it until we finish out work. So, I think no changes needed. I'm going to push this if no objections. ------ Regards, Alexander Korotkov
Вложения
Hi Alexander,
> I'm going to push this if no objections.
I took a fresh look at the patch and it LGTM. I only did a few
cosmetic changes, PFA v7.
Changes since v6 are:
```
@@ -318,12 +318,12 @@ heapam_tuple_delete(Relation relation,
ItemPointer tid, CommandId cid,
result = heap_delete(relation, tid, cid, crosscheck, wait, tmfd,
changingPart);
/*
- * If the tuple has been concurrently updated, get lock already so that on
- * retry it will succeed, provided that the caller asked to do this by
- * providing a lockedSlot.
+ * If lockUpdated is true and the tuple has been concurrently updated, get
+ * the lock immediately so that on retry we will succeed.
*/
if (result == TM_Updated && lockUpdated)
{
+ Assert(lockedSlot != NULL);
```
... and the same for heapam_tuple_update().
--
Best regards,
Aleksander Alekseev
Вложения
Hi Aleksander, On Mon, Jan 9, 2023 at 12:56 PM Aleksander Alekseev <aleksander@timescale.com> wrote: > > I'm going to push this if no objections. > > I took a fresh look at the patch and it LGTM. I only did a few > cosmetic changes, PFA v7. > > Changes since v6 are: Thank you for looking into this. It appears that I've applied changes proposed by Mason to v5, not v6. That lead to comment mismatch with the code that you've noticed. v8 should be correct. Please, recheck. ------ Regards, Alexander Korotkov
Вложения
On Mon, Jan 9, 2023 at 1:10 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: > On Mon, Jan 9, 2023 at 12:56 PM Aleksander Alekseev > <aleksander@timescale.com> wrote: > > > I'm going to push this if no objections. > > > > I took a fresh look at the patch and it LGTM. I only did a few > > cosmetic changes, PFA v7. > > > > Changes since v6 are: > > Thank you for looking into this. It appears that I've applied changes > proposed by Mason to v5, not v6. That lead to comment mismatch with > the code that you've noticed. v8 should be correct. Please, recheck. v9 also incorporates lost changes to the commit message by Pavel Borisov. ------ Regards, Alexander Korotkov
Вложения
Hi, Alexander! On Mon, 9 Jan 2023 at 13:29, Alexander Korotkov <aekorotkov@gmail.com> wrote: > > On Mon, Jan 9, 2023 at 1:10 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: > > On Mon, Jan 9, 2023 at 12:56 PM Aleksander Alekseev > > <aleksander@timescale.com> wrote: > > > > I'm going to push this if no objections. > > > > > > I took a fresh look at the patch and it LGTM. I only did a few > > > cosmetic changes, PFA v7. > > > > > > Changes since v6 are: > > > > Thank you for looking into this. It appears that I've applied changes > > proposed by Mason to v5, not v6. That lead to comment mismatch with > > the code that you've noticed. v8 should be correct. Please, recheck. > > v9 also incorporates lost changes to the commit message by Pavel Borisov. I've looked through patch v9. It resembles patch v5 plus comments clarification by Mason plus the right discussion link in the commit message from v8. Aleksander's proposal of Assert in v7 was due to changes lost between v5 and v6, as combining connected variables in v5 makes checks for them being in agreement one with the other unnecessary. So changes from v7 are not in v9. Sorry for being so detailed in small details. In my opinion the patch now is ready to be committed. Regards, Pavel Borisov
Alexander, Pavel, > Sorry for being so detailed in small details. In my opinion the patch > now is ready to be committed. Agree. Personally I liked the version with (lockUpdated, lockedSlot) pair a bit more since it is a bit more readable, however the version without lockUpdated is less error prone and slightly more efficient. So all in all I have no strong opinion on which is better. -- Best regards, Aleksander Alekseev
Hi, Pavel! On Mon, Jan 9, 2023 at 1:41 PM Pavel Borisov <pashkin.elfe@gmail.com> wrote: > On Mon, 9 Jan 2023 at 13:29, Alexander Korotkov <aekorotkov@gmail.com> wrote: > > On Mon, Jan 9, 2023 at 1:10 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: > > > On Mon, Jan 9, 2023 at 12:56 PM Aleksander Alekseev > > > <aleksander@timescale.com> wrote: > > > > > I'm going to push this if no objections. > > > > > > > > I took a fresh look at the patch and it LGTM. I only did a few > > > > cosmetic changes, PFA v7. > > > > > > > > Changes since v6 are: > > > > > > Thank you for looking into this. It appears that I've applied changes > > > proposed by Mason to v5, not v6. That lead to comment mismatch with > > > the code that you've noticed. v8 should be correct. Please, recheck. > > > > v9 also incorporates lost changes to the commit message by Pavel Borisov. > I've looked through patch v9. It resembles patch v5 plus comments > clarification by Mason plus the right discussion link in the commit > message from v8. Aleksander's proposal of Assert in v7 was due to > changes lost between v5 and v6, as combining connected variables in v5 > makes checks for them being in agreement one with the other > unnecessary. So changes from v7 are not in v9. > > Sorry for being so detailed in small details. In my opinion the patch > now is ready to be committed. Sorry for creating this mess with lost changes. And thank you for confirming it's good now. I'm going to push v9. ------ Regards, Alexander Korotkov
Hi, On 2023-01-09 13:46:50 +0300, Alexander Korotkov wrote: > I'm going to push v9. Could you hold off for a bit? I'd like to look at this, I'm not sure I like the direction. Greetings, Andres Freund
Hi,
I'm a bit worried that this is optimizing the rare case while hurting the
common case. See e.g. my point below about creating additional slots in the
happy path.
It's also not clear that change is right directionally. If we want to avoid
re-fetching the "original" row version, why don't we provide that
functionality via table_tuple_lock()?
On 2023-01-09 13:29:18 +0300, Alexander Korotkov wrote:
> @@ -53,6 +53,12 @@ static bool SampleHeapTupleVisible(TableScanDesc scan, Buffer buffer,
> HeapTuple tuple,
> OffsetNumber tupoffset);
>
> +static TM_Result heapam_tuple_lock_internal(Relation relation, ItemPointer tid,
> + Snapshot snapshot, TupleTableSlot *slot,
> + CommandId cid, LockTupleMode mode,
> + LockWaitPolicy wait_policy, uint8 flags,
> + TM_FailureData *tmfd, bool updated);
> +
> static BlockNumber heapam_scan_get_blocks_done(HeapScanDesc hscan);
>
> static const TableAmRoutine heapam_methods;
> @@ -299,14 +305,39 @@ heapam_tuple_complete_speculative(Relation relation, TupleTableSlot *slot,
> static TM_Result
> heapam_tuple_delete(Relation relation, ItemPointer tid, CommandId cid,
> Snapshot snapshot, Snapshot crosscheck, bool wait,
> - TM_FailureData *tmfd, bool changingPart)
> + TM_FailureData *tmfd, bool changingPart,
> + TupleTableSlot *lockedSlot)
> {
> + TM_Result result;
> +
> /*
> * Currently Deleting of index tuples are handled at vacuum, in case if
> * the storage itself is cleaning the dead tuples by itself, it is the
> * time to call the index tuple deletion also.
> */
> - return heap_delete(relation, tid, cid, crosscheck, wait, tmfd, changingPart);
> + result = heap_delete(relation, tid, cid, crosscheck, wait, tmfd, changingPart);
> +
> + /*
> + * If the tuple has been concurrently updated, get lock already so that on
> + * retry it will succeed, provided that the caller asked to do this by
> + * providing a lockedSlot.
> + */
> + if (result == TM_Updated && lockedSlot != NULL)
> + {
> + result = heapam_tuple_lock_internal(relation, tid, snapshot,
> + lockedSlot, cid, LockTupleExclusive,
> + LockWaitBlock,
> + TUPLE_LOCK_FLAG_FIND_LAST_VERSION,
> + tmfd, true);
You're ignoring the 'wait' parameter here, no? I think the modification to
heapam_tuple_update() has the same issue.
> + if (result == TM_Ok)
> + {
> + tmfd->traversed = true;
> + return TM_Updated;
> + }
> + }
> +
> + return result;
Doesn't this mean that the caller can't easily distinguish between
heapam_tuple_delete() and heapam_tuple_lock_internal() returning a failure
state?
> @@ -350,213 +402,8 @@ heapam_tuple_lock(Relation relation, ItemPointer tid, Snapshot snapshot,
> LockWaitPolicy wait_policy, uint8 flags,
> TM_FailureData *tmfd)
> {
Moving the entire body of the function around, makes it harder to review
this change, because the code movement is intermingled with "actual" changes.
> +/*
> + * This routine does the work for heapam_tuple_lock(), but also support
> + * `updated` to re-use the work done by heapam_tuple_update() or
> + * heapam_tuple_delete() on fetching tuple and checking its visibility.
> + */
> +static TM_Result
> +heapam_tuple_lock_internal(Relation relation, ItemPointer tid, Snapshot snapshot,
> + TupleTableSlot *slot, CommandId cid, LockTupleMode mode,
> + LockWaitPolicy wait_policy, uint8 flags,
> + TM_FailureData *tmfd, bool updated)
> +{
> + BufferHeapTupleTableSlot *bslot = (BufferHeapTupleTableSlot *) slot;
> + TM_Result result;
> + Buffer buffer = InvalidBuffer;
> + HeapTuple tuple = &bslot->base.tupdata;
> + bool follow_updates;
> +
> + follow_updates = (flags & TUPLE_LOCK_FLAG_LOCK_UPDATE_IN_PROGRESS) != 0;
> + tmfd->traversed = false;
> +
> + Assert(TTS_IS_BUFFERTUPLE(slot));
> +
> +tuple_lock_retry:
> + tuple->t_self = *tid;
> + if (!updated)
> + result = heap_lock_tuple(relation, tuple, cid, mode, wait_policy,
> + follow_updates, &buffer, tmfd);
> + else
> + result = TM_Updated;
To make sure I understand: You're basically trying to have
heapam_tuple_lock_internal() work as before, except that you want to omit
fetching the first row version, assuming that the caller already tried to lock
it?
I think at the very this needs an assert verifying that the slot actually
contains a tuple in the "updated" path.
> + if (result == TM_Updated &&
> + (flags & TUPLE_LOCK_FLAG_FIND_LAST_VERSION))
> + {
> + if (!updated)
> + {
> + /* Should not encounter speculative tuple on recheck */
> + Assert(!HeapTupleHeaderIsSpeculative(tuple->t_data));
Why shouldn't this be checked in the updated case as well?
> @@ -1490,7 +1492,16 @@ ExecDelete(ModifyTableContext *context,
> * transaction-snapshot mode transactions.
> */
> ldelete:
> - result = ExecDeleteAct(context, resultRelInfo, tupleid, changingPart);
> +
> + /*
> + * Ask ExecDeleteAct() to immediately place the lock on the updated
> + * tuple if we will need EvalPlanQual() in that case to handle it.
> + */
> + if (!IsolationUsesXactSnapshot())
> + slot = ExecGetReturningSlot(estate, resultRelInfo);
> +
> + result = ExecDeleteAct(context, resultRelInfo, tupleid, changingPart,
> + slot);
I don't like that 'slot' is now used for multiple things. I think this could
best be addressed by simply moving the slot variable inside the blocks using
it. And here it should be named more accurately.
Is there a potential conflict with other uses of the ExecGetReturningSlot()?
Given that we now always create the slot, doesn't this increase the overhead
for the very common case of not needing EPQ? We'll create unnecessary slots
all the time, no?
> */
> EvalPlanQualBegin(context->epqstate);
> inputslot = EvalPlanQualSlot(context->epqstate, resultRelationDesc,
> resultRelInfo->ri_RangeTableIndex);
> + ExecCopySlot(inputslot, slot);
> - result = table_tuple_lock(resultRelationDesc, tupleid,
> - estate->es_snapshot,
> - inputslot, estate->es_output_cid,
> - LockTupleExclusive, LockWaitBlock,
> - TUPLE_LOCK_FLAG_FIND_LAST_VERSION,
> - &context->tmfd);
> + Assert(context->tmfd.traversed);
> + epqslot = EvalPlanQual(context->epqstate,
> + resultRelationDesc,
> + resultRelInfo->ri_RangeTableIndex,
> + inputslot);
The only point of using EvalPlanQualSlot() is to avoid copying the tuple from
one slot to another. Given that we're not benefiting from that anymore (due to
your manual ExecCopySlot() call), it seems we could just pass 'slot' to
EvalPlanQual() and not bother with EvalPlanQualSlot().
> @@ -1449,6 +1451,8 @@ table_multi_insert(Relation rel, TupleTableSlot **slots, int nslots,
> * tmfd - filled in failure cases (see below)
> * changingPart - true iff the tuple is being moved to another partition
> * table due to an update of the partition key. Otherwise, false.
> + * lockedSlot - slot to save the locked tuple if should lock the last row
> + * version during the concurrent update. NULL if not needed.
The grammar in the new comments is off ("if should lock").
I think this is also needs to mention that this *significantly* changes the
behaviour of table_tuple_delete(). That's not at all clear from the comment.
Greetings,
Andres Freund
It looks like this patch received some feedback from Andres and hasn't had any further work posted. I'm going to move it to "Waiting on Author". It doesn't sound like this is likely to get committed this release cycle unless responding to Andres's points simpler than I expect.
On Wed, Mar 1, 2023 at 12:03 AM Gregory Stark <stark@postgresql.org> wrote: > It looks like this patch received some feedback from Andres and hasn't > had any further work posted. I'm going to move it to "Waiting on > Author". I'll post the updated version in the next couple of days. > It doesn't sound like this is likely to get committed this release > cycle unless responding to Andres's points simpler than I expect. I wouldn't think ahead that much. ------ Regards, Alexander Korotkov
Hi, Andres.
Thank you for your review. Sorry for the late reply. I took some
time for me to figure out how to revise the patch.
The revised patchset is attached. I decided to split the patch into two:
1) Avoid re-fetching the "original" row version during update and delete.
2) Save the efforts by re-using existing context of
tuple_update()/tuple_delete() for locking the tuple.
They are two separate optimizations. So let's evaluate their
performance separately.
On Tue, Jan 10, 2023 at 4:07 AM Andres Freund <andres@anarazel.de> wrote:
> I'm a bit worried that this is optimizing the rare case while hurting the
> common case. See e.g. my point below about creating additional slots in the
> happy path.
This makes sense. It worth to allocate the slot only if we're going
to store a tuple there. I implemented this by passing a callback for
slot allocation instead of the slot.
> It's also not clear that change is right directionally. If we want to avoid
> re-fetching the "original" row version, why don't we provide that
> functionality via table_tuple_lock()?
These are two distinct optimizations. Now, they come as two distinct patches.
> On 2023-01-09 13:29:18 +0300, Alexander Korotkov wrote:
> > @@ -53,6 +53,12 @@ static bool SampleHeapTupleVisible(TableScanDesc scan, Buffer buffer,
> > HeapTuple tuple,
> > OffsetNumber tupoffset);
> >
> > +static TM_Result heapam_tuple_lock_internal(Relation relation, ItemPointer tid,
> > + Snapshot snapshot,
TupleTableSlot*slot,
> > + CommandId cid, LockTupleMode
mode,
> > + LockWaitPolicy wait_policy,
uint8flags,
> > + TM_FailureData *tmfd, bool
updated);
> > +
> > static BlockNumber heapam_scan_get_blocks_done(HeapScanDesc hscan);
> >
> > static const TableAmRoutine heapam_methods;
> > @@ -299,14 +305,39 @@ heapam_tuple_complete_speculative(Relation relation, TupleTableSlot *slot,
> > static TM_Result
> > heapam_tuple_delete(Relation relation, ItemPointer tid, CommandId cid,
> > Snapshot snapshot, Snapshot crosscheck, bool wait,
> > - TM_FailureData *tmfd, bool changingPart)
> > + TM_FailureData *tmfd, bool changingPart,
> > + TupleTableSlot *lockedSlot)
> > {
> > + TM_Result result;
> > +
> > /*
> > * Currently Deleting of index tuples are handled at vacuum, in case if
> > * the storage itself is cleaning the dead tuples by itself, it is the
> > * time to call the index tuple deletion also.
> > */
> > - return heap_delete(relation, tid, cid, crosscheck, wait, tmfd, changingPart);
> > + result = heap_delete(relation, tid, cid, crosscheck, wait, tmfd, changingPart);
> > +
> > + /*
> > + * If the tuple has been concurrently updated, get lock already so that on
> > + * retry it will succeed, provided that the caller asked to do this by
> > + * providing a lockedSlot.
> > + */
> > + if (result == TM_Updated && lockedSlot != NULL)
> > + {
> > + result = heapam_tuple_lock_internal(relation, tid, snapshot,
> > + lockedSlot, cid,
LockTupleExclusive,
> > + LockWaitBlock,
> > +
TUPLE_LOCK_FLAG_FIND_LAST_VERSION,
> > + tmfd, true);
>
> You're ignoring the 'wait' parameter here, no? I think the modification to
> heapam_tuple_update() has the same issue.
Yep. I didn't catch this, because currently we also call
tuple_update()/tuple_delete() with wait == true. Fixed.
> > + if (result == TM_Ok)
> > + {
> > + tmfd->traversed = true;
> > + return TM_Updated;
> > + }
> > + }
> > +
> > + return result;
>
> Doesn't this mean that the caller can't easily distinguish between
> heapam_tuple_delete() and heapam_tuple_lock_internal() returning a failure
> state?
Exactly. But currently nodeModifyTable.c handles these failure states
in the similar way. And I don't see why it should be different in
future.
> > @@ -350,213 +402,8 @@ heapam_tuple_lock(Relation relation, ItemPointer tid, Snapshot snapshot,
> > LockWaitPolicy wait_policy, uint8 flags,
> > TM_FailureData *tmfd)
> > {
>
> Moving the entire body of the function around, makes it harder to review
> this change, because the code movement is intermingled with "actual" changes.
OK, fixed.
> > +/*
> > + * This routine does the work for heapam_tuple_lock(), but also support
> > + * `updated` to re-use the work done by heapam_tuple_update() or
> > + * heapam_tuple_delete() on fetching tuple and checking its visibility.
> > + */
> > +static TM_Result
> > +heapam_tuple_lock_internal(Relation relation, ItemPointer tid, Snapshot snapshot,
> > + TupleTableSlot *slot, CommandId cid, LockTupleMode mode,
> > + LockWaitPolicy wait_policy, uint8 flags,
> > + TM_FailureData *tmfd, bool updated)
> > +{
> > + BufferHeapTupleTableSlot *bslot = (BufferHeapTupleTableSlot *) slot;
> > + TM_Result result;
> > + Buffer buffer = InvalidBuffer;
> > + HeapTuple tuple = &bslot->base.tupdata;
> > + bool follow_updates;
> > +
> > + follow_updates = (flags & TUPLE_LOCK_FLAG_LOCK_UPDATE_IN_PROGRESS) != 0;
> > + tmfd->traversed = false;
> > +
> > + Assert(TTS_IS_BUFFERTUPLE(slot));
> > +
> > +tuple_lock_retry:
> > + tuple->t_self = *tid;
> > + if (!updated)
> > + result = heap_lock_tuple(relation, tuple, cid, mode, wait_policy,
> > + follow_updates, &buffer, tmfd);
> > + else
> > + result = TM_Updated;
>
> To make sure I understand: You're basically trying to have
> heapam_tuple_lock_internal() work as before, except that you want to omit
> fetching the first row version, assuming that the caller already tried to lock
> it?
>
> I think at the very this needs an assert verifying that the slot actually
> contains a tuple in the "updated" path.
This part was re-written.
> > + if (result == TM_Updated &&
> > + (flags & TUPLE_LOCK_FLAG_FIND_LAST_VERSION))
> > + {
> > + if (!updated)
> > + {
> > + /* Should not encounter speculative tuple on recheck */
> > + Assert(!HeapTupleHeaderIsSpeculative(tuple->t_data));
>
> Why shouldn't this be checked in the updated case as well?
>
>
> > @@ -1490,7 +1492,16 @@ ExecDelete(ModifyTableContext *context,
> > * transaction-snapshot mode transactions.
> > */
> > ldelete:
> > - result = ExecDeleteAct(context, resultRelInfo, tupleid, changingPart);
> > +
> > + /*
> > + * Ask ExecDeleteAct() to immediately place the lock on the updated
> > + * tuple if we will need EvalPlanQual() in that case to handle it.
> > + */
> > + if (!IsolationUsesXactSnapshot())
> > + slot = ExecGetReturningSlot(estate, resultRelInfo);
> > +
> > + result = ExecDeleteAct(context, resultRelInfo, tupleid, changingPart,
> > + slot);
>
> I don't like that 'slot' is now used for multiple things. I think this could
> best be addressed by simply moving the slot variable inside the blocks using
> it. And here it should be named more accurately.
I didn't do that refactoring. But now editing introduced by the 1st
patch of the set are more granular and doesn't affect usage of the
'slot' variable.
> Is there a potential conflict with other uses of the ExecGetReturningSlot()?
Yep. The current revision evades this random usage of slots.
> Given that we now always create the slot, doesn't this increase the overhead
> for the very common case of not needing EPQ? We'll create unnecessary slots
> all the time, no?
Yes, this is addressed by allocating EPQ slot only once it is needed
via callback. I'm thinking about wrapping this into some abstraction
called 'LazySlot'.
> > */
> > EvalPlanQualBegin(context->epqstate);
> > inputslot = EvalPlanQualSlot(context->epqstate, resultRelationDesc,
> >
resultRelInfo->ri_RangeTableIndex);
> > + ExecCopySlot(inputslot, slot);
>
> > - result = table_tuple_lock(resultRelationDesc, tupleid,
> > - estate->es_snapshot,
> > - inputslot,
estate->es_output_cid,
> > - LockTupleExclusive,
LockWaitBlock,
> > -
TUPLE_LOCK_FLAG_FIND_LAST_VERSION,
> > - &context->tmfd);
> > + Assert(context->tmfd.traversed);
> > + epqslot = EvalPlanQual(context->epqstate,
> > + resultRelationDesc,
> > +
resultRelInfo->ri_RangeTableIndex,
> > + inputslot);
>
> The only point of using EvalPlanQualSlot() is to avoid copying the tuple from
> one slot to another. Given that we're not benefiting from that anymore (due to
> your manual ExecCopySlot() call), it seems we could just pass 'slot' to
> EvalPlanQual() and not bother with EvalPlanQualSlot().
This makes sense. Now, usage pattern of the slots is more clear.
> > @@ -1449,6 +1451,8 @@ table_multi_insert(Relation rel, TupleTableSlot **slots, int nslots,
> > * tmfd - filled in failure cases (see below)
> > * changingPart - true iff the tuple is being moved to another partition
> > * table due to an update of the partition key. Otherwise, false.
> > + * lockedSlot - slot to save the locked tuple if should lock the last row
> > + * version during the concurrent update. NULL if not needed.
>
> The grammar in the new comments is off ("if should lock").
>
> I think this is also needs to mention that this *significantly* changes the
> behaviour of table_tuple_delete(). That's not at all clear from the comment.
Let's see the performance results for the patchset. I'll properly
revise the comments if results will be good.
Pavel, could you please re-run your tests over revised patchset?
------
Regards,
Alexander Korotkov
Вложения
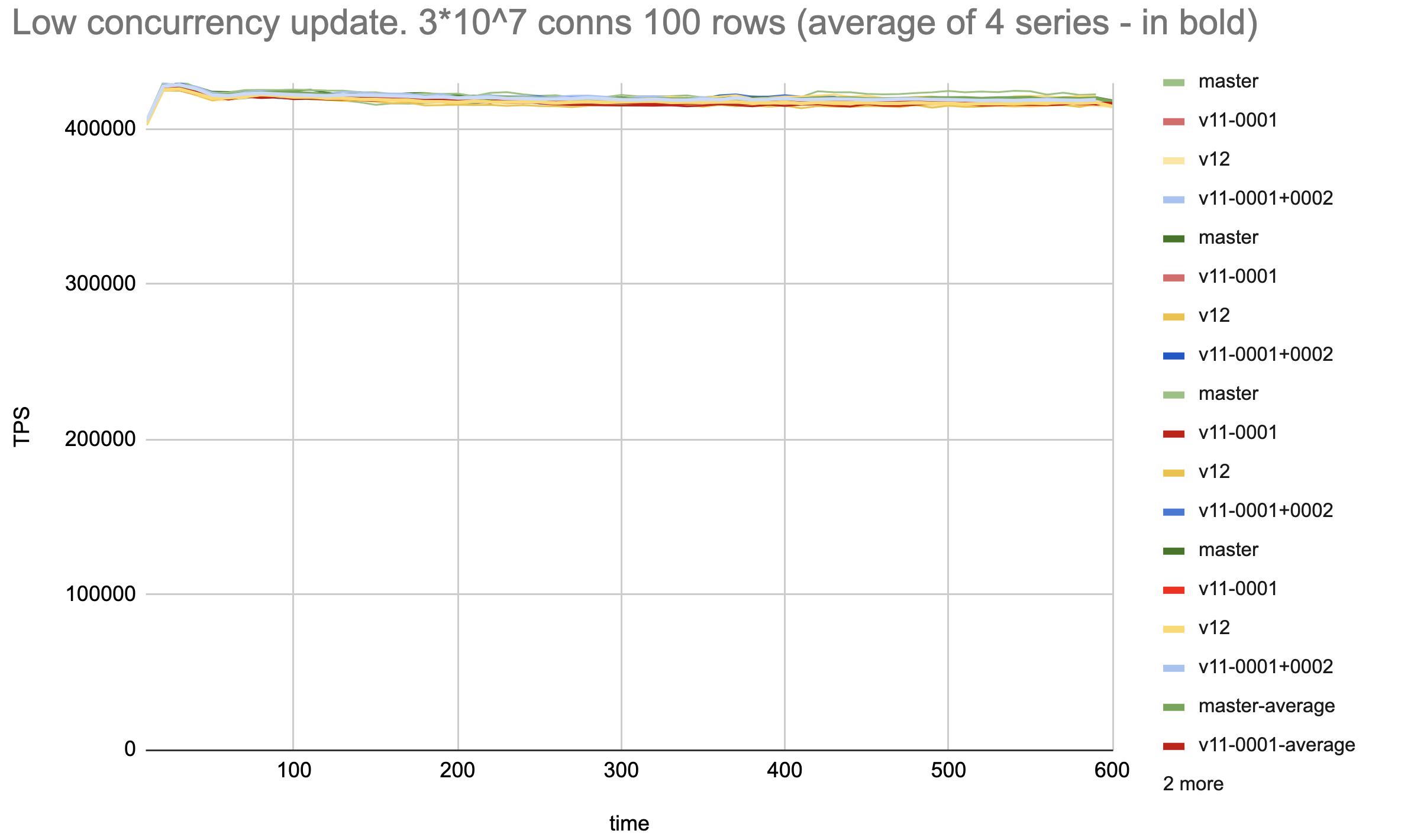
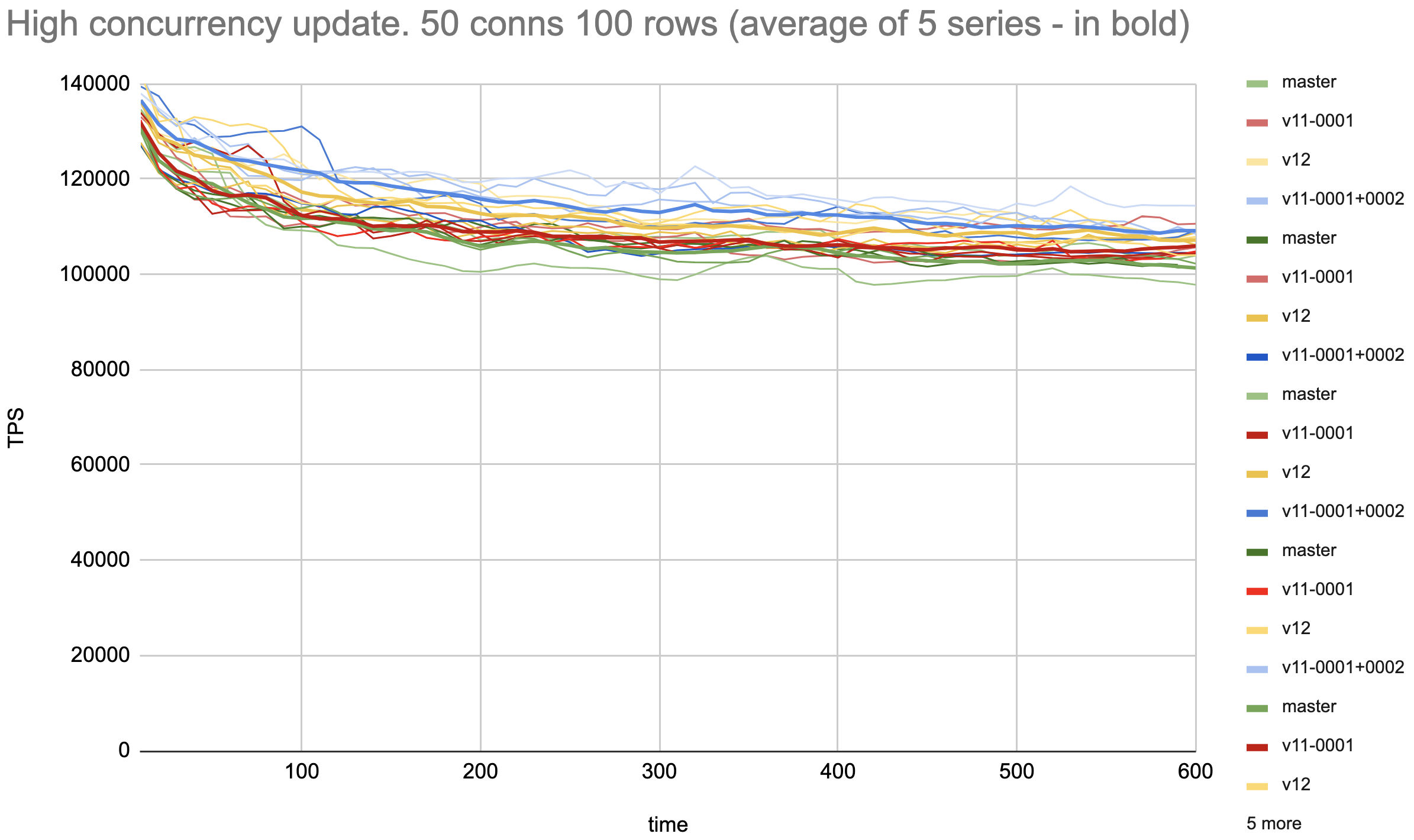
Hi, Alexander! > Let's see the performance results for the patchset. I'll properly > revise the comments if results will be good. > > Pavel, could you please re-run your tests over revised patchset? Since last time I've improved the test to avoid significant series differences due to AWS storage access variation that is seen in [1]. I.e. each series of tests is run on a tmpfs with newly inited pgbench tables and vacuum. Also, I've added a test for low-concurrency updates where the locking optimization isn't expected to improve performance, just to make sure the patches don't make things worse. The tests are as follows: 1. Heap updates with high tuple concurrency: Prepare without pkeys (pgbench -d postgres -i -I dtGv -s 10 --unlogged-tables) Update tellers 100 rows, 50 conns ( pgbench postgres -f ./update-only-tellers.sql -s 10 -P10 -M prepared -T 600 -j 5 -c 50 ) Result: Average of 5 series with patches (0001+0002) is around 5% faster than both master and patch 0001. Still, there are some fluctuations between different series of the measurements of the same patch, but much less than in [1] 2. Heap updates with low tuple concurrency: Prepare with pkeys (pgbench -d postgres -i -I dtGvp -s 300 --unlogged-tables) Update 3*10^7 rows, 50 conns (pgbench postgres -f ./update-only-account.sql -s 300 -P10 -M prepared -T 600 -j 5 -c 50) Result: Both patches and master are the same within a tolerance of less than 0.7%. Tests are run on the same 36-vcore AWS c5.9xlarge as [1]. The results pictures are attached. Using pkeys in low-concurrency cases is to make the index search of a tuple to be updated. No pkeys in case of high concurrency is for concurrent index updates not contribute to updates performance. Common settings: shared_memory 20Gb max_worker_processes = 1024 max_parallel_workers = 1024 max_connections=10000 autovacuum_multixact_freeze_max_age=2000000000 autovacuum_freeze_max_age=2000000000 max_wal_senders=0 wal_level=minimal max_wal_size = 10G autovacuum = off fsync = off full_page_writes = off Kind regards, Pavel Borisov, Supabase. [1] https://www.postgresql.org/message-id/CALT9ZEGhxwh2_WOpOjdazW7CNkBzen17h7xMdLbBjfZb5aULgg%40mail.gmail.com
Вложения
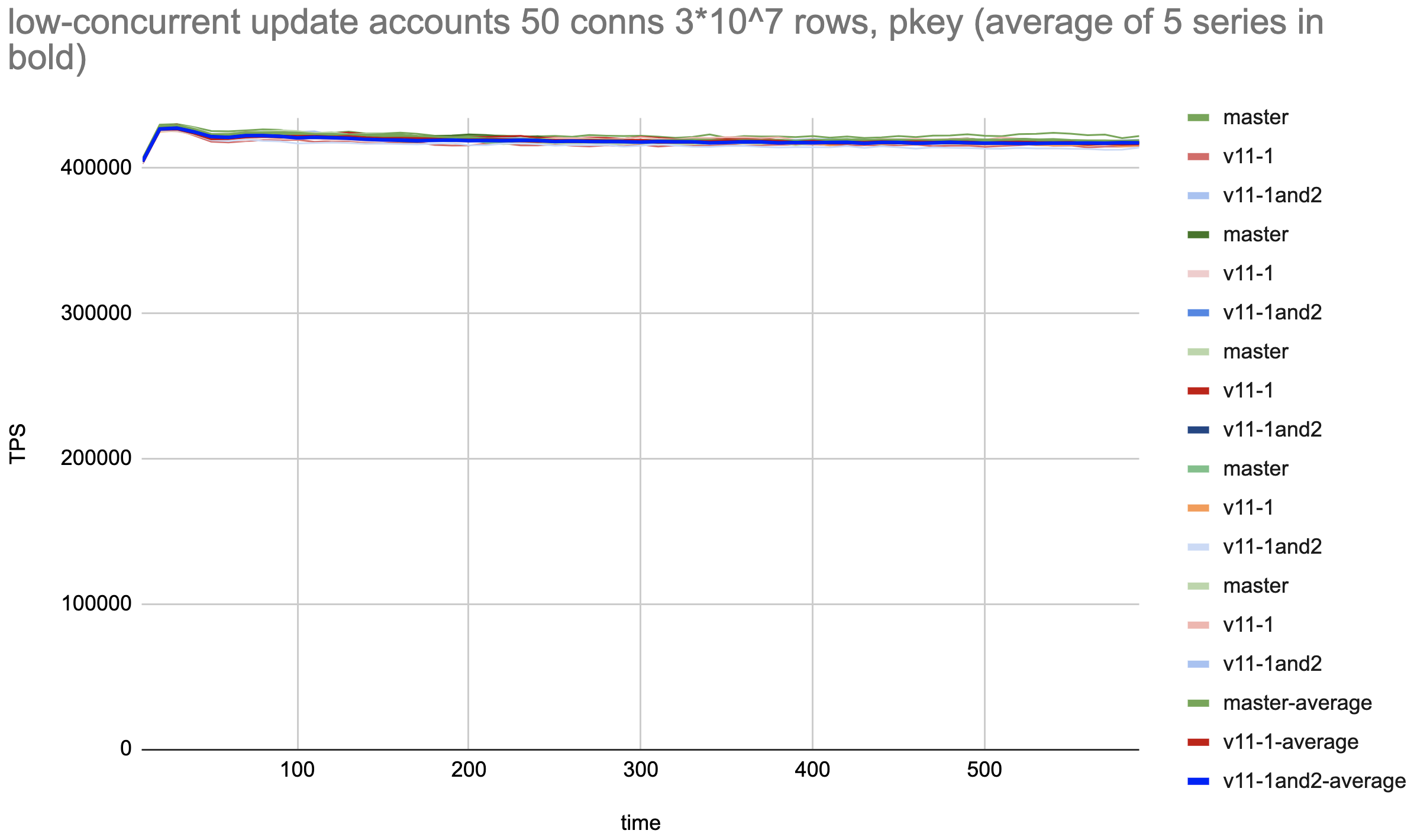{kind=link}
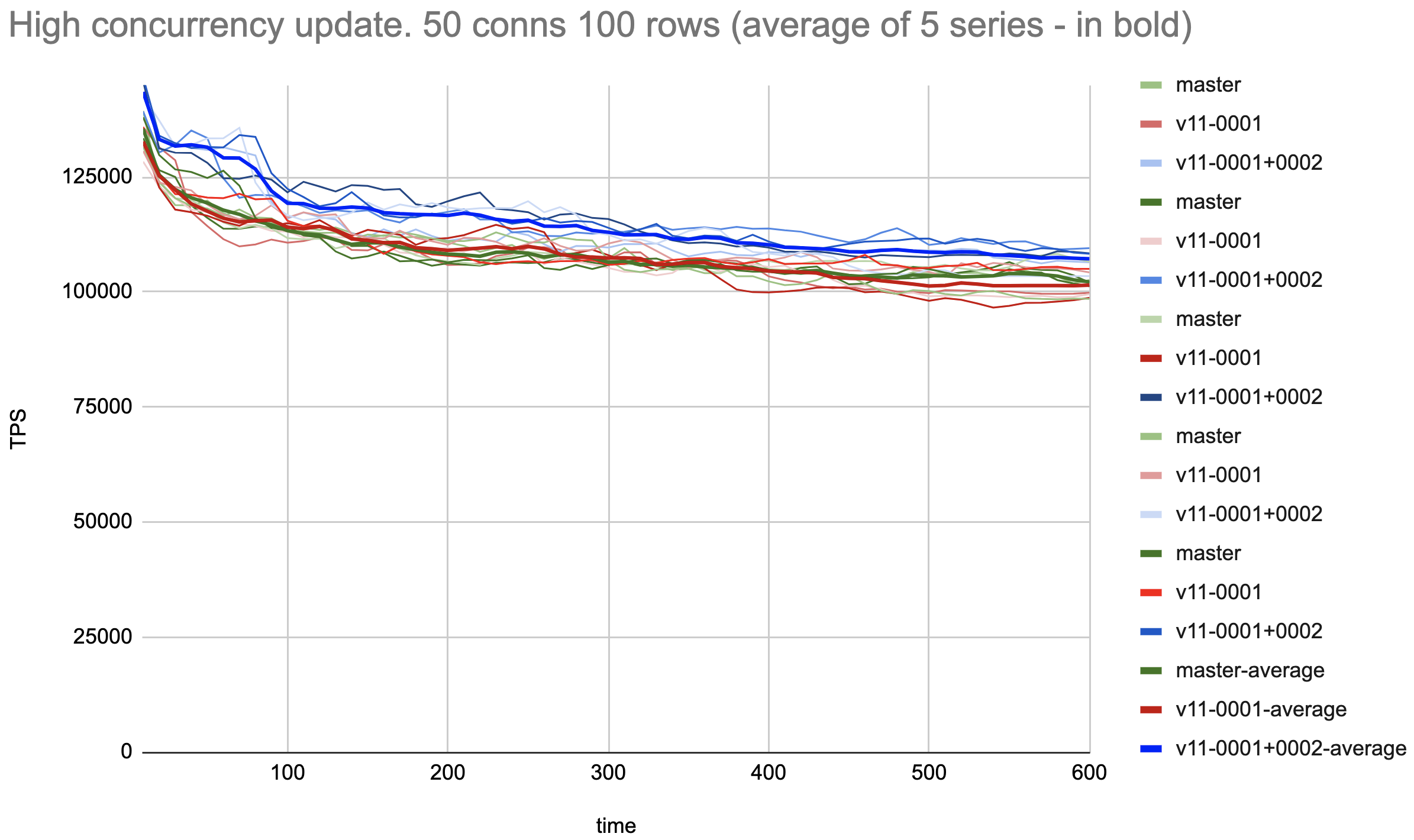{kind=link}
Hi, Pavel! On Thu, Mar 2, 2023 at 1:29 PM Pavel Borisov <pashkin.elfe@gmail.com> wrote: > > Let's see the performance results for the patchset. I'll properly > > revise the comments if results will be good. > > > > Pavel, could you please re-run your tests over revised patchset? > > Since last time I've improved the test to avoid significant series > differences due to AWS storage access variation that is seen in [1]. > I.e. each series of tests is run on a tmpfs with newly inited pgbench > tables and vacuum. Also, I've added a test for low-concurrency updates > where the locking optimization isn't expected to improve performance, > just to make sure the patches don't make things worse. > > The tests are as follows: > 1. Heap updates with high tuple concurrency: > Prepare without pkeys (pgbench -d postgres -i -I dtGv -s 10 --unlogged-tables) > Update tellers 100 rows, 50 conns ( pgbench postgres -f > ./update-only-tellers.sql -s 10 -P10 -M prepared -T 600 -j 5 -c 50 ) > > Result: Average of 5 series with patches (0001+0002) is around 5% > faster than both master and patch 0001. Still, there are some > fluctuations between different series of the measurements of the same > patch, but much less than in [1] Thank you for running this that fast! So, it appears that 0001 patch has no effect. So, we probably should consider to drop 0001 patch and consider just 0002 patch. The attached patch v12 contains v11 0002 patch extracted separately. Please, add it to the performance comparison. Thanks. ------ Regards, Alexander Korotkov
Вложения
Hi, Alexander! On Thu, 2 Mar 2023 at 18:53, Alexander Korotkov <aekorotkov@gmail.com> wrote: > > Hi, Pavel! > > On Thu, Mar 2, 2023 at 1:29 PM Pavel Borisov <pashkin.elfe@gmail.com> wrote: > > > Let's see the performance results for the patchset. I'll properly > > > revise the comments if results will be good. > > > > > > Pavel, could you please re-run your tests over revised patchset? > > > > Since last time I've improved the test to avoid significant series > > differences due to AWS storage access variation that is seen in [1]. > > I.e. each series of tests is run on a tmpfs with newly inited pgbench > > tables and vacuum. Also, I've added a test for low-concurrency updates > > where the locking optimization isn't expected to improve performance, > > just to make sure the patches don't make things worse. > > > > The tests are as follows: > > 1. Heap updates with high tuple concurrency: > > Prepare without pkeys (pgbench -d postgres -i -I dtGv -s 10 --unlogged-tables) > > Update tellers 100 rows, 50 conns ( pgbench postgres -f > > ./update-only-tellers.sql -s 10 -P10 -M prepared -T 600 -j 5 -c 50 ) > > > > Result: Average of 5 series with patches (0001+0002) is around 5% > > faster than both master and patch 0001. Still, there are some > > fluctuations between different series of the measurements of the same > > patch, but much less than in [1] > > Thank you for running this that fast! > > So, it appears that 0001 patch has no effect. So, we probably should > consider to drop 0001 patch and consider just 0002 patch. > > The attached patch v12 contains v11 0002 patch extracted separately. > Please, add it to the performance comparison. Thanks. I've done a benchmarking on a full series of four variants: master vs v11-0001 vs v11-0001+0002 vs v12 in the same configuration as in the previous measurement. The results are as follows: 1. Heap updates with high tuple concurrency: Average of 5 series v11-0001+0002 is around 7% faster than the master. I need to note that while v11-0001+0002 shows consistent performance improvement over the master, its value can not be determined more precisely than a couple of percents even with averaging. So I'd suppose we may not conclude from the results if a more subtle difference between v11-0001+0002 vs v12 (and master vs v11-0001) really exists. 2. Heap updates with high tuple concurrency: All patches and master are still the same within a tolerance of less than 0.7%. Overall patch v11-0001+0002 doesn't show performance degradation so I don't see why to apply only patch 0002 skipping 0001. Regards, Pavel Borisov, Supabase.
Вложения
{kind=link}
{kind=link}
On Thu, Mar 2, 2023 at 9:17 PM Pavel Borisov <pashkin.elfe@gmail.com> wrote: > On Thu, 2 Mar 2023 at 18:53, Alexander Korotkov <aekorotkov@gmail.com> wrote: > > On Thu, Mar 2, 2023 at 1:29 PM Pavel Borisov <pashkin.elfe@gmail.com> wrote: > > > > Let's see the performance results for the patchset. I'll properly > > > > revise the comments if results will be good. > > > > > > > > Pavel, could you please re-run your tests over revised patchset? > > > > > > Since last time I've improved the test to avoid significant series > > > differences due to AWS storage access variation that is seen in [1]. > > > I.e. each series of tests is run on a tmpfs with newly inited pgbench > > > tables and vacuum. Also, I've added a test for low-concurrency updates > > > where the locking optimization isn't expected to improve performance, > > > just to make sure the patches don't make things worse. > > > > > > The tests are as follows: > > > 1. Heap updates with high tuple concurrency: > > > Prepare without pkeys (pgbench -d postgres -i -I dtGv -s 10 --unlogged-tables) > > > Update tellers 100 rows, 50 conns ( pgbench postgres -f > > > ./update-only-tellers.sql -s 10 -P10 -M prepared -T 600 -j 5 -c 50 ) > > > > > > Result: Average of 5 series with patches (0001+0002) is around 5% > > > faster than both master and patch 0001. Still, there are some > > > fluctuations between different series of the measurements of the same > > > patch, but much less than in [1] > > > > Thank you for running this that fast! > > > > So, it appears that 0001 patch has no effect. So, we probably should > > consider to drop 0001 patch and consider just 0002 patch. > > > > The attached patch v12 contains v11 0002 patch extracted separately. > > Please, add it to the performance comparison. Thanks. > > I've done a benchmarking on a full series of four variants: master vs > v11-0001 vs v11-0001+0002 vs v12 in the same configuration as in the > previous measurement. The results are as follows: > > 1. Heap updates with high tuple concurrency: > Average of 5 series v11-0001+0002 is around 7% faster than the master. > I need to note that while v11-0001+0002 shows consistent performance > improvement over the master, its value can not be determined more > precisely than a couple of percents even with averaging. So I'd > suppose we may not conclude from the results if a more subtle > difference between v11-0001+0002 vs v12 (and master vs v11-0001) > really exists. > > 2. Heap updates with high tuple concurrency: > All patches and master are still the same within a tolerance of > less than 0.7%. > > Overall patch v11-0001+0002 doesn't show performance degradation so I > don't see why to apply only patch 0002 skipping 0001. Thank you, Pavel. So, it seems that we have substantial benefit only with two patches. So, I'll continue working on both of them. ------ Regards, Alexander Korotkov
On Thu, Mar 2, 2023 at 11:16 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: > On Thu, Mar 2, 2023 at 9:17 PM Pavel Borisov <pashkin.elfe@gmail.com> wrote: > > On Thu, 2 Mar 2023 at 18:53, Alexander Korotkov <aekorotkov@gmail.com> wrote: > > > On Thu, Mar 2, 2023 at 1:29 PM Pavel Borisov <pashkin.elfe@gmail.com> wrote: > > > > > Let's see the performance results for the patchset. I'll properly > > > > > revise the comments if results will be good. > > > > > > > > > > Pavel, could you please re-run your tests over revised patchset? > > > > > > > > Since last time I've improved the test to avoid significant series > > > > differences due to AWS storage access variation that is seen in [1]. > > > > I.e. each series of tests is run on a tmpfs with newly inited pgbench > > > > tables and vacuum. Also, I've added a test for low-concurrency updates > > > > where the locking optimization isn't expected to improve performance, > > > > just to make sure the patches don't make things worse. > > > > > > > > The tests are as follows: > > > > 1. Heap updates with high tuple concurrency: > > > > Prepare without pkeys (pgbench -d postgres -i -I dtGv -s 10 --unlogged-tables) > > > > Update tellers 100 rows, 50 conns ( pgbench postgres -f > > > > ./update-only-tellers.sql -s 10 -P10 -M prepared -T 600 -j 5 -c 50 ) > > > > > > > > Result: Average of 5 series with patches (0001+0002) is around 5% > > > > faster than both master and patch 0001. Still, there are some > > > > fluctuations between different series of the measurements of the same > > > > patch, but much less than in [1] > > > > > > Thank you for running this that fast! > > > > > > So, it appears that 0001 patch has no effect. So, we probably should > > > consider to drop 0001 patch and consider just 0002 patch. > > > > > > The attached patch v12 contains v11 0002 patch extracted separately. > > > Please, add it to the performance comparison. Thanks. > > > > I've done a benchmarking on a full series of four variants: master vs > > v11-0001 vs v11-0001+0002 vs v12 in the same configuration as in the > > previous measurement. The results are as follows: > > > > 1. Heap updates with high tuple concurrency: > > Average of 5 series v11-0001+0002 is around 7% faster than the master. > > I need to note that while v11-0001+0002 shows consistent performance > > improvement over the master, its value can not be determined more > > precisely than a couple of percents even with averaging. So I'd > > suppose we may not conclude from the results if a more subtle > > difference between v11-0001+0002 vs v12 (and master vs v11-0001) > > really exists. > > > > 2. Heap updates with high tuple concurrency: > > All patches and master are still the same within a tolerance of > > less than 0.7%. > > > > Overall patch v11-0001+0002 doesn't show performance degradation so I > > don't see why to apply only patch 0002 skipping 0001. > > Thank you, Pavel. So, it seems that we have substantial benefit only > with two patches. So, I'll continue working on both of them. The revised patchset is attached. The patch removing extra table_tuple_fetch_row_version() is back. The second patch now implements a concept of LazyTupleTableSlot, a slot which gets allocated only when needed. Also, there is more minor refactoring and more comments. ------ Regards, Alexander Korotkov
Вложения
Hi, On 2023-03-02 14:28:56 +0400, Pavel Borisov wrote: > 2. Heap updates with low tuple concurrency: > Prepare with pkeys (pgbench -d postgres -i -I dtGvp -s 300 --unlogged-tables) > Update 3*10^7 rows, 50 conns (pgbench postgres -f > ./update-only-account.sql -s 300 -P10 -M prepared -T 600 -j 5 -c 50) > > Result: Both patches and master are the same within a tolerance of > less than 0.7%. What exactly does that mean? I would definitely not want to accept a 0.7% regression of the uncontended case to benefit the contended case here... Greetings, Andres Freund
On Tue, Mar 7, 2023 at 4:50 AM Andres Freund <andres@anarazel.de> wrote: > On 2023-03-02 14:28:56 +0400, Pavel Borisov wrote: > > 2. Heap updates with low tuple concurrency: > > Prepare with pkeys (pgbench -d postgres -i -I dtGvp -s 300 --unlogged-tables) > > Update 3*10^7 rows, 50 conns (pgbench postgres -f > > ./update-only-account.sql -s 300 -P10 -M prepared -T 600 -j 5 -c 50) > > > > Result: Both patches and master are the same within a tolerance of > > less than 0.7%. > > What exactly does that mean? I would definitely not want to accept a 0.7% > regression of the uncontended case to benefit the contended case here... I don't know what exactly Pavel meant, but average overall numbers for low concurrency are. master: 420401 (stddev of average 233) patchset v11: 420111 (stddev of average 199) The difference is less than 0.1% and that is very safely within the error. ------ Regards, Alexander Korotkov
Hi, Andres and Alexander!
On Tue, 7 Mar 2023, 10:10 Alexander Korotkov, <aekorotkov@gmail.com> wrote:
On Tue, Mar 7, 2023 at 4:50 AM Andres Freund <andres@anarazel.de> wrote:
> On 2023-03-02 14:28:56 +0400, Pavel Borisov wrote:
> > 2. Heap updates with low tuple concurrency:
> > Prepare with pkeys (pgbench -d postgres -i -I dtGvp -s 300 --unlogged-tables)
> > Update 3*10^7 rows, 50 conns (pgbench postgres -f
> > ./update-only-account.sql -s 300 -P10 -M prepared -T 600 -j 5 -c 50)
> >
> > Result: Both patches and master are the same within a tolerance of
> > less than 0.7%.
>
> What exactly does that mean? I would definitely not want to accept a 0.7%
> regression of the uncontended case to benefit the contended case here...
I don't know what exactly Pavel meant, but average overall numbers for
low concurrency are.
master: 420401 (stddev of average 233)
patchset v11: 420111 (stddev of average 199)
The difference is less than 0.1% and that is very safely within the error.
Yes, the only thing that I meant is that for low-concurrency case the results between patch and master are within the difference between repeated series of measurements. So I concluded that the test can not prove any difference between patch and master.
I haven't meant or written there is some performance degradation.
Alexander, I suppose did an extra step and calculated overall average and stddev, from raw data provided. Thanks!
Regards,
Pavel.
On Tue, Mar 7, 2023 at 7:26 PM Pavel Borisov <pashkin.elfe@gmail.com> wrote: > On Tue, 7 Mar 2023, 10:10 Alexander Korotkov, <aekorotkov@gmail.com> wrote: >> I don't know what exactly Pavel meant, but average overall numbers for >> low concurrency are. >> master: 420401 (stddev of average 233) >> patchset v11: 420111 (stddev of average 199) >> The difference is less than 0.1% and that is very safely within the error. > > > Yes, the only thing that I meant is that for low-concurrency case the results between patch and master are within the differencebetween repeated series of measurements. So I concluded that the test can not prove any difference between patchand master. > > I haven't meant or written there is some performance degradation. > > Alexander, I suppose did an extra step and calculated overall average and stddev, from raw data provided. Thanks! Pavel, thank you for verifying this. Could you, please, rerun performance benchmarks for the v13? It introduces LazyTupleTableSlot, which shouldn't do any measurable impact on performance. But still. ------ Regards, Alexander Korotkov
Hi, On 2023-03-07 04:45:32 +0300, Alexander Korotkov wrote: > The second patch now implements a concept of LazyTupleTableSlot, a slot > which gets allocated only when needed. Also, there is more minor > refactoring and more comments. This patch already is pretty big for what it actually improves. Introducing even infrastructure to get a not that big win, in a not particularly interesting, extreme, workload... What is motivating this? Greetings, Andres Freund
On Wed, Mar 8, 2023 at 4:22 AM Andres Freund <andres@anarazel.de> wrote: > On 2023-03-07 04:45:32 +0300, Alexander Korotkov wrote: > > The second patch now implements a concept of LazyTupleTableSlot, a slot > > which gets allocated only when needed. Also, there is more minor > > refactoring and more comments. > > This patch already is pretty big for what it actually improves. Introducing > even infrastructure to get a not that big win, in a not particularly > interesting, extreme, workload... It's true that the win isn't dramatic. But can't agree that workload isn't interesting. In my experience, high-contention over limited set of row is something that frequently happen is production. I personally took part in multiple investigations over such workloads. > What is motivating this? Right, the improvement this patch gives to heap is not the full motivation. Another motivation is improvement it gives to TableAM API. Our current API implies that the effort on locating the tuple by tid is small. This is more or less true for heap, where we just need to pin and lock the buffer. But imagine other TableAM implementations, where locating a tuple is more expensive. Current API insist that we do that twice in update attempt and lock. Doing that in single call could give such TableAM's singification economy (but even for heap it's something). I'm working on such TableAM: it's OrioleDB which implements index-organized tables. And I know there are other examples (for instance, zedstore), where TID lookup includes some indirection. ------ Regards, Alexander Korotkov
"Right, the improvement this patch gives to the heap is not the full motivation. Another motivation is the improvement itgives to TableAM API. Our current API implies that the effort on locating the tuple by tid is small. This is more or lesstrue for the heap, where we just need to pin and lock the buffer. But imagine other TableAM implementations, where locatinga tuple is more expensive." Yeah. Our TableAM API is a very nice start to getting pluggable storage, but we still have a long ways to go to have an abilityto really provide a wide variety of pluggable storage engines. In particular, the following approaches are likely to have much more expensive tid lookups: - columnar storage (may require a lot of random IO to reconstruct a tuple) - index oriented storage (tid no longer physically locatable in the file via seek) - compressed cold storage like pg_ctyogen (again seek may be problematic). To my mind I think the performance benefits are a nice side benefit, but the main interest I have on this is regarding improvementsin the TableAM capabilities. I cannot see how to do this without a lot more infrastructure.
On Fri, Mar 10, 2023 at 8:17 PM Chris Travers <chris.travers@gmail.com> wrote: > "Right, the improvement this patch gives to the heap is not the full motivation. Another motivation is the improvementit gives to TableAM API. Our current API implies that the effort on locating the tuple by tid is small. This ismore or less true for the heap, where we just need to pin and lock the buffer. But imagine other TableAM implementations,where locating a tuple is more expensive." > > Yeah. Our TableAM API is a very nice start to getting pluggable storage, but we still have a long ways to go to have anability to really provide a wide variety of pluggable storage engines. > > In particular, the following approaches are likely to have much more expensive tid lookups: > - columnar storage (may require a lot of random IO to reconstruct a tuple) > - index oriented storage (tid no longer physically locatable in the file via seek) > - compressed cold storage like pg_ctyogen (again seek may be problematic). > > To my mind I think the performance benefits are a nice side benefit, but the main interest I have on this is regardingimprovements in the TableAM capabilities. I cannot see how to do this without a lot more infrastructure. Chris, thank you for your feedback. The revised patch set is attached. Some comments are improved. Also, we implicitly skip the new facility for the MERGE case. As I get Dean Rasheed is going to revise the locking for MERGE soon [1]. Pavel, could you please re-run your test case on the revised patch? 1. https://www.postgresql.org/message-id/CAEZATCU9e9Ccbi70yNbCcF7xvZ+zrjiD0_6eEq2zEZA1p+707A@mail.gmail.com ------ Regards, Alexander Korotkov
Вложения
Hi! On Sun, Mar 12, 2023 at 7:05 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: > The revised patch set is attached. Some comments are improved. Also, > we implicitly skip the new facility for the MERGE case. As I get Dean > Rasheed is going to revise the locking for MERGE soon [1]. > > Pavel, could you please re-run your test case on the revised patch? I found the experiments made by Pavel [1] hard to reproduce due to the high variation of the TPS. Instead, I constructed a different benchmark, which includes multiple updates (40 rows) in one query, and run it on c5d.18xlarge. That produces stable performance results as well as measurable performance benefits of the patch. I found that patchsets v11 and v14 not showing any performance improvements over v10. v10 is also much less invasive for heap-related code. This is why I made v15 using the v10 approach and porting LazyTupleTableSlot and improved comments there. I think this should address some of Andres's complaints regarding introducing too much infrastructure [2]. The average results for high concurrency case (errors are given for a 95% confidence level) are given below. We can see that v15 gives a measurable performance improvement. master = 40084 +- 447 tps patchset v10 = 41761 +- 1117 tps patchset v11 = 41473 +- 773 tps patchset v14 = 40966 +- 1008 tps patchset v15 = 42855 +- 977 tps The average results for low concurrency case (errors are given for a 95% confidence level) are given below. It verifies that the patch introduces no overhead in the low concurrency case. master = 50626 +- 784 tps patchset v15 = 51297 +- 876 tps See attachments for raw experiment data and scripts. So, as we can see patch gives a small performance improvement for the heap in edge high concurrency case. But also it improves table AM API for future use cases [3][4]. I'm going to push patchset v15 if no objections. Links 1. https://www.postgresql.org/message-id/CALT9ZEHKdCF_jCoK2ErUuUtCuYPf82%2BZr1XE5URzneSFxz3zqA%40mail.gmail.com 2. https://www.postgresql.org/message-id/20230308012157.wo73y22ll2cojpvk%40awork3.anarazel.de 3. https://www.postgresql.org/message-id/CAPpHfdu1dqqcTz9V9iG-ZRewYAFL2VhizwfiN5SW%3DZ%2B1rj99-g%40mail.gmail.com 4. https://www.postgresql.org/message-id/167846860062.628976.2440696515718158538.pgcf%40coridan.postgresql.org ------ Regards, Alexander Korotkov
Вложения
Hi, On 2023-03-21 01:25:11 +0300, Alexander Korotkov wrote: > I'm going to push patchset v15 if no objections. Just saw that this went in - didn't catch up with the thread before, unfortunately. At the very least I'd like to see some more work on cleaning up the lazy tuple slot stuff. It's replete with unnecessary multiple-evaluation hazards - I realize that there's some of those already, but I don't think we should go further down that route. As far as I can tell there's no need for any of this to be macros. > From a8b4e8a7b27815e013ea07b8cc9ac68541a9ac07 Mon Sep 17 00:00:00 2001 > From: Alexander Korotkov <akorotkov@postgresql.org> > Date: Tue, 21 Mar 2023 00:34:15 +0300 > Subject: [PATCH 1/2] Evade extra table_tuple_fetch_row_version() in > ExecUpdate()/ExecDelete() > > When we lock tuple using table_tuple_lock() then we at the same time fetch > the locked tuple to the slot. In this case we can skip extra > table_tuple_fetch_row_version() thank to we've already fetched the 'old' tuple > and nobody can change it concurrently since it's locked. > > Discussion: https://postgr.es/m/CAPpHfdua-YFw3XTprfutzGp28xXLigFtzNbuFY8yPhqeq6X5kg%40mail.gmail.com > Reviewed-by: Aleksander Alekseev, Pavel Borisov, Vignesh C, Mason Sharp > Reviewed-by: Andres Freund, Chris Travers > --- > src/backend/executor/nodeModifyTable.c | 48 +++++++++++++++++++------- > 1 file changed, 35 insertions(+), 13 deletions(-) > > diff --git a/src/backend/executor/nodeModifyTable.c b/src/backend/executor/nodeModifyTable.c > index 3a673895082..93ebfdbb0d8 100644 > --- a/src/backend/executor/nodeModifyTable.c > +++ b/src/backend/executor/nodeModifyTable.c > @@ -1559,6 +1559,22 @@ ldelete: > { > case TM_Ok: > Assert(context->tmfd.traversed); > + > + /* > + * Save locked tuple for further processing of > + * RETURNING clause. > + */ > + if (processReturning && > + resultRelInfo->ri_projectReturning && > + !resultRelInfo->ri_FdwRoutine) > + { > + TupleTableSlot *returningSlot; > + > + returningSlot = ExecGetReturningSlot(estate, resultRelInfo); > + ExecCopySlot(returningSlot, inputslot); > + ExecMaterializeSlot(returningSlot); > + } > + > epqslot = EvalPlanQual(context->epqstate, > resultRelationDesc, > resultRelInfo->ri_RangeTableIndex, This seems a bit byzantine. We use inputslot = EvalPlanQualSlot(...) to make EvalPlanQual() a bit cheaper, because that avoids a slot copy inside EvalPlanQual(). But now we copy and materialize that slot anyway - and we do so even if EPQ fails. And we afaics also do it when epqreturnslot is set, in which case we'll afaics never use the copied slot. Read the next paragraph below before replying to the above - I don't think this is right for other reasons: > @@ -1673,12 +1689,17 @@ ldelete: > } > else > { > + /* > + * Tuple can be already fetched to the returning slot in case > + * we've previously locked it. Fetch the tuple only if the slot > + * is empty. > + */ > slot = ExecGetReturningSlot(estate, resultRelInfo); > if (oldtuple != NULL) > { > ExecForceStoreHeapTuple(oldtuple, slot, false); > } > - else > + else if (TupIsNull(slot)) > { > if (!table_tuple_fetch_row_version(resultRelationDesc, tupleid, > SnapshotAny, slot)) I don't think this is correct as-is - what if ExecDelete() is called with some older tuple in the returning slot? If we don't enter the TM_Updated path, it won't get updated, and we'll return the wrong tuple. It certainly looks possible to me - consider what happens if a first tuple enter the TM_Updated path but then fails EvalPlanQual(). If a second tuple is deleted without entering the TM_Updated path, the wrong tuple will be used for RETURNING. <plays around with isolationtester> Yes, indeed. The attached isolationtest breaks with 764da7710bf. I think it's entirely sensible to avoid the tuple fetching in ExecDelete(), but it needs a bit less localized work. Instead of using the presence of a tuple in the returning slot, ExecDelete() should track whether it already has fetched the deleted tuple. Or alternatively, do the work to avoid refetching the tuple for the much more common case of not needing EPQ at all. I guess this really is part of my issue with this change - it optimizes the rare case, while not addressing the same inefficiency in the common case. > @@ -299,14 +305,46 @@ heapam_tuple_complete_speculative(Relation relation, TupleTableSlot *slot, > static TM_Result > heapam_tuple_delete(Relation relation, ItemPointer tid, CommandId cid, > Snapshot snapshot, Snapshot crosscheck, bool wait, > - TM_FailureData *tmfd, bool changingPart) > + TM_FailureData *tmfd, bool changingPart, > + LazyTupleTableSlot *lockedSlot) > { > + TM_Result result; > + > /* > * Currently Deleting of index tuples are handled at vacuum, in case if > * the storage itself is cleaning the dead tuples by itself, it is the > * time to call the index tuple deletion also. > */ > - return heap_delete(relation, tid, cid, crosscheck, wait, tmfd, changingPart); > + result = heap_delete(relation, tid, cid, crosscheck, wait, > + tmfd, changingPart); > + > + /* > + * If the tuple has been concurrently updated, then get the lock on it. > + * (Do this if caller asked for tat by providing a 'lockedSlot'.) With the > + * lock held retry of delete should succeed even if there are more > + * concurrent update attempts. > + */ > + if (result == TM_Updated && lockedSlot) > + { > + TupleTableSlot *evalSlot; > + > + Assert(wait); > + > + evalSlot = LAZY_TTS_EVAL(lockedSlot); > + result = heapam_tuple_lock_internal(relation, tid, snapshot, > + evalSlot, cid, LockTupleExclusive, > + LockWaitBlock, > + TUPLE_LOCK_FLAG_FIND_LAST_VERSION, > + tmfd, true); Oh, huh? As I mentioned before, the unconditional use of LockWaitBlock means the wait parameter is ignored. I'm frankly getting annoyed here. > +/* > + * This routine does the work for heapam_tuple_lock(), but also support > + * `updated` argument to re-use the work done by heapam_tuple_update() or > + * heapam_tuple_delete() on figuring out that tuple was concurrently updated. > + */ > +static TM_Result > +heapam_tuple_lock_internal(Relation relation, ItemPointer tid, > + Snapshot snapshot, TupleTableSlot *slot, > + CommandId cid, LockTupleMode mode, > + LockWaitPolicy wait_policy, uint8 flags, > + TM_FailureData *tmfd, bool updated) Why is the new parameter named 'updated'? > { > BufferHeapTupleTableSlot *bslot = (BufferHeapTupleTableSlot *) slot; > TM_Result result; > - Buffer buffer; > + Buffer buffer = InvalidBuffer; > HeapTuple tuple = &bslot->base.tupdata; > bool follow_updates; > > @@ -374,16 +455,26 @@ heapam_tuple_lock(Relation relation, ItemPointer tid, Snapshot snapshot, > > tuple_lock_retry: > tuple->t_self = *tid; > - result = heap_lock_tuple(relation, tuple, cid, mode, wait_policy, > - follow_updates, &buffer, tmfd); > + if (!updated) > + result = heap_lock_tuple(relation, tuple, cid, mode, wait_policy, > + follow_updates, &buffer, tmfd); > + else > + result = TM_Updated; > > if (result == TM_Updated && > (flags & TUPLE_LOCK_FLAG_FIND_LAST_VERSION)) > { > - /* Should not encounter speculative tuple on recheck */ > - Assert(!HeapTupleHeaderIsSpeculative(tuple->t_data)); > + if (!updated) > + { > + /* Should not encounter speculative tuple on recheck */ > + Assert(!HeapTupleHeaderIsSpeculative(tuple->t_data)); Hm, why is it ok to encounter speculative tuples in the updated case? Oh, I guess you got failures because slot doesn't point anywhere at this point. > - ReleaseBuffer(buffer); > + ReleaseBuffer(buffer); > + } > + else > + { > + updated = false; > + } > > if (!ItemPointerEquals(&tmfd->ctid, &tuple->t_self)) > { Which means this is completely bogus now? HeapTuple tuple = &bslot->base.tupdata; In the first iteration this just points to the newly created slot. Which doesn't have a tuple stored in it. So the above checks some uninitialized memory. Giving up at this point. This doesn't seem ready to have been committed. Greetings, Andres Freund
Вложения
Hi! On Thu, Mar 23, 2023 at 3:30 AM Andres Freund <andres@anarazel.de> wrote: > On 2023-03-21 01:25:11 +0300, Alexander Korotkov wrote: > > I'm going to push patchset v15 if no objections. > > Just saw that this went in - didn't catch up with the thread before, > unfortunately. At the very least I'd like to see some more work on cleaning up > the lazy tuple slot stuff. It's replete with unnecessary multiple-evaluation > hazards - I realize that there's some of those already, but I don't think we > should go further down that route. As far as I can tell there's no need for > any of this to be macros. Thank you for taking a look at this, even post-commit. Regarding marcos, do you think inline functions would be good instead? > > From a8b4e8a7b27815e013ea07b8cc9ac68541a9ac07 Mon Sep 17 00:00:00 2001 > > From: Alexander Korotkov <akorotkov@postgresql.org> > > Date: Tue, 21 Mar 2023 00:34:15 +0300 > > Subject: [PATCH 1/2] Evade extra table_tuple_fetch_row_version() in > > ExecUpdate()/ExecDelete() > > > > When we lock tuple using table_tuple_lock() then we at the same time fetch > > the locked tuple to the slot. In this case we can skip extra > > table_tuple_fetch_row_version() thank to we've already fetched the 'old' tuple > > and nobody can change it concurrently since it's locked. > > > > Discussion: https://postgr.es/m/CAPpHfdua-YFw3XTprfutzGp28xXLigFtzNbuFY8yPhqeq6X5kg%40mail.gmail.com > > Reviewed-by: Aleksander Alekseev, Pavel Borisov, Vignesh C, Mason Sharp > > Reviewed-by: Andres Freund, Chris Travers > > --- > > src/backend/executor/nodeModifyTable.c | 48 +++++++++++++++++++------- > > 1 file changed, 35 insertions(+), 13 deletions(-) > > > > diff --git a/src/backend/executor/nodeModifyTable.c b/src/backend/executor/nodeModifyTable.c > > index 3a673895082..93ebfdbb0d8 100644 > > --- a/src/backend/executor/nodeModifyTable.c > > +++ b/src/backend/executor/nodeModifyTable.c > > @@ -1559,6 +1559,22 @@ ldelete: > > { > > case TM_Ok: > > Assert(context->tmfd.traversed); > > + > > + /* > > + * Save locked tuple for further processing of > > + * RETURNING clause. > > + */ > > + if (processReturning && > > + resultRelInfo->ri_projectReturning && > > + !resultRelInfo->ri_FdwRoutine) > > + { > > + TupleTableSlot *returningSlot; > > + > > + returningSlot = ExecGetReturningSlot(estate, resultRelInfo); > > + ExecCopySlot(returningSlot, inputslot); > > + ExecMaterializeSlot(returningSlot); > > + } > > + > > epqslot = EvalPlanQual(context->epqstate, > > resultRelationDesc, > > resultRelInfo->ri_RangeTableIndex, > > This seems a bit byzantine. We use inputslot = EvalPlanQualSlot(...) to make > EvalPlanQual() a bit cheaper, because that avoids a slot copy inside > EvalPlanQual(). But now we copy and materialize that slot anyway - and we do > so even if EPQ fails. And we afaics also do it when epqreturnslot is set, in > which case we'll afaics never use the copied slot. Yes, I agree that there is a redundancy we could avoid. > Read the next paragraph below before replying to the above - I don't think > this is right for other reasons: > > > @@ -1673,12 +1689,17 @@ ldelete: > > } > > else > > { > > + /* > > + * Tuple can be already fetched to the returning slot in case > > + * we've previously locked it. Fetch the tuple only if the slot > > + * is empty. > > + */ > > slot = ExecGetReturningSlot(estate, resultRelInfo); > > if (oldtuple != NULL) > > { > > ExecForceStoreHeapTuple(oldtuple, slot, false); > > } > > - else > > + else if (TupIsNull(slot)) > > { > > if (!table_tuple_fetch_row_version(resultRelationDesc, tupleid, > > SnapshotAny, slot)) > > > I don't think this is correct as-is - what if ExecDelete() is called with some > older tuple in the returning slot? If we don't enter the TM_Updated path, it > won't get updated, and we'll return the wrong tuple. It certainly looks > possible to me - consider what happens if a first tuple enter the TM_Updated > path but then fails EvalPlanQual(). If a second tuple is deleted without > entering the TM_Updated path, the wrong tuple will be used for RETURNING. > > <plays around with isolationtester> > > Yes, indeed. The attached isolationtest breaks with 764da7710bf. Thank you for cathing this! This is definitely a bug. > I think it's entirely sensible to avoid the tuple fetching in ExecDelete(), > but it needs a bit less localized work. Instead of using the presence of a > tuple in the returning slot, ExecDelete() should track whether it already has > fetched the deleted tuple. > > Or alternatively, do the work to avoid refetching the tuple for the much more > common case of not needing EPQ at all. > > I guess this really is part of my issue with this change - it optimizes the > rare case, while not addressing the same inefficiency in the common case. I'm going to fix this for ExecDelete(). Avoiding refetching the tuple in more common case is something I'm definitely very interested in. But I would leave it for the future. > > @@ -299,14 +305,46 @@ heapam_tuple_complete_speculative(Relation relation, TupleTableSlot *slot, > > static TM_Result > > heapam_tuple_delete(Relation relation, ItemPointer tid, CommandId cid, > > Snapshot snapshot, Snapshot crosscheck, bool wait, > > - TM_FailureData *tmfd, bool changingPart) > > + TM_FailureData *tmfd, bool changingPart, > > + LazyTupleTableSlot *lockedSlot) > > { > > + TM_Result result; > > + > > /* > > * Currently Deleting of index tuples are handled at vacuum, in case if > > * the storage itself is cleaning the dead tuples by itself, it is the > > * time to call the index tuple deletion also. > > */ > > - return heap_delete(relation, tid, cid, crosscheck, wait, tmfd, changingPart); > > + result = heap_delete(relation, tid, cid, crosscheck, wait, > > + tmfd, changingPart); > > + > > + /* > > + * If the tuple has been concurrently updated, then get the lock on it. > > + * (Do this if caller asked for tat by providing a 'lockedSlot'.) With the > > + * lock held retry of delete should succeed even if there are more > > + * concurrent update attempts. > > + */ > > + if (result == TM_Updated && lockedSlot) > > + { > > + TupleTableSlot *evalSlot; > > + > > + Assert(wait); > > + > > + evalSlot = LAZY_TTS_EVAL(lockedSlot); > > + result = heapam_tuple_lock_internal(relation, tid, snapshot, > > + evalSlot, cid, LockTupleExclusive, > > + LockWaitBlock, > > + TUPLE_LOCK_FLAG_FIND_LAST_VERSION, > > + tmfd, true); > > Oh, huh? As I mentioned before, the unconditional use of LockWaitBlock means > the wait parameter is ignored. > > I'm frankly getting annoyed here. lockedSlot shoudln't be provided when wait == false. The assertion above expresses this intention. However, the code lacking of comment directly expressing this idea. And sorry for getting you annoyed. The relevant comment should be already there. > > +/* > > + * This routine does the work for heapam_tuple_lock(), but also support > > + * `updated` argument to re-use the work done by heapam_tuple_update() or > > + * heapam_tuple_delete() on figuring out that tuple was concurrently updated. > > + */ > > +static TM_Result > > +heapam_tuple_lock_internal(Relation relation, ItemPointer tid, > > + Snapshot snapshot, TupleTableSlot *slot, > > + CommandId cid, LockTupleMode mode, > > + LockWaitPolicy wait_policy, uint8 flags, > > + TM_FailureData *tmfd, bool updated) > > Why is the new parameter named 'updated'? To indicate that we know that we're locking the updated tuple. Probably not descriptive enough. > > { > > BufferHeapTupleTableSlot *bslot = (BufferHeapTupleTableSlot *) slot; > > TM_Result result; > > - Buffer buffer; > > + Buffer buffer = InvalidBuffer; > > HeapTuple tuple = &bslot->base.tupdata; > > bool follow_updates; > > > > @@ -374,16 +455,26 @@ heapam_tuple_lock(Relation relation, ItemPointer tid, Snapshot snapshot, > > > > tuple_lock_retry: > > tuple->t_self = *tid; > > - result = heap_lock_tuple(relation, tuple, cid, mode, wait_policy, > > - follow_updates, &buffer, tmfd); > > + if (!updated) > > + result = heap_lock_tuple(relation, tuple, cid, mode, wait_policy, > > + follow_updates, &buffer, tmfd); > > + else > > + result = TM_Updated; > > > > if (result == TM_Updated && > > (flags & TUPLE_LOCK_FLAG_FIND_LAST_VERSION)) > > { > > - /* Should not encounter speculative tuple on recheck */ > > - Assert(!HeapTupleHeaderIsSpeculative(tuple->t_data)); > > + if (!updated) > > + { > > + /* Should not encounter speculative tuple on recheck */ > > + Assert(!HeapTupleHeaderIsSpeculative(tuple->t_data)); > > Hm, why is it ok to encounter speculative tuples in the updated case? Oh, I > guess you got failures because slot doesn't point anywhere at this point. Yes, given that tuple is not accessible, this assert can't work. I've a couple ideas on how to replace it. 1) As I get the primary point of of this assertion is to be sure that tmfd->ctid really points us to a correct tuple (while speculative token doesn't do). So, for the 'updated' case we can check tmfd->ctid directly (or even for both cases?). However, I can't find the relevant macro for this, probably 2) We can check that we don't return TM_Updated from heap_update() and heap_delete(), when old tuple is speculative token. > > - ReleaseBuffer(buffer); > > + ReleaseBuffer(buffer); > > + } > > + else > > + { > > + updated = false; > > + } > > > > if (!ItemPointerEquals(&tmfd->ctid, &tuple->t_self)) > > { > > Which means this is completely bogus now? > > HeapTuple tuple = &bslot->base.tupdata; > > In the first iteration this just points to the newly created slot. Which > doesn't have a tuple stored in it. So the above checks some uninitialized > memory. No, this is not so. tuple->t_self is unconditionally assigned few lines before. So, it can't be uninitialized memory given that *tid is initialized. I seriously doubt this patch could pass the tests if that comparison would use uninitialized memory. > Giving up at this point. > > > This doesn't seem ready to have been committed. Yep, that could be better. Given, that item pointer comparison doesn't really use uninitialized memory, probably not as bad as you thought at the first glance. I'm going to post a patch to address the issues you've raised in next 24h. ------ Regards, Alexander Korotkov
Hi,
On 2023-03-23 18:08:36 +0300, Alexander Korotkov wrote:
> On Thu, Mar 23, 2023 at 3:30 AM Andres Freund <andres@anarazel.de> wrote:
> > On 2023-03-21 01:25:11 +0300, Alexander Korotkov wrote:
> > > I'm going to push patchset v15 if no objections.
> >
> > Just saw that this went in - didn't catch up with the thread before,
> > unfortunately. At the very least I'd like to see some more work on cleaning up
> > the lazy tuple slot stuff. It's replete with unnecessary multiple-evaluation
> > hazards - I realize that there's some of those already, but I don't think we
> > should go further down that route. As far as I can tell there's no need for
> > any of this to be macros.
>
> Thank you for taking a look at this, even post-commit. Regarding
> marcos, do you think inline functions would be good instead?
Yes.
> > I think it's entirely sensible to avoid the tuple fetching in ExecDelete(),
> > but it needs a bit less localized work. Instead of using the presence of a
> > tuple in the returning slot, ExecDelete() should track whether it already has
> > fetched the deleted tuple.
> >
> > Or alternatively, do the work to avoid refetching the tuple for the much more
> > common case of not needing EPQ at all.
> >
> > I guess this really is part of my issue with this change - it optimizes the
> > rare case, while not addressing the same inefficiency in the common case.
>
> I'm going to fix this for ExecDelete(). Avoiding refetching the tuple
> in more common case is something I'm definitely very interested in.
> But I would leave it for the future.
It doesn't seem like a good plan to start with the rare and then address the
common case. The solution for the common case might solve the rare case as
well. One way to make to fix the common case would be to return a tuple
suitable for returning computation as part of the input plan - which would
also fix the EPQ case, since we could just use the EPQ output. Of course there
are complications like triggers, but they seem like they could be dealt with.
> > > @@ -299,14 +305,46 @@ heapam_tuple_complete_speculative(Relation relation, TupleTableSlot *slot,
> > > static TM_Result
> > > heapam_tuple_delete(Relation relation, ItemPointer tid, CommandId cid,
> > > Snapshot snapshot, Snapshot crosscheck, bool wait,
> > > - TM_FailureData *tmfd, bool changingPart)
> > > + TM_FailureData *tmfd, bool changingPart,
> > > + LazyTupleTableSlot *lockedSlot)
> > > {
> > > + TM_Result result;
> > > +
> > > /*
> > > * Currently Deleting of index tuples are handled at vacuum, in case if
> > > * the storage itself is cleaning the dead tuples by itself, it is the
> > > * time to call the index tuple deletion also.
> > > */
> > > - return heap_delete(relation, tid, cid, crosscheck, wait, tmfd, changingPart);
> > > + result = heap_delete(relation, tid, cid, crosscheck, wait,
> > > + tmfd, changingPart);
> > > +
> > > + /*
> > > + * If the tuple has been concurrently updated, then get the lock on it.
> > > + * (Do this if caller asked for tat by providing a 'lockedSlot'.) With the
> > > + * lock held retry of delete should succeed even if there are more
> > > + * concurrent update attempts.
> > > + */
> > > + if (result == TM_Updated && lockedSlot)
> > > + {
> > > + TupleTableSlot *evalSlot;
> > > +
> > > + Assert(wait);
> > > +
> > > + evalSlot = LAZY_TTS_EVAL(lockedSlot);
> > > + result = heapam_tuple_lock_internal(relation, tid, snapshot,
> > > + evalSlot, cid,
LockTupleExclusive,
> > > + LockWaitBlock,
> > > +
TUPLE_LOCK_FLAG_FIND_LAST_VERSION,
> > > + tmfd, true);
> >
> > Oh, huh? As I mentioned before, the unconditional use of LockWaitBlock means
> > the wait parameter is ignored.
> >
> > I'm frankly getting annoyed here.
>
> lockedSlot shoudln't be provided when wait == false. The assertion
> above expresses this intention. However, the code lacking of comment
> directly expressing this idea.
I don't think a comment here is going to fix things. You can't expect somebody
trying to use tableam to look into the guts of a heapam function to understand
the API constraints to this degree. And there's afaict no comments in tableam
that indicate any of this.
I also just don't see why this is a sensible constraint? Why should this only
work if wait == false?
> > > +/*
> > > + * This routine does the work for heapam_tuple_lock(), but also support
> > > + * `updated` argument to re-use the work done by heapam_tuple_update() or
> > > + * heapam_tuple_delete() on figuring out that tuple was concurrently updated.
> > > + */
> > > +static TM_Result
> > > +heapam_tuple_lock_internal(Relation relation, ItemPointer tid,
> > > + Snapshot snapshot, TupleTableSlot *slot,
> > > + CommandId cid, LockTupleMode mode,
> > > + LockWaitPolicy wait_policy, uint8 flags,
> > > + TM_FailureData *tmfd, bool updated)
> >
> > Why is the new parameter named 'updated'?
>
> To indicate that we know that we're locking the updated tuple.
> Probably not descriptive enough.
Given it's used for deletions, I'd say so.
> > > - ReleaseBuffer(buffer);
> > > + ReleaseBuffer(buffer);
> > > + }
> > > + else
> > > + {
> > > + updated = false;
> > > + }
> > >
> > > if (!ItemPointerEquals(&tmfd->ctid, &tuple->t_self))
> > > {
> >
> > Which means this is completely bogus now?
> >
> > HeapTuple tuple = &bslot->base.tupdata;
> >
> > In the first iteration this just points to the newly created slot. Which
> > doesn't have a tuple stored in it. So the above checks some uninitialized
> > memory.
>
> No, this is not so. tuple->t_self is unconditionally assigned few
> lines before. So, it can't be uninitialized memory given that *tid is
> initialized.
Ugh. This means you're basically leaving uninitialized / not initialized state
in the other portions of the tuple/slot, without even documenting that. The
code was ugly starting out, but this certainly makes it worse.
There's also no comment explaining that tmfd suddenly is load-bearing *input*
into heapam_tuple_lock_internal(), whereas previously it was purely an output
parameter - and is documented as such:
* Output parameters:
* *slot: contains the target tuple
* *tmfd: filled in failure cases (see below)
This is an *awful* API.
> I seriously doubt this patch could pass the tests if that comparison
> would use uninitialized memory.
IDK about that - it's hard to exercise this code in the regression tests, and
plenty things are zero initialized, which often makes things appear to work in
the first iteration.
> > Giving up at this point.
> >
> >
> > This doesn't seem ready to have been committed.
>
> Yep, that could be better. Given, that item pointer comparison
> doesn't really use uninitialized memory, probably not as bad as you
> thought at the first glance.
The details of how it's bad maybe differ slightly, but looking at it a bit
longer I also found new things. So I don't really think it's better than what
I though it was.
Greetings,
Andres Freund
Hi, An off-list conversation veered on-topic again. Reposting for posterity: On 2023-03-23 23:24:19 +0300, Alexander Korotkov wrote: > On Thu, Mar 23, 2023 at 8:06 PM Andres Freund <andres@anarazel.de> wrote: > > I seriously doubt that solving this at the tuple locking level is the right > > thing. If we want to avoid refetching tuples, why don't we add a parameter to > > delete/update to generally put the old tuple version into a slot, not just as > > an optimization for a subsequent lock_tuple()? Then we could remove all > > refetching tuples for triggers. It'd also provide the basis for adding support > > for referencing the OLD version in RETURNING, which'd be quite powerful. > > I spent some time thinking on this. Does our attempt to update/delete > tuple imply that we've already fetched the old tuple version? Yes, but somewhat "far away", below the ExecProcNode() in ExecModifyTable(). I don't think we can rely on that. The old tuple is just identified via a junk attribute (c.f. "For UPDATE/DELETE/MERGE, fetch the row identity info for the tuple..."). The NEW tuple is computed in the target list of the source query. It's possible that for some simpler cases we could figure out that the returned slot is the "old" tuple, but it'd be hard to make that work. Alternatively we could evaluate returning as part of the source query plan. While that'd work nicely for the EPQ cases (the EPQ evaluation would compute the new values), it could not be relied upon for before triggers. It might or might not be a win to try to do so - if you have a selective query, ferrying around the entire source tuple might cost more than it saves. > We needed that at least to do initial qual check and calculation of the new > tuple (for update case). The NEW tuple is computed in the source query, as I mentioned, I don't think we easily can get access to the source row in the general case. > We currently may not have the old tuple at hand at the time we do > table_tuple_update()/table_tuple_delete(). But that seems to be just and > issue of our executor code. Do it worth to make table AM fetch the old > *unmodified* tuple given that we've already fetched it for sure? Not unconditionally (e.g. if you neither have triggers, nor RETURNING, there's not much point, unless the query is simple enough that we could make it free). But in the other cases it seems beneficial. The caller would reliably know whether they want the source tuple to be fetched, or not. We could make it so that iff we already have the "old" tuple in the slot, it'll not be put in there "again", but if it's not the right row version, it is. We could use the same approach to make the "happy path" in update/delete cheaper. If the source tuple is provided, heap_delete(), heap_update() won't need to do a ReadBuffer(), they could just IncrBufferRefCount(). That'd be a quite substantial win. Greetings, Andres Freund
Hi! On Fri, Mar 24, 2023 at 3:39 AM Andres Freund <andres@anarazel.de> wrote: > On 2023-03-23 23:24:19 +0300, Alexander Korotkov wrote: > > On Thu, Mar 23, 2023 at 8:06 PM Andres Freund <andres@anarazel.de> wrote: > > > I seriously doubt that solving this at the tuple locking level is the right > > > thing. If we want to avoid refetching tuples, why don't we add a parameter to > > > delete/update to generally put the old tuple version into a slot, not just as > > > an optimization for a subsequent lock_tuple()? Then we could remove all > > > refetching tuples for triggers. It'd also provide the basis for adding support > > > for referencing the OLD version in RETURNING, which'd be quite powerful. After some thoughts, I think I like idea of fetching old tuple version in update/delete. Everything that evades extra tuple fetching and do more of related work in a single table AM call, makes table AM API more flexible. I'm working on patch implementing this. I'm going to post it later today. ------ Regards, Alexander Korotkov
Andres, On Mon, Mar 27, 2023 at 1:49 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: > On Fri, Mar 24, 2023 at 3:39 AM Andres Freund <andres@anarazel.de> wrote: > > On 2023-03-23 23:24:19 +0300, Alexander Korotkov wrote: > > > On Thu, Mar 23, 2023 at 8:06 PM Andres Freund <andres@anarazel.de> wrote: > > > > I seriously doubt that solving this at the tuple locking level is the right > > > > thing. If we want to avoid refetching tuples, why don't we add a parameter to > > > > delete/update to generally put the old tuple version into a slot, not just as > > > > an optimization for a subsequent lock_tuple()? Then we could remove all > > > > refetching tuples for triggers. It'd also provide the basis for adding support > > > > for referencing the OLD version in RETURNING, which'd be quite powerful. > > After some thoughts, I think I like idea of fetching old tuple version > in update/delete. Everything that evades extra tuple fetching and do > more of related work in a single table AM call, makes table AM API > more flexible. > > I'm working on patch implementing this. I'm going to post it later today. Here is the patchset. I'm continue to work on comments and refactoring. My quick question is why do we need ri_TrigOldSlot for triggers? Can't we just pass the old tuple for after row trigger in ri_oldTupleSlot? Also, I wonder if we really need a LazyTupleSlot. It allows to evade extra tuple slot allocation. But as I get in the end the tuple slot allocation is just a single palloc. I bet the effect would be invisible in the benchmarks. ------ Regards, Alexander Korotkov
Вложения
On Wed, Mar 29, 2023 at 8:34 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: > On Mon, Mar 27, 2023 at 1:49 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: > > On Fri, Mar 24, 2023 at 3:39 AM Andres Freund <andres@anarazel.de> wrote: > > > On 2023-03-23 23:24:19 +0300, Alexander Korotkov wrote: > > > > On Thu, Mar 23, 2023 at 8:06 PM Andres Freund <andres@anarazel.de> wrote: > > > > > I seriously doubt that solving this at the tuple locking level is the right > > > > > thing. If we want to avoid refetching tuples, why don't we add a parameter to > > > > > delete/update to generally put the old tuple version into a slot, not just as > > > > > an optimization for a subsequent lock_tuple()? Then we could remove all > > > > > refetching tuples for triggers. It'd also provide the basis for adding support > > > > > for referencing the OLD version in RETURNING, which'd be quite powerful. > > > > After some thoughts, I think I like idea of fetching old tuple version > > in update/delete. Everything that evades extra tuple fetching and do > > more of related work in a single table AM call, makes table AM API > > more flexible. > > > > I'm working on patch implementing this. I'm going to post it later today. > > Here is the patchset. I'm continue to work on comments and refactoring. > > My quick question is why do we need ri_TrigOldSlot for triggers? > Can't we just pass the old tuple for after row trigger in > ri_oldTupleSlot? > > Also, I wonder if we really need a LazyTupleSlot. It allows to evade > extra tuple slot allocation. But as I get in the end the tuple slot > allocation is just a single palloc. I bet the effect would be > invisible in the benchmarks. Sorry, previous patches don't even compile. The fixed version is attached. I'm going to post significantly revised patchset soon. ------ Regards, Alexander Korotkov
Вложения
Hi, On 2023-03-31 16:57:41 +0300, Alexander Korotkov wrote: > On Wed, Mar 29, 2023 at 8:34 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: > > On Mon, Mar 27, 2023 at 1:49 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: > > > On Fri, Mar 24, 2023 at 3:39 AM Andres Freund <andres@anarazel.de> wrote: > > > > On 2023-03-23 23:24:19 +0300, Alexander Korotkov wrote: > > > > > On Thu, Mar 23, 2023 at 8:06 PM Andres Freund <andres@anarazel.de> wrote: > > > > > > I seriously doubt that solving this at the tuple locking level is the right > > > > > > thing. If we want to avoid refetching tuples, why don't we add a parameter to > > > > > > delete/update to generally put the old tuple version into a slot, not just as > > > > > > an optimization for a subsequent lock_tuple()? Then we could remove all > > > > > > refetching tuples for triggers. It'd also provide the basis for adding support > > > > > > for referencing the OLD version in RETURNING, which'd be quite powerful. > > > > > > After some thoughts, I think I like idea of fetching old tuple version > > > in update/delete. Everything that evades extra tuple fetching and do > > > more of related work in a single table AM call, makes table AM API > > > more flexible. > > > > > > I'm working on patch implementing this. I'm going to post it later today. > > > > Here is the patchset. I'm continue to work on comments and refactoring. > > > > My quick question is why do we need ri_TrigOldSlot for triggers? > > Can't we just pass the old tuple for after row trigger in > > ri_oldTupleSlot? > > > > Also, I wonder if we really need a LazyTupleSlot. It allows to evade > > extra tuple slot allocation. But as I get in the end the tuple slot > > allocation is just a single palloc. I bet the effect would be > > invisible in the benchmarks. > > Sorry, previous patches don't even compile. The fixed version is attached. > I'm going to post significantly revised patchset soon. Given that the in-tree state has been broken for a week, I think it probably is time to revert the commits that already went in. Greetings, Andres Freund
Hi, Andres!
On Sat, 1 Apr 2023, 09:21 Andres Freund, <andres@anarazel.de> wrote:
Given that the in-tree state has been broken for a week, I think it probably
is time to revert the commits that already went in.
It seems that although the patch addressing the issues is not a quick fix, there is a big progress in it already. I propose to see it's status a week later and if it is not ready then to revert existing. Hope there are no other patches in the existing branch complained to suffer this.
Kind regards,
Pavel Borisov,
Supabase
.Hi! On Sat, Apr 1, 2023 at 8:21 AM Andres Freund <andres@anarazel.de> wrote: > On 2023-03-31 16:57:41 +0300, Alexander Korotkov wrote: > > On Wed, Mar 29, 2023 at 8:34 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: > > > On Mon, Mar 27, 2023 at 1:49 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: > > > > On Fri, Mar 24, 2023 at 3:39 AM Andres Freund <andres@anarazel.de> wrote: > > > > > On 2023-03-23 23:24:19 +0300, Alexander Korotkov wrote: > > > > > > On Thu, Mar 23, 2023 at 8:06 PM Andres Freund <andres@anarazel.de> wrote: > > > > > > > I seriously doubt that solving this at the tuple locking level is the right > > > > > > > thing. If we want to avoid refetching tuples, why don't we add a parameter to > > > > > > > delete/update to generally put the old tuple version into a slot, not just as > > > > > > > an optimization for a subsequent lock_tuple()? Then we could remove all > > > > > > > refetching tuples for triggers. It'd also provide the basis for adding support > > > > > > > for referencing the OLD version in RETURNING, which'd be quite powerful. > > > > > > > > After some thoughts, I think I like idea of fetching old tuple version > > > > in update/delete. Everything that evades extra tuple fetching and do > > > > more of related work in a single table AM call, makes table AM API > > > > more flexible. > > > > > > > > I'm working on patch implementing this. I'm going to post it later today. > > > > > > Here is the patchset. I'm continue to work on comments and refactoring. > > > > > > My quick question is why do we need ri_TrigOldSlot for triggers? > > > Can't we just pass the old tuple for after row trigger in > > > ri_oldTupleSlot? > > > > > > Also, I wonder if we really need a LazyTupleSlot. It allows to evade > > > extra tuple slot allocation. But as I get in the end the tuple slot > > > allocation is just a single palloc. I bet the effect would be > > > invisible in the benchmarks. > > > > Sorry, previous patches don't even compile. The fixed version is attached. > > I'm going to post significantly revised patchset soon. > > Given that the in-tree state has been broken for a week, I think it probably > is time to revert the commits that already went in. The revised patch is attached. The most notable change is getting rid of LazyTupleTableSlot. Also get rid of complex computations to detect how to initialize LazyTupleTableSlot. Instead just pass the oldSlot as an argument of ExecUpdate() and ExecDelete(). The price for this is just preallocation of ri_oldTupleSlot before calling ExecDelete(). The slot allocation is quite cheap. After all wrappers it's table_slot_callbacks(), which is very cheap, single palloc() and few fields initialization. It doesn't seem reasonable to introduce an infrastructure to evade this. I think patch resolves all the major issues you've highlighted. Even if there are some minor things missed, I'd prefer to push this rather than reverting the whole work. ------ Regards, Alexander Korotkov
Вложения
Hi, On 2023-04-02 03:37:19 +0300, Alexander Korotkov wrote: > On Sat, Apr 1, 2023 at 8:21 AM Andres Freund <andres@anarazel.de> wrote: > > Given that the in-tree state has been broken for a week, I think it probably > > is time to revert the commits that already went in. > > The revised patch is attached. The most notable change is getting rid > of LazyTupleTableSlot. Also get rid of complex computations to detect > how to initialize LazyTupleTableSlot. Instead just pass the oldSlot > as an argument of ExecUpdate() and ExecDelete(). The price for this > is just preallocation of ri_oldTupleSlot before calling ExecDelete(). > The slot allocation is quite cheap. After all wrappers it's > table_slot_callbacks(), which is very cheap, single palloc() and few > fields initialization. It doesn't seem reasonable to introduce an > infrastructure to evade this. > > I think patch resolves all the major issues you've highlighted. Even > if there are some minor things missed, I'd prefer to push this rather > than reverting the whole work. Shrug. You're designing new APIs, days before the feature freeze. This just doesn't seem ready in time for 16. I certainly won't have time to look at it sufficiently in the next 5 days. Greetings, Andres Freund
On Sun, Apr 2, 2023 at 3:47 AM Andres Freund <andres@anarazel.de> wrote: > On 2023-04-02 03:37:19 +0300, Alexander Korotkov wrote: > > On Sat, Apr 1, 2023 at 8:21 AM Andres Freund <andres@anarazel.de> wrote: > > > Given that the in-tree state has been broken for a week, I think it probably > > > is time to revert the commits that already went in. > > > > The revised patch is attached. The most notable change is getting rid > > of LazyTupleTableSlot. Also get rid of complex computations to detect > > how to initialize LazyTupleTableSlot. Instead just pass the oldSlot > > as an argument of ExecUpdate() and ExecDelete(). The price for this > > is just preallocation of ri_oldTupleSlot before calling ExecDelete(). > > The slot allocation is quite cheap. After all wrappers it's > > table_slot_callbacks(), which is very cheap, single palloc() and few > > fields initialization. It doesn't seem reasonable to introduce an > > infrastructure to evade this. > > > > I think patch resolves all the major issues you've highlighted. Even > > if there are some minor things missed, I'd prefer to push this rather > > than reverting the whole work. > > Shrug. You're designing new APIs, days before the feature freeze. This just > doesn't seem ready in time for 16. I certainly won't have time to look at it > sufficiently in the next 5 days. OK. Reverted. ------ Regards, Alexander Korotkov
Hi, Alexander! On 2023-04-02 03:37:19 +0300, Alexander Korotkov wrote: > On Sat, Apr 1, 2023 at 8:21 AM Andres Freund <andres@anarazel.de> wrote: > > Given that the in-tree state has been broken for a week, I think it probably > > is time to revert the commits that already went in. > > The revised patch is attached. The most notable change is getting rid > of LazyTupleTableSlot. Also get rid of complex computations to detect > how to initialize LazyTupleTableSlot. Instead just pass the oldSlot > as an argument of ExecUpdate() and ExecDelete(). The price for this > is just preallocation of ri_oldTupleSlot before calling ExecDelete(). > The slot allocation is quite cheap. After all wrappers it's > table_slot_callbacks(), which is very cheap, single palloc() and few > fields initialization. It doesn't seem reasonable to introduce an > infrastructure to evade this. > > I think patch resolves all the major issues you've highlighted. Even > if there are some minor things missed, I'd prefer to push this rather > than reverting the whole work. I looked into the latest patch v3. In my view, it addresses all the issues discussed in [1]. Also, with the pushing oldslot logic outside code becomes more transparent. I've added some very minor modifications to the code and comments in patch v4-0001. Also, I'm for committing Andres' isolation test. I've added some minor revisions to make the test run routinely among the other isolation tests. The test could also be made a part of the existing eval-plan-qual.spec, but I have left it separate yet. Also, I think that signatures of ExecUpdate() and ExecDelete() functions, especially the last one are somewhat overloaded with different status bool variables added by different authors on different occasions. If they are combined into some kind of status variable, it would be nice. But as this doesn't touch API, is not related to the current update/delete optimization, it could be modified anytime in the future as well. The changes that indeed touch API are adding TupleTableSlot and conversion of bool wait flag into now four-state options variable for tuple_update(), tuple_delete(), heap_update(), heap_delete() and heap_lock_tuple() and a couple of Exec*DeleteTriggers(). I think they are justified. One thing that is not clear to me is that we pass oldSlot into simple_table_tuple_update() whereas as per the comment on this function "concurrent updates of the target tuple is not expected (for example, because we have a lock on the relation associated with the tuple)". It seems not to break anything but maybe this could be simplified. Overall I think the patch is good enough. Regards, Pavel Borisov, Supabase. [1] https://www.postgresql.org/message-id/CAPpHfdtwKb5UVXKkDQZYW8nQCODy0fY_S7mV5Z%2Bcg7urL%3DzDEA%40mail.gmail.com
Вложения
Upon Alexander reverting patches v15 from master, I've rebased what was correction patches v4 in a message above on a fresh master (together with patches v15). The resulting patch v16 is attached. Pavel.
Вложения
On Mon, Apr 3, 2023 at 5:12 PM Pavel Borisov <pashkin.elfe@gmail.com> wrote: > Upon Alexander reverting patches v15 from master, I've rebased what > was correction patches v4 in a message above on a fresh master > (together with patches v15). The resulting patch v16 is attached. Pavel, thank you for you review, revisions and rebase. We'll reconsider this once v17 is branched. ------ Regards, Alexander Korotkov
On Tue, Apr 04, 2023 at 01:25:46AM +0300, Alexander Korotkov wrote: > Pavel, thank you for you review, revisions and rebase. > We'll reconsider this once v17 is branched. The patch was still in the current CF, so I have moved it to the next one based on the latest updates. -- Michael
Вложения
Hi, hackers! > You're designing new APIs, days before the feature freeze. On Wed, 5 Apr 2023 at 06:54, Michael Paquier <michael@paquier.xyz> wrote: > > On Tue, Apr 04, 2023 at 01:25:46AM +0300, Alexander Korotkov wrote: > > Pavel, thank you for you review, revisions and rebase. > > We'll reconsider this once v17 is branched. I've looked through patches v16 once more and think they're good enough, and previous issues are all addressed. I see that there is nothing that blocks it from being committed except the last iteration was days before v16 feature freeze. Recently in another thread [1] Alexander posted a new version of patches v16 (as 0001 and 0002) In 0001 only indenation, comments, and commit messages changed from v16 in this thread. In 0002 new test eval-plan-qual-2 was integrated into the existing eval-plan-qual test. For maintaining the most recent versions in this thread I'm attaching them under v17. I suppose that we can commit these patches to v17 if there are no objections or additional reviews. [1] https://www.postgresql.org/message-id/flat/CAPpHfdurb9ycV8udYqM%3Do0sPS66PJ4RCBM1g-bBpvzUfogY0EA%40mail.gmail.com Kind regards, Pavel Borisov
Вложения
Hi, Pavel! On Tue, Nov 28, 2023 at 11:00 AM Pavel Borisov <pashkin.elfe@gmail.com> wrote: > > You're designing new APIs, days before the feature freeze. > On Wed, 5 Apr 2023 at 06:54, Michael Paquier <michael@paquier.xyz> wrote: > > > > On Tue, Apr 04, 2023 at 01:25:46AM +0300, Alexander Korotkov wrote: > > > Pavel, thank you for you review, revisions and rebase. > > > We'll reconsider this once v17 is branched. > > I've looked through patches v16 once more and think they're good > enough, and previous issues are all addressed. I see that there is > nothing that blocks it from being committed except the last iteration > was days before v16 feature freeze. > > Recently in another thread [1] Alexander posted a new version of > patches v16 (as 0001 and 0002) In 0001 only indenation, comments, and > commit messages changed from v16 in this thread. In 0002 new test > eval-plan-qual-2 was integrated into the existing eval-plan-qual test. > For maintaining the most recent versions in this thread I'm attaching > them under v17. I suppose that we can commit these patches to v17 if > there are no objections or additional reviews. > > [1] https://www.postgresql.org/message-id/flat/CAPpHfdurb9ycV8udYqM%3Do0sPS66PJ4RCBM1g-bBpvzUfogY0EA%40mail.gmail.com The new revision of patches is attached. It has updated commit messages, new comments, and some variables were renamed to be more consistent with surroundings. I also think that all the design issues spoken before are resolved. It would be nice to hear from Andres about this. I'll continue rechecking these patches myself. ------ Regards, Alexander Korotkov
Вложения
On Tue, Mar 19, 2024 at 5:20 PM Alexander Korotkov <aekorotkov@gmail.com> wrote: > On Tue, Nov 28, 2023 at 11:00 AM Pavel Borisov <pashkin.elfe@gmail.com> wrote: > > > You're designing new APIs, days before the feature freeze. > > On Wed, 5 Apr 2023 at 06:54, Michael Paquier <michael@paquier.xyz> wrote: > > > > > > On Tue, Apr 04, 2023 at 01:25:46AM +0300, Alexander Korotkov wrote: > > > > Pavel, thank you for you review, revisions and rebase. > > > > We'll reconsider this once v17 is branched. > > > > I've looked through patches v16 once more and think they're good > > enough, and previous issues are all addressed. I see that there is > > nothing that blocks it from being committed except the last iteration > > was days before v16 feature freeze. > > > > Recently in another thread [1] Alexander posted a new version of > > patches v16 (as 0001 and 0002) In 0001 only indenation, comments, and > > commit messages changed from v16 in this thread. In 0002 new test > > eval-plan-qual-2 was integrated into the existing eval-plan-qual test. > > For maintaining the most recent versions in this thread I'm attaching > > them under v17. I suppose that we can commit these patches to v17 if > > there are no objections or additional reviews. > > > > [1] https://www.postgresql.org/message-id/flat/CAPpHfdurb9ycV8udYqM%3Do0sPS66PJ4RCBM1g-bBpvzUfogY0EA%40mail.gmail.com > > The new revision of patches is attached. > > It has updated commit messages, new comments, and some variables were > renamed to be more consistent with surroundings. > > I also think that all the design issues spoken before are resolved. > It would be nice to hear from Andres about this. > > I'll continue rechecking these patches myself. I've re-read this thread. It still seems to me that the issues raised before are addressed now. Fingers crossed, I'm going to push this if there are no objections. ------ Regards, Alexander Korotkov