Обсуждение: remaining sql/json patches
Hello.
I'm starting a new thread for $subject per Alvaro's suggestion at [1].
So the following sql/json things still remain to be done:
* sql/json query functions:
json_exists()
json_query()
json_value()
* other sql/json functions:
json()
json_scalar()
json_serialize()
* finally:
json_table
Attached is the rebased patch for the 1st part.
It also addresses Alvaro's review comments on Apr 4, though see my
comments below.
On Tue, Apr 4, 2023 at 9:36 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote:
> On 2023-Apr-04, Amit Langote wrote:
> > On Tue, Apr 4, 2023 at 2:16 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote:
> > > - the gram.y solution to the "ON ERROR/ON EMPTY" clauses is quite ugly.
> > > I think we could make that stuff use something similar to
> > > ConstraintAttributeSpec with an accompanying post-processing function.
> > > That would reduce the number of ad-hoc hacks, which seem excessive.
>>
> > Do you mean the solution involving the JsonBehavior node?
>
> Right. It has spilled as the separate on_behavior struct in the core
> parser %union in addition to the raw jsbehavior, which is something
> we've gone 30 years without having, and I don't see why we should start
> now.
I looked into trying to make this look like ConstraintAttributeSpec
but came to the conclusion that that's not quite doable in this case.
A "behavior" cannot be represented simply as an integer flag, because
there's `DEFAULT a_expr` to fit in, so it's got to be this
JsonBehavior node. However...
> This stuff is terrible:
>
> json_exists_error_clause_opt:
> json_exists_error_behavior ON ERROR_P { $$ = $1; }
> | /* EMPTY */ { $$ = NULL; }
> ;
>
> json_exists_error_behavior:
> ERROR_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_ERROR, NULL); }
> | TRUE_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_TRUE, NULL); }
> | FALSE_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_FALSE, NULL); }
> | UNKNOWN { $$ = makeJsonBehavior(JSON_BEHAVIOR_UNKNOWN, NULL); }
> ;
>
> json_value_behavior:
> NULL_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_NULL, NULL); }
> | ERROR_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_ERROR, NULL); }
> | DEFAULT a_expr { $$ = makeJsonBehavior(JSON_BEHAVIOR_DEFAULT, $2); }
> ;
>
> json_value_on_behavior_clause_opt:
> json_value_behavior ON EMPTY_P
> { $$.on_empty = $1; $$.on_error = NULL; }
> | json_value_behavior ON EMPTY_P json_value_behavior ON ERROR_P
> { $$.on_empty = $1; $$.on_error = $4; }
> | json_value_behavior ON ERROR_P
> { $$.on_empty = NULL; $$.on_error = $1; }
> | /* EMPTY */
> { $$.on_empty = NULL; $$.on_error = NULL; }
> ;
>
> json_query_behavior:
> ERROR_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_ERROR, NULL); }
> | NULL_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_NULL, NULL); }
> | EMPTY_P ARRAY { $$ = makeJsonBehavior(JSON_BEHAVIOR_EMPTY_ARRAY, NULL); }
> /* non-standard, for Oracle compatibility only */
> | EMPTY_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_EMPTY_ARRAY, NULL); }
> | EMPTY_P OBJECT_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_EMPTY_OBJECT, NULL); }
> | DEFAULT a_expr { $$ = makeJsonBehavior(JSON_BEHAVIOR_DEFAULT, $2); }
> ;
>
> json_query_on_behavior_clause_opt:
> json_query_behavior ON EMPTY_P
> { $$.on_empty = $1; $$.on_error = NULL; }
> | json_query_behavior ON EMPTY_P json_query_behavior ON ERROR_P
> { $$.on_empty = $1; $$.on_error = $4; }
> | json_query_behavior ON ERROR_P
> { $$.on_empty = NULL; $$.on_error = $1; }
> | /* EMPTY */
> { $$.on_empty = NULL; $$.on_error = NULL; }
> ;
>
> Surely this can be made cleaner.
...I've managed to reduce the above down to:
MergeWhenClause *mergewhen;
struct KeyActions *keyactions;
struct KeyAction *keyaction;
+ JsonBehavior *jsbehavior;
...
+%type <jsbehavior> json_value_behavior
+ json_query_behavior
+ json_exists_behavior
...
+json_query_behavior:
+ ERROR_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_ERROR, NULL); }
+ | NULL_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_NULL, NULL); }
+ | DEFAULT a_expr { $$ =
makeJsonBehavior(JSON_BEHAVIOR_DEFAULT, $2); }
+ | EMPTY_P ARRAY { $$ =
makeJsonBehavior(JSON_BEHAVIOR_EMPTY_ARRAY, NULL); }
+ | EMPTY_P OBJECT_P { $$ =
makeJsonBehavior(JSON_BEHAVIOR_EMPTY_OBJECT, NULL); }
+ /* non-standard, for Oracle compatibility only */
+ | EMPTY_P { $$ =
makeJsonBehavior(JSON_BEHAVIOR_EMPTY_ARRAY, NULL); }
+ ;
+
+json_exists_behavior:
+ ERROR_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_ERROR, NULL); }
+ | TRUE_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_TRUE, NULL); }
+ | FALSE_P { $$ =
makeJsonBehavior(JSON_BEHAVIOR_FALSE, NULL); }
+ | UNKNOWN { $$ =
makeJsonBehavior(JSON_BEHAVIOR_UNKNOWN, NULL); }
+ ;
+
+json_value_behavior:
+ NULL_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_NULL, NULL); }
+ | ERROR_P { $$ =
makeJsonBehavior(JSON_BEHAVIOR_ERROR, NULL); }
+ | DEFAULT a_expr { $$ =
makeJsonBehavior(JSON_BEHAVIOR_DEFAULT, $2); }
+ ;
Though, that does mean that there are now more rules for
func_expr_common_subexpr to implement the variations of ON ERROR, ON
EMPTY clauses for each of JSON_EXISTS, JSON_QUERY, and JSON_VALUE.
> By the way -- that comment about clauses being non-standard, can you
> spot exactly *which* clauses that comment applies to?
I've moved comment as shown above to make clear that a bare EMPTY_P is
needed for Oracle compatibility
On Tue, Apr 4, 2023 at 2:16 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote:
> - the changes in formatting.h have no explanation whatsoever. At the
> very least, the new function should have a comment in the .c file.
> (And why is it at end of file? I bet there's a better location)
Apparently, the newly exported routine is needed in the JSON-specific
subroutine for the planner's contain_mutable_functions_walker(), to
check if a JsonExpr's path_spec contains any timezone-dependent
constant. In the attached, I've changed the newly exported function's
name as follows:
datetime_format_flags -> datetime_format_has_tz
which let me do away with exporting those DCH_* constants in formatting.h.
> - some nasty hacks are being used in the ECPG grammar with no tests at
> all. It's easy to add a few lines to the .pgc file I added in prior
> commits.
Ah, those ecpg.trailer changes weren't in the original commit that
added added SQL/JSON query functions (1a36bc9dba8ea), but came in
5f0adec2537d, 83f1c7b742e8 to fix some damage caused by the former's
making STRING a keyword. If I don't include the ecpg.trailer bit,
test_informix.pgc fails, so I think the change is already covered.
> - Some functions in jsonfuncs.c have changed from throwing hard errors
> into soft ones. I think this deserves more commentary.
I've merged the delta patch I had posted earlier addressing this [2]
into the attached.
> - func.sgml: The new functions are documented in a separate table for no
> reason that I can see. Needs to be merged into one of the existing
> tables. I didn't actually review the docs.
Hmm, so we already have "SQL/JSON Testing Functions" that were
committed into v16 in a separate table (Table 9.48) under "9.16.1.
Processing and Creating JSON Data". So, I don't see a problem with
adding "SQL/JSON Query Functions" in a separate table, though maybe it
should not be under the same sub-section. Maybe under "9.16.2. The
SQL/JSON Path Language" is more appropriate?
I'll rebase and post the patches for "other sql/json functions" and
"json_table" shortly.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
[1] https://www.postgresql.org/message-id/20230503181732.26hx5ihbdkmzhlyw%40alvherre.pgsql
[2] https://www.postgresql.org/message-id/CA%2BHiwqHGghuFpxE%3DpfUFPT%2BZzKvHWSN4BcrWr%3DZRjd4i4qubfQ%40mail.gmail.com
Вложения
On Mon, Jun 19, 2023 at 5:31 PM Amit Langote <amitlangote09@gmail.com> wrote: > So the following sql/json things still remain to be done: > > * sql/json query functions: > json_exists() > json_query() > json_value() > > * other sql/json functions: > json() > json_scalar() > json_serialize() > > * finally: > json_table > > Attached is the rebased patch for the 1st part. ... > I'll rebase and post the patches for "other sql/json functions" and > "json_table" shortly. And here they are. I realized that the patch for the "other sql/json functions" part is relatively straightforward and has no dependence on the "sql/json query functions" part getting done first. So I've made that one the 0001 patch. The patch I posted in the last email is now 0002, though it only has changes related to changing the order of the patch, so I decided not to change the patch version marker (v1). -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
On 21.06.23 10:25, Amit Langote wrote: > I realized that the patch for the "other sql/json functions" part is > relatively straightforward and has no dependence on the "sql/json > query functions" part getting done first. So I've made that one the > 0001 patch. The patch I posted in the last email is now 0002, though > it only has changes related to changing the order of the patch, so I > decided not to change the patch version marker (v1). (I suggest you change the version number anyway, next time. There are plenty of numbers available.) The 0001 patch contains a change to doc/src/sgml/keywords/sql2016-02-reserved.txt, which seems inappropriate. The additional keywords are already listed in the 2023 file, and they are not SQL:2016 keywords. Another thing, I noticed that the SQL/JSON patches in PG16 introduced some nonstandard indentation in gram.y. I would like to apply the attached patch to straighten this out.
Вложения
On Fri, Jul 7, 2023 at 8:31 PM Peter Eisentraut <peter@eisentraut.org> wrote: > On 21.06.23 10:25, Amit Langote wrote: > > I realized that the patch for the "other sql/json functions" part is > > relatively straightforward and has no dependence on the "sql/json > > query functions" part getting done first. So I've made that one the > > 0001 patch. The patch I posted in the last email is now 0002, though > > it only has changes related to changing the order of the patch, so I > > decided not to change the patch version marker (v1). > > (I suggest you change the version number anyway, next time. There are > plenty of numbers available.) Will do. :) > The 0001 patch contains a change to > doc/src/sgml/keywords/sql2016-02-reserved.txt, which seems > inappropriate. The additional keywords are already listed in the 2023 > file, and they are not SQL:2016 keywords. Ah, indeed. Will remove. > Another thing, I noticed that the SQL/JSON patches in PG16 introduced > some nonstandard indentation in gram.y. I would like to apply the > attached patch to straighten this out. Sounds fine to me. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
On Fri, Jul 7, 2023 at 8:59 PM Amit Langote <amitlangote09@gmail.com> wrote: > On Fri, Jul 7, 2023 at 8:31 PM Peter Eisentraut <peter@eisentraut.org> wrote: > > On 21.06.23 10:25, Amit Langote wrote: > > > I realized that the patch for the "other sql/json functions" part is > > > relatively straightforward and has no dependence on the "sql/json > > > query functions" part getting done first. So I've made that one the > > > 0001 patch. The patch I posted in the last email is now 0002, though > > > it only has changes related to changing the order of the patch, so I > > > decided not to change the patch version marker (v1). > > > > (I suggest you change the version number anyway, next time. There are > > plenty of numbers available.) > > Will do. :) Here's v2. 0001 and 0002 are new patches for some improvements of the existing code. In the main patches (0003~), I've mainly removed a few nonterminals in favor of new rules in the remaining nonterminals, especially in the JSON_TABLE patch. I've also removed additions to sql2016-02-reserved.txt as Peter suggested. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
Looking at 0001 now. I noticed that it adds JSON, JSON_SCALAR and JSON_SERIALIZE as reserved keywords to doc/src/sgml/keywords/sql2016-02-reserved.txt; but those keywords do not appear in the 2016 standard as reserved. I see that those keywords appear as reserved in sql2023-02-reserved.txt, so I suppose you're covered as far as that goes; you don't need to patch sql2016, and indeed that's the wrong thing to do. I see that you add json_returning_clause_opt, but we already have json_output_clause_opt. Shouldn't these two be one and the same? I think the new name is more sensible than the old one, since the governing keyword is RETURNING; I suppose naming it "output" comes from the fact that the standard calls this <JSON output clause>. typo "requeted" I'm not in love with the fact that JSON and JSONB have pretty much parallel type categorizing functionality. It seems entirely artificial. Maybe this didn't matter when these were contained inside each .c file and nobody else had to deal with that, but I think it's not good to make this an exported concept. Is it possible to do away with that? I mean, reduce both to a single categorization enum, and a single categorization API. Here you have to cast the enum value to int in order to make ExecInitExprRec work, and that seems a bit lame; moreso when the "is_jsonb" is determined separately (cf. ExecEvalJsonConstructor) In the 2023 standard, JSON_SCALAR is just <JSON scalar> ::= JSON_SCALAR <left paren> <value expression> <right paren> but we seem to have added a <JSON output format> clause to it. Should we really? -- Álvaro Herrera Breisgau, Deutschland — https://www.EnterpriseDB.com/ "Entristecido, Wutra (canción de Las Barreras) echa a Freyr a rodar y a nosotros al mar"
Hi Alvaro,
On Fri, Jul 7, 2023 at 9:28 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote:
> Looking at 0001 now.
Thanks.
> I noticed that it adds JSON, JSON_SCALAR and JSON_SERIALIZE as reserved
> keywords to doc/src/sgml/keywords/sql2016-02-reserved.txt; but those
> keywords do not appear in the 2016 standard as reserved. I see that
> those keywords appear as reserved in sql2023-02-reserved.txt, so I
> suppose you're covered as far as that goes; you don't need to patch
> sql2016, and indeed that's the wrong thing to do.
Yeah, fixed that after Peter pointed it out.
> I see that you add json_returning_clause_opt, but we already have
> json_output_clause_opt. Shouldn't these two be one and the same?
> I think the new name is more sensible than the old one, since the
> governing keyword is RETURNING; I suppose naming it "output" comes from
> the fact that the standard calls this <JSON output clause>.
One difference between the two is that json_output_clause_opt allows
specifying the FORMAT clause in addition to the RETURNING type name,
while json_returning_clause_op only allows specifying the type name.
I'm inclined to keep only json_returning_clause_opt as you suggest and
make parse_expr.c output an error if the FORMAT clause is specified in
JSON() and JSON_SCALAR(), so turning the current syntax error on
specifying RETURNING ... FORMAT for these functions into a parsing
error. Done that way in the attached updated patch and also updated
the latter patch that adds JSON_EXISTS() and JSON_VALUE() to have
similar behavior.
> typo "requeted"
Fixed.
> I'm not in love with the fact that JSON and JSONB have pretty much
> parallel type categorizing functionality. It seems entirely artificial.
> Maybe this didn't matter when these were contained inside each .c file
> and nobody else had to deal with that, but I think it's not good to make
> this an exported concept. Is it possible to do away with that? I mean,
> reduce both to a single categorization enum, and a single categorization
> API. Here you have to cast the enum value to int in order to make
> ExecInitExprRec work, and that seems a bit lame; moreso when the
> "is_jsonb" is determined separately (cf. ExecEvalJsonConstructor)
OK, I agree that a unified categorizing API might be better. I'll
look at making this better. Btw, does src/include/common/jsonapi.h
look like an appropriate place for that?
> In the 2023 standard, JSON_SCALAR is just
>
> <JSON scalar> ::= JSON_SCALAR <left paren> <value expression> <right paren>
>
> but we seem to have added a <JSON output format> clause to it. Should
> we really?
Hmm, I am not seeing <JSON output format> in the rule for JSON_SCALAR,
which looks like this in the current grammar:
func_expr_common_subexpr:
...
| JSON_SCALAR '(' a_expr json_returning_clause_opt ')'
{
JsonScalarExpr *n = makeNode(JsonScalarExpr);
n->expr = (Expr *) $3;
n->output = (JsonOutput *) $4;
n->location = @1;
$$ = (Node *) n;
}
...
json_returning_clause_opt:
RETURNING Typename
{
JsonOutput *n = makeNode(JsonOutput);
n->typeName = $2;
n->returning = makeNode(JsonReturning);
n->returning->format =
makeJsonFormat(JS_FORMAT_DEFAULT, JS_ENC_DEFAULT, @2);
$$ = (Node *) n;
}
| /* EMPTY */ { $$ = NULL; }
;
Per what I wrote above, the grammar for JSON() and JSON_SCALAR() does
not allow specifying the FORMAT clause. Though considering what you
wrote, the RETURNING clause does appear to be an extension to the
standard's spec. I can't find any reasoning in the original
discussion as to how that came about, except an email from Andrew [1]
saying that he added it back to the patch.
Here's v3 in the meantime.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
[1] https://www.postgresql.org/message-id/flat/cd0bb935-0158-78a7-08b5-904886deac4b%40postgrespro.ru
Вложения
On 2023-Jul-10, Amit Langote wrote: > > I see that you add json_returning_clause_opt, but we already have > > json_output_clause_opt. Shouldn't these two be one and the same? > > I think the new name is more sensible than the old one, since the > > governing keyword is RETURNING; I suppose naming it "output" comes from > > the fact that the standard calls this <JSON output clause>. > > One difference between the two is that json_output_clause_opt allows > specifying the FORMAT clause in addition to the RETURNING type name, > while json_returning_clause_op only allows specifying the type name. > > I'm inclined to keep only json_returning_clause_opt as you suggest and > make parse_expr.c output an error if the FORMAT clause is specified in > JSON() and JSON_SCALAR(), so turning the current syntax error on > specifying RETURNING ... FORMAT for these functions into a parsing > error. Done that way in the attached updated patch and also updated > the latter patch that adds JSON_EXISTS() and JSON_VALUE() to have > similar behavior. Yeah, that's reasonable. > > I'm not in love with the fact that JSON and JSONB have pretty much > > parallel type categorizing functionality. It seems entirely artificial. > > Maybe this didn't matter when these were contained inside each .c file > > and nobody else had to deal with that, but I think it's not good to make > > this an exported concept. Is it possible to do away with that? I mean, > > reduce both to a single categorization enum, and a single categorization > > API. Here you have to cast the enum value to int in order to make > > ExecInitExprRec work, and that seems a bit lame; moreso when the > > "is_jsonb" is determined separately (cf. ExecEvalJsonConstructor) > > OK, I agree that a unified categorizing API might be better. I'll > look at making this better. Btw, does src/include/common/jsonapi.h > look like an appropriate place for that? Hmm, that header is frontend-available, and the type-category appears to be backend-only, so maybe no. Perhaps jsonfuncs.h is more apropos? execExpr.c is already dealing with array internals, so having to deal with json internals doesn't seem completely out of place. > > In the 2023 standard, JSON_SCALAR is just > > > > <JSON scalar> ::= JSON_SCALAR <left paren> <value expression> <right paren> > > > > but we seem to have added a <JSON output format> clause to it. Should > > we really? > > Hmm, I am not seeing <JSON output format> in the rule for JSON_SCALAR, Agh, yeah, I confused myself, sorry. > Per what I wrote above, the grammar for JSON() and JSON_SCALAR() does > not allow specifying the FORMAT clause. Though considering what you > wrote, the RETURNING clause does appear to be an extension to the > standard's spec. Hmm, I see that <JSON output clause> (which is RETURNING plus optional FORMAT) appears included in JSON_OBJECT, JSON_ARRAY, JSON_QUERY, JSON_SERIALIZE, JSON_OBJECTAGG, JSON_ARRAYAGG. It's not necessarily a bad thing to have it in other places, but we should consider it carefully. Do we really want/need it in JSON() and JSON_SCALAR()? -- Álvaro Herrera 48°01'N 7°57'E — https://www.EnterpriseDB.com/
I forgot to add: * 0001 looks an obvious improvement. You could just push it now, to avoid carrying it forward anymore. I would just put the constructName ahead of value expr in the argument list, though. * 0002: I have no idea what this is (though I probably should). I would also push it right away -- if anything, so that we figure out sooner that it was actually needed in the first place. Or maybe you just need the right test cases? -- Álvaro Herrera 48°01'N 7°57'E — https://www.EnterpriseDB.com/
On Mon, Jul 10, 2023 at 11:52 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > I forgot to add: Thanks for the review of these. > * 0001 looks an obvious improvement. You could just push it now, to > avoid carrying it forward anymore. I would just put the constructName > ahead of value expr in the argument list, though. Sure, that makes sense. > * 0002: I have no idea what this is (though I probably should). I would > also push it right away -- if anything, so that we figure out sooner > that it was actually needed in the first place. Or maybe you just need > the right test cases? Hmm, I don't think having or not having CaseTestExpr makes a difference to the result of evaluating JsonValueExpr.format_expr, so there are no test cases to prove one way or the other. After staring at this again for a while, I think I figured out why the CaseTestExpr might have been put there in the first place. It seems to have to do with the fact that JsonValueExpr.raw_expr is currently evaluated independently of JsonValueExpr.formatted_expr and the CaseTestExpr propagates the result of the former to the evaluation of the latter. Actually, formatted_expr is effectively formatting_function(<result-of-raw_expr>), so if we put raw_expr itself into formatted_expr such that it is evaluated as part of evaluating formatted_expr, then there is no need for the CaseTestExpr as the propagator for raw_expr's result. I've expanded the commit message to mention the details. I'll push these tomorrow. On Mon, Jul 10, 2023 at 11:47 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > On 2023-Jul-10, Amit Langote wrote: > > > I'm not in love with the fact that JSON and JSONB have pretty much > > > parallel type categorizing functionality. It seems entirely artificial. > > > Maybe this didn't matter when these were contained inside each .c file > > > and nobody else had to deal with that, but I think it's not good to make > > > this an exported concept. Is it possible to do away with that? I mean, > > > reduce both to a single categorization enum, and a single categorization > > > API. Here you have to cast the enum value to int in order to make > > > ExecInitExprRec work, and that seems a bit lame; moreso when the > > > "is_jsonb" is determined separately (cf. ExecEvalJsonConstructor) > > > > OK, I agree that a unified categorizing API might be better. I'll > > look at making this better. Btw, does src/include/common/jsonapi.h > > look like an appropriate place for that? > > Hmm, that header is frontend-available, and the type-category appears to > be backend-only, so maybe no. Perhaps jsonfuncs.h is more apropos? > execExpr.c is already dealing with array internals, so having to deal > with json internals doesn't seem completely out of place. OK, attached 0003 does it like that. Essentially, I decided to only keep JsonTypeCategory and json_categorize_type(), with some modifications to accommodate the callers in jsonb.c. > > > In the 2023 standard, JSON_SCALAR is just > > > > > > <JSON scalar> ::= JSON_SCALAR <left paren> <value expression> <right paren> > > > > > > but we seem to have added a <JSON output format> clause to it. Should > > > we really? > > > > Hmm, I am not seeing <JSON output format> in the rule for JSON_SCALAR, > > Agh, yeah, I confused myself, sorry. > > > Per what I wrote above, the grammar for JSON() and JSON_SCALAR() does > > not allow specifying the FORMAT clause. Though considering what you > > wrote, the RETURNING clause does appear to be an extension to the > > standard's spec. > > Hmm, I see that <JSON output clause> (which is RETURNING plus optional > FORMAT) appears included in JSON_OBJECT, JSON_ARRAY, JSON_QUERY, > JSON_SERIALIZE, JSON_OBJECTAGG, JSON_ARRAYAGG. It's not necessarily a > bad thing to have it in other places, but we should consider it > carefully. Do we really want/need it in JSON() and JSON_SCALAR()? I thought that removing that support breaks JSON_TABLE() or something but it doesn't, so maybe we can do without the extension if there's no particular reason it's there in the first place. Maybe Andrew (cc'd) remembers why he decided in [1] to (re-) add the RETURNING clause to JSON() and JSON_SCALAR()? Updated patches, with 0003 being a new refactoring patch, are attached. Patches 0004~ contain a few updates around JsonValueExpr. Specifically, I removed the case for T_JsonValueExpr in transformExprRecurse(), because I realized that JsonValueExpr expressions never appear embedded in other expressions. That allowed me to get rid of some needless refactoring around transformJsonValueExpr() in the patch that adds JSON_VALUE() etc. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com [1] https://www.postgresql.org/message-id/1d44d832-4ea9-1ec9-81e9-bc6b2bd8cc43%40dunslane.net
Вложения
- v4-0003-Unify-JSON-categorize-type-API-and-export-for-ext.patch
- v4-0004-SQL-JSON-functions.patch
- v4-0007-Claim-SQL-standard-compliance-for-SQL-JSON-featur.patch
- v4-0006-JSON_TABLE.patch
- v4-0005-SQL-JSON-query-functions.patch
- v4-0002-Don-t-include-CaseTestExpr-in-JsonValueExpr.forma.patch
- v4-0001-Pass-constructName-to-transformJsonValueExpr.patch
On Wed, Jul 12, 2023 at 6:41 PM Amit Langote <amitlangote09@gmail.com> wrote: > On Mon, Jul 10, 2023 at 11:52 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > I forgot to add: > > Thanks for the review of these. > > > * 0001 looks an obvious improvement. You could just push it now, to > > avoid carrying it forward anymore. I would just put the constructName > > ahead of value expr in the argument list, though. > > Sure, that makes sense. > > > * 0002: I have no idea what this is (though I probably should). I would > > also push it right away -- if anything, so that we figure out sooner > > that it was actually needed in the first place. Or maybe you just need > > the right test cases? > > Hmm, I don't think having or not having CaseTestExpr makes a > difference to the result of evaluating JsonValueExpr.format_expr, so > there are no test cases to prove one way or the other. > > After staring at this again for a while, I think I figured out why the > CaseTestExpr might have been put there in the first place. It seems > to have to do with the fact that JsonValueExpr.raw_expr is currently > evaluated independently of JsonValueExpr.formatted_expr and the > CaseTestExpr propagates the result of the former to the evaluation of > the latter. Actually, formatted_expr is effectively > formatting_function(<result-of-raw_expr>), so if we put raw_expr > itself into formatted_expr such that it is evaluated as part of > evaluating formatted_expr, then there is no need for the CaseTestExpr > as the propagator for raw_expr's result. > > I've expanded the commit message to mention the details. > > I'll push these tomorrow. I updated it to make the code in makeJsonConstructorExpr() that *does* need to use a CaseTestExpr a bit more readable. Also, updated the comment above CaseTestExpr to mention this instance of its usage. > On Mon, Jul 10, 2023 at 11:47 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > On 2023-Jul-10, Amit Langote wrote: > > > > I'm not in love with the fact that JSON and JSONB have pretty much > > > > parallel type categorizing functionality. It seems entirely artificial. > > > > Maybe this didn't matter when these were contained inside each .c file > > > > and nobody else had to deal with that, but I think it's not good to make > > > > this an exported concept. Is it possible to do away with that? I mean, > > > > reduce both to a single categorization enum, and a single categorization > > > > API. Here you have to cast the enum value to int in order to make > > > > ExecInitExprRec work, and that seems a bit lame; moreso when the > > > > "is_jsonb" is determined separately (cf. ExecEvalJsonConstructor) > > > > > > OK, I agree that a unified categorizing API might be better. I'll > > > look at making this better. Btw, does src/include/common/jsonapi.h > > > look like an appropriate place for that? > > > > Hmm, that header is frontend-available, and the type-category appears to > > be backend-only, so maybe no. Perhaps jsonfuncs.h is more apropos? > > execExpr.c is already dealing with array internals, so having to deal > > with json internals doesn't seem completely out of place. > > OK, attached 0003 does it like that. Essentially, I decided to only > keep JsonTypeCategory and json_categorize_type(), with some > modifications to accommodate the callers in jsonb.c. > > > > > In the 2023 standard, JSON_SCALAR is just > > > > > > > > <JSON scalar> ::= JSON_SCALAR <left paren> <value expression> <right paren> > > > > > > > > but we seem to have added a <JSON output format> clause to it. Should > > > > we really? > > > > > > Hmm, I am not seeing <JSON output format> in the rule for JSON_SCALAR, > > > > Agh, yeah, I confused myself, sorry. > > > > > Per what I wrote above, the grammar for JSON() and JSON_SCALAR() does > > > not allow specifying the FORMAT clause. Though considering what you > > > wrote, the RETURNING clause does appear to be an extension to the > > > standard's spec. > > > > Hmm, I see that <JSON output clause> (which is RETURNING plus optional > > FORMAT) appears included in JSON_OBJECT, JSON_ARRAY, JSON_QUERY, > > JSON_SERIALIZE, JSON_OBJECTAGG, JSON_ARRAYAGG. It's not necessarily a > > bad thing to have it in other places, but we should consider it > > carefully. Do we really want/need it in JSON() and JSON_SCALAR()? > > I thought that removing that support breaks JSON_TABLE() or something > but it doesn't, so maybe we can do without the extension if there's no > particular reason it's there in the first place. Maybe Andrew (cc'd) > remembers why he decided in [1] to (re-) add the RETURNING clause to > JSON() and JSON_SCALAR()? > > Updated patches, with 0003 being a new refactoring patch, are > attached. Patches 0004~ contain a few updates around JsonValueExpr. > Specifically, I removed the case for T_JsonValueExpr in > transformExprRecurse(), because I realized that JsonValueExpr > expressions never appear embedded in other expressions. That allowed > me to get rid of some needless refactoring around > transformJsonValueExpr() in the patch that adds JSON_VALUE() etc. I noticed that 0003 was giving some warnings, which is fixed in the attached updated set of patches. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
- v5-0007-Claim-SQL-standard-compliance-for-SQL-JSON-featur.patch
- v5-0003-Unify-JSON-categorize-type-API-and-export-for-ext.patch
- v5-0004-SQL-JSON-functions.patch
- v5-0006-JSON_TABLE.patch
- v5-0005-SQL-JSON-query-functions.patch
- v5-0001-Pass-constructName-to-transformJsonValueExpr.patch
- v5-0002-Don-t-include-CaseTestExpr-in-JsonValueExpr.forma.patch
On Wed, Jul 12, 2023 at 10:23 PM Amit Langote <amitlangote09@gmail.com> wrote: > On Wed, Jul 12, 2023 at 6:41 PM Amit Langote <amitlangote09@gmail.com> wrote: > > On Mon, Jul 10, 2023 at 11:52 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > > I forgot to add: > > > > Thanks for the review of these. > > > > > * 0001 looks an obvious improvement. You could just push it now, to > > > avoid carrying it forward anymore. I would just put the constructName > > > ahead of value expr in the argument list, though. > > > > Sure, that makes sense. > > > > > * 0002: I have no idea what this is (though I probably should). I would > > > also push it right away -- if anything, so that we figure out sooner > > > that it was actually needed in the first place. Or maybe you just need > > > the right test cases? > > > > Hmm, I don't think having or not having CaseTestExpr makes a > > difference to the result of evaluating JsonValueExpr.format_expr, so > > there are no test cases to prove one way or the other. > > > > After staring at this again for a while, I think I figured out why the > > CaseTestExpr might have been put there in the first place. It seems > > to have to do with the fact that JsonValueExpr.raw_expr is currently > > evaluated independently of JsonValueExpr.formatted_expr and the > > CaseTestExpr propagates the result of the former to the evaluation of > > the latter. Actually, formatted_expr is effectively > > formatting_function(<result-of-raw_expr>), so if we put raw_expr > > itself into formatted_expr such that it is evaluated as part of > > evaluating formatted_expr, then there is no need for the CaseTestExpr > > as the propagator for raw_expr's result. > > > > I've expanded the commit message to mention the details. > > > > I'll push these tomorrow. > > I updated it to make the code in makeJsonConstructorExpr() that *does* > need to use a CaseTestExpr a bit more readable. Also, updated the > comment above CaseTestExpr to mention this instance of its usage. Pushed these two just now. > > On Mon, Jul 10, 2023 at 11:47 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > > On 2023-Jul-10, Amit Langote wrote: > > > > > I'm not in love with the fact that JSON and JSONB have pretty much > > > > > parallel type categorizing functionality. It seems entirely artificial. > > > > > Maybe this didn't matter when these were contained inside each .c file > > > > > and nobody else had to deal with that, but I think it's not good to make > > > > > this an exported concept. Is it possible to do away with that? I mean, > > > > > reduce both to a single categorization enum, and a single categorization > > > > > API. Here you have to cast the enum value to int in order to make > > > > > ExecInitExprRec work, and that seems a bit lame; moreso when the > > > > > "is_jsonb" is determined separately (cf. ExecEvalJsonConstructor) > > > > > > > > OK, I agree that a unified categorizing API might be better. I'll > > > > look at making this better. Btw, does src/include/common/jsonapi.h > > > > look like an appropriate place for that? > > > > > > Hmm, that header is frontend-available, and the type-category appears to > > > be backend-only, so maybe no. Perhaps jsonfuncs.h is more apropos? > > > execExpr.c is already dealing with array internals, so having to deal > > > with json internals doesn't seem completely out of place. > > > > OK, attached 0003 does it like that. Essentially, I decided to only > > keep JsonTypeCategory and json_categorize_type(), with some > > modifications to accommodate the callers in jsonb.c. > > > > > > > In the 2023 standard, JSON_SCALAR is just > > > > > > > > > > <JSON scalar> ::= JSON_SCALAR <left paren> <value expression> <right paren> > > > > > > > > > > but we seem to have added a <JSON output format> clause to it. Should > > > > > we really? > > > > > > > > Hmm, I am not seeing <JSON output format> in the rule for JSON_SCALAR, > > > > > > Agh, yeah, I confused myself, sorry. > > > > > > > Per what I wrote above, the grammar for JSON() and JSON_SCALAR() does > > > > not allow specifying the FORMAT clause. Though considering what you > > > > wrote, the RETURNING clause does appear to be an extension to the > > > > standard's spec. > > > > > > Hmm, I see that <JSON output clause> (which is RETURNING plus optional > > > FORMAT) appears included in JSON_OBJECT, JSON_ARRAY, JSON_QUERY, > > > JSON_SERIALIZE, JSON_OBJECTAGG, JSON_ARRAYAGG. It's not necessarily a > > > bad thing to have it in other places, but we should consider it > > > carefully. Do we really want/need it in JSON() and JSON_SCALAR()? > > > > I thought that removing that support breaks JSON_TABLE() or something > > but it doesn't, so maybe we can do without the extension if there's no > > particular reason it's there in the first place. Maybe Andrew (cc'd) > > remembers why he decided in [1] to (re-) add the RETURNING clause to > > JSON() and JSON_SCALAR()? > > > > Updated patches, with 0003 being a new refactoring patch, are > > attached. Patches 0004~ contain a few updates around JsonValueExpr. > > Specifically, I removed the case for T_JsonValueExpr in > > transformExprRecurse(), because I realized that JsonValueExpr > > expressions never appear embedded in other expressions. That allowed > > me to get rid of some needless refactoring around > > transformJsonValueExpr() in the patch that adds JSON_VALUE() etc. > > I noticed that 0003 was giving some warnings, which is fixed in the > attached updated set of patches. Here are the remaining patches, rebased. I'll remove the RETURNING clause from JSON() and JSON_SCALAR() in the next version that I will post tomorrow unless I hear objections. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
I looked at your 0001. My 0001 are some trivial comment cleanups to that. I scrolled through all of jsonfuncs.c to see if there was a better place for the new function than the end of the file. Man, is that one ugly file. There are almost no comments! I almost wish you would create a new file so that you don't have to put this new function in such bad company. But maybe it'll improve someday, so ... whatever. In the original code, the functions here being (re)moved do not need to return a type output function in a few cases. This works okay when the functions are each contained in a single file (because each function knows that the respective datum_to_json/datum_to_jsonb user of the returned values won't need the function OID in those other cases); but as an exported function, that strange API doesn't seem great. (It only works for 0002 because the only thing that the executor does with these cached values is call datum_to_json/b). That seems easy to solve, since we can return the hardcoded output function OID in those cases anyway. A possible complaint about this is that the OID so returned would be untested code, so they might be wrong and we'd never know. However, ISTM it's better to make a promise about always returning a function OID and later fixing any bogus function OID if we ever discover that we return one, rather than having to document in the function's comment that "we only return function OIDs in such and such cases". So I made this change my 0002. A similar complain can be made about which casts we look for. Right now, only an explicit cast to JSON is useful, so that's the only thing we do. But maybe one day a cast to JSONB would become useful if there's no cast to JSON for some datatype (in the is_jsonb case only?); and maybe another type of cast would be useful. However, that seems like going too much into uncharted territory with no useful use case, so let's just not go there for now. Maybe in the future we can improve this aspect of it, if need arises. -- Álvaro Herrera Breisgau, Deutschland — https://www.EnterpriseDB.com/
Вложения
Hi Alvaro, On Fri, Jul 14, 2023 at 1:54 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > I looked at your 0001. My 0001 are some trivial comment cleanups to > that. Thanks. > I scrolled through all of jsonfuncs.c to see if there was a better place > for the new function than the end of the file. Man, is that one ugly > file. There are almost no comments! I almost wish you would create a > new file so that you don't have to put this new function in such bad > company. But maybe it'll improve someday, so ... whatever. I tried to put it somewhere that is not the end of the file, though anywhere would have looked arbitrary anyway for the reasons you mention, so I didn't after all. > In the original code, the functions here being (re)moved do not need to > return a type output function in a few cases. This works okay when the > functions are each contained in a single file (because each function > knows that the respective datum_to_json/datum_to_jsonb user of the > returned values won't need the function OID in those other cases); but > as an exported function, that strange API doesn't seem great. (It only > works for 0002 because the only thing that the executor does with these > cached values is call datum_to_json/b). Agreed about not tying the new API too closely to datum_to_json[b]'s needs. > That seems easy to solve, since > we can return the hardcoded output function OID in those cases anyway. > A possible complaint about this is that the OID so returned would be > untested code, so they might be wrong and we'd never know. However, > ISTM it's better to make a promise about always returning a function OID > and later fixing any bogus function OID if we ever discover that we > return one, rather than having to document in the function's comment > that "we only return function OIDs in such and such cases". So I made > this change my 0002. +1 > A similar complaint can be made about which casts we look for. Right > now, only an explicit cast to JSON is useful, so that's the only thing > we do. But maybe one day a cast to JSONB would become useful if there's > no cast to JSON for some datatype (in the is_jsonb case only?); and > maybe another type of cast would be useful. However, that seems like > going too much into uncharted territory with no useful use case, so > let's just not go there for now. Maybe in the future we can improve > this aspect of it, if need arises. Hmm, yes, the note in the nearby comment stresses "to json (not to jsonb)", though the (historical) reason why is not so clear to me. I'm inclined to leave that as-is. I've merged your deltas in the attached 0001 and rebased the other patches. In 0002, I have now removed RETURNING support for JSON() and JSON_SCALAR(). -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
hi.
seems there is no explanation about, json_api_common_syntax in
functions-json.html
I can get json_query full synopsis from functions-json.html as follows:
json_query ( context_item, path_expression [ PASSING { value AS
varname } [, ...]] [ RETURNING data_type [ FORMAT JSON [ ENCODING UTF8
] ] ] [ { WITHOUT | WITH { CONDITIONAL | [UNCONDITIONAL] } } [ ARRAY ]
WRAPPER ] [ { KEEP | OMIT } QUOTES [ ON SCALAR STRING ] ] [ { ERROR |
NULL | EMPTY { [ ARRAY ] | OBJECT } | DEFAULT expression } ON EMPTY ]
[ { ERROR | NULL | EMPTY { [ ARRAY ] | OBJECT } | DEFAULT expression }
ON ERROR ])
seems doesn't have a full synopsis for json_table? only partial one
by one explanation.
Op 7/17/23 om 07:00 schreef jian he:
> hi.
> seems there is no explanation about, json_api_common_syntax in
> functions-json.html
>
> I can get json_query full synopsis from functions-json.html as follows:
> json_query ( context_item, path_expression [ PASSING { value AS
> varname } [, ...]] [ RETURNING data_type [ FORMAT JSON [ ENCODING UTF8
> ] ] ] [ { WITHOUT | WITH { CONDITIONAL | [UNCONDITIONAL] } } [ ARRAY ]
> WRAPPER ] [ { KEEP | OMIT } QUOTES [ ON SCALAR STRING ] ] [ { ERROR |
> NULL | EMPTY { [ ARRAY ] | OBJECT } | DEFAULT expression } ON EMPTY ]
> [ { ERROR | NULL | EMPTY { [ ARRAY ] | OBJECT } | DEFAULT expression }
> ON ERROR ])
>
> seems doesn't have a full synopsis for json_table? only partial one
> by one explanation.
>
FWIW, Re: json_api_common_syntax
An (old) pdf that I have (ISO/IEC TR 19075-6 First edition 2017-03)
contains the below specification. It's probably the source of the
particular term. It's easy to see how it maps onto the current v7
SQL/JSON implementation. (I don't know if it has changed in later
incarnations.)
------ 8< ------------
5.2 JSON API common syntax
The SQL/JSON query functions all need a path specification, the JSON
value to be input to that path specification for querying and
processing, and optional parameter values passed to the path
specification. They use a common syntax:
<JSON API common syntax> ::=
<JSON context item> <comma> <JSON path specification>
[ AS <JSON table path name> ]
[ <JSON passing clause> ]
<JSON context item> ::=
<JSON value expression>
<JSON path specification> ::=
<character string literal>
<JSON passing clause> ::=
PASSING <JSON argument> [ { <comma> <JSON argument> } ]
<JSON argument> ::=
<JSON value expression> AS <identifier>
------ 8< ------------
And yes, we might need a readable translation of that in the docs
although it might be easier to just get get rid of the term
'json_api_common_syntax'.
HTH,
Erik Rijkers
Hi,
On Mon, Jul 17, 2023 at 4:14 PM Erik Rijkers <er@xs4all.nl> wrote:
> Op 7/17/23 om 07:00 schreef jian he:
> > hi.
> > seems there is no explanation about, json_api_common_syntax in
> > functions-json.html
> >
> > I can get json_query full synopsis from functions-json.html as follows:
> > json_query ( context_item, path_expression [ PASSING { value AS
> > varname } [, ...]] [ RETURNING data_type [ FORMAT JSON [ ENCODING UTF8
> > ] ] ] [ { WITHOUT | WITH { CONDITIONAL | [UNCONDITIONAL] } } [ ARRAY ]
> > WRAPPER ] [ { KEEP | OMIT } QUOTES [ ON SCALAR STRING ] ] [ { ERROR |
> > NULL | EMPTY { [ ARRAY ] | OBJECT } | DEFAULT expression } ON EMPTY ]
> > [ { ERROR | NULL | EMPTY { [ ARRAY ] | OBJECT } | DEFAULT expression }
> > ON ERROR ])
> >
> > seems doesn't have a full synopsis for json_table? only partial one
> > by one explanation.
I looked through the history of the docs portion of the patch and it
looks like the synopsis for JSON_TABLE(...) used to be there but was
taken out during one of the doc reworks [1].
I've added it back in the patch as I agree that it would help to have
it. Though, I am not totally sure where I've put it is the right
place for it. JSON_TABLE() is a beast that won't fit into the table
that JSON_QUERY() et al are in, so maybe that's how it will have to
be? I have no better idea.
> FWIW, Re: json_api_common_syntax
...
> An (old) pdf that I have (ISO/IEC TR 19075-6 First edition 2017-03)
> contains the below specification. It's probably the source of the
> particular term. It's easy to see how it maps onto the current v7
> SQL/JSON implementation. (I don't know if it has changed in later
> incarnations.)
>
>
> ------ 8< ------------
> 5.2 JSON API common syntax
>
> The SQL/JSON query functions all need a path specification, the JSON
> value to be input to that path specification for querying and
> processing, and optional parameter values passed to the path
> specification. They use a common syntax:
>
> <JSON API common syntax> ::=
> <JSON context item> <comma> <JSON path specification>
> [ AS <JSON table path name> ]
> [ <JSON passing clause> ]
>
> <JSON context item> ::=
> <JSON value expression>
>
> <JSON path specification> ::=
> <character string literal>
>
> <JSON passing clause> ::=
> PASSING <JSON argument> [ { <comma> <JSON argument> } ]
>
> <JSON argument> ::=
> <JSON value expression> AS <identifier>
>
> ------ 8< ------------
>
> And yes, we might need a readable translation of that in the docs
> although it might be easier to just get get rid of the term
> 'json_api_common_syntax'.
I found a patch proposed by Andrew Dunstan in the v15 dev cycle to get
rid of the term in the JSON_TABLE docs that Erik seemed to agree with
[2], so I've applied it.
Attached updated patches. In 0002, I removed the mention of the
RETURNING clause in the JSON(), JSON_SCALAR() documentation, which I
had forgotten to do in the last version which removed its support in
code.
I think 0001 looks ready to go. Alvaro?
Also, I've been wondering if it isn't too late to apply the following
to v16 too, so as to make the code look similar in both branches:
b6e1157e7d Don't include CaseTestExpr in JsonValueExpr.formatted_expr
785480c953 Pass constructName to transformJsonValueExpr()
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
[1] https://www.postgresql.org/message-id/044204fa-738d-d89a-0e81-1c04696ba676%40dunslane.net
[2] https://www.postgresql.org/message-id/10c997db-9270-bdd5-04d5-0ffc1eefcdb7%40dunslane.net
Вложения
On 2023-Jul-18, Amit Langote wrote: > Attached updated patches. In 0002, I removed the mention of the > RETURNING clause in the JSON(), JSON_SCALAR() documentation, which I > had forgotten to do in the last version which removed its support in > code. > I think 0001 looks ready to go. Alvaro? It looks reasonable to me. > Also, I've been wondering if it isn't too late to apply the following > to v16 too, so as to make the code look similar in both branches: Hmm. > 785480c953 Pass constructName to transformJsonValueExpr() I think 785480c953 can easily be considered a bugfix on 7081ac46ace8, so I agree it's better to apply it to 16. > b6e1157e7d Don't include CaseTestExpr in JsonValueExpr.formatted_expr I feel a bit uneasy about this one. It seems to assume that formatted_expr is always set, but at the same time it's not obvious that it is. (Maybe this aspect just needs some more commentary). I agree that it would be better to make both branches identical, because if there's a problem, we are better equipped to get a fix done to both. As for the removal of makeCaseTestExpr(), I agree -- of the six callers of makeNode(CastTestExpr), only two of them would be able to use the new function, so it doesn't look of general enough usefulness. -- Álvaro Herrera Breisgau, Deutschland — https://www.EnterpriseDB.com/ Y una voz del caos me habló y me dijo "Sonríe y sé feliz, podría ser peor". Y sonreí. Y fui feliz. Y fue peor.
On Wed, Jul 19, 2023 at 12:53 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > On 2023-Jul-18, Amit Langote wrote: > > > Attached updated patches. In 0002, I removed the mention of the > > RETURNING clause in the JSON(), JSON_SCALAR() documentation, which I > > had forgotten to do in the last version which removed its support in > > code. > > > I think 0001 looks ready to go. Alvaro? > > It looks reasonable to me. Thanks for taking another look. I will push this tomorrow. > > Also, I've been wondering if it isn't too late to apply the following > > to v16 too, so as to make the code look similar in both branches: > > Hmm. > > > 785480c953 Pass constructName to transformJsonValueExpr() > > I think 785480c953 can easily be considered a bugfix on 7081ac46ace8, so > I agree it's better to apply it to 16. OK. > > b6e1157e7d Don't include CaseTestExpr in JsonValueExpr.formatted_expr > > I feel a bit uneasy about this one. It seems to assume that > formatted_expr is always set, but at the same time it's not obvious that > it is. (Maybe this aspect just needs some more commentary). Hmm, I agree that the comments about formatted_expr could be improved further, for which I propose the attached. Actually, staring some more at this, I'm inclined to change makeJsonValueExpr() to allow callers to pass it the finished 'formatted_expr' rather than set it by themselves. > I agree > that it would be better to make both branches identical, because if > there's a problem, we are better equipped to get a fix done to both. > > As for the removal of makeCaseTestExpr(), I agree -- of the six callers > of makeNode(CastTestExpr), only two of them would be able to use the new > function, so it doesn't look of general enough usefulness. OK, so you agree with back-patching this one too, though perhaps only after applying something like the aforementioned patch. Just to be sure, would the good practice in this case be to squash the fixup patch into b6e1157e7d before back-patching? -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
On Wed, Jul 19, 2023 at 5:17 PM Amit Langote <amitlangote09@gmail.com> wrote: > On Wed, Jul 19, 2023 at 12:53 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > On 2023-Jul-18, Amit Langote wrote: > > > b6e1157e7d Don't include CaseTestExpr in JsonValueExpr.formatted_expr > > > > I feel a bit uneasy about this one. It seems to assume that > > formatted_expr is always set, but at the same time it's not obvious that > > it is. (Maybe this aspect just needs some more commentary). > > Hmm, I agree that the comments about formatted_expr could be improved > further, for which I propose the attached. Actually, staring some > more at this, I'm inclined to change makeJsonValueExpr() to allow > callers to pass it the finished 'formatted_expr' rather than set it by > themselves. Hmm, after looking some more, it may not be entirely right that formatted_expr is always set in the code paths that call transformJsonValueExpr(). Will look at this some more tomorrow. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
On Tue, Jul 18, 2023 at 5:11 PM Amit Langote <amitlangote09@gmail.com> wrote:
>
> Hi,
>
> On Mon, Jul 17, 2023 at 4:14 PM Erik Rijkers <er@xs4all.nl> wrote:
> > Op 7/17/23 om 07:00 schreef jian he:
> > > hi.
> > > seems there is no explanation about, json_api_common_syntax in
> > > functions-json.html
> > >
> > > I can get json_query full synopsis from functions-json.html as follows:
> > > json_query ( context_item, path_expression [ PASSING { value AS
> > > varname } [, ...]] [ RETURNING data_type [ FORMAT JSON [ ENCODING UTF8
> > > ] ] ] [ { WITHOUT | WITH { CONDITIONAL | [UNCONDITIONAL] } } [ ARRAY ]
> > > WRAPPER ] [ { KEEP | OMIT } QUOTES [ ON SCALAR STRING ] ] [ { ERROR |
> > > NULL | EMPTY { [ ARRAY ] | OBJECT } | DEFAULT expression } ON EMPTY ]
> > > [ { ERROR | NULL | EMPTY { [ ARRAY ] | OBJECT } | DEFAULT expression }
> > > ON ERROR ])
> > >
> > > seems doesn't have a full synopsis for json_table? only partial one
> > > by one explanation.
>
> I looked through the history of the docs portion of the patch and it
> looks like the synopsis for JSON_TABLE(...) used to be there but was
> taken out during one of the doc reworks [1].
>
> I've added it back in the patch as I agree that it would help to have
> it. Though, I am not totally sure where I've put it is the right
> place for it. JSON_TABLE() is a beast that won't fit into the table
> that JSON_QUERY() et al are in, so maybe that's how it will have to
> be? I have no better idea.
>
> >
attached screenshot render json_table syntax almost plain html. It looks fine.
based on syntax, then I am kind of confused with following 2 cases:
--1
SELECT * FROM JSON_TABLE(jsonb '1', '$'
COLUMNS (a int PATH 'strict $.a' default 1 ON EMPTY default 2 on error)
ERROR ON ERROR) jt;
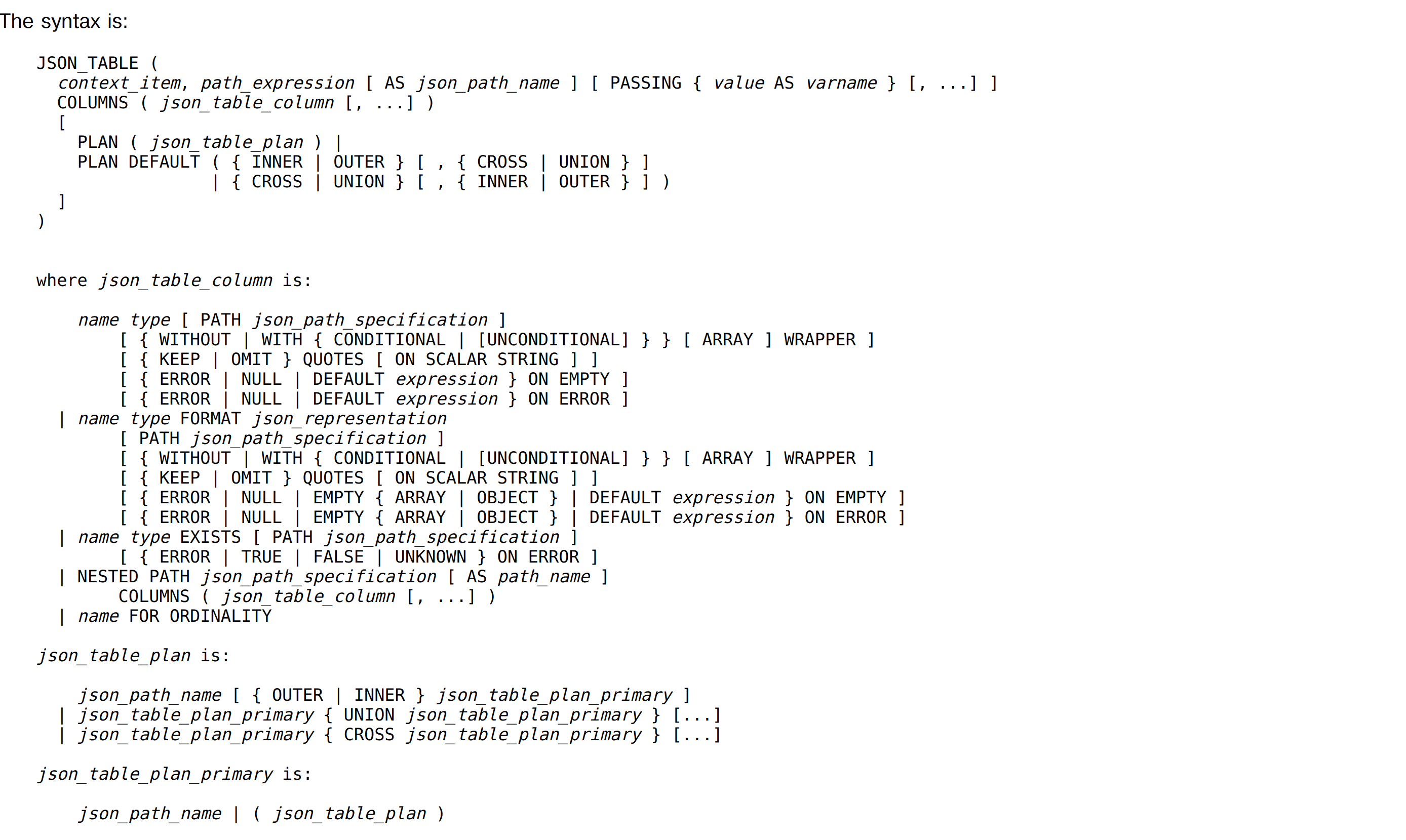
COLUMNS (a int PATH 'strict $.a' default 1 ON EMPTY default 2 on error)
ERROR ON ERROR) jt;
--2
SELECT * FROM JSON_TABLE(jsonb '1', '$'
COLUMNS (a int PATH 'strict $.a' default 1 ON EMPTY default 2 on error)) jt;
the first one should yield syntax error?
SELECT * FROM JSON_TABLE(jsonb '1', '$'
COLUMNS (a int PATH 'strict $.a' default 1 ON EMPTY default 2 on error)) jt;
the first one should yield syntax error?
Вложения
Hello,
On Thu, Jul 20, 2023 at 10:35 AM jian he <jian.universality@gmail.com> wrote:
> On Tue, Jul 18, 2023 at 5:11 PM Amit Langote <amitlangote09@gmail.com> wrote:
> > > Op 7/17/23 om 07:00 schreef jian he:
> > > > hi.
> > > > seems there is no explanation about, json_api_common_syntax in
> > > > functions-json.html
> > > >
> > > > I can get json_query full synopsis from functions-json.html as follows:
> > > > json_query ( context_item, path_expression [ PASSING { value AS
> > > > varname } [, ...]] [ RETURNING data_type [ FORMAT JSON [ ENCODING UTF8
> > > > ] ] ] [ { WITHOUT | WITH { CONDITIONAL | [UNCONDITIONAL] } } [ ARRAY ]
> > > > WRAPPER ] [ { KEEP | OMIT } QUOTES [ ON SCALAR STRING ] ] [ { ERROR |
> > > > NULL | EMPTY { [ ARRAY ] | OBJECT } | DEFAULT expression } ON EMPTY ]
> > > > [ { ERROR | NULL | EMPTY { [ ARRAY ] | OBJECT } | DEFAULT expression }
> > > > ON ERROR ])
> > > >
> > > > seems doesn't have a full synopsis for json_table? only partial one
> > > > by one explanation.
> >
> > I looked through the history of the docs portion of the patch and it
> > looks like the synopsis for JSON_TABLE(...) used to be there but was
> > taken out during one of the doc reworks [1].
> >
> > I've added it back in the patch as I agree that it would help to have
> > it. Though, I am not totally sure where I've put it is the right
> > place for it. JSON_TABLE() is a beast that won't fit into the table
> > that JSON_QUERY() et al are in, so maybe that's how it will have to
> > be? I have no better idea.
>
> attached screenshot render json_table syntax almost plain html. It looks fine.
Thanks for checking.
> based on syntax, then I am kind of confused with following 2 cases:
> --1
> SELECT * FROM JSON_TABLE(jsonb '1', '$'
> COLUMNS (a int PATH 'strict $.a' default 1 ON EMPTY default 2 on error)
> ERROR ON ERROR) jt;
>
> --2
> SELECT * FROM JSON_TABLE(jsonb '1', '$'
> COLUMNS (a int PATH 'strict $.a' default 1 ON EMPTY default 2 on error)) jt;
>
> the first one should yield syntax error?
No. Actually, the synopsis missed the optional ON ERROR clause that
can appear after COLUMNS(...). Will fix it.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
On Wed, Jul 19, 2023 at 5:17 PM Amit Langote <amitlangote09@gmail.com> wrote: > On Wed, Jul 19, 2023 at 12:53 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > On 2023-Jul-18, Amit Langote wrote: > > > > > Attached updated patches. In 0002, I removed the mention of the > > > RETURNING clause in the JSON(), JSON_SCALAR() documentation, which I > > > had forgotten to do in the last version which removed its support in > > > code. > > > > > I think 0001 looks ready to go. Alvaro? > > > > It looks reasonable to me. > > Thanks for taking another look. > > I will push this tomorrow. Pushed. > > > Also, I've been wondering if it isn't too late to apply the following > > > to v16 too, so as to make the code look similar in both branches: > > > > Hmm. > > > > > 785480c953 Pass constructName to transformJsonValueExpr() > > > > I think 785480c953 can easily be considered a bugfix on 7081ac46ace8, so > > I agree it's better to apply it to 16. > > OK. Pushed to 16. > > > b6e1157e7d Don't include CaseTestExpr in JsonValueExpr.formatted_expr > > > > I feel a bit uneasy about this one. It seems to assume that > > formatted_expr is always set, but at the same time it's not obvious that > > it is. (Maybe this aspect just needs some more commentary). > > Hmm, I agree that the comments about formatted_expr could be improved > further, for which I propose the attached. Actually, staring some > more at this, I'm inclined to change makeJsonValueExpr() to allow > callers to pass it the finished 'formatted_expr' rather than set it by > themselves. > > > I agree > > that it would be better to make both branches identical, because if > > there's a problem, we are better equipped to get a fix done to both. > > > > As for the removal of makeCaseTestExpr(), I agree -- of the six callers > > of makeNode(CastTestExpr), only two of them would be able to use the new > > function, so it doesn't look of general enough usefulness. > > OK, so you agree with back-patching this one too, though perhaps only > after applying something like the aforementioned patch. I looked at this some more and concluded that it's fine to think that all JsonValueExpr nodes leaving the parser have their formatted_expr set. I've updated the commentary some more in the patch attached as 0001. Rebased SQL/JSON patches also attached. I've fixed the JSON_TABLE syntax synopsis in the documentation as mentioned in my other email. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
On Thu, Jul 20, 2023 at 17:19 Amit Langote <amitlangote09@gmail.com> wrote:
On Wed, Jul 19, 2023 at 5:17 PM Amit Langote <amitlangote09@gmail.com> wrote:
> On Wed, Jul 19, 2023 at 12:53 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote:
> > On 2023-Jul-18, Amit Langote wrote:
> >
> > > Attached updated patches. In 0002, I removed the mention of the
> > > RETURNING clause in the JSON(), JSON_SCALAR() documentation, which I
> > > had forgotten to do in the last version which removed its support in
> > > code.
> >
> > > I think 0001 looks ready to go. Alvaro?
> >
> > It looks reasonable to me.
>
> Thanks for taking another look.
>
> I will push this tomorrow.
Pushed.
> > > Also, I've been wondering if it isn't too late to apply the following
> > > to v16 too, so as to make the code look similar in both branches:
> >
> > Hmm.
> >
> > > 785480c953 Pass constructName to transformJsonValueExpr()
> >
> > I think 785480c953 can easily be considered a bugfix on 7081ac46ace8, so
> > I agree it's better to apply it to 16.
>
> OK.
Pushed to 16.
> > > b6e1157e7d Don't include CaseTestExpr in JsonValueExpr.formatted_expr
> >
> > I feel a bit uneasy about this one. It seems to assume that
> > formatted_expr is always set, but at the same time it's not obvious that
> > it is. (Maybe this aspect just needs some more commentary).
>
> Hmm, I agree that the comments about formatted_expr could be improved
> further, for which I propose the attached. Actually, staring some
> more at this, I'm inclined to change makeJsonValueExpr() to allow
> callers to pass it the finished 'formatted_expr' rather than set it by
> themselves.
>
> > I agree
> > that it would be better to make both branches identical, because if
> > there's a problem, we are better equipped to get a fix done to both.
> >
> > As for the removal of makeCaseTestExpr(), I agree -- of the six callers
> > of makeNode(CastTestExpr), only two of them would be able to use the new
> > function, so it doesn't look of general enough usefulness.
>
> OK, so you agree with back-patching this one too, though perhaps only
> after applying something like the aforementioned patch.
I looked at this some more and concluded that it's fine to think that
all JsonValueExpr nodes leaving the parser have their formatted_expr
set. I've updated the commentary some more in the patch attached as
0001.
Rebased SQL/JSON patches also attached. I've fixed the JSON_TABLE
syntax synopsis in the documentation as mentioned in my other email.
I’m thinking of pushing 0001 and 0002 tomorrow barring objections.
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
EDB: http://www.enterprisedb.com
On 2023-Jul-21, Amit Langote wrote: > I’m thinking of pushing 0001 and 0002 tomorrow barring objections. 0001 looks reasonable to me. I think you asked whether to squash that one with the other bugfix commit for the same code that you already pushed to master; I think there's no point in committing as separate patches, because the first one won't show up in the git_changelog output as a single entity with the one in 16, so it'll just be additional noise. I've looked at 0002 at various points in time and I think it looks generally reasonable. I think your removal of a couple of newlines (where originally two appear in sequence) is unwarranted; that the name to_json[b]_worker is ugly for exported functions (maybe "datum_to_json" would be better, or you may have better ideas); and that the omission of the stock comment in the new stanzas in FigureColnameInternal() is strange. But I don't have anything serious. Do add some ecpg tests ... Also, remember to pgindent and bump catversion, if you haven't already. -- Álvaro Herrera 48°01'N 7°57'E — https://www.EnterpriseDB.com/ "No hay hombre que no aspire a la plenitud, es decir, la suma de experiencias de que un hombre es capaz"
Hi Alvaro, Thanks for taking a look. On Fri, Jul 21, 2023 at 1:02 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > On 2023-Jul-21, Amit Langote wrote: > > > I’m thinking of pushing 0001 and 0002 tomorrow barring objections. > > 0001 looks reasonable to me. I think you asked whether to squash that > one with the other bugfix commit for the same code that you already > pushed to master; I think there's no point in committing as separate > patches, because the first one won't show up in the git_changelog output > as a single entity with the one in 16, so it'll just be additional > noise. OK, pushed 0001 to HEAD and b6e1157e7d + 0001 to 16. > I've looked at 0002 at various points in time and I think it looks > generally reasonable. I think your removal of a couple of newlines > (where originally two appear in sequence) is unwarranted; that the name > to_json[b]_worker is ugly for exported functions (maybe "datum_to_json" > would be better, or you may have better ideas); Went with datum_to_json[b]. Created a separate refactoring patch for this, attached as 0001. Created another refactoring patch for the hunks related to renaming of a nonterminal in gram.y, attached as 0002. > and that the omission of > the stock comment in the new stanzas in FigureColnameInternal() is > strange. Yes, fixed. > But I don't have anything serious. Do add some ecpg tests ... Added. > Also, remember to pgindent and bump catversion, if you haven't already. Will do. Wasn't sure myself whether the catversion should be bumped, but I suppose it must be because ruleutils.c has changed. Attaching latest patches. Will push 0001, 0002, and 0003 on Monday to avoid worrying about the buildfarm on a Friday evening. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
- v10-0002-Rename-a-nonterminal-used-in-SQL-JSON-grammar.patch
- v10-0006-Claim-SQL-standard-compliance-for-SQL-JSON-featu.patch
- v10-0003-Add-more-SQL-JSON-constructor-functions.patch
- v10-0005-JSON_TABLE.patch
- v10-0004-SQL-JSON-query-functions.patch
- v10-0001-Some-refactoring-to-export-json-b-conversion-fun.patch
hi
based on v10*.patch. questions/ideas about the doc.
> json_exists ( context_item, path_expression [ PASSING { value AS varname } [, ...]] [ RETURNING data_type ] [ { TRUE
|FALSE | UNKNOWN | ERROR } ON ERROR ])
> Returns true if the SQL/JSON path_expression applied to the context_item using the values yields any items. The ON
ERRORclause specifies what is returned if an error occurs. Note that if the path_expression is strict, an error is
generatedif it yields no items. The default value is UNKNOWN which causes a NULL result.
only SELECT JSON_EXISTS(NULL::jsonb, '$'); will cause a null result.
In lex mode, if yield no items return false, no error will return,
even error on error.
Only case error will happen, strict mode error on error. (select
json_exists(jsonb '{"a": [1,2,3]}', 'strict $.b' error on error)
so I came up with the following:
Returns true if the SQL/JSON path_expression applied to the
context_item using the values yields any items. The ON ERROR clause
specifies what is returned if an error occurs, if not specified, the
default value is false when it yields no items.
Note that if the path_expression is strict, ERROR ON ERROR specified,
an error is generated if it yields no items.
--------------------------------------------------------------------------------------------------
/* --first branch of json_table_column spec.
name type [ PATH json_path_specification ]
[ { WITHOUT | WITH { CONDITIONAL | [UNCONDITIONAL] } } [ ARRAY
] WRAPPER ]
[ { KEEP | OMIT } QUOTES [ ON SCALAR STRING ] ]
[ { ERROR | NULL | DEFAULT expression } ON EMPTY ]
[ { ERROR | NULL | DEFAULT expression } ON ERROR ]
*/
I am not sure what " [ ON SCALAR STRING ]" means. There is no test on this.
i wonder how to achieve the following query with json_table:
select json_query(jsonb '"world"', '$' returning text keep quotes) ;
the following case will fail.
SELECT * FROM JSON_TABLE(jsonb '"world"', '$' COLUMNS (item text PATH
'$' keep quotes ON SCALAR STRING ));
ERROR: cannot use OMIT QUOTES clause with scalar columns
LINE 1: ...T * FROM JSON_TABLE(jsonb '"world"', '$' COLUMNS (item text ...
^
error should be ERROR: cannot use KEEP QUOTES clause with scalar columns?
LINE1 should be: SELECT * FROM JSON_TABLE(jsonb '"world"', '$' COLUMNS
(item text ...
--------------------------------------------------------------------------------
quote from json_query:
> This function must return a JSON string, so if the path expression returns multiple SQL/JSON items, you must wrap the
resultusing the
> WITH WRAPPER clause.
I think the final result will be: if the RETURNING clause is not
specified, then the returned data type is jsonb. if multiple SQL/JSON
items returned, if not specified WITH WRAPPER, null will be returned.
------------------------------------------------------------------------------------
quote from json_query:
> The ON ERROR and ON EMPTY clauses have similar semantics to those clauses for json_value.
quote from json_table:
> These clauses have the same syntax and semantics as for json_value and json_query.
it would be better in json_value syntax explicit mention: if not
explicitly mentioned, what will happen when on error, on empty
happened ?
-------------------------------------------------------------------------------------
> You can have only one ordinality column per table
but the regress test shows that you can have more than one ordinality column.
----------------------------------------------------------------------------
similar to here
https://git.postgresql.org/cgit/postgresql.git/tree/src/test/regress/expected/sqljson.out#n804
Maybe in file src/test/regress/sql/jsonb_sqljson.sql line 349, you can
also create a table first. insert corner case data.
then split the very wide select query (more than 26 columns) into 4
small queries, better to view the expected result on the web.
On Fri, Jul 21, 2023 at 7:33 PM Amit Langote <amitlangote09@gmail.com> wrote: > On Fri, Jul 21, 2023 at 1:02 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > On 2023-Jul-21, Amit Langote wrote: > > > > > I’m thinking of pushing 0001 and 0002 tomorrow barring objections. > > > > 0001 looks reasonable to me. I think you asked whether to squash that > > one with the other bugfix commit for the same code that you already > > pushed to master; I think there's no point in committing as separate > > patches, because the first one won't show up in the git_changelog output > > as a single entity with the one in 16, so it'll just be additional > > noise. > > OK, pushed 0001 to HEAD and b6e1157e7d + 0001 to 16. > > > I've looked at 0002 at various points in time and I think it looks > > generally reasonable. I think your removal of a couple of newlines > > (where originally two appear in sequence) is unwarranted; that the name > > to_json[b]_worker is ugly for exported functions (maybe "datum_to_json" > > would be better, or you may have better ideas); > > Went with datum_to_json[b]. Created a separate refactoring patch for > this, attached as 0001. > > Created another refactoring patch for the hunks related to renaming of > a nonterminal in gram.y, attached as 0002. > > > and that the omission of > > the stock comment in the new stanzas in FigureColnameInternal() is > > strange. > > Yes, fixed. > > > But I don't have anything serious. Do add some ecpg tests ... > > Added. > > > Also, remember to pgindent and bump catversion, if you haven't already. > > Will do. Wasn't sure myself whether the catversion should be bumped, > but I suppose it must be because ruleutils.c has changed. > > Attaching latest patches. Will push 0001, 0002, and 0003 on Monday to > avoid worrying about the buildfarm on a Friday evening. And pushed. Will post the remaining patches after addressing jian he's comments. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Hi, Thank you for developing such a great feature. The attached patch formats the documentation like any other function definition: - Added right parenthesis to json function calls. - Added <returnvalue> to json functions. - Added a space to the 'expression' part of the json_scalar function. - Added a space to the 'expression' part of the json_serialize function. It seems that the three functions added this time do not have tuples in the pg_proc catalog. Is it unnecessary? Regards, Noriyoshi Shinoda -----Original Message----- From: Amit Langote <amitlangote09@gmail.com> Sent: Wednesday, July 26, 2023 5:10 PM To: Alvaro Herrera <alvherre@alvh.no-ip.org> Cc: Andrew Dunstan <andrew@dunslane.net>; Erik Rijkers <er@xs4all.nl>; PostgreSQL-development <pgsql-hackers@postgresql.org>;jian he <jian.universality@gmail.com> Subject: Re: remaining sql/json patches On Fri, Jul 21, 2023 at 7:33 PM Amit Langote <amitlangote09@gmail.com> wrote: > On Fri, Jul 21, 2023 at 1:02 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > On 2023-Jul-21, Amit Langote wrote: > > > > > I’m thinking of pushing 0001 and 0002 tomorrow barring objections. > > > > 0001 looks reasonable to me. I think you asked whether to squash > > that one with the other bugfix commit for the same code that you > > already pushed to master; I think there's no point in committing as > > separate patches, because the first one won't show up in the > > git_changelog output as a single entity with the one in 16, so it'll > > just be additional noise. > > OK, pushed 0001 to HEAD and b6e1157e7d + 0001 to 16. > > > I've looked at 0002 at various points in time and I think it looks > > generally reasonable. I think your removal of a couple of newlines > > (where originally two appear in sequence) is unwarranted; that the > > name to_json[b]_worker is ugly for exported functions (maybe "datum_to_json" > > would be better, or you may have better ideas); > > Went with datum_to_json[b]. Created a separate refactoring patch for > this, attached as 0001. > > Created another refactoring patch for the hunks related to renaming of > a nonterminal in gram.y, attached as 0002. > > > and that the omission of > > the stock comment in the new stanzas in FigureColnameInternal() is > > strange. > > Yes, fixed. > > > But I don't have anything serious. Do add some ecpg tests ... > > Added. > > > Also, remember to pgindent and bump catversion, if you haven't already. > > Will do. Wasn't sure myself whether the catversion should be bumped, > but I suppose it must be because ruleutils.c has changed. > > Attaching latest patches. Will push 0001, 0002, and 0003 on Monday to > avoid worrying about the buildfarm on a Friday evening. And pushed. Will post the remaining patches after addressing jian he's comments. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
Hello, On Thu, Jul 27, 2023 at 6:36 PM Shinoda, Noriyoshi (HPE Services Japan - FSIP) <noriyoshi.shinoda@hpe.com> wrote: > Hi, > Thank you for developing such a great feature. The attached patch formats the documentation like any other function definition: > - Added right parenthesis to json function calls. > - Added <returnvalue> to json functions. > - Added a space to the 'expression' part of the json_scalar function. > - Added a space to the 'expression' part of the json_serialize function. Thanks for checking and the patch. Will push shortly. > It seems that the three functions added this time do not have tuples in the pg_proc catalog. Is it unnecessary? Yes. These are not functions that get pg_proc entries, but SQL constructs that *look like* functions, similar to XMLEXISTS(), etc. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Op 7/21/23 om 12:33 schreef Amit Langote: > > Thanks for taking a look. > Hi Amit, Is there any chance to rebase the outstanding SQL/JSON patches, (esp. json_query)? Thanks! Erik Rijkers
Hi,
On Fri, Aug 4, 2023 at 19:01 Erik Rijkers <er@xs4all.nl> wrote:
Op 7/21/23 om 12:33 schreef Amit Langote:
>
> Thanks for taking a look.
>
Hi Amit,
Is there any chance to rebase the outstanding SQL/JSON patches, (esp.
json_query)?
Yes, working on it. Will post a WIP shortly.
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
EDB: http://www.enterprisedb.com
Hi,
On Sun, Jul 23, 2023 at 5:17 PM jian he <jian.universality@gmail.com> wrote:
> hi
> based on v10*.patch. questions/ideas about the doc.
Thanks for taking a look.
> > json_exists ( context_item, path_expression [ PASSING { value AS varname } [, ...]] [ RETURNING data_type ] [ {
TRUE| FALSE | UNKNOWN | ERROR } ON ERROR ])
> > Returns true if the SQL/JSON path_expression applied to the context_item using the values yields any items. The ON
ERRORclause specifies what is returned if an error occurs. Note that if the path_expression is strict, an error is
generatedif it yields no items. The default value is UNKNOWN which causes a NULL result.
>
> only SELECT JSON_EXISTS(NULL::jsonb, '$'); will cause a null result.
> In lex mode, if yield no items return false, no error will return,
> even error on error.
> Only case error will happen, strict mode error on error. (select
> json_exists(jsonb '{"a": [1,2,3]}', 'strict $.b' error on error)
>
> so I came up with the following:
> Returns true if the SQL/JSON path_expression applied to the
> context_item using the values yields any items. The ON ERROR clause
> specifies what is returned if an error occurs, if not specified, the
> default value is false when it yields no items.
> Note that if the path_expression is strict, ERROR ON ERROR specified,
> an error is generated if it yields no items.
OK, will change the text to say that the default ON ERROR behavior is
to return false.
> --------------------------------------------------------------------------------------------------
> /* --first branch of json_table_column spec.
>
> name type [ PATH json_path_specification ]
> [ { WITHOUT | WITH { CONDITIONAL | [UNCONDITIONAL] } } [ ARRAY
> ] WRAPPER ]
> [ { KEEP | OMIT } QUOTES [ ON SCALAR STRING ] ]
> [ { ERROR | NULL | DEFAULT expression } ON EMPTY ]
> [ { ERROR | NULL | DEFAULT expression } ON ERROR ]
> */
> I am not sure what " [ ON SCALAR STRING ]" means. There is no test on this.
ON SCALAR STRING is just syntactic sugar. KEEP/OMIT QUOTES specifies
the behavior when the result of JSON_QUERY() is a JSON scalar value.
> i wonder how to achieve the following query with json_table:
> select json_query(jsonb '"world"', '$' returning text keep quotes) ;
>
> the following case will fail.
> SELECT * FROM JSON_TABLE(jsonb '"world"', '$' COLUMNS (item text PATH
> '$' keep quotes ON SCALAR STRING ));
> ERROR: cannot use OMIT QUOTES clause with scalar columns
> LINE 1: ...T * FROM JSON_TABLE(jsonb '"world"', '$' COLUMNS (item text ...
> ^
> error should be ERROR: cannot use KEEP QUOTES clause with scalar columns?
> LINE1 should be: SELECT * FROM JSON_TABLE(jsonb '"world"', '$' COLUMNS
> (item text ...
Hmm, yes, I think the code that produces the error is not trying hard
enough to figure out the actually specified QUOTES clause. Fixed and
added new tests.
> --------------------------------------------------------------------------------
> quote from json_query:
> > This function must return a JSON string, so if the path expression returns multiple SQL/JSON items, you must wrap
theresult using the
> > WITH WRAPPER clause.
>
> I think the final result will be: if the RETURNING clause is not
> specified, then the returned data type is jsonb. if multiple SQL/JSON
> items returned, if not specified WITH WRAPPER, null will be returned.
I suppose you mean the following case:
SELECT JSON_QUERY(jsonb '[1,2]', '$[*]');
json_query
------------
(1 row)
which with ERROR ON ERROR gives:
SELECT JSON_QUERY(jsonb '[1,2]', '$[*]' ERROR ON ERROR);
ERROR: JSON path expression in JSON_QUERY should return singleton
item without wrapper
HINT: Use WITH WRAPPER clause to wrap SQL/JSON item sequence into array.
The default return value for JSON_QUERY when an error occurs during
path expression evaluation is NULL. I don't think that it needs to be
mentioned separately.
> ------------------------------------------------------------------------------------
> quote from json_query:
> > The ON ERROR and ON EMPTY clauses have similar semantics to those clauses for json_value.
> quote from json_table:
> > These clauses have the same syntax and semantics as for json_value and json_query.
>
> it would be better in json_value syntax explicit mention: if not
> explicitly mentioned, what will happen when on error, on empty
> happened ?
OK, I've improved the text here.
> -------------------------------------------------------------------------------------
> > You can have only one ordinality column per table
> but the regress test shows that you can have more than one ordinality column.
Hmm, I am not sure why the code's allowing that. Anyway, for the lack
any historical notes on why it should be allowed, I've fixed the code
to allow only one ordinality columns and modified the tests.
> ----------------------------------------------------------------------------
> similar to here
> https://git.postgresql.org/cgit/postgresql.git/tree/src/test/regress/expected/sqljson.out#n804
> Maybe in file src/test/regress/sql/jsonb_sqljson.sql line 349, you can
> also create a table first. insert corner case data.
> then split the very wide select query (more than 26 columns) into 4
> small queries, better to view the expected result on the web.
OK, done.
I'm still finding things to fix here and there, but here's what I have
got so far.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
Вложения
Hi. in v11, json_query: + The returned <replaceable>data_type</replaceable> has the same semantics + as for constructor functions like <function>json_objectagg</function>; + the default returned type is <type>text</type>. + The <literal>ON EMPTY</literal> clause specifies the behavior if the + <replaceable>path_expression</replaceable> yields no value at all; the + default when <literal>ON ERROR</literal> is not specified is to return a + null value. the default returned type is jsonb? Also in above quoted second last line should be <literal>ON EMPTY</literal> ? Other than that, the doc looks good.
On Tue, Aug 15, 2023 at 5:58 PM jian he <jian.universality@gmail.com> wrote: > Hi. > in v11, json_query: > + The returned <replaceable>data_type</replaceable> has the > same semantics > + as for constructor functions like <function>json_objectagg</function>; > + the default returned type is <type>text</type>. > + The <literal>ON EMPTY</literal> clause specifies the behavior if the > + <replaceable>path_expression</replaceable> yields no value at all; the > + default when <literal>ON ERROR</literal> is not specified is > to return a > + null value. > > the default returned type is jsonb? You are correct. > Also in above quoted second last > line should be <literal>ON EMPTY</literal> ? Correct too. > Other than that, the doc looks good. Thanks for the review. I will post a new version after finishing working on a few other improvements I am working on. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Hello, On Wed, Aug 16, 2023 at 1:27 PM Amit Langote <amitlangote09@gmail.com> wrote: > I will post a new version after finishing working on a few other > improvements I am working on. Sorry about the delay. Here's a new version. I found out that llvmjit_expr.c additions have been broken all along, I mean since I rewrote the JsonExpr evaluation code to use soft error handling back in January or so. For example, I had made CoerceiViaIO evaluation code (EEOP_IOCOERCE ExprEvalStep) invoked by JsonCoercion node's evaluation to pass an ErrorSaveContext to the type input functions so that any errors result in returning NULL instead of throwing the error. Though the llvmjit_expr.c code was not modified to do the same, so the SQL/JSON query functions would return wrong results when JITed. I have made many revisions to the JsonExpr expression evaluation itself, not all of which were reflected in the llvmjit_expr.c counterparts. I've fixed all that in the attached. I've broken the parts to teach the CoerceViaIO evaluation code to handle errors softly into a separate patch attached as 0001. Other notable changes in the SQL/JSON query functions patch (now 0002): * Significantly rewrote the parser changes to make it a bit more readable than before. My main goal was to separate the code for each JSON_EXISTS_OP, JSON_QUERY_OP, and JSON_VALUE_OP such that the op-type-specific behaviors are more readily apparent by reading the code. * Got rid of JsonItemCoercions struct/node, which contained a JsonCoercion field to store the coercion expressions for each JSON item type that needs to be coerced to the RETURNING type, in favor of using List of JsonCoercion nodes. That resulted in simpler code in many places, most notably in the executor / llvmjit_expr.c. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
Op 8/31/23 om 14:57 schreef Amit Langote:
> Hello,
>
> On Wed, Aug 16, 2023 at 1:27 PM Amit Langote <amitlangote09@gmail.com> wrote:
>> I will post a new version after finishing working on a few other
>> improvements I am working on.
>
> Sorry about the delay. Here's a new version.
>
Hi,
While compiling the new set
[v12-0001-Support-soft-error-handling-during-CoerceViaIO-e.patch]
[v12-0002-SQL-JSON-query-functions.patch]
[v12-0003-JSON_TABLE.patch]
[v12-0004-Claim-SQL-standard-compliance-for-SQL-JSON-featu.patch]
gcc 13.2.0 is sputtering somewhat:
--------------
In function ‘transformJsonFuncExpr’,
inlined from ‘transformExprRecurse’ at parse_expr.c:374:13:
parse_expr.c:4362:13: warning: ‘contextItemExpr’ may be used
uninitialized [-Wmaybe-uninitialized]
4362 | if (exprType(contextItemExpr) != JSONBOID)
| ^~~~~~~~~~~~~~~~~~~~~~~~~
parse_expr.c: In function ‘transformExprRecurse’:
parse_expr.c:4214:21: note: ‘contextItemExpr’ was declared here
4214 | Node *contextItemExpr;
| ^~~~~~~~~~~~~~~
nodeFuncs.c: In function ‘exprSetCollation’:
nodeFuncs.c:1238:25: warning: this statement may fall through
[-Wimplicit-fallthrough=]
1238 | {
| ^
nodeFuncs.c:1247:17: note: here
1247 | case T_JsonCoercion:
| ^~~~
--------------
Those looks pretty unimportant, but I thought I'd let you know.
Tests (check, check-world and my own) still run fine.
Thanks,
Erik Rijkers
> I found out that llvmjit_expr.c additions have been broken all along,
> I mean since I rewrote the JsonExpr evaluation code to use soft error
> handling back in January or so. For example, I had made CoerceiViaIO
> evaluation code (EEOP_IOCOERCE ExprEvalStep) invoked by JsonCoercion
> node's evaluation to pass an ErrorSaveContext to the type input
> functions so that any errors result in returning NULL instead of
> throwing the error. Though the llvmjit_expr.c code was not modified
> to do the same, so the SQL/JSON query functions would return wrong
> results when JITed. I have made many revisions to the JsonExpr
> expression evaluation itself, not all of which were reflected in the
> llvmjit_expr.c counterparts. I've fixed all that in the attached.
>
> I've broken the parts to teach the CoerceViaIO evaluation code to
> handle errors softly into a separate patch attached as 0001.
>
> Other notable changes in the SQL/JSON query functions patch (now 0002):
>
> * Significantly rewrote the parser changes to make it a bit more
> readable than before. My main goal was to separate the code for each
> JSON_EXISTS_OP, JSON_QUERY_OP, and JSON_VALUE_OP such that the
> op-type-specific behaviors are more readily apparent by reading the
> code.
>
> * Got rid of JsonItemCoercions struct/node, which contained a
> JsonCoercion field to store the coercion expressions for each JSON
> item type that needs to be coerced to the RETURNING type, in favor of
> using List of JsonCoercion nodes. That resulted in simpler code in
> many places, most notably in the executor / llvmjit_expr.c.
>
Hi,
On Thu, Aug 31, 2023 at 10:49 PM Erik Rijkers <er@xs4all.nl> wrote:
>
> Op 8/31/23 om 14:57 schreef Amit Langote:
> > Hello,
> >
> > On Wed, Aug 16, 2023 at 1:27 PM Amit Langote <amitlangote09@gmail.com> wrote:
> >> I will post a new version after finishing working on a few other
> >> improvements I am working on.
> >
> > Sorry about the delay. Here's a new version.
> >
> Hi,
>
> While compiling the new set
>
> [v12-0001-Support-soft-error-handling-during-CoerceViaIO-e.patch]
> [v12-0002-SQL-JSON-query-functions.patch]
> [v12-0003-JSON_TABLE.patch]
> [v12-0004-Claim-SQL-standard-compliance-for-SQL-JSON-featu.patch]
>
> gcc 13.2.0 is sputtering somewhat:
>
> --------------
> In function ‘transformJsonFuncExpr’,
> inlined from ‘transformExprRecurse’ at parse_expr.c:374:13:
> parse_expr.c:4362:13: warning: ‘contextItemExpr’ may be used
> uninitialized [-Wmaybe-uninitialized]
> 4362 | if (exprType(contextItemExpr) != JSONBOID)
> | ^~~~~~~~~~~~~~~~~~~~~~~~~
> parse_expr.c: In function ‘transformExprRecurse’:
> parse_expr.c:4214:21: note: ‘contextItemExpr’ was declared here
> 4214 | Node *contextItemExpr;
> | ^~~~~~~~~~~~~~~
> nodeFuncs.c: In function ‘exprSetCollation’:
> nodeFuncs.c:1238:25: warning: this statement may fall through
> [-Wimplicit-fallthrough=]
> 1238 | {
> | ^
> nodeFuncs.c:1247:17: note: here
> 1247 | case T_JsonCoercion:
> | ^~~~
> --------------
>
> Those looks pretty unimportant, but I thought I'd let you know.
Oops, fixed in the attached. Thanks for checking.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
Вложения
0001 is quite mysterious to me. I've been reading it but I'm not sure I grok it, so I don't have anything too intelligent to say about it at this point. But here are my thoughts anyway. Assert()ing that a pointer is not null, and in the next line dereferencing that pointer, is useless: the process would crash anyway at the time of dereference, so the Assert() adds no value. Better to leave the assert out. (This appears both in ExecExprEnableErrorSafe and ExecExprDisableErrorSafe). Is it not a problem to set just the node type, and not reset the contents of the node to zeroes, in ExecExprEnableErrorSafe? I'm not sure if it's possible to enable error-safe on a node two times with an error reported in between; would that result in the escontext filled with junk the second time around? That might be dangerous. Maybe a simple cross-check is to verify (assert) in ExecExprEnableErrorSafe() that the struct is already all-zeroes, so that if this happens, we'll get reports about it. (After all, there are very few nodes that handle the SOFT_ERROR_OCCURRED case). Do we need to have the ->details_wanted flag turned on? Maybe if we're having ExecExprEnableErrorSafe() as a generic tool, it should receive the boolean to use as an argument. Why palloc the escontext always, and not just when ExecExprEnableErrorSafe is called? (At Disable time, just memset it to zero, and next time it is enabled for that node, we don't need to allocate it again, just set the nodetype.) ExecExprEnableErrorSafe() is a strange name for this operation. Maybe you mean ExecExprEnableSoftErrors()? Maybe it'd be better to leave it as NULL initially, so that for the majority of cases we don't even allocate it. In 0002 you're adding soft-error support for a bunch of existing operations, in addition to introducing SQL/JSON query functions. Maybe the soft-error stuff should be done separately in a preparatory patch. I think functions such as populate_array_element() that can now save soft errors and which currently do not have a return value, should acquire a convention to let caller know that things failed: maybe return false if SOFT_ERROR_OCCURRED(). Otherwise it appears that, for instance populate_array_dim_jsonb() can return happily if an error occurs when parsing the last element in the array. Splitting 0002 to have a preparatory patch where all such soft-error-saving changes are introduced separately would help review that this is indeed being handled by all their callers. -- Álvaro Herrera Breisgau, Deutschland — https://www.EnterpriseDB.com/ "Por suerte hoy explotó el califont porque si no me habría muerto de aburrido" (Papelucho)
On 06.09.23 17:01, Alvaro Herrera wrote: > Assert()ing that a pointer is not null, and in the next line > dereferencing that pointer, is useless: the process would crash anyway > at the time of dereference, so the Assert() adds no value. Better to > leave the assert out. I don't think this is quite correct. If you dereference a pointer, the compiler may assume that it is not null and rearrange code accordingly. So it might not crash. Keeping the assertion would alter that assumption.
Peter Eisentraut <peter@eisentraut.org> writes:
> On 06.09.23 17:01, Alvaro Herrera wrote:
>> Assert()ing that a pointer is not null, and in the next line
>> dereferencing that pointer, is useless: the process would crash anyway
>> at the time of dereference, so the Assert() adds no value. Better to
>> leave the assert out.
> I don't think this is quite correct. If you dereference a pointer, the
> compiler may assume that it is not null and rearrange code accordingly.
> So it might not crash. Keeping the assertion would alter that assumption.
Uh ... only in assert-enabled builds. If your claim is correct,
this'd result in different behavior in debug and production builds,
which would be even worse. But I don't believe the claim.
I side with Alvaro's position here: such an assert is unhelpful.
regards, tom lane
Thanks for the review. On Thu, Sep 7, 2023 at 12:01 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > 0001 is quite mysterious to me. I've been reading it but I'm not sure I > grok it, so I don't have anything too intelligent to say about it at > this point. But here are my thoughts anyway. > > Assert()ing that a pointer is not null, and in the next line > dereferencing that pointer, is useless: the process would crash anyway > at the time of dereference, so the Assert() adds no value. Better to > leave the assert out. (This appears both in ExecExprEnableErrorSafe and > ExecExprDisableErrorSafe). > > Is it not a problem to set just the node type, and not reset the > contents of the node to zeroes, in ExecExprEnableErrorSafe? I'm not > sure if it's possible to enable error-safe on a node two times with an > error reported in between; would that result in the escontext filled > with junk the second time around? That might be dangerous. Maybe a > simple cross-check is to verify (assert) in ExecExprEnableErrorSafe() > that the struct is already all-zeroes, so that if this happens, we'll > get reports about it. (After all, there are very few nodes that handle > the SOFT_ERROR_OCCURRED case). > > Do we need to have the ->details_wanted flag turned on? Maybe if we're > having ExecExprEnableErrorSafe() as a generic tool, it should receive > the boolean to use as an argument. > > Why palloc the escontext always, and not just when > ExecExprEnableErrorSafe is called? (At Disable time, just memset it to > zero, and next time it is enabled for that node, we don't need to > allocate it again, just set the nodetype.) > > ExecExprEnableErrorSafe() is a strange name for this operation. Maybe > you mean ExecExprEnableSoftErrors()? Maybe it'd be better to leave it > as NULL initially, so that for the majority of cases we don't even > allocate it. I should have clarified earlier why the ErrorSaveContext must be allocated statically during the expression compilation phase. This is necessary because llvm_compile_expr() requires a valid pointer to the ErrorSaveContext to integrate into the compiled version. Thus, runtime allocation isn't feasible. After some consideration, I believe we shouldn't introduce the generic ExecExprEnable/Disable* interface. Instead, we should let individual expressions manage the ErrorSaveContext that they want to use directly, using ExprState.escontext just as a temporary global variable, much like ExprState.innermost_caseval is used. The revised 0001 now only contains the changes necessary to make CoerceViaIO evaluation code support soft error handling. > In 0002 you're adding soft-error support for a bunch of existing > operations, in addition to introducing SQL/JSON query functions. Maybe > the soft-error stuff should be done separately in a preparatory patch. Hmm, there'd be only 1 ExecExprEnableErrorSafe() in 0002 -- that in ExecEvalJsonExprCoercion(). I'm not sure which others you're referring to. Given what I said above, the code to reset the ErrorSaveContext present in 0002 now looks different. It now resets the error_occurred flag directly instead of using memset-0-ing the whole struct. details_wanted and error_data are both supposed to be NULL in this case anyway and remain set to NULL throughout the lifetime of the ExprState. > I think functions such as populate_array_element() that can now save > soft errors and which currently do not have a return value, should > acquire a convention to let caller know that things failed: maybe return > false if SOFT_ERROR_OCCURRED(). Otherwise it appears that, for instance > populate_array_dim_jsonb() can return happily if an error occurs when > parsing the last element in the array. Splitting 0002 to have a > preparatory patch where all such soft-error-saving changes are > introduced separately would help review that this is indeed being > handled by all their callers. I've separated the changes to jsonfuncs.c into an independent patch. Upon reviewing the code accessible from populate_record_field() -- which serves as the entry point for the executor via json_populate_type() -- I identified a few more instances where errors could be thrown even with a non-NULL escontext. I've included tests for these in patch 0003. While some error reports, like those in construct_md_array() (invoked by populate_array()), fall outside jsonfuncs.c, I assume they're deliberately excluded from SQL/JSON's ON ERROR support. I've opted not to modify any external interfaces. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
Op 9/14/23 om 10:14 schreef Amit Langote:
>
>
Hi Amit,
Just now I built a v14-patched server and I found this crash:
select json_query(jsonb '
{
"arr": [
{"arr": [2,3]}
, {"arr": [4,5]}
]
}'
, '$.arr[*].arr ? (@ <= 3)' returning anyarray WITH WRAPPER) --crash
;
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
connection to server was lost
Can you have a look?
Thanks,
Erik
On Sun, Sep 17, 2023 at 3:34 PM Erik Rijkers <er@xs4all.nl> wrote:
> Op 9/14/23 om 10:14 schreef Amit Langote:
> >
> >
>
> Hi Amit,
>
> Just now I built a v14-patched server and I found this crash:
>
> select json_query(jsonb '
> {
> "arr": [
> {"arr": [2,3]}
> , {"arr": [4,5]}
> ]
> }'
> , '$.arr[*].arr ? (@ <= 3)' returning anyarray WITH WRAPPER) --crash
> ;
> server closed the connection unexpectedly
> This probably means the server terminated abnormally
> before or while processing the request.
> connection to server was lost
Thanks for the report.
Attached updated version fixes the crash, but you get an error as is
to be expected:
select json_query(jsonb '
{
"arr": [
{"arr": [2,3]}
, {"arr": [4,5]}
]
}'
, '$.arr[*].arr ? (@ <= 3)' returning anyarray WITH WRAPPER);
ERROR: cannot accept a value of type anyarray
unlike when using int[]:
select json_query(jsonb '
{
"arr": [
{"arr": [2,3]}
, {"arr": [4,5]}
]
}'
, '$.arr[*].arr ? (@ <= 3)' returning int[] WITH WRAPPER);
json_query
------------
{2,3}
(1 row)
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
Вложения
Op 9/18/23 om 05:15 schreef Amit Langote:
> On Sun, Sep 17, 2023 at 3:34 PM Erik Rijkers <er@xs4all.nl> wrote:
>> Op 9/14/23 om 10:14 schreef Amit Langote:
>>>
>>>
>>
>> Hi Amit,
>>
>> Just now I built a v14-patched server and I found this crash:
>>
>> select json_query(jsonb '
>> {
>> "arr": [
>> {"arr": [2,3]}
>> , {"arr": [4,5]}
>> ]
>> }'
>> , '$.arr[*].arr ? (@ <= 3)' returning anyarray WITH WRAPPER) --crash
>> ;
>> server closed the connection unexpectedly
>> This probably means the server terminated abnormally
>> before or while processing the request.
>> connection to server was lost
>
> Thanks for the report.
>
> Attached updated version fixes the crash, but you get an error as is
> to be expected:
>
> select json_query(jsonb '
> {
> "arr": [
> {"arr": [2,3]}
> , {"arr": [4,5]}
> ]
> }'
> , '$.arr[*].arr ? (@ <= 3)' returning anyarray WITH WRAPPER);
> ERROR: cannot accept a value of type anyarray
>
> unlike when using int[]:
>
> select json_query(jsonb '
> {
> "arr": [
> {"arr": [2,3]}
> , {"arr": [4,5]}
> ]
> }'
> , '$.arr[*].arr ? (@ <= 3)' returning int[] WITH WRAPPER);
> json_query
> ------------
> {2,3}
> (1 row)
>
Thanks, Amit. Alas, there are more: for 'anyarray' I thought I'd
substitute 'interval', 'int4range', 'int8range', and sure enough they
all give similar crashes. Patched with v15:
psql -qX -e << SQL
select json_query(jsonb'{"a":[{"a":[2,3]},{"a":[4,5]}]}',
'$.a[*].a?(@<=3)'returning int[] with wrapper --ok
);
select json_query(jsonb'{"a": [{"a": [2,3]}, {"a": [4,5]}]}',
'$.a[*].a?(@<=3)'returning interval with wrapper --crash
--'$.a[*].a?(@<=3)'returning int4range with wrapper --crash
--'$.a[*].a?(@<=3)'returning int8range with wrapper --crash
--'$.a[*].a?(@<=3)'returning numeric[] with wrapper --{2,3} =ok
--'$.a[*].a?(@<=3)'returning anyarray with wrapper --fixed
--'$.a[*].a?(@<=3)'returning anyarray --null =ok
--'$.a[*].a?(@<=3)'returning int --null =ok
--'$.a[*].a?(@<=3)'returning int with wrapper --error =ok
--'$.a[*].a?(@<=3)'returning int[] with wrapper -- {2,3} =ok
);
SQL
=> server closed the connection unexpectedly, etc
Because those first three tries gave a crash (*all three*), I'm a bit
worried there may be many more.
I am sorry to be bothering you with these somewhat idiotic SQL
statements but I suppose somehow it needs to be made more solid.
Thanks!
Erik
Hi Erik,
On Mon, Sep 18, 2023 at 19:09 Erik Rijkers <er@xs4all.nl> wrote:
Op 9/18/23 om 05:15 schreef Amit Langote:
> On Sun, Sep 17, 2023 at 3:34 PM Erik Rijkers <er@xs4all.nl> wrote:
>> Op 9/14/23 om 10:14 schreef Amit Langote:
>>>
>>>
>>
>> Hi Amit,
>>
>> Just now I built a v14-patched server and I found this crash:
>>
>> select json_query(jsonb '
>> {
>> "arr": [
>> {"arr": [2,3]}
>> , {"arr": [4,5]}
>> ]
>> }'
>> , '$.arr[*].arr ? (@ <= 3)' returning anyarray WITH WRAPPER) --crash
>> ;
>> server closed the connection unexpectedly
>> This probably means the server terminated abnormally
>> before or while processing the request.
>> connection to server was lost
>
> Thanks for the report.
>
> Attached updated version fixes the crash, but you get an error as is
> to be expected:
>
> select json_query(jsonb '
> {
> "arr": [
> {"arr": [2,3]}
> , {"arr": [4,5]}
> ]
> }'
> , '$.arr[*].arr ? (@ <= 3)' returning anyarray WITH WRAPPER);
> ERROR: cannot accept a value of type anyarray
>
> unlike when using int[]:
>
> select json_query(jsonb '
> {
> "arr": [
> {"arr": [2,3]}
> , {"arr": [4,5]}
> ]
> }'
> , '$.arr[*].arr ? (@ <= 3)' returning int[] WITH WRAPPER);
> json_query
> ------------
> {2,3}
> (1 row)
>
Thanks, Amit. Alas, there are more: for 'anyarray' I thought I'd
substitute 'interval', 'int4range', 'int8range', and sure enough they
all give similar crashes. Patched with v15:
psql -qX -e << SQL
select json_query(jsonb'{"a":[{"a":[2,3]},{"a":[4,5]}]}',
'$.a[*].a?(@<=3)'returning int[] with wrapper --ok
);
select json_query(jsonb'{"a": [{"a": [2,3]}, {"a": [4,5]}]}',
'$.a[*].a?(@<=3)'returning interval with wrapper --crash
--'$.a[*].a?(@<=3)'returning int4range with wrapper --crash
--'$.a[*].a?(@<=3)'returning int8range with wrapper --crash
--'$.a[*].a?(@<=3)'returning numeric[] with wrapper --{2,3} =ok
--'$.a[*].a?(@<=3)'returning anyarray with wrapper --fixed
--'$.a[*].a?(@<=3)'returning anyarray --null =ok
--'$.a[*].a?(@<=3)'returning int --null =ok
--'$.a[*].a?(@<=3)'returning int with wrapper --error =ok
--'$.a[*].a?(@<=3)'returning int[] with wrapper -- {2,3} =ok
);
SQL
=> server closed the connection unexpectedly, etc
Because those first three tries gave a crash (*all three*), I'm a bit
worried there may be many more.
I am sorry to be bothering you with these somewhat idiotic SQL
statements but I suppose somehow it needs to be made more solid.
No, thanks for your testing. I’ll look into these.
Op 9/18/23 om 12:20 schreef Amit Langote:
> Hi Erik,
>
>> I am sorry to be bothering you with these somewhat idiotic SQL
>> statements but I suppose somehow it needs to be made more solid.
>
For 60 datatypes, I ran this statement:
select json_query(jsonb'{"a":[{"a":[2,3]},{"a":[4,5]}]}',
'$.a[*].a?(@<=3)'returning ${datatype} with wrapper
);
against a 17devel server (a0a5) with json v15 patches and caught the
output, incl. 30+ crashes, in the attached .txt. I hope that's useful.
Erik
Вложения
Op 9/18/23 om 13:14 schreef Erik Rijkers:
> Op 9/18/23 om 12:20 schreef Amit Langote:
>> Hi Erik,
>>
>>> I am sorry to be bothering you with these somewhat idiotic SQL
>>> statements but I suppose somehow it needs to be made more solid.
>>
>
> For 60 datatypes, I ran this statement:
>
> select json_query(jsonb'{"a":[{"a":[2,3]},{"a":[4,5]}]}',
> '$.a[*].a?(@<=3)'returning ${datatype} with wrapper
> );
>
> against a 17devel server (a0a5) with json v15 patches and caught the
> output, incl. 30+ crashes, in the attached .txt. I hope that's useful.
>
and FYI: None of these crashes occur when I leave off the 'WITH WRAPPER'
clause.
>
> Erik
>
0001: I wonder why you used Node for the ErrorSaveContext pointer instead of the specific struct you want. I propose the attached, for some extra type-safety. Or did you have a reason to do it that way? -- Álvaro Herrera Breisgau, Deutschland — https://www.EnterpriseDB.com/ "How amazing is that? I call it a night and come back to find that a bug has been identified and patched while I sleep." (Robert Davidson) http://archives.postgresql.org/pgsql-sql/2006-03/msg00378.php
Вложения
On Mon, Sep 18, 2023 at 7:51 PM Erik Rijkers <er@xs4all.nl> wrote:
>
> and FYI: None of these crashes occur when I leave off the 'WITH WRAPPER'
> clause.
>
> >
> > Erik
> >
if specify with wrapper, then default behavior is keep quotes, so
jexpr->omit_quotes will be false, which make val_string NULL.
in ExecEvalJsonExprCoercion: InputFunctionCallSafe, val_string is
NULL, flinfo->fn_strict is true, it will return: *op->resvalue =
(Datum) 0. but at the same time *op->resnull is still false!
if not specify with wrapper, then JsonPathQuery will return NULL.
(because after apply the path_expression, cannot multiple SQL/JSON
items)
select json_query(jsonb'{"a":[{"a":3},{"a":[4,5]}]}','$.a[*].a?(@<=3)'
returning int4range);
also make server crash, because default is KEEP QUOTES, so in
ExecEvalJsonExprCoercion jexpr->omit_quotes will be false.
val_string will be NULL again as mentioned above.
another funny case:
create domain domain_int4range int4range;
select json_query(jsonb'{"a":[{"a":[2,3]},{"a":[4,5]}]}','$.a[*].a?(@<=3)'
returning domain_int4range with wrapper);
should I expect it to return [2,4) ?
-------------------
https://www.postgresql.org/docs/current/extend-type-system.html#EXTEND-TYPES-POLYMORPHIC
>> When the return value of a function is declared as a polymorphic type, there must be at least one argument position
thatis also
>> polymorphic, and the actual data type(s) supplied for the polymorphic arguments determine the actual result type for
thatcall.
select json_query(jsonb'{"a":[{"a":[2,3]},{"a":[4,5]}]}','$.a[*].a?(@<=3)'
returning anyrange);
should fail. Now it returns NULL. Maybe we can validate it in
transformJsonFuncExpr?
-------------------
On Tue, Sep 19, 2023 at 7:18 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > 0001: I wonder why you used Node for the ErrorSaveContext pointer > instead of the specific struct you want. I propose the attached, for > some extra type-safety. Or did you have a reason to do it that way? No reason other than that most other headers use Node. I agree that making an exception for this patch might be better, so I've incorporated your patch into 0001. I've also updated the query functions patch (0003) to address the crashing bug reported by Erik. Essentially, I made the coercion step of JSON_QUERY to always use json_populate_type() when WITH WRAPPER is used. You might get funny errors with ERROR OR ERROR for many types when used in RETURNING, but at least there should no longer be any crashes. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
On Tue, Sep 19, 2023 at 7:37 PM jian he <jian.universality@gmail.com> wrote:
> On Mon, Sep 18, 2023 at 7:51 PM Erik Rijkers <er@xs4all.nl> wrote:
> >
> > and FYI: None of these crashes occur when I leave off the 'WITH WRAPPER'
> > clause.
> >
> > >
> > > Erik
> > >
>
> if specify with wrapper, then default behavior is keep quotes, so
> jexpr->omit_quotes will be false, which make val_string NULL.
> in ExecEvalJsonExprCoercion: InputFunctionCallSafe, val_string is
> NULL, flinfo->fn_strict is true, it will return: *op->resvalue =
> (Datum) 0. but at the same time *op->resnull is still false!
>
> if not specify with wrapper, then JsonPathQuery will return NULL.
> (because after apply the path_expression, cannot multiple SQL/JSON
> items)
>
> select json_query(jsonb'{"a":[{"a":3},{"a":[4,5]}]}','$.a[*].a?(@<=3)'
> returning int4range);
> also make server crash, because default is KEEP QUOTES, so in
> ExecEvalJsonExprCoercion jexpr->omit_quotes will be false.
> val_string will be NULL again as mentioned above.
That's right.
> another funny case:
> create domain domain_int4range int4range;
> select json_query(jsonb'{"a":[{"a":[2,3]},{"a":[4,5]}]}','$.a[*].a?(@<=3)'
> returning domain_int4range with wrapper);
>
> should I expect it to return [2,4) ?
This is what you'll get with v16 that I just posted.
> -------------------
> https://www.postgresql.org/docs/current/extend-type-system.html#EXTEND-TYPES-POLYMORPHIC
> >> When the return value of a function is declared as a polymorphic type, there must be at least one argument
positionthat is also
> >> polymorphic, and the actual data type(s) supplied for the polymorphic arguments determine the actual result type
forthat call.
>
> select json_query(jsonb'{"a":[{"a":[2,3]},{"a":[4,5]}]}','$.a[*].a?(@<=3)'
> returning anyrange);
> should fail. Now it returns NULL. Maybe we can validate it in
> transformJsonFuncExpr?
> -------------------
I'm not sure whether we should make the parser complain about the
weird types being specified in RETURNING. The NULL you get in the
above example is because of the following error:
select json_query(jsonb'{"a":[{"a":[2,3]},{"a":[4,5]}]}','$.a[*].a?(@<=3)'
returning anyrange error on error);
ERROR: JSON path expression in JSON_QUERY should return singleton
item without wrapper
HINT: Use WITH WRAPPER clause to wrap SQL/JSON item sequence into array.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
Op 9/19/23 om 13:56 schreef Amit Langote:
> On Tue, Sep 19, 2023 at 7:18 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote:
>> 0001: I wonder why you used Node for the ErrorSaveContext pointer
>> instead of the specific struct you want. I propose the attached, for
>> some extra type-safety. Or did you have a reason to do it that way?
>
> No reason other than that most other headers use Node. I agree that
> making an exception for this patch might be better, so I've
> incorporated your patch into 0001.
>
> I've also updated the query functions patch (0003) to address the
> crashing bug reported by Erik. Essentially, I made the coercion step
> of JSON_QUERY to always use json_populate_type() when WITH WRAPPER is
> used. You might get funny errors with ERROR OR ERROR for many types
> when used in RETURNING, but at least there should no longer be any
> crashes.
>
Indeed, with v16 those crashes are gone.
Some lesser evil: gcc 13.2.0 gave some warnings, slightly different in
assert vs non-assert build.
--- assert build:
-- [2023.09.19 14:06:35 json_table2/0] make core: make --quiet -j 4
In file included from ../../../src/include/postgres.h:45,
from parse_expr.c:16:
In function ‘transformJsonFuncExpr’,
inlined from ‘transformExprRecurse’ at parse_expr.c:374:13:
parse_expr.c:4355:22: warning: ‘jsexpr’ may be used uninitialized
[-Wmaybe-uninitialized]
4355 | Assert(jsexpr->formatted_expr);
../../../src/include/c.h:864:23: note: in definition of macro ‘Assert’
864 | if (!(condition)) \
| ^~~~~~~~~
parse_expr.c: In function ‘transformExprRecurse’:
parse_expr.c:4212:21: note: ‘jsexpr’ was declared here
4212 | JsonExpr *jsexpr;
| ^~~~~~
--- non-assert build:
-- [2023.09.19 14:11:03 json_table2/1] make core: make --quiet -j 4
In function ‘transformJsonFuncExpr’,
inlined from ‘transformExprRecurse’ at parse_expr.c:374:13:
parse_expr.c:4356:28: warning: ‘jsexpr’ may be used uninitialized
[-Wmaybe-uninitialized]
4356 | if (exprType(jsexpr->formatted_expr) != JSONBOID)
| ~~~~~~^~~~~~~~~~~~~~~~
parse_expr.c: In function ‘transformExprRecurse’:
parse_expr.c:4212:21: note: ‘jsexpr’ was declared here
4212 | JsonExpr *jsexpr;
| ^~~~~~
Thank you,
Erik
On Tue, Sep 19, 2023 at 9:31 PM Erik Rijkers <er@xs4all.nl> wrote: > Op 9/19/23 om 13:56 schreef Amit Langote: > > On Tue, Sep 19, 2023 at 7:18 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > >> 0001: I wonder why you used Node for the ErrorSaveContext pointer > >> instead of the specific struct you want. I propose the attached, for > >> some extra type-safety. Or did you have a reason to do it that way? > > > > No reason other than that most other headers use Node. I agree that > > making an exception for this patch might be better, so I've > > incorporated your patch into 0001. > > > > I've also updated the query functions patch (0003) to address the > > crashing bug reported by Erik. Essentially, I made the coercion step > > of JSON_QUERY to always use json_populate_type() when WITH WRAPPER is > > used. You might get funny errors with ERROR OR ERROR for many types > > when used in RETURNING, but at least there should no longer be any > > crashes. > > > > Indeed, with v16 those crashes are gone. > > Some lesser evil: gcc 13.2.0 gave some warnings, slightly different in > assert vs non-assert build. > > --- assert build: > > -- [2023.09.19 14:06:35 json_table2/0] make core: make --quiet -j 4 > In file included from ../../../src/include/postgres.h:45, > from parse_expr.c:16: > In function ‘transformJsonFuncExpr’, > inlined from ‘transformExprRecurse’ at parse_expr.c:374:13: > parse_expr.c:4355:22: warning: ‘jsexpr’ may be used uninitialized > [-Wmaybe-uninitialized] > 4355 | Assert(jsexpr->formatted_expr); > ../../../src/include/c.h:864:23: note: in definition of macro ‘Assert’ > 864 | if (!(condition)) \ > | ^~~~~~~~~ > parse_expr.c: In function ‘transformExprRecurse’: > parse_expr.c:4212:21: note: ‘jsexpr’ was declared here > 4212 | JsonExpr *jsexpr; > | ^~~~~~ > > > --- non-assert build: > > -- [2023.09.19 14:11:03 json_table2/1] make core: make --quiet -j 4 > In function ‘transformJsonFuncExpr’, > inlined from ‘transformExprRecurse’ at parse_expr.c:374:13: > parse_expr.c:4356:28: warning: ‘jsexpr’ may be used uninitialized > [-Wmaybe-uninitialized] > 4356 | if (exprType(jsexpr->formatted_expr) != JSONBOID) > | ~~~~~~^~~~~~~~~~~~~~~~ > parse_expr.c: In function ‘transformExprRecurse’: > parse_expr.c:4212:21: note: ‘jsexpr’ was declared here > 4212 | JsonExpr *jsexpr; > | ^~~~~~ Thanks, fixed. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
On Tue, Sep 19, 2023 at 9:00 PM Amit Langote <amitlangote09@gmail.com> wrote: > On Tue, Sep 19, 2023 at 7:37 PM jian he <jian.universality@gmail.com> wrote: > > ------------------- > > https://www.postgresql.org/docs/current/extend-type-system.html#EXTEND-TYPES-POLYMORPHIC > > >> When the return value of a function is declared as a polymorphic type, there must be at least one argument positionthat is also > > >> polymorphic, and the actual data type(s) supplied for the polymorphic arguments determine the actual result type forthat call. > > > > select json_query(jsonb'{"a":[{"a":[2,3]},{"a":[4,5]}]}','$.a[*].a?(@<=3)' > > returning anyrange); > > should fail. Now it returns NULL. Maybe we can validate it in > > transformJsonFuncExpr? > > ------------------- > > I'm not sure whether we should make the parser complain about the > weird types being specified in RETURNING. Sleeping over this, maybe adding the following to transformJsonOutput() does make sense? + if (get_typtype(ret->typid) == TYPTYPE_PSEUDO) + ereport(ERROR, + errcode(ERRCODE_FEATURE_NOT_SUPPORTED), + errmsg("returning pseudo-types is not supported in SQL/JSON functions")); + -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
On 2023-09-19 Tu 23:07, Amit Langote wrote:
On Tue, Sep 19, 2023 at 9:00 PM Amit Langote <amitlangote09@gmail.com> wrote:On Tue, Sep 19, 2023 at 7:37 PM jian he <jian.universality@gmail.com> wrote:------------------- https://www.postgresql.org/docs/current/extend-type-system.html#EXTEND-TYPES-POLYMORPHICWhen the return value of a function is declared as a polymorphic type, there must be at least one argument position that is also polymorphic, and the actual data type(s) supplied for the polymorphic arguments determine the actual result type for that call.select json_query(jsonb'{"a":[{"a":[2,3]},{"a":[4,5]}]}','$.a[*].a?(@<=3)' returning anyrange); should fail. Now it returns NULL. Maybe we can validate it in transformJsonFuncExpr? -------------------I'm not sure whether we should make the parser complain about the weird types being specified in RETURNING.Sleeping over this, maybe adding the following to transformJsonOutput() does make sense? + if (get_typtype(ret->typid) == TYPTYPE_PSEUDO) + ereport(ERROR, + errcode(ERRCODE_FEATURE_NOT_SUPPORTED), + errmsg("returning pseudo-types is not supported in SQL/JSON functions")); +
Seems reasonable.
cheers
andrew
-- Andrew Dunstan EDB: https://www.enterprisedb.com
On Thu, Sep 21, 2023 at 4:14 AM Andrew Dunstan <andrew@dunslane.net> wrote: > On 2023-09-19 Tu 23:07, Amit Langote wrote: > On Tue, Sep 19, 2023 at 9:00 PM Amit Langote <amitlangote09@gmail.com> wrote: > On Tue, Sep 19, 2023 at 7:37 PM jian he <jian.universality@gmail.com> wrote: > > ------------------- > https://www.postgresql.org/docs/current/extend-type-system.html#EXTEND-TYPES-POLYMORPHIC > > When the return value of a function is declared as a polymorphic type, there must be at least one argument position thatis also > polymorphic, and the actual data type(s) supplied for the polymorphic arguments determine the actual result type for thatcall. > > select json_query(jsonb'{"a":[{"a":[2,3]},{"a":[4,5]}]}','$.a[*].a?(@<=3)' > returning anyrange); > should fail. Now it returns NULL. Maybe we can validate it in > transformJsonFuncExpr? > ------------------- > > I'm not sure whether we should make the parser complain about the > weird types being specified in RETURNING. > > Sleeping over this, maybe adding the following to > transformJsonOutput() does make sense? > > + if (get_typtype(ret->typid) == TYPTYPE_PSEUDO) > + ereport(ERROR, > + errcode(ERRCODE_FEATURE_NOT_SUPPORTED), > + errmsg("returning pseudo-types is not supported in > SQL/JSON functions")); > + > > Seems reasonable. OK, thanks for confirming. Here is a set where I've included the above change in 0003. I had some doubts about the following bit in 0001 but I've come to know through some googling that LLVM handles this alright: +/* + * Emit constant oid. + */ +static inline LLVMValueRef +l_oid_const(Oid i) +{ + return LLVMConstInt(LLVMInt32Type(), i, false); +} + The doubt I had was whether the Oid that l_oid_const() takes, which is an unsigned int, might overflow the integer that LLVM provides through LLVMConstInt() here. Apparently, LLVM IR always uses the full 32-bit width to store the integer value, so there's no worry of the overflow if I'm understanding this correctly. Patches 0001 and 0002 look ready to me to go in. Please let me know if anyone thinks otherwise. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
I keep looking at 0001, and in the struct definition I think putting the
escontext at the bottom is not great, because there's a comment a few
lines above that says "XXX: following fields only needed during
"compilation"), could be thrown away afterwards". This comment is not
strictly true, because innermost_caseval is actually used by
array_map(); yet it seems that ->escontext should appear before that
comment.
However, if you put it before steps_len, it would push members steps_len
and steps_alloc beyond the struct's first cache line(*). If those
struct members are critical for expression init performance, then maybe
it's not a good tradeoff. I don't know if this was struct laid out
carefully with that consideration in mind or not.
Also, ->escontext's own comment in ExprState seems to be saying too much
and not saying enough. I would reword it as "For expression nodes that
support soft errors. NULL if caller wants them thrown instead". The
shortest I could make so that it fits in a single is "For nodes that can
error softly. NULL if caller wants them thrown", or "For
soft-error-enabled nodes. NULL if caller wants errors thrown". Not
sure if those are good enough, or just make the comment the whole four
lines ...
(*) This is what pahole says about the struct as 0001 would put it:
struct ExprState {
NodeTag type; /* 0 4 */
uint8 flags; /* 4 1 */
_Bool resnull; /* 5 1 */
/* XXX 2 bytes hole, try to pack */
Datum resvalue; /* 8 8 */
TupleTableSlot * resultslot; /* 16 8 */
struct ExprEvalStep * steps; /* 24 8 */
ExprStateEvalFunc evalfunc; /* 32 8 */
Expr * expr; /* 40 8 */
void * evalfunc_private; /* 48 8 */
int steps_len; /* 56 4 */
int steps_alloc; /* 60 4 */
/* --- cacheline 1 boundary (64 bytes) --- */
struct PlanState * parent; /* 64 8 */
ParamListInfo ext_params; /* 72 8 */
Datum * innermost_caseval; /* 80 8 */
_Bool * innermost_casenull; /* 88 8 */
Datum * innermost_domainval; /* 96 8 */
_Bool * innermost_domainnull; /* 104 8 */
ErrorSaveContext * escontext; /* 112 8 */
/* size: 120, cachelines: 2, members: 18 */
/* sum members: 118, holes: 1, sum holes: 2 */
/* last cacheline: 56 bytes */
};
--
Álvaro Herrera Breisgau, Deutschland — https://www.EnterpriseDB.com/
"Nunca se desea ardientemente lo que solo se desea por razón" (F. Alexandre)
On Thu, Sep 21, 2023 at 5:58 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > I keep looking at 0001, and in the struct definition I think putting the > escontext at the bottom is not great, because there's a comment a few > lines above that says "XXX: following fields only needed during > "compilation"), could be thrown away afterwards". This comment is not > strictly true, because innermost_caseval is actually used by > array_map(); yet it seems that ->escontext should appear before that > comment. Hmm. Actually, we can make it so that *escontext* is only needed during ExecInitExprRec() and never after that. I've done that in the attached updated patch, where you can see that ExprState.escontext is only ever touched in execExpr.c. Also, I noticed that I had forgotten to extract one more expression node type's conversion to use soft errors from the main patch (0003). That is CoerceToDomain, which I've now moved into 0001. > Also, ->escontext's own comment in ExprState seems to be saying too much > and not saying enough. I would reword it as "For expression nodes that > support soft errors. NULL if caller wants them thrown instead". The > shortest I could make so that it fits in a single is "For nodes that can > error softly. NULL if caller wants them thrown", or "For > soft-error-enabled nodes. NULL if caller wants errors thrown". Not > sure if those are good enough, or just make the comment the whole four > lines ... How about: + /* + * For expression nodes that support soft errors. Set to NULL before + * calling ExecInitExprRec() if the caller wants errors thrown. + */ -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
On Thu, Sep 21, 2023 at 9:41 PM Amit Langote <amitlangote09@gmail.com> wrote: > On Thu, Sep 21, 2023 at 5:58 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > I keep looking at 0001, and in the struct definition I think putting the > > escontext at the bottom is not great, because there's a comment a few > > lines above that says "XXX: following fields only needed during > > "compilation"), could be thrown away afterwards". This comment is not > > strictly true, because innermost_caseval is actually used by > > array_map(); yet it seems that ->escontext should appear before that > > comment. > > Hmm. Actually, we can make it so that *escontext* is only needed > during ExecInitExprRec() and never after that. I've done that in the > attached updated patch, where you can see that ExprState.escontext is > only ever touched in execExpr.c. Also, I noticed that I had > forgotten to extract one more expression node type's conversion to use > soft errors from the main patch (0003). That is CoerceToDomain, which > I've now moved into 0001. > > > Also, ->escontext's own comment in ExprState seems to be saying too much > > and not saying enough. I would reword it as "For expression nodes that > > support soft errors. NULL if caller wants them thrown instead". The > > shortest I could make so that it fits in a single is "For nodes that can > > error softly. NULL if caller wants them thrown", or "For > > soft-error-enabled nodes. NULL if caller wants errors thrown". Not > > sure if those are good enough, or just make the comment the whole four > > lines ... > > How about: > > + /* > + * For expression nodes that support soft errors. Set to NULL before > + * calling ExecInitExprRec() if the caller wants errors thrown. > + */ Maybe the following is better: + /* + * For expression nodes that support soft errors. Should be set to NULL + * before calling ExecInitExprRec() if the caller wants errors thrown. + */ ...as in the attached. Alvaro, do you think your concern regarding escontext not being in the right spot in the ExprState struct is addressed? It doesn't seem very critical to me to place it in the struct's 1st cacheline, because escontext is not accessed in performance critical paths such as during expression evaluation, especially with the latest version. (It would get accessed during evaluation with previous versions.) If so, I'd like to move ahead with committing it. 0002 seems almost there too. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
Op 9/27/23 om 15:55 schreef Amit Langote: > On Thu, Sep 21, 2023 at 9:41 PM Amit Langote <amitlangote09@gmail.com> wrote: I don't knoe, maybe it's worthwhile to fix this (admittedly trivial) fail in the tests? It's been there for a while. Thanks, Erik
Вложения
On Wed, Sep 27, 2023 at 11:21 PM Erik Rijkers <er@xs4all.nl> wrote: > Op 9/27/23 om 15:55 schreef Amit Langote: > > On Thu, Sep 21, 2023 at 9:41 PM Amit Langote <amitlangote09@gmail.com> wrote: > > I don't knoe, maybe it's worthwhile to fix this (admittedly trivial) > fail in the tests? It's been there for a while. Thanks, fixed. Patches also needed to be rebased over some llvm changes that got in yesterday. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
On 2023-Sep-27, Amit Langote wrote: > Maybe the following is better: > > + /* > + * For expression nodes that support soft errors. Should be set to NULL > + * before calling ExecInitExprRec() if the caller wants errors thrown. > + */ > > ...as in the attached. That's good. > Alvaro, do you think your concern regarding escontext not being in the > right spot in the ExprState struct is addressed? It doesn't seem very > critical to me to place it in the struct's 1st cacheline, because > escontext is not accessed in performance critical paths such as during > expression evaluation, especially with the latest version. (It would > get accessed during evaluation with previous versions.) > > If so, I'd like to move ahead with committing it. Yeah, looks OK to me in v21. -- Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/
On Thu, Sep 28, 2023 at 8:04 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > On 2023-Sep-27, Amit Langote wrote: > > Maybe the following is better: > > > > + /* > > + * For expression nodes that support soft errors. Should be set to NULL > > + * before calling ExecInitExprRec() if the caller wants errors thrown. > > + */ > > > > ...as in the attached. > > That's good. > > > Alvaro, do you think your concern regarding escontext not being in the > > right spot in the ExprState struct is addressed? It doesn't seem very > > critical to me to place it in the struct's 1st cacheline, because > > escontext is not accessed in performance critical paths such as during > > expression evaluation, especially with the latest version. (It would > > get accessed during evaluation with previous versions.) > > > > If so, I'd like to move ahead with committing it. > > Yeah, looks OK to me in v21. Thanks. I will push the attached 0001 shortly. Also, I've updated 0002's commit message to mention why it only changes the functions local to jsonfuncs.c to add the Node *escontext parameter, but not any external ones that may be invoked, such as, makeMdArrayResult(). The assumption behind that is that jsonfuncs.c functions validate any data that they pass to such external functions, so no *suppressible* errors should occur. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
On Fri, Sep 29, 2023 at 1:57 PM Amit Langote <amitlangote09@gmail.com> wrote:
> On Thu, Sep 28, 2023 at 8:04 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote:
> > On 2023-Sep-27, Amit Langote wrote:
> > > Maybe the following is better:
> > >
> > > + /*
> > > + * For expression nodes that support soft errors. Should be set to NULL
> > > + * before calling ExecInitExprRec() if the caller wants errors thrown.
> > > + */
> > >
> > > ...as in the attached.
> >
> > That's good.
> >
> > > Alvaro, do you think your concern regarding escontext not being in the
> > > right spot in the ExprState struct is addressed? It doesn't seem very
> > > critical to me to place it in the struct's 1st cacheline, because
> > > escontext is not accessed in performance critical paths such as during
> > > expression evaluation, especially with the latest version. (It would
> > > get accessed during evaluation with previous versions.)
> > >
> > > If so, I'd like to move ahead with committing it.
> >
> > Yeah, looks OK to me in v21.
>
> Thanks. I will push the attached 0001 shortly.
Pushed this 30 min ago (no email on -committers yet!) and am looking
at the following llvm crash reported by buildfarm animal pogona [1]:
#0 __pthread_kill_implementation (threadid=<optimized out>,
signo=signo@entry=6, no_tid=no_tid@entry=0) at
./nptl/pthread_kill.c:44
44 ./nptl/pthread_kill.c: No such file or directory.
#0 __pthread_kill_implementation (threadid=<optimized out>,
signo=signo@entry=6, no_tid=no_tid@entry=0) at
./nptl/pthread_kill.c:44
#1 0x00007f5bcebcb15f in __pthread_kill_internal (signo=6,
threadid=<optimized out>) at ./nptl/pthread_kill.c:78
#2 0x00007f5bceb7d472 in __GI_raise (sig=sig@entry=6) at
../sysdeps/posix/raise.c:26
#3 0x00007f5bceb674b2 in __GI_abort () at ./stdlib/abort.c:79
#4 0x00007f5bceb673d5 in __assert_fail_base (fmt=0x7f5bcecdbdc8
"%s%s%s:%u: %s%sAssertion `%s' failed.\\n%n",
assertion=assertion@entry=0x7f5bc1336419 "(i >= FTy->getNumParams() ||
FTy->getParamType(i) == Args[i]->getType()) && \\"Calling a function
with a bad signature!\\"", file=file@entry=0x7f5bc1336051
"/home/bf/src/llvm-project-5/llvm/lib/IR/Instructions.cpp",
line=line@entry=299, function=function@entry=0x7f5bc13362af "void
llvm::CallInst::init(llvm::FunctionType *, llvm::Value *,
ArrayRef<llvm::Value *>, ArrayRef<llvm::OperandBundleDef>, const
llvm::Twine &)") at ./assert/assert.c:92
#5 0x00007f5bceb763a2 in __assert_fail (assertion=0x7f5bc1336419 "(i
>= FTy->getNumParams() || FTy->getParamType(i) == Args[i]->getType())
&& \\"Calling a function with a bad signature!\\"",
file=0x7f5bc1336051
"/home/bf/src/llvm-project-5/llvm/lib/IR/Instructions.cpp", line=299,
function=0x7f5bc13362af "void llvm::CallInst::init(llvm::FunctionType
*, llvm::Value *, ArrayRef<llvm::Value *>,
ArrayRef<llvm::OperandBundleDef>, const llvm::Twine &)") at
./assert/assert.c:101
#6 0x00007f5bc110f138 in llvm::CallInst::init (this=0x557a91f3e508,
FTy=0x557a91ed9ae0, Func=0x557a91f8be88, Args=..., Bundles=...,
NameStr=...) at
/home/bf/src/llvm-project-5/llvm/lib/IR/Instructions.cpp:297
#7 0x00007f5bc0fa579d in llvm::CallInst::CallInst
(this=0x557a91f3e508, Ty=0x557a91ed9ae0, Func=0x557a91f8be88,
Args=..., Bundles=..., NameStr=..., InsertBefore=0x0) at
/home/bf/src/llvm-project-5/llvm/include/llvm/IR/Instructions.h:1934
#8 0x00007f5bc0fa538c in llvm::CallInst::Create (Ty=0x557a91ed9ae0,
Func=0x557a91f8be88, Args=..., Bundles=..., NameStr=...,
InsertBefore=0x0) at
/home/bf/src/llvm-project-5/llvm/include/llvm/IR/Instructions.h:1444
#9 0x00007f5bc0fa51f9 in llvm::IRBuilder<llvm::ConstantFolder,
llvm::IRBuilderDefaultInserter>::CreateCall (this=0x557a91f9c6a0,
FTy=0x557a91ed9ae0, Callee=0x557a91f8be88, Args=..., Name=...,
FPMathTag=0x0) at
/home/bf/src/llvm-project-5/llvm/include/llvm/IR/IRBuilder.h:1669
#10 0x00007f5bc100edda in llvm::IRBuilder<llvm::ConstantFolder,
llvm::IRBuilderDefaultInserter>::CreateCall (this=0x557a91f9c6a0,
Callee=0x557a91f8be88, Args=..., Name=..., FPMathTag=0x0) at
/home/bf/src/llvm-project-5/llvm/include/llvm/IR/IRBuilder.h:1663
#11 0x00007f5bc100714e in LLVMBuildCall (B=0x557a91f9c6a0,
Fn=0x557a91f8be88, Args=0x7ffde6fa0b50, NumArgs=6, Name=0x7f5bc30b648c
"funccall_iocoerce_in_safe") at
/home/bf/src/llvm-project-5/llvm/lib/IR/Core.cpp:2964
#12 0x00007f5bc30af861 in llvm_compile_expr (state=0x557a91fbeac0) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/jit/llvm/llvmjit_expr.c:1373
#13 0x0000557a915992db in jit_compile_expr
(state=state@entry=0x557a91fbeac0) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/jit/jit.c:177
#14 0x0000557a9123071d in ExecReadyExpr
(state=state@entry=0x557a91fbeac0) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/executor/execExpr.c:880
#15 0x0000557a912340d7 in ExecBuildProjectionInfo
(targetList=0x557a91fa6b58, econtext=<optimized out>, slot=<optimized
out>, parent=parent@entry=0x557a91f430a8,
inputDesc=inputDesc@entry=0x0) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/executor/execExpr.c:484
#16 0x0000557a9124e61e in ExecAssignProjectionInfo
(planstate=planstate@entry=0x557a91f430a8,
inputDesc=inputDesc@entry=0x0) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/executor/execUtils.c:547
#17 0x0000557a91274961 in ExecInitNestLoop
(node=node@entry=0x557a91f9e5d8, estate=estate@entry=0x557a91f425a0,
eflags=<optimized out>, eflags@entry=33) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/executor/nodeNestloop.c:308
#18 0x0000557a9124760f in ExecInitNode (node=0x557a91f9e5d8,
estate=estate@entry=0x557a91f425a0, eflags=eflags@entry=33) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/executor/execProcnode.c:298
#19 0x0000557a91255d39 in ExecInitAgg (node=node@entry=0x557a91f91540,
estate=estate@entry=0x557a91f425a0, eflags=eflags@entry=33) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/executor/nodeAgg.c:3306
#20 0x0000557a912476bf in ExecInitNode (node=0x557a91f91540,
estate=estate@entry=0x557a91f425a0, eflags=eflags@entry=33) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/executor/execProcnode.c:341
#21 0x0000557a912770c3 in ExecInitSort
(node=node@entry=0x557a91f9e850, estate=estate@entry=0x557a91f425a0,
eflags=eflags@entry=33) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/executor/nodeSort.c:265
#22 0x0000557a91247667 in ExecInitNode
(node=node@entry=0x557a91f9e850, estate=estate@entry=0x557a91f425a0,
eflags=eflags@entry=33) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/executor/execProcnode.c:321
#23 0x0000557a912402f5 in InitPlan (eflags=33,
queryDesc=0x557a91fa6fb8) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/executor/execMain.c:968
#24 standard_ExecutorStart (queryDesc=queryDesc@entry=0x557a91fa6fb8,
eflags=33, eflags@entry=1) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/executor/execMain.c:266
#25 0x0000557a912403c9 in ExecutorStart
(queryDesc=queryDesc@entry=0x557a91fa6fb8, eflags=1) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/executor/execMain.c:145
#26 0x0000557a911c2153 in ExplainOnePlan
(plannedstmt=plannedstmt@entry=0x557a91fa6ea8, into=into@entry=0x0,
es=es@entry=0x557a91f932e8,
queryString=queryString@entry=0x557a91dbd650 "EXPLAIN (COSTS
OFF)\\nSELECT DISTINCT (i || '/' || j)::pg_lsn f\\n FROM
generate_series(1, 10) i,\\n generate_series(1, 10) j,\\n
generate_series(1, 5) k\\n WHERE i <= 10 AND j > 0 AND j <= 10\\n
O"..., params=params@entry=0x0, queryEnv=queryEnv@entry=0x0,
planduration=0x7ffde6fa1258, bufusage=0x0) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/commands/explain.c:590
#27 0x0000557a911c23b2 in ExplainOneQuery (query=<optimized out>,
cursorOptions=cursorOptions@entry=2048, into=into@entry=0x0,
es=es@entry=0x557a91f932e8, queryString=0x557a91dbd650 "EXPLAIN (COSTS
OFF)\\nSELECT DISTINCT (i || '/' || j)::pg_lsn f\\n FROM
generate_series(1, 10) i,\\n generate_series(1, 10) j,\\n
generate_series(1, 5) k\\n WHERE i <= 10 AND j > 0 AND j <= 10\\n
O"..., params=params@entry=0x0, queryEnv=0x0) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/commands/explain.c:419
#28 0x0000557a911c2ddb in ExplainQuery
(pstate=pstate@entry=0x557a91f3eb18, stmt=stmt@entry=0x557a91e881d0,
params=params@entry=0x0, dest=dest@entry=0x557a91f3ea88) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/include/nodes/nodes.h:193
#29 0x0000557a91413811 in standard_ProcessUtility
(pstmt=0x557a91e88280, queryString=0x557a91dbd650 "EXPLAIN (COSTS
OFF)\\nSELECT DISTINCT (i || '/' || j)::pg_lsn f\\n FROM
generate_series(1, 10) i,\\n generate_series(1, 10) j,\\n
generate_series(1, 5) k\\n WHERE i <= 10 AND j > 0 AND j <= 10\\n
O"..., readOnlyTree=<optimized out>, context=PROCESS_UTILITY_TOPLEVEL,
params=0x0, queryEnv=0x0, dest=0x557a91f3ea88, qc=0x7ffde6fa1500) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/tcop/utility.c:870
#30 0x0000557a91413ed9 in ProcessUtility
(pstmt=pstmt@entry=0x557a91e88280, queryString=<optimized out>,
readOnlyTree=<optimized out>,
context=context@entry=PROCESS_UTILITY_TOPLEVEL, params=<optimized
out>, queryEnv=<optimized out>, dest=0x557a91f3ea88,
qc=0x7ffde6fa1500) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/tcop/utility.c:530
#31 0x0000557a91411537 in PortalRunUtility
(portal=portal@entry=0x557a91e35970, pstmt=0x557a91e88280,
isTopLevel=true, setHoldSnapshot=setHoldSnapshot@entry=true,
dest=dest@entry=0x557a91f3ea88, qc=qc@entry=0x7ffde6fa1500) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/tcop/pquery.c:1158
#32 0x0000557a914119a4 in FillPortalStore
(portal=portal@entry=0x557a91e35970, isTopLevel=isTopLevel@entry=true)
at /home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/include/nodes/nodes.h:193
#33 0x0000557a91411d6d in PortalRun
(portal=portal@entry=0x557a91e35970,
count=count@entry=9223372036854775807,
isTopLevel=isTopLevel@entry=true, run_once=run_once@entry=true,
dest=dest@entry=0x557a91e88900, altdest=altdest@entry=0x557a91e88900,
qc=0x7ffde6fa1700) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/tcop/pquery.c:763
#34 0x0000557a9140d65f in exec_simple_query
(query_string=query_string@entry=0x557a91dbd650 "EXPLAIN (COSTS
OFF)\\nSELECT DISTINCT (i || '/' || j)::pg_lsn f\\n FROM
generate_series(1, 10) i,\\n generate_series(1, 10) j,\\n
generate_series(1, 5) k\\n WHERE i <= 10 AND j > 0 AND j <= 10\\n
O"...) at /home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/tcop/postgres.c:1272
#35 0x0000557a9140e305 in PostgresMain (dbname=<optimized out>,
username=<optimized out>) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/tcop/postgres.c:4652
#36 0x0000557a91372bf0 in BackendRun (port=0x557a91de8730) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/postmaster/postmaster.c:4439
#37 BackendStartup (port=0x557a91de8730) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/postmaster/postmaster.c:4167
#38 ServerLoop () at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/postmaster/postmaster.c:1781
#39 0x0000557a9137488e in PostmasterMain (argc=argc@entry=8,
argv=argv@entry=0x557a91d7cc10) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/postmaster/postmaster.c:1465
#40 0x0000557a912a001e in main (argc=8, argv=0x557a91d7cc10) at
/home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/main/main.c:198
$1 = {si_signo = 6, si_errno = 0, si_code = -6, _sifields = {_pad =
{3110875, 1000, 0 <repeats 26 times>}, _kill = {si_pid = 3110875,
si_uid = 1000}, _timer = {si_tid = 3110875, si_overrun = 1000,
si_sigval = {sival_int = 0, sival_ptr = 0x0}}, _rt = {si_pid =
3110875, si_uid = 1000, si_sigval = {sival_int = 0, sival_ptr = 0x0}},
_sigchld = {si_pid = 3110875, si_uid = 1000, si_status = 0, si_utime =
0, si_stime = 0}, _sigfault = {si_addr = 0x3e8002f77db, _addr_lsb = 0,
_addr_bnd = {_lower = 0x0, _upper = 0x0}}, _sigpoll = {si_band =
4294970406875, si_fd = 0}, _sigsys = {_call_addr = 0x3e8002f77db,
_syscall = 0, _arch = 0}}}
This seems to me to be complaining about the following addition:
+ {
+ Oid ioparam = op->d.iocoerce.typioparam;
+ LLVMValueRef v_params[6];
+ LLVMValueRef v_success;
+
+ v_params[0] = l_ptr_const(op->d.iocoerce.finfo_in,
+ l_ptr(StructFmgrInfo));
+ v_params[1] = v_output;
+ v_params[2] = l_oid_const(lc, ioparam);
+ v_params[3] = l_int32_const(lc, -1);
+ v_params[4] = l_ptr_const(op->d.iocoerce.escontext,
+
l_ptr(StructErrorSaveContext));
- LLVMBuildStore(b, v_retval, v_resvaluep);
+ /*
+ * InputFunctionCallSafe() will write directly into
+ * *op->resvalue.
+ */
+ v_params[5] = v_resvaluep;
+
+ v_success = LLVMBuildCall(b, llvm_pg_func(mod,
"InputFunctionCallSafe"),
+ v_params, lengthof(v_params),
+ "funccall_iocoerce_in_safe");
+
+ /*
+ * Return null if InputFunctionCallSafe() encountered
+ * an error.
+ */
+ v_resnullp = LLVMBuildICmp(b, LLVMIntEQ, v_success,
+ l_sbool_const(0), "");
+ }
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
[1] https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=pogona&dt=2023-10-02%2003%3A50%3A20
On Mon, Oct 2, 2023 at 1:24 PM Amit Langote <amitlangote09@gmail.com> wrote:
> Pushed this 30 min ago (no email on -committers yet!) and am looking
> at the following llvm crash reported by buildfarm animal pogona [1]:
>
> Pushed this 30 min ago (no email on -committers yet!) and am looking
> at the following llvm crash reported by buildfarm animal pogona [1]:
>
> #4 0x00007f5bceb673d5 in __assert_fail_base (fmt=0x7f5bcecdbdc8
> "%s%s%s:%u: %s%sAssertion `%s' failed.\\n%n",
> assertion=assertion@entry=0x7f5bc1336419 "(i >= FTy->getNumParams() ||
> FTy->getParamType(i) == Args[i]->getType()) && \\"Calling a function
> with a bad signature!\\"", file=file@entry=0x7f5bc1336051
> "/home/bf/src/llvm-project-5/llvm/lib/IR/Instructions.cpp",
> line=line@entry=299, function=function@entry=0x7f5bc13362af "void
> llvm::CallInst::init(llvm::FunctionType *, llvm::Value *,
> ArrayRef<llvm::Value *>, ArrayRef<llvm::OperandBundleDef>, const
> llvm::Twine &)") at ./assert/assert.c:92
> #5 0x00007f5bceb763a2 in __assert_fail (assertion=0x7f5bc1336419 "(i
> >= FTy->getNumParams() || FTy->getParamType(i) == Args[i]->getType())
> && \\"Calling a function with a bad signature!\\"",
> file=0x7f5bc1336051
> "/home/bf/src/llvm-project-5/llvm/lib/IR/Instructions.cpp", line=299,
> function=0x7f5bc13362af "void llvm::CallInst::init(llvm::FunctionType
> *, llvm::Value *, ArrayRef<llvm::Value *>,
> ArrayRef<llvm::OperandBundleDef>, const llvm::Twine &)") at
> ./assert/assert.c:101
> #6 0x00007f5bc110f138 in llvm::CallInst::init (this=0x557a91f3e508,
> FTy=0x557a91ed9ae0, Func=0x557a91f8be88, Args=..., Bundles=...,
> NameStr=...) at
> /home/bf/src/llvm-project-5/llvm/lib/IR/Instructions.cpp:297
> #7 0x00007f5bc0fa579d in llvm::CallInst::CallInst
> (this=0x557a91f3e508, Ty=0x557a91ed9ae0, Func=0x557a91f8be88,
> Args=..., Bundles=..., NameStr=..., InsertBefore=0x0) at
> /home/bf/src/llvm-project-5/llvm/include/llvm/IR/Instructions.h:1934
> #8 0x00007f5bc0fa538c in llvm::CallInst::Create (Ty=0x557a91ed9ae0,
> Func=0x557a91f8be88, Args=..., Bundles=..., NameStr=...,
> InsertBefore=0x0) at
> /home/bf/src/llvm-project-5/llvm/include/llvm/IR/Instructions.h:1444
> #9 0x00007f5bc0fa51f9 in llvm::IRBuilder<llvm::ConstantFolder,
> llvm::IRBuilderDefaultInserter>::CreateCall (this=0x557a91f9c6a0,
> FTy=0x557a91ed9ae0, Callee=0x557a91f8be88, Args=..., Name=...,
> FPMathTag=0x0) at
> /home/bf/src/llvm-project-5/llvm/include/llvm/IR/IRBuilder.h:1669
> #10 0x00007f5bc100edda in llvm::IRBuilder<llvm::ConstantFolder,
> llvm::IRBuilderDefaultInserter>::CreateCall (this=0x557a91f9c6a0,
> Callee=0x557a91f8be88, Args=..., Name=..., FPMathTag=0x0) at
> /home/bf/src/llvm-project-5/llvm/include/llvm/IR/IRBuilder.h:1663
> #11 0x00007f5bc100714e in LLVMBuildCall (B=0x557a91f9c6a0,
> Fn=0x557a91f8be88, Args=0x7ffde6fa0b50, NumArgs=6, Name=0x7f5bc30b648c
> "funccall_iocoerce_in_safe") at
> /home/bf/src/llvm-project-5/llvm/lib/IR/Core.cpp:2964
> #12 0x00007f5bc30af861 in llvm_compile_expr (state=0x557a91fbeac0) at
> /home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/jit/llvm/llvmjit_expr.c:1373
>
> This seems to me to be complaining about the following addition:
>
> + {
> + Oid ioparam = op->d.iocoerce.typioparam;
> + LLVMValueRef v_params[6];
> + LLVMValueRef v_success;
> +
> + v_params[0] = l_ptr_const(op->d.iocoerce.finfo_in,
> + l_ptr(StructFmgrInfo));
> + v_params[1] = v_output;
> + v_params[2] = l_oid_const(lc, ioparam);
> + v_params[3] = l_int32_const(lc, -1);
> + v_params[4] = l_ptr_const(op->d.iocoerce.escontext,
> +
> l_ptr(StructErrorSaveContext));
>
> - LLVMBuildStore(b, v_retval, v_resvaluep);
> + /*
> + * InputFunctionCallSafe() will write directly into
> + * *op->resvalue.
> + */
> + v_params[5] = v_resvaluep;
> +
> + v_success = LLVMBuildCall(b, llvm_pg_func(mod,
> "InputFunctionCallSafe"),
> + v_params, lengthof(v_params),
> + "funccall_iocoerce_in_safe");
> +
> + /*
> + * Return null if InputFunctionCallSafe() encountered
> + * an error.
> + */
> + v_resnullp = LLVMBuildICmp(b, LLVMIntEQ, v_success,
> + l_sbool_const(0), "");
> + }
> "%s%s%s:%u: %s%sAssertion `%s' failed.\\n%n",
> assertion=assertion@entry=0x7f5bc1336419 "(i >= FTy->getNumParams() ||
> FTy->getParamType(i) == Args[i]->getType()) && \\"Calling a function
> with a bad signature!\\"", file=file@entry=0x7f5bc1336051
> "/home/bf/src/llvm-project-5/llvm/lib/IR/Instructions.cpp",
> line=line@entry=299, function=function@entry=0x7f5bc13362af "void
> llvm::CallInst::init(llvm::FunctionType *, llvm::Value *,
> ArrayRef<llvm::Value *>, ArrayRef<llvm::OperandBundleDef>, const
> llvm::Twine &)") at ./assert/assert.c:92
> #5 0x00007f5bceb763a2 in __assert_fail (assertion=0x7f5bc1336419 "(i
> >= FTy->getNumParams() || FTy->getParamType(i) == Args[i]->getType())
> && \\"Calling a function with a bad signature!\\"",
> file=0x7f5bc1336051
> "/home/bf/src/llvm-project-5/llvm/lib/IR/Instructions.cpp", line=299,
> function=0x7f5bc13362af "void llvm::CallInst::init(llvm::FunctionType
> *, llvm::Value *, ArrayRef<llvm::Value *>,
> ArrayRef<llvm::OperandBundleDef>, const llvm::Twine &)") at
> ./assert/assert.c:101
> #6 0x00007f5bc110f138 in llvm::CallInst::init (this=0x557a91f3e508,
> FTy=0x557a91ed9ae0, Func=0x557a91f8be88, Args=..., Bundles=...,
> NameStr=...) at
> /home/bf/src/llvm-project-5/llvm/lib/IR/Instructions.cpp:297
> #7 0x00007f5bc0fa579d in llvm::CallInst::CallInst
> (this=0x557a91f3e508, Ty=0x557a91ed9ae0, Func=0x557a91f8be88,
> Args=..., Bundles=..., NameStr=..., InsertBefore=0x0) at
> /home/bf/src/llvm-project-5/llvm/include/llvm/IR/Instructions.h:1934
> #8 0x00007f5bc0fa538c in llvm::CallInst::Create (Ty=0x557a91ed9ae0,
> Func=0x557a91f8be88, Args=..., Bundles=..., NameStr=...,
> InsertBefore=0x0) at
> /home/bf/src/llvm-project-5/llvm/include/llvm/IR/Instructions.h:1444
> #9 0x00007f5bc0fa51f9 in llvm::IRBuilder<llvm::ConstantFolder,
> llvm::IRBuilderDefaultInserter>::CreateCall (this=0x557a91f9c6a0,
> FTy=0x557a91ed9ae0, Callee=0x557a91f8be88, Args=..., Name=...,
> FPMathTag=0x0) at
> /home/bf/src/llvm-project-5/llvm/include/llvm/IR/IRBuilder.h:1669
> #10 0x00007f5bc100edda in llvm::IRBuilder<llvm::ConstantFolder,
> llvm::IRBuilderDefaultInserter>::CreateCall (this=0x557a91f9c6a0,
> Callee=0x557a91f8be88, Args=..., Name=..., FPMathTag=0x0) at
> /home/bf/src/llvm-project-5/llvm/include/llvm/IR/IRBuilder.h:1663
> #11 0x00007f5bc100714e in LLVMBuildCall (B=0x557a91f9c6a0,
> Fn=0x557a91f8be88, Args=0x7ffde6fa0b50, NumArgs=6, Name=0x7f5bc30b648c
> "funccall_iocoerce_in_safe") at
> /home/bf/src/llvm-project-5/llvm/lib/IR/Core.cpp:2964
> #12 0x00007f5bc30af861 in llvm_compile_expr (state=0x557a91fbeac0) at
> /home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/jit/llvm/llvmjit_expr.c:1373
>
> This seems to me to be complaining about the following addition:
>
> + {
> + Oid ioparam = op->d.iocoerce.typioparam;
> + LLVMValueRef v_params[6];
> + LLVMValueRef v_success;
> +
> + v_params[0] = l_ptr_const(op->d.iocoerce.finfo_in,
> + l_ptr(StructFmgrInfo));
> + v_params[1] = v_output;
> + v_params[2] = l_oid_const(lc, ioparam);
> + v_params[3] = l_int32_const(lc, -1);
> + v_params[4] = l_ptr_const(op->d.iocoerce.escontext,
> +
> l_ptr(StructErrorSaveContext));
>
> - LLVMBuildStore(b, v_retval, v_resvaluep);
> + /*
> + * InputFunctionCallSafe() will write directly into
> + * *op->resvalue.
> + */
> + v_params[5] = v_resvaluep;
> +
> + v_success = LLVMBuildCall(b, llvm_pg_func(mod,
> "InputFunctionCallSafe"),
> + v_params, lengthof(v_params),
> + "funccall_iocoerce_in_safe");
> +
> + /*
> + * Return null if InputFunctionCallSafe() encountered
> + * an error.
> + */
> + v_resnullp = LLVMBuildICmp(b, LLVMIntEQ, v_success,
> + l_sbool_const(0), "");
> + }
Although most animals except pogona looked fine, I've decided to revert the patch for now.
IIUC, LLVM is complaining that the code in the above block is not passing the arguments of InputFunctionCallSafe() using the correct types. I'm not exactly sure which particular argument is not handled correctly in the above code, but perhaps it's:
IIUC, LLVM is complaining that the code in the above block is not passing the arguments of InputFunctionCallSafe() using the correct types. I'm not exactly sure which particular argument is not handled correctly in the above code, but perhaps it's:
+ v_params[1] = v_output;
which maps to char *str argument of InputFunctionCallSafe(). v_output is set in the code preceding the above block as follows:
/* and call output function (can never return NULL) */
v_output = LLVMBuildCall(b, v_fn_out, &v_fcinfo_out,
1, "funccall_coerce_out");
I thought that it would be fine to pass it as-is to the call of InputFunctionCallSafe() given that v_fn_out is a call to a function that returns char *, but perhaps not.
/* and call output function (can never return NULL) */
v_output = LLVMBuildCall(b, v_fn_out, &v_fcinfo_out,
1, "funccall_coerce_out");
I thought that it would be fine to pass it as-is to the call of InputFunctionCallSafe() given that v_fn_out is a call to a function that returns char *, but perhaps not.
On Mon, Oct 2, 2023 at 2:26 PM Amit Langote <amitlangote09@gmail.com> wrote:
> On Mon, Oct 2, 2023 at 1:24 PM Amit Langote <amitlangote09@gmail.com> wrote:
> > Pushed this 30 min ago (no email on -committers yet!) and am looking
> > at the following llvm crash reported by buildfarm animal pogona [1]:
> >
> > #4 0x00007f5bceb673d5 in __assert_fail_base (fmt=0x7f5bcecdbdc8
> > "%s%s%s:%u: %s%sAssertion `%s' failed.\\n%n",
> > assertion=assertion@entry=0x7f5bc1336419 "(i >= FTy->getNumParams() ||
> > FTy->getParamType(i) == Args[i]->getType()) && \\"Calling a function
> > with a bad signature!\\"", file=file@entry=0x7f5bc1336051
> > "/home/bf/src/llvm-project-5/llvm/lib/IR/Instructions.cpp",
> > line=line@entry=299, function=function@entry=0x7f5bc13362af "void
> > llvm::CallInst::init(llvm::FunctionType *, llvm::Value *,
> > ArrayRef<llvm::Value *>, ArrayRef<llvm::OperandBundleDef>, const
> > llvm::Twine &)") at ./assert/assert.c:92
> > #5 0x00007f5bceb763a2 in __assert_fail (assertion=0x7f5bc1336419 "(i
> > >= FTy->getNumParams() || FTy->getParamType(i) == Args[i]->getType())
> > && \\"Calling a function with a bad signature!\\"",
> > file=0x7f5bc1336051
> > "/home/bf/src/llvm-project-5/llvm/lib/IR/Instructions.cpp", line=299,
> > function=0x7f5bc13362af "void llvm::CallInst::init(llvm::FunctionType
> > *, llvm::Value *, ArrayRef<llvm::Value *>,
> > ArrayRef<llvm::OperandBundleDef>, const llvm::Twine &)") at
> > ./assert/assert.c:101
> > #6 0x00007f5bc110f138 in llvm::CallInst::init (this=0x557a91f3e508,
> > FTy=0x557a91ed9ae0, Func=0x557a91f8be88, Args=..., Bundles=...,
> > NameStr=...) at
> > /home/bf/src/llvm-project-5/llvm/lib/IR/Instructions.cpp:297
> > #7 0x00007f5bc0fa579d in llvm::CallInst::CallInst
> > (this=0x557a91f3e508, Ty=0x557a91ed9ae0, Func=0x557a91f8be88,
> > Args=..., Bundles=..., NameStr=..., InsertBefore=0x0) at
> > /home/bf/src/llvm-project-5/llvm/include/llvm/IR/Instructions.h:1934
> > #8 0x00007f5bc0fa538c in llvm::CallInst::Create (Ty=0x557a91ed9ae0,
> > Func=0x557a91f8be88, Args=..., Bundles=..., NameStr=...,
> > InsertBefore=0x0) at
> > /home/bf/src/llvm-project-5/llvm/include/llvm/IR/Instructions.h:1444
> > #9 0x00007f5bc0fa51f9 in llvm::IRBuilder<llvm::ConstantFolder,
> > llvm::IRBuilderDefaultInserter>::CreateCall (this=0x557a91f9c6a0,
> > FTy=0x557a91ed9ae0, Callee=0x557a91f8be88, Args=..., Name=...,
> > FPMathTag=0x0) at
> > /home/bf/src/llvm-project-5/llvm/include/llvm/IR/IRBuilder.h:1669
> > #10 0x00007f5bc100edda in llvm::IRBuilder<llvm::ConstantFolder,
> > llvm::IRBuilderDefaultInserter>::CreateCall (this=0x557a91f9c6a0,
> > Callee=0x557a91f8be88, Args=..., Name=..., FPMathTag=0x0) at
> > /home/bf/src/llvm-project-5/llvm/include/llvm/IR/IRBuilder.h:1663
> > #11 0x00007f5bc100714e in LLVMBuildCall (B=0x557a91f9c6a0,
> > Fn=0x557a91f8be88, Args=0x7ffde6fa0b50, NumArgs=6, Name=0x7f5bc30b648c
> > "funccall_iocoerce_in_safe") at
> > /home/bf/src/llvm-project-5/llvm/lib/IR/Core.cpp:2964
> > #12 0x00007f5bc30af861 in llvm_compile_expr (state=0x557a91fbeac0) at
> > /home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/jit/llvm/llvmjit_expr.c:1373
> >
> > This seems to me to be complaining about the following addition:
> >
> > + {
> > + Oid ioparam = op->d.iocoerce.typioparam;
> > + LLVMValueRef v_params[6];
> > + LLVMValueRef v_success;
> > +
> > + v_params[0] = l_ptr_const(op->d.iocoerce.finfo_in,
> > + l_ptr(StructFmgrInfo));
> > + v_params[1] = v_output;
> > + v_params[2] = l_oid_const(lc, ioparam);
> > + v_params[3] = l_int32_const(lc, -1);
> > + v_params[4] = l_ptr_const(op->d.iocoerce.escontext,
> > +
> > l_ptr(StructErrorSaveContext));
> >
> > - LLVMBuildStore(b, v_retval, v_resvaluep);
> > + /*
> > + * InputFunctionCallSafe() will write directly into
> > + * *op->resvalue.
> > + */
> > + v_params[5] = v_resvaluep;
> > +
> > + v_success = LLVMBuildCall(b, llvm_pg_func(mod,
> > "InputFunctionCallSafe"),
> > + v_params, lengthof(v_params),
> > + "funccall_iocoerce_in_safe");
> > +
> > + /*
> > + * Return null if InputFunctionCallSafe() encountered
> > + * an error.
> > + */
> > + v_resnullp = LLVMBuildICmp(b, LLVMIntEQ, v_success,
> > + l_sbool_const(0), "");
> > + }
>
> Although most animals except pogona looked fine, I've decided to revert the patch for now.
>
> IIUC, LLVM is complaining that the code in the above block is not passing the arguments of InputFunctionCallSafe()
usingthe correct types. I'm not exactly sure which particular argument is not handled correctly in the above code, but
perhapsit's:
>
>
> + v_params[1] = v_output;
>
> which maps to char *str argument of InputFunctionCallSafe(). v_output is set in the code preceding the above block
asfollows:
>
> /* and call output function (can never return NULL) */
> v_output = LLVMBuildCall(b, v_fn_out, &v_fcinfo_out,
> 1, "funccall_coerce_out");
>
> I thought that it would be fine to pass it as-is to the call of InputFunctionCallSafe() given that v_fn_out is a call
toa function that returns char *, but perhaps not.
OK, I think I could use some help from LLVM experts here.
So, the LLVM code involving setting up a call to
InputFunctionCallSafe() seems to *work*, but BF animal pogona's debug
build (?) is complaining that the parameter types don't match up.
Parameters are set up as follows:
+ {
+ Oid ioparam = op->d.iocoerce.typioparam;
+ LLVMValueRef v_params[6];
+ LLVMValueRef v_success;
+
+ v_params[0] = l_ptr_const(op->d.iocoerce.finfo_in,
+ l_ptr(StructFmgrInfo));
+ v_params[1] = v_output;
+ v_params[2] = l_oid_const(lc, ioparam);
+ v_params[3] = l_int32_const(lc, -1);
+ v_params[4] = l_ptr_const(op->d.iocoerce.escontext,
+
l_ptr(StructErrorSaveContext));
+ /*
+ * InputFunctionCallSafe() will write directly into
+ * *op->resvalue.
+ */
+ v_params[5] = v_resvaluep;
+
+ v_success = LLVMBuildCall(b, llvm_pg_func(mod,
"InputFunctionCallSafe"),
+ v_params, lengthof(v_params),
+ "funccall_iocoerce_in_safe");
+
+ /*
+ * Return null if InputFunctionCallSafe() encountered
+ * an error.
+ */
+ v_resnullp = LLVMBuildICmp(b, LLVMIntEQ, v_success,
+ l_sbool_const(0), "");
+ }
And here's InputFunctionCallSafe's signature:
bool
InputFunctionCallSafe(FmgrInfo *flinfo, Datum d,
Oid typioparam, int32 typmod,
fmNodePtr escontext,
Datum *result)
I suspected that assignment to either param[1] or param[5] might be wrong.
param[1] in InputFunctionCallSafe's signature is char *, but the code
assigns it v_output, which is an LLVMValueRef for the output
function's output, a Datum, so I thought LLVM's type checker is
complaining that I'm trying to pass the Datum to char * without
appropriate conversion.
param[5] in InputFunctionCallSafe's signature is Node *, but the above
code is assigning it an LLVMValueRef for iocoerce's escontext whose
type is ErrorSaveContext.
Maybe some other param is wrong.
I tried various ways to fix both, but with no success. My way of
checking for failure is to disassemble the IR code in .bc files
(generated with jit_dump_bitcode) with llvm-dis and finding that it
gives me errors such as:
$ llvm-dis 58536.0.bc
llvm-dis: error: Invalid record (Producer: 'LLVM7.0.1' Reader: 'LLVM 7.0.1')
$ llvm-dis 58536.0.bc
llvm-dis: error: Invalid cast (Producer: 'LLVM7.0.1' Reader: 'LLVM 7.0.1')
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
On Tue, Oct 3, 2023 at 10:11 PM Amit Langote <amitlangote09@gmail.com> wrote:
> On Mon, Oct 2, 2023 at 2:26 PM Amit Langote <amitlangote09@gmail.com> wrote:
> > On Mon, Oct 2, 2023 at 1:24 PM Amit Langote <amitlangote09@gmail.com> wrote:
> > > Pushed this 30 min ago (no email on -committers yet!) and am looking
> > > at the following llvm crash reported by buildfarm animal pogona [1]:
> > >
> > > #4 0x00007f5bceb673d5 in __assert_fail_base (fmt=0x7f5bcecdbdc8
> > > "%s%s%s:%u: %s%sAssertion `%s' failed.\\n%n",
> > > assertion=assertion@entry=0x7f5bc1336419 "(i >= FTy->getNumParams() ||
> > > FTy->getParamType(i) == Args[i]->getType()) && \\"Calling a function
> > > with a bad signature!\\"", file=file@entry=0x7f5bc1336051
> > > "/home/bf/src/llvm-project-5/llvm/lib/IR/Instructions.cpp",
> > > line=line@entry=299, function=function@entry=0x7f5bc13362af "void
> > > llvm::CallInst::init(llvm::FunctionType *, llvm::Value *,
> > > ArrayRef<llvm::Value *>, ArrayRef<llvm::OperandBundleDef>, const
> > > llvm::Twine &)") at ./assert/assert.c:92
> > > #5 0x00007f5bceb763a2 in __assert_fail (assertion=0x7f5bc1336419 "(i
> > > >= FTy->getNumParams() || FTy->getParamType(i) == Args[i]->getType())
> > > && \\"Calling a function with a bad signature!\\"",
> > > file=0x7f5bc1336051
> > > "/home/bf/src/llvm-project-5/llvm/lib/IR/Instructions.cpp", line=299,
> > > function=0x7f5bc13362af "void llvm::CallInst::init(llvm::FunctionType
> > > *, llvm::Value *, ArrayRef<llvm::Value *>,
> > > ArrayRef<llvm::OperandBundleDef>, const llvm::Twine &)") at
> > > ./assert/assert.c:101
> > > #6 0x00007f5bc110f138 in llvm::CallInst::init (this=0x557a91f3e508,
> > > FTy=0x557a91ed9ae0, Func=0x557a91f8be88, Args=..., Bundles=...,
> > > NameStr=...) at
> > > /home/bf/src/llvm-project-5/llvm/lib/IR/Instructions.cpp:297
> > > #7 0x00007f5bc0fa579d in llvm::CallInst::CallInst
> > > (this=0x557a91f3e508, Ty=0x557a91ed9ae0, Func=0x557a91f8be88,
> > > Args=..., Bundles=..., NameStr=..., InsertBefore=0x0) at
> > > /home/bf/src/llvm-project-5/llvm/include/llvm/IR/Instructions.h:1934
> > > #8 0x00007f5bc0fa538c in llvm::CallInst::Create (Ty=0x557a91ed9ae0,
> > > Func=0x557a91f8be88, Args=..., Bundles=..., NameStr=...,
> > > InsertBefore=0x0) at
> > > /home/bf/src/llvm-project-5/llvm/include/llvm/IR/Instructions.h:1444
> > > #9 0x00007f5bc0fa51f9 in llvm::IRBuilder<llvm::ConstantFolder,
> > > llvm::IRBuilderDefaultInserter>::CreateCall (this=0x557a91f9c6a0,
> > > FTy=0x557a91ed9ae0, Callee=0x557a91f8be88, Args=..., Name=...,
> > > FPMathTag=0x0) at
> > > /home/bf/src/llvm-project-5/llvm/include/llvm/IR/IRBuilder.h:1669
> > > #10 0x00007f5bc100edda in llvm::IRBuilder<llvm::ConstantFolder,
> > > llvm::IRBuilderDefaultInserter>::CreateCall (this=0x557a91f9c6a0,
> > > Callee=0x557a91f8be88, Args=..., Name=..., FPMathTag=0x0) at
> > > /home/bf/src/llvm-project-5/llvm/include/llvm/IR/IRBuilder.h:1663
> > > #11 0x00007f5bc100714e in LLVMBuildCall (B=0x557a91f9c6a0,
> > > Fn=0x557a91f8be88, Args=0x7ffde6fa0b50, NumArgs=6, Name=0x7f5bc30b648c
> > > "funccall_iocoerce_in_safe") at
> > > /home/bf/src/llvm-project-5/llvm/lib/IR/Core.cpp:2964
> > > #12 0x00007f5bc30af861 in llvm_compile_expr (state=0x557a91fbeac0) at
> > > /home/bf/bf-build/pogona/HEAD/pgsql.build/../pgsql/src/backend/jit/llvm/llvmjit_expr.c:1373
> > >
> > > This seems to me to be complaining about the following addition:
> > >
> > > + {
> > > + Oid ioparam = op->d.iocoerce.typioparam;
> > > + LLVMValueRef v_params[6];
> > > + LLVMValueRef v_success;
> > > +
> > > + v_params[0] = l_ptr_const(op->d.iocoerce.finfo_in,
> > > + l_ptr(StructFmgrInfo));
> > > + v_params[1] = v_output;
> > > + v_params[2] = l_oid_const(lc, ioparam);
> > > + v_params[3] = l_int32_const(lc, -1);
> > > + v_params[4] = l_ptr_const(op->d.iocoerce.escontext,
> > > +
> > > l_ptr(StructErrorSaveContext));
> > >
> > > - LLVMBuildStore(b, v_retval, v_resvaluep);
> > > + /*
> > > + * InputFunctionCallSafe() will write directly into
> > > + * *op->resvalue.
> > > + */
> > > + v_params[5] = v_resvaluep;
> > > +
> > > + v_success = LLVMBuildCall(b, llvm_pg_func(mod,
> > > "InputFunctionCallSafe"),
> > > + v_params, lengthof(v_params),
> > > + "funccall_iocoerce_in_safe");
> > > +
> > > + /*
> > > + * Return null if InputFunctionCallSafe() encountered
> > > + * an error.
> > > + */
> > > + v_resnullp = LLVMBuildICmp(b, LLVMIntEQ, v_success,
> > > + l_sbool_const(0), "");
> > > + }
> >
> > Although most animals except pogona looked fine, I've decided to revert the patch for now.
> >
> > IIUC, LLVM is complaining that the code in the above block is not passing the arguments of InputFunctionCallSafe()
usingthe correct types. I'm not exactly sure which particular argument is not handled correctly in the above code, but
perhapsit's:
> >
> >
> > + v_params[1] = v_output;
> >
> > which maps to char *str argument of InputFunctionCallSafe(). v_output is set in the code preceding the above block
asfollows:
> >
> > /* and call output function (can never return NULL) */
> > v_output = LLVMBuildCall(b, v_fn_out, &v_fcinfo_out,
> > 1, "funccall_coerce_out");
> >
> > I thought that it would be fine to pass it as-is to the call of InputFunctionCallSafe() given that v_fn_out is a
callto a function that returns char *, but perhaps not.
>
> OK, I think I could use some help from LLVM experts here.
>
> So, the LLVM code involving setting up a call to
> InputFunctionCallSafe() seems to *work*, but BF animal pogona's debug
> build (?) is complaining that the parameter types don't match up.
> Parameters are set up as follows:
>
> + {
> + Oid ioparam = op->d.iocoerce.typioparam;
> + LLVMValueRef v_params[6];
> + LLVMValueRef v_success;
> +
> + v_params[0] = l_ptr_const(op->d.iocoerce.finfo_in,
> + l_ptr(StructFmgrInfo));
> + v_params[1] = v_output;
> + v_params[2] = l_oid_const(lc, ioparam);
> + v_params[3] = l_int32_const(lc, -1);
> + v_params[4] = l_ptr_const(op->d.iocoerce.escontext,
> +
> l_ptr(StructErrorSaveContext));
> + /*
> + * InputFunctionCallSafe() will write directly into
> + * *op->resvalue.
> + */
> + v_params[5] = v_resvaluep;
> +
> + v_success = LLVMBuildCall(b, llvm_pg_func(mod,
> "InputFunctionCallSafe"),
> + v_params, lengthof(v_params),
> + "funccall_iocoerce_in_safe");
> +
> + /*
> + * Return null if InputFunctionCallSafe() encountered
> + * an error.
> + */
> + v_resnullp = LLVMBuildICmp(b, LLVMIntEQ, v_success,
> + l_sbool_const(0), "");
> + }
>
> And here's InputFunctionCallSafe's signature:
>
> bool
> InputFunctionCallSafe(FmgrInfo *flinfo, Datum d,
> Oid typioparam, int32 typmod,
> fmNodePtr escontext,
> Datum *result)
>
> I suspected that assignment to either param[1] or param[5] might be wrong.
>
> param[1] in InputFunctionCallSafe's signature is char *, but the code
> assigns it v_output, which is an LLVMValueRef for the output
> function's output, a Datum, so I thought LLVM's type checker is
> complaining that I'm trying to pass the Datum to char * without
> appropriate conversion.
>
> param[5] in InputFunctionCallSafe's signature is Node *, but the above
> code is assigning it an LLVMValueRef for iocoerce's escontext whose
> type is ErrorSaveContext.
>
> Maybe some other param is wrong.
>
> I tried various ways to fix both, but with no success. My way of
> checking for failure is to disassemble the IR code in .bc files
> (generated with jit_dump_bitcode) with llvm-dis and finding that it
> gives me errors such as:
>
> $ llvm-dis 58536.0.bc
> llvm-dis: error: Invalid record (Producer: 'LLVM7.0.1' Reader: 'LLVM 7.0.1')
>
> $ llvm-dis 58536.0.bc
> llvm-dis: error: Invalid cast (Producer: 'LLVM7.0.1' Reader: 'LLVM 7.0.1')
So I built LLVM sources to get asserts like pogona:
$ llvm-config --version
15.0.7
$ llvm-config --assertion-mode
ON
and I do now get a crash with bt that looks like this (not same as pogona):
#0 0x00007fe31e83c387 in raise () from /lib64/libc.so.6
#1 0x00007fe31e83da78 in abort () from /lib64/libc.so.6
#2 0x00007fe31e8351a6 in __assert_fail_base () from /lib64/libc.so.6
#3 0x00007fe31e835252 in __assert_fail () from /lib64/libc.so.6
#4 0x00007fe3136d8132 in llvm::CallInst::init(llvm::FunctionType*,
llvm::Value*, llvm::ArrayRef<llvm::Value*>,
llvm::ArrayRef<llvm::OperandBundleDefT<llvm::Value*> >, llvm::Twine
const&) ()
from /home/amit/llvm/lib/libLLVMCore.so.15
#5 0x00007fe31362137a in
llvm::IRBuilderBase::CreateCall(llvm::FunctionType*, llvm::Value*,
llvm::ArrayRef<llvm::Value*>, llvm::Twine const&, llvm::MDNode*) ()
from /home/amit/llvm/lib/libLLVMCore.so.15
#6 0x00007fe31362d627 in LLVMBuildCall () from
/home/amit/llvm/lib/libLLVMCore.so.15
#7 0x00007fe3205e7e92 in llvm_compile_expr (state=0x1114e48) at
llvmjit_expr.c:1374
#8 0x0000000000bd3fbc in jit_compile_expr (state=0x1114e48) at jit.c:177
#9 0x000000000072442b in ExecReadyExpr (state=0x1114e48) at execExpr.c:880
#10 0x000000000072387c in ExecBuildProjectionInfo
(targetList=0x1110840, econtext=0x1114a20, slot=0x1114db0,
parent=0x1114830, inputDesc=0x1114ab0) at execExpr.c:484
#11 0x000000000074e917 in ExecAssignProjectionInfo
(planstate=0x1114830, inputDesc=0x1114ab0) at execUtils.c:547
#12 0x000000000074ea02 in ExecConditionalAssignProjectionInfo
(planstate=0x1114830, inputDesc=0x1114ab0, varno=2)
at execUtils.c:585
#13 0x0000000000749814 in ExecAssignScanProjectionInfo
(node=0x1114830) at execScan.c:276
#14 0x0000000000790bf0 in ExecInitValuesScan (node=0x1045020,
estate=0x1114600, eflags=32)
at nodeValuesscan.c:257
#15 0x00000000007451c9 in ExecInitNode (node=0x1045020,
estate=0x1114600, eflags=32) at execProcnode.c:265
#16 0x000000000073a952 in InitPlan (queryDesc=0x1070760, eflags=32) at
execMain.c:968
#17 0x0000000000739828 in standard_ExecutorStart (queryDesc=0x1070760,
eflags=32) at execMain.c:266
#18 0x000000000073959d in ExecutorStart (queryDesc=0x1070760,
eflags=0) at execMain.c:145
#19 0x00000000009c1aaa in PortalStart (portal=0x10bf7d0, params=0x0,
eflags=0, snapshot=0x0) at pquery.c:517
#20 0x00000000009bbba8 in exec_simple_query (
query_string=0x10433c0 "select i::pg_lsn from (values ('x/a'),
('b/b')) a(i);") at postgres.c:1233
#21 0x00000000009c0263 in PostgresMain (dbname=0x1079750 "postgres",
username=0x1079738 "amit")
at postgres.c:4652
#22 0x00000000008f72d6 in BackendRun (port=0x106e740) at postmaster.c:4439
#23 0x00000000008f6c6f in BackendStartup (port=0x106e740) at postmaster.c:4167
#24 0x00000000008f363e in ServerLoop () at postmaster.c:1781
#25 0x00000000008f300e in PostmasterMain (argc=5, argv=0x103dc60) at
postmaster.c:1465
#26 0x00000000007bbfb4 in main (argc=5, argv=0x103dc60) at main.c:198
The LLVMBuildCall() in frame #6 is added by the patch that I also
mentioned in the previous replies. I haven't yet pinpointed down
which of the LLVM's asserts it is, nor have I been able to walk
through LLVM source code using gdb to figure what the new code is
doing wrong. Maybe I'm still missing a trick or two...
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
On Wed, Oct 4, 2023 at 10:26 PM Amit Langote <amitlangote09@gmail.com> wrote:
> On Tue, Oct 3, 2023 at 10:11 PM Amit Langote <amitlangote09@gmail.com> wrote:
> > On Mon, Oct 2, 2023 at 2:26 PM Amit Langote <amitlangote09@gmail.com> wrote:
> > > On Mon, Oct 2, 2023 at 1:24 PM Amit Langote <amitlangote09@gmail.com> wrote:
> > > > Pushed this 30 min ago (no email on -committers yet!) and am looking
> > > > at the following llvm crash reported by buildfarm animal pogona [1]:
> > > > This seems to me to be complaining about the following addition:
> > > >
> > > > + {
> > > > + Oid ioparam = op->d.iocoerce.typioparam;
> > > > + LLVMValueRef v_params[6];
> > > > + LLVMValueRef v_success;
> > > > +
> > > > + v_params[0] = l_ptr_const(op->d.iocoerce.finfo_in,
> > > > + l_ptr(StructFmgrInfo));
> > > > + v_params[1] = v_output;
> > > > + v_params[2] = l_oid_const(lc, ioparam);
> > > > + v_params[3] = l_int32_const(lc, -1);
> > > > + v_params[4] = l_ptr_const(op->d.iocoerce.escontext,
> > > > +
> > > > l_ptr(StructErrorSaveContext));
> > > >
> > > > - LLVMBuildStore(b, v_retval, v_resvaluep);
> > > > + /*
> > > > + * InputFunctionCallSafe() will write directly into
> > > > + * *op->resvalue.
> > > > + */
> > > > + v_params[5] = v_resvaluep;
> > > > +
> > > > + v_success = LLVMBuildCall(b, llvm_pg_func(mod,
> > > > "InputFunctionCallSafe"),
> > > > + v_params, lengthof(v_params),
> > > > + "funccall_iocoerce_in_safe");
> > > > +
> > > > + /*
> > > > + * Return null if InputFunctionCallSafe() encountered
> > > > + * an error.
> > > > + */
> > > > + v_resnullp = LLVMBuildICmp(b, LLVMIntEQ, v_success,
> > > > + l_sbool_const(0), "");
> > > > + }
> > >
> ...I haven't yet pinpointed down
> which of the LLVM's asserts it is, nor have I been able to walk
> through LLVM source code using gdb to figure what the new code is
> doing wrong. Maybe I'm still missing a trick or two...
I finally managed to analyze the crash by getting the correct LLVM build.
So the following bits are the culprits:
1. v_output needed to be converted from being reference to a Datum to
be reference to char * as follows before passing to
InputFunctionCallSafe():
- v_params[1] = v_output;
+ v_params[1] = LLVMBuildIntToPtr(b, v_output,
+
l_ptr(LLVMInt8TypeInContext(lc)),
+ "");
2. Assignment of op->d.iocoerce.escontext needed to be changed like this:
v_params[4] = l_ptr_const(op->d.iocoerce.escontext,
-
l_ptr(StructErrorSaveContext));
+ l_ptr(StructNode));
3. v_success needed to be "zero-extended" to match in type with
whatever s_bool_const() produces, as follows:
+ v_success = LLVMBuildZExt(b, v_success,
TypeStorageBool, "");
v_resnullp = LLVMBuildICmp(b, LLVMIntEQ, v_success,
l_sbool_const(0), "");
No more crashes with the above fixes.
Attached shows the delta against the patch I reverted. I'll push the
fixed up version on Monday.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
Вложения
On 2023-Oct-06, Amit Langote wrote: > 2. Assignment of op->d.iocoerce.escontext needed to be changed like this: > > v_params[4] = l_ptr_const(op->d.iocoerce.escontext, > - > l_ptr(StructErrorSaveContext)); > + l_ptr(StructNode)); Oh, so you had to go back to using StructNode in order to get this fixed? That's weird. Is it just because InputFunctionCallSafe is defined to take fmNodePtr? (I still fail to see that a pointer to ErrorSaveContext would differ in any material way from a pointer to Node). Another think I thought was weird is that it would only crash in LLVM5 debug and not the other LLVM-enabled animals, but looking closer at the buildfarm results, I think that may have been only because you reverted too quickly, and phycodorus and petalura didn't actually run with 7fbc75b26ed8 before you reverted it. Dragonet did make a run with it, but it's marked as "LLVM optimized" instead of "LLVM debug". I suppose that must be making a difference. -- Álvaro Herrera Breisgau, Deutschland — https://www.EnterpriseDB.com/ "World domination is proceeding according to plan" (Andrew Morton)
On Fri, Oct 6, 2023 at 19:01 Alvaro Herrera <alvherre@alvh.no-ip.org> wrote:
On 2023-Oct-06, Amit Langote wrote:
> 2. Assignment of op->d.iocoerce.escontext needed to be changed like this:
>
> v_params[4] = l_ptr_const(op->d.iocoerce.escontext,
> -
> l_ptr(StructErrorSaveContext));
> + l_ptr(StructNode));
Oh, so you had to go back to using StructNode in order to get this
fixed? That's weird. Is it just because InputFunctionCallSafe is
defined to take fmNodePtr? (I still fail to see that a pointer to
ErrorSaveContext would differ in any material way from a pointer to
Node).
The difference matters to LLVM’s type system, which considers Node to be a type with 1 sub-type (struct member) and ErrorSaveContext with 4 sub-types. It doesn’t seem to understand that both share the first member.
Another think I thought was weird is that it would only crash in LLVM5
debug and not the other LLVM-enabled animals, but looking closer at the
buildfarm results, I think that may have been only because you reverted
too quickly, and phycodorus and petalura didn't actually run with
7fbc75b26ed8 before you reverted it. Dragonet did make a run with it,
but it's marked as "LLVM optimized" instead of "LLVM debug". I suppose
that must be making a difference.
AFAICS, only assert-enabled LLVM builds crash.
Hi,
On 2023-09-29 13:57:46 +0900, Amit Langote wrote:
> Thanks. I will push the attached 0001 shortly.
Sorry for not looking at this earlier.
Have you done benchmarking to verify that 0001 does not cause performance
regressions? I'd not be suprised if it did. I'd split the soft-error path into
a separate opcode. For JIT it can largely be implemented using the same code,
eliding the check if it's the non-soft path. Or you can just put it into an
out-of-line function.
I don't like adding more stuff to ExprState. This one seems particularly
awkward, because it might be used by more than one level in an expression
subtree, which means you really need to save/restore old values when
recursing.
> @@ -1579,25 +1582,13 @@ ExecInitExprRec(Expr *node, ExprState *state,
>
> /* lookup the result type's input function */
> scratch.d.iocoerce.finfo_in = palloc0(sizeof(FmgrInfo));
> - scratch.d.iocoerce.fcinfo_data_in = palloc0(SizeForFunctionCallInfo(3));
> -
> getTypeInputInfo(iocoerce->resulttype,
> - &iofunc, &typioparam);
> + &iofunc, &scratch.d.iocoerce.typioparam);
> fmgr_info(iofunc, scratch.d.iocoerce.finfo_in);
> fmgr_info_set_expr((Node *) node, scratch.d.iocoerce.finfo_in);
> - InitFunctionCallInfoData(*scratch.d.iocoerce.fcinfo_data_in,
> - scratch.d.iocoerce.finfo_in,
> - 3, InvalidOid, NULL, NULL);
>
> - /*
> - * We can preload the second and third arguments for the input
> - * function, since they're constants.
> - */
> - fcinfo_in = scratch.d.iocoerce.fcinfo_data_in;
> - fcinfo_in->args[1].value = ObjectIdGetDatum(typioparam);
> - fcinfo_in->args[1].isnull = false;
> - fcinfo_in->args[2].value = Int32GetDatum(-1);
> - fcinfo_in->args[2].isnull = false;
> + /* Use the ErrorSaveContext passed by the caller. */
> + scratch.d.iocoerce.escontext = state->escontext;
>
> ExprEvalPushStep(state, &scratch);
> break;
I think it's likely that removing the optimization of not needing to set these
arguments ahead of time will result in a performance regression. Not to speak
of initializing the fcinfo from scratch on every evaluation of the expression.
I think this shouldn't not be merged as is.
> src/backend/parser/gram.y | 348 +++++-
This causes a nontrivial increase in the size of the parser (~5% in an
optimized build here), I wonder if we can do better.
> +/*
> + * Push steps to evaluate a JsonExpr and its various subsidiary expressions.
> + */
> +static void
> +ExecInitJsonExpr(JsonExpr *jexpr, ExprState *state,
> + Datum *resv, bool *resnull,
> + ExprEvalStep *scratch)
> +{
> + JsonExprState *jsestate = palloc0(sizeof(JsonExprState));
> + JsonExprPreEvalState *pre_eval = &jsestate->pre_eval;
> + ListCell *argexprlc;
> + ListCell *argnamelc;
> + int skip_step_off = -1;
> + int passing_args_step_off = -1;
> + int coercion_step_off = -1;
> + int coercion_finish_step_off = -1;
> + int behavior_step_off = -1;
> + int onempty_expr_step_off = -1;
> + int onempty_jump_step_off = -1;
> + int onerror_expr_step_off = -1;
> + int onerror_jump_step_off = -1;
> + int result_coercion_jump_step_off = -1;
> + List *adjust_jumps = NIL;
> + ListCell *lc;
> + ExprEvalStep *as;
> +
> + jsestate->jsexpr = jexpr;
> +
> + /*
> + * Add steps to compute formatted_expr, pathspec, and PASSING arg
> + * expressions as things that must be evaluated *before* the actual JSON
> + * path expression.
> + */
> + ExecInitExprRec((Expr *) jexpr->formatted_expr, state,
> + &pre_eval->formatted_expr.value,
> + &pre_eval->formatted_expr.isnull);
> + ExecInitExprRec((Expr *) jexpr->path_spec, state,
> + &pre_eval->pathspec.value,
> + &pre_eval->pathspec.isnull);
> +
> + /*
> + * Before pushing steps for PASSING args, push a step to decide whether to
> + * skip evaluating the args and the JSON path expression depending on
> + * whether either of formatted_expr and pathspec is NULL; see
> + * ExecEvalJsonExprSkip().
> + */
> + scratch->opcode = EEOP_JSONEXPR_SKIP;
> + scratch->d.jsonexpr_skip.jsestate = jsestate;
> + skip_step_off = state->steps_len;
> + ExprEvalPushStep(state, scratch);
Could SKIP be implemented using EEOP_JUMP_IF_NULL with a bit of work? I see
that it sets jsestate->post_eval.jcstate, but I don't understand why it needs
to be done that way. /* ExecEvalJsonExprCoercion() depends on this. */ doesn't
explain that much.
> + /* PASSING args. */
> + jsestate->pre_eval.args = NIL;
> + passing_args_step_off = state->steps_len;
> + forboth(argexprlc, jexpr->passing_values,
> + argnamelc, jexpr->passing_names)
> + {
> + Expr *argexpr = (Expr *) lfirst(argexprlc);
> + String *argname = lfirst_node(String, argnamelc);
> + JsonPathVariable *var = palloc(sizeof(*var));
> +
> + var->name = pstrdup(argname->sval);
Why does this need to be strdup'd?
> + /* Step for the actual JSON path evaluation; see ExecEvalJsonExpr(). */
> + scratch->opcode = EEOP_JSONEXPR_PATH;
> + scratch->d.jsonexpr.jsestate = jsestate;
> + ExprEvalPushStep(state, scratch);
> +
> + /*
> + * Step to handle ON ERROR and ON EMPTY behavior. Also, to handle errors
> + * that may occur during coercion handling.
> + *
> + * See ExecEvalJsonExprBehavior().
> + */
> + scratch->opcode = EEOP_JSONEXPR_BEHAVIOR;
> + scratch->d.jsonexpr_behavior.jsestate = jsestate;
> + behavior_step_off = state->steps_len;
> + ExprEvalPushStep(state, scratch);
From what I can tell there a) can never be a step between EEOP_JSONEXPR_PATH
and EEOP_JSONEXPR_BEHAVIOR b) EEOP_JSONEXPR_PATH ends with an unconditional
branch. What's the point of the two different steps here?
>
> + EEO_CASE(EEOP_JSONEXPR_PATH)
> + {
> + /* too complex for an inline implementation */
> + ExecEvalJsonExpr(state, op, econtext);
> + EEO_NEXT();
> + }
Why does EEOP_JSONEXPR_PATH call ExecEvalJsonExpr, the names don't match...
> + EEO_CASE(EEOP_JSONEXPR_SKIP)
> + {
> + /* too complex for an inline implementation */
> + EEO_JUMP(ExecEvalJsonExprSkip(state, op));
> + }
...
> + EEO_CASE(EEOP_JSONEXPR_COERCION_FINISH)
> + {
> + /* too complex for an inline implementation */
> + EEO_JUMP(ExecEvalJsonExprCoercionFinish(state, op));
> + }
This seems to just return op->d.jsonexpr_coercion_finish.jump_coercion_error
or op->d.jsonexpr_coercion_finish.jump_coercion_done. Which makes me think
it'd be better to return a boolean? Particularly because that's how you
already implemented it for JIT (except that you did it by hardcoding the jump
step to compare to, which seems odd).
Separately, why do we even need a jump for both cases, and not just for the
error case?
> + EEO_CASE(EEOP_JSONEXPR_BEHAVIOR)
> + {
> + /* too complex for an inline implementation */
> + EEO_JUMP(ExecEvalJsonExprBehavior(state, op));
> + }
> +
> + EEO_CASE(EEOP_JSONEXPR_COERCION)
> + {
> + /* too complex for an inline implementation */
> + EEO_JUMP(ExecEvalJsonExprCoercion(state, op, econtext,
> + *op->resvalue, *op->resnull));
> + }
I wonder if this is the right design for this op - you're declaring this to be
op not worth implementing inline, yet you then have it implemented by hand for JIT.
> +/*
> + * Evaluate given JsonExpr by performing the specified JSON operation.
> + *
> + * This also populates the JsonExprPostEvalState with the information needed
> + * by the subsequent steps that handle the specified JsonBehavior.
> + */
> +void
> +ExecEvalJsonExpr(ExprState *state, ExprEvalStep *op, ExprContext *econtext)
> +{
> + JsonExprState *jsestate = op->d.jsonexpr.jsestate;
> + JsonExprPreEvalState *pre_eval = &jsestate->pre_eval;
> + JsonExprPostEvalState *post_eval = &jsestate->post_eval;
> + JsonExpr *jexpr = jsestate->jsexpr;
> + Datum item;
> + Datum res = (Datum) 0;
> + bool resnull = true;
> + JsonPath *path;
> + bool throw_error = (jexpr->on_error->btype == JSON_BEHAVIOR_ERROR);
> + bool *error = &post_eval->error;
> + bool *empty = &post_eval->empty;
> +
> + item = pre_eval->formatted_expr.value;
> + path = DatumGetJsonPathP(pre_eval->pathspec.value);
> +
> + /* Reset JsonExprPostEvalState for this evaluation. */
> + memset(post_eval, 0, sizeof(*post_eval));
> +
> + switch (jexpr->op)
> + {
> + case JSON_EXISTS_OP:
> + {
> + bool exists = JsonPathExists(item, path,
> + !throw_error ? error : NULL,
> + pre_eval->args);
> +
> + post_eval->jcstate = jsestate->result_jcstate;
> + if (*error)
> + {
> + *op->resnull = true;
> + *op->resvalue = (Datum) 0;
> + return;
> + }
> +
> + resnull = false;
> + res = BoolGetDatum(exists);
> + break;
> + }
Kinda seems there should be a EEOP_JSON_EXISTS/JSON_QUERY_OP op, instead of
implementing it all inside ExecEvalJsonExpr. I think this might obsolete
needing to rediscover that the value is null in SKIP etc?
> + case JSON_QUERY_OP:
> + res = JsonPathQuery(item, path, jexpr->wrapper, empty,
> + !throw_error ? error : NULL,
> + pre_eval->args);
> +
> + post_eval->jcstate = jsestate->result_jcstate;
> + if (*error)
> + {
> + *op->resnull = true;
> + *op->resvalue = (Datum) 0;
> + return;
> + }
> + resnull = !DatumGetPointer(res);
Shoulnd't this check empty?
FWIW, it's also pretty odd that JsonPathQuery() once
return (Datum) 0;
and later does
return PointerGetDatum(NULL);
> + case JSON_VALUE_OP:
> + {
> + JsonbValue *jbv = JsonPathValue(item, path, empty,
> + !throw_error ? error : NULL,
> + pre_eval->args);
> +
> + /* Might get overridden below by an item_jcstate. */
> + post_eval->jcstate = jsestate->result_jcstate;
> + if (*error)
> + {
> + *op->resnull = true;
> + *op->resvalue = (Datum) 0;
> + return;
> + }
> +
> + if (!jbv) /* NULL or empty */
> + {
> + resnull = true;
> + break;
> + }
> +
> + Assert(!*empty);
> +
> + resnull = false;
> +
> + /* Coerce scalar item to the output type */
> +
> + /*
> + * If the requested output type is json(b), use
> + * JsonExprState.result_coercion to do the coercion.
> + */
> + if (jexpr->returning->typid == JSONOID ||
> + jexpr->returning->typid == JSONBOID)
> + {
> + /* Use result_coercion from json[b] to the output type */
> + res = JsonbPGetDatum(JsonbValueToJsonb(jbv));
> + break;
> + }
> +
> + /*
> + * Else, use one of the item_coercions.
> + *
> + * Error out if no cast exists to coerce SQL/JSON item to the
> + * the output type.
> + */
> + res = ExecPrepareJsonItemCoercion(jbv,
> + jsestate->item_jcstates,
> + &post_eval->jcstate);
> + if (post_eval->jcstate &&
> + post_eval->jcstate->coercion &&
> + (post_eval->jcstate->coercion->via_io ||
> + post_eval->jcstate->coercion->via_populate))
> + {
> + if (!throw_error)
> + {
> + *op->resnull = true;
> + *op->resvalue = (Datum) 0;
> + return;
> + }
> +
> + /*
> + * Coercion via I/O means here that the cast to the target
> + * type simply does not exist.
> + */
> + ereport(ERROR,
> + (errcode(ERRCODE_SQL_JSON_ITEM_CANNOT_BE_CAST_TO_TARGET_TYPE),
> + errmsg("SQL/JSON item cannot be cast to target type")));
> + }
> + break;
> + }
> +
> + default:
> + elog(ERROR, "unrecognized SQL/JSON expression op %d", jexpr->op);
> + *op->resnull = true;
> + *op->resvalue = (Datum) 0;
> + return;
> + }
> +
> + /*
> + * If the ON EMPTY behavior is to cause an error, do so here. Other
> + * behaviors will be handled in ExecEvalJsonExprBehavior().
> + */
> + if (*empty)
> + {
> + Assert(jexpr->on_empty); /* it is not JSON_EXISTS */
> +
> + if (jexpr->on_empty->btype == JSON_BEHAVIOR_ERROR)
> + {
> + if (!throw_error)
> + {
> + *op->resnull = true;
> + *op->resvalue = (Datum) 0;
> + return;
> + }
> +
> + ereport(ERROR,
> + (errcode(ERRCODE_NO_SQL_JSON_ITEM),
> + errmsg("no SQL/JSON item")));
> + }
> + }
> +
> + *op->resvalue = res;
> + *op->resnull = resnull;
> +}
> +
> +/*
> + * Skip calling ExecEvalJson() on the given JsonExpr?
I don't think that function exists.
> + * Returns the step address to be performed next.
> + */
> +int
> +ExecEvalJsonExprSkip(ExprState *state, ExprEvalStep *op)
> +{
> + JsonExprState *jsestate = op->d.jsonexpr_skip.jsestate;
> +
> + /*
> + * Skip if either of the input expressions has turned out to be NULL,
> + * though do execute domain checks for NULLs, which are handled by the
> + * coercion step.
> + */
> + if (jsestate->pre_eval.formatted_expr.isnull ||
> + jsestate->pre_eval.pathspec.isnull)
> + {
> + *op->resvalue = (Datum) 0;
> + *op->resnull = true;
> +
> + /* ExecEvalJsonExprCoercion() depends on this. */
> + jsestate->post_eval.jcstate = jsestate->result_jcstate;
> +
> + return op->d.jsonexpr_skip.jump_coercion;
> + }
> +
> + /*
> + * Go evaluate the PASSING args if any and subsequently JSON path itself.
> + */
> + return op->d.jsonexpr_skip.jump_passing_args;
> +}
> +
> +/*
> + * Returns the step address to perform the JsonBehavior applicable to
> + * the JSON item that resulted from evaluating the given JsonExpr.
> + *
> + * Returns the step address to be performed next.
> + */
> +int
> +ExecEvalJsonExprBehavior(ExprState *state, ExprEvalStep *op)
> +{
> + JsonExprState *jsestate = op->d.jsonexpr_behavior.jsestate;
> + JsonExprPostEvalState *post_eval = &jsestate->post_eval;
> + JsonBehavior *behavior = NULL;
> + int jump_to = -1;
> +
> + if (post_eval->error || post_eval->coercion_error)
> + {
> + behavior = jsestate->jsexpr->on_error;
> + jump_to = op->d.jsonexpr_behavior.jump_onerror_expr;
> + }
> + else if (post_eval->empty)
> + {
> + behavior = jsestate->jsexpr->on_empty;
> + jump_to = op->d.jsonexpr_behavior.jump_onempty_expr;
> + }
> + else if (!post_eval->coercion_done)
> + {
> + /*
> + * If no error or the JSON item is not empty, directly go to the
> + * coercion step to coerce the item as is.
> + */
> + return op->d.jsonexpr_behavior.jump_coercion;
> + }
> +
> + Assert(behavior);
> +
> + /*
> + * Set up for coercion step that will run to coerce a non-default behavior
> + * value. It should use result_coercion, if any. Errors that may occur
> + * should be thrown for JSON ops other than JSON_VALUE_OP.
> + */
> + if (behavior->btype != JSON_BEHAVIOR_DEFAULT)
> + {
> + post_eval->jcstate = jsestate->result_jcstate;
> + post_eval->coercing_behavior_expr = true;
> + }
> +
> + Assert(jump_to >= 0);
> + return jump_to;
> +}
> +
> +/*
> + * Evaluate or return the step address to evaluate a coercion of a JSON item
> + * to the target type. The former if the coercion must be done right away by
> + * calling the target type's input function, and for some types, by calling
> + * json_populate_type().
> + *
> + * Returns the step address to be performed next.
> + */
> +int
> +ExecEvalJsonExprCoercion(ExprState *state, ExprEvalStep *op,
> + ExprContext *econtext,
> + Datum res, bool resnull)
> +{
> + JsonExprState *jsestate = op->d.jsonexpr_coercion.jsestate;
> + JsonExpr *jexpr = jsestate->jsexpr;
> + JsonExprPostEvalState *post_eval = &jsestate->post_eval;
> + JsonCoercionState *jcstate = post_eval->jcstate;
> + char *val_string = NULL;
> + bool omit_quotes = false;
> +
> + switch (jexpr->op)
> + {
> + case JSON_EXISTS_OP:
> + if (jcstate && jcstate->jump_eval_expr >= 0)
> + return jcstate->jump_eval_expr;
Shouldn't this be a compile-time check and instead be handled by simply not
emitting a step instead?
> + /* No coercion needed. */
> + post_eval->coercion_done = true;
> + return op->d.jsonexpr_coercion.jump_coercion_done;
Which then means we also don't need to emit anything here, no?
> +/*
> + * Prepare SQL/JSON item coercion to the output type. Returned a datum of the
> + * corresponding SQL type and a pointer to the coercion state.
> + */
> +static Datum
> +ExecPrepareJsonItemCoercion(JsonbValue *item, List *item_jcstates,
> + JsonCoercionState **p_item_jcstate)
I might have missed it, but if not: The whole way the coercion stuff works
needs a decent comment explaining how things fit together.
What does "item" really mean here?
> +{
> + JsonCoercionState *item_jcstate;
> + Datum res;
> + JsonbValue buf;
> +
> + if (item->type == jbvBinary &&
> + JsonContainerIsScalar(item->val.binary.data))
> + {
> + bool res PG_USED_FOR_ASSERTS_ONLY;
> +
> + res = JsonbExtractScalar(item->val.binary.data, &buf);
> + item = &buf;
> + Assert(res);
> + }
> +
> + /* get coercion state reference and datum of the corresponding SQL type */
> + switch (item->type)
> + {
> + case jbvNull:
> + item_jcstate = list_nth(item_jcstates, JsonItemTypeNull);
This seems quite odd. We apparently have a fixed-length array, where specific
offsets have specific meanings, yet it's encoded as a list that's then
accessed with constant offsets?
Right now ExecEvalJsonExpr() stores what ExecPrepareJsonItemCoercion() chooses
in post_eval->jcstate. Which the immediately following
ExecEvalJsonExprBehavior() then digs out again. Then there's also control flow
via post_eval->coercing_behavior_expr. This is ... not nice.
ISTM that jsestate should have an array of jump targets, indexed by
item->type. Which, for llvm IR, you can encode as a switch statement, instead
of doing control flow via JsonExprState/JsonExprPostEvalState. There's
obviously a bit more needed, but I think something like that should work, and
simplify things a fair bit.
> @@ -15711,6 +15721,192 @@ func_expr_common_subexpr:
> n->location = @1;
> $$ = (Node *) n;
> }
> + | JSON_QUERY '('
> + json_api_common_syntax
> + json_returning_clause_opt
> + json_wrapper_behavior
> + json_quotes_clause_opt
> + ')'
> + {
> + JsonFuncExpr *n = makeNode(JsonFuncExpr);
> +
> + n->op = JSON_QUERY_OP;
> + n->common = (JsonCommon *) $3;
> + n->output = (JsonOutput *) $4;
> + n->wrapper = $5;
> + if (n->wrapper != JSW_NONE && $6 != JS_QUOTES_UNSPEC)
> + ereport(ERROR,
> + (errcode(ERRCODE_SYNTAX_ERROR),
> + errmsg("SQL/JSON QUOTES behavior must not be specified when WITH WRAPPER is
used"),
> + parser_errposition(@6)));
> + n->quotes = $6;
> + n->location = @1;
> + $$ = (Node *) n;
> + }
> + | JSON_QUERY '('
> + json_api_common_syntax
> + json_returning_clause_opt
> + json_wrapper_behavior
> + json_quotes_clause_opt
> + json_query_behavior ON EMPTY_P
> + ')'
> + {
> + JsonFuncExpr *n = makeNode(JsonFuncExpr);
> +
> + n->op = JSON_QUERY_OP;
> + n->common = (JsonCommon *) $3;
> + n->output = (JsonOutput *) $4;
> + n->wrapper = $5;
> + if (n->wrapper != JSW_NONE && $6 != JS_QUOTES_UNSPEC)
> + ereport(ERROR,
> + (errcode(ERRCODE_SYNTAX_ERROR),
> + errmsg("SQL/JSON QUOTES behavior must not be specified when WITH WRAPPER is
used"),
> + parser_errposition(@6)));
> + n->quotes = $6;
> + n->on_empty = $7;
> + n->location = @1;
> + $$ = (Node *) n;
> + }
> + | JSON_QUERY '('
> + json_api_common_syntax
> + json_returning_clause_opt
> + json_wrapper_behavior
> + json_quotes_clause_opt
> + json_query_behavior ON ERROR_P
> + ')'
> + {
> + JsonFuncExpr *n = makeNode(JsonFuncExpr);
> +
> + n->op = JSON_QUERY_OP;
> + n->common = (JsonCommon *) $3;
> + n->output = (JsonOutput *) $4;
> + n->wrapper = $5;
> + if (n->wrapper != JSW_NONE && $6 != JS_QUOTES_UNSPEC)
> + ereport(ERROR,
> + (errcode(ERRCODE_SYNTAX_ERROR),
> + errmsg("SQL/JSON QUOTES behavior must not be specified when WITH WRAPPER is
used"),
> + parser_errposition(@6)));
> + n->quotes = $6;
> + n->on_error = $7;
> + n->location = @1;
> + $$ = (Node *) n;
> + }
> + | JSON_QUERY '('
> + json_api_common_syntax
> + json_returning_clause_opt
> + json_wrapper_behavior
> + json_quotes_clause_opt
> + json_query_behavior ON EMPTY_P
> + json_query_behavior ON ERROR_P
> + ')'
> + {
> + JsonFuncExpr *n = makeNode(JsonFuncExpr);
> +
> + n->op = JSON_QUERY_OP;
> + n->common = (JsonCommon *) $3;
> + n->output = (JsonOutput *) $4;
> + n->wrapper = $5;
> + if (n->wrapper != JSW_NONE && $6 != JS_QUOTES_UNSPEC)
> + ereport(ERROR,
> + (errcode(ERRCODE_SYNTAX_ERROR),
> + errmsg("SQL/JSON QUOTES behavior must not be specified when WITH WRAPPER is
used"),
> + parser_errposition(@6)));
> + n->quotes = $6;
> + n->on_empty = $7;
> + n->on_error = $10;
> + n->location = @1;
> + $$ = (Node *) n;
> + }
I'm sure we can find a way to deduplicate this.
> + | JSON_EXISTS '('
> + json_api_common_syntax
> + json_returning_clause_opt
> + ')'
> + {
> + JsonFuncExpr *p = makeNode(JsonFuncExpr);
> +
> + p->op = JSON_EXISTS_OP;
> + p->common = (JsonCommon *) $3;
> + p->output = (JsonOutput *) $4;
> + p->location = @1;
> + $$ = (Node *) p;
> + }
> + | JSON_EXISTS '('
> + json_api_common_syntax
> + json_returning_clause_opt
> + json_exists_behavior ON ERROR_P
> + ')'
> + {
> + JsonFuncExpr *p = makeNode(JsonFuncExpr);
> +
> + p->op = JSON_EXISTS_OP;
> + p->common = (JsonCommon *) $3;
> + p->output = (JsonOutput *) $4;
> + p->on_error = $5;
> + p->location = @1;
> + $$ = (Node *) p;
> + }
> + | JSON_VALUE '('
> + json_api_common_syntax
> + json_returning_clause_opt
> + ')'
> + {
> + JsonFuncExpr *n = makeNode(JsonFuncExpr);
> +
> + n->op = JSON_VALUE_OP;
> + n->common = (JsonCommon *) $3;
> + n->output = (JsonOutput *) $4;
> + n->location = @1;
> + $$ = (Node *) n;
> + }
> +
> + | JSON_VALUE '('
> + json_api_common_syntax
> + json_returning_clause_opt
> + json_value_behavior ON EMPTY_P
> + ')'
> + {
> + JsonFuncExpr *n = makeNode(JsonFuncExpr);
> +
> + n->op = JSON_VALUE_OP;
> + n->common = (JsonCommon *) $3;
> + n->output = (JsonOutput *) $4;
> + n->on_empty = $5;
> + n->location = @1;
> + $$ = (Node *) n;
> + }
> + | JSON_VALUE '('
> + json_api_common_syntax
> + json_returning_clause_opt
> + json_value_behavior ON ERROR_P
> + ')'
> + {
> + JsonFuncExpr *n = makeNode(JsonFuncExpr);
> +
> + n->op = JSON_VALUE_OP;
> + n->common = (JsonCommon *) $3;
> + n->output = (JsonOutput *) $4;
> + n->on_error = $5;
> + n->location = @1;
> + $$ = (Node *) n;
> + }
> +
> + | JSON_VALUE '('
> + json_api_common_syntax
> + json_returning_clause_opt
> + json_value_behavior ON EMPTY_P
> + json_value_behavior ON ERROR_P
> + ')'
> + {
> + JsonFuncExpr *n = makeNode(JsonFuncExpr);
> +
> + n->op = JSON_VALUE_OP;
> + n->common = (JsonCommon *) $3;
> + n->output = (JsonOutput *) $4;
> + n->on_empty = $5;
> + n->on_error = $8;
> + n->location = @1;
> + $$ = (Node *) n;
> + }
> ;
And this.
> +json_query_behavior:
> + ERROR_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_ERROR, NULL, @1); }
> + | NULL_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_NULL, NULL, @1); }
> + | DEFAULT a_expr { $$ = makeJsonBehavior(JSON_BEHAVIOR_DEFAULT, $2, @1); }
> + | EMPTY_P ARRAY { $$ = makeJsonBehavior(JSON_BEHAVIOR_EMPTY_ARRAY, NULL, @1); }
> + | EMPTY_P OBJECT_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_EMPTY_OBJECT, NULL, @1); }
> + /* non-standard, for Oracle compatibility only */
> + | EMPTY_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_EMPTY_ARRAY, NULL, @1); }
> + ;
> +json_exists_behavior:
> + ERROR_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_ERROR, NULL, @1); }
> + | TRUE_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_TRUE, NULL, @1); }
> + | FALSE_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_FALSE, NULL, @1); }
> + | UNKNOWN { $$ = makeJsonBehavior(JSON_BEHAVIOR_UNKNOWN, NULL, @1); }
> + ;
> +
> +json_value_behavior:
> + NULL_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_NULL, NULL, @1); }
> + | ERROR_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_ERROR, NULL, @1); }
> + | DEFAULT a_expr { $$ = makeJsonBehavior(JSON_BEHAVIOR_DEFAULT, $2, @1); }
> + ;
This also seems like it could use some dedup.
Greetings,
Andres Freund
On 2023-Oct-06, Andres Freund wrote:
> > +json_query_behavior:
> > + ERROR_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_ERROR, NULL, @1); }
> > + | NULL_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_NULL, NULL, @1); }
> > + | DEFAULT a_expr { $$ = makeJsonBehavior(JSON_BEHAVIOR_DEFAULT, $2, @1); }
> > + | EMPTY_P ARRAY { $$ = makeJsonBehavior(JSON_BEHAVIOR_EMPTY_ARRAY, NULL, @1); }
> > + | EMPTY_P OBJECT_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_EMPTY_OBJECT, NULL, @1); }
> > + /* non-standard, for Oracle compatibility only */
> > + | EMPTY_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_EMPTY_ARRAY, NULL, @1); }
> > + ;
>
> > +json_exists_behavior:
> > + ERROR_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_ERROR, NULL, @1); }
> > + | TRUE_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_TRUE, NULL, @1); }
> > + | FALSE_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_FALSE, NULL, @1); }
> > + | UNKNOWN { $$ = makeJsonBehavior(JSON_BEHAVIOR_UNKNOWN, NULL, @1); }
> > + ;
> > +
> > +json_value_behavior:
> > + NULL_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_NULL, NULL, @1); }
> > + | ERROR_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_ERROR, NULL, @1); }
> > + | DEFAULT a_expr { $$ = makeJsonBehavior(JSON_BEHAVIOR_DEFAULT, $2, @1); }
> > + ;
>
> This also seems like it could use some dedup.
Yeah, I was looking at this the other day and thinking that we should
just have a single json_behavior that's used by all these productions;
at runtime we can check whether a value has been used that's improper
for that particular node, and error out with a syntax error or some
such.
Other parts of the grammar definitely needs more work, too. It appears
to me that they were written by looking at what the standard says, more
or less literally.
--
Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/
"Someone said that it is at least an order of magnitude more work to do
production software than a prototype. I think he is wrong by at least
an order of magnitude." (Brian Kernighan)
Hi Andres,
On Sat, Oct 7, 2023 at 6:49 AM Andres Freund <andres@anarazel.de> wrote:
> Hi,
>
> On 2023-09-29 13:57:46 +0900, Amit Langote wrote:
> > Thanks. I will push the attached 0001 shortly.
>
> Sorry for not looking at this earlier.
Thanks for the review. Replying here only to your comments on 0001.
> Have you done benchmarking to verify that 0001 does not cause performance
> regressions? I'd not be suprised if it did.
I found that it indeed did once I benchmarked with something that
would stress EEOP_IOCOERCE:
do $$
begin
for i in 1..20000000 loop
i := i::text;
end loop; end; $$ language plpgsql;
DO
Times and perf report:
HEAD:
Time: 1815.824 ms (00:01.816)
Time: 1818.980 ms (00:01.819)
Time: 1695.555 ms (00:01.696)
Time: 1762.022 ms (00:01.762)
--97.49%--exec_stmts
|
--85.97%--exec_assign_expr
|
|--65.56%--exec_eval_expr
| |
| |--53.71%--ExecInterpExpr
| | |
| | |--14.14%--textin
Patched:
Time: 1872.469 ms (00:01.872)
Time: 1927.371 ms (00:01.927)
Time: 1910.126 ms (00:01.910)
Time: 1948.322 ms (00:01.948)
--97.70%--exec_stmts
|
--88.13%--exec_assign_expr
|
|--73.27%--exec_eval_expr
| |
| |--58.29%--ExecInterpExpr
| | |
| |
|--25.69%--InputFunctionCallSafe
| | | |
| | |
|--14.75%--textin
So, yes, putting InputFunctionCallSafe() in the common path may not
have been such a good idea.
> I'd split the soft-error path into
> a separate opcode. For JIT it can largely be implemented using the same code,
> eliding the check if it's the non-soft path. Or you can just put it into an
> out-of-line function.
Do you mean putting the execExprInterp.c code for the soft-error path
(with a new opcode) into an out-of-line function? That definitely
makes the JIT version a tad simpler than if the error-checking is done
in-line.
So, the existing code for EEOP_IOCOERCE in both execExprInterp.c and
llvmjit_expr.c will remain unchanged. Also, I can write the code for
the new opcode such that it doesn't use InputFunctionCallSafe() at
runtime, but rather passes the ErrorSaveContext directly by putting
that in the input function's FunctionCallInfo.context and checking
SOFT_ERROR_OCCURRED() directly. That will have less overhead.
> I don't like adding more stuff to ExprState. This one seems particularly
> awkward, because it might be used by more than one level in an expression
> subtree, which means you really need to save/restore old values when
> recursing.
Hmm, I'd think that all levels will follow either soft or non-soft
error mode, so sharing the ErrorSaveContext passed via ExprState
doesn't look wrong to me. IOW, there's only one value, not one for
every level, so there doesn't appear to be any need to have the
save/restore convention as we have for innermost_domainval et al.
I can see your point that adding another 8 bytes at the end of
ExprState might be undesirable. Note though that ExprState.escontext
is only accessed in the ExecInitExpr phase, but during evaluation.
The alternative to not passing the ErrorSaveContext via ExprState is
to add a new parameter to ExecInitExprRec() and to functions that call
it. The footprint would be much larger though. Would you rather
prefer that?
> > @@ -1579,25 +1582,13 @@ ExecInitExprRec(Expr *node, ExprState *state,
> >
> > /* lookup the result type's input function */
> > scratch.d.iocoerce.finfo_in = palloc0(sizeof(FmgrInfo));
> > - scratch.d.iocoerce.fcinfo_data_in = palloc0(SizeForFunctionCallInfo(3));
> > -
> > getTypeInputInfo(iocoerce->resulttype,
> > - &iofunc, &typioparam);
> > + &iofunc, &scratch.d.iocoerce.typioparam);
> > fmgr_info(iofunc, scratch.d.iocoerce.finfo_in);
> > fmgr_info_set_expr((Node *) node, scratch.d.iocoerce.finfo_in);
> > - InitFunctionCallInfoData(*scratch.d.iocoerce.fcinfo_data_in,
> > - scratch.d.iocoerce.finfo_in,
> > - 3, InvalidOid, NULL, NULL);
> >
> > - /*
> > - * We can preload the second and third arguments for the input
> > - * function, since they're constants.
> > - */
> > - fcinfo_in = scratch.d.iocoerce.fcinfo_data_in;
> > - fcinfo_in->args[1].value = ObjectIdGetDatum(typioparam);
> > - fcinfo_in->args[1].isnull = false;
> > - fcinfo_in->args[2].value = Int32GetDatum(-1);
> > - fcinfo_in->args[2].isnull = false;
> > + /* Use the ErrorSaveContext passed by the caller. */
> > + scratch.d.iocoerce.escontext = state->escontext;
> >
> > ExprEvalPushStep(state, &scratch);
> > break;
>
> I think it's likely that removing the optimization of not needing to set these
> arguments ahead of time will result in a performance regression. Not to speak
> of initializing the fcinfo from scratch on every evaluation of the expression.
Yes, that's not good. I agree with separating out the soft-error path.
I'll post the patch and benchmarking results with the new patch shortly.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
On Wed, Oct 11, 2023 at 2:08 PM Amit Langote <amitlangote09@gmail.com> wrote: > On Sat, Oct 7, 2023 at 6:49 AM Andres Freund <andres@anarazel.de> wrote: > > On 2023-09-29 13:57:46 +0900, Amit Langote wrote: > > > Thanks. I will push the attached 0001 shortly. > > > > Sorry for not looking at this earlier. > > Thanks for the review. Replying here only to your comments on 0001. > > > Have you done benchmarking to verify that 0001 does not cause performance > > regressions? I'd not be suprised if it did. > > I found that it indeed did once I benchmarked with something that > would stress EEOP_IOCOERCE: > > do $$ > begin > for i in 1..20000000 loop > i := i::text; > end loop; end; $$ language plpgsql; > DO > > Times and perf report: > > HEAD: > > Time: 1815.824 ms (00:01.816) > Time: 1818.980 ms (00:01.819) > Time: 1695.555 ms (00:01.696) > Time: 1762.022 ms (00:01.762) > > --97.49%--exec_stmts > | > --85.97%--exec_assign_expr > | > |--65.56%--exec_eval_expr > | | > | |--53.71%--ExecInterpExpr > | | | > | | |--14.14%--textin > > > Patched: > > Time: 1872.469 ms (00:01.872) > Time: 1927.371 ms (00:01.927) > Time: 1910.126 ms (00:01.910) > Time: 1948.322 ms (00:01.948) > > --97.70%--exec_stmts > | > --88.13%--exec_assign_expr > | > |--73.27%--exec_eval_expr > | | > | |--58.29%--ExecInterpExpr > | | | > | | > |--25.69%--InputFunctionCallSafe > | | | | > | | | > |--14.75%--textin > > So, yes, putting InputFunctionCallSafe() in the common path may not > have been such a good idea. > > > I'd split the soft-error path into > > a separate opcode. For JIT it can largely be implemented using the same code, > > eliding the check if it's the non-soft path. Or you can just put it into an > > out-of-line function. > > Do you mean putting the execExprInterp.c code for the soft-error path > (with a new opcode) into an out-of-line function? That definitely > makes the JIT version a tad simpler than if the error-checking is done > in-line. > > So, the existing code for EEOP_IOCOERCE in both execExprInterp.c and > llvmjit_expr.c will remain unchanged. Also, I can write the code for > the new opcode such that it doesn't use InputFunctionCallSafe() at > runtime, but rather passes the ErrorSaveContext directly by putting > that in the input function's FunctionCallInfo.context and checking > SOFT_ERROR_OCCURRED() directly. That will have less overhead. > > > I don't like adding more stuff to ExprState. This one seems particularly > > awkward, because it might be used by more than one level in an expression > > subtree, which means you really need to save/restore old values when > > recursing. > > Hmm, I'd think that all levels will follow either soft or non-soft > error mode, so sharing the ErrorSaveContext passed via ExprState > doesn't look wrong to me. IOW, there's only one value, not one for > every level, so there doesn't appear to be any need to have the > save/restore convention as we have for innermost_domainval et al. > > I can see your point that adding another 8 bytes at the end of > ExprState might be undesirable. Note though that ExprState.escontext > is only accessed in the ExecInitExpr phase, but during evaluation. > > The alternative to not passing the ErrorSaveContext via ExprState is > to add a new parameter to ExecInitExprRec() and to functions that call > it. The footprint would be much larger though. Would you rather > prefer that? > > > > @@ -1579,25 +1582,13 @@ ExecInitExprRec(Expr *node, ExprState *state, > > > > > > /* lookup the result type's input function */ > > > scratch.d.iocoerce.finfo_in = palloc0(sizeof(FmgrInfo)); > > > - scratch.d.iocoerce.fcinfo_data_in = palloc0(SizeForFunctionCallInfo(3)); > > > - > > > getTypeInputInfo(iocoerce->resulttype, > > > - &iofunc, &typioparam); > > > + &iofunc, &scratch.d.iocoerce.typioparam); > > > fmgr_info(iofunc, scratch.d.iocoerce.finfo_in); > > > fmgr_info_set_expr((Node *) node, scratch.d.iocoerce.finfo_in); > > > - InitFunctionCallInfoData(*scratch.d.iocoerce.fcinfo_data_in, > > > - scratch.d.iocoerce.finfo_in, > > > - 3, InvalidOid, NULL, NULL); > > > > > > - /* > > > - * We can preload the second and third arguments for the input > > > - * function, since they're constants. > > > - */ > > > - fcinfo_in = scratch.d.iocoerce.fcinfo_data_in; > > > - fcinfo_in->args[1].value = ObjectIdGetDatum(typioparam); > > > - fcinfo_in->args[1].isnull = false; > > > - fcinfo_in->args[2].value = Int32GetDatum(-1); > > > - fcinfo_in->args[2].isnull = false; > > > + /* Use the ErrorSaveContext passed by the caller. */ > > > + scratch.d.iocoerce.escontext = state->escontext; > > > > > > ExprEvalPushStep(state, &scratch); > > > break; > > > > I think it's likely that removing the optimization of not needing to set these > > arguments ahead of time will result in a performance regression. Not to speak > > of initializing the fcinfo from scratch on every evaluation of the expression. > > Yes, that's not good. I agree with separating out the soft-error path. > > I'll post the patch and benchmarking results with the new patch shortly. So here's 0001, rewritten to address the above comments. It adds a new eval opcode EEOP_IOCOERCE_SAFE, which basically copies the implementation of EEOP_IOCOERCE but passes the ErrorSaveContext passed by the caller to the input function via the latter's FunctionCallInfo.context. However, unlike EEOP_IOCOERCE, it's implemented in a separate function to encapsulate away the logic of returning NULL when an error occurs. This makes JITing much simpler, because it now involves simply calling the function. Here are the benchmark results: Same DO block: do $$ begin for i in 1..20000000 loop i := i::text; end loop; end; $$ language plpgsql; HEAD: Time: 1629.461 ms (00:01.629) Time: 1635.439 ms (00:01.635) Time: 1634.432 ms (00:01.634) Patched: Time: 1657.657 ms (00:01.658) Time: 1686.779 ms (00:01.687) Time: 1626.985 ms (00:01.627) Using the SQL/JSON query functions patch rebased over the new 0001, I also compared the difference in performance between EEOP_IOCOERCE and EEOP_IOCOERCE_SAFE: -- uses EEOP_IOCOERCE because ERROR ON ERROR do $$ begin for i in 1..20000000 loop i := JSON_VALUE(jsonb '1', '$' RETURNING text ERROR ON ERROR ); end loop; end; $$ language plpgsql; -- uses EEOP_IOCOERCE because ERROR ON ERROR do $$ begin for i in 1..20000000 loop i := JSON_VALUE(jsonb '1', '$' RETURNING text ERROR ON ERROR ); end loop; end; $$ language plpgsql; Time: 2960.434 ms (00:02.960) Time: 2968.895 ms (00:02.969) Time: 3006.691 ms (00:03.007) -- uses EEOP_IOCOERCE_SAFE because NULL ON ERROR do $$ begin for i in 1..20000000 loop i := JSON_VALUE(jsonb '1', '$' RETURNING text NULL ON ERROR); end loop; end; $$ language plpgsql; Time: 3046.933 ms (00:03.047) Time: 3073.385 ms (00:03.073) Time: 3121.619 ms (00:03.122) There's only a slight degradation with the SAFE variant presumably due to the extra whether-error-occurred check after calling the input function. I'd think the difference would have been more pronounced had I continued to use InputFunctionCallSafe(). -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
Hi!
With the latest set of patches we encountered failure with the following query:
postgres@postgres=# SELECT JSON_QUERY(jsonpath '"aaa"', '$' RETURNING text);
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
The connection to the server was lost. Attempting reset: Failed.
The connection to the server was lost. Attempting reset: Failed.
Time: 11.165 ms
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
The connection to the server was lost. Attempting reset: Failed.
The connection to the server was lost. Attempting reset: Failed.
Time: 11.165 ms
A colleague of mine, Anton Melnikov, proposed the following changes which slightly
alter coercion functions to process this kind of error correctly.
Please check attached patch set.
--
Вложения
Hi,
Also FYI - the following case results in segmentation fault:
postgres@postgres=# CREATE TABLE test_jsonb_constraints (
js text,
i int,
x jsonb DEFAULT JSON_QUERY(jsonb '[1,2]', '$[*]' WITH WRAPPER)
CONSTRAINT test_jsonb_constraint1
CHECK (js IS JSON)
CONSTRAINT test_jsonb_constraint5
CHECK (JSON_QUERY(js::jsonb, '$.mm' RETURNING char(5) OMIT QUOTES EMPTY ARRAY ON EMPTY) > 'a' COLLATE "C")
CONSTRAINT test_jsonb_constraint6
CHECK (JSON_EXISTS(js::jsonb, 'strict $.a' RETURNING int TRUE ON ERROR) < 2)
);
CREATE TABLE
Time: 13.518 ms
postgres@postgres=# INSERT INTO test_jsonb_constraints VALUES ('[]');
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
The connection to the server was lost. Attempting reset: Failed.
The connection to the server was lost. Attempting reset: Failed.
Time: 6.858 ms
@!>
js text,
i int,
x jsonb DEFAULT JSON_QUERY(jsonb '[1,2]', '$[*]' WITH WRAPPER)
CONSTRAINT test_jsonb_constraint1
CHECK (js IS JSON)
CONSTRAINT test_jsonb_constraint5
CHECK (JSON_QUERY(js::jsonb, '$.mm' RETURNING char(5) OMIT QUOTES EMPTY ARRAY ON EMPTY) > 'a' COLLATE "C")
CONSTRAINT test_jsonb_constraint6
CHECK (JSON_EXISTS(js::jsonb, 'strict $.a' RETURNING int TRUE ON ERROR) < 2)
);
CREATE TABLE
Time: 13.518 ms
postgres@postgres=# INSERT INTO test_jsonb_constraints VALUES ('[]');
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
The connection to the server was lost. Attempting reset: Failed.
The connection to the server was lost. Attempting reset: Failed.
Time: 6.858 ms
@!>
We're currently looking into this case.
--
Hi,
On Mon, Oct 16, 2023 at 5:34 PM Nikita Malakhov <hukutoc@gmail.com> wrote:
>
> Hi,
>
> Also FYI - the following case results in segmentation fault:
>
> postgres@postgres=# CREATE TABLE test_jsonb_constraints (
> js text,
> i int,
> x jsonb DEFAULT JSON_QUERY(jsonb '[1,2]', '$[*]' WITH WRAPPER)
> CONSTRAINT test_jsonb_constraint1
> CHECK (js IS JSON)
> CONSTRAINT test_jsonb_constraint5
> CHECK (JSON_QUERY(js::jsonb, '$.mm' RETURNING char(5) OMIT QUOTES EMPTY ARRAY ON EMPTY) > 'a'
COLLATE"C")
> CONSTRAINT test_jsonb_constraint6
> CHECK (JSON_EXISTS(js::jsonb, 'strict $.a' RETURNING int TRUE ON ERROR) < 2)
> );
> CREATE TABLE
> Time: 13.518 ms
> postgres@postgres=# INSERT INTO test_jsonb_constraints VALUES ('[]');
> server closed the connection unexpectedly
> This probably means the server terminated abnormally
> before or while processing the request.
> The connection to the server was lost. Attempting reset: Failed.
> The connection to the server was lost. Attempting reset: Failed.
> Time: 6.858 ms
> @!>
>
> We're currently looking into this case.
Thanks for the report. I think I've figured out the problem --
ExecEvalJsonExprCoercion() mishandles the EMPTY ARRAY ON EMPTY case.
I'm reading the other 2 patches...
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
Hi,
Sorry, forgot to mention above - patches from our patch set should be applied
onto SQL/JSON part 3 - v22-0003-SQL-JSON-query-functions.patch, thus
they are numbered as v23-0003-1 and -2.
--
On Mon, Oct 16, 2023 at 5:47 PM Amit Langote <amitlangote09@gmail.com> wrote: > > > We're currently looking into this case. > > Thanks for the report. I think I've figured out the problem -- > ExecEvalJsonExprCoercion() mishandles the EMPTY ARRAY ON EMPTY case. > > I'm reading the other 2 patches... > > -- > Thanks, Amit Langote > EDB: http://www.enterprisedb.com query: select JSON_QUERY('[]'::jsonb, '$.mm' RETURNING text OMIT QUOTES EMPTY ON EMPTY); Breakpoint 2, ExecEvalJsonExpr (state=0x55e47ad685c0, op=0x55e47ad68818, econtext=0x55e47ad682e8) at ../../Desktop/pg_sources/main/postgres/src/backend/executor/execExprInterp.c:4188 4188 JsonExprState *jsestate = op->d.jsonexpr.jsestate; (gdb) fin Run till exit from #0 ExecEvalJsonExpr (state=0x55e47ad685c0, op=0x55e47ad68818, econtext=0x55e47ad682e8) at ../../Desktop/pg_sources/main/postgres/src/backend/executor/execExprInterp.c:4188 ExecInterpExpr (state=0x55e47ad685c0, econtext=0x55e47ad682e8, isnull=0x7ffe63659e2f) at ../../Desktop/pg_sources/main/postgres/src/backend/executor/execExprInterp.c:1556 1556 EEO_NEXT(); (gdb) p *op->resnull $1 = true (gdb) cont Continuing. Breakpoint 1, ExecEvalJsonExprCoercion (state=0x55e47ad685c0, op=0x55e47ad68998, econtext=0x55e47ad682e8, res=94439801785192, resnull=false) at ../../Desktop/pg_sources/main/postgres/src/backend/executor/execExprInterp.c:4453 4453 { (gdb) i args state = 0x55e47ad685c0 op = 0x55e47ad68998 econtext = 0x55e47ad682e8 res = 94439801785192 resnull = false (gdb) p *op->resnull $2 = false ------------------------------------------------------- in ExecEvalJsonExpr, *op->resnull is true. then in ExecEvalJsonExprCoercion *op->resnull is false. I am not sure why *op->resnull value changes, when changes. ------------------------------------------------------- in ExecEvalJsonExprCoercion, if resnull is true, then jb is null, but it seems there is no code to handle the case. ----------------------------- add the following code after ExecEvalJsonExprCoercion if (!InputFunctionCallSafe(...) works, but seems like a hack. if (!val_string) { *op->resnull = true; *op->resvalue = (Datum) 0; }
Hello!
On 16.10.2023 15:49, jian he wrote:
> add the following code after ExecEvalJsonExprCoercion if
> (!InputFunctionCallSafe(...) works, but seems like a hack.
>
> if (!val_string)
> {
> *op->resnull = true;
> *op->resvalue = (Datum) 0;
> }
It seems the constraint should work here:
After
CREATE TABLE test (
js text,
i int,
x jsonb DEFAULT JSON_QUERY(jsonb '[1,2]', '$[*]' WITH WRAPPER)
CONSTRAINT test_constraint
CHECK (JSON_QUERY(js::jsonb, '$.a' RETURNING char(5) OMIT QUOTES EMPTY ARRAY ON EMPTY) > 'a')
);
INSERT INTO test_jsonb_constraints VALUES ('[]');
one expected to see an error like that:
ERROR: new row for relation "test" violates check constraint "test_constraint"
DETAIL: Failing row contains ([], null, [1, 2]).
not "INSERT 0 1"
With best regards,
--
Anton A. Melnikov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On Mon, Oct 16, 2023 at 10:44 PM Anton A. Melnikov
<a.melnikov@postgrespro.ru> wrote:
> On 16.10.2023 15:49, jian he wrote:
> > add the following code after ExecEvalJsonExprCoercion if
> > (!InputFunctionCallSafe(...) works, but seems like a hack.
> >
> > if (!val_string)
> > {
> > *op->resnull = true;
> > *op->resvalue = (Datum) 0;
> > }
>
> It seems the constraint should work here:
>
> After
>
> CREATE TABLE test (
> js text,
> i int,
> x jsonb DEFAULT JSON_QUERY(jsonb '[1,2]', '$[*]' WITH WRAPPER)
> CONSTRAINT test_constraint
> CHECK (JSON_QUERY(js::jsonb, '$.a' RETURNING char(5) OMIT QUOTES EMPTY ARRAY ON EMPTY) > 'a')
> );
>
> INSERT INTO test_jsonb_constraints VALUES ('[]');
>
> one expected to see an error like that:
>
> ERROR: new row for relation "test" violates check constraint "test_constraint"
> DETAIL: Failing row contains ([], null, [1, 2]).
>
> not "INSERT 0 1"
Yes, the correct thing here is for the constraint to fail.
One thing jian he missed during the debugging is that
ExecEvalJsonExprCoersion() receives the EMPTY ARRAY value via
*op->resvalue/resnull, set by ExecEvalJsonExprBehavior(), because
that's the ON EMPTY behavior specified in the constraint. The bug was
that the code in ExecEvalJsonExprCoercion() failed to set val_string
to that value ("[]") before passing to InputFunctionCallSafe(), so the
latter would assume the input is NULL.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
On 17.10.2023 07:02, Amit Langote wrote:
> One thing jian he missed during the debugging is that
> ExecEvalJsonExprCoersion() receives the EMPTY ARRAY value via
> *op->resvalue/resnull, set by ExecEvalJsonExprBehavior(), because
> that's the ON EMPTY behavior specified in the constraint. The bug was
> that the code in ExecEvalJsonExprCoercion() failed to set val_string
> to that value ("[]") before passing to InputFunctionCallSafe(), so the
> latter would assume the input is NULL.
>
Thank a lot for this remark!
I tried to dig to the transformJsonOutput() to fix it earlier at the analyze stage,
but it looks like a rather hard way.
Maybe simple in accordance with you note remove the second condition from this line:
if (jb && JB_ROOT_IS_SCALAR(jb)) ?
There is a simplified reproduction before such a fix:
postgres=# select JSON_QUERY(jsonb '[]', '$' RETURNING char(5) OMIT QUOTES EMPTY ON EMPTY);
server closed the connection unexpectedly
This probably means the server terminated abnormally
after:
postgres=# select JSON_QUERY(jsonb '[]', '$' RETURNING char(5) OMIT QUOTES EMPTY ON EMPTY);
json_query
------------
[]
(1 row)
And at the moment i havn't found any side effects of that fix.
Please point me if i'm missing something.
With the best wishes!
--
Anton A. Melnikov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
Hi Anton,
On Tue, Oct 17, 2023 at 4:11 PM Anton A. Melnikov
<a.melnikov@postgrespro.ru> wrote:
> On 17.10.2023 07:02, Amit Langote wrote:
>
> > One thing jian he missed during the debugging is that
> > ExecEvalJsonExprCoersion() receives the EMPTY ARRAY value via
> > *op->resvalue/resnull, set by ExecEvalJsonExprBehavior(), because
> > that's the ON EMPTY behavior specified in the constraint. The bug was
> > that the code in ExecEvalJsonExprCoercion() failed to set val_string
> > to that value ("[]") before passing to InputFunctionCallSafe(), so the
> > latter would assume the input is NULL.
> >
> Thank a lot for this remark!
>
> I tried to dig to the transformJsonOutput() to fix it earlier at the analyze stage,
> but it looks like a rather hard way.
Indeed. As I said, the problem was a bug in ExecEvalJsonExprCoercion().
>
> Maybe simple in accordance with you note remove the second condition from this line:
> if (jb && JB_ROOT_IS_SCALAR(jb)) ?
Yeah, that's how I would fix it.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
On Mon, Oct 16, 2023 at 5:21 PM Nikita Malakhov <hukutoc@gmail.com> wrote:
>
> Hi!
>
> With the latest set of patches we encountered failure with the following query:
>
> postgres@postgres=# SELECT JSON_QUERY(jsonpath '"aaa"', '$' RETURNING text);
> server closed the connection unexpectedly
> This probably means the server terminated abnormally
> before or while processing the request.
> The connection to the server was lost. Attempting reset: Failed.
> The connection to the server was lost. Attempting reset: Failed.
> Time: 11.165 ms
>
> A colleague of mine, Anton Melnikov, proposed the following changes which slightly
> alter coercion functions to process this kind of error correctly.
>
> Please check attached patch set.
Thanks for the patches.
I think I understand patch 1. It makes each of JSON_{QUERY | VALUE |
EXISTS}() use FORMAT JSON for the context item by default, which I
think is the correct behavior.
As for patch 2, maybe the executor part is fine, but I'm not so sure
about the parser part. Could you please explain why you think the
parser must check error-safety of the target type for allowing IO
coercion for non-ERROR behaviors?
Even if we consider that that's what should be done, it doesn't seem
like a good idea for the parser to implement its own logic for
determining error-safety. IOW, the parser should really be using some
type cache API. I thought there might have been a flag in pg_proc
(prosafe) or pg_type (typinsafe), but apparently there isn't.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
Hi. based on v22. I added some tests again json_value for the sake of coverager test. A previous email thread mentioned needing to check *empty in ExecEvalJsonExpr. since JSON_VALUE_OP, JSON_QUERY_OP, JSON_EXISTS_OP all need to have *empty cases, So I refactored a little bit. might be helpful. Maybe we can also refactor *error cases. The following part is not easy to understand. res = ExecPrepareJsonItemCoercion(jbv, + jsestate->item_jcstates, + &post_eval->jcstate); + if (post_eval->jcstate && + post_eval->jcstate->coercion && + (post_eval->jcstate->coercion->via_io || + post_eval->jcstate->coercion->via_populate))
Вложения
Hi!
Amit, on previous email, patch #2 - I agree that it is not the best idea to introduce
new type of logic into the parser, so this logic could be moved to the executor,
or removed at all. What do you think of these options?
On Wed, Oct 18, 2023 at 5:19 AM jian he <jian.universality@gmail.com> wrote:
Hi.
based on v22.
I added some tests again json_value for the sake of coverager test.
A previous email thread mentioned needing to check *empty in ExecEvalJsonExpr.
since JSON_VALUE_OP, JSON_QUERY_OP, JSON_EXISTS_OP all need to have
*empty cases, So I refactored a little bit.
might be helpful. Maybe we can also refactor *error cases.
The following part is not easy to understand.
res = ExecPrepareJsonItemCoercion(jbv,
+ jsestate->item_jcstates,
+ &post_eval->jcstate);
+ if (post_eval->jcstate &&
+ post_eval->jcstate->coercion &&
+ (post_eval->jcstate->coercion->via_io ||
+ post_eval->jcstate->coercion->via_populate))
Hi Nikita, On Thu, Oct 26, 2023 at 2:13 AM Nikita Malakhov <hukutoc@gmail.com> wrote: > Amit, on previous email, patch #2 - I agree that it is not the best idea to introduce > new type of logic into the parser, so this logic could be moved to the executor, > or removed at all. What do you think of these options? Yes maybe, though I'd first like to have a good answer to why is that logic necessary at all. Maybe you think it's better to emit an error in the SQL/JSON layer of code than in the type input function if it's unsafe? -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Hi,
The main goal was to correctly process invalid queries (as in examples above).
I'm not sure this could be done in type input functions. I thought that some
coercions could be checked before evaluating expressions for saving reasons.
--
Hi, On Thu, Oct 26, 2023 at 9:20 PM Nikita Malakhov <hukutoc@gmail.com> wrote: > > Hi, > > The main goal was to correctly process invalid queries (as in examples above). > I'm not sure this could be done in type input functions. I thought that some > coercions could be checked before evaluating expressions for saving reasons. I assume by "invalid" you mean queries specifying types in RETURNING that don't support soft-error handling in their input function. Adding a check makes sense but its implementation should include a type cache interface to check whether a given type has error-safe input handling, possibly as a separate patch. IOW, the SQL/JSON patch shouldn't really make a list of types to report as unsupported. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Hi,
-- Agreed on the latter, that must not be the part of it for sure.
Would think on how to make this part correct.
Hi!
According to the discussion above, I've added the 'proerrsafe' attribute to the PG_PROC relation.
The same was done some time ago by Nikita Glukhov but this part was reverted.
This is a WIP patch, I am new to this part of Postgres, so please correct me if I'm going the wrong way.
Вложения
Hi!
Read Tom Lane's note in previous discussion (quite long, so I've missed it)
on pg_proc column -
>I strongly recommend against having a new pg_proc column at all.
>I doubt that you really need it, and having one will create
>enormous mechanical burdens to making the conversion. (For example,
>needing a catversion bump every time we convert one more function,
>or an extension version bump to convert extensions.)
>I doubt that you really need it, and having one will create
>enormous mechanical burdens to making the conversion. (For example,
>needing a catversion bump every time we convert one more function,
>or an extension version bump to convert extensions.)
so should figure out another way to do it.
Hi, At the moment, what is the patchset to be tested? The latest SQL/JSON server I have is from September, and it's become unclear to me what belongs to the SQL/JSON patchset. It seems to me cfbot erroneously shows green because it successfully compiles later detail-patches (i.e., not the SQL/JSON set itself). Please correct me if I'm wrong and it is in fact possible to derive from cfbot a patchset that are the ones to use to build the latest SQL/JSON server. Thanks! Erik
Hi Erik,
On Sat, Nov 11, 2023 at 11:52 Erik Rijkers <er@xs4all.nl> wrote:
Hi,
At the moment, what is the patchset to be tested? The latest SQL/JSON
server I have is from September, and it's become unclear to me what
belongs to the SQL/JSON patchset. It seems to me cfbot erroneously
shows green because it successfully compiles later detail-patches (i.e.,
not the SQL/JSON set itself). Please correct me if I'm wrong and it is
in fact possible to derive from cfbot a patchset that are the ones to
use to build the latest SQL/JSON server.
I’ll be posting a new set that addresses Andres’ comments early next week.
Hi,
Sorry for the late reply.
On Sat, Oct 7, 2023 at 6:49 AM Andres Freund <andres@anarazel.de> wrote:
> On 2023-09-29 13:57:46 +0900, Amit Langote wrote:
> > +/*
> > + * Push steps to evaluate a JsonExpr and its various subsidiary expressions.
> > + */
> > +static void
> > +ExecInitJsonExpr(JsonExpr *jexpr, ExprState *state,
> > + Datum *resv, bool *resnull,
> > + ExprEvalStep *scratch)
> > +{
> > + JsonExprState *jsestate = palloc0(sizeof(JsonExprState));
> > + JsonExprPreEvalState *pre_eval = &jsestate->pre_eval;
> > + ListCell *argexprlc;
> > + ListCell *argnamelc;
> > + int skip_step_off = -1;
> > + int passing_args_step_off = -1;
> > + int coercion_step_off = -1;
> > + int coercion_finish_step_off = -1;
> > + int behavior_step_off = -1;
> > + int onempty_expr_step_off = -1;
> > + int onempty_jump_step_off = -1;
> > + int onerror_expr_step_off = -1;
> > + int onerror_jump_step_off = -1;
> > + int result_coercion_jump_step_off = -1;
> > + List *adjust_jumps = NIL;
> > + ListCell *lc;
> > + ExprEvalStep *as;
> > +
> > + jsestate->jsexpr = jexpr;
> > +
> > + /*
> > + * Add steps to compute formatted_expr, pathspec, and PASSING arg
> > + * expressions as things that must be evaluated *before* the actual JSON
> > + * path expression.
> > + */
> > + ExecInitExprRec((Expr *) jexpr->formatted_expr, state,
> > + &pre_eval->formatted_expr.value,
> > + &pre_eval->formatted_expr.isnull);
> > + ExecInitExprRec((Expr *) jexpr->path_spec, state,
> > + &pre_eval->pathspec.value,
> > + &pre_eval->pathspec.isnull);
> > +
> > + /*
> > + * Before pushing steps for PASSING args, push a step to decide whether to
> > + * skip evaluating the args and the JSON path expression depending on
> > + * whether either of formatted_expr and pathspec is NULL; see
> > + * ExecEvalJsonExprSkip().
> > + */
> > + scratch->opcode = EEOP_JSONEXPR_SKIP;
> > + scratch->d.jsonexpr_skip.jsestate = jsestate;
> > + skip_step_off = state->steps_len;
> > + ExprEvalPushStep(state, scratch);
>
> Could SKIP be implemented using EEOP_JUMP_IF_NULL with a bit of work? I see
> that it sets jsestate->post_eval.jcstate, but I don't understand why it needs
> to be done that way. /* ExecEvalJsonExprCoercion() depends on this. */ doesn't
> explain that much.
OK, I've managed to make this work using EEOP_JUMP_IF_NULL for each of
the two expressions that need checking: formatted_expr and pathspec.
> > + /* PASSING args. */
> > + jsestate->pre_eval.args = NIL;
> > + passing_args_step_off = state->steps_len;
> > + forboth(argexprlc, jexpr->passing_values,
> > + argnamelc, jexpr->passing_names)
> > + {
> > + Expr *argexpr = (Expr *) lfirst(argexprlc);
> > + String *argname = lfirst_node(String, argnamelc);
> > + JsonPathVariable *var = palloc(sizeof(*var));
> > +
> > + var->name = pstrdup(argname->sval);
>
> Why does this need to be strdup'd?
Seems unnecessary, so removed.
> > + /* Step for the actual JSON path evaluation; see ExecEvalJsonExpr(). */
> > + scratch->opcode = EEOP_JSONEXPR_PATH;
> > + scratch->d.jsonexpr.jsestate = jsestate;
> > + ExprEvalPushStep(state, scratch);
> > +
> > + /*
> > + * Step to handle ON ERROR and ON EMPTY behavior. Also, to handle errors
> > + * that may occur during coercion handling.
> > + *
> > + * See ExecEvalJsonExprBehavior().
> > + */
> > + scratch->opcode = EEOP_JSONEXPR_BEHAVIOR;
> > + scratch->d.jsonexpr_behavior.jsestate = jsestate;
> > + behavior_step_off = state->steps_len;
> > + ExprEvalPushStep(state, scratch);
>
> From what I can tell there a) can never be a step between EEOP_JSONEXPR_PATH
> and EEOP_JSONEXPR_BEHAVIOR b) EEOP_JSONEXPR_PATH ends with an unconditional
> branch. What's the point of the two different steps here?
A separate BEHAVIOR step is needed to jump to when the coercion step
catches an error which must be handled with the appropriate ON ERROR
behavior.
> > + EEO_CASE(EEOP_JSONEXPR_PATH)
> > + {
> > + /* too complex for an inline implementation */
> > + ExecEvalJsonExpr(state, op, econtext);
> > + EEO_NEXT();
> > + }
>
> Why does EEOP_JSONEXPR_PATH call ExecEvalJsonExpr, the names don't match...
Renamed to ExecEvalJsonExprPath().
> > + EEO_CASE(EEOP_JSONEXPR_SKIP)
> > + {
> > + /* too complex for an inline implementation */
> > + EEO_JUMP(ExecEvalJsonExprSkip(state, op));
> > + }
> ...
>
>
> > + EEO_CASE(EEOP_JSONEXPR_COERCION_FINISH)
> > + {
> > + /* too complex for an inline implementation */
> > + EEO_JUMP(ExecEvalJsonExprCoercionFinish(state, op));
> > + }
>
> This seems to just return op->d.jsonexpr_coercion_finish.jump_coercion_error
> or op->d.jsonexpr_coercion_finish.jump_coercion_done. Which makes me think
> it'd be better to return a boolean? Particularly because that's how you
> already implemented it for JIT (except that you did it by hardcoding the jump
> step to compare to, which seems odd).
>
> Separately, why do we even need a jump for both cases, and not just for the
> error case?
Agreed. I've redesigned all of the steps so that we need to remember
only a couple of jump addresses in JsonExprState for hard-coded
jumping:
1. the address of the step that handles ON ERROR/EMPTY clause
(statically set during compilation)
2. the address of the step that evaluates coercion (dynamically set
depending on the type of the JSON value to coerce)
The redesign involved changing:
* What each step does
* Arranging steps in the order of operations that must be performed in
the following order:
1. compute formatted_expr
2. JUMP_IF_NULL (jumps to coerce the NULL result)
3. compute pathspec
4. JUMP_IF_NULL (jumps to coerce the NULL result)
5. compute PASSING arg expressions or noop
6. compute JsonPath{Exists|Query|Value} (hard-coded jump to step 9 if
error/empty or to appropriate coercion)
7. evaluate coercion (via expression or via IO in
ExecEvalJsonCoercionViaPopulateOrIO) ->
8. coercion finish
9. JUMP_IF_NOT_TRUE (error) (jumps to skip the next expression if !error)
10. ON ERROR expression
12. JUMP_IF_NOT_TRUE (empty) (jumps to skip the next expression if !empty)
13. ON EMPTY expression
There are also some unconditional JUMPs added in between above steps
to skip to end or the appropriate target address as needed.
> > + EEO_CASE(EEOP_JSONEXPR_BEHAVIOR)
> > + {
> > + /* too complex for an inline implementation */
> > + EEO_JUMP(ExecEvalJsonExprBehavior(state, op));
> > + }
> > +
> > + EEO_CASE(EEOP_JSONEXPR_COERCION)
> > + {
> > + /* too complex for an inline implementation */
> > + EEO_JUMP(ExecEvalJsonExprCoercion(state, op, econtext,
> > + *op->resvalue,
*op->resnull));
> > + }
>
> I wonder if this is the right design for this op - you're declaring this to be
> op not worth implementing inline, yet you then have it implemented by hand for JIT.
This has been redesigned to not require the hard-coded jumps like these.
> > +/*
> > + * Evaluate given JsonExpr by performing the specified JSON operation.
> > + *
> > + * This also populates the JsonExprPostEvalState with the information needed
> > + * by the subsequent steps that handle the specified JsonBehavior.
> > + */
> > +void
> > +ExecEvalJsonExpr(ExprState *state, ExprEvalStep *op, ExprContext *econtext)
> > +{
> > + JsonExprState *jsestate = op->d.jsonexpr.jsestate;
> > + JsonExprPreEvalState *pre_eval = &jsestate->pre_eval;
> > + JsonExprPostEvalState *post_eval = &jsestate->post_eval;
> > + JsonExpr *jexpr = jsestate->jsexpr;
> > + Datum item;
> > + Datum res = (Datum) 0;
> > + bool resnull = true;
> > + JsonPath *path;
> > + bool throw_error = (jexpr->on_error->btype == JSON_BEHAVIOR_ERROR);
> > + bool *error = &post_eval->error;
> > + bool *empty = &post_eval->empty;
> > +
> > + item = pre_eval->formatted_expr.value;
> > + path = DatumGetJsonPathP(pre_eval->pathspec.value);
> > +
> > + /* Reset JsonExprPostEvalState for this evaluation. */
> > + memset(post_eval, 0, sizeof(*post_eval));
> > +
> > + switch (jexpr->op)
> > + {
> > + case JSON_EXISTS_OP:
> > + {
> > + bool exists = JsonPathExists(item, path,
> > + !throw_error
?error : NULL,
> > +
pre_eval->args);
> > +
> > + post_eval->jcstate = jsestate->result_jcstate;
> > + if (*error)
> > + {
> > + *op->resnull = true;
> > + *op->resvalue = (Datum) 0;
> > + return;
> > + }
> > +
> > + resnull = false;
> > + res = BoolGetDatum(exists);
> > + break;
> > + }
>
> Kinda seems there should be a EEOP_JSON_EXISTS/JSON_QUERY_OP op, instead of
> implementing it all inside ExecEvalJsonExpr. I think this might obsolete
> needing to rediscover that the value is null in SKIP etc?
I tried but didn't really see the point of breaking
ExecEvalJsonExprPath() down into one step per JSON_*OP.
The skipping logic is based on the result of *2* input expressions
formatted_expr and pathspec which are computed before getting to
ExecEvalJsonExprPath(). Also, the skipping logic also allows to skip
the evaluation of PASSING arguments which also need to be computed
before ExecEvalJsonExprPath().
> > + case JSON_QUERY_OP:
> > + res = JsonPathQuery(item, path, jexpr->wrapper, empty,
> > + !throw_error ? error : NULL,
> > + pre_eval->args);
> > +
> > + post_eval->jcstate = jsestate->result_jcstate;
> > + if (*error)
> > + {
> > + *op->resnull = true;
> > + *op->resvalue = (Datum) 0;
> > + return;
> > + }
> > + resnull = !DatumGetPointer(res);
>
> Shoulnd't this check empty?
Fixed.
> FWIW, it's also pretty odd that JsonPathQuery() once
> return (Datum) 0;
> and later does
> return PointerGetDatum(NULL);
Yes, fixed to use the former style at all returns.
> > + case JSON_VALUE_OP:
> > + {
> > + JsonbValue *jbv = JsonPathValue(item, path, empty,
> > + !throw_error ? error
:NULL,
> > + pre_eval->args);
> > +
> > + /* Might get overridden below by an item_jcstate. */
> > + post_eval->jcstate = jsestate->result_jcstate;
> > + if (*error)
> > + {
> > + *op->resnull = true;
> > + *op->resvalue = (Datum) 0;
> > + return;
> > + }
> > +
> > + if (!jbv) /* NULL or empty */
> > + {
> > + resnull = true;
> > + break;
> > + }
> > +
> > + Assert(!*empty);
> > +
> > + resnull = false;
> > +
> > + /* Coerce scalar item to the output type */
> > +
> > + /*
> > + * If the requested output type is json(b), use
> > + * JsonExprState.result_coercion to do the coercion.
> > + */
> > + if (jexpr->returning->typid == JSONOID ||
> > + jexpr->returning->typid == JSONBOID)
> > + {
> > + /* Use result_coercion from json[b] to the output type */
> > + res = JsonbPGetDatum(JsonbValueToJsonb(jbv));
> > + break;
> > + }
> > +
> > + /*
> > + * Else, use one of the item_coercions.
> > + *
> > + * Error out if no cast exists to coerce SQL/JSON item to the
> > + * the output type.
> > + */
> > + res = ExecPrepareJsonItemCoercion(jbv,
> > +
jsestate->item_jcstates,
> > +
&post_eval->jcstate);
> > + if (post_eval->jcstate &&
> > + post_eval->jcstate->coercion &&
> > + (post_eval->jcstate->coercion->via_io ||
> > + post_eval->jcstate->coercion->via_populate))
> > + {
> > + if (!throw_error)
> > + {
> > + *op->resnull = true;
> > + *op->resvalue = (Datum) 0;
> > + return;
> > + }
> > +
> > + /*
> > + * Coercion via I/O means here that the cast to the target
> > + * type simply does not exist.
> > + */
> > + ereport(ERROR,
> > +
(errcode(ERRCODE_SQL_JSON_ITEM_CANNOT_BE_CAST_TO_TARGET_TYPE),
> > + errmsg("SQL/JSON item cannot be cast to target type")));
> > + }
> > + break;
> > + }
> > +
> > + default:
> > + elog(ERROR, "unrecognized SQL/JSON expression op %d", jexpr->op);
> > + *op->resnull = true;
> > + *op->resvalue = (Datum) 0;
> > + return;
> > + }
> > +
> > + /*
> > + * If the ON EMPTY behavior is to cause an error, do so here. Other
> > + * behaviors will be handled in ExecEvalJsonExprBehavior().
> > + */
> > + if (*empty)
> > + {
> > + Assert(jexpr->on_empty); /* it is not JSON_EXISTS */
> > +
> > + if (jexpr->on_empty->btype == JSON_BEHAVIOR_ERROR)
> > + {
> > + if (!throw_error)
> > + {
> > + *op->resnull = true;
> > + *op->resvalue = (Datum) 0;
> > + return;
> > + }
> > +
> > + ereport(ERROR,
> > + (errcode(ERRCODE_NO_SQL_JSON_ITEM),
> > + errmsg("no SQL/JSON item")));
> > + }
> > + }
> > +
> > + *op->resvalue = res;
> > + *op->resnull = resnull;
> > +}
> > +
> > +/*
> > + * Skip calling ExecEvalJson() on the given JsonExpr?
>
> I don't think that function exists.
Fixed.
> > + * Returns the step address to be performed next.
> > + */
> > +int
> > +ExecEvalJsonExprSkip(ExprState *state, ExprEvalStep *op)
> > +{
> > + JsonExprState *jsestate = op->d.jsonexpr_skip.jsestate;
> > +
> > + /*
> > + * Skip if either of the input expressions has turned out to be NULL,
> > + * though do execute domain checks for NULLs, which are handled by the
> > + * coercion step.
> > + */
> > + if (jsestate->pre_eval.formatted_expr.isnull ||
> > + jsestate->pre_eval.pathspec.isnull)
> > + {
> > + *op->resvalue = (Datum) 0;
> > + *op->resnull = true;
> > +
> > + /* ExecEvalJsonExprCoercion() depends on this. */
> > + jsestate->post_eval.jcstate = jsestate->result_jcstate;
> > +
> > + return op->d.jsonexpr_skip.jump_coercion;
> > + }
> > +
> > + /*
> > + * Go evaluate the PASSING args if any and subsequently JSON path itself.
> > + */
> > + return op->d.jsonexpr_skip.jump_passing_args;
> > +}
> > +
> > +/*
> > + * Returns the step address to perform the JsonBehavior applicable to
> > + * the JSON item that resulted from evaluating the given JsonExpr.
> > + *
> > + * Returns the step address to be performed next.
> > + */
> > +int
> > +ExecEvalJsonExprBehavior(ExprState *state, ExprEvalStep *op)
> > +{
> > + JsonExprState *jsestate = op->d.jsonexpr_behavior.jsestate;
> > + JsonExprPostEvalState *post_eval = &jsestate->post_eval;
> > + JsonBehavior *behavior = NULL;
> > + int jump_to = -1;
> > +
> > + if (post_eval->error || post_eval->coercion_error)
> > + {
> > + behavior = jsestate->jsexpr->on_error;
> > + jump_to = op->d.jsonexpr_behavior.jump_onerror_expr;
> > + }
> > + else if (post_eval->empty)
> > + {
> > + behavior = jsestate->jsexpr->on_empty;
> > + jump_to = op->d.jsonexpr_behavior.jump_onempty_expr;
> > + }
> > + else if (!post_eval->coercion_done)
> > + {
> > + /*
> > + * If no error or the JSON item is not empty, directly go to the
> > + * coercion step to coerce the item as is.
> > + */
> > + return op->d.jsonexpr_behavior.jump_coercion;
> > + }
> > +
> > + Assert(behavior);
> > +
> > + /*
> > + * Set up for coercion step that will run to coerce a non-default behavior
> > + * value. It should use result_coercion, if any. Errors that may occur
> > + * should be thrown for JSON ops other than JSON_VALUE_OP.
> > + */
> > + if (behavior->btype != JSON_BEHAVIOR_DEFAULT)
> > + {
> > + post_eval->jcstate = jsestate->result_jcstate;
> > + post_eval->coercing_behavior_expr = true;
> > + }
> > +
> > + Assert(jump_to >= 0);
> > + return jump_to;
> > +}
> > +
> > +/*
> > + * Evaluate or return the step address to evaluate a coercion of a JSON item
> > + * to the target type. The former if the coercion must be done right away by
> > + * calling the target type's input function, and for some types, by calling
> > + * json_populate_type().
> > + *
> > + * Returns the step address to be performed next.
> > + */
> > +int
> > +ExecEvalJsonExprCoercion(ExprState *state, ExprEvalStep *op,
> > + ExprContext *econtext,
> > + Datum res, bool resnull)
> > +{
> > + JsonExprState *jsestate = op->d.jsonexpr_coercion.jsestate;
> > + JsonExpr *jexpr = jsestate->jsexpr;
> > + JsonExprPostEvalState *post_eval = &jsestate->post_eval;
> > + JsonCoercionState *jcstate = post_eval->jcstate;
> > + char *val_string = NULL;
> > + bool omit_quotes = false;
> > +
> > + switch (jexpr->op)
> > + {
> > + case JSON_EXISTS_OP:
> > + if (jcstate && jcstate->jump_eval_expr >= 0)
> > + return jcstate->jump_eval_expr;
>
> Shouldn't this be a compile-time check and instead be handled by simply not
> emitting a step instead?
Yes and...
> > + /* No coercion needed. */
> > + post_eval->coercion_done = true;
> > + return op->d.jsonexpr_coercion.jump_coercion_done;
>
> Which then means we also don't need to emit anything here, no?
Yes.
Basically all jump address selection logic is now handled in
ExecInitJsonExpr() (compile-time) as described above.
> > +/*
> > + * Prepare SQL/JSON item coercion to the output type. Returned a datum of the
> > + * corresponding SQL type and a pointer to the coercion state.
> > + */
> > +static Datum
> > +ExecPrepareJsonItemCoercion(JsonbValue *item, List *item_jcstates,
> > + JsonCoercionState **p_item_jcstate)
>
> I might have missed it, but if not: The whole way the coercion stuff works
> needs a decent comment explaining how things fit together.
>
> What does "item" really mean here?
This term "item" I think refers to the JsonbValue returned by
JsonPathValue(), which can be one of jbvType types. Because we need
multiple coercions to account for that, I assume the original authors
decided to use the term/phrase "item coercions" to distinguish from
the result_coercion which assumes either a Boolean (EXISTS) or
Jsonb/text (QUERY) result.
> > +{
> > + JsonCoercionState *item_jcstate;
> > + Datum res;
> > + JsonbValue buf;
> > +
> > + if (item->type == jbvBinary &&
> > + JsonContainerIsScalar(item->val.binary.data))
> > + {
> > + bool res PG_USED_FOR_ASSERTS_ONLY;
> > +
> > + res = JsonbExtractScalar(item->val.binary.data, &buf);
> > + item = &buf;
> > + Assert(res);
> > + }
> > +
> > + /* get coercion state reference and datum of the corresponding SQL type */
> > + switch (item->type)
> > + {
> > + case jbvNull:
> > + item_jcstate = list_nth(item_jcstates, JsonItemTypeNull);
>
> This seems quite odd. We apparently have a fixed-length array, where specific
> offsets have specific meanings, yet it's encoded as a list that's then
> accessed with constant offsets?
>
> Right now ExecEvalJsonExpr() stores what ExecPrepareJsonItemCoercion() chooses
> in post_eval->jcstate. Which the immediately following
> ExecEvalJsonExprBehavior() then digs out again. Then there's also control flow
> via post_eval->coercing_behavior_expr. This is ... not nice.
Agree.
In the new code, the struct JsonCoercionState is gone. So any given
coercion boils down to a steps address during runtime, which is
determined by ExecEvalJsonExprPath().
> ISTM that jsestate should have an array of jump targets, indexed by
> item->type.
Yes, an array of jump targets seems better for these "item coercions".
result_coercion is a single address stored separately.
> Which, for llvm IR, you can encode as a switch statement, instead
> of doing control flow via JsonExprState/JsonExprPostEvalState. There's
> obviously a bit more needed, but I think something like that should work, and
> simplify things a fair bit.
Thanks for suggesting the switch-case idea. The LLVM IR for
EEOP_JSONEXPR_PATH now includes one to jump to one of the coercion
addresses between that for result_coercion and "item coercions" if
present.
> > @@ -15711,6 +15721,192 @@ func_expr_common_subexpr:
> > n->location = @1;
> > $$ = (Node *) n;
> > }
> > + | JSON_QUERY '('
> > + json_api_common_syntax
> > + json_returning_clause_opt
> > + json_wrapper_behavior
> > + json_quotes_clause_opt
> > + ')'
> > + {
> > + JsonFuncExpr *n = makeNode(JsonFuncExpr);
> > +
> > + n->op = JSON_QUERY_OP;
> > + n->common = (JsonCommon *) $3;
> > + n->output = (JsonOutput *) $4;
> > + n->wrapper = $5;
> > + if (n->wrapper != JSW_NONE && $6 != JS_QUOTES_UNSPEC)
> > + ereport(ERROR,
> > + (errcode(ERRCODE_SYNTAX_ERROR),
> > + errmsg("SQL/JSON QUOTES behavior must not be
specifiedwhen WITH WRAPPER is used"),
> > + parser_errposition(@6)));
> > + n->quotes = $6;
> > + n->location = @1;
> > + $$ = (Node *) n;
> > + }
> > + | JSON_QUERY '('
> > + json_api_common_syntax
> > + json_returning_clause_opt
> > + json_wrapper_behavior
> > + json_quotes_clause_opt
> > + json_query_behavior ON EMPTY_P
> > + ')'
> > + {
> > + JsonFuncExpr *n = makeNode(JsonFuncExpr);
> > +
> > + n->op = JSON_QUERY_OP;
> > + n->common = (JsonCommon *) $3;
> > + n->output = (JsonOutput *) $4;
> > + n->wrapper = $5;
> > + if (n->wrapper != JSW_NONE && $6 != JS_QUOTES_UNSPEC)
> > + ereport(ERROR,
> > + (errcode(ERRCODE_SYNTAX_ERROR),
> > + errmsg("SQL/JSON QUOTES behavior must not be
specifiedwhen WITH WRAPPER is used"),
> > + parser_errposition(@6)));
> > + n->quotes = $6;
> > + n->on_empty = $7;
> > + n->location = @1;
> > + $$ = (Node *) n;
> > + }
> > + | JSON_QUERY '('
> > + json_api_common_syntax
> > + json_returning_clause_opt
> > + json_wrapper_behavior
> > + json_quotes_clause_opt
> > + json_query_behavior ON ERROR_P
> > + ')'
> > + {
> > + JsonFuncExpr *n = makeNode(JsonFuncExpr);
> > +
> > + n->op = JSON_QUERY_OP;
> > + n->common = (JsonCommon *) $3;
> > + n->output = (JsonOutput *) $4;
> > + n->wrapper = $5;
> > + if (n->wrapper != JSW_NONE && $6 != JS_QUOTES_UNSPEC)
> > + ereport(ERROR,
> > + (errcode(ERRCODE_SYNTAX_ERROR),
> > + errmsg("SQL/JSON QUOTES behavior must not be
specifiedwhen WITH WRAPPER is used"),
> > + parser_errposition(@6)));
> > + n->quotes = $6;
> > + n->on_error = $7;
> > + n->location = @1;
> > + $$ = (Node *) n;
> > + }
> > + | JSON_QUERY '('
> > + json_api_common_syntax
> > + json_returning_clause_opt
> > + json_wrapper_behavior
> > + json_quotes_clause_opt
> > + json_query_behavior ON EMPTY_P
> > + json_query_behavior ON ERROR_P
> > + ')'
> > + {
> > + JsonFuncExpr *n = makeNode(JsonFuncExpr);
> > +
> > + n->op = JSON_QUERY_OP;
> > + n->common = (JsonCommon *) $3;
> > + n->output = (JsonOutput *) $4;
> > + n->wrapper = $5;
> > + if (n->wrapper != JSW_NONE && $6 != JS_QUOTES_UNSPEC)
> > + ereport(ERROR,
> > + (errcode(ERRCODE_SYNTAX_ERROR),
> > + errmsg("SQL/JSON QUOTES behavior must not be
specifiedwhen WITH WRAPPER is used"),
> > + parser_errposition(@6)));
> > + n->quotes = $6;
> > + n->on_empty = $7;
> > + n->on_error = $10;
> > + n->location = @1;
> > + $$ = (Node *) n;
> > + }
>
> I'm sure we can find a way to deduplicate this.
>
>
> > + | JSON_EXISTS '('
> > + json_api_common_syntax
> > + json_returning_clause_opt
> > + ')'
> > + {
> > + JsonFuncExpr *p = makeNode(JsonFuncExpr);
> > +
> > + p->op = JSON_EXISTS_OP;
> > + p->common = (JsonCommon *) $3;
> > + p->output = (JsonOutput *) $4;
> > + p->location = @1;
> > + $$ = (Node *) p;
> > + }
> > + | JSON_EXISTS '('
> > + json_api_common_syntax
> > + json_returning_clause_opt
> > + json_exists_behavior ON ERROR_P
> > + ')'
> > + {
> > + JsonFuncExpr *p = makeNode(JsonFuncExpr);
> > +
> > + p->op = JSON_EXISTS_OP;
> > + p->common = (JsonCommon *) $3;
> > + p->output = (JsonOutput *) $4;
> > + p->on_error = $5;
> > + p->location = @1;
> > + $$ = (Node *) p;
> > + }
> > + | JSON_VALUE '('
> > + json_api_common_syntax
> > + json_returning_clause_opt
> > + ')'
> > + {
> > + JsonFuncExpr *n = makeNode(JsonFuncExpr);
> > +
> > + n->op = JSON_VALUE_OP;
> > + n->common = (JsonCommon *) $3;
> > + n->output = (JsonOutput *) $4;
> > + n->location = @1;
> > + $$ = (Node *) n;
> > + }
> > +
> > + | JSON_VALUE '('
> > + json_api_common_syntax
> > + json_returning_clause_opt
> > + json_value_behavior ON EMPTY_P
> > + ')'
> > + {
> > + JsonFuncExpr *n = makeNode(JsonFuncExpr);
> > +
> > + n->op = JSON_VALUE_OP;
> > + n->common = (JsonCommon *) $3;
> > + n->output = (JsonOutput *) $4;
> > + n->on_empty = $5;
> > + n->location = @1;
> > + $$ = (Node *) n;
> > + }
> > + | JSON_VALUE '('
> > + json_api_common_syntax
> > + json_returning_clause_opt
> > + json_value_behavior ON ERROR_P
> > + ')'
> > + {
> > + JsonFuncExpr *n = makeNode(JsonFuncExpr);
> > +
> > + n->op = JSON_VALUE_OP;
> > + n->common = (JsonCommon *) $3;
> > + n->output = (JsonOutput *) $4;
> > + n->on_error = $5;
> > + n->location = @1;
> > + $$ = (Node *) n;
> > + }
> > +
> > + | JSON_VALUE '('
> > + json_api_common_syntax
> > + json_returning_clause_opt
> > + json_value_behavior ON EMPTY_P
> > + json_value_behavior ON ERROR_P
> > + ')'
> > + {
> > + JsonFuncExpr *n = makeNode(JsonFuncExpr);
> > +
> > + n->op = JSON_VALUE_OP;
> > + n->common = (JsonCommon *) $3;
> > + n->output = (JsonOutput *) $4;
> > + n->on_empty = $5;
> > + n->on_error = $8;
> > + n->location = @1;
> > + $$ = (Node *) n;
> > + }
> > ;
>
> And this.
>
>
>
> > +json_query_behavior:
> > + ERROR_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_ERROR, NULL, @1); }
> > + | NULL_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_NULL, NULL, @1); }
> > + | DEFAULT a_expr { $$ = makeJsonBehavior(JSON_BEHAVIOR_DEFAULT, $2, @1); }
> > + | EMPTY_P ARRAY { $$ = makeJsonBehavior(JSON_BEHAVIOR_EMPTY_ARRAY, NULL, @1); }
> > + | EMPTY_P OBJECT_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_EMPTY_OBJECT, NULL, @1); }
> > + /* non-standard, for Oracle compatibility only */
> > + | EMPTY_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_EMPTY_ARRAY, NULL, @1); }
> > + ;
>
>
> > +json_exists_behavior:
> > + ERROR_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_ERROR, NULL, @1); }
> > + | TRUE_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_TRUE, NULL, @1); }
> > + | FALSE_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_FALSE, NULL, @1); }
> > + | UNKNOWN { $$ = makeJsonBehavior(JSON_BEHAVIOR_UNKNOWN, NULL, @1); }
> > + ;
> > +
> > +json_value_behavior:
> > + NULL_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_NULL, NULL, @1); }
> > + | ERROR_P { $$ = makeJsonBehavior(JSON_BEHAVIOR_ERROR, NULL, @1); }
> > + | DEFAULT a_expr { $$ = makeJsonBehavior(JSON_BEHAVIOR_DEFAULT, $2, @1); }
> > + ;
>
> This also seems like it could use some dedup.
>
> > src/backend/parser/gram.y | 348 +++++-
I've given that a try and managed to reduce the gram.y footprint down to:
src/backend/parser/gram.y | 217 +++-
> This causes a nontrivial increase in the size of the parser (~5% in an
> optimized build here), I wonder if we can do better.
Hmm, sorry if I sound ignorant but what do you mean by the parser here?
I can see that the byte-size of gram.o increases by 1.66% after the
above additions (1.72% with previous versions). I've also checked
using log_parser_stats that there isn't much slowdown in the
raw-parsing speed.
Attached updated patch. The version of 0001 that I posted on Oct 11
to add the error-safe version of CoerceViaIO contained many
unnecessary bits that are now removed.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
Вложения
Hi, Thanks, this looks like a substantial improvement. I don't quite have time to look right now, but I thought I'd answer one question below. On 2023-11-15 22:00:41 +0900, Amit Langote wrote: > > This causes a nontrivial increase in the size of the parser (~5% in an > > optimized build here), I wonder if we can do better. > > Hmm, sorry if I sound ignorant but what do you mean by the parser here? gram.o, in an optimized build. > I can see that the byte-size of gram.o increases by 1.66% after the > above additions (1.72% with previous versions). I'm not sure anymore how I measured it, but if you just looked at the total file size, that might not show the full gain, because of debug symbols etc. You can use the size command to look at just the code and data size. > I've also checked > using log_parser_stats that there isn't much slowdown in the > raw-parsing speed. What does "isn't much slowdown" mean in numbers? Greetings, Andres Freund
On 2023-11-15 09:11:19 -0800, Andres Freund wrote: > On 2023-11-15 22:00:41 +0900, Amit Langote wrote: > > > This causes a nontrivial increase in the size of the parser (~5% in an > > > optimized build here), I wonder if we can do better. > > > > Hmm, sorry if I sound ignorant but what do you mean by the parser here? > > gram.o, in an optimized build. Or, hm, maybe I meant the size of the generated gram.c actually. Either is worth looking at.
Op 11/15/23 om 14:00 schreef Amit Langote: > Hi, [..] > Attached updated patch. The version of 0001 that I posted on Oct 11 > to add the error-safe version of CoerceViaIO contained many > unnecessary bits that are now removed. > > -- > Thanks, Amit Langote > EDB: http://www.enterprisedb.com > [v24-0001-Add-soft-error-handling-to-some-expression-nodes.patch] > [v24-0002-Add-soft-error-handling-to-populate_record_field.patch] > [v24-0003-SQL-JSON-query-functions.patch] > [v24-0004-JSON_TABLE.patch] > [v24-0005-Claim-SQL-standard-compliance-for-SQL-JSON-featu.patch] Hi Amit, Here is a statement that seems to gobble up all memory and to totally lock up the machine. No ctrl-C - only a power reset gets me out of that. It was in one of my tests, so it used to work: select json_query( jsonb '"[3,4]"' , '$[*]' returning bigint[] empty object on error ); Can you have a look? Thanks, Erik
Hi Erik,
On Thu, Nov 16, 2023 at 13:52 Erik Rijkers <er@xs4all.nl> wrote:
Op 11/15/23 om 14:00 schreef Amit Langote:
> Hi,
[..]
> Attached updated patch. The version of 0001 that I posted on Oct 11
> to add the error-safe version of CoerceViaIO contained many
> unnecessary bits that are now removed.
>
> --
> Thanks, Amit Langote
> EDB: http://www.enterprisedb.com
> [v24-0001-Add-soft-error-handling-to-some-expression-nodes.patch]
> [v24-0002-Add-soft-error-handling-to-populate_record_field.patch]
> [v24-0003-SQL-JSON-query-functions.patch]
> [v24-0004-JSON_TABLE.patch]
> [v24-0005-Claim-SQL-standard-compliance-for-SQL-JSON-featu.patch]
Hi Amit,
Here is a statement that seems to gobble up all memory and to totally
lock up the machine. No ctrl-C - only a power reset gets me out of that.
It was in one of my tests, so it used to work:
select json_query(
jsonb '"[3,4]"'
, '$[*]' returning bigint[] empty object on error
);
Can you have a look?
Wow, will look. Thanks.
On Thu, Nov 16, 2023 at 1:57 PM Amit Langote <amitlangote09@gmail.com> wrote: > On Thu, Nov 16, 2023 at 13:52 Erik Rijkers <er@xs4all.nl> wrote: >> Op 11/15/23 om 14:00 schreef Amit Langote: >> > [v24-0001-Add-soft-error-handling-to-some-expression-nodes.patch] >> > [v24-0002-Add-soft-error-handling-to-populate_record_field.patch] >> > [v24-0003-SQL-JSON-query-functions.patch] >> > [v24-0004-JSON_TABLE.patch] >> > [v24-0005-Claim-SQL-standard-compliance-for-SQL-JSON-featu.patch] >> >> Hi Amit, >> >> Here is a statement that seems to gobble up all memory and to totally >> lock up the machine. No ctrl-C - only a power reset gets me out of that. >> It was in one of my tests, so it used to work: >> >> select json_query( >> jsonb '"[3,4]"' >> , '$[*]' returning bigint[] empty object on error >> ); >> >> Can you have a look? > > Wow, will look. Thanks. Should be fixed in the attached. The bug was caused by the recent redesign of JsonExpr evaluation steps. Your testing is very much appreciated. Thanks. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
On Thu, Nov 16, 2023 at 2:11 AM Andres Freund <andres@anarazel.de> wrote: > On 2023-11-15 22:00:41 +0900, Amit Langote wrote: > > > This causes a nontrivial increase in the size of the parser (~5% in an > > > optimized build here), I wonder if we can do better. > > > > Hmm, sorry if I sound ignorant but what do you mean by the parser here? > > gram.o, in an optimized build. > > > I can see that the byte-size of gram.o increases by 1.66% after the > > above additions (1.72% with previous versions). > > I'm not sure anymore how I measured it, but if you just looked at the total > file size, that might not show the full gain, because of debug symbols > etc. You can use the size command to look at just the code and data size. $ size /tmp/gram.* text data bss dec hex filename 661808 0 0 661808 a1930 /tmp/gram.o.unpatched 672800 0 0 672800 a4420 /tmp/gram.o.patched That's still a 1.66% increase in the code size: (672800 - 661808) / 661808 % = 1.66 As for gram.c, the increase is a bit larger: $ ll /tmp/gram.* -rw-rw-r--. 1 amit amit 2605925 Nov 16 16:18 /tmp/gram.c.unpatched -rw-rw-r--. 1 amit amit 2709422 Nov 16 16:22 /tmp/gram.c.patched (2709422 - 2605925) / 2605925 % = 3.97 > > I've also checked > > using log_parser_stats that there isn't much slowdown in the > > raw-parsing speed. > > What does "isn't much slowdown" mean in numbers? Sure, the benchmark I used measured the elapsed time (using log_parser_stats) of parsing a simple select statement (*) averaged over 10000 repetitions of the same query performed with `psql -c`: Unpatched: 0.000061 seconds Patched: 0.000061 seconds Here's a look at the perf: Unpatched: 0.59% [.] AllocSetAlloc 0.51% [.] hash_search_with_hash_value 0.47% [.] base_yyparse Patched: 0.63% [.] AllocSetAlloc 0.52% [.] hash_search_with_hash_value 0.44% [.] base_yyparse (*) select 1, 2, 3 from foo where a = 1 Is there a more relevant benchmark I could use? -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
hi. minor issues. In transformJsonFuncExpr(ParseState *pstate, JsonFuncExpr *func) func.behavior->on_empty->location and func.behavior->on_error->location are correct. but in ExecInitJsonExpr, jsestate->jsexpr->on_empty->location is -1, jsestate->jsexpr->on_error->location is -1. Maybe we can preserve these on_empty, on_error token locations in transformJsonBehavior. some enum declaration, ending element need an extra comma? + /* + * ExecEvalJsonExprPath() will set this to the address of the step to + * use to coerce the result of JsonPath* evaluation to the RETURNING + * type. Also see the description of possible step addresses this + * could be set to in the definition of JsonExprState.ZZ + */ "ZZ", typo?
On Fri, Nov 17, 2023 at 4:27 PM jian he <jian.universality@gmail.com> wrote: > hi. > minor issues. Thanks for checking. > In transformJsonFuncExpr(ParseState *pstate, JsonFuncExpr *func) > func.behavior->on_empty->location and > func.behavior->on_error->location are correct. > but in ExecInitJsonExpr, jsestate->jsexpr->on_empty->location is -1, > jsestate->jsexpr->on_error->location is -1. > Maybe we can preserve these on_empty, on_error token locations in > transformJsonBehavior. Sure. > some enum declaration, ending element need an extra comma? Didn't know about the convention to have that comma, but I can see it is present in most enum definitions. Changed all enums that the patch adds to conform. > + /* > + * ExecEvalJsonExprPath() will set this to the address of the step to > + * use to coerce the result of JsonPath* evaluation to the RETURNING > + * type. Also see the description of possible step addresses this > + * could be set to in the definition of JsonExprState.ZZ > + */ > > "ZZ", typo? Indeed. Will include the fixes in the next version. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
On 2023-Nov-17, Amit Langote wrote: > On Fri, Nov 17, 2023 at 4:27 PM jian he <jian.universality@gmail.com> wrote: > > some enum declaration, ending element need an extra comma? > > Didn't know about the convention to have that comma, but I can see it > is present in most enum definitions. It's new. See commit 611806cd726f. -- Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/
On Nov 16, 2023, at 17:48, Amit Langote <amitlangote09@gmail.com> wrote:
On Thu, Nov 16, 2023 at 2:11 AM Andres Freund <andres@anarazel.de> wrote:On 2023-11-15 22:00:41 +0900, Amit Langote wrote:This causes a nontrivial increase in the size of the parser (~5% in an
optimized build here), I wonder if we can do better.
Hmm, sorry if I sound ignorant but what do you mean by the parser here?
gram.o, in an optimized build.I can see that the byte-size of gram.o increases by 1.66% after the
above additions (1.72% with previous versions).
I'm not sure anymore how I measured it, but if you just looked at the total
file size, that might not show the full gain, because of debug symbols
etc. You can use the size command to look at just the code and data size.
$ size /tmp/gram.*
text data bss dec hex filename
661808 0 0 661808 a1930 /tmp/gram.o.unpatched
672800 0 0 672800 a4420 /tmp/gram.o.patched
That's still a 1.66% increase in the code size:
(672800 - 661808) / 661808 % = 1.66
As for gram.c, the increase is a bit larger:
$ ll /tmp/gram.*
-rw-rw-r--. 1 amit amit 2605925 Nov 16 16:18 /tmp/gram.c.unpatched
-rw-rw-r--. 1 amit amit 2709422 Nov 16 16:22 /tmp/gram.c.patched
(2709422 - 2605925) / 2605925 % = 3.97I've also checked
using log_parser_stats that there isn't much slowdown in the
raw-parsing speed.
What does "isn't much slowdown" mean in numbers?
Sure, the benchmark I used measured the elapsed time (using
log_parser_stats) of parsing a simple select statement (*) averaged
over 10000 repetitions of the same query performed with `psql -c`:
Unpatched: 0.000061 seconds
Patched: 0.000061 seconds
Here's a look at the perf:
Unpatched:
0.59% [.] AllocSetAlloc
0.51% [.] hash_search_with_hash_value
0.47% [.] base_yyparse
Patched:
0.63% [.] AllocSetAlloc
0.52% [.] hash_search_with_hash_value
0.44% [.] base_yyparse
(*) select 1, 2, 3 from foo where a = 1
Is there a more relevant benchmark I could use?
Thought I’d share a few more numbers I collected to analyze the parser size increase over releases.
* gram.o text bytes is from the output of `size gram.o`.
* compiled with -O3
version gram.o text bytes %change gram.c bytes %change
9.6 534010 - 2108984 -
10 582554 9.09 2258313 7.08
11 584596 0.35 2313475 2.44
12 590957 1.08 2341564 1.21
13 590381 -0.09 2357327 0.67
14 600707 1.74 2428841 3.03
15 633180 5.40 2495364 2.73
16 653464 3.20 2575269 3.20
17-sqljson 672800 2.95 2709422 3.97
So if we put SQL/JSON (including JSON_TABLE()) into 17, we end up with a gram.o 2.95% larger than v16, which granted is a somewhat larger bump, though also smaller than with some of recent releases.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
I looked a bit at the parser additions, because there were some concerns expressed that they are quite big. It looks like the parser rules were mostly literally copied from the BNF in the SQL standard. That's probably a reasonable place to start, but now at the end, there is some room for simplification. Attached are a few patches that apply on top of the 0003 patch. (I haven't gotten to 0004 in detail yet.) Some explanations: 0001-Put-keywords-in-right-order.patch This is just an unrelated cleanup. 0002-Remove-js_quotes-union-entry.patch We usually don't want to put every single node type into the gram.y %union. This one can be trivially removed. 0003-Move-some-code-from-gram.y-to-parse-analysis.patch Code like this can be postponed to parse analysis, keeping gram.y smaller. The error pointer loses a bit of precision, but I think that's ok. (There is similar code in your 0004 patch, which could be similarly moved.) 0004-Remove-JsonBehavior-stuff-from-union.patch Similar to my 0002. This adds a few casts as a result, but that is the typical style in gram.y. 0005-Get-rid-of-JsonBehaviorClause.patch I think this two-level wrapping of the behavior clauses is both confusing and overkill. I was trying to just list the on-empty and on-error clauses separately in the top-level productions (JSON_VALUE etc.), but that led to shift/reduce errors. So the existing rule structure is probably ok. But we don't need a separate node type just to combine two values and then unpack them again shortly thereafter. So I just replaced all this with a list. 0006-Get-rid-of-JsonCommon.patch This is an example where the SQL standard BNF is not sensible to apply literally. I moved those clauses up directly into their callers, thus removing one intermediate levels of rules and also nodes. Also, the path name (AS name) stuff is only for JSON_TABLE, so it's not needed in this patch. I removed it here, but it would have to be readded in your 0004 patch. Another thing: In your patch, JSON_EXISTS has a RETURNING clause (json_returning_clause_opt), but I don't see that in the standard, and also not in the Oracle or Db2 docs. Where did this come from? With these changes, I think the grammar complexity in your 0003 patch is at an acceptable level. Similar simplification opportunities exist in the 0004 patch, but I haven't worked on that yet. I suggest that you focus on getting 0001..0003 committed around this commit fest and then deal with 0004 in the next one. (Also split up the 0005 patch into the pieces that apply to 0003 and 0004, respectively.)
Вложения
- 0001-Put-keywords-in-right-order.patch.nocfbot
- 0002-Remove-js_quotes-union-entry.patch.nocfbot
- 0003-Move-some-code-from-gram.y-to-parse-analysis.patch.nocfbot
- 0004-Remove-JsonBehavior-stuff-from-union.patch.nocfbot
- 0005-Get-rid-of-JsonBehaviorClause.patch.nocfbot
- 0006-Get-rid-of-JsonCommon.patch.nocfbot
On Tue, Nov 21, 2023 at 4:09 PM Peter Eisentraut <peter@eisentraut.org> wrote:
> I looked a bit at the parser additions, because there were some concerns
> expressed that they are quite big.
Thanks Peter.
> It looks like the parser rules were mostly literally copied from the BNF
> in the SQL standard. That's probably a reasonable place to start, but
> now at the end, there is some room for simplification.
>
> Attached are a few patches that apply on top of the 0003 patch. (I
> haven't gotten to 0004 in detail yet.) Some explanations:
>
> 0001-Put-keywords-in-right-order.patch
>
> This is just an unrelated cleanup.
>
> 0002-Remove-js_quotes-union-entry.patch
>
> We usually don't want to put every single node type into the gram.y
> %union. This one can be trivially removed.
>
> 0003-Move-some-code-from-gram.y-to-parse-analysis.patch
>
> Code like this can be postponed to parse analysis, keeping gram.y
> smaller. The error pointer loses a bit of precision, but I think that's
> ok. (There is similar code in your 0004 patch, which could be similarly
> moved.)
>
> 0004-Remove-JsonBehavior-stuff-from-union.patch
>
> Similar to my 0002. This adds a few casts as a result, but that is the
> typical style in gram.y.
Check.
> 0005-Get-rid-of-JsonBehaviorClause.patch
>
> I think this two-level wrapping of the behavior clauses is both
> confusing and overkill. I was trying to just list the on-empty and
> on-error clauses separately in the top-level productions (JSON_VALUE
> etc.), but that led to shift/reduce errors. So the existing rule
> structure is probably ok. But we don't need a separate node type just
> to combine two values and then unpack them again shortly thereafter. So
> I just replaced all this with a list.
OK, a List of two JsonBehavior nodes does sound better in this context
than a whole new parser node.
> 0006-Get-rid-of-JsonCommon.patch
>
> This is an example where the SQL standard BNF is not sensible to apply
> literally. I moved those clauses up directly into their callers, thus
> removing one intermediate levels of rules and also nodes. Also, the
> path name (AS name) stuff is only for JSON_TABLE, so it's not needed in
> this patch. I removed it here, but it would have to be readded in your
> 0004 patch.
OK, done.
> Another thing: In your patch, JSON_EXISTS has a RETURNING clause
> (json_returning_clause_opt), but I don't see that in the standard, and
> also not in the Oracle or Db2 docs. Where did this come from?
TBH, I had no idea till I searched the original SQL/JSON development
thread for a clue and found one at [1]:
===
* Added RETURNING clause to JSON_EXISTS() ("side effect" of
implementation EXISTS PATH columns in JSON_TABLE)
===
So that's talking of EXISTS PATH columns of JSON_TABLE() being able to
have a non-default ("bool") type specified, as follows:
JSON_TABLE(
vals.js::jsonb, 'lax $[*]'
COLUMNS (
exists1 bool EXISTS PATH '$.aaa',
exists2 int EXISTS PATH '$.aaa',
I figured that JSON_EXISTS() doesn't really need a dedicated RETURNING
clause for the above functionality to work.
Attached patch 0004 to fix that; will squash into 0003 before committing.
> With these changes, I think the grammar complexity in your 0003 patch is
> at an acceptable level.
The last line in the chart I sent in the last email now look like this:
17-sqljson 670262 2.57 2640912 1.34
meaning the gram.o text size changes by 2.57% as opposed to 2.97%
before your fixes.
> Similar simplification opportunities exist in
> the 0004 patch, but I haven't worked on that yet. I suggest that you
> focus on getting 0001..0003 committed around this commit fest and then
> deal with 0004 in the next one.
OK, I will keep polishing 0001-0003 with the intent to push it next
week barring objections / damning findings.
I'll also start looking into further improving 0004.
> (Also split up the 0005 patch into the
> pieces that apply to 0003 and 0004, respectively.)
Done.
[1] https://www.postgresql.org/message-id/cf675d1b-47d2-04cd-30f7-c13830341347%40postgrespro.ru
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
Вложения
Hi, On 2023-11-22 15:09:36 +0900, Amit Langote wrote: > OK, I will keep polishing 0001-0003 with the intent to push it next > week barring objections / damning findings. I don't think the patchset is quite there yet. It's definitely getting closer though! I'll try to do another review next week. Greetings, Andres Freund
On Wed, Nov 22, 2023 at 4:37 PM Andres Freund <andres@anarazel.de> wrote: > On 2023-11-22 15:09:36 +0900, Amit Langote wrote: > > OK, I will keep polishing 0001-0003 with the intent to push it next > > week barring objections / damning findings. > > I don't think the patchset is quite there yet. It's definitely getting closer > though! I'll try to do another review next week. That would be great, thank you. I'll post an update on Friday. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
On Fri, Nov 17, 2023 at 6:40 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > On 2023-Nov-17, Amit Langote wrote: > > > On Fri, Nov 17, 2023 at 4:27 PM jian he <jian.universality@gmail.com> wrote: > > > > some enum declaration, ending element need an extra comma? > > > > Didn't know about the convention to have that comma, but I can see it > > is present in most enum definitions. > > It's new. See commit 611806cd726f. I see, thanks. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
On Wed, Nov 22, 2023 at 3:09 PM Amit Langote <amitlangote09@gmail.com> wrote: > The last line in the chart I sent in the last email now look like this: > > 17-sqljson 670262 2.57 2640912 1.34 > > meaning the gram.o text size changes by 2.57% as opposed to 2.97% > before your fixes. Andrew asked off-list what the percent increase is compared to 17dev HEAD. It's 1.27% (was 1.66% with the previous version). -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Hi, On 2023-11-21 12:52:35 +0900, Amit Langote wrote: > version gram.o text bytes %change gram.c bytes %change > > 9.6 534010 - 2108984 - > 10 582554 9.09 2258313 7.08 > 11 584596 0.35 2313475 2.44 > 12 590957 1.08 2341564 1.21 > 13 590381 -0.09 2357327 0.67 > 14 600707 1.74 2428841 3.03 > 15 633180 5.40 2495364 2.73 > 16 653464 3.20 2575269 3.20 > 17-sqljson 672800 2.95 2709422 3.97 > > So if we put SQL/JSON (including JSON_TABLE()) into 17, we end up with a gram.o 2.95% larger than v16, which granted isa somewhat larger bump, though also smaller than with some of recent releases. I think it's ok to increase the size if it's necessary increases - but I also think we've been a bit careless at times, and that that has made the parser slower. There's probably also some "infrastructure" work we could do combat some of the growth too. I know I triggered the use of the .c bytes and text size, but it'd probably more sensible to look at the size of the important tables generated by bison. I think the most relevant defines are: #define YYLAST 117115 #define YYNTOKENS 521 #define YYNNTS 707 #define YYNRULES 3300 #define YYNSTATES 6255 #define YYMAXUTOK 758 I think a lot of the reason we end up with such a big "state transition" space is that a single addition to e.g. col_name_keyword or unreserved_keyword increases the state space substantially, because it adds new transitions to so many places. We're in quadratic territory, I think. We might be able to do some lexer hackery to avoid that, but not sure. Greetings, Andres Freund
minor issue. maybe you can add the following after /src/test/regress/sql/jsonb_sqljson.sql: 127. Test coverage for ExecPrepareJsonItemCoercion function. SELECT JSON_VALUE(jsonb 'null', '$ts' PASSING date '2018-02-21 12:34:56 +10' AS ts returning date); SELECT JSON_VALUE(jsonb 'null', '$ts' PASSING time '2018-02-21 12:34:56 +10' AS ts returning time); SELECT JSON_VALUE(jsonb 'null', '$ts' PASSING timetz '2018-02-21 12:34:56 +10' AS ts returning timetz); SELECT JSON_VALUE(jsonb 'null', '$ts' PASSING timestamp '2018-02-21 12:34:56 +10' AS ts returning timestamp);
+/*
+ * Evaluate or return the step address to evaluate a coercion of a JSON item
+ * to the target type. The former if the coercion must be done right away by
+ * calling the target type's input function, and for some types, by calling
+ * json_populate_type().
+ *
+ * Returns the step address to be performed next.
+ */
+void
+ExecEvalJsonCoercionViaPopulateOrIO(ExprState *state, ExprEvalStep *op,
+ ExprContext *econtext)
the comment seems not right? it does return anything. it did the evaluation.
some logic in ExecEvalJsonCoercionViaPopulateOrIO, like if
(SOFT_ERROR_OCCURRED(escontext_p)) and if
(!InputFunctionCallSafe){...}, seems validated twice,
ExecEvalJsonCoercionFinish also did it. I uncommented the following
part, and still passed the test.
/src/backend/executor/execExprInterp.c
4452: // if (SOFT_ERROR_OCCURRED(escontext_p))
4453: // {
4454: // post_eval->error.value = BoolGetDatum(true);
4455: // *op->resvalue = (Datum) 0;
4456: // *op->resnull = true;
4457: // }
4470: // post_eval->error.value = BoolGetDatum(true);
4471: // *op->resnull = true;
4472: // *op->resvalue = (Datum) 0;
4473: return;
Correct me if I'm wrong.
like in "empty array on empty empty object on error", the "empty
array" refers to constant literal '[]' the assumed data type is jsonb,
the "empty object" refers to const literal '{}', the assumed data type
is jsonb.
--these two queries will fail very early, before ExecEvalJsonExprPath.
SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.a' RETURNING int4range
default '[1.1,2]' on error);
SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.a' RETURNING int4range
default '[1.1,2]' on empty);
-----these four will fail later, and will call
ExecEvalJsonCoercionViaPopulateOrIO twice.
SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
object on empty empty object on error);
SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
array on empty empty array on error);
SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
array on empty empty object on error);
SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
object on empty empty array on error);
-----however these four will not fail.
SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
object on error);
SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
array on error);
SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
array on empty);
SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
object on empty);
should the last four query fail or just return null?
hi.
+ /*
+ * Set information for RETURNING type's input function used by
+ * ExecEvalJsonExprCoercion().
+ */
"ExecEvalJsonExprCoercion" comment is wrong?
+ /*
+ * Step to jump to the EEOP_JSONEXPR_FINISH step skipping over item
+ * coercion steps that will be added below, if any.
+ */
"EEOP_JSONEXPR_FINISH" comment is wrong?
seems on error, on empty behavior have some issues. The following are
tests for json_value.
select json_value(jsonb '{"a":[123.45,1]}', '$.z' returning text
error on error);
select json_value(jsonb '{"a":[123.45,1]}', '$.z' returning text
error on empty); ---imho, this should fail?
select json_value(jsonb '{"a":[123.45,1]}', '$.z' returning text
error on empty error on error);
I did some minor refactoring, please see the attached.
In transformJsonFuncExpr, only (jsexpr->result_coercion) is not null
then do InitJsonItemCoercions.
The ExecInitJsonExpr ending part is for Adjust EEOP_JUMP steps. so I
moved "Set information for RETURNING type" inside
if (jexpr->result_coercion || jexpr->omit_quotes).
there are two if (jexpr->item_coercions). so I combined them together.
Вложения
On Thu, Nov 23, 2023 at 4:38 AM Andres Freund <andres@anarazel.de> wrote:
> On 2023-11-21 12:52:35 +0900, Amit Langote wrote:
> > version gram.o text bytes %change gram.c bytes %change
> >
> > 9.6 534010 - 2108984 -
> > 10 582554 9.09 2258313 7.08
> > 11 584596 0.35 2313475 2.44
> > 12 590957 1.08 2341564 1.21
> > 13 590381 -0.09 2357327 0.67
> > 14 600707 1.74 2428841 3.03
> > 15 633180 5.40 2495364 2.73
> > 16 653464 3.20 2575269 3.20
> > 17-sqljson 672800 2.95 2709422 3.97
> >
> > So if we put SQL/JSON (including JSON_TABLE()) into 17, we end up with a gram.o 2.95% larger than v16, which
grantedis a somewhat larger bump, though also smaller than with some of recent releases.
>
> I think it's ok to increase the size if it's necessary increases - but I also
> think we've been a bit careless at times, and that that has made the parser
> slower. There's probably also some "infrastructure" work we could do combat
> some of the growth too.
>
> I know I triggered the use of the .c bytes and text size, but it'd probably
> more sensible to look at the size of the important tables generated by bison.
> I think the most relevant defines are:
>
> #define YYLAST 117115
> #define YYNTOKENS 521
> #define YYNNTS 707
> #define YYNRULES 3300
> #define YYNSTATES 6255
> #define YYMAXUTOK 758
>
>
> I think a lot of the reason we end up with such a big "state transition" space
> is that a single addition to e.g. col_name_keyword or unreserved_keyword
> increases the state space substantially, because it adds new transitions to so
> many places. We're in quadratic territory, I think. We might be able to do
> some lexer hackery to avoid that, but not sure.
One thing I noticed when looking at the raw parsing times across
versions is that they improved a bit around v12 and then some in v13:
9.0 0.000060 s
9.6 0.000061 s
10 0.000061 s
11 0.000063 s
12 0.000055 s
13 0.000054 s
15 0.000057 s
16 0.000059 s
I think they might be due to the following commits in v12 and v13 resp.:
commit c64d0cd5ce24a344798534f1bc5827a9199b7a6e
Author: Tom Lane <tgl@sss.pgh.pa.us>
Date: Wed Jan 9 19:47:38 2019 -0500
Use perfect hashing, instead of binary search, for keyword lookup.
...
Discussion: https://postgr.es/m/20190103163340.GA15803@britannica.bec.de
commit 7f380c59f800f7e0fb49f45a6ff7787256851a59
Author: Tom Lane <tgl@sss.pgh.pa.us>
Date: Mon Jan 13 15:04:31 2020 -0500
Reduce size of backend scanner's tables.
...
Discussion:
https://postgr.es/m/CACPNZCvaoa3EgVWm5yZhcSTX6RAtaLgniCPcBVOCwm8h3xpWkw@mail.gmail.com
I haven't read the whole discussions there to see if the target(s)
included the metrics you've mentioned though, either directly or
indirectly.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
Some quick grepping gave me this table,
YYLAST YYNTOKENS YYNNTS YYNRULES YYNSTATES YYMAXUTOK
REL9_1_STABLE 69680 429 546 2218 4179 666
REL9_2_STABLE 73834 432 546 2261 4301 669
REL9_3_STABLE 77969 437 558 2322 4471 674
REL9_4_STABLE 79419 442 576 2369 4591 679
REL9_5_STABLE 92495 456 612 2490 4946 693
REL9_6_STABLE 92660 459 618 2515 5006 696
REL_10_STABLE 99601 472 653 2663 5323 709
REL_11_STABLE 102007 480 668 2728 5477 717
REL_12_STABLE 103948 482 667 2724 5488 719
REL_13_STABLE 104224 492 673 2760 5558 729
REL_14_STABLE 108111 503 676 3159 5980 740
REL_15_STABLE 111091 506 688 3206 6090 743
REL_16_STABLE 115435 519 706 3283 6221 756
master 117115 521 707 3300 6255 758
master+v26 121817 537 738 3415 6470 774
and the attached chart. (v26 is with all patches applied, including the
JSON_TABLE one whose grammar has not yet been fully tweaked.)
So, while the jump from v26 is not a trivial one, it seems within
reasonable bounds. For example, the jump between 13 and 14 looks worse.
(I do wonder what happened there.)
--
Álvaro Herrera 48°01'N 7°57'E — https://www.EnterpriseDB.com/
"Cada quien es cada cual y baja las escaleras como quiere" (JMSerrat)
Вложения
{kind=link}
On Fri, Nov 24, 2023 at 9:28 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote:
> Some quick grepping gave me this table,
>
> YYLAST YYNTOKENS YYNNTS YYNRULES YYNSTATES YYMAXUTOK
> REL9_1_STABLE 69680 429 546 2218 4179 666
> REL9_2_STABLE 73834 432 546 2261 4301 669
> REL9_3_STABLE 77969 437 558 2322 4471 674
> REL9_4_STABLE 79419 442 576 2369 4591 679
> REL9_5_STABLE 92495 456 612 2490 4946 693
> REL9_6_STABLE 92660 459 618 2515 5006 696
> REL_10_STABLE 99601 472 653 2663 5323 709
> REL_11_STABLE 102007 480 668 2728 5477 717
> REL_12_STABLE 103948 482 667 2724 5488 719
> REL_13_STABLE 104224 492 673 2760 5558 729
> REL_14_STABLE 108111 503 676 3159 5980 740
> REL_15_STABLE 111091 506 688 3206 6090 743
> REL_16_STABLE 115435 519 706 3283 6221 756
> master 117115 521 707 3300 6255 758
> master+v26 121817 537 738 3415 6470 774
>
> and the attached chart. (v26 is with all patches applied, including the
> JSON_TABLE one whose grammar has not yet been fully tweaked.)
Thanks for the chart.
> So, while the jump from v26 is not a trivial one, it seems within
> reasonable bounds.
Agreed.
> For example, the jump between 13 and 14 looks worse.
> (I do wonder what happened there.)
The following commit sounds like it might be related?
commit 06a7c3154f5bfad65549810cc84f0e3a77b408bf
Author: Tom Lane <tgl@sss.pgh.pa.us>
Date: Fri Sep 18 16:46:26 2020 -0400
Allow most keywords to be used as column labels without requiring AS.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
On 2023-Nov-27, Amit Langote wrote: > > For example, the jump between 13 and 14 looks worse. > > (I do wonder what happened there.) > > The following commit sounds like it might be related? Yes, but not only that one. I did some more trolling in the commit log for the 14 timeframe further and found that the following commits are the ones with highest additions to YYLAST during that cycle: yylast │ yylast_addition │ commit │ subject ────────┼─────────────────┼────────────┼──────────────────────────────────────────────────────────────────────────────── 106051 │ 1883 │ 92bf7e2d02 │ Provide the OR REPLACE option for CREATE TRIGGER. 105325 │ 1869 │ 06a7c3154f │ Allow most keywords to be used as column labels without requiring AS. 104395 │ 1816 │ 45b9805706 │ Allow CURRENT_ROLE where CURRENT_USER is accepted 107537 │ 1139 │ a4d75c86bf │ Extended statistics on expressions 105410 │ 1067 │ b5913f6120 │ Refactor CLUSTER and REINDEX grammar to use DefElem for option lists 106007 │ 965 │ 3696a600e2 │ SEARCH and CYCLE clauses 106864 │ 733 │ be45be9c33 │ Implement GROUP BY DISTINCT 105886 │ 609 │ 844fe9f159 │ Add the ability for the core grammar to have more than one parse target. 108400 │ 571 │ ec48314708 │ Revert per-index collation version tracking feature. 108939 │ 539 │ e6241d8e03 │ Rethink definition of pg_attribute.attcompression. but we also have these: 105521 │ -530 │ 926fa801ac │ Remove undocumented IS [NOT] OF syntax. 104202 │ -640 │ c4325cefba │ Fold AlterForeignTableStmt into AlterTableStmt 104168 │ -718 │ 40c24bfef9 │ Improve our ability to regurgitate SQL-syntax function calls. 108111 │ -828 │ e56bce5d43 │ Reconsider the handling of procedure OUT parameters. 106398 │ -834 │ 71f4c8c6f7 │ ALTER TABLE ... DETACH PARTITION ... CONCURRENTLY 104402 │ -923 │ 2453ea1422 │ Support for OUT parameters in procedures 103456 │ -939 │ 1ed6b89563 │ Remove support for postfix (right-unary) operators. 104343 │ -1178 │ 873ea9ee69 │ Refactor parsing rules for option lists of EXPLAIN, VACUUM and ANALYZE 102784 │ -1417 │ 8f5b596744 │ Refactor AlterExtensionContentsStmt grammar (59 filas) -- Álvaro Herrera Breisgau, Deutschland — https://www.EnterpriseDB.com/ "How strange it is to find the words "Perl" and "saner" in such close proximity, with no apparent sense of irony. I doubt that Larry himself could have managed it." (ncm, http://lwn.net/Articles/174769/)
On 2023-11-27 Mo 05:42, Alvaro Herrera wrote: > On 2023-Nov-27, Amit Langote wrote: > >>> For example, the jump between 13 and 14 looks worse. >>> (I do wonder what happened there.) >> The following commit sounds like it might be related? > Yes, but not only that one. I did some more trolling in the commit log > for the 14 timeframe further and found that the following commits are > the ones with highest additions to YYLAST during that cycle: > > yylast │ yylast_addition │ commit │ subject > ────────┼─────────────────┼────────────┼──────────────────────────────────────────────────────────────────────────────── > 106051 │ 1883 │ 92bf7e2d02 │ Provide the OR REPLACE option for CREATE TRIGGER. > 105325 │ 1869 │ 06a7c3154f │ Allow most keywords to be used as column labels without requiring AS. > 104395 │ 1816 │ 45b9805706 │ Allow CURRENT_ROLE where CURRENT_USER is accepted > 107537 │ 1139 │ a4d75c86bf │ Extended statistics on expressions > 105410 │ 1067 │ b5913f6120 │ Refactor CLUSTER and REINDEX grammar to use DefElem for option lists > 106007 │ 965 │ 3696a600e2 │ SEARCH and CYCLE clauses > 106864 │ 733 │ be45be9c33 │ Implement GROUP BY DISTINCT > 105886 │ 609 │ 844fe9f159 │ Add the ability for the core grammar to have more than one parse target. > 108400 │ 571 │ ec48314708 │ Revert per-index collation version tracking feature. > 108939 │ 539 │ e6241d8e03 │ Rethink definition of pg_attribute.attcompression. > > but we also have these: > > 105521 │ -530 │ 926fa801ac │ Remove undocumented IS [NOT] OF syntax. > 104202 │ -640 │ c4325cefba │ Fold AlterForeignTableStmt into AlterTableStmt > 104168 │ -718 │ 40c24bfef9 │ Improve our ability to regurgitate SQL-syntax function calls. > 108111 │ -828 │ e56bce5d43 │ Reconsider the handling of procedure OUT parameters. > 106398 │ -834 │ 71f4c8c6f7 │ ALTER TABLE ... DETACH PARTITION ... CONCURRENTLY > 104402 │ -923 │ 2453ea1422 │ Support for OUT parameters in procedures > 103456 │ -939 │ 1ed6b89563 │ Remove support for postfix (right-unary) operators. > 104343 │ -1178 │ 873ea9ee69 │ Refactor parsing rules for option lists of EXPLAIN, VACUUM and ANALYZE > 102784 │ -1417 │ 8f5b596744 │ Refactor AlterExtensionContentsStmt grammar > (59 filas) > Interesting. But inferring a speed effect from such changes is difficult. I don't have a good idea about measuring parser speed, but a tool to do that would be useful. Amit has made a start on such measurements, but it's only a start. I'd prefer to have evidence rather than speculation. cheers andrew -- Andrew Dunstan EDB: https://www.enterprisedb.com
On 2023-Nov-27, Andrew Dunstan wrote: > Interesting. But inferring a speed effect from such changes is difficult. I > don't have a good idea about measuring parser speed, but a tool to do that > would be useful. Amit has made a start on such measurements, but it's only a > start. I'd prefer to have evidence rather than speculation. At this point one thing that IMO we cannot afford to do, is stop feature progress work on the name of parser speed. I mean, parser speed is important, and we need to be mindful that what we add is reasonable. But at some point we'll probably have to fix that by parsing differently (a top-down parser, perhaps? Split the parser in smaller pieces that each deal with subsets of the whole thing?) Peter told me earlier today that he noticed that the parser changes he proposed made the parser source code smaller, they result in larger parser tables (in terms of the number of states, I think he said). But source code maintainability is also very important, so my suggestion would be that those changes be absorbed into Amit's commits nonetheless. The amount of effort spent on the parsing aspect on this thread seems in line with what we should always be doing: keep an eye on it, but not disregard the work just because the parser tables have grown. -- Álvaro Herrera 48°01'N 7°57'E — https://www.EnterpriseDB.com/ "La persona que no quería pecar / estaba obligada a sentarse en duras y empinadas sillas / desprovistas, por cierto de blandos atenuantes" (Patricio Vogel)
Hi, On 2023-11-27 15:06:12 +0100, Alvaro Herrera wrote: > On 2023-Nov-27, Andrew Dunstan wrote: > > > Interesting. But inferring a speed effect from such changes is difficult. I > > don't have a good idea about measuring parser speed, but a tool to do that > > would be useful. Amit has made a start on such measurements, but it's only a > > start. I'd prefer to have evidence rather than speculation. Yea, the parser table sizes are influenced by the increase in complexity of the grammar, but it's not a trivial correlation. Bison attempts to compress the state space and it looks like there are some heuristics involved. > At this point one thing that IMO we cannot afford to do, is stop feature > progress work on the name of parser speed. Agreed - I don't think anyone advocated that though. > But at some point we'll probably have to fix that by parsing differently (a > top-down parser, perhaps? Split the parser in smaller pieces that each deal > with subsets of the whole thing?) Yea. Both perhaps. Being able to have sub-grammars would be quite powerful I think, and we might be able to do it without loosing cross-checking from bison that our grammar is conflict free. Even if the resulting combined state space is larger, better locality should more than make up for that. > The amount of effort spent on the parsing aspect on this thread seems in > line with what we should always be doing: keep an eye on it, but not > disregard the work just because the parser tables have grown. I think we've, in other threads, not paid enough attention to it and just added stuff to the grammar in the first way that didn't produce shift/reduce conflicts... Of course a decent part of the problem here is the SQL standard that so seems to like adding one-off forms of grammar (yes, func_expr_common_subexpr, I'm looking at you)... Greetings, Andres Freund
On Thu, Nov 23, 2023 at 6:46 PM jian he <jian.universality@gmail.com> wrote:
>
> -----however these four will not fail.
> SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
> object on error);
> SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
> array on error);
> SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
> array on empty);
> SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
> object on empty);
>
> should the last four query fail or just return null?
I refactored making the above four queries fail.
SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
object on error);
The new error is: ERROR: cannot cast DEFAULT expression of type jsonb
to int4range.
also make the following query fail, which is as expected, imho.
select json_value(jsonb '{"a":[123.45,1]}', '$.z' returning text
error on empty);
Вложения
On Mon, Nov 27, 2023 at 8:57 PM Andrew Dunstan <andrew@dunslane.net> wrote: > Interesting. But inferring a speed effect from such changes is > difficult. I don't have a good idea about measuring parser speed, but a > tool to do that would be useful. Amit has made a start on such > measurements, but it's only a start. I'd prefer to have evidence rather > than speculation. Tom shared this test a while back, and that's the one I've used in the past. The downside for a micro-benchmark like that is that it can monopolize the CPU cache. Cache misses in real world queries are likely much more dominant. https://www.postgresql.org/message-id/14616.1558560331@sss.pgh.pa.us Aside on the relevance of parser speed: I've seen customers successfully lower their monthly cloud bills by moving away from prepared statements, allowing smaller-memory instances.
On 2023-11-28 Tu 00:10, John Naylor wrote: > On Mon, Nov 27, 2023 at 8:57 PM Andrew Dunstan <andrew@dunslane.net> wrote: >> Interesting. But inferring a speed effect from such changes is >> difficult. I don't have a good idea about measuring parser speed, but a >> tool to do that would be useful. Amit has made a start on such >> measurements, but it's only a start. I'd prefer to have evidence rather >> than speculation. > Tom shared this test a while back, and that's the one I've used in the > past. The downside for a micro-benchmark like that is that it can > monopolize the CPU cache. Cache misses in real world queries are > likely much more dominant. > > https://www.postgresql.org/message-id/14616.1558560331@sss.pgh.pa.us Cool, I took this and ran with it a bit. (See attached) Here are comparative timings for 1000 iterations parsing most of the information_schema.sql, all the way back to 9.3: ==== REL9_3_STABLE ==== Time: 3998.701 ms ==== REL9_4_STABLE ==== Time: 3987.596 ms ==== REL9_5_STABLE ==== Time: 4129.049 ms ==== REL9_6_STABLE ==== Time: 4145.777 ms ==== REL_10_STABLE ==== Time: 4140.927 ms (00:04.141) ==== REL_11_STABLE ==== Time: 4145.078 ms (00:04.145) ==== REL_12_STABLE ==== Time: 3528.625 ms (00:03.529) ==== REL_13_STABLE ==== Time: 3356.067 ms (00:03.356) ==== REL_14_STABLE ==== Time: 3401.406 ms (00:03.401) ==== REL_15_STABLE ==== Time: 3372.491 ms (00:03.372) ==== REL_16_STABLE ==== Time: 1654.056 ms (00:01.654) ==== HEAD ==== Time: 1614.949 ms (00:01.615) This is fairly repeatable. The first good news is that the parser is pretty fast. Even 4ms to parse almost all the information schema setup is pretty good. The second piece of good news is that recent modifications have vastly improved the speed. So even if the changes from the SQL/JSON patches eat up a bit of that gain, I think we're in good shape. In a few days I'll re-run the test with the SQL/JSON patches applied. cheers andrew -- Andrew Dunstan EDB: https://www.enterprisedb.com
On 2023-11-28 Tu 15:49, Andrew Dunstan wrote: > > On 2023-11-28 Tu 00:10, John Naylor wrote: >> On Mon, Nov 27, 2023 at 8:57 PM Andrew Dunstan <andrew@dunslane.net> >> wrote: >>> Interesting. But inferring a speed effect from such changes is >>> difficult. I don't have a good idea about measuring parser speed, but a >>> tool to do that would be useful. Amit has made a start on such >>> measurements, but it's only a start. I'd prefer to have evidence rather >>> than speculation. >> Tom shared this test a while back, and that's the one I've used in the >> past. The downside for a micro-benchmark like that is that it can >> monopolize the CPU cache. Cache misses in real world queries are >> likely much more dominant. >> >> https://www.postgresql.org/message-id/14616.1558560331@sss.pgh.pa.us > > > > Cool, I took this and ran with it a bit. (See attached) Here are > comparative timings for 1000 iterations parsing most of the > information_schema.sql, all the way back to 9.3: > > > ==== REL9_3_STABLE ==== > Time: 3998.701 ms > ==== REL9_4_STABLE ==== > Time: 3987.596 ms > ==== REL9_5_STABLE ==== > Time: 4129.049 ms > ==== REL9_6_STABLE ==== > Time: 4145.777 ms > ==== REL_10_STABLE ==== > Time: 4140.927 ms (00:04.141) > ==== REL_11_STABLE ==== > Time: 4145.078 ms (00:04.145) > ==== REL_12_STABLE ==== > Time: 3528.625 ms (00:03.529) > ==== REL_13_STABLE ==== > Time: 3356.067 ms (00:03.356) > ==== REL_14_STABLE ==== > Time: 3401.406 ms (00:03.401) > ==== REL_15_STABLE ==== > Time: 3372.491 ms (00:03.372) > ==== REL_16_STABLE ==== > Time: 1654.056 ms (00:01.654) > ==== HEAD ==== > Time: 1614.949 ms (00:01.615) > > > This is fairly repeatable. > > The first good news is that the parser is pretty fast. Even 4ms to > parse almost all the information schema setup is pretty good. > > The second piece of good news is that recent modifications have vastly > improved the speed. So even if the changes from the SQL/JSON patches > eat up a bit of that gain, I think we're in good shape. > > In a few days I'll re-run the test with the SQL/JSON patches applied. > > To avoid upsetting the cfbot, I published the code here: <https://github.com/adunstan/parser_benchmark> cheers andrew Andrew Dunstan EDB: https://www.enterprisedb.com
Hi, On 2023-11-28 15:57:45 -0500, Andrew Dunstan wrote: > To avoid upsetting the cfbot, I published the code here: > <https://github.com/adunstan/parser_benchmark> Neat. I wonder if we ought to include something like this into core, so that we can more easily evaluate performance effects going forward. Andres
Andrew Dunstan <andrew@dunslane.net> writes:
> Cool, I took this and ran with it a bit. (See attached) Here are
> comparative timings for 1000 iterations parsing most of the
> information_schema.sql, all the way back to 9.3:
> ...
> ==== REL_15_STABLE ====
> Time: 3372.491 ms (00:03.372)
> ==== REL_16_STABLE ====
> Time: 1654.056 ms (00:01.654)
> ==== HEAD ====
> Time: 1614.949 ms (00:01.615)
> This is fairly repeatable.
These results astonished me, because I didn't recall us having done
anything that'd be likely to double the speed of the raw parser.
So I set out to replicate them, intending to bisect to find where
the change happened. And ... I can't replicate them. What I got
is essentially level performance from HEAD back to d10b19e22
(Stamp HEAD as 14devel):
HEAD: 3742.544 ms
d31d30973a (16 stamp): 3871.441 ms
596b5af1d (15 stamp): 3759.319 ms
d10b19e22 (14 stamp): 3730.834 ms
The run-to-run variation is a couple percent, which means that
these differences are down in the noise. This is using your
test code from github (but with 5000 iterations not 1000).
Builds are pretty vanilla with asserts off, on an M1 MacBook Pro.
The bison version might matter here: it's 3.8.2 from MacPorts.
I wondered if you'd tested assert-enabled builds, but there
doesn't seem to be much variation with that turned on either.
So I'm now a bit baffled. Can you provide more color on what
your test setup is?
regards, tom lane
On 2023-11-28 Tu 19:32, Tom Lane wrote: > Andrew Dunstan <andrew@dunslane.net> writes: >> Cool, I took this and ran with it a bit. (See attached) Here are >> comparative timings for 1000 iterations parsing most of the >> information_schema.sql, all the way back to 9.3: >> ... >> ==== REL_15_STABLE ==== >> Time: 3372.491 ms (00:03.372) >> ==== REL_16_STABLE ==== >> Time: 1654.056 ms (00:01.654) >> ==== HEAD ==== >> Time: 1614.949 ms (00:01.615) >> This is fairly repeatable. > These results astonished me, because I didn't recall us having done > anything that'd be likely to double the speed of the raw parser. > So I set out to replicate them, intending to bisect to find where > the change happened. And ... I can't replicate them. What I got > is essentially level performance from HEAD back to d10b19e22 > (Stamp HEAD as 14devel): > > HEAD: 3742.544 ms > d31d30973a (16 stamp): 3871.441 ms > 596b5af1d (15 stamp): 3759.319 ms > d10b19e22 (14 stamp): 3730.834 ms > > The run-to-run variation is a couple percent, which means that > these differences are down in the noise. This is using your > test code from github (but with 5000 iterations not 1000). > Builds are pretty vanilla with asserts off, on an M1 MacBook Pro. > The bison version might matter here: it's 3.8.2 from MacPorts. > > I wondered if you'd tested assert-enabled builds, but there > doesn't seem to be much variation with that turned on either. > > So I'm now a bit baffled. Can you provide more color on what > your test setup is? *sigh* yes, you're right. I inadvertently used a setup that used meson for building REL16_STABLE and HEAD. When I switch it to autoconf I get results that are similar to the earlier branches: ==== REL_16_STABLE ==== Time: 3401.625 ms (00:03.402) ==== HEAD ==== Time: 3419.088 ms (00:03.419) It's not clear to me why that should be. I didn't have assertions enabled anywhere. It's the same version of bison, same compiler throughout. Maybe meson sets a higher level of optimization? It shouldn't really matter, ISTM. cheers andrew -- Andrew Dunstan EDB: https://www.enterprisedb.com
Hi,
On 2023-11-28 20:58:41 -0500, Andrew Dunstan wrote:
> On 2023-11-28 Tu 19:32, Tom Lane wrote:
> > Andrew Dunstan <andrew@dunslane.net> writes:
> > So I'm now a bit baffled. Can you provide more color on what
> > your test setup is?
>
>
> *sigh* yes, you're right. I inadvertently used a setup that used meson for
> building REL16_STABLE and HEAD. When I switch it to autoconf I get results
> that are similar to the earlier branches:
>
>
> ==== REL_16_STABLE ====
> Time: 3401.625 ms (00:03.402)
> ==== HEAD ====
> Time: 3419.088 ms (00:03.419)
>
>
> It's not clear to me why that should be. I didn't have assertions enabled
> anywhere. It's the same version of bison, same compiler throughout. Maybe
> meson sets a higher level of optimization? It shouldn't really matter, ISTM.
Is it possible that you have CFLAGS set in your environment? For reasons that
I find very debatable, configure.ac only adds -O2 when CFLAGS is not set:
# C[XX]FLAGS are selected so:
# If the user specifies something in the environment, that is used.
# else: If the template file set something, that is used.
# else: If coverage was enabled, don't set anything.
# else: If the compiler is GCC, then we use -O2.
# else: If the compiler is something else, then we use -O, unless debugging.
if test "$ac_env_CFLAGS_set" = set; then
CFLAGS=$ac_env_CFLAGS_value
elif test "${CFLAGS+set}" = set; then
: # (keep what template set)
elif test "$enable_coverage" = yes; then
: # no optimization by default
elif test "$GCC" = yes; then
CFLAGS="-O2"
else
# if the user selected debug mode, don't use -O
if test "$enable_debug" != yes; then
CFLAGS="-O"
fi
fi
So if you have CFLAGS set in the environment, we'll not add -O2 to the
compilation flags.
I'd check what the actual flags are when building a some .o.
Greetings,
Andres Freund
On 2023-11-28 Tu 21:10, Andres Freund wrote:
> Hi,
>
> On 2023-11-28 20:58:41 -0500, Andrew Dunstan wrote:
>> On 2023-11-28 Tu 19:32, Tom Lane wrote:
>>> Andrew Dunstan <andrew@dunslane.net> writes:
>>> So I'm now a bit baffled. Can you provide more color on what
>>> your test setup is?
>>
>> *sigh* yes, you're right. I inadvertently used a setup that used meson for
>> building REL16_STABLE and HEAD. When I switch it to autoconf I get results
>> that are similar to the earlier branches:
>>
>>
>> ==== REL_16_STABLE ====
>> Time: 3401.625 ms (00:03.402)
>> ==== HEAD ====
>> Time: 3419.088 ms (00:03.419)
>>
>>
>> It's not clear to me why that should be. I didn't have assertions enabled
>> anywhere. It's the same version of bison, same compiler throughout. Maybe
>> meson sets a higher level of optimization? It shouldn't really matter, ISTM.
> Is it possible that you have CFLAGS set in your environment? For reasons that
> I find very debatable, configure.ac only adds -O2 when CFLAGS is not set:
>
> # C[XX]FLAGS are selected so:
> # If the user specifies something in the environment, that is used.
> # else: If the template file set something, that is used.
> # else: If coverage was enabled, don't set anything.
> # else: If the compiler is GCC, then we use -O2.
> # else: If the compiler is something else, then we use -O, unless debugging.
>
> if test "$ac_env_CFLAGS_set" = set; then
> CFLAGS=$ac_env_CFLAGS_value
> elif test "${CFLAGS+set}" = set; then
> : # (keep what template set)
> elif test "$enable_coverage" = yes; then
> : # no optimization by default
> elif test "$GCC" = yes; then
> CFLAGS="-O2"
> else
> # if the user selected debug mode, don't use -O
> if test "$enable_debug" != yes; then
> CFLAGS="-O"
> fi
> fi
>
> So if you have CFLAGS set in the environment, we'll not add -O2 to the
> compilation flags.
>
> I'd check what the actual flags are when building a some .o.
>
I do have a CFLAGS setting, but for meson I used '-Ddebug=true' and no
buildtype or optimization setting. However, I see that in meson.build
we're defaulting to "buildtype=debugoptimized" as opposed to the
standard meson "buildtype=debug", so I guess that accounts for it.
Still getting used to this stuff.
cheers
andrew
--
Andrew Dunstan
EDB: https://www.enterprisedb.com
On 2023-11-28 Tu 20:58, Andrew Dunstan wrote: > > On 2023-11-28 Tu 19:32, Tom Lane wrote: >> Andrew Dunstan <andrew@dunslane.net> writes: >>> Cool, I took this and ran with it a bit. (See attached) Here are >>> comparative timings for 1000 iterations parsing most of the >>> information_schema.sql, all the way back to 9.3: >>> ... >>> ==== REL_15_STABLE ==== >>> Time: 3372.491 ms (00:03.372) >>> ==== REL_16_STABLE ==== >>> Time: 1654.056 ms (00:01.654) >>> ==== HEAD ==== >>> Time: 1614.949 ms (00:01.615) >>> This is fairly repeatable. >> These results astonished me, because I didn't recall us having done >> anything that'd be likely to double the speed of the raw parser. >> So I set out to replicate them, intending to bisect to find where >> the change happened. And ... I can't replicate them. What I got >> is essentially level performance from HEAD back to d10b19e22 >> (Stamp HEAD as 14devel): >> >> HEAD: 3742.544 ms >> d31d30973a (16 stamp): 3871.441 ms >> 596b5af1d (15 stamp): 3759.319 ms >> d10b19e22 (14 stamp): 3730.834 ms >> >> The run-to-run variation is a couple percent, which means that >> these differences are down in the noise. This is using your >> test code from github (but with 5000 iterations not 1000). >> Builds are pretty vanilla with asserts off, on an M1 MacBook Pro. >> The bison version might matter here: it's 3.8.2 from MacPorts. >> >> I wondered if you'd tested assert-enabled builds, but there >> doesn't seem to be much variation with that turned on either. >> >> So I'm now a bit baffled. Can you provide more color on what >> your test setup is? > > > *sigh* yes, you're right. I inadvertently used a setup that used meson > for building REL16_STABLE and HEAD. When I switch it to autoconf I get > results that are similar to the earlier branches: > > > ==== REL_16_STABLE ==== > Time: 3401.625 ms (00:03.402) > ==== HEAD ==== > Time: 3419.088 ms (00:03.419) > > > It's not clear to me why that should be. I didn't have assertions > enabled anywhere. It's the same version of bison, same compiler > throughout. Maybe meson sets a higher level of optimization? It > shouldn't really matter, ISTM. OK, with completely vanilla autoconf builds, doing 5000 iterations, here are the timings I get, including a test with Amit's latest published patches (with a small fixup due to bitrot). Essentially, with the patches applied it's very slightly slower than master, about the same as release 16, faster than everything earlier. And we hope to improve the grammar impact of the JSON_TABLE piece before we're done. ==== REL_11_STABLE ==== Time: 10381.814 ms (00:10.382) ==== REL_12_STABLE ==== Time: 8151.213 ms (00:08.151) ==== REL_13_STABLE ==== Time: 7774.034 ms (00:07.774) ==== REL_14_STABLE ==== Time: 7911.005 ms (00:07.911) ==== REL_15_STABLE ==== Time: 7868.483 ms (00:07.868) ==== REL_16_STABLE ==== Time: 7729.359 ms (00:07.729) ==== master ==== Time: 7615.815 ms (00:07.616) ==== sqljson ==== Time: 7715.652 ms (00:07.716) Bottom line: I don't think grammar slowdown is a reason to be concerned about these patches. cheers andrew -- Andrew Dunstan EDB: https://www.enterprisedb.com
Hi,
On 2023-11-29 07:37:53 -0500, Andrew Dunstan wrote:
> On 2023-11-28 Tu 21:10, Andres Freund wrote:
> > Hi,
> >
> > On 2023-11-28 20:58:41 -0500, Andrew Dunstan wrote:
> > > On 2023-11-28 Tu 19:32, Tom Lane wrote:
> > > > Andrew Dunstan <andrew@dunslane.net> writes:
> > > > So I'm now a bit baffled. Can you provide more color on what
> > > > your test setup is?
> > >
> > > *sigh* yes, you're right. I inadvertently used a setup that used meson for
> > > building REL16_STABLE and HEAD. When I switch it to autoconf I get results
> > > that are similar to the earlier branches:
> > >
> > >
> > > ==== REL_16_STABLE ====
> > > Time: 3401.625 ms (00:03.402)
> > > ==== HEAD ====
> > > Time: 3419.088 ms (00:03.419)
> > >
> > >
> > > It's not clear to me why that should be. I didn't have assertions enabled
> > > anywhere. It's the same version of bison, same compiler throughout. Maybe
> > > meson sets a higher level of optimization? It shouldn't really matter, ISTM.
> > Is it possible that you have CFLAGS set in your environment? For reasons that
> > I find very debatable, configure.ac only adds -O2 when CFLAGS is not set:
> >
> > # C[XX]FLAGS are selected so:
> > # If the user specifies something in the environment, that is used.
> > # else: If the template file set something, that is used.
> > # else: If coverage was enabled, don't set anything.
> > # else: If the compiler is GCC, then we use -O2.
> > # else: If the compiler is something else, then we use -O, unless debugging.
> >
> > if test "$ac_env_CFLAGS_set" = set; then
> > CFLAGS=$ac_env_CFLAGS_value
> > elif test "${CFLAGS+set}" = set; then
> > : # (keep what template set)
> > elif test "$enable_coverage" = yes; then
> > : # no optimization by default
> > elif test "$GCC" = yes; then
> > CFLAGS="-O2"
> > else
> > # if the user selected debug mode, don't use -O
> > if test "$enable_debug" != yes; then
> > CFLAGS="-O"
> > fi
> > fi
> >
> > So if you have CFLAGS set in the environment, we'll not add -O2 to the
> > compilation flags.
> >
> > I'd check what the actual flags are when building a some .o.
> >
>
> I do have a CFLAGS setting, but for meson I used '-Ddebug=true' and no
> buildtype or optimization setting. However, I see that in meson.build we're
> defaulting to "buildtype=debugoptimized" as opposed to the standard meson
> "buildtype=debug", so I guess that accounts for it.
>
> Still getting used to this stuff.
What I meant was whether you set CFLAGS for the *autoconf* build, because that
will result in an unoptimized build unless you explicitly add -O2 (or whatnot)
to the flags. Doing benchmarking without compiler optimizations is pretty
pointless.
Greetings,
Andres Freund
On 2023-11-29 We 12:42, Andres Freund wrote:
> Hi,
>
> On 2023-11-29 07:37:53 -0500, Andrew Dunstan wrote:
>> On 2023-11-28 Tu 21:10, Andres Freund wrote:
>>> Hi,
>>>
>>> On 2023-11-28 20:58:41 -0500, Andrew Dunstan wrote:
>>>> On 2023-11-28 Tu 19:32, Tom Lane wrote:
>>>>> Andrew Dunstan <andrew@dunslane.net> writes:
>>>>> So I'm now a bit baffled. Can you provide more color on what
>>>>> your test setup is?
>>>> *sigh* yes, you're right. I inadvertently used a setup that used meson for
>>>> building REL16_STABLE and HEAD. When I switch it to autoconf I get results
>>>> that are similar to the earlier branches:
>>>>
>>>>
>>>> ==== REL_16_STABLE ====
>>>> Time: 3401.625 ms (00:03.402)
>>>> ==== HEAD ====
>>>> Time: 3419.088 ms (00:03.419)
>>>>
>>>>
>>>> It's not clear to me why that should be. I didn't have assertions enabled
>>>> anywhere. It's the same version of bison, same compiler throughout. Maybe
>>>> meson sets a higher level of optimization? It shouldn't really matter, ISTM.
>>> Is it possible that you have CFLAGS set in your environment? For reasons that
>>> I find very debatable, configure.ac only adds -O2 when CFLAGS is not set:
>>>
>>> # C[XX]FLAGS are selected so:
>>> # If the user specifies something in the environment, that is used.
>>> # else: If the template file set something, that is used.
>>> # else: If coverage was enabled, don't set anything.
>>> # else: If the compiler is GCC, then we use -O2.
>>> # else: If the compiler is something else, then we use -O, unless debugging.
>>>
>>> if test "$ac_env_CFLAGS_set" = set; then
>>> CFLAGS=$ac_env_CFLAGS_value
>>> elif test "${CFLAGS+set}" = set; then
>>> : # (keep what template set)
>>> elif test "$enable_coverage" = yes; then
>>> : # no optimization by default
>>> elif test "$GCC" = yes; then
>>> CFLAGS="-O2"
>>> else
>>> # if the user selected debug mode, don't use -O
>>> if test "$enable_debug" != yes; then
>>> CFLAGS="-O"
>>> fi
>>> fi
>>>
>>> So if you have CFLAGS set in the environment, we'll not add -O2 to the
>>> compilation flags.
>>>
>>> I'd check what the actual flags are when building a some .o.
>>>
>> I do have a CFLAGS setting, but for meson I used '-Ddebug=true' and no
>> buildtype or optimization setting. However, I see that in meson.build we're
>> defaulting to "buildtype=debugoptimized" as opposed to the standard meson
>> "buildtype=debug", so I guess that accounts for it.
>>
>> Still getting used to this stuff.
> What I meant was whether you set CFLAGS for the *autoconf* build,
That's what I meant too.
> because that
> will result in an unoptimized build unless you explicitly add -O2 (or whatnot)
> to the flags. Doing benchmarking without compiler optimizations is pretty
> pointless.
>
Right. My latest reported results should all be at -O2.
cheers
andrew
--
Andrew Dunstan
EDB: https://www.enterprisedb.com
Hi, On 2023-11-29 14:21:59 -0500, Andrew Dunstan wrote: > On 2023-11-29 We 12:42, Andres Freund wrote: > > > I do have a CFLAGS setting, but for meson I used '-Ddebug=true' and no > > > buildtype or optimization setting. However, I see that in meson.build we're > > > defaulting to "buildtype=debugoptimized" as opposed to the standard meson > > > "buildtype=debug", so I guess that accounts for it. > > > > > > Still getting used to this stuff. > > What I meant was whether you set CFLAGS for the *autoconf* build, > > That's what I meant too. > > > because that > > will result in an unoptimized build unless you explicitly add -O2 (or whatnot) > > to the flags. Doing benchmarking without compiler optimizations is pretty > > pointless. > > > > Right. My latest reported results should all be at -O2. Why are the results suddenly so much slower? Greetings, Andres Freund
> On Nov 29, 2023, at 2:41 PM, Andres Freund <andres@anarazel.de> wrote: > > Hi, > >> On 2023-11-29 14:21:59 -0500, Andrew Dunstan wrote: >> On 2023-11-29 We 12:42, Andres Freund wrote: >>>> I do have a CFLAGS setting, but for meson I used '-Ddebug=true' and no >>>> buildtype or optimization setting. However, I see that in meson.build we're >>>> defaulting to "buildtype=debugoptimized" as opposed to the standard meson >>>> "buildtype=debug", so I guess that accounts for it. >>>> >>>> Still getting used to this stuff. >>> What I meant was whether you set CFLAGS for the *autoconf* build, >> >> That's what I meant too. >> >>> because that >>> will result in an unoptimized build unless you explicitly add -O2 (or whatnot) >>> to the flags. Doing benchmarking without compiler optimizations is pretty >>> pointless. >>> >> >> Right. My latest reported results should all be at -O2. > > Why are the results suddenly so much slower? > > As I mentioned I increased the iteration count to 5000. Cheers Andrew
Hi,
Thanks for the reviews. Replying to all emails here.
On Thu, Nov 23, 2023 at 3:55 PM jian he <jian.universality@gmail.com> wrote:
> minor issue.
> maybe you can add the following after
> /src/test/regress/sql/jsonb_sqljson.sql: 127.
> Test coverage for ExecPrepareJsonItemCoercion function.
>
> SELECT JSON_VALUE(jsonb 'null', '$ts' PASSING date '2018-02-21
> 12:34:56 +10' AS ts returning date);
> SELECT JSON_VALUE(jsonb 'null', '$ts' PASSING time '2018-02-21
> 12:34:56 +10' AS ts returning time);
> SELECT JSON_VALUE(jsonb 'null', '$ts' PASSING timetz '2018-02-21
> 12:34:56 +10' AS ts returning timetz);
> SELECT JSON_VALUE(jsonb 'null', '$ts' PASSING timestamp '2018-02-21
> 12:34:56 +10' AS ts returning timestamp);
Added, though I decided to not include the function name in the
comment and rather reworded the nearby comment a bit.
On Thu, Nov 23, 2023 at 7:47 PM jian he <jian.universality@gmail.com> wrote:
> +/*
> + * Evaluate or return the step address to evaluate a coercion of a JSON item
> + * to the target type. The former if the coercion must be done right away by
> + * calling the target type's input function, and for some types, by calling
> + * json_populate_type().
> + *
> + * Returns the step address to be performed next.
> + */
> +void
> +ExecEvalJsonCoercionViaPopulateOrIO(ExprState *state, ExprEvalStep *op,
> + ExprContext *econtext)
>
> the comment seems not right? it does return anything. it did the evaluation.
Fixed the comment. Actually, I've also restored the old name of the
function because of reworking coercion machinery to use a JsonCoercion
node only for cases where the coercion is performed using I/O or
json_populdate_type().
> some logic in ExecEvalJsonCoercionViaPopulateOrIO, like if
> (SOFT_ERROR_OCCURRED(escontext_p)) and if
> (!InputFunctionCallSafe){...}, seems validated twice,
> ExecEvalJsonCoercionFinish also did it. I uncommented the following
> part, and still passed the test.
> /src/backend/executor/execExprInterp.c
> 4452: // if (SOFT_ERROR_OCCURRED(escontext_p))
> 4453: // {
> 4454: // post_eval->error.value = BoolGetDatum(true);
> 4455: // *op->resvalue = (Datum) 0;
> 4456: // *op->resnull = true;
> 4457: // }
>
> 4470: // post_eval->error.value = BoolGetDatum(true);
> 4471: // *op->resnull = true;
> 4472: // *op->resvalue = (Datum) 0;
> 4473: return;
Yes, you're right. ExecEvalJsonCoercionFinish()'s check for
soft-error suffices.
> Correct me if I'm wrong.
> like in "empty array on empty empty object on error", the "empty
> array" refers to constant literal '[]' the assumed data type is jsonb,
> the "empty object" refers to const literal '{}', the assumed data type
> is jsonb.
That's correct.
> --these two queries will fail very early, before ExecEvalJsonExprPath.
> SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.a' RETURNING int4range
> default '[1.1,2]' on error);
> SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.a' RETURNING int4range
> default '[1.1,2]' on empty);
They fail early because the user-specified DEFAULT [ON ERROR/EMPTY]
expression is coerced at parse time.
> -----these four will fail later, and will call
> ExecEvalJsonCoercionViaPopulateOrIO twice.
> SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
> object on empty empty object on error);
> SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
> array on empty empty array on error);
> SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
> array on empty empty object on error);
> SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
> object on empty empty array on error);
With the latest version, you'll now get the following errors:
ERROR: cannot cast behavior expression of type jsonb to int4range
LINE 1: ...RY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty obje...
^
ERROR: cannot cast behavior expression of type jsonb to int4range
LINE 1: ...RY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty arra...
^
ERROR: cannot cast behavior expression of type jsonb to int4range
LINE 1: ...RY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty arra...
^
ERROR: cannot cast behavior expression of type jsonb to int4range
LINE 1: ...RY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty obje...
> -----however these four will not fail.
> SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
> object on error);
> SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
> array on error);
> SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
> array on empty);
> SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
> object on empty);
> should the last four query fail or just return null?
You'll get the following with the latest version:
ERROR: cannot cast behavior expression of type jsonb to int4range
LINE 1: ...RY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty obje...
^
ERROR: cannot cast behavior expression of type jsonb to int4range
LINE 1: ...RY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty arra...
^
ERROR: cannot cast behavior expression of type jsonb to int4range
LINE 1: ...RY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty arra...
^
ERROR: cannot cast behavior expression of type jsonb to int4range
LINE 1: ...RY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty obje...
On Fri, Nov 24, 2023 at 5:41 PM jian he <jian.universality@gmail.com> wrote:
> + /*
> + * Set information for RETURNING type's input function used by
> + * ExecEvalJsonExprCoercion().
> + */
> "ExecEvalJsonExprCoercion" comment is wrong?
Comment removed in the latest version.
> + /*
> + * Step to jump to the EEOP_JSONEXPR_FINISH step skipping over item
> + * coercion steps that will be added below, if any.
> + */
> "EEOP_JSONEXPR_FINISH" comment is wrong?
Not wrong though the wording is misleading. It's describing what will
happen at runtime -- jump after performing result_coercion to skip
over any steps that might be present between the last of the
result_coercion steps and the EEOP_JSONEXPR_FINISH step. You can see
the code that follows is adding steps for JSON_VALUE "item" coercions,
which will be skipped by performing that jump.
> seems on error, on empty behavior have some issues. The following are
> tests for json_value.
> select json_value(jsonb '{"a":[123.45,1]}', '$.z' returning text
> error on error);
> select json_value(jsonb '{"a":[123.45,1]}', '$.z' returning text
> error on empty); ---imho, this should fail?
> select json_value(jsonb '{"a":[123.45,1]}', '$.z' returning text
> error on empty error on error);
Yes, I agree there are issues. I think these all should give an
error. So, the no-match scenario (empty=true) should give an error
both when ERROR ON EMPTY is specified and also if only ERROR ON ERROR
is specified. With the current code, ON ERROR basically overrides ON
EMPTY clause which seems wrong.
With the latest patch, you'll get the following:
select json_value(jsonb '{"a":[123.45,1]}', '$.z' returning text
error on error);
ERROR: no SQL/JSON item
select json_value(jsonb '{"a":[123.45,1]}', '$.z' returning text
error on empty); ---imho, this should fail?
ERROR: no SQL/JSON item
select json_value(jsonb '{"a":[123.45,1]}', '$.z' returning text
error on empty error on error);
ERROR: no SQL/JSON item
> I did some minor refactoring, please see the attached.
> In transformJsonFuncExpr, only (jsexpr->result_coercion) is not null
> then do InitJsonItemCoercions.
Makes sense.
> The ExecInitJsonExpr ending part is for Adjust EEOP_JUMP steps. so I
> moved "Set information for RETURNING type" inside
> if (jexpr->result_coercion || jexpr->omit_quotes).
> there are two if (jexpr->item_coercions). so I combined them together.
This code has moved to a different place with the latest patch,
wherein I've redesigned the io/populate-based coercions.
On Tue, Nov 28, 2023 at 11:01 AM jian he <jian.universality@gmail.com> wrote:
> On Thu, Nov 23, 2023 at 6:46 PM jian he <jian.universality@gmail.com> wrote:
> >
> > -----however these four will not fail.
> > SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
> > object on error);
> > SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
> > array on error);
> > SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
> > array on empty);
> > SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
> > object on empty);
> >
> > should the last four query fail or just return null?
>
> I refactored making the above four queries fail.
> SELECT JSON_QUERY(jsonb '{"a":[3,4]}', '$.z' RETURNING int4range empty
> object on error);
> The new error is: ERROR: cannot cast DEFAULT expression of type jsonb
> to int4range.
>
> also make the following query fail, which is as expected, imho.
> select json_value(jsonb '{"a":[123.45,1]}', '$.z' returning text
> error on empty);
Agreed. I've incorporated your suggestions into the latest patch
though not using the exact code that you shared.
Attached please find the latest patches. Other than the points
mentioned above, I've made substantial changes to how JsonBehavior and
JsonCoercion nodes work.
I've attempted to trim down the JSON_TABLE grammar (0004), but this is
all I've managed so far. Among other things, I couldn't refactor the
grammar to do away with the following:
+%nonassoc NESTED
+%left PATH
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
Вложения
On 2023-Dec-05, Amit Langote wrote:
> I've attempted to trim down the JSON_TABLE grammar (0004), but this is
> all I've managed so far. Among other things, I couldn't refactor the
> grammar to do away with the following:
>
> +%nonassoc NESTED
> +%left PATH
To recap, the reason we're arguing about this is that this creates two
new precedence classes, which are higher than everything else. Judging
by the discussios in thread [1], this is not acceptable. Without either
those new classes or the two hacks I describe below, the grammar has the
following shift/reduce conflict:
State 6220
2331 json_table_column_definition: NESTED . path_opt Sconst COLUMNS '(' json_table_column_definition_list ')'
2332 | NESTED . path_opt Sconst AS name COLUMNS '(' json_table_column_definition_list
')'
2636 unreserved_keyword: NESTED .
PATH shift, and go to state 6286
SCONST reduce using rule 2336 (path_opt)
PATH [reduce using rule 2636 (unreserved_keyword)]
$default reduce using rule 2636 (unreserved_keyword)
path_opt go to state 6287
First, while the grammar uses "NESTED path_opt" in the relevant productions, I
noticed that there's no test that uses NESTED without PATH, so if we break that
case, we won't notice. I propose we remove the PATH keyword from one of
the tests in jsonb_sqljson.sql in order to make sure the grammar
continues to work after whatever hacking we do:
diff --git a/src/test/regress/expected/jsonb_sqljson.out b/src/test/regress/expected/jsonb_sqljson.out
index 7e8ae6a696..8fd2385cdc 100644
--- a/src/test/regress/expected/jsonb_sqljson.out
+++ b/src/test/regress/expected/jsonb_sqljson.out
@@ -1548,7 +1548,7 @@ HINT: JSON_TABLE column names must be distinct from one another.
SELECT * FROM JSON_TABLE(
jsonb 'null', '$[*]' AS p0
COLUMNS (
- NESTED PATH '$' AS p1 COLUMNS (
+ NESTED '$' AS p1 COLUMNS (
NESTED PATH '$' AS p11 COLUMNS ( foo int ),
NESTED PATH '$' AS p12 COLUMNS ( bar int )
),
diff --git a/src/test/regress/sql/jsonb_sqljson.sql b/src/test/regress/sql/jsonb_sqljson.sql
index ea5db88b40..ea9b4ff8b6 100644
--- a/src/test/regress/sql/jsonb_sqljson.sql
+++ b/src/test/regress/sql/jsonb_sqljson.sql
@@ -617,7 +617,7 @@ SELECT * FROM JSON_TABLE(
SELECT * FROM JSON_TABLE(
jsonb 'null', '$[*]' AS p0
COLUMNS (
- NESTED PATH '$' AS p1 COLUMNS (
+ NESTED '$' AS p1 COLUMNS (
NESTED PATH '$' AS p11 COLUMNS ( foo int ),
NESTED PATH '$' AS p12 COLUMNS ( bar int )
),
Having done that, AFAICS there are two possible fixes for the grammar.
One is to keep the idea of assigning precedence explicitly to these
keywords, but do something less hackish -- we can put NESTED together
with UNBOUNDED, and classify PATH in the IDENT group. This requires no
further changes. This would make NESTED PATH follow the same rationale
as UNBOUNDED FOLLOWING / UNBOUNDED PRECEDING. Here's is a preliminary
patch for that (the large comment above needs to be updated.)
diff --git a/src/backend/parser/gram.y b/src/backend/parser/gram.y
index c15fcf2eb2..1493ac7580 100644
--- a/src/backend/parser/gram.y
+++ b/src/backend/parser/gram.y
@@ -887,9 +887,9 @@ static Node *makeRecursiveViewSelect(char *relname, List *aliases, Node *query);
* json_predicate_type_constraint and json_key_uniqueness_constraint_opt
* productions (see comments there).
*/
-%nonassoc UNBOUNDED /* ideally would have same precedence as IDENT */
+%nonassoc UNBOUNDED NESTED /* ideally would have same precedence as IDENT */
%nonassoc IDENT PARTITION RANGE ROWS GROUPS PRECEDING FOLLOWING CUBE ROLLUP
- SET KEYS OBJECT_P SCALAR VALUE_P WITH WITHOUT
+ SET KEYS OBJECT_P SCALAR VALUE_P WITH WITHOUT PATH
%left Op OPERATOR /* multi-character ops and user-defined operators */
%left '+' '-'
%left '*' '/' '%'
@@ -911,8 +911,6 @@ static Node *makeRecursiveViewSelect(char *relname, List *aliases, Node *query);
*/
%left JOIN CROSS LEFT FULL RIGHT INNER_P NATURAL
-%nonassoc NESTED
-%left PATH
%%
/*
The other thing we can do is use the two-token lookahead trick, by
declaring
%token NESTED_LA
and using the parser.c code to replace NESTED with NESTED_LA when it is
followed by PATH. This doesn't require assigning precedence to
anything. We do need to expand the two rules that have "NESTED
opt_path Sconst" to each be two rules, one for "NESTED_LA PATH Sconst"
and another for "NESTED Sconst". So the opt_path production goes away.
This preliminary patch does that. (I did not touch the ecpg grammar, but
it needs an update too.)
diff --git a/src/backend/parser/gram.y b/src/backend/parser/gram.y
index c15fcf2eb2..8e4c1d4ebe 100644
--- a/src/backend/parser/gram.y
+++ b/src/backend/parser/gram.y
@@ -817,7 +817,7 @@ static Node *makeRecursiveViewSelect(char *relname, List *aliases, Node *query);
* FORMAT_LA, NULLS_LA, WITH_LA, and WITHOUT_LA are needed to make the grammar
* LALR(1).
*/
-%token FORMAT_LA NOT_LA NULLS_LA WITH_LA WITHOUT_LA
+%token FORMAT_LA NESTED_LA NOT_LA NULLS_LA WITH_LA WITHOUT_LA
/*
* The grammar likewise thinks these tokens are keywords, but they are never
@@ -911,8 +911,6 @@ static Node *makeRecursiveViewSelect(char *relname, List *aliases, Node *query);
*/
%left JOIN CROSS LEFT FULL RIGHT INNER_P NATURAL
-%nonassoc NESTED
-%left PATH
%%
/*
@@ -16771,7 +16769,7 @@ json_table_column_definition:
n->location = @1;
$$ = (Node *) n;
}
- | NESTED path_opt Sconst
+ | NESTED_LA PATH Sconst
COLUMNS '(' json_table_column_definition_list ')'
{
JsonTableColumn *n = makeNode(JsonTableColumn);
@@ -16783,7 +16781,19 @@ json_table_column_definition:
n->location = @1;
$$ = (Node *) n;
}
- | NESTED path_opt Sconst AS name
+ | NESTED Sconst
+ COLUMNS '(' json_table_column_definition_list ')'
+ {
+ JsonTableColumn *n = makeNode(JsonTableColumn);
+
+ n->coltype = JTC_NESTED;
+ n->pathspec = $2;
+ n->pathname = NULL;
+ n->columns = $5;
+ n->location = @1;
+ $$ = (Node *) n;
+ }
+ | NESTED_LA PATH Sconst AS name
COLUMNS '(' json_table_column_definition_list ')'
{
JsonTableColumn *n = makeNode(JsonTableColumn);
@@ -16795,6 +16805,19 @@ json_table_column_definition:
n->location = @1;
$$ = (Node *) n;
}
+ | NESTED Sconst AS name
+ COLUMNS '(' json_table_column_definition_list ')'
+ {
+ JsonTableColumn *n = makeNode(JsonTableColumn);
+
+ n->coltype = JTC_NESTED;
+ n->pathspec = $2;
+ n->pathname = $4;
+ n->columns = $7;
+ n->location = @1;
+ $$ = (Node *) n;
+ }
+
;
json_table_column_path_specification_clause_opt:
@@ -16802,11 +16825,6 @@ json_table_column_path_specification_clause_opt:
| /* EMPTY */ { $$ = NULL; }
;
-path_opt:
- PATH { }
- | /* EMPTY */ { }
- ;
-
json_table_plan_clause_opt:
PLAN '(' json_table_plan ')' { $$ = $3; }
| PLAN DEFAULT '(' json_table_default_plan_choices ')'
diff --git a/src/backend/parser/parser.c b/src/backend/parser/parser.c
index e17c310cc1..e3092f2c3e 100644
--- a/src/backend/parser/parser.c
+++ b/src/backend/parser/parser.c
@@ -138,6 +138,7 @@ base_yylex(YYSTYPE *lvalp, YYLTYPE *llocp, core_yyscan_t yyscanner)
switch (cur_token)
{
case FORMAT:
+ case NESTED:
cur_token_length = 6;
break;
case NOT:
@@ -204,6 +205,16 @@ base_yylex(YYSTYPE *lvalp, YYLTYPE *llocp, core_yyscan_t yyscanner)
}
break;
+ case NESTED:
+ /* Replace NESTED by NESTED_LA if it's followed by PATH */
+ switch (next_token)
+ {
+ case PATH:
+ cur_token = NESTED_LA;
+ break;
+ }
+ break;
+
case NOT:
/* Replace NOT by NOT_LA if it's followed by BETWEEN, IN, etc */
switch (next_token)
I don't know which of the two "fixes" is less bad. Like Amit, I was not
able to find a solution to the problem by merely attaching precedences
to rules. (I did not try to mess with the precedence of
unreserved_keyword, because I'm pretty sure that would not be a good
solution even if I could make it work.)
[1] https://postgr.es/m/CADT4RqBPdbsZW7HS1jJP319TMRHs1hzUiP=iRJYR6UqgHCrgNQ@mail.gmail.com
--
Álvaro Herrera 48°01'N 7°57'E — https://www.EnterpriseDB.com/
Thanks Alvaro.
On Wed, Dec 6, 2023 at 7:43 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote:
> On 2023-Dec-05, Amit Langote wrote:
>
> > I've attempted to trim down the JSON_TABLE grammar (0004), but this is
> > all I've managed so far. Among other things, I couldn't refactor the
> > grammar to do away with the following:
> >
> > +%nonassoc NESTED
> > +%left PATH
>
> To recap, the reason we're arguing about this is that this creates two
> new precedence classes, which are higher than everything else. Judging
> by the discussios in thread [1], this is not acceptable. Without either
> those new classes or the two hacks I describe below, the grammar has the
> following shift/reduce conflict:
>
> State 6220
>
> 2331 json_table_column_definition: NESTED . path_opt Sconst COLUMNS '(' json_table_column_definition_list ')'
> 2332 | NESTED . path_opt Sconst AS name COLUMNS '(' json_table_column_definition_list
')'
> 2636 unreserved_keyword: NESTED .
>
> PATH shift, and go to state 6286
>
> SCONST reduce using rule 2336 (path_opt)
> PATH [reduce using rule 2636 (unreserved_keyword)]
> $default reduce using rule 2636 (unreserved_keyword)
>
> path_opt go to state 6287
>
>
>
> First, while the grammar uses "NESTED path_opt" in the relevant productions, I
> noticed that there's no test that uses NESTED without PATH, so if we break that
> case, we won't notice. I propose we remove the PATH keyword from one of
> the tests in jsonb_sqljson.sql in order to make sure the grammar
> continues to work after whatever hacking we do:
>
> diff --git a/src/test/regress/expected/jsonb_sqljson.out b/src/test/regress/expected/jsonb_sqljson.out
> index 7e8ae6a696..8fd2385cdc 100644
> --- a/src/test/regress/expected/jsonb_sqljson.out
> +++ b/src/test/regress/expected/jsonb_sqljson.out
> @@ -1548,7 +1548,7 @@ HINT: JSON_TABLE column names must be distinct from one another.
> SELECT * FROM JSON_TABLE(
> jsonb 'null', '$[*]' AS p0
> COLUMNS (
> - NESTED PATH '$' AS p1 COLUMNS (
> + NESTED '$' AS p1 COLUMNS (
> NESTED PATH '$' AS p11 COLUMNS ( foo int ),
> NESTED PATH '$' AS p12 COLUMNS ( bar int )
> ),
> diff --git a/src/test/regress/sql/jsonb_sqljson.sql b/src/test/regress/sql/jsonb_sqljson.sql
> index ea5db88b40..ea9b4ff8b6 100644
> --- a/src/test/regress/sql/jsonb_sqljson.sql
> +++ b/src/test/regress/sql/jsonb_sqljson.sql
> @@ -617,7 +617,7 @@ SELECT * FROM JSON_TABLE(
> SELECT * FROM JSON_TABLE(
> jsonb 'null', '$[*]' AS p0
> COLUMNS (
> - NESTED PATH '$' AS p1 COLUMNS (
> + NESTED '$' AS p1 COLUMNS (
> NESTED PATH '$' AS p11 COLUMNS ( foo int ),
> NESTED PATH '$' AS p12 COLUMNS ( bar int )
> ),
Fixed the test case like that in the attached.
> Having done that, AFAICS there are two possible fixes for the grammar.
> One is to keep the idea of assigning precedence explicitly to these
> keywords, but do something less hackish -- we can put NESTED together
> with UNBOUNDED, and classify PATH in the IDENT group. This requires no
> further changes. This would make NESTED PATH follow the same rationale
> as UNBOUNDED FOLLOWING / UNBOUNDED PRECEDING. Here's is a preliminary
> patch for that (the large comment above needs to be updated.)
>
> diff --git a/src/backend/parser/gram.y b/src/backend/parser/gram.y
> index c15fcf2eb2..1493ac7580 100644
> --- a/src/backend/parser/gram.y
> +++ b/src/backend/parser/gram.y
> @@ -887,9 +887,9 @@ static Node *makeRecursiveViewSelect(char *relname, List *aliases, Node *query);
> * json_predicate_type_constraint and json_key_uniqueness_constraint_opt
> * productions (see comments there).
> */
> -%nonassoc UNBOUNDED /* ideally would have same precedence as IDENT */
> +%nonassoc UNBOUNDED NESTED /* ideally would have same precedence as IDENT */
> %nonassoc IDENT PARTITION RANGE ROWS GROUPS PRECEDING FOLLOWING CUBE ROLLUP
> - SET KEYS OBJECT_P SCALAR VALUE_P WITH WITHOUT
> + SET KEYS OBJECT_P SCALAR VALUE_P WITH WITHOUT PATH
> %left Op OPERATOR /* multi-character ops and user-defined operators */
> %left '+' '-'
> %left '*' '/' '%'
> @@ -911,8 +911,6 @@ static Node *makeRecursiveViewSelect(char *relname, List *aliases, Node *query);
> */
> %left JOIN CROSS LEFT FULL RIGHT INNER_P NATURAL
>
> -%nonassoc NESTED
> -%left PATH
> %%
>
> /*
>
>
> The other thing we can do is use the two-token lookahead trick, by
> declaring
> %token NESTED_LA
> and using the parser.c code to replace NESTED with NESTED_LA when it is
> followed by PATH. This doesn't require assigning precedence to
> anything. We do need to expand the two rules that have "NESTED
> opt_path Sconst" to each be two rules, one for "NESTED_LA PATH Sconst"
> and another for "NESTED Sconst". So the opt_path production goes away.
> This preliminary patch does that. (I did not touch the ecpg grammar, but
> it needs an update too.)
>
> diff --git a/src/backend/parser/gram.y b/src/backend/parser/gram.y
> index c15fcf2eb2..8e4c1d4ebe 100644
> --- a/src/backend/parser/gram.y
> +++ b/src/backend/parser/gram.y
> @@ -817,7 +817,7 @@ static Node *makeRecursiveViewSelect(char *relname, List *aliases, Node *query);
> * FORMAT_LA, NULLS_LA, WITH_LA, and WITHOUT_LA are needed to make the grammar
> * LALR(1).
> */
> -%token FORMAT_LA NOT_LA NULLS_LA WITH_LA WITHOUT_LA
> +%token FORMAT_LA NESTED_LA NOT_LA NULLS_LA WITH_LA WITHOUT_LA
>
> /*
> * The grammar likewise thinks these tokens are keywords, but they are never
> @@ -911,8 +911,6 @@ static Node *makeRecursiveViewSelect(char *relname, List *aliases, Node *query);
> */
> %left JOIN CROSS LEFT FULL RIGHT INNER_P NATURAL
>
> -%nonassoc NESTED
> -%left PATH
> %%
>
> /*
> @@ -16771,7 +16769,7 @@ json_table_column_definition:
> n->location = @1;
> $$ = (Node *) n;
> }
> - | NESTED path_opt Sconst
> + | NESTED_LA PATH Sconst
> COLUMNS '(' json_table_column_definition_list ')'
> {
> JsonTableColumn *n = makeNode(JsonTableColumn);
> @@ -16783,7 +16781,19 @@ json_table_column_definition:
> n->location = @1;
> $$ = (Node *) n;
> }
> - | NESTED path_opt Sconst AS name
> + | NESTED Sconst
> + COLUMNS '(' json_table_column_definition_list ')'
> + {
> + JsonTableColumn *n = makeNode(JsonTableColumn);
> +
> + n->coltype = JTC_NESTED;
> + n->pathspec = $2;
> + n->pathname = NULL;
> + n->columns = $5;
> + n->location = @1;
> + $$ = (Node *) n;
> + }
> + | NESTED_LA PATH Sconst AS name
> COLUMNS '(' json_table_column_definition_list ')'
> {
> JsonTableColumn *n = makeNode(JsonTableColumn);
> @@ -16795,6 +16805,19 @@ json_table_column_definition:
> n->location = @1;
> $$ = (Node *) n;
> }
> + | NESTED Sconst AS name
> + COLUMNS '(' json_table_column_definition_list ')'
> + {
> + JsonTableColumn *n = makeNode(JsonTableColumn);
> +
> + n->coltype = JTC_NESTED;
> + n->pathspec = $2;
> + n->pathname = $4;
> + n->columns = $7;
> + n->location = @1;
> + $$ = (Node *) n;
> + }
> +
> ;
>
> json_table_column_path_specification_clause_opt:
> @@ -16802,11 +16825,6 @@ json_table_column_path_specification_clause_opt:
> | /* EMPTY */ { $$ = NULL; }
> ;
>
> -path_opt:
> - PATH { }
> - | /* EMPTY */ { }
> - ;
> -
> json_table_plan_clause_opt:
> PLAN '(' json_table_plan ')' { $$ = $3; }
> | PLAN DEFAULT '(' json_table_default_plan_choices ')'
> diff --git a/src/backend/parser/parser.c b/src/backend/parser/parser.c
> index e17c310cc1..e3092f2c3e 100644
> --- a/src/backend/parser/parser.c
> +++ b/src/backend/parser/parser.c
> @@ -138,6 +138,7 @@ base_yylex(YYSTYPE *lvalp, YYLTYPE *llocp, core_yyscan_t yyscanner)
> switch (cur_token)
> {
> case FORMAT:
> + case NESTED:
> cur_token_length = 6;
> break;
> case NOT:
> @@ -204,6 +205,16 @@ base_yylex(YYSTYPE *lvalp, YYLTYPE *llocp, core_yyscan_t yyscanner)
> }
> break;
>
> + case NESTED:
> + /* Replace NESTED by NESTED_LA if it's followed by PATH */
> + switch (next_token)
> + {
> + case PATH:
> + cur_token = NESTED_LA;
> + break;
> + }
> + break;
> +
> case NOT:
> /* Replace NOT by NOT_LA if it's followed by BETWEEN, IN, etc */
> switch (next_token)
>
>
> I don't know which of the two "fixes" is less bad.
I think I'm inclined toward adapting the LA-token fix (attached 0005),
because we've done that before with SQL/JSON constructors patch.
Also, if I understand the concerns that Tom mentioned at [1]
correctly, maybe we'd be better off not assigning precedence to
symbols as much as possible, so there's that too against the approach
#1.
Also I've attached 0006 to add news tests under ECPG for the SQL/JSON
query functions, which I haven't done so far but realized after you
mentioned ECPG. It also includes the ECPG variant of the LA-token
fix. I'll eventually merge it into 0003 and 0004 after expanding the
test cases some more. I do wonder what kinds of tests we normally add
to ECPG suite but not others?
Finally, I also fixed a couple of silly mistakes in 0003 around
transformJsonBehavior() and some further assorted tightening in the ON
ERROR / EMPTY expression coercion handling code.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
Вложения
- v28-0005-JSON_TABLE-don-t-assign-precedence-to-NESTED-PAT.patch
- v28-0002-Add-soft-error-handling-to-populate_record_field.patch
- v28-0006-ECPG-add-SQL-JSON-query-function-tests-and-parse.patch
- v28-0004-JSON_TABLE.patch
- v28-0003-SQL-JSON-query-functions.patch
- v28-0001-Add-soft-error-handling-to-some-expression-nodes.patch
On 2023-Dec-06, Amit Langote wrote: > I think I'm inclined toward adapting the LA-token fix (attached 0005), > because we've done that before with SQL/JSON constructors patch. > Also, if I understand the concerns that Tom mentioned at [1] > correctly, maybe we'd be better off not assigning precedence to > symbols as much as possible, so there's that too against the approach > #1. Sounds ok to me, but I'm happy for this decision to be overridden by others with more experience in parser code. > Also I've attached 0006 to add news tests under ECPG for the SQL/JSON > query functions, which I haven't done so far but realized after you > mentioned ECPG. It also includes the ECPG variant of the LA-token > fix. I'll eventually merge it into 0003 and 0004 after expanding the > test cases some more. I do wonder what kinds of tests we normally add > to ECPG suite but not others? Well, I only added tests to the ecpg suite in the previous round of SQL/JSON deeds because its grammar was being modified, so it seemed possible that it'd break. Because you're also going to modify its parser.c, it seems reasonable to expect tests to be added. I wouldn't expect to have to do this for other patches, because it should behave like straight SQL usage. Looking at 0002 I noticed that populate_array_assign_ndims() is called in some places and its return value is not checked, so we'd ultimately return JSON_SUCCESS even though there's actually a soft error stored somewhere. I don't know if it's possible to hit this in practice, but it seems odd. Looking at get_json_object_as_hash(), I think its comment is not explicit enough about its behavior when an error is stored in escontext, so its hard to judge whether its caller is doing the right thing (I think it is). OTOH, populate_record seems to have the same issue, but callers of that definitely seem to be doing the wrong thing -- namely, not checking whether an error was saved; particularly populate_composite seems to rely on the returned tuple, even though an error might have been reported. (I didn't look at the subsequent patches in the series to see if these things were fixed later.) -- Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/
On Wed, Dec 6, 2023 at 10:02 PM Amit Langote <amitlangote09@gmail.com> wrote:
>
> Finally, I also fixed a couple of silly mistakes in 0003 around
> transformJsonBehavior() and some further assorted tightening in the ON
> ERROR / EMPTY expression coercion handling code.
>
typo:
+ * If a soft-error occurs, it will be checked by EEOP_JSONEXPR_COECION_FINISH
json_exists no RETURNING clause.
so the following part in src/backend/parser/parse_expr.c can be removed?
+ else if (jsexpr->returning->typid != BOOLOID)
+ {
+ Node *coercion_expr;
+ CaseTestExpr *placeholder = makeNode(CaseTestExpr);
+ int location = exprLocation((Node *) jsexpr);
+
+ /*
+ * We abuse CaseTestExpr here as placeholder to pass the
+ * result of evaluating JSON_EXISTS to the coercion
+ * expression.
+ */
+ placeholder->typeId = BOOLOID;
+ placeholder->typeMod = -1;
+ placeholder->collation = InvalidOid;
+
+ coercion_expr =
+ coerce_to_target_type(pstate, (Node *) placeholder, BOOLOID,
+ jsexpr->returning->typid,
+ jsexpr->returning->typmod,
+ COERCION_EXPLICIT,
+ COERCE_IMPLICIT_CAST,
+ location);
+
+ if (coercion_expr == NULL)
+ ereport(ERROR,
+ (errcode(ERRCODE_CANNOT_COERCE),
+ errmsg("cannot cast type %s to %s",
+ format_type_be(BOOLOID),
+ format_type_be(jsexpr->returning->typid)),
+ parser_coercion_errposition(pstate, location, (Node *) jsexpr)));
+
+ if (coercion_expr != (Node *) placeholder)
+ jsexpr->result_coercion = coercion_expr;
+ }
Similarly, since JSON_EXISTS has no RETURNING clause, the following
also needs to be refactored?
+ /*
+ * Disallow FORMAT specification in the RETURNING clause of JSON_EXISTS()
+ * and JSON_VALUE().
+ */
+ if (func->output &&
+ (func->op == JSON_VALUE_OP || func->op == JSON_EXISTS_OP))
+ {
+ JsonFormat *format = func->output->returning->format;
+
+ if (format->format_type != JS_FORMAT_DEFAULT ||
+ format->encoding != JS_ENC_DEFAULT)
+ ereport(ERROR,
+ (errcode(ERRCODE_SYNTAX_ERROR),
+ errmsg("cannot specify FORMAT in RETURNING clause of %s",
+ func->op == JSON_VALUE_OP ? "JSON_VALUE()" :
+ "JSON_EXISTS()"),
+ parser_errposition(pstate, format->location)));
Here are a couple of small patches to tidy up the parser a bit in your v28-0004 (JSON_TABLE) patch. It's not a lot; the rest looks okay to me. (I don't have an opinion on the concurrent discussion on resolving some precedence issues.)
Вложения
On Thu, Dec 7, 2023 at 12:26 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote:
> On 2023-Dec-06, Amit Langote wrote:
> > I think I'm inclined toward adapting the LA-token fix (attached 0005),
> > because we've done that before with SQL/JSON constructors patch.
> > Also, if I understand the concerns that Tom mentioned at [1]
> > correctly, maybe we'd be better off not assigning precedence to
> > symbols as much as possible, so there's that too against the approach
> > #1.
>
> Sounds ok to me, but I'm happy for this decision to be overridden by
> others with more experience in parser code.
OK, I'll wait to hear from others.
> > Also I've attached 0006 to add news tests under ECPG for the SQL/JSON
> > query functions, which I haven't done so far but realized after you
> > mentioned ECPG. It also includes the ECPG variant of the LA-token
> > fix. I'll eventually merge it into 0003 and 0004 after expanding the
> > test cases some more. I do wonder what kinds of tests we normally add
> > to ECPG suite but not others?
>
> Well, I only added tests to the ecpg suite in the previous round of
> SQL/JSON deeds because its grammar was being modified, so it seemed
> possible that it'd break. Because you're also going to modify its
> parser.c, it seems reasonable to expect tests to be added. I wouldn't
> expect to have to do this for other patches, because it should behave
> like straight SQL usage.
Ah, ok, so ecpg tests are only needed in the JSON_TABLE patch.
> Looking at 0002 I noticed that populate_array_assign_ndims() is called
> in some places and its return value is not checked, so we'd ultimately
> return JSON_SUCCESS even though there's actually a soft error stored
> somewhere. I don't know if it's possible to hit this in practice, but
> it seems odd.
Indeed, fixed. I think I missed the callbacks in JsonSemAction
because I only looked at functions directly reachable from
json_populate_record() or something.
> Looking at get_json_object_as_hash(), I think its comment is not
> explicit enough about its behavior when an error is stored in escontext,
> so its hard to judge whether its caller is doing the right thing (I
> think it is).
I've modified get_json_object_as_hash() to return NULL if
pg_parse_json_or_errsave() returns false because of an error. Maybe
that's an overkill but that's at least a bit clearer than a hash table
of indeterminate state. Added a comment too.
> OTOH, populate_record seems to have the same issue, but
> callers of that definitely seem to be doing the wrong thing -- namely,
> not checking whether an error was saved; particularly populate_composite
> seems to rely on the returned tuple, even though an error might have
> been reported.
Right, populate_composite() should return NULL after checking escontext. Fixed.
On Thu, Dec 7, 2023 at 12:11 PM jian he <jian.universality@gmail.com> wrote:
> typo:
> + * If a soft-error occurs, it will be checked by EEOP_JSONEXPR_COECION_FINISH
Fixed.
> json_exists no RETURNING clause.
> so the following part in src/backend/parser/parse_expr.c can be removed?
>
> + else if (jsexpr->returning->typid != BOOLOID)
> + {
> + Node *coercion_expr;
> + CaseTestExpr *placeholder = makeNode(CaseTestExpr);
> + int location = exprLocation((Node *) jsexpr);
> +
> + /*
> + * We abuse CaseTestExpr here as placeholder to pass the
> + * result of evaluating JSON_EXISTS to the coercion
> + * expression.
> + */
> + placeholder->typeId = BOOLOID;
> + placeholder->typeMod = -1;
> + placeholder->collation = InvalidOid;
> +
> + coercion_expr =
> + coerce_to_target_type(pstate, (Node *) placeholder, BOOLOID,
> + jsexpr->returning->typid,
> + jsexpr->returning->typmod,
> + COERCION_EXPLICIT,
> + COERCE_IMPLICIT_CAST,
> + location);
> +
> + if (coercion_expr == NULL)
> + ereport(ERROR,
> + (errcode(ERRCODE_CANNOT_COERCE),
> + errmsg("cannot cast type %s to %s",
> + format_type_be(BOOLOID),
> + format_type_be(jsexpr->returning->typid)),
> + parser_coercion_errposition(pstate, location, (Node *) jsexpr)));
> +
> + if (coercion_expr != (Node *) placeholder)
> + jsexpr->result_coercion = coercion_expr;
> + }
This is needed in the JSON_TABLE patch as explained in [1]. Moved
this part into patch 0004.
> Similarly, since JSON_EXISTS has no RETURNING clause, the following
> also needs to be refactored?
>
> + /*
> + * Disallow FORMAT specification in the RETURNING clause of JSON_EXISTS()
> + * and JSON_VALUE().
> + */
> + if (func->output &&
> + (func->op == JSON_VALUE_OP || func->op == JSON_EXISTS_OP))
> + {
> + JsonFormat *format = func->output->returning->format;
> +
> + if (format->format_type != JS_FORMAT_DEFAULT ||
> + format->encoding != JS_ENC_DEFAULT)
> + ereport(ERROR,
> + (errcode(ERRCODE_SYNTAX_ERROR),
> + errmsg("cannot specify FORMAT in RETURNING clause of %s",
> + func->op == JSON_VALUE_OP ? "JSON_VALUE()" :
> + "JSON_EXISTS()"),
> + parser_errposition(pstate, format->location)));
This one needs to be fixed, so done.
On Thu, Dec 7, 2023 at 5:25 PM Peter Eisentraut <peter@eisentraut.org> wrote:
> Here are a couple of small patches to tidy up the parser a bit in your
> v28-0004 (JSON_TABLE) patch. It's not a lot; the rest looks okay to me.
Thanks Peter. I've merged these into 0004.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
[1] https://www.postgresql.org/message-id/CA%2BHiwqGsByGXLUniPxBgZjn6PeDr0Scp0jxxQOmBXy63tiJ60A%40mail.gmail.com
Вложения
Op 12/7/23 om 10:32 schreef Amit Langote: > On Thu, Dec 7, 2023 at 12:26 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: >> On 2023-Dec-06, Amit Langote wrote: >>> I think I'm inclined toward adapting the LA-token fix (attached 0005), > This one needs to be fixed, so done. > > On Thu, Dec 7, 2023 at 5:25 PM Peter Eisentraut <peter@eisentraut.org> wrote: >> Here are a couple of small patches to tidy up the parser a bit in your >> v28-0004 (JSON_TABLE) patch. It's not a lot; the rest looks okay to me. > > Thanks Peter. I've merged these into 0004. Hm, this set doesn't apply for me. 0003 gives error, see below (sorrty for my interspersed bash echoing - seemed best to leave it in. (I'm using patch; should be all right, no? Am I doing it wrong?) -- [2023.12.07 11:29:39 json_table2] patch 1 of 5 (json_table2) [/home/aardvark/download/pgpatches/0170/json_table/20231207/v29-0001-Add-soft-error-handling-to-some-expression-nodes.patch] rv [] # [ok] OK, patch returned [0] so now break and continue (all is well) -- [2023.12.07 11:29:39 json_table2] patch 2 of 5 (json_table2) [/home/aardvark/download/pgpatches/0170/json_table/20231207/v29-0002-Add-soft-error-handling-to-populate_record_field.patch] rv [0] # [ok] OK, patch returned [0] so now break and continue (all is well) -- [2023.12.07 11:29:39 json_table2] patch 3 of 5 (json_table2) [/home/aardvark/download/pgpatches/0170/json_table/20231207/v29-0003-SQL-JSON-query-functions.patch] rv [0] # [ok] File src/interfaces/ecpg/test/sql/sqljson_queryfuncs: git binary diffs are not supported. patch apply failed: rv = 1 patch file: /home/aardvark/download/pgpatches/0170/json_table/20231207/v29-0003-SQL-JSON-query-functions.patch rv [1] # [ok] The text leading up to this was: -------------------------- |From 712b95c8a1a3dd683852ac151e229440af783243 Mon Sep 17 00:00:00 2001 |From: Amit Langote <amitlan@postgresql.org> |Date: Tue, 5 Dec 2023 14:33:25 +0900 |Subject: [PATCH v29 3/5] SQL/JSON query functions |MIME-Version: 1.0 |Content-Type: text/plain; charset=UTF-8 |Content-Transfer-Encoding: 8bit | |This introduces the SQL/JSON functions for querying JSON data using |jsonpath expressions. The functions are: | |JSON_EXISTS() |JSON_QUERY() |JSON_VALUE() | Erik > -- > Thanks, Amit Langote > EDB: http://www.enterprisedb.com > > [1] https://www.postgresql.org/message-id/CA%2BHiwqGsByGXLUniPxBgZjn6PeDr0Scp0jxxQOmBXy63tiJ60A%40mail.gmail.com
two JsonCoercionState in src/tools/pgindent/typedefs.list.
+JsonCoercionState
JsonConstructorExpr
JsonConstructorExprState
JsonConstructorType
JsonEncoding
+JsonExpr
+JsonExprOp
+JsonExprPostEvalState
+JsonExprState
+JsonCoercionState
+ post_eval->jump_eval_coercion = jsestate->jump_eval_result_coercion;
+ if (jbv == NULL)
+ {
+ /* Will be coerced with result_coercion. */
+ *op->resvalue = (Datum) 0;
+ *op->resnull = true;
+ }
+ else if (!error && !empty)
+ {
+ Assert(jbv != NULL);
the above "Assert(jbv != NULL);" will always be true?
based on:
json_behavior_clause_opt:
json_behavior ON EMPTY_P
{ $$ = list_make2($1, NULL); }
| json_behavior ON ERROR_P
{ $$ = list_make2(NULL, $1); }
| json_behavior ON EMPTY_P json_behavior ON ERROR_P
{ $$ = list_make2($1, $4); }
| /* EMPTY */
{ $$ = list_make2(NULL, NULL); }
;
so
+ if (func->behavior)
+ {
+ on_empty = linitial(func->behavior);
+ on_error = lsecond(func->behavior);
+ }
`if (func->behavior)` will always be true?
By the way, in the above "{ $$ = list_make2($1, $4); }" what does $4
refer to? (I don't know gram.y....)
+ jsexpr->formatted_expr = transformJsonValueExpr(pstate, constructName,
+ func->context_item,
+ JS_FORMAT_JSON,
+ InvalidOid, false);
+
+ Assert(jsexpr->formatted_expr != NULL);
This Assert is unnecessary? transformJsonValueExpr function already
has an assert in the end, will it fail that one first?
On 2023-Dec-07, Erik Rijkers wrote: > Hm, this set doesn't apply for me. 0003 gives error, see below (sorrty for > my interspersed bash echoing - seemed best to leave it in. > (I'm using patch; should be all right, no? Am I doing it wrong?) There's definitely something wrong with the patch file; that binary file should not be there. OTOH clearly if we ever start including binary files in our tree, `patch` is no longer going to cut it. Maybe we won't ever do that, though. There's also a complaint about whitespace. -- Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/ "El destino baraja y nosotros jugamos" (A. Schopenhauer)
On Thu, Dec 7, 2023 at 7:51 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > On 2023-Dec-07, Erik Rijkers wrote: > > > Hm, this set doesn't apply for me. 0003 gives error, see below (sorrty for > > my interspersed bash echoing - seemed best to leave it in. > > (I'm using patch; should be all right, no? Am I doing it wrong?) > > There's definitely something wrong with the patch file; that binary file > should not be there. OTOH clearly if we ever start including binary > files in our tree, `patch` is no longer going to cut it. Maybe we won't > ever do that, though. > > There's also a complaint about whitespace. Looks like I messed something up when using git (rebase -i). :-( Apply-able patches attached, including fixes based on jian he's comments. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
On Thu, Dec 7, 2023 at 7:39 PM jian he <jian.universality@gmail.com> wrote:
> based on:
> json_behavior_clause_opt:
> json_behavior ON EMPTY_P
> { $$ = list_make2($1, NULL); }
> | json_behavior ON ERROR_P
> { $$ = list_make2(NULL, $1); }
> | json_behavior ON EMPTY_P json_behavior ON ERROR_P
> { $$ = list_make2($1, $4); }
> | /* EMPTY */
> { $$ = list_make2(NULL, NULL); }
> ;
> so
> + if (func->behavior)
> + {
> + on_empty = linitial(func->behavior);
> + on_error = lsecond(func->behavior);
> + }
Yeah, maybe.
> `if (func->behavior)` will always be true?
> By the way, in the above "{ $$ = list_make2($1, $4); }" what does $4
> refer to? (I don't know gram.y....)
$1 and $4 refer to the 1st and 4th symbols in the following:
json_behavior ON EMPTY_P json_behavior ON ERROR_P
So $1 gives the json_behavior (JsonBehavior) node for ON EMPTY and $4
gives that for ON ERROR.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
On Wed, Dec 6, 2023 at 10:26 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > I think I'm inclined toward adapting the LA-token fix (attached 0005), > > because we've done that before with SQL/JSON constructors patch. > > Also, if I understand the concerns that Tom mentioned at [1] > > correctly, maybe we'd be better off not assigning precedence to > > symbols as much as possible, so there's that too against the approach > > #1. > > Sounds ok to me, but I'm happy for this decision to be overridden by > others with more experience in parser code. In my experience, the lookahead solution is typically suitable when the keywords involved aren't used very much in other parts of the grammar. I think the situation that basically gets you into trouble is if there's some way to have a situation where NESTED shouldn't be changed to NESTED_LA when PATH immediately follows. For example, if NESTED could be used like DISTINCT in a SELECT query: SELECT DISTINCT a, b, c FROM whatever ...then that would be a strong indication in my mind that we shouldn't use the lookahead solution, because what if you substitute "path" for "a"? Now you have a mess. I haven't gone over the grammar changes in a lot of detail so I'm not sure how much risk there is here. It looks to me like there's some syntax that goes NESTED [PATH] 'literal string', and if that were the only use of NESTED or PATH then I think we'd be completely fine. I see that PATH b_expr also gets added to xmltable_column_option_el, and that's a little more worrying, because you don't really want to see keywords that are used for special lookahead rules in places where they can creep into general expressions, but it seems like it might still be OK as long as NESTED doesn't also start to get used in other places. If you ever create a situation where NESTED can bump up against PATH without wanting that to turn into NESTED_LA PATH, then I think it's likely that this whole approach will unravel. As long as we don't think that will ever happen, I think it's probably OK. If we do think it's going to happen, then we should probably grit our teeth and use precedence. -- Robert Haas EDB: http://www.enterprisedb.com
I noticed that JSON_TABLE uses an explicit FORMAT JSON in one of the rules, instead of using json_format_clause_opt like everywhere else. I wondered why, and noticed that it's because it wants to set coltype JTC_FORMATTED when the clause is present but JTC_REGULAR otherwise. This seemed a little odd, but I thought to split json_format_clause_opt in two productions, one without the empty rule (json_format_clause) and another with it. This is not a groundbreaking improvement, but it seems more natural, and it helps contain the FORMAT stuff a little better. I also noticed while at it that we can do away not only with the json_encoding_clause_opt clause, but also with makeJsonEncoding(). The attach patch does it. This is not derived from the patches you're currently working on; it's more of a revise of the previous SQL/JSON code I committed in 7081ac46ace8. It goes before your 0003 and has a couple of easily resolved conflicts with both 0003 and 0004; then in 0004 you have to edit the JSON_TABLE rule that has FORMAT_LA and replace that with json_format_clause. -- Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/ "El que vive para el futuro es un iluso, y el que vive para el pasado, un imbécil" (Luis Adler, "Los tripulantes de la noche")
Вложения
On Fri, Dec 8, 2023 at 2:19 AM Robert Haas <robertmhaas@gmail.com> wrote: > On Wed, Dec 6, 2023 at 10:26 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > > > I think I'm inclined toward adapting the LA-token fix (attached 0005), > > > because we've done that before with SQL/JSON constructors patch. > > > Also, if I understand the concerns that Tom mentioned at [1] > > > correctly, maybe we'd be better off not assigning precedence to > > > symbols as much as possible, so there's that too against the approach > > > #1. > > > > Sounds ok to me, but I'm happy for this decision to be overridden by > > others with more experience in parser code. > > In my experience, the lookahead solution is typically suitable when > the keywords involved aren't used very much in other parts of the > grammar. I think the situation that basically gets you into trouble is > if there's some way to have a situation where NESTED shouldn't be > changed to NESTED_LA when PATH immediately follows. For example, if > NESTED could be used like DISTINCT in a SELECT query: > > SELECT DISTINCT a, b, c FROM whatever > > ...then that would be a strong indication in my mind that we shouldn't > use the lookahead solution, because what if you substitute "path" for > "a"? Now you have a mess. > > I haven't gone over the grammar changes in a lot of detail so I'm not > sure how much risk there is here. It looks to me like there's some > syntax that goes NESTED [PATH] 'literal string', and if that were the > only use of NESTED or PATH then I think we'd be completely fine. I see > that PATH b_expr also gets added to xmltable_column_option_el, and > that's a little more worrying, because you don't really want to see > keywords that are used for special lookahead rules in places where > they can creep into general expressions, but it seems like it might > still be OK as long as NESTED doesn't also start to get used in other > places. If you ever create a situation where NESTED can bump up > against PATH without wanting that to turn into NESTED_LA PATH, then I > think it's likely that this whole approach will unravel. As long as we > don't think that will ever happen, I think it's probably OK. If we do > think it's going to happen, then we should probably grit our teeth and > use precedence. Would it be messy to replace the lookahead approach by whatever's suiable *in the future* when it becomes necessary to do so? -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
On Fri, Dec 8, 2023 at 3:42 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > I noticed that JSON_TABLE uses an explicit FORMAT JSON in one of the > rules, instead of using json_format_clause_opt like everywhere else. I > wondered why, and noticed that it's because it wants to set coltype > JTC_FORMATTED when the clause is present but JTC_REGULAR otherwise. > This seemed a little odd, but I thought to split json_format_clause_opt > in two productions, one without the empty rule (json_format_clause) and > another with it. This is not a groundbreaking improvement, but it seems > more natural, and it helps contain the FORMAT stuff a little better. > > I also noticed while at it that we can do away not only with the > json_encoding_clause_opt clause, but also with makeJsonEncoding(). > > The attach patch does it. This is not derived from the patches you're > currently working on; it's more of a revise of the previous SQL/JSON > code I committed in 7081ac46ace8. > > It goes before your 0003 and has a couple of easily resolved conflicts > with both 0003 and 0004; then in 0004 you have to edit the JSON_TABLE > rule that has FORMAT_LA and replace that with json_format_clause. Thanks. I've adapted that as the attached 0004. I started thinking that some changes to src/backend/utils/adt/jsonpath_exec.c made by SQL/JSON query functions patch belong in a separate refactoring patch, which I've attached as patch 0003. They are the changes related to how jsonpath executor takes and extracts "variables". -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
- v31-0004-Simplify-productions-for-FORMAT-JSON-ENCODING-na.patch
- v31-0007-JSON_TABLE-don-t-assign-precedence-to-NESTED-PAT.patch
- v31-0006-JSON_TABLE.patch
- v31-0003-Refactor-code-used-by-jsonpath-executor-to-fetch.patch
- v31-0005-SQL-JSON-query-functions.patch
- v31-0001-Add-soft-error-handling-to-some-expression-nodes.patch
- v31-0002-Add-soft-error-handling-to-populate_record_field.patch
On Fri, Dec 8, 2023 at 1:59 AM Amit Langote <amitlangote09@gmail.com> wrote: > Would it be messy to replace the lookahead approach by whatever's > suiable *in the future* when it becomes necessary to do so? It might be. Changing grammar rules to tends to change corner-case behavior if nothing else. We're best off picking the approach that we think is correct long term. -- Robert Haas EDB: http://www.enterprisedb.com
On 2023-12-08 Fr 11:37, Robert Haas wrote: > On Fri, Dec 8, 2023 at 1:59 AM Amit Langote <amitlangote09@gmail.com> wrote: >> Would it be messy to replace the lookahead approach by whatever's >> suiable *in the future* when it becomes necessary to do so? > It might be. Changing grammar rules to tends to change corner-case > behavior if nothing else. We're best off picking the approach that we > think is correct long term. All this makes me wonder if Alvaro's first suggested solution (adding NESTED to the UNBOUNDED precedence level) wouldn't be better after all. cheers andrew -- Andrew Dunstan EDB: https://www.enterprisedb.com
Hi, On 2023-12-07 21:07:59 +0900, Amit Langote wrote: > --- a/src/include/executor/execExpr.h > +++ b/src/include/executor/execExpr.h > @@ -16,6 +16,7 @@ > > #include "executor/nodeAgg.h" > #include "nodes/execnodes.h" > +#include "nodes/miscnodes.h" > > /* forward references to avoid circularity */ > struct ExprEvalStep; > @@ -168,6 +169,7 @@ typedef enum ExprEvalOp > > /* evaluate assorted special-purpose expression types */ > EEOP_IOCOERCE, > + EEOP_IOCOERCE_SAFE, > EEOP_DISTINCT, > EEOP_NOT_DISTINCT, > EEOP_NULLIF, > @@ -547,6 +549,7 @@ typedef struct ExprEvalStep > bool *checknull; > /* OID of domain type */ > Oid resulttype; > + ErrorSaveContext *escontext; > } domaincheck; > > /* for EEOP_CONVERT_ROWTYPE */ > @@ -776,6 +779,7 @@ extern void ExecEvalParamExec(ExprState *state, ExprEvalStep *op, > ExprContext *econtext); > extern void ExecEvalParamExtern(ExprState *state, ExprEvalStep *op, > ExprContext *econtext); > +extern void ExecEvalCoerceViaIOSafe(ExprState *state, ExprEvalStep *op); > extern void ExecEvalSQLValueFunction(ExprState *state, ExprEvalStep *op); > extern void ExecEvalCurrentOfExpr(ExprState *state, ExprEvalStep *op); > extern void ExecEvalNextValueExpr(ExprState *state, ExprEvalStep *op); > diff --git a/src/include/nodes/execnodes.h b/src/include/nodes/execnodes.h > index 5d7f17dee0..6a7118d300 100644 > --- a/src/include/nodes/execnodes.h > +++ b/src/include/nodes/execnodes.h > @@ -34,6 +34,7 @@ > #include "fmgr.h" > #include "lib/ilist.h" > #include "lib/pairingheap.h" > +#include "nodes/miscnodes.h" > #include "nodes/params.h" > #include "nodes/plannodes.h" > #include "nodes/tidbitmap.h" > @@ -129,6 +130,12 @@ typedef struct ExprState > > Datum *innermost_domainval; > bool *innermost_domainnull; > + > + /* > + * For expression nodes that support soft errors. Should be set to NULL > + * before calling ExecInitExprRec() if the caller wants errors thrown. > + */ > + ErrorSaveContext *escontext; > } ExprState; Why do we need this both in ExprState *and* in ExprEvalStep? > From 38b53297b2d435d5cebf78c1f81e4748fed6c8b6 Mon Sep 17 00:00:00 2001 > From: Amit Langote <amitlan@postgresql.org> > Date: Wed, 22 Nov 2023 13:18:49 +0900 > Subject: [PATCH v30 2/5] Add soft error handling to populate_record_field() > > An uncoming patch would like the ability to call it from the > executor for some SQL/JSON expression nodes and ask to suppress any > errors that may occur. > > This commit does two things mainly: > > * It modifies the various interfaces internal to jsonfuncs.c to pass > the ErrorSaveContext around. > > * Make necessary modifications to handle the cases where the > processing is aborted partway through various functions that take > an ErrorSaveContext when a soft error occurs. > > Note that the above changes are only intended to suppress errors in > the functions in jsonfuncs.c, but not those in any external functions > that the functions in jsonfuncs.c in turn call, such as those from > arrayfuncs.c. It is assumed that the various populate_* functions > validate the data before passing those to external functions. > > Discussion: https://postgr.es/m/CA+HiwqE4XTdfb1nW=Ojoy_tQSRhYt-q_kb6i5d4xcKyrLC1Nbg@mail.gmail.com The code here is getting substantially more verbose / less readable. I wonder if there's something more general that could be improved to make this less painful? I'd not at all be surprised if this caused a measurable slowdown. > --- > src/backend/utils/adt/jsonfuncs.c | 310 +++++++++++++++++++++++------- > 1 file changed, 236 insertions(+), 74 deletions(-) > /* functions supporting jsonb_delete, jsonb_set and jsonb_concat */ > static JsonbValue *IteratorConcat(JsonbIterator **it1, JsonbIterator **it2, > @@ -2484,12 +2491,12 @@ populate_array_report_expected_array(PopulateArrayContext *ctx, int ndim) > if (ndim <= 0) > { > if (ctx->colname) > - ereport(ERROR, > + errsave(ctx->escontext, > (errcode(ERRCODE_INVALID_TEXT_REPRESENTATION), > errmsg("expected JSON array"), > errhint("See the value of key \"%s\".", ctx->colname))); > else > - ereport(ERROR, > + errsave(ctx->escontext, > (errcode(ERRCODE_INVALID_TEXT_REPRESENTATION), > errmsg("expected JSON array"))); > } > @@ -2506,13 +2513,13 @@ populate_array_report_expected_array(PopulateArrayContext *ctx, int ndim) > appendStringInfo(&indices, "[%d]", ctx->sizes[i]); > > if (ctx->colname) > - ereport(ERROR, > + errsave(ctx->escontext, > (errcode(ERRCODE_INVALID_TEXT_REPRESENTATION), > errmsg("expected JSON array"), > errhint("See the array element %s of key \"%s\".", > indices.data, ctx->colname))); > else > - ereport(ERROR, > + errsave(ctx->escontext, > (errcode(ERRCODE_INVALID_TEXT_REPRESENTATION), > errmsg("expected JSON array"), > errhint("See the array element %s.", > @@ -2520,8 +2527,13 @@ populate_array_report_expected_array(PopulateArrayContext *ctx, int ndim) > } > } It seems mildly errorprone to use errsave() but not have any returns in the code after the errsave()s - it seems plausible that somebody later would come and add more code expecting to not reach the later code. > +/* > + * Validate and set ndims for populating an array with some > + * populate_array_*() function. > + * > + * Returns false if the input (ndims) is erratic. I don't think "erratic" is the right word, "erroneous" maybe? > From 35cf1759f67a1c8ca7691aa87727a9f2c404b7c2 Mon Sep 17 00:00:00 2001 > From: Amit Langote <amitlan@postgresql.org> > Date: Tue, 5 Dec 2023 14:33:25 +0900 > Subject: [PATCH v30 3/5] SQL/JSON query functions > MIME-Version: 1.0 > Content-Type: text/plain; charset=UTF-8 > Content-Transfer-Encoding: 8bit > > This introduces the SQL/JSON functions for querying JSON data using > jsonpath expressions. The functions are: > > JSON_EXISTS() > JSON_QUERY() > JSON_VALUE() > > JSON_EXISTS() tests if the jsonpath expression applied to the jsonb > value yields any values. > > JSON_VALUE() must return a single value, and an error occurs if it > tries to return multiple values. > > JSON_QUERY() must return a json object or array, and there are > various WRAPPER options for handling scalar or multi-value results. > Both these functions have options for handling EMPTY and ERROR > conditions. > > All of these functions only operate on jsonb. The workaround for now > is to cast the argument to jsonb. > > Author: Nikita Glukhov <n.gluhov@postgrespro.ru> > Author: Teodor Sigaev <teodor@sigaev.ru> > Author: Oleg Bartunov <obartunov@gmail.com> > Author: Alexander Korotkov <aekorotkov@gmail.com> > Author: Andrew Dunstan <andrew@dunslane.net> > Author: Amit Langote <amitlangote09@gmail.com> > Author: Peter Eisentraut <peter@eisentraut.org> > Author: jian he <jian.universality@gmail.com> > > Reviewers have included (in no particular order) Andres Freund, Alexander > Korotkov, Pavel Stehule, Andrew Alsup, Erik Rijkers, Zihong Yu, > Himanshu Upadhyaya, Daniel Gustafsson, Justin Pryzby, Álvaro Herrera, > jian he, Anton A. Melnikov, Nikita Malakhov, Peter Eisentraut > > Discussion: https://postgr.es/m/cd0bb935-0158-78a7-08b5-904886deac4b@postgrespro.ru > Discussion: https://postgr.es/m/20220616233130.rparivafipt6doj3@alap3.anarazel.de > Discussion: https://postgr.es/m/abd9b83b-aa66-f230-3d6d-734817f0995d%40postgresql.org > Discussion: https://postgr.es/m/CA+HiwqE4XTdfb1nW=Ojoy_tQSRhYt-q_kb6i5d4xcKyrLC1Nbg@mail.gmail.com > --- > doc/src/sgml/func.sgml | 151 +++ > src/backend/catalog/sql_features.txt | 12 +- > src/backend/executor/execExpr.c | 363 +++++++ > src/backend/executor/execExprInterp.c | 365 ++++++- > src/backend/jit/llvm/llvmjit.c | 2 + > src/backend/jit/llvm/llvmjit_expr.c | 140 +++ > src/backend/jit/llvm/llvmjit_types.c | 4 + > src/backend/nodes/makefuncs.c | 18 + > src/backend/nodes/nodeFuncs.c | 238 ++++- > src/backend/optimizer/path/costsize.c | 3 +- > src/backend/optimizer/util/clauses.c | 19 + > src/backend/parser/gram.y | 178 +++- > src/backend/parser/parse_expr.c | 621 ++++++++++- > src/backend/parser/parse_target.c | 15 + > src/backend/utils/adt/formatting.c | 44 + > src/backend/utils/adt/jsonb.c | 31 + > src/backend/utils/adt/jsonfuncs.c | 52 +- > src/backend/utils/adt/jsonpath.c | 255 +++++ > src/backend/utils/adt/jsonpath_exec.c | 391 ++++++- > src/backend/utils/adt/ruleutils.c | 136 +++ > src/include/executor/execExpr.h | 133 +++ > src/include/fmgr.h | 1 + > src/include/jit/llvmjit.h | 1 + > src/include/nodes/makefuncs.h | 2 + > src/include/nodes/parsenodes.h | 47 + > src/include/nodes/primnodes.h | 130 +++ > src/include/parser/kwlist.h | 11 + > src/include/utils/formatting.h | 1 + > src/include/utils/jsonb.h | 1 + > src/include/utils/jsonfuncs.h | 5 + > src/include/utils/jsonpath.h | 27 + > src/interfaces/ecpg/preproc/ecpg.trailer | 28 + > src/test/regress/expected/json_sqljson.out | 18 + > src/test/regress/expected/jsonb_sqljson.out | 1032 +++++++++++++++++++ > src/test/regress/parallel_schedule | 2 +- > src/test/regress/sql/json_sqljson.sql | 11 + > src/test/regress/sql/jsonb_sqljson.sql | 337 ++++++ > src/tools/pgindent/typedefs.list | 18 + > 38 files changed, 4767 insertions(+), 76 deletions(-) I think it'd be worth trying to break this into smaller bits - it's not easy to review this at once. > +/* > + * Information about the state of JsonPath* evaluation. > + */ > +typedef struct JsonExprPostEvalState > +{ > + /* Did JsonPath* evaluation cause an error? */ > + NullableDatum error; > + > + /* Is the result of JsonPath* evaluation empty? */ > + NullableDatum empty; > + > + /* > + * ExecEvalJsonExprPath() will set this to the address of the step to > + * use to coerce the result of JsonPath* evaluation to the RETURNING type. > + * Also see the description of possible step addresses that this could be > + * set to in the definition of JsonExprState. > + */ > +#define FIELDNO_JSONEXPRPOSTEVALSTATE_JUMP_EVAL_COERCION 2 > + int jump_eval_coercion; > +} JsonExprPostEvalState; > + > +/* State for evaluating a JsonExpr, too big to inline */ > +typedef struct JsonExprState > +{ > + /* original expression node */ > + JsonExpr *jsexpr; > + > + /* value/isnull for formatted_expr */ > + NullableDatum formatted_expr; > + > + /* value/isnull for pathspec */ > + NullableDatum pathspec; > + > + /* JsonPathVariable entries for passing_values */ > + List *args; > + > + /* > + * Per-row result status info populated by ExecEvalJsonExprPath() > + * and ExecEvalJsonCoercionFinish(). > + */ > + JsonExprPostEvalState post_eval; > + > + /* > + * Address of the step that implements the non-ERROR variant of ON ERROR > + * and ON EMPTY behaviors, to be jumped to when ExecEvalJsonExprPath() > + * returns false on encountering an error during JsonPath* evaluation > + * (ON ERROR) or on finding that no matching JSON item was returned (ON > + * EMPTY). The same steps are also performed on encountering an error > + * when coercing JsonPath* result to the RETURNING type. > + */ > + int jump_error; > + > + /* > + * Addresses of steps to perform the coercion of the JsonPath* result value > + * to the RETURNING type. Each address points to either 1) a special > + * EEOP_JSONEXPR_COERCION step that handles coercion using the RETURNING > + * type's input function or by using json_via_populate(), or 2) an > + * expression such as CoerceViaIO. It may be -1 if no coercion is > + * necessary. > + * > + * jump_eval_result_coercion points to the step to evaluate the coercion > + * given in JsonExpr.result_coercion. > + */ > + int jump_eval_result_coercion; > + > + /* eval_item_coercion_jumps is an array of num_item_coercions elements > + * each containing a step address to evaluate the coercion from a value of > + * the given JsonItemType to the RETURNING type, or -1 if no coercion is > + * necessary. item_coercion_via_expr is an array of boolean flags of the > + * same length that indicates whether each valid step address in the > + * eval_item_coercion_jumps array points to an expression or a > + * EEOP_JSONEXPR_COERCION step. ExecEvalJsonExprPath() will cause an > + * error if it's the latter, because that mode of coercion is not > + * supported for all JsonItemTypes. > + */ > + int num_item_coercions; > + int *eval_item_coercion_jumps; > + bool *item_coercion_via_expr; > + > + /* > + * For passing when initializing a EEOP_IOCOERCE_SAFE step for any > + * CoerceViaIO nodes in the expression that must be evaluated in an > + * error-safe manner. > + */ > + ErrorSaveContext escontext; > +} JsonExprState; > + > +/* > + * State for coercing a value to the target type specified in 'coercion' using > + * either json_populate_type() or by calling the type's input function. > + */ > +typedef struct JsonCoercionState > +{ > + /* original expression node */ > + JsonCoercion *coercion; > + > + /* Input function info for the target type. */ > + struct > + { > + FmgrInfo *finfo; > + Oid typioparam; > + } input; > + > + /* Cache for json_populate_type() */ > + void *cache; > + > + /* > + * For soft-error handling in json_populate_type() or > + * in InputFunctionCallSafe(). > + */ > + ErrorSaveContext *escontext; > +} JsonCoercionState; Does all of this stuff need to live in this header? Some of it seems like it doesn't need to be in a header at all, and other bits seem like they belong somewhere more json specific? > +/* > + * JsonItemType > + * Represents type codes to identify a JsonCoercion node to use when > + * coercing a given SQL/JSON items to the output SQL type > + * > + * The comment next to each item type mentions the JsonbValue.jbvType of the > + * source JsonbValue value to be coerced using the expression in the > + * JsonCoercion node. > + * > + * Also, see InitJsonItemCoercions() and ExecPrepareJsonItemCoercion(). > + */ > +typedef enum JsonItemType > +{ > + JsonItemTypeNull = 0, /* jbvNull */ > + JsonItemTypeString = 1, /* jbvString */ > + JsonItemTypeNumeric = 2, /* jbvNumeric */ > + JsonItemTypeBoolean = 3, /* jbvBool */ > + JsonItemTypeDate = 4, /* jbvDatetime: DATEOID */ > + JsonItemTypeTime = 5, /* jbvDatetime: TIMEOID */ > + JsonItemTypeTimetz = 6, /* jbvDatetime: TIMETZOID */ > + JsonItemTypeTimestamp = 7, /* jbvDatetime: TIMESTAMPOID */ > + JsonItemTypeTimestamptz = 8, /* jbvDatetime: TIMESTAMPTZOID */ > + JsonItemTypeComposite = 9, /* jbvArray, jbvObject, jbvBinary */ > + JsonItemTypeInvalid = 10, > +} JsonItemType; Why do we need manually assigned values here? > +/* > + * JsonCoercion - > + * coercion from SQL/JSON item types to SQL types > + */ > +typedef struct JsonCoercion > +{ > + NodeTag type; > + > + Oid targettype; > + int32 targettypmod; > + bool via_populate; /* coerce result using json_populate_type()? */ > + bool via_io; /* coerce result using type input function? */ > + Oid collation; /* collation for coercion via I/O or populate */ > +} JsonCoercion; > + > +typedef struct JsonItemCoercion > +{ > + NodeTag type; > + > + JsonItemType item_type; > + Node *coercion; > +} JsonItemCoercion; What's the difference between an "ItemCoercion" and a "Coercion"? > +/* > + * JsonBehavior - > + * representation of a given JSON behavior My editor warns about space-before-tab here. > + */ > +typedef struct JsonBehavior > +{ > + NodeTag type; > + JsonBehaviorType btype; /* behavior type */ > + Node *expr; /* behavior expression */ These comment don't seem helpful. I think there's need for comments here, but restating the field name in different words isn't helpful. What's needed is an explanation of how things interact, perhaps also why that's the appropriate representation. > + JsonCoercion *coercion; /* to coerce behavior expression when there is > + * no cast to the target type */ > + int location; /* token location, or -1 if unknown */ > +} JsonBehavior; > + > +/* > + * JsonExpr - > + * transformed representation of JSON_VALUE(), JSON_QUERY(), JSON_EXISTS() > + */ > +typedef struct JsonExpr > +{ > + Expr xpr; > + > + JsonExprOp op; /* json function ID */ > + Node *formatted_expr; /* formatted context item expression */ > + Node *result_coercion; /* resulting coercion to RETURNING type */ > + JsonFormat *format; /* context item format (JSON/JSONB) */ > + Node *path_spec; /* JSON path specification expression */ > + List *passing_names; /* PASSING argument names */ > + List *passing_values; /* PASSING argument values */ > + JsonReturning *returning; /* RETURNING clause type/format info */ > + JsonBehavior *on_empty; /* ON EMPTY behavior */ > + JsonBehavior *on_error; /* ON ERROR behavior */ > + List *item_coercions; /* coercions for JSON_VALUE */ > + JsonWrapper wrapper; /* WRAPPER for JSON_QUERY */ > + bool omit_quotes; /* KEEP/OMIT QUOTES for JSON_QUERY */ > + int location; /* token location, or -1 if unknown */ > +} JsonExpr; These comments seem even worse. > +static void ExecInitJsonExpr(JsonExpr *jexpr, ExprState *state, > + Datum *resv, bool *resnull, > + ExprEvalStep *scratch); > +static int ExecInitJsonExprCoercion(ExprState *state, Node *coercion, > + ErrorSaveContext *escontext, > + Datum *resv, bool *resnull); > > > /* > @@ -2416,6 +2423,36 @@ ExecInitExprRec(Expr *node, ExprState *state, > break; > } > > + case T_JsonExpr: > + { > + JsonExpr *jexpr = castNode(JsonExpr, node); > + > + ExecInitJsonExpr(jexpr, state, resv, resnull, &scratch); > + break; > + } > + > + case T_JsonCoercion: > + { > + JsonCoercion *coercion = castNode(JsonCoercion, node); > + JsonCoercionState *jcstate = palloc0(sizeof(JsonCoercionState)); > + Oid typinput; > + FmgrInfo *finfo; > + > + getTypeInputInfo(coercion->targettype, &typinput, > + &jcstate->input.typioparam); > + finfo = palloc0(sizeof(FmgrInfo)); > + fmgr_info(typinput, finfo); > + jcstate->input.finfo = finfo; > + > + jcstate->coercion = coercion; > + jcstate->escontext = state->escontext; > + > + scratch.opcode = EEOP_JSONEXPR_COERCION; > + scratch.d.jsonexpr_coercion.jcstate = jcstate; > + ExprEvalPushStep(state, &scratch); > + break; > + } It's confusing that we have ExecInitJsonExprCoercion, but aren't using that here, but then use it later, in ExecInitJsonExpr(). > case T_NullTest: > { > NullTest *ntest = (NullTest *) node; > @@ -4184,3 +4221,329 @@ ExecBuildParamSetEqual(TupleDesc desc, > > return state; > } > + > +/* > + * Push steps to evaluate a JsonExpr and its various subsidiary expressions. > + */ > +static void > +ExecInitJsonExpr(JsonExpr *jexpr, ExprState *state, > + Datum *resv, bool *resnull, > + ExprEvalStep *scratch) > +{ > + JsonExprState *jsestate = palloc0(sizeof(JsonExprState)); > + JsonExprPostEvalState *post_eval = &jsestate->post_eval; > + ListCell *argexprlc; > + ListCell *argnamelc; > + List *jumps_if_skip = NIL; > + List *jumps_to_coerce_finish = NIL; > + List *jumps_to_end = NIL; > + ListCell *lc; > + ExprEvalStep *as; > + > + jsestate->jsexpr = jexpr; > + > + /* > + * Evaluate formatted_expr storing the result into > + * jsestate->formatted_expr. > + */ > + ExecInitExprRec((Expr *) jexpr->formatted_expr, state, > + &jsestate->formatted_expr.value, > + &jsestate->formatted_expr.isnull); > + > + /* Steps to jump to end if formatted_expr evaluates to NULL */ > + scratch->opcode = EEOP_JUMP_IF_NULL; > + scratch->resnull = &jsestate->formatted_expr.isnull; > + scratch->d.jump.jumpdone = -1; /* set below */ > + jumps_if_skip = lappend_int(jumps_if_skip, state->steps_len); > + ExprEvalPushStep(state, scratch); > + > + /* > + * Evaluate pathspec expression storing the result into > + * jsestate->pathspec. > + */ > + ExecInitExprRec((Expr *) jexpr->path_spec, state, > + &jsestate->pathspec.value, > + &jsestate->pathspec.isnull); > + > + /* Steps to JUMP to end if pathspec evaluates to NULL */ > + scratch->opcode = EEOP_JUMP_IF_NULL; > + scratch->resnull = &jsestate->pathspec.isnull; > + scratch->d.jump.jumpdone = -1; /* set below */ > + jumps_if_skip = lappend_int(jumps_if_skip, state->steps_len); > + ExprEvalPushStep(state, scratch); > + > + /* Steps to compute PASSING args. */ > + jsestate->args = NIL; > + forboth(argexprlc, jexpr->passing_values, > + argnamelc, jexpr->passing_names) > + { > + Expr *argexpr = (Expr *) lfirst(argexprlc); > + String *argname = lfirst_node(String, argnamelc); > + JsonPathVariable *var = palloc(sizeof(*var)); > + > + var->name = argname->sval; > + var->typid = exprType((Node *) argexpr); > + var->typmod = exprTypmod((Node *) argexpr); > + > + ExecInitExprRec((Expr *) argexpr, state, &var->value, &var->isnull); > + > + jsestate->args = lappend(jsestate->args, var); > + } > + > + /* Step for JsonPath* evaluation; see ExecEvalJsonExprPath(). */ > + scratch->opcode = EEOP_JSONEXPR_PATH; > + scratch->resvalue = resv; > + scratch->resnull = resnull; > + scratch->d.jsonexpr.jsestate = jsestate; > + ExprEvalPushStep(state, scratch); > + > + /* > + * Step to jump to end when there's neither an error when evaluating > + * JsonPath* nor any need to coerce the result because it's already > + * of the specified type. > + */ > + scratch->opcode = EEOP_JUMP; > + scratch->d.jump.jumpdone = -1; /* set below */ > + jumps_to_end = lappend_int(jumps_to_end, state->steps_len); > + ExprEvalPushStep(state, scratch); > + > + /* > + * Steps to coerce the result value computed by EEOP_JSONEXPR_PATH. > + * To handle coercion errors softly, use the following ErrorSaveContext > + * when initializing the coercion expressions, including any JsonCoercion > + * nodes. > + */ > + jsestate->escontext.type = T_ErrorSaveContext; > + if (jexpr->result_coercion || jexpr->omit_quotes) > + { > + jsestate->jump_eval_result_coercion = > + ExecInitJsonExprCoercion(state, jexpr->result_coercion, > + jexpr->on_error->btype != JSON_BEHAVIOR_ERROR ? > + &jsestate->escontext : NULL, > + resv, resnull); > + } > + else > + jsestate->jump_eval_result_coercion = -1; > + > + /* Steps for coercing JsonItemType values returned by JsonPathValue(). */ > + if (jexpr->item_coercions) > + { > + /* > + * Jump to COERCION_FINISH to skip over the following steps if > + * result_coercion is present. > + */ > + if (jsestate->jump_eval_result_coercion >= 0) > + { > + scratch->opcode = EEOP_JUMP; > + scratch->d.jump.jumpdone = -1; /* set below */ > + jumps_to_coerce_finish = lappend_int(jumps_to_coerce_finish, > + state->steps_len); > + ExprEvalPushStep(state, scratch); > + } > + > + /* > + * Here we create the steps for each JsonItemType type's coercion > + * expression and also store a flag whether the expression is > + * a JsonCoercion node. ExecPrepareJsonItemCoercion() called by > + * ExecEvalJsonExprPath() will map a given JsonbValue returned by > + * JsonPathValue() to its JsonItemType's expression's step address > + * and the flag by indexing the following arrays with JsonItemType > + * enum value. > + */ > + jsestate->num_item_coercions = list_length(jexpr->item_coercions); > + jsestate->eval_item_coercion_jumps = (int *) > + palloc(jsestate->num_item_coercions * sizeof(int)); > + jsestate->item_coercion_via_expr = (bool *) > + palloc0(jsestate->num_item_coercions * sizeof(bool)); > + foreach(lc, jexpr->item_coercions) > + { > + JsonItemCoercion *item_coercion = lfirst(lc); > + Node *coercion = item_coercion->coercion; > + > + jsestate->item_coercion_via_expr[item_coercion->item_type] = > + (coercion != NULL && !IsA(coercion, JsonCoercion)); > + jsestate->eval_item_coercion_jumps[item_coercion->item_type] = > + ExecInitJsonExprCoercion(state, coercion, > + jexpr->on_error->btype != JSON_BEHAVIOR_ERROR ? > + &jsestate->escontext : NULL, > + resv, resnull); > + > + /* Emit JUMP step to skip past other coercions' steps. */ > + scratch->opcode = EEOP_JUMP; > + scratch->d.jump.jumpdone = -1; /* set below */ > + jumps_to_coerce_finish = lappend_int(jumps_to_coerce_finish, > + state->steps_len); > + ExprEvalPushStep(state, scratch); > + } > + } > + > + /* > + * Add step to reset the ErrorSaveContext and set error flag if the > + * coercion steps encountered an error but was not thrown because of the > + * ON ERROR behavior. > + */ > + if (jexpr->result_coercion || jexpr->item_coercions) > + { > + foreach(lc, jumps_to_coerce_finish) > + { > + as = &state->steps[lfirst_int(lc)]; > + as->d.jump.jumpdone = state->steps_len; > + } > + > + scratch->opcode = EEOP_JSONEXPR_COERCION_FINISH; > + scratch->d.jsonexpr.jsestate = jsestate; > + ExprEvalPushStep(state, scratch); > + } > + > + /* > + * Step to handle ON ERROR behaviors. This handles both the errors > + * that occur during EEOP_JSONEXPR_PATH evaluation and subsequent coercion > + * evaluation. > + */ > + jsestate->jump_error = -1; > + if (jexpr->on_error && > + jexpr->on_error->btype != JSON_BEHAVIOR_ERROR) > + { > + jsestate->jump_error = state->steps_len; > + scratch->opcode = EEOP_JUMP_IF_NOT_TRUE; > + > + /* > + * post_eval.error is set by ExecEvalJsonExprPath() and > + * ExecEvalJsonCoercionFinish(). > + */ > + scratch->resvalue = &post_eval->error.value; > + scratch->resnull = &post_eval->error.isnull; > + > + scratch->d.jump.jumpdone = -1; /* set below */ > + ExprEvalPushStep(state, scratch); > + > + /* Steps to evaluate the ON ERROR expression */ > + ExecInitExprRec((Expr *) jexpr->on_error->expr, > + state, resv, resnull); > + > + /* Steps to coerce the ON ERROR expression if needed */ > + if (jexpr->on_error->coercion) > + ExecInitExprRec((Expr *) jexpr->on_error->coercion, state, > + resv, resnull); > + > + jumps_to_end = lappend_int(jumps_to_end, state->steps_len); > + scratch->opcode = EEOP_JUMP; > + scratch->d.jump.jumpdone = -1; > + ExprEvalPushStep(state, scratch); > + } > + > + /* Step to handle ON EMPTY behaviors. */ > + if (jexpr->on_empty != NULL && > + jexpr->on_empty->btype != JSON_BEHAVIOR_ERROR) > + { > + /* > + * Make the ON ERROR behavior JUMP to here after checking the error > + * and if it's not present then make EEOP_JSONEXPR_PATH directly > + * jump here. > + */ > + if (jsestate->jump_error >= 0) > + { > + as = &state->steps[jsestate->jump_error]; > + as->d.jump.jumpdone = state->steps_len; > + } > + else > + jsestate->jump_error = state->steps_len; > + > + scratch->opcode = EEOP_JUMP_IF_NOT_TRUE; > + scratch->resvalue = &post_eval->empty.value; > + scratch->resnull = &post_eval->empty.isnull; > + scratch->d.jump.jumpdone = -1; /* set below */ > + jumps_to_end = lappend_int(jumps_to_end, state->steps_len); > + ExprEvalPushStep(state, scratch); > + > + /* Steps to evaluate the ON EMPTY expression */ > + ExecInitExprRec((Expr *) jexpr->on_empty->expr, > + state, resv, resnull); > + > + /* Steps to coerce the ON EMPTY expression if needed */ > + if (jexpr->on_empty->coercion) > + ExecInitExprRec((Expr *) jexpr->on_empty->coercion, state, > + resv, resnull); > + > + scratch->opcode = EEOP_JUMP; > + scratch->d.jump.jumpdone = -1; /* set below */ > + jumps_to_end = lappend_int(jumps_to_end, state->steps_len); > + ExprEvalPushStep(state, scratch); > + } > + /* Make EEOP_JSONEXPR_PATH jump to end if no ON EMPTY clause present. */ > + else if (jsestate->jump_error >= 0) > + jumps_to_end = lappend_int(jumps_to_end, jsestate->jump_error); > + > + /* > + * If neither ON ERROR nor ON EMPTY jumps present, then add one to go > + * to end. > + */ > + if (jsestate->jump_error < 0) > + { > + scratch->opcode = EEOP_JUMP; > + scratch->d.jump.jumpdone = -1; /* set below */ > + jumps_to_end = lappend_int(jumps_to_end, state->steps_len); > + ExprEvalPushStep(state, scratch); > + } > + > + /* Return NULL when either formatted_expr or pathspec is NULL. */ > + foreach(lc, jumps_if_skip) > + { > + as = &state->steps[lfirst_int(lc)]; > + as->d.jump.jumpdone = state->steps_len; > + } > + scratch->opcode = EEOP_CONST; > + scratch->resvalue = resv; > + scratch->resnull = resnull; > + scratch->d.constval.value = (Datum) 0; > + scratch->d.constval.isnull = true; > + ExprEvalPushStep(state, scratch); > + > + /* Jump to coerce the NULL using result_coercion is present. */ > + if (jsestate->jump_eval_result_coercion >= 0) > + { > + scratch->opcode = EEOP_JUMP; > + scratch->d.jump.jumpdone = jsestate->jump_eval_result_coercion; > + ExprEvalPushStep(state, scratch); > + } > + > + foreach(lc, jumps_to_end) > + { > + as = &state->steps[lfirst_int(lc)]; > + as->d.jump.jumpdone = state->steps_len; > + } > +} > + > +/* Initialize one JsonCoercion for execution. */ > +static int > +ExecInitJsonExprCoercion(ExprState *state, Node *coercion, > + ErrorSaveContext *escontext, > + Datum *resv, bool *resnull) > +{ > + int jump_eval_coercion; > + Datum *save_innermost_caseval; > + bool *save_innermost_casenull; > + ErrorSaveContext *save_escontext; > + > + if (coercion == NULL) > + return -1; > + > + jump_eval_coercion = state->steps_len; > + > + /* Push step(s) to compute cstate->coercion. */ > + save_innermost_caseval = state->innermost_caseval; > + save_innermost_casenull = state->innermost_casenull; > + save_escontext = state->escontext; > + > + state->innermost_caseval = resv; > + state->innermost_casenull = resnull; > + state->escontext = escontext; > + > + ExecInitExprRec((Expr *) coercion, state, resv, resnull); > + > + state->innermost_caseval = save_innermost_caseval; > + state->innermost_casenull = save_innermost_casenull; > + state->escontext = save_escontext; > + > + return jump_eval_coercion; > +} > diff --git a/src/backend/executor/execExprInterp.c b/src/backend/executor/execExprInterp.c > index d5db96444c..a18662cbf9 100644 > --- a/src/backend/executor/execExprInterp.c > +++ b/src/backend/executor/execExprInterp.c > @@ -73,8 +73,8 @@ > #include "utils/datum.h" > #include "utils/expandedrecord.h" > #include "utils/json.h" > -#include "utils/jsonb.h" > #include "utils/jsonfuncs.h" > +#include "utils/jsonpath.h" > #include "utils/lsyscache.h" > #include "utils/memutils.h" > #include "utils/timestamp.h" > @@ -181,6 +181,10 @@ static pg_attribute_always_inline void ExecAggPlainTransByRef(AggState *aggstate > AggStatePerGroup pergroup, > ExprContext *aggcontext, > int setno); > +static void ExecPrepareJsonItemCoercion(JsonbValue *item, JsonExprState *jsestate, > + bool throw_error, > + int *jump_eval_item_coercion, > + Datum *resvalue, bool *resnull); > > /* > * ScalarArrayOpExprHashEntry > @@ -482,6 +486,9 @@ ExecInterpExpr(ExprState *state, ExprContext *econtext, bool *isnull) > &&CASE_EEOP_XMLEXPR, > &&CASE_EEOP_JSON_CONSTRUCTOR, > &&CASE_EEOP_IS_JSON, > + &&CASE_EEOP_JSONEXPR_PATH, > + &&CASE_EEOP_JSONEXPR_COERCION, > + &&CASE_EEOP_JSONEXPR_COERCION_FINISH, > &&CASE_EEOP_AGGREF, > &&CASE_EEOP_GROUPING_FUNC, > &&CASE_EEOP_WINDOW_FUNC, > @@ -1551,6 +1558,35 @@ ExecInterpExpr(ExprState *state, ExprContext *econtext, bool *isnull) > EEO_NEXT(); > } > > + EEO_CASE(EEOP_JSONEXPR_PATH) > + { > + JsonExprState *jsestate = op->d.jsonexpr.jsestate; > + > + /* too complex for an inline implementation */ > + if (!ExecEvalJsonExprPath(state, op, econtext)) > + EEO_JUMP(jsestate->jump_error); > + else if (jsestate->post_eval.jump_eval_coercion >= 0) > + EEO_JUMP(jsestate->post_eval.jump_eval_coercion); > + > + EEO_NEXT(); > + } Why do we need post_eval.jump_eval_coercion? Seems like that could more cleanly be implemented by just emitting a constant JUMP step? Oh, I see - you're changing post_eval.jump_eval_coercion at runtime. This seems like a BAD idea. I strongly suggest that instead of modifying the field, you instead return the target jump step as a return value from ExecEvalJsonExprPath or such. > +/* > + * Performs JsonPath{Exists|Query|Value}() for given context item and JSON > + * path. > + * > + * Result is set in *op->resvalue and *op->resnull. > + * > + * On return, JsonExprPostEvalState is populated with the following details: > + * - jump_eval_coercion: step address of coercion to apply to the result > + * - error.value: true if an error occurred during JsonPath evaluation > + * - empty.value: true if JsonPath{Query|Value}() found no matching item > + * > + * No return if the ON ERROR/EMPTY behavior is ERROR. > + */ > +bool > +ExecEvalJsonExprPath(ExprState *state, ExprEvalStep *op, > + ExprContext *econtext) > +{ > + JsonExprState *jsestate = op->d.jsonexpr.jsestate; > + JsonExprPostEvalState *post_eval = &jsestate->post_eval; > + JsonExpr *jexpr = jsestate->jsexpr; > + Datum item; > + JsonPath *path; > + bool throw_error = (jexpr->on_error->btype == JSON_BEHAVIOR_ERROR); What's the deal with the parentheses here and in similar places below? There's no danger of ambiguity without, no? > + case JSON_VALUE_OP: > + { > + JsonbValue *jbv = JsonPathValue(item, path, &empty, > + !throw_error ? &error : NULL, > + jsestate->args); > + > + /* Might get overridden by an item coercion below. */ > + post_eval->jump_eval_coercion = jsestate->jump_eval_result_coercion; > + if (jbv == NULL) > + { > + /* Will be coerced with result_coercion. */ > + *op->resvalue = (Datum) 0; > + *op->resnull = true; > + } > + else if (!error && !empty) > + { > + /* > + * If the requested output type is json(b), use > + * result_coercion to do the coercion. > + */ > + if (jexpr->returning->typid == JSONOID || > + jexpr->returning->typid == JSONBOID) > + { > + *op->resvalue = JsonbPGetDatum(JsonbValueToJsonb(jbv)); > + *op->resnull = false; > + } > + else > + { > + /* > + * Else, use one of the item_coercions. > + * > + * Error out if no cast expression exists. > + */ > + ExecPrepareJsonItemCoercion(jbv, jsestate, throw_error, > + &post_eval->jump_eval_coercion, > + op->resvalue, op->resnull); > + if (empty) > + { > + if (jexpr->on_empty) > + { > + if (jexpr->on_empty->btype == JSON_BEHAVIOR_ERROR) > + ereport(ERROR, > + (errcode(ERRCODE_NO_SQL_JSON_ITEM), > + errmsg("no SQL/JSON item"))); No need for the parens around ereport() arguments anymore. Same in a few other places. > diff --git a/src/backend/parser/gram.y b/src/backend/parser/gram.y > index d631ac89a9..4f92d000ec 100644 > --- a/src/backend/parser/gram.y > +++ b/src/backend/parser/gram.y > @@ -650,11 +650,18 @@ static Node *makeRecursiveViewSelect(char *relname, List *aliases, Node *query); > json_returning_clause_opt > json_name_and_value > json_aggregate_func > + json_argument > + json_behavior > %type <list> json_name_and_value_list > json_value_expr_list > json_array_aggregate_order_by_clause_opt > + json_arguments > + json_behavior_clause_opt > + json_passing_clause_opt > %type <ival> json_encoding_clause_opt > json_predicate_type_constraint > + json_quotes_clause_opt > + json_wrapper_behavior > %type <boolean> json_key_uniqueness_constraint_opt > json_object_constructor_null_clause_opt > json_array_constructor_null_clause_opt > @@ -695,7 +702,7 @@ static Node *makeRecursiveViewSelect(char *relname, List *aliases, Node *query); > CACHE CALL CALLED CASCADE CASCADED CASE CAST CATALOG_P CHAIN CHAR_P > CHARACTER CHARACTERISTICS CHECK CHECKPOINT CLASS CLOSE > CLUSTER COALESCE COLLATE COLLATION COLUMN COLUMNS COMMENT COMMENTS COMMIT > - COMMITTED COMPRESSION CONCURRENTLY CONFIGURATION CONFLICT > + COMMITTED COMPRESSION CONCURRENTLY CONDITIONAL CONFIGURATION CONFLICT > CONNECTION CONSTRAINT CONSTRAINTS CONTENT_P CONTINUE_P CONVERSION_P COPY > COST CREATE CROSS CSV CUBE CURRENT_P > CURRENT_CATALOG CURRENT_DATE CURRENT_ROLE CURRENT_SCHEMA > @@ -706,8 +713,8 @@ static Node *makeRecursiveViewSelect(char *relname, List *aliases, Node *query); > DETACH DICTIONARY DISABLE_P DISCARD DISTINCT DO DOCUMENT_P DOMAIN_P > DOUBLE_P DROP > > - EACH ELSE ENABLE_P ENCODING ENCRYPTED END_P ENUM_P ESCAPE EVENT EXCEPT > - EXCLUDE EXCLUDING EXCLUSIVE EXECUTE EXISTS EXPLAIN EXPRESSION > + EACH ELSE EMPTY_P ENABLE_P ENCODING ENCRYPTED END_P ENUM_P ERROR_P ESCAPE > + EVENT EXCEPT EXCLUDE EXCLUDING EXCLUSIVE EXECUTE EXISTS EXPLAIN EXPRESSION > EXTENSION EXTERNAL EXTRACT > > FALSE_P FAMILY FETCH FILTER FINALIZE FIRST_P FLOAT_P FOLLOWING FOR > @@ -722,10 +729,10 @@ static Node *makeRecursiveViewSelect(char *relname, List *aliases, Node *query); > INNER_P INOUT INPUT_P INSENSITIVE INSERT INSTEAD INT_P INTEGER > INTERSECT INTERVAL INTO INVOKER IS ISNULL ISOLATION > > - JOIN JSON JSON_ARRAY JSON_ARRAYAGG JSON_OBJECT JSON_OBJECTAGG > - JSON_SCALAR JSON_SERIALIZE > + JOIN JSON JSON_ARRAY JSON_ARRAYAGG JSON_EXISTS JSON_OBJECT JSON_OBJECTAGG > + JSON_QUERY JSON_SCALAR JSON_SERIALIZE JSON_VALUE > > - KEY KEYS > + KEEP KEY KEYS > > LABEL LANGUAGE LARGE_P LAST_P LATERAL_P > LEADING LEAKPROOF LEAST LEFT LEVEL LIKE LIMIT LISTEN LOAD LOCAL > @@ -739,7 +746,7 @@ static Node *makeRecursiveViewSelect(char *relname, List *aliases, Node *query); > NOT NOTHING NOTIFY NOTNULL NOWAIT NULL_P NULLIF > NULLS_P NUMERIC > > - OBJECT_P OF OFF OFFSET OIDS OLD ON ONLY OPERATOR OPTION OPTIONS OR > + OBJECT_P OF OFF OFFSET OIDS OLD OMIT ON ONLY OPERATOR OPTION OPTIONS OR > ORDER ORDINALITY OTHERS OUT_P OUTER_P > OVER OVERLAPS OVERLAY OVERRIDING OWNED OWNER > > @@ -748,7 +755,7 @@ static Node *makeRecursiveViewSelect(char *relname, List *aliases, Node *query); > POSITION PRECEDING PRECISION PRESERVE PREPARE PREPARED PRIMARY > PRIOR PRIVILEGES PROCEDURAL PROCEDURE PROCEDURES PROGRAM PUBLICATION > > - QUOTE > + QUOTE QUOTES > > RANGE READ REAL REASSIGN RECHECK RECURSIVE REF_P REFERENCES REFERENCING > REFRESH REINDEX RELATIVE_P RELEASE RENAME REPEATABLE REPLACE REPLICA > @@ -759,7 +766,7 @@ static Node *makeRecursiveViewSelect(char *relname, List *aliases, Node *query); > SEQUENCE SEQUENCES > SERIALIZABLE SERVER SESSION SESSION_USER SET SETS SETOF SHARE SHOW > SIMILAR SIMPLE SKIP SMALLINT SNAPSHOT SOME SQL_P STABLE STANDALONE_P > - START STATEMENT STATISTICS STDIN STDOUT STORAGE STORED STRICT_P STRIP_P > + START STATEMENT STATISTICS STDIN STDOUT STORAGE STORED STRICT_P STRING_P STRIP_P > SUBSCRIPTION SUBSTRING SUPPORT SYMMETRIC SYSID SYSTEM_P SYSTEM_USER > > TABLE TABLES TABLESAMPLE TABLESPACE TEMP TEMPLATE TEMPORARY TEXT_P THEN > @@ -767,7 +774,7 @@ static Node *makeRecursiveViewSelect(char *relname, List *aliases, Node *query); > TREAT TRIGGER TRIM TRUE_P > TRUNCATE TRUSTED TYPE_P TYPES_P > > - UESCAPE UNBOUNDED UNCOMMITTED UNENCRYPTED UNION UNIQUE UNKNOWN > + UESCAPE UNBOUNDED UNCONDITIONAL UNCOMMITTED UNENCRYPTED UNION UNIQUE UNKNOWN > UNLISTEN UNLOGGED UNTIL UPDATE USER USING > > VACUUM VALID VALIDATE VALIDATOR VALUE_P VALUES VARCHAR VARIADIC VARYING > @@ -15768,6 +15775,60 @@ func_expr_common_subexpr: > n->location = @1; > $$ = (Node *) n; > } > + | JSON_QUERY '(' > + json_value_expr ',' a_expr json_passing_clause_opt > + json_returning_clause_opt > + json_wrapper_behavior > + json_quotes_clause_opt > + json_behavior_clause_opt > + ')' > + { > + JsonFuncExpr *n = makeNode(JsonFuncExpr); > + > + n->op = JSON_QUERY_OP; > + n->context_item = (JsonValueExpr *) $3; > + n->pathspec = $5; > + n->passing = $6; > + n->output = (JsonOutput *) $7; > + n->wrapper = $8; > + n->quotes = $9; > + n->behavior = $10; > + n->location = @1; > + $$ = (Node *) n; > + } > + | JSON_EXISTS '(' > + json_value_expr ',' a_expr json_passing_clause_opt > + json_behavior_clause_opt > + ')' > + { > + JsonFuncExpr *n = makeNode(JsonFuncExpr); > + > + n->op = JSON_EXISTS_OP; > + n->context_item = (JsonValueExpr *) $3; > + n->pathspec = $5; > + n->passing = $6; > + n->output = NULL; > + n->behavior = $7; > + n->location = @1; > + $$ = (Node *) n; > + } > + | JSON_VALUE '(' > + json_value_expr ',' a_expr json_passing_clause_opt > + json_returning_clause_opt > + json_behavior_clause_opt > + ')' > + { > + JsonFuncExpr *n = makeNode(JsonFuncExpr); > + > + n->op = JSON_VALUE_OP; > + n->context_item = (JsonValueExpr *) $3; > + n->pathspec = $5; > + n->passing = $6; > + n->output = (JsonOutput *) $7; > + n->behavior = $8; > + n->location = @1; > + $$ = (Node *) n; > + } > ; > > > @@ -16494,6 +16555,27 @@ opt_asymmetric: ASYMMETRIC > ; > > /* SQL/JSON support */ > +json_passing_clause_opt: > + PASSING json_arguments { $$ = $2; } > + | /*EMPTY*/ { $$ = NIL; } > + ; > + > +json_arguments: > + json_argument { $$ = list_make1($1); } > + | json_arguments ',' json_argument { $$ = lappend($1, $3); } > + ; > + > +json_argument: > + json_value_expr AS ColLabel > + { > + JsonArgument *n = makeNode(JsonArgument); > + > + n->val = (JsonValueExpr *) $1; > + n->name = $3; > + $$ = (Node *) n; > + } > + ; > + > json_value_expr: > a_expr json_format_clause_opt > { > @@ -16519,6 +16601,27 @@ json_encoding_clause_opt: > | /* EMPTY */ { $$ = JS_ENC_DEFAULT; } > ; > > +/* ARRAY is a noise word */ > +json_wrapper_behavior: > + WITHOUT WRAPPER { $$ = JSW_NONE; } > + | WITHOUT ARRAY WRAPPER { $$ = JSW_NONE; } > + | WITH WRAPPER { $$ = JSW_UNCONDITIONAL; } > + | WITH ARRAY WRAPPER { $$ = JSW_UNCONDITIONAL; } > + | WITH CONDITIONAL ARRAY WRAPPER { $$ = JSW_CONDITIONAL; } > + | WITH UNCONDITIONAL ARRAY WRAPPER { $$ = JSW_UNCONDITIONAL; } > + | WITH CONDITIONAL WRAPPER { $$ = JSW_CONDITIONAL; } > + | WITH UNCONDITIONAL WRAPPER { $$ = JSW_UNCONDITIONAL; } > + | /* empty */ { $$ = JSW_NONE; } > + ; > + > +json_quotes_clause_opt: > + KEEP QUOTES ON SCALAR STRING_P { $$ = JS_QUOTES_KEEP; } > + | KEEP QUOTES { $$ = JS_QUOTES_KEEP; } > + | OMIT QUOTES ON SCALAR STRING_P { $$ = JS_QUOTES_OMIT; } > + | OMIT QUOTES { $$ = JS_QUOTES_OMIT; } > + | /* EMPTY */ { $$ = JS_QUOTES_UNSPEC; } > + ; > + > json_returning_clause_opt: > RETURNING Typename json_format_clause_opt > { > @@ -16532,6 +16635,39 @@ json_returning_clause_opt: > | /* EMPTY */ { $$ = NULL; } > ; > > +json_behavior: > + DEFAULT a_expr > + { $$ = (Node *) makeJsonBehavior(JSON_BEHAVIOR_DEFAULT, $2, NULL, @1); } > + | ERROR_P > + { $$ = (Node *) makeJsonBehavior(JSON_BEHAVIOR_ERROR, NULL, NULL, @1); } > + | NULL_P > + { $$ = (Node *) makeJsonBehavior(JSON_BEHAVIOR_NULL, NULL, NULL, @1); } > + | TRUE_P > + { $$ = (Node *) makeJsonBehavior(JSON_BEHAVIOR_TRUE, NULL, NULL, @1); } > + | FALSE_P > + { $$ = (Node *) makeJsonBehavior(JSON_BEHAVIOR_FALSE, NULL, NULL, @1); } > + | UNKNOWN > + { $$ = (Node *) makeJsonBehavior(JSON_BEHAVIOR_UNKNOWN, NULL, NULL, @1); } > + | EMPTY_P ARRAY > + { $$ = (Node *) makeJsonBehavior(JSON_BEHAVIOR_EMPTY_ARRAY, NULL, NULL, @1); } > + | EMPTY_P OBJECT_P > + { $$ = (Node *) makeJsonBehavior(JSON_BEHAVIOR_EMPTY_OBJECT, NULL, NULL, @1); } > + /* non-standard, for Oracle compatibility only */ > + | EMPTY_P > + { $$ = (Node *) makeJsonBehavior(JSON_BEHAVIOR_EMPTY_ARRAY, NULL, NULL, @1); } > + ; Seems like this would look better if you made json_behavior return just the enum values and had one makeJsonBehavior() at the place referencing it? > +json_behavior_clause_opt: > + json_behavior ON EMPTY_P > + { $$ = list_make2($1, NULL); } > + | json_behavior ON ERROR_P > + { $$ = list_make2(NULL, $1); } > + | json_behavior ON EMPTY_P json_behavior ON ERROR_P > + { $$ = list_make2($1, $4); } > + | /* EMPTY */ > + { $$ = list_make2(NULL, NULL); } > + ; This seems like an odd representation - why represent the behavior as a two element list where one needs to know what is stored at which list offset? Greetings, Andres Freund
Hi. function JsonPathExecResult comment needs to be refactored? since it changed a lot.
Hi. small issues I found...
typo:
+-- Test mutabilily od query functions
+ default:
+ ereport(ERROR,
+ (errcode(ERRCODE_INVALID_PARAMETER_VALUE),
+ errmsg("only datetime, bool, numeric, and text types can be casted
to jsonpath types")));
transformJsonPassingArgs's function: transformJsonValueExpr will make
the above code unreached.
also based on the `switch (typid)` cases,
I guess best message would be
errmsg("only datetime, bool, numeric, text, json, jsonb types can be
casted to jsonpath types")));
+ case JSON_QUERY_OP:
+ jsexpr->wrapper = func->wrapper;
+ jsexpr->omit_quotes = (func->quotes == JS_QUOTES_OMIT);
+
+ if (!OidIsValid(jsexpr->returning->typid))
+ {
+ JsonReturning *ret = jsexpr->returning;
+
+ ret->typid = JsonFuncExprDefaultReturnType(jsexpr);
+ ret->typmod = -1;
+ }
+ jsexpr->result_coercion = coerceJsonFuncExprOutput(pstate, jsexpr);
I noticed, if (!OidIsValid(jsexpr->returning->typid)) is the true
function JsonFuncExprDefaultReturnType may be called twice, not sure
if it's good or not..
Thanks for the review. On Sat, Dec 9, 2023 at 2:30 AM Andres Freund <andres@anarazel.de> wrote: > On 2023-12-07 21:07:59 +0900, Amit Langote wrote: > > --- a/src/include/executor/execExpr.h > > +++ b/src/include/executor/execExpr.h > > @@ -547,6 +549,7 @@ typedef struct ExprEvalStep > > bool *checknull; > > /* OID of domain type */ > > Oid resulttype; > > + ErrorSaveContext *escontext; > > } domaincheck; > > > > diff --git a/src/include/nodes/execnodes.h b/src/include/nodes/execnodes.h > > index 5d7f17dee0..6a7118d300 100644 > > --- a/src/include/nodes/execnodes.h > > +++ b/src/include/nodes/execnodes.h > > @@ -34,6 +34,7 @@ > > #include "fmgr.h" > > #include "lib/ilist.h" > > #include "lib/pairingheap.h" > > +#include "nodes/miscnodes.h" > > #include "nodes/params.h" > > #include "nodes/plannodes.h" > > #include "nodes/tidbitmap.h" > > @@ -129,6 +130,12 @@ typedef struct ExprState > > > > Datum *innermost_domainval; > > bool *innermost_domainnull; > > + > > + /* > > + * For expression nodes that support soft errors. Should be set to NULL > > + * before calling ExecInitExprRec() if the caller wants errors thrown. > > + */ > > + ErrorSaveContext *escontext; > > } ExprState; > > Why do we need this both in ExprState *and* in ExprEvalStep? In the current design, ExprState.escontext is only set when initializing sub-expressions that should have their errors handled softly and is supposed to be NULL at the runtime. So, the design expects the expressions to save the ErrorSaveContext pointer into their struct in ExecEvalStep or somewhere else (input function's FunctionCallInfo in CoerceViaIO's case). > > From 38b53297b2d435d5cebf78c1f81e4748fed6c8b6 Mon Sep 17 00:00:00 2001 > > From: Amit Langote <amitlan@postgresql.org> > > Date: Wed, 22 Nov 2023 13:18:49 +0900 > > Subject: [PATCH v30 2/5] Add soft error handling to populate_record_field() > > > > An uncoming patch would like the ability to call it from the > > executor for some SQL/JSON expression nodes and ask to suppress any > > errors that may occur. > > > > This commit does two things mainly: > > > > * It modifies the various interfaces internal to jsonfuncs.c to pass > > the ErrorSaveContext around. > > > > * Make necessary modifications to handle the cases where the > > processing is aborted partway through various functions that take > > an ErrorSaveContext when a soft error occurs. > > > > Note that the above changes are only intended to suppress errors in > > the functions in jsonfuncs.c, but not those in any external functions > > that the functions in jsonfuncs.c in turn call, such as those from > > arrayfuncs.c. It is assumed that the various populate_* functions > > validate the data before passing those to external functions. > > > > Discussion: https://postgr.es/m/CA+HiwqE4XTdfb1nW=Ojoy_tQSRhYt-q_kb6i5d4xcKyrLC1Nbg@mail.gmail.com > > The code here is getting substantially more verbose / less readable. I wonder > if there's something more general that could be improved to make this less > painful? Hmm, I can't think of anything short of a rewrite of the code under populate_record_field() so that any error-producing code is well isolated or adding a variant/wrapper with soft-error handling capabilities. I'll give this some more thought, though I'm happy to hear ideas. > I'd not at all be surprised if this caused a measurable slowdown. Patches 0004, 0005, and 0006 are new. I don't notice a significant slowdown. The benchmark I used is the time to run the following query: select json_populate_record(row(1,1), '{"f1":1, "f2":1}') from generate_series(1, 1000000) Here are the times: Unpatched: Time: 1262.011 ms (00:01.262) Time: 1202.354 ms (00:01.202) Time: 1187.708 ms (00:01.188) Time: 1171.752 ms (00:01.172) Time: 1174.249 ms (00:01.174) Patched: Time: 1233.927 ms (00:01.234) Time: 1185.381 ms (00:01.185) Time: 1202.245 ms (00:01.202) Time: 1164.994 ms (00:01.165) Time: 1179.009 ms (00:01.179) perf shows that a significant amount of time is spent is json_lex() dwarfing the time spent in dispatching code that is being changed here. > > --- > > src/backend/utils/adt/jsonfuncs.c | 310 +++++++++++++++++++++++------- > > 1 file changed, 236 insertions(+), 74 deletions(-) > > > /* functions supporting jsonb_delete, jsonb_set and jsonb_concat */ > > static JsonbValue *IteratorConcat(JsonbIterator **it1, JsonbIterator **it2, > > @@ -2484,12 +2491,12 @@ populate_array_report_expected_array(PopulateArrayContext *ctx, int ndim) > > if (ndim <= 0) > > { > > if (ctx->colname) > > - ereport(ERROR, > > + errsave(ctx->escontext, > > (errcode(ERRCODE_INVALID_TEXT_REPRESENTATION), > > errmsg("expected JSON array"), > > errhint("See the value of key \"%s\".", ctx->colname))); > > else > > - ereport(ERROR, > > + errsave(ctx->escontext, > > (errcode(ERRCODE_INVALID_TEXT_REPRESENTATION), > > errmsg("expected JSON array"))); > > } > > @@ -2506,13 +2513,13 @@ populate_array_report_expected_array(PopulateArrayContext *ctx, int ndim) > > appendStringInfo(&indices, "[%d]", ctx->sizes[i]); > > > > if (ctx->colname) > > - ereport(ERROR, > > + errsave(ctx->escontext, > > (errcode(ERRCODE_INVALID_TEXT_REPRESENTATION), > > errmsg("expected JSON array"), > > errhint("See the array element %s of key \"%s\".", > > indices.data, ctx->colname))); > > else > > - ereport(ERROR, > > + errsave(ctx->escontext, > > (errcode(ERRCODE_INVALID_TEXT_REPRESENTATION), > > errmsg("expected JSON array"), > > errhint("See the array element %s.", > > @@ -2520,8 +2527,13 @@ populate_array_report_expected_array(PopulateArrayContext *ctx, int ndim) > > } > > } > > It seems mildly errorprone to use errsave() but not have any returns in the > code after the errsave()s - it seems plausible that somebody later would come > and add more code expecting to not reach the later code. Having returns in the code blocks containing errsave() sounds prudent, so done. > > +/* > > + * Validate and set ndims for populating an array with some > > + * populate_array_*() function. > > + * > > + * Returns false if the input (ndims) is erratic. > > I don't think "erratic" is the right word, "erroneous" maybe? "erroneous" sounds better. > > --- > > doc/src/sgml/func.sgml | 151 +++ > > src/backend/catalog/sql_features.txt | 12 +- > > src/backend/executor/execExpr.c | 363 +++++++ > > src/backend/executor/execExprInterp.c | 365 ++++++- > > src/backend/jit/llvm/llvmjit.c | 2 + > > src/backend/jit/llvm/llvmjit_expr.c | 140 +++ > > src/backend/jit/llvm/llvmjit_types.c | 4 + > > src/backend/nodes/makefuncs.c | 18 + > > src/backend/nodes/nodeFuncs.c | 238 ++++- > > src/backend/optimizer/path/costsize.c | 3 +- > > src/backend/optimizer/util/clauses.c | 19 + > > src/backend/parser/gram.y | 178 +++- > > src/backend/parser/parse_expr.c | 621 ++++++++++- > > src/backend/parser/parse_target.c | 15 + > > src/backend/utils/adt/formatting.c | 44 + > > src/backend/utils/adt/jsonb.c | 31 + > > src/backend/utils/adt/jsonfuncs.c | 52 +- > > src/backend/utils/adt/jsonpath.c | 255 +++++ > > src/backend/utils/adt/jsonpath_exec.c | 391 ++++++- > > src/backend/utils/adt/ruleutils.c | 136 +++ > > src/include/executor/execExpr.h | 133 +++ > > src/include/fmgr.h | 1 + > > src/include/jit/llvmjit.h | 1 + > > src/include/nodes/makefuncs.h | 2 + > > src/include/nodes/parsenodes.h | 47 + > > src/include/nodes/primnodes.h | 130 +++ > > src/include/parser/kwlist.h | 11 + > > src/include/utils/formatting.h | 1 + > > src/include/utils/jsonb.h | 1 + > > src/include/utils/jsonfuncs.h | 5 + > > src/include/utils/jsonpath.h | 27 + > > src/interfaces/ecpg/preproc/ecpg.trailer | 28 + > > src/test/regress/expected/json_sqljson.out | 18 + > > src/test/regress/expected/jsonb_sqljson.out | 1032 +++++++++++++++++++ > > src/test/regress/parallel_schedule | 2 +- > > src/test/regress/sql/json_sqljson.sql | 11 + > > src/test/regress/sql/jsonb_sqljson.sql | 337 ++++++ > > src/tools/pgindent/typedefs.list | 18 + > > 38 files changed, 4767 insertions(+), 76 deletions(-) > > I think it'd be worth trying to break this into smaller bits - it's not easy > to review this at once. ISTM that the only piece that can be broken out at this point is the additions under src/backend/utils/adt. I'm not entirely sure if it'd be a good idea to commit the various bits on their own, that is, without tests which cannot be added without the rest of the parser/executor additions for JsonFuncExpr, JsonExpr, and the supporting child nodes. I've extracted those bits as separate patches even if only for the ease of review. > > +/* > > + * Information about the state of JsonPath* evaluation. > > + */ > > +typedef struct JsonExprPostEvalState > > +{ > > + /* Did JsonPath* evaluation cause an error? */ > > + NullableDatum error; > > + > > + /* Is the result of JsonPath* evaluation empty? */ > > + NullableDatum empty; > > + > > + /* > > + * ExecEvalJsonExprPath() will set this to the address of the step to > > + * use to coerce the result of JsonPath* evaluation to the RETURNING type. > > + * Also see the description of possible step addresses that this could be > > + * set to in the definition of JsonExprState. > > + */ > > +#define FIELDNO_JSONEXPRPOSTEVALSTATE_JUMP_EVAL_COERCION 2 > > + int jump_eval_coercion; > > +} JsonExprPostEvalState; > > + > > +/* State for evaluating a JsonExpr, too big to inline */ > > +typedef struct JsonExprState > > +{ > > + /* original expression node */ > > + JsonExpr *jsexpr; > > + > > + /* value/isnull for formatted_expr */ > > + NullableDatum formatted_expr; > > + > > + /* value/isnull for pathspec */ > > + NullableDatum pathspec; > > + > > + /* JsonPathVariable entries for passing_values */ > > + List *args; > > + > > + /* > > + * Per-row result status info populated by ExecEvalJsonExprPath() > > + * and ExecEvalJsonCoercionFinish(). > > + */ > > + JsonExprPostEvalState post_eval; > > + > > + /* > > + * Address of the step that implements the non-ERROR variant of ON ERROR > > + * and ON EMPTY behaviors, to be jumped to when ExecEvalJsonExprPath() > > + * returns false on encountering an error during JsonPath* evaluation > > + * (ON ERROR) or on finding that no matching JSON item was returned (ON > > + * EMPTY). The same steps are also performed on encountering an error > > + * when coercing JsonPath* result to the RETURNING type. > > + */ > > + int jump_error; > > + > > + /* > > + * Addresses of steps to perform the coercion of the JsonPath* result value > > + * to the RETURNING type. Each address points to either 1) a special > > + * EEOP_JSONEXPR_COERCION step that handles coercion using the RETURNING > > + * type's input function or by using json_via_populate(), or 2) an > > + * expression such as CoerceViaIO. It may be -1 if no coercion is > > + * necessary. > > + * > > + * jump_eval_result_coercion points to the step to evaluate the coercion > > + * given in JsonExpr.result_coercion. > > + */ > > + int jump_eval_result_coercion; > > + > > + /* eval_item_coercion_jumps is an array of num_item_coercions elements > > + * each containing a step address to evaluate the coercion from a value of > > + * the given JsonItemType to the RETURNING type, or -1 if no coercion is > > + * necessary. item_coercion_via_expr is an array of boolean flags of the > > + * same length that indicates whether each valid step address in the > > + * eval_item_coercion_jumps array points to an expression or a > > + * EEOP_JSONEXPR_COERCION step. ExecEvalJsonExprPath() will cause an > > + * error if it's the latter, because that mode of coercion is not > > + * supported for all JsonItemTypes. > > + */ > > + int num_item_coercions; > > + int *eval_item_coercion_jumps; > > + bool *item_coercion_via_expr; > > + > > + /* > > + * For passing when initializing a EEOP_IOCOERCE_SAFE step for any > > + * CoerceViaIO nodes in the expression that must be evaluated in an > > + * error-safe manner. > > + */ > > + ErrorSaveContext escontext; > > +} JsonExprState; > > + > > +/* > > + * State for coercing a value to the target type specified in 'coercion' using > > + * either json_populate_type() or by calling the type's input function. > > + */ > > +typedef struct JsonCoercionState > > +{ > > + /* original expression node */ > > + JsonCoercion *coercion; > > + > > + /* Input function info for the target type. */ > > + struct > > + { > > + FmgrInfo *finfo; > > + Oid typioparam; > > + } input; > > + > > + /* Cache for json_populate_type() */ > > + void *cache; > > + > > + /* > > + * For soft-error handling in json_populate_type() or > > + * in InputFunctionCallSafe(). > > + */ > > + ErrorSaveContext *escontext; > > +} JsonCoercionState; > > Does all of this stuff need to live in this header? Some of it seems like it > doesn't need to be in a header at all, and other bits seem like they belong > somewhere more json specific? I've gotten rid of JsonCoercionState, moving the fields directly into ExprEvalStep.d.jsonexpr_coercion. Regarding JsonExprState and JsonExprPostEvalState, maybe they're better put in execnodes.h to be near other expression state nodes like WindowFuncExprState, so have moved them there. I'm not sure of a json-specific place for this. All of the information contained in those structs is populated and used by execInterpExpr.c, so execnodes.h seems appropriate to me. > > +/* > > + * JsonItemType > > + * Represents type codes to identify a JsonCoercion node to use when > > + * coercing a given SQL/JSON items to the output SQL type > > + * > > + * The comment next to each item type mentions the JsonbValue.jbvType of the > > + * source JsonbValue value to be coerced using the expression in the > > + * JsonCoercion node. > > + * > > + * Also, see InitJsonItemCoercions() and ExecPrepareJsonItemCoercion(). > > + */ > > +typedef enum JsonItemType > > +{ > > + JsonItemTypeNull = 0, /* jbvNull */ > > + JsonItemTypeString = 1, /* jbvString */ > > + JsonItemTypeNumeric = 2, /* jbvNumeric */ > > + JsonItemTypeBoolean = 3, /* jbvBool */ > > + JsonItemTypeDate = 4, /* jbvDatetime: DATEOID */ > > + JsonItemTypeTime = 5, /* jbvDatetime: TIMEOID */ > > + JsonItemTypeTimetz = 6, /* jbvDatetime: TIMETZOID */ > > + JsonItemTypeTimestamp = 7, /* jbvDatetime: TIMESTAMPOID */ > > + JsonItemTypeTimestamptz = 8, /* jbvDatetime: TIMESTAMPTZOID */ > > + JsonItemTypeComposite = 9, /* jbvArray, jbvObject, jbvBinary */ > > + JsonItemTypeInvalid = 10, > > +} JsonItemType; > > Why do we need manually assigned values here? Not really necessary here. I think I simply copied the style from some other json-related enum where assigning values seems necessary. > > +/* > > + * JsonCoercion - > > + * coercion from SQL/JSON item types to SQL types > > + */ > > +typedef struct JsonCoercion > > +{ > > + NodeTag type; > > + > > + Oid targettype; > > + int32 targettypmod; > > + bool via_populate; /* coerce result using json_populate_type()? */ > > + bool via_io; /* coerce result using type input function? */ > > + Oid collation; /* collation for coercion via I/O or populate */ > > +} JsonCoercion; > > + > > +typedef struct JsonItemCoercion > > +{ > > + NodeTag type; > > + > > + JsonItemType item_type; > > + Node *coercion; > > +} JsonItemCoercion; > > What's the difference between an "ItemCoercion" and a "Coercion"? ItemCoercion is used to store the coercion expression used at runtime to convert the value of given JsonItemType to the target type specified in the JsonExpr.returning. It can either be a cast expression node found by the parser or a JsonCoercion node. I'll update the comments. > > +/* > > + * JsonBehavior - > > + * representation of a given JSON behavior > > My editor warns about space-before-tab here. Fixed. > > + */ > > +typedef struct JsonBehavior > > +{ > > + NodeTag type; > > > + JsonBehaviorType btype; /* behavior type */ > > + Node *expr; /* behavior expression */ > > These comment don't seem helpful. I think there's need for comments here, but > restating the field name in different words isn't helpful. What's needed is an > explanation of how things interact, perhaps also why that's the appropriate > representation. > > > + JsonCoercion *coercion; /* to coerce behavior expression when there is > > + * no cast to the target type */ > > + int location; /* token location, or -1 if unknown */ > > > +} JsonBehavior; > > + > > +/* > > + * JsonExpr - > > + * transformed representation of JSON_VALUE(), JSON_QUERY(), JSON_EXISTS() > > + */ > > +typedef struct JsonExpr > > +{ > > + Expr xpr; > > + > > + JsonExprOp op; /* json function ID */ > > + Node *formatted_expr; /* formatted context item expression */ > > + Node *result_coercion; /* resulting coercion to RETURNING type */ > > + JsonFormat *format; /* context item format (JSON/JSONB) */ > > + Node *path_spec; /* JSON path specification expression */ > > + List *passing_names; /* PASSING argument names */ > > + List *passing_values; /* PASSING argument values */ > > + JsonReturning *returning; /* RETURNING clause type/format info */ > > + JsonBehavior *on_empty; /* ON EMPTY behavior */ > > + JsonBehavior *on_error; /* ON ERROR behavior */ > > + List *item_coercions; /* coercions for JSON_VALUE */ > > + JsonWrapper wrapper; /* WRAPPER for JSON_QUERY */ > > + bool omit_quotes; /* KEEP/OMIT QUOTES for JSON_QUERY */ > > + int location; /* token location, or -1 if unknown */ > > +} JsonExpr; > > These comments seem even worse. OK, I've rewritten the comments about JsonBehavior and JsonExpr. > > +static void ExecInitJsonExpr(JsonExpr *jexpr, ExprState *state, > > + Datum *resv, bool *resnull, > > + ExprEvalStep *scratch); > > +static int ExecInitJsonExprCoercion(ExprState *state, Node *coercion, > > + ErrorSaveContext *escontext, > > + Datum *resv, bool *resnull); > > > > > > /* > > @@ -2416,6 +2423,36 @@ ExecInitExprRec(Expr *node, ExprState *state, > > break; > > } > > > > + case T_JsonExpr: > > + { > > + JsonExpr *jexpr = castNode(JsonExpr, node); > > + > > + ExecInitJsonExpr(jexpr, state, resv, resnull, &scratch); > > + break; > > + } > > + > > + case T_JsonCoercion: > > + { > > + JsonCoercion *coercion = castNode(JsonCoercion, node); > > + JsonCoercionState *jcstate = palloc0(sizeof(JsonCoercionState)); > > + Oid typinput; > > + FmgrInfo *finfo; > > + > > + getTypeInputInfo(coercion->targettype, &typinput, > > + &jcstate->input.typioparam); > > + finfo = palloc0(sizeof(FmgrInfo)); > > + fmgr_info(typinput, finfo); > > + jcstate->input.finfo = finfo; > > + > > + jcstate->coercion = coercion; > > + jcstate->escontext = state->escontext; > > + > > + scratch.opcode = EEOP_JSONEXPR_COERCION; > > + scratch.d.jsonexpr_coercion.jcstate = jcstate; > > + ExprEvalPushStep(state, &scratch); > > + break; > > + } > > It's confusing that we have ExecInitJsonExprCoercion, but aren't using that > here, but then use it later, in ExecInitJsonExpr(). I had moved this code out of ExecInitJsonExprCoercion() into ExecInitExprRec() to make the JsonCoercion node look like a first class citizen of execExpr.c, but maybe that's not such a good idea after all. I've moved it back to make it just another implementation detail of JsonExpr. > > + EEO_CASE(EEOP_JSONEXPR_PATH) > > + { > > + JsonExprState *jsestate = op->d.jsonexpr.jsestate; > > + > > + /* too complex for an inline implementation */ > > + if (!ExecEvalJsonExprPath(state, op, econtext)) > > + EEO_JUMP(jsestate->jump_error); > > + else if (jsestate->post_eval.jump_eval_coercion >= 0) > > + EEO_JUMP(jsestate->post_eval.jump_eval_coercion); > > + > > + EEO_NEXT(); > > + } > > Why do we need post_eval.jump_eval_coercion? Seems like that could more > cleanly be implemented by just emitting a constant JUMP step? Oh, I see - > you're changing post_eval.jump_eval_coercion at runtime. This seems like a > BAD idea. I strongly suggest that instead of modifying the field, you instead > return the target jump step as a return value from ExecEvalJsonExprPath or > such. OK, done that way. > > + bool throw_error = (jexpr->on_error->btype == JSON_BEHAVIOR_ERROR); > > What's the deal with the parentheses here and in similar places below? There's > no danger of ambiguity without, no? Yes, this looks like a remnant of an old version of this condition. > > + if (empty) > > + { > > + if (jexpr->on_empty) > > + { > > + if (jexpr->on_empty->btype == JSON_BEHAVIOR_ERROR) > > + ereport(ERROR, > > + (errcode(ERRCODE_NO_SQL_JSON_ITEM), > > + errmsg("no SQL/JSON item"))); > > No need for the parens around ereport() arguments anymore. Same in a few other places. All fixed. > > diff --git a/src/backend/parser/gram.y b/src/backend/parser/gram.y > > index d631ac89a9..4f92d000ec 100644 > > --- a/src/backend/parser/gram.y > > +++ b/src/backend/parser/gram.y > > +json_behavior: > > + DEFAULT a_expr > > + { $$ = (Node *) makeJsonBehavior(JSON_BEHAVIOR_DEFAULT, $2, NULL, @1); } > > + | ERROR_P > > + { $$ = (Node *) makeJsonBehavior(JSON_BEHAVIOR_ERROR, NULL, NULL, @1); } > > + | NULL_P > > + { $$ = (Node *) makeJsonBehavior(JSON_BEHAVIOR_NULL, NULL, NULL, @1); } > > + | TRUE_P > > + { $$ = (Node *) makeJsonBehavior(JSON_BEHAVIOR_TRUE, NULL, NULL, @1); } > > + | FALSE_P > > + { $$ = (Node *) makeJsonBehavior(JSON_BEHAVIOR_FALSE, NULL, NULL, @1); } > > + | UNKNOWN > > + { $$ = (Node *) makeJsonBehavior(JSON_BEHAVIOR_UNKNOWN, NULL, NULL, @1); } > > + | EMPTY_P ARRAY > > + { $$ = (Node *) makeJsonBehavior(JSON_BEHAVIOR_EMPTY_ARRAY, NULL, NULL, @1); } > > + | EMPTY_P OBJECT_P > > + { $$ = (Node *) makeJsonBehavior(JSON_BEHAVIOR_EMPTY_OBJECT, NULL, NULL, @1); } > > + /* non-standard, for Oracle compatibility only */ > > + | EMPTY_P > > + { $$ = (Node *) makeJsonBehavior(JSON_BEHAVIOR_EMPTY_ARRAY, NULL, NULL, @1); } > > + ; > > Seems like this would look better if you made json_behavior return just the > enum values and had one makeJsonBehavior() at the place referencing it? Yes, changed like that. > > +json_behavior_clause_opt: > > + json_behavior ON EMPTY_P > > + { $$ = list_make2($1, NULL); } > > + | json_behavior ON ERROR_P > > + { $$ = list_make2(NULL, $1); } > > + | json_behavior ON EMPTY_P json_behavior ON ERROR_P > > + { $$ = list_make2($1, $4); } > > + | /* EMPTY */ > > + { $$ = list_make2(NULL, NULL); } > > + ; > > This seems like an odd representation - why represent the behavior as a two > element list where one needs to know what is stored at which list offset? A previous version had a JsonBehaviorClause containing 2 JsonBehavior nodes, but Peter didn't like it, so we have this. Like Peter, I prefer to use the List instead of a whole new parser node, but maybe the damage would be less if we make the List be local to gram.y. I've done that by adding two JsonBehavior nodes to JsonFuncExpr itself which are assigned appropriate values from the List in gram.y itself. Updated patches attached. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
- v32-0001-Add-soft-error-handling-to-some-expression-nodes.patch
- v32-0005-Add-a-jsonpath-support-function-jspIsMutable.patch
- v32-0003-Refactor-code-used-by-jsonpath-executor-to-fetch.patch
- v32-0004-Add-jsonpath_exec-APIs-to-use-in-SQL-JSON-query-.patch
- v32-0002-Add-json_populate_type-with-support-for-soft-err.patch
- v32-0006-Add-jsonb-support-function-JsonbUnquote.patch
- v32-0007-SQL-JSON-query-functions.patch
- v32-0008-JSON_TABLE.patch
On Sat, Dec 9, 2023 at 2:05 AM Andrew Dunstan <andrew@dunslane.net> wrote: > On 2023-12-08 Fr 11:37, Robert Haas wrote: > > On Fri, Dec 8, 2023 at 1:59 AM Amit Langote <amitlangote09@gmail.com> wrote: > >> Would it be messy to replace the lookahead approach by whatever's > >> suiable *in the future* when it becomes necessary to do so? > > It might be. Changing grammar rules to tends to change corner-case > > behavior if nothing else. We're best off picking the approach that we > > think is correct long term. > > All this makes me wonder if Alvaro's first suggested solution (adding > NESTED to the UNBOUNDED precedence level) wouldn't be better after all. I've done just that in the latest v32. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
On Sat, Dec 9, 2023 at 2:05 PM jian he <jian.universality@gmail.com> wrote:
> Hi.
Thanks for the review.
> function JsonPathExecResult comment needs to be refactored? since it
> changed a lot.
I suppose you meant executeJsonPath()'s comment. I've added a
description of the new callback function arguments.
On Wed, Dec 13, 2023 at 6:59 PM jian he <jian.universality@gmail.com> wrote:
> Hi. small issues I found...
>
> typo:
> +-- Test mutabilily od query functions
Fixed.
>
> + default:
> + ereport(ERROR,
> + (errcode(ERRCODE_INVALID_PARAMETER_VALUE),
> + errmsg("only datetime, bool, numeric, and text types can be casted
> to jsonpath types")));
>
> transformJsonPassingArgs's function: transformJsonValueExpr will make
> the above code unreached.
It's good to have the ereport to catch errors caused by any future changes.
> also based on the `switch (typid)` cases,
> I guess best message would be
> errmsg("only datetime, bool, numeric, text, json, jsonb types can be
> casted to jsonpath types")));
I've rewritten the message to mention the unsupported type. Maybe the
supported types can go in a DETAIL message. I might do that later.
> + case JSON_QUERY_OP:
> + jsexpr->wrapper = func->wrapper;
> + jsexpr->omit_quotes = (func->quotes == JS_QUOTES_OMIT);
> +
> + if (!OidIsValid(jsexpr->returning->typid))
> + {
> + JsonReturning *ret = jsexpr->returning;
> +
> + ret->typid = JsonFuncExprDefaultReturnType(jsexpr);
> + ret->typmod = -1;
> + }
> + jsexpr->result_coercion = coerceJsonFuncExprOutput(pstate, jsexpr);
>
> I noticed, if (!OidIsValid(jsexpr->returning->typid)) is the true
> function JsonFuncExprDefaultReturnType may be called twice, not sure
> if it's good or not..
If avoiding the double-calling means that we've to add more conditions
in the code, I'm fine with leaving this as-is.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
hi.
since InitJsonItemCoercions cannot return NULL.
per transformJsonFuncExpr, jsexpr->item_coercions not null imply
jsexpr->result_coercion not null.
so I did the attached refactoring.
now every ExecInitJsonExprCoercion function call followed with:
scratch->opcode = EEOP_JUMP;
scratch->d.jump.jumpdone = -1; /* set below */
jumps_to_coerce_finish = lappend_int(jumps_to_coerce_finish,
state->steps_len);
ExprEvalPushStep(state, scratch);
It looks more consistent.
we can also change
+ */
+ if (jexpr->result_coercion || jexpr->item_coercions)
+ {
+
to
+ if (jexpr->result_coercion)
since jexpr->item_coercions not null imply jexpr->result_coercion not null.
Вложения
Hi! another minor issue I found: +SELECT pg_get_expr(adbin, adrelid) +FROM pg_attrdef +WHERE adrelid = 'test_jsonb_constraints'::regclass +ORDER BY 1; + +SELECT pg_get_expr(adbin, adrelid) FROM pg_attrdef WHERE adrelid = 'test_jsonb_constraints'::regclass; I think these two queries are the same? Why do we test it twice.....
On Thu, Dec 14, 2023 at 5:04 PM Amit Langote <amitlangote09@gmail.com> wrote: > On Sat, Dec 9, 2023 at 2:30 AM Andres Freund <andres@anarazel.de> wrote: > > On 2023-12-07 21:07:59 +0900, Amit Langote wrote: > > > From 38b53297b2d435d5cebf78c1f81e4748fed6c8b6 Mon Sep 17 00:00:00 2001 > > > From: Amit Langote <amitlan@postgresql.org> > > > Date: Wed, 22 Nov 2023 13:18:49 +0900 > > > Subject: [PATCH v30 2/5] Add soft error handling to populate_record_field() > > > > > > An uncoming patch would like the ability to call it from the > > > executor for some SQL/JSON expression nodes and ask to suppress any > > > errors that may occur. > > > > > > This commit does two things mainly: > > > > > > * It modifies the various interfaces internal to jsonfuncs.c to pass > > > the ErrorSaveContext around. > > > > > > * Make necessary modifications to handle the cases where the > > > processing is aborted partway through various functions that take > > > an ErrorSaveContext when a soft error occurs. > > > > > > Note that the above changes are only intended to suppress errors in > > > the functions in jsonfuncs.c, but not those in any external functions > > > that the functions in jsonfuncs.c in turn call, such as those from > > > arrayfuncs.c. It is assumed that the various populate_* functions > > > validate the data before passing those to external functions. > > > > > > Discussion: https://postgr.es/m/CA+HiwqE4XTdfb1nW=Ojoy_tQSRhYt-q_kb6i5d4xcKyrLC1Nbg@mail.gmail.com > > > > The code here is getting substantially more verbose / less readable. I wonder > > if there's something more general that could be improved to make this less > > painful? > > Hmm, I can't think of anything short of a rewrite of the code under > populate_record_field() so that any error-producing code is well > isolated or adding a variant/wrapper with soft-error handling > capabilities. I'll give this some more thought, though I'm happy to > hear ideas. I looked at this and wasn't able to come up with alternative takes that are better in terms of the verbosity/readability. I'd still want to hear if someone well-versed in the json(b) code has any advice. I also looked at some commits touching src/backend/utils/adt/json* files to add soft error handling and I can't help but notice that those commits look not very different from this. For example, commits c60c9bad, 50428a30 contain changes like: @@ -454,7 +474,11 @@ parse_array_element(JsonLexContext *lex, JsonSemAction *sem) return result; if (aend != NULL) - (*aend) (sem->semstate, isnull); + { + result = (*aend) (sem->semstate, isnull); + if (result != JSON_SUCCESS) + return result; + } Attached updated patches addressing jian he's comments, some minor fixes, and commit message updates. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
- v33-0002-Add-json_populate_type-with-support-for-soft-err.patch
- v33-0005-Add-a-jsonpath-support-function-jspIsMutable.patch
- v33-0001-Add-soft-error-handling-to-some-expression-nodes.patch
- v33-0004-Add-jsonpath_exec-APIs-to-use-in-SQL-JSON-query-.patch
- v33-0003-Refactor-code-used-by-jsonpath-executor-to-fetch.patch
- v33-0006-Add-jsonb-support-function-JsonbUnquote.patch
- v33-0007-SQL-JSON-query-functions.patch
- v33-0008-JSON_TABLE.patch
Hi
v33-0007-SQL-JSON-query-functions.patch, commit message:
This introduces the SQL/JSON functions for querying JSON data using
jsonpath expressions. The functions are:
should it be "These functions are"
+ <para>
+ Returns true if the SQL/JSON <replaceable>path_expression</replaceable>
+ applied to the <replaceable>context_item</replaceable> using the
+ <replaceable>value</replaceable>s yields any items.
+ The <literal>ON ERROR</literal> clause specifies what is returned if
+ an error occurs; the default is to return <literal>FALSE</literal>.
+ Note that if the <replaceable>path_expression</replaceable>
+ is <literal>strict</literal>, an error is generated if it
yields no items.
+ </para>
I think the following description is more accurate.
+ Note that if the <replaceable>path_expression</replaceable>
+ is <literal>strict</literal> and the <literal>ON
ERROR</literal> clause is <literal> ERROR</literal>,
+ an error is generated if it yields no items.
+ </para>
+/*
+ * transformJsonTable -
+ * Transform a raw JsonTable into TableFunc.
+ *
+ * Transform the document-generating expression, the row-generating expression,
+ * the column-generating expressions, and the default value expressions.
+ */
+ParseNamespaceItem *
+transformJsonTable(ParseState *pstate, JsonTable *jt)
+{
+ JsonTableParseContext cxt;
+ TableFunc *tf = makeNode(TableFunc);
+ JsonFuncExpr *jfe = makeNode(JsonFuncExpr);
+ JsonExpr *je;
+ JsonTablePlan *plan = jt->plan;
+ char *rootPathName = jt->pathname;
+ char *rootPath;
+ bool is_lateral;
+
+ if (jt->on_empty)
+ ereport(ERROR,
+ (errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
+ errmsg("ON EMPTY not allowed in JSON_TABLE"),
+ parser_errposition(pstate,
+ exprLocation((Node *) jt->on_empty))));
This error may be slightly misleading?
you can add ON EMPTY inside the COLUMNS part, like the following:
SELECT * FROM (VALUES ('1'), ('"1"')) vals(js) LEFT OUTER JOIN
JSON_TABLE(vals.js::jsonb, '$' COLUMNS (a int PATH '$' default 1 ON
empty)) jt ON true;
+ <para>
+ Each <literal>NESTED PATH</literal> clause can generate one or more
+ columns. Columns produced by <literal>NESTED PATH</literal>s at the
+ same level are considered to be <firstterm>siblings</firstterm>,
+ while a column produced by a <literal>NESTED PATH</literal> is
+ considered to be a child of the column produced by a
+ <literal>NESTED PATH</literal> or row expression at a higher level.
+ Sibling columns are always joined first. Once they are processed,
+ the resulting rows are joined to the parent row.
+ </para>
Does changing to the following make sense?
+ considered to be a <firstterm>child</firstterm> of the column produced by a
+ the resulting rows are joined to the <firstterm>parent</firstterm> row.
seems like `format json_representation`, not listed in the
documentation, but json_representation is "Parameters", do we need
add a section to explain it?
even though I think currently we can only do `FORMAT JSON`.
SELECT * FROM JSON_TABLE(jsonb '123', '$' COLUMNS (item int PATH '$'
empty on empty)) bar;
ERROR: cannot cast jsonb array to type integer
The error is the same as the output of the following:
SELECT * FROM JSON_TABLE(jsonb '123', '$' COLUMNS (item int PATH '$'
empty array on empty )) bar;
but these two are different things?
+ /* FALLTHROUGH */
+ case JTC_EXISTS:
+ case JTC_FORMATTED:
+ {
+ Node *je;
+ CaseTestExpr *param = makeNode(CaseTestExpr);
+
+ param->collation = InvalidOid;
+ param->typeId = cxt->contextItemTypid;
+ param->typeMod = -1;
+
+ if (rawc->wrapper != JSW_NONE &&
+ rawc->quotes != JS_QUOTES_UNSPEC)
+ ereport(ERROR,
+ (errcode(ERRCODE_SYNTAX_ERROR),
+ errmsg("cannot use WITH WRAPPER clause for formatted colunmns"
+ " without also specifying OMIT/KEEP QUOTES"),
+ parser_errposition(pstate, rawc->location)));
typo, should be "formatted columns".
I suspect people will be confused with the meaning of "formatted column".
maybe we can replace this part:"cannot use WITH WRAPPER clause for
formatted column"
to
"SQL/JSON WITH WRAPPER behavior must not be specified when FORMAT
clause is used"
SELECT * FROM JSON_TABLE(jsonb '"world"', '$' COLUMNS (item text
FORMAT JSON PATH '$' with wrapper KEEP QUOTES));
ERROR: cannot use WITH WRAPPER clause for formatted colunmns without
also specifying OMIT/KEEP QUOTES
LINE 1: ...T * FROM JSON_TABLE(jsonb '"world"', '$' COLUMNS (item text ...
^
this error is misleading, since now I am using WITH WRAPPER clause for
formatted columns and specified KEEP QUOTES.
in parse_expr.c, we have errmsg("SQL/JSON QUOTES behavior must not be
specified when WITH WRAPPER is used").
+/*
+ * Fetch next row from a cross/union joined scan.
+ *
+ * Returns false at the end of a scan, true otherwise.
+ */
+static bool
+JsonTablePlanNextRow(JsonTablePlanState * state)
+{
+ JsonTableJoinState *join;
+
+ if (state->type == JSON_TABLE_SCAN_STATE)
+ return JsonTableScanNextRow((JsonTableScanState *) state);
+
+ join = (JsonTableJoinState *) state;
+ if (join->advanceRight)
+ {
+ /* fetch next inner row */
+ if (JsonTablePlanNextRow(join->right))
+ return true;
+
+ /* inner rows are exhausted */
+ if (join->cross)
+ join->advanceRight = false; /* next outer row */
+ else
+ return false; /* end of scan */
+ }
+
+ while (!join->advanceRight)
+ {
+ /* fetch next outer row */
+ bool left = JsonTablePlanNextRow(join->left);
+ bool left = JsonTablePlanNextRow(join->left);
JsonTablePlanNextRow function comment says "Returns false at the end
of a scan, true otherwise.",
so bool variable name as "left" seems not so good?
It might help others understand the whole code by adding some comments on
struct JsonTableScanState and struct JsonTableJoinState.
since json_table patch is quite recursive, IMHO.
I did some minor refactoring in parse_expr.c, since some code like
transformJsonExprCommon is duplicated.
Вложения
Hi.
+/*
+ * JsonTableFetchRow
+ * Prepare the next "current" tuple for upcoming GetValue calls.
+ * Returns FALSE if the row-filter expression returned no more rows.
+ */
+static bool
+JsonTableFetchRow(TableFuncScanState *state)
+{
+ JsonTableExecContext *cxt =
+ GetJsonTableExecContext(state, "JsonTableFetchRow");
+
+ if (cxt->empty)
+ return false;
+
+ return JsonTableScanNextRow(cxt->root);
+}
The declaration of struct JsonbTableRoutine, SetRowFilter field is
null. So I am confused by the above comment.
also seems the `if (cxt->empty)` part never called.
+static inline JsonTableExecContext *
+GetJsonTableExecContext(TableFuncScanState *state, const char *fname)
+{
+ JsonTableExecContext *result;
+
+ if (!IsA(state, TableFuncScanState))
+ elog(ERROR, "%s called with invalid TableFuncScanState", fname);
+ result = (JsonTableExecContext *) state->opaque;
+ if (result->magic != JSON_TABLE_EXEC_CONTEXT_MAGIC)
+ elog(ERROR, "%s called with invalid TableFuncScanState", fname);
+
+ return result;
+}
I think Assert(IsA(state, TableFuncScanState)) would be better.
+/*
+ * JsonTablePlanType -
+ * flags for JSON_TABLE plan node types representation
+ */
+typedef enum JsonTablePlanType
+{
+ JSTP_DEFAULT,
+ JSTP_SIMPLE,
+ JSTP_JOINED,
+} JsonTablePlanType;
it would be better to add some comments on it. thanks.
JsonTablePlanNextRow is quite recursive! Adding more explanation would
be helpful, thanks.
+/* Recursively reset scan and its child nodes */
+static void
+JsonTableRescanRecursive(JsonTablePlanState * state)
+{
+ if (state->type == JSON_TABLE_JOIN_STATE)
+ {
+ JsonTableJoinState *join = (JsonTableJoinState *) state;
+
+ JsonTableRescanRecursive(join->left);
+ JsonTableRescanRecursive(join->right);
+ join->advanceRight = false;
+ }
+ else
+ {
+ JsonTableScanState *scan = (JsonTableScanState *) state;
+
+ Assert(state->type == JSON_TABLE_SCAN_STATE);
+ JsonTableRescan(scan);
+ if (scan->plan.nested)
+ JsonTableRescanRecursive(scan->plan.nested);
+ }
+}
From the coverage report, I noticed the first IF branch in
JsonTableRescanRecursive never called.
+ foreach(col, columns)
+ {
+ JsonTableColumn *rawc = castNode(JsonTableColumn, lfirst(col));
+ Oid typid;
+ int32 typmod;
+ Node *colexpr;
+
+ if (rawc->name)
+ {
+ /* make sure column names are unique */
+ ListCell *colname;
+
+ foreach(colname, tf->colnames)
+ if (!strcmp((const char *) colname, rawc->name))
+ ereport(ERROR,
+ (errcode(ERRCODE_SYNTAX_ERROR),
+ errmsg("column name \"%s\" is not unique",
+ rawc->name),
+ parser_errposition(pstate, rawc->location)));
this `/* make sure column names are unique */` logic part already
validated in isJsonTablePathNameDuplicate, so we don't need it?
actually isJsonTablePathNameDuplicate validates both column name and pathname.
select jt.* from jsonb_table_test jtt,
json_table (jtt.js,'strict $[*]' as p
columns (n for ordinality,
nested path 'strict $.b[*]' as pb columns ( c int path '$' ),
nested path 'strict $.b[*]' as pb columns ( s int path '$' ))
) jt;
ERROR: duplicate JSON_TABLE column name: pb
HINT: JSON_TABLE column names must be distinct from one another.
the error is not very accurate, since pb is a pathname?
On Fri, Dec 22, 2023 at 9:01 PM jian he <jian.universality@gmail.com> wrote:
>
> Hi
>
> + /* FALLTHROUGH */
> + case JTC_EXISTS:
> + case JTC_FORMATTED:
> + {
> + Node *je;
> + CaseTestExpr *param = makeNode(CaseTestExpr);
> +
> + param->collation = InvalidOid;
> + param->typeId = cxt->contextItemTypid;
> + param->typeMod = -1;
> +
> + if (rawc->wrapper != JSW_NONE &&
> + rawc->quotes != JS_QUOTES_UNSPEC)
> + ereport(ERROR,
> + (errcode(ERRCODE_SYNTAX_ERROR),
> + errmsg("cannot use WITH WRAPPER clause for formatted colunmns"
> + " without also specifying OMIT/KEEP QUOTES"),
> + parser_errposition(pstate, rawc->location)));
>
> typo, should be "formatted columns".
> I suspect people will be confused with the meaning of "formatted column".
> maybe we can replace this part:"cannot use WITH WRAPPER clause for
> formatted column"
> to
> "SQL/JSON WITH WRAPPER behavior must not be specified when FORMAT
> clause is used"
>
> SELECT * FROM JSON_TABLE(jsonb '"world"', '$' COLUMNS (item text
> FORMAT JSON PATH '$' with wrapper KEEP QUOTES));
> ERROR: cannot use WITH WRAPPER clause for formatted colunmns without
> also specifying OMIT/KEEP QUOTES
> LINE 1: ...T * FROM JSON_TABLE(jsonb '"world"', '$' COLUMNS (item text ...
> ^
> this error is misleading, since now I am using WITH WRAPPER clause for
> formatted columns and specified KEEP QUOTES.
>
Hi. still based on v33.
JSON_TABLE:
I also refactor parse_jsontable.c error reporting, now the error
message will be consistent with json_query.
now you can specify wrapper freely as long as you don't specify
wrapper and quote at the same time.
overall, json_table behavior is more consistent with json_query and json_value.
I also added some tests.
+void
+ExecEvalJsonCoercion(ExprState *state, ExprEvalStep *op,
+ ExprContext *econtext)
+{
+ JsonCoercion *coercion = op->d.jsonexpr_coercion.coercion;
+ ErrorSaveContext *escontext = op->d.jsonexpr_coercion.escontext;
+ Datum res = *op->resvalue;
+ bool resnull = *op->resnull;
+
+ if (coercion->via_populate)
+ {
+ void *cache = op->d.jsonexpr_coercion.json_populate_type_cache;
+
+ *op->resvalue = json_populate_type(res, JSONBOID,
+ coercion->targettype,
+ coercion->targettypmod,
+ &cache,
+ econtext->ecxt_per_query_memory,
+ op->resnull, (Node *) escontext);
+ }
+ else if (coercion->via_io)
+ {
+ FmgrInfo *input_finfo = op->d.jsonexpr_coercion.input_finfo;
+ Oid typioparam = op->d.jsonexpr_coercion.typioparam;
+ char *val_string = resnull ? NULL :
+ JsonbUnquote(DatumGetJsonbP(res));
+
+ (void) InputFunctionCallSafe(input_finfo, val_string, typioparam,
+ coercion->targettypmod,
+ (Node *) escontext,
+ op->resvalue);
+ }
via_populate, via_io should be mutually exclusive.
your patch, in some cases, both (coercion->via_io) and
(coercion->via_populate) are true.
(we can use elog find out).
I refactor coerceJsonFuncExprOutput, so now it will be mutually exclusive.
I also add asserts to it.
By default, json_query keeps quotes, json_value omit quotes.
However, json_table will be transformed to json_value or json_query
based on certain criteria,
that means we need to explicitly set the JsonExpr->omit_quotes in the
function transformJsonFuncExpr
for case JSON_QUERY_OP and JSON_VALUE_OP.
We need to know the QUOTE behavior in the function ExecEvalJsonCoercion.
Because for ExecEvalJsonCoercion, the coercion datum source can be a
scalar string item,
scalar items means RETURNING clause is dependent on QUOTE behavior.
keep quotes, omit quotes the results are different.
consider
JSON_QUERY(jsonb'{"rec": "[1,2]"}', '$.rec' returning int4range omit quotes);
and
JSON_QUERY(jsonb'{"rec": "[1,2]"}', '$.rec' returning int4range omit quotes);
to make sure ExecEvalJsonCoercion can distinguish keep and omit quotes,
I added a bool keep_quotes to struct JsonCoercion.
(maybe there is a more simple way, so far, that's what I come up with).
the keep_quotes value will be settled in the function transformJsonFuncExpr.
After refactoring, in ExecEvalJsonCoercion, keep_quotes is true then
call JsonbToCString, else call JsonbUnquote.
example:
SELECT JSON_QUERY(jsonb'{"rec": "{1,2,3}"}', '$.rec' returning int[]
omit quotes);
without my changes, return NULL
with my changes:
{1,2,3}
JSON_VALUE:
main changes:
--- a/src/test/regress/expected/jsonb_sqljson.out
+++ b/src/test/regress/expected/jsonb_sqljson.out
@@ -301,7 +301,11 @@ SELECT JSON_VALUE(jsonb '"2017-02-20"', '$'
RETURNING date) + 9;
-- Test NULL checks execution in domain types
CREATE DOMAIN sqljsonb_int_not_null AS int NOT NULL;
SELECT JSON_VALUE(jsonb 'null', '$' RETURNING sqljsonb_int_not_null);
-ERROR: domain sqljsonb_int_not_null does not allow null values
+ json_value
+------------
+
+(1 row)
+
I think the change is correct, given `SELECT JSON_VALUE(jsonb 'null',
'$' RETURNING int4range);` returns NULL.
I also attached a test.sql, without_patch.out (apply v33 only),
with_patch.out (my changes based on v33).
So you can see the difference after applying the patch, in case, my
wording is not clear.
Вложения
some more minor issues:
SELECT * FROM JSON_TABLE(jsonb '{"a":[123,2]}', '$'
COLUMNS (item int[] PATH '$.a' error on error, foo text path '$'
error on error)) bar;
ERROR: JSON path expression in JSON_VALUE should return singleton scalar item
the error message seems not so great, imho.
since the JSON_TABLE doc entries didn't mention that
JSON_TABLE actually transformed to json_value, json_query, json_exists.
JSON_VALUE even though cannot specify KEEP | OMIT QUOTES.
It might be a good idea to mention the default is to omit quotes in the doc.
because JSON_TABLE actually transformed to json_value, json_query, json_exists.
JSON_TABLE can specify quotes behavior freely.
bother again, i kind of get what the function transformJsonTableChildPlan do,
but adding more comments would make it easier to understand....
(json_query)
+ This function must return a JSON string, so if the path expression
+ returns multiple SQL/JSON items, you must wrap the result using the
+ <literal>WITH WRAPPER</literal> clause. If the wrapper is
+ <literal>UNCONDITIONAL</literal>, an array wrapper will always
+ be applied, even if the returned value is already a single JSON object
+ or an array, but if it is <literal>CONDITIONAL</literal>, it
will not be
+ applied to a single array or object. <literal>UNCONDITIONAL</literal>
+ is the default. If the result is a scalar string, by default the value
+ returned will have surrounding quotes making it a valid JSON value,
+ which can be made explicit by specifying <literal>KEEP
QUOTES</literal>.
+ Conversely, quotes can be omitted by specifying <literal>OMIT
QUOTES</literal>.
+ The returned <replaceable>data_type</replaceable> has the
same semantics
+ as for constructor functions like <function>json_objectagg</function>;
+ the default returned type is <type>jsonb</type>.
+ <para>
+ Returns the result of applying the
+ <replaceable>path_expression</replaceable> to the
+ <replaceable>context_item</replaceable> using the
+ <literal>PASSING</literal> <replaceable>value</replaceable>s. The
+ extracted value must be a single <acronym>SQL/JSON</acronym> scalar
+ item. For results that are objects or arrays, use the
+ <function>json_query</function> function instead.
+ The returned <replaceable>data_type</replaceable> has the
same semantics
+ as for constructor functions like <function>json_objectagg</function>.
+ The default returned type is <type>text</type>.
+ The <literal>ON ERROR</literal> and <literal>ON EMPTY</literal>
+ clauses have similar semantics as mentioned in the description of
+ <function>json_query</function>.
+ </para>
+ The returned <replaceable>data_type</replaceable> has the
same semantics
+ as for constructor functions like <function>json_objectagg</function>.
IMHO, the above description is not so good, since the function
json_objectagg is listed in functions-aggregate.html,
using Ctrl + F in the browser cannot find json_objectagg in functions-json.html.
for json_query, maybe we can rephrase like:
the RETURNING clause, which specifies the data type returned. It must
be a type for which there is a cast from text to that type.
By default, the <type>jsonb</type> type is returned.
json_value:
the RETURNING clause, which specifies the data type returned. It must
be a type for which there is a cast from text to that type.
By default, the <type>text</type> type is returned.
some tests after applying V33 and my small changes.
setup:
create table test_scalar1(js jsonb);
insert into test_scalar1 select jsonb '{"a":"[12,13]"}' FROM
generate_series(1,1e5) g;
create table test_scalar2(js jsonb);
insert into test_scalar2 select jsonb '{"a":12}' FROM generate_series(1,1e5) g;
create table test_array1(js jsonb);
insert into test_array1 select jsonb '{"a":[1,2,3,4,5]}' FROM
generate_series(1,1e5) g;
create table test_array2(js jsonb);
insert into test_array2 select jsonb '{"a": "{1,2,3,4,5}"}' FROM
generate_series(1,1e5) g;
tests:
----------------------------------------return a scalar int4range
explain(costs off,analyze) SELECT item FROM test_scalar1,
JSON_TABLE(js, '$.a' COLUMNS (item int4range PATH '$' omit quotes))
\watch count=5
237.753 ms
explain(costs off,analyze) select json_query(js, '$.a' returning
int4range omit quotes) from test_scalar1 \watch count=5
462.379 ms
explain(costs off,analyze) select json_value(js,'$.a' returning
int4range) from test_scalar1 \watch count=5
362.148 ms
explain(costs off,analyze) select (js->>'a')::int4range from
test_scalar1 \watch count=5
301.089 ms
explain(costs off,analyze) select trim(both '"' from
jsonb_path_query_first(js,'$.a')::text)::int4range from test_scalar1
\watch count=5
643.337 ms
----------------------------return a numeric array from jsonb array.
explain(costs off,analyze) SELECT item FROM test_array1,
JSON_TABLE(js, '$.a' COLUMNS (item numeric[] PATH '$')) \watch count=5
727.807 ms
explain(costs off,analyze) SELECT json_query(js, '$.a' returning
numeric[]) from test_array1 \watch count=5
2995.909 ms
explain(costs off,analyze) SELECT
replace(replace(js->>'a','[','{'),']','}')::numeric[] from test_array1
\watch count=5
2990.114 ms
----------------------------return a numeric array from jsonb string
explain(costs off,analyze) SELECT item FROM test_array2,
JSON_TABLE(js, '$.a' COLUMNS (item numeric[] PATH '$' omit quotes))
\watch count=5
237.863 ms
explain(costs off,analyze) SELECT json_query(js,'$.a' returning
numeric[] omit quotes) from test_array2 \watch count=5
893.888 ms
explain(costs off,analyze) SELECT trim(both '"'
from(jsonb_path_query(js,'$.a')::text))::numeric[] from test_array2
\watch count=5
1329.713 ms
explain(costs off,analyze) SELECT (js->>'a')::numeric[] from
test_array2 \watch count=5
740.645 ms
explain(costs off,analyze) SELECT trim(both '"' from
(json_query(js,'$.a' returning text)))::numeric[] from test_array2
\watch count=5
1085.230 ms
----------------------------return a scalar numeric
explain(costs off,analyze) SELECT item FROM test_scalar2,
JSON_TABLE(js, '$.a' COLUMNS (item numeric PATH '$' omit quotes)) \watch count=5
238.036 ms
explain(costs off,analyze) select json_query(js,'$.a' returning
numeric) from test_scalar2 \watch count=5
300.862 ms
explain(costs off,analyze) select json_value(js,'$.a' returning
numeric) from test_scalar2 \watch count=5
160.035 ms
explain(costs off,analyze) select
jsonb_path_query_first(js,'$.a')::numeric from test_scalar2 \watch
count=5
294.666 ms
explain(costs off,analyze) select jsonb_path_query(js,'$.a')::numeric
from test_scalar2 \watch count=5
547.130 ms
explain(costs off,analyze) select (js->>'a')::numeric from
test_scalar2 \watch count=5
243.652 ms
explain(costs off,analyze) select (js->>'a')::numeric,
(js->>'a')::numeric from test_scalar2 \watch count=5
403.183 ms
explain(costs off,analyze) select json_value(js,'$.a' returning numeric),
json_value(js,'$.a' returning numeric) from test_scalar2 \watch count=5
246.405 ms
explain(costs off,analyze) select json_query(js,'$.a' returning numeric),
json_query(js,'$.a' returning numeric) from test_scalar2 \watch count=5
520.754 ms
explain(costs off,analyze) SELECT item, item1 FROM test_scalar2,
JSON_TABLE(js, '$.a' COLUMNS (item numeric PATH '$' omit quotes,
item1 numeric PATH '$' omit quotes)) \watch count=5
242.586 ms
---------------------------------
overall, json_value is faster than json_query. but json_value can not
deal with arrays in some cases.
but as you can see, in some cases, json_value and json_query are not
as fast as our current implementation.
Here I only test simple nested levels. if you extra multiple values
from jsonb to sql type, then json_table is faster.
In almost all cases, json_table is faster.
json_table is actually called json_value_op, json_query_op under the hood.
Without json_value and json_query related code, json_table cannot be
implemented.
On Sat, Jan 6, 2024 at 8:44 AM jian he <jian.universality@gmail.com> wrote:
>
> some tests after applying V33 and my small changes.
> setup:
> create table test_scalar1(js jsonb);
> insert into test_scalar1 select jsonb '{"a":"[12,13]"}' FROM
> generate_series(1,1e5) g;
> create table test_scalar2(js jsonb);
> insert into test_scalar2 select jsonb '{"a":12}' FROM generate_series(1,1e5) g;
> create table test_array1(js jsonb);
> insert into test_array1 select jsonb '{"a":[1,2,3,4,5]}' FROM
> generate_series(1,1e5) g;
> create table test_array2(js jsonb);
> insert into test_array2 select jsonb '{"a": "{1,2,3,4,5}"}' FROM
> generate_series(1,1e5) g;
>
same as before, v33 plus my 4 minor changes (dot no-cfbot in previous thread).
I realized my previous tests were wrong.because I use build type=debug and also add a bunch of c_args.
so the following test results have no c_args, just -Dbuildtype=release.
so the following test results have no c_args, just -Dbuildtype=release.
I actually tested several times.
----------------------------------------return a scalar int4range
explain(costs off,analyze) SELECT item FROM test_scalar1, JSON_TABLE(js, '$.a' COLUMNS (item int4range PATH '$' omit quotes)) \watch count=5
56.487 ms
explain(costs off,analyze) select json_query(js, '$.a' returning int4range omit quotes) from test_scalar1 \watch count=5
27.272 ms
explain(costs off,analyze) select json_value(js,'$.a' returning int4range) from test_scalar1 \watch count=5
22.775 ms
explain(costs off,analyze) select (js->>'a')::int4range from test_scalar1 \watch count=5
17.520 ms
explain(costs off,analyze) select trim(both '"' from jsonb_path_query_first(js,'$.a')::text)::int4range from test_scalar1 \watch count=5
36.946 ms
----------------------------return a numeric array from jsonb array.
explain(costs off,analyze) SELECT item FROM test_array1, JSON_TABLE(js, '$.a' COLUMNS (item numeric[] PATH '$')) \watch count=5
20.197 ms
explain(costs off,analyze) SELECT json_query(js, '$.a' returning numeric[]) from test_array1 \watch count=5
69.759 ms
explain(costs off,analyze) SELECT replace(replace(js->>'a','[','{'),']','}')::numeric[] from test_array1 \watch count=5
62.114 ms
----------------------------return a numeric array from jsonb string
explain(costs off,analyze) SELECT item FROM test_array2, JSON_TABLE(js, '$.a' COLUMNS (item numeric[] PATH '$' omit quotes)) \watch count=5
18.770 ms
explain(costs off,analyze) SELECT json_query(js,'$.a' returning numeric[] omit quotes) from test_array2 \watch count=5
46.373 ms
explain(costs off,analyze) SELECT trim(both '"' from(jsonb_path_query(js,'$.a')::text))::numeric[] from test_array2 \watch count=5
71.901 ms
explain(costs off,analyze) SELECT (js->>'a')::numeric[] from test_array2 \watch count=5
35.572 ms
explain(costs off,analyze) SELECT trim(both '"' from (json_query(js,'$.a' returning text)))::numeric[] from test_array2 \watch count=5
58.755 ms
----------------------------return a scalar numeric
explain(costs off,analyze) SELECT item FROM test_scalar2,
JSON_TABLE(js, '$.a' COLUMNS (item numeric PATH '$' omit quotes)) \watch count=5
18.723 ms
explain(costs off,analyze) select json_query(js,'$.a' returning numeric) from test_scalar2 \watch count=5
18.234 ms
explain(costs off,analyze) select json_value(js,'$.a' returning numeric) from test_scalar2 \watch count=5
11.667 ms
explain(costs off,analyze) select jsonb_path_query_first(js,'$.a')::numeric from test_scalar2 \watch count=5
17.691 ms
explain(costs off,analyze) select jsonb_path_query(js,'$.a')::numeric from test_scalar2 \watch count=5
31.596 ms
explain(costs off,analyze) select (js->>'a')::numeric from test_scalar2 \watch count=5
13.887 ms
----------------------------return two scalar numeric
explain(costs off,analyze) select (js->>'a')::numeric, (js->>'a')::numeric from test_scalar2 \watch count=5
22.201 ms
explain(costs off,analyze) SELECT item, item1 FROM test_scalar2, JSON_TABLE(js, '$.a' COLUMNS (item numeric PATH '$' omit quotes,
item1 numeric PATH '$' omit quotes)) \watch count=5
19.108 ms
explain(costs off,analyze) select json_value(js,'$.a' returning numeric),
json_value(js,'$.a' returning numeric) from test_scalar2 \watch count=5
17.915 ms
Hi, Thought I'd share an update. I've been going through Jian He's comments (thanks for the reviews!), most of which affect the last JSON_TABLE() patch and in some cases the query functions patch (0007). It seems I'll need to spend a little more time, especially on the JSON_TABLE() patch, as I'm finding things to improve other than those mentioned in the comments. As for the preliminary patches 0001-0006, I'm thinking that it would be a good idea to get them out of the way sooner rather than waiting till the main patches are in perfect shape. I'd like to get them committed by next week after a bit of polishing, so if anyone would like to take a look, please let me know. I'll post a new set tomorrow. 0007, the query functions patch, also looks close to ready, though I might need to change a few things in it as I work through the JSON_TABLE() changes. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
I've been eyeballing the coverage report generated after applying all
patches (but I only checked the code added by the 0008 patch). AFAICS
the coverage is pretty good. Some uncovered paths:
commands/explain.c (Hmm, I think this is a preexisting bug actually)
3893 18 : case T_TableFuncScan:
3894 18 : Assert(rte->rtekind == RTE_TABLEFUNC);
3895 18 : if (rte->tablefunc)
3896 0 : if (rte->tablefunc->functype == TFT_XMLTABLE)
3897 0 : objectname = "xmltable";
3898 : else /* Must be TFT_JSON_TABLE */
3899 0 : objectname = "json_table";
3900 : else
3901 18 : objectname = NULL;
3902 18 : objecttag = "Table Function Name";
3903 18 : break;
parser/gram.y:
16940 : json_table_plan_cross:
16941 : json_table_plan_primary CROSS json_table_plan_primary
16942 39 : { $$ = makeJsonTableJoinedPlan(JSTPJ_CROSS, $1, $3, @1); }
16943 : | json_table_plan_cross CROSS json_table_plan_primary
16944 0 : { $$ = makeJsonTableJoinedPlan(JSTPJ_CROSS, $1, $3, @1); }
Not really sure how critical this one is TBH.
utils/adt/jsonpath_exec.c:
3492 : /* Recursively reset scan and its child nodes */
3493 : static void
3494 120 : JsonTableRescanRecursive(JsonTablePlanState * state)
3495 : {
3496 120 : if (state->type == JSON_TABLE_JOIN_STATE)
3497 : {
3498 0 : JsonTableJoinState *join = (JsonTableJoinState *) state;
3499 :
3500 0 : JsonTableRescanRecursive(join->left);
3501 0 : JsonTableRescanRecursive(join->right);
3502 0 : join->advanceRight = false;
3503 : }
I think this one had better be covered.
--
Álvaro Herrera 48°01'N 7°57'E — https://www.EnterpriseDB.com/
"The saddest aspect of life right now is that science gathers knowledge faster
than society gathers wisdom." (Isaac Asimov)
Hi,
On Fri, Dec 22, 2023 at 10:01 PM jian he <jian.universality@gmail.com> wrote:
> Hi
Thanks for the reviews.
> v33-0007-SQL-JSON-query-functions.patch, commit message:
> This introduces the SQL/JSON functions for querying JSON data using
> jsonpath expressions. The functions are:
>
> should it be "These functions are"
Rewrote that sentence to say "introduces the following SQL/JSON functions..."
> + <para>
> + Returns true if the SQL/JSON <replaceable>path_expression</replaceable>
> + applied to the <replaceable>context_item</replaceable> using the
> + <replaceable>value</replaceable>s yields any items.
> + The <literal>ON ERROR</literal> clause specifies what is returned if
> + an error occurs; the default is to return <literal>FALSE</literal>.
> + Note that if the <replaceable>path_expression</replaceable>
> + is <literal>strict</literal>, an error is generated if it
> yields no items.
> + </para>
>
> I think the following description is more accurate.
> + Note that if the <replaceable>path_expression</replaceable>
> + is <literal>strict</literal> and the <literal>ON
> ERROR</literal> clause is <literal> ERROR</literal>,
> + an error is generated if it yields no items.
> + </para>
True, fixed.
> +/*
> + * transformJsonTable -
> + * Transform a raw JsonTable into TableFunc.
> + *
> + * Transform the document-generating expression, the row-generating expression,
> + * the column-generating expressions, and the default value expressions.
> + */
> +ParseNamespaceItem *
> +transformJsonTable(ParseState *pstate, JsonTable *jt)
> +{
> + JsonTableParseContext cxt;
> + TableFunc *tf = makeNode(TableFunc);
> + JsonFuncExpr *jfe = makeNode(JsonFuncExpr);
> + JsonExpr *je;
> + JsonTablePlan *plan = jt->plan;
> + char *rootPathName = jt->pathname;
> + char *rootPath;
> + bool is_lateral;
> +
> + if (jt->on_empty)
> + ereport(ERROR,
> + (errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
> + errmsg("ON EMPTY not allowed in JSON_TABLE"),
> + parser_errposition(pstate,
> + exprLocation((Node *) jt->on_empty))));
>
> This error may be slightly misleading?
> you can add ON EMPTY inside the COLUMNS part, like the following:
> SELECT * FROM (VALUES ('1'), ('"1"')) vals(js) LEFT OUTER JOIN
> JSON_TABLE(vals.js::jsonb, '$' COLUMNS (a int PATH '$' default 1 ON
> empty)) jt ON true;
That check is to catch an ON EMPTY specified *outside* the COLUMN(...)
clause of a JSON_TABLE(...) expression. It was added during a recent
gram.y refactoring, but maybe that wasn't a great idea. It seems
better to disallow the ON EMPTY clause in the grammar itself.
> + <para>
> + Each <literal>NESTED PATH</literal> clause can generate one or more
> + columns. Columns produced by <literal>NESTED PATH</literal>s at the
> + same level are considered to be <firstterm>siblings</firstterm>,
> + while a column produced by a <literal>NESTED PATH</literal> is
> + considered to be a child of the column produced by a
> + <literal>NESTED PATH</literal> or row expression at a higher level.
> + Sibling columns are always joined first. Once they are processed,
> + the resulting rows are joined to the parent row.
> + </para>
> Does changing to the following make sense?
> + considered to be a <firstterm>child</firstterm> of the column produced by a
> + the resulting rows are joined to the <firstterm>parent</firstterm> row.
Terms "child" and "parent" are already introduced in previous
paragraphs, so no need for the <firstterm> tag.
> seems like `format json_representation`, not listed in the
> documentation, but json_representation is "Parameters", do we need
> add a section to explain it?
> even though I think currently we can only do `FORMAT JSON`.
The syntax appears to allow an optional ENCODING UTF8 too, so I've
gotten rid of json_representation and literally listed out what the
syntax says.
> SELECT * FROM JSON_TABLE(jsonb '123', '$' COLUMNS (item int PATH '$'
> empty on empty)) bar;
> ERROR: cannot cast jsonb array to type integer
> The error is the same as the output of the following:
> SELECT * FROM JSON_TABLE(jsonb '123', '$' COLUMNS (item int PATH '$'
> empty array on empty )) bar;
> but these two are different things?
EMPTY and EMPTY ARRAY both spell out an array:
json_behavior_type:
...
| EMPTY_P ARRAY { $$ = JSON_BEHAVIOR_EMPTY_ARRAY; }
/* non-standard, for Oracle compatibility only */
| EMPTY_P { $$ = JSON_BEHAVIOR_EMPTY_ARRAY; }
> + /* FALLTHROUGH */
> + case JTC_EXISTS:
> + case JTC_FORMATTED:
> + {
> + Node *je;
> + CaseTestExpr *param = makeNode(CaseTestExpr);
> +
> + param->collation = InvalidOid;
> + param->typeId = cxt->contextItemTypid;
> + param->typeMod = -1;
> +
> + if (rawc->wrapper != JSW_NONE &&
> + rawc->quotes != JS_QUOTES_UNSPEC)
> + ereport(ERROR,
> + (errcode(ERRCODE_SYNTAX_ERROR),
> + errmsg("cannot use WITH WRAPPER clause for formatted colunmns"
> + " without also specifying OMIT/KEEP QUOTES"),
> + parser_errposition(pstate, rawc->location)));
>
> typo, should be "formatted columns".
Oops.
> I suspect people will be confused with the meaning of "formatted column".
> maybe we can replace this part:"cannot use WITH WRAPPER clause for
> formatted column"
> to
> "SQL/JSON WITH WRAPPER behavior must not be specified when FORMAT
> clause is used"
>
> SELECT * FROM JSON_TABLE(jsonb '"world"', '$' COLUMNS (item text
> FORMAT JSON PATH '$' with wrapper KEEP QUOTES));
> ERROR: cannot use WITH WRAPPER clause for formatted colunmns without
> also specifying OMIT/KEEP QUOTES
> LINE 1: ...T * FROM JSON_TABLE(jsonb '"world"', '$' COLUMNS (item text ...
> ^
> this error is misleading, since now I am using WITH WRAPPER clause for
> formatted columns and specified KEEP QUOTES.
>
> in parse_expr.c, we have errmsg("SQL/JSON QUOTES behavior must not be
> specified when WITH WRAPPER is used").
It seems to me that we should just remove the above check in
appendJsonTableColumns() and let the check(s) in parse_expr.c take
care of the various allowed/disallowed scenarios for "formatted"
columns. Also see further below...
> +/*
> + * Fetch next row from a cross/union joined scan.
> + *
> + * Returns false at the end of a scan, true otherwise.
> + */
> +static bool
> +JsonTablePlanNextRow(JsonTablePlanState * state)
> +{
> + JsonTableJoinState *join;
> +
> + if (state->type == JSON_TABLE_SCAN_STATE)
> + return JsonTableScanNextRow((JsonTableScanState *) state);
> +
> + join = (JsonTableJoinState *) state;
> + if (join->advanceRight)
> + {
> + /* fetch next inner row */
> + if (JsonTablePlanNextRow(join->right))
> + return true;
> +
> + /* inner rows are exhausted */
> + if (join->cross)
> + join->advanceRight = false; /* next outer row */
> + else
> + return false; /* end of scan */
> + }
> +
> + while (!join->advanceRight)
> + {
> + /* fetch next outer row */
> + bool left = JsonTablePlanNextRow(join->left);
>
> + bool left = JsonTablePlanNextRow(join->left);
> JsonTablePlanNextRow function comment says "Returns false at the end
> of a scan, true otherwise.",
> so bool variable name as "left" seems not so good?
Hmm, maybe, "more" might be more appropriate given the context.
> It might help others understand the whole code by adding some comments on
> struct JsonTableScanState and struct JsonTableJoinState.
> since json_table patch is quite recursive, IMHO.
Agree that the various JsonTable parser/executor comments are lacking.
Working on adding more commentary and improving the notation -- struct
names, etc.
> I did some minor refactoring in parse_expr.c, since some code like
> transformJsonExprCommon is duplicated.
Thanks, I've adopted some of the ideas in your patch.
On Mon, Dec 25, 2023 at 2:03 PM jian he <jian.universality@gmail.com> wrote:
> +/*
> + * JsonTableFetchRow
> + * Prepare the next "current" tuple for upcoming GetValue calls.
> + * Returns FALSE if the row-filter expression returned no more rows.
> + */
> +static bool
> +JsonTableFetchRow(TableFuncScanState *state)
> +{
> + JsonTableExecContext *cxt =
> + GetJsonTableExecContext(state, "JsonTableFetchRow");
> +
> + if (cxt->empty)
> + return false;
> +
> + return JsonTableScanNextRow(cxt->root);
> +}
>
> The declaration of struct JsonbTableRoutine, SetRowFilter field is
> null. So I am confused by the above comment.
Yeah, it might be a leftover from copy-pasting the XML code. Reworded
the comment to not mention SetRowFilter.
> also seems the `if (cxt->empty)` part never called.
I don't understand why the context struct has that empty flag too, it
might be a leftover field. Removed.
> +static inline JsonTableExecContext *
> +GetJsonTableExecContext(TableFuncScanState *state, const char *fname)
> +{
> + JsonTableExecContext *result;
> +
> + if (!IsA(state, TableFuncScanState))
> + elog(ERROR, "%s called with invalid TableFuncScanState", fname);
> + result = (JsonTableExecContext *) state->opaque;
> + if (result->magic != JSON_TABLE_EXEC_CONTEXT_MAGIC)
> + elog(ERROR, "%s called with invalid TableFuncScanState", fname);
> +
> + return result;
> +}
> I think Assert(IsA(state, TableFuncScanState)) would be better.
Hmm, better to leave this as-is to be consistent with what the XML
code is doing. Though I also wonder why it's not an Assert in the
first place.
> +/*
> + * JsonTablePlanType -
> + * flags for JSON_TABLE plan node types representation
> + */
> +typedef enum JsonTablePlanType
> +{
> + JSTP_DEFAULT,
> + JSTP_SIMPLE,
> + JSTP_JOINED,
> +} JsonTablePlanType;
> it would be better to add some comments on it. thanks.
>
> JsonTablePlanNextRow is quite recursive! Adding more explanation would
> be helpful, thanks.
Will do.
> +/* Recursively reset scan and its child nodes */
> +static void
> +JsonTableRescanRecursive(JsonTablePlanState * state)
> +{
> + if (state->type == JSON_TABLE_JOIN_STATE)
> + {
> + JsonTableJoinState *join = (JsonTableJoinState *) state;
> +
> + JsonTableRescanRecursive(join->left);
> + JsonTableRescanRecursive(join->right);
> + join->advanceRight = false;
> + }
> + else
> + {
> + JsonTableScanState *scan = (JsonTableScanState *) state;
> +
> + Assert(state->type == JSON_TABLE_SCAN_STATE);
> + JsonTableRescan(scan);
> + if (scan->plan.nested)
> + JsonTableRescanRecursive(scan->plan.nested);
> + }
> +}
>
> From the coverage report, I noticed the first IF branch in
> JsonTableRescanRecursive never called.
Will look into this.
> + foreach(col, columns)
> + {
> + JsonTableColumn *rawc = castNode(JsonTableColumn, lfirst(col));
> + Oid typid;
> + int32 typmod;
> + Node *colexpr;
> +
> + if (rawc->name)
> + {
> + /* make sure column names are unique */
> + ListCell *colname;
> +
> + foreach(colname, tf->colnames)
> + if (!strcmp((const char *) colname, rawc->name))
> + ereport(ERROR,
> + (errcode(ERRCODE_SYNTAX_ERROR),
> + errmsg("column name \"%s\" is not unique",
> + rawc->name),
> + parser_errposition(pstate, rawc->location)));
>
> this `/* make sure column names are unique */` logic part already
> validated in isJsonTablePathNameDuplicate, so we don't need it?
> actually isJsonTablePathNameDuplicate validates both column name and pathname.
I think you are right. All columns/path names are de-duplicated much
earlier at the beginning of transformJsonTable(), so there's no need
for the above check.
That said, I don't know why column and path names share the namespace
or whether that has any semantic issues. Maybe there aren't, but will
think some more on that.
> select jt.* from jsonb_table_test jtt,
> json_table (jtt.js,'strict $[*]' as p
> columns (n for ordinality,
> nested path 'strict $.b[*]' as pb columns ( c int path '$' ),
> nested path 'strict $.b[*]' as pb columns ( s int path '$' ))
> ) jt;
>
> ERROR: duplicate JSON_TABLE column name: pb
> HINT: JSON_TABLE column names must be distinct from one another.
> the error is not very accurate, since pb is a pathname?
I think this can be improved by passing the information whether it's a
column or path name to the deduplication code. I've reworked that
code to get more useful error info.
On Wed, Jan 3, 2024 at 7:53 PM jian he <jian.universality@gmail.com> wrote:
> some more minor issues:
> SELECT * FROM JSON_TABLE(jsonb '{"a":[123,2]}', '$'
> COLUMNS (item int[] PATH '$.a' error on error, foo text path '$'
> error on error)) bar;
> ERROR: JSON path expression in JSON_VALUE should return singleton scalar item
>
> the error message seems not so great, imho.
> since the JSON_TABLE doc entries didn't mention that
> JSON_TABLE actually transformed to json_value, json_query, json_exists.
Hmm, yes, the context whether the JSON_VALUE() is user-specified or
internally generated is not readily available where the error is
reported.
I'm inlinced to document this aspect of JSON_TABLE(), instead of
complicating the executor interfaces in order to make the error
message better.
> JSON_VALUE even though cannot specify KEEP | OMIT QUOTES.
> It might be a good idea to mention the default is to omit quotes in the doc.
> because JSON_TABLE actually transformed to json_value, json_query, json_exists.
> JSON_TABLE can specify quotes behavior freely.
Done.
> (json_query)
> + This function must return a JSON string, so if the path expression
> + returns multiple SQL/JSON items, you must wrap the result using the
> + <literal>WITH WRAPPER</literal> clause. If the wrapper is
> + <literal>UNCONDITIONAL</literal>, an array wrapper will always
> + be applied, even if the returned value is already a single JSON object
> + or an array, but if it is <literal>CONDITIONAL</literal>, it
> will not be
> + applied to a single array or object. <literal>UNCONDITIONAL</literal>
> + is the default. If the result is a scalar string, by default the value
> + returned will have surrounding quotes making it a valid JSON value,
> + which can be made explicit by specifying <literal>KEEP
> QUOTES</literal>.
> + Conversely, quotes can be omitted by specifying <literal>OMIT
> QUOTES</literal>.
> + The returned <replaceable>data_type</replaceable> has the
> same semantics
> + as for constructor functions like <function>json_objectagg</function>;
> + the default returned type is <type>jsonb</type>.
>
> + <para>
> + Returns the result of applying the
> + <replaceable>path_expression</replaceable> to the
> + <replaceable>context_item</replaceable> using the
> + <literal>PASSING</literal> <replaceable>value</replaceable>s. The
> + extracted value must be a single <acronym>SQL/JSON</acronym> scalar
> + item. For results that are objects or arrays, use the
> + <function>json_query</function> function instead.
> + The returned <replaceable>data_type</replaceable> has the
> same semantics
> + as for constructor functions like <function>json_objectagg</function>.
> + The default returned type is <type>text</type>.
> + The <literal>ON ERROR</literal> and <literal>ON EMPTY</literal>
> + clauses have similar semantics as mentioned in the description of
> + <function>json_query</function>.
> + </para>
>
> + The returned <replaceable>data_type</replaceable> has the
> same semantics
> + as for constructor functions like <function>json_objectagg</function>.
>
> IMHO, the above description is not so good, since the function
> json_objectagg is listed in functions-aggregate.html,
> using Ctrl + F in the browser cannot find json_objectagg in functions-json.html.
>
> for json_query, maybe we can rephrase like:
> the RETURNING clause, which specifies the data type returned. It must
> be a type for which there is a cast from text to that type.
> By default, the <type>jsonb</type> type is returned.
>
> json_value:
> the RETURNING clause, which specifies the data type returned. It must
> be a type for which there is a cast from text to that type.
> By default, the <type>text</type> type is returned.
Fixed the description of returned type for both json_query() and
json_value(). For the latter, the cast to the returned type must
exist from each possible JSON scalar type viz. text, boolean, numeric,
and various datetime types.
On Wed, Jan 3, 2024 at 7:50 PM jian he <jian.universality@gmail.com> wrote:
> Hi. still based on v33.
> JSON_TABLE:
> I also refactor parse_jsontable.c error reporting, now the error
> message will be consistent with json_query.
> now you can specify wrapper freely as long as you don't specify
> wrapper and quote at the same time.
> overall, json_table behavior is more consistent with json_query and json_value.
> I also added some tests.
Thanks for the patches. I've taken the tests, some of your suggested
code changes, and made some changes of my own. Some of the new tests
give a different error message than what your patch had but I think
what I have is fine.
> +void
> +ExecEvalJsonCoercion(ExprState *state, ExprEvalStep *op,
> + ExprContext *econtext)
> +{
> + JsonCoercion *coercion = op->d.jsonexpr_coercion.coercion;
> + ErrorSaveContext *escontext = op->d.jsonexpr_coercion.escontext;
> + Datum res = *op->resvalue;
> + bool resnull = *op->resnull;
> +
> + if (coercion->via_populate)
> + {
> + void *cache = op->d.jsonexpr_coercion.json_populate_type_cache;
> +
> + *op->resvalue = json_populate_type(res, JSONBOID,
> + coercion->targettype,
> + coercion->targettypmod,
> + &cache,
> + econtext->ecxt_per_query_memory,
> + op->resnull, (Node *) escontext);
> + }
> + else if (coercion->via_io)
> + {
> + FmgrInfo *input_finfo = op->d.jsonexpr_coercion.input_finfo;
> + Oid typioparam = op->d.jsonexpr_coercion.typioparam;
> + char *val_string = resnull ? NULL :
> + JsonbUnquote(DatumGetJsonbP(res));
> +
> + (void) InputFunctionCallSafe(input_finfo, val_string, typioparam,
> + coercion->targettypmod,
> + (Node *) escontext,
> + op->resvalue);
> + }
> via_populate, via_io should be mutually exclusive.
> your patch, in some cases, both (coercion->via_io) and
> (coercion->via_populate) are true.
> (we can use elog find out).
> I refactor coerceJsonFuncExprOutput, so now it will be mutually exclusive.
> I also add asserts to it.
I realized that we don't really need the via_io and via_populate
flags. You can see in the latest patch that the decision of whether
to call json_populate_type() or the RETURNING type's input function is
now deferred to run-time or ExecEvalJsonCoercion(). The new comment
should also make it clear why one or the other is used for a given
source datum passed to ExecEvalJsonCoercion().
> By default, json_query keeps quotes, json_value omit quotes.
> However, json_table will be transformed to json_value or json_query
> based on certain criteria,
> that means we need to explicitly set the JsonExpr->omit_quotes in the
> function transformJsonFuncExpr
> for case JSON_QUERY_OP and JSON_VALUE_OP.
>
> We need to know the QUOTE behavior in the function ExecEvalJsonCoercion.
> Because for ExecEvalJsonCoercion, the coercion datum source can be a
> scalar string item,
> scalar items means RETURNING clause is dependent on QUOTE behavior.
> keep quotes, omit quotes the results are different.
> consider
> JSON_QUERY(jsonb'{"rec": "[1,2]"}', '$.rec' returning int4range omit quotes);
> and
> JSON_QUERY(jsonb'{"rec": "[1,2]"}', '$.rec' returning int4range omit quotes);
>
> to make sure ExecEvalJsonCoercion can distinguish keep and omit quotes,
> I added a bool keep_quotes to struct JsonCoercion.
> (maybe there is a more simple way, so far, that's what I come up with).
> the keep_quotes value will be settled in the function transformJsonFuncExpr.
> After refactoring, in ExecEvalJsonCoercion, keep_quotes is true then
> call JsonbToCString, else call JsonbUnquote.
>
> example:
> SELECT JSON_QUERY(jsonb'{"rec": "{1,2,3}"}', '$.rec' returning int[]
> omit quotes);
> without my changes, return NULL
> with my changes:
> {1,2,3}
>
> JSON_VALUE:
> main changes:
> --- a/src/test/regress/expected/jsonb_sqljson.out
> +++ b/src/test/regress/expected/jsonb_sqljson.out
> @@ -301,7 +301,11 @@ SELECT JSON_VALUE(jsonb '"2017-02-20"', '$'
> RETURNING date) + 9;
> -- Test NULL checks execution in domain types
> CREATE DOMAIN sqljsonb_int_not_null AS int NOT NULL;
> SELECT JSON_VALUE(jsonb 'null', '$' RETURNING sqljsonb_int_not_null);
> -ERROR: domain sqljsonb_int_not_null does not allow null values
> + json_value
> +------------
> +
> +(1 row)
> +
> I think the change is correct, given `SELECT JSON_VALUE(jsonb 'null',
> '$' RETURNING int4range);` returns NULL.
>
> I also attached a test.sql, without_patch.out (apply v33 only),
> with_patch.out (my changes based on v33).
> So you can see the difference after applying the patch, in case, my
> wording is not clear.
To address these points:
* I've taken your idea to make omit/keep_quotes available to
ExecEvalJsonCoercion().
* I've also taken your suggestion to fix parse_jsontable.c such that
WRAPPER/QUOTES combinations specified with JSON_TABLE() columns work
without many arbitrary-looking restrictions.
Please take a look at the attached latest patch and let me know if
anything looks amiss.
On Sat, Jan 6, 2024 at 9:45 AM jian he <jian.universality@gmail.com> wrote:
> some tests after applying V33 and my small changes.
> setup:
> create table test_scalar1(js jsonb);
> insert into test_scalar1 select jsonb '{"a":"[12,13]"}' FROM
> generate_series(1,1e5) g;
> create table test_scalar2(js jsonb);
> insert into test_scalar2 select jsonb '{"a":12}' FROM generate_series(1,1e5) g;
> create table test_array1(js jsonb);
> insert into test_array1 select jsonb '{"a":[1,2,3,4,5]}' FROM
> generate_series(1,1e5) g;
> create table test_array2(js jsonb);
> insert into test_array2 select jsonb '{"a": "{1,2,3,4,5}"}' FROM
> generate_series(1,1e5) g;
>
> tests:
> ----------------------------------------return a scalar int4range
> explain(costs off,analyze) SELECT item FROM test_scalar1,
> JSON_TABLE(js, '$.a' COLUMNS (item int4range PATH '$' omit quotes))
> \watch count=5
> 237.753 ms
>
> explain(costs off,analyze) select json_query(js, '$.a' returning
> int4range omit quotes) from test_scalar1 \watch count=5
> 462.379 ms
>
> explain(costs off,analyze) select json_value(js,'$.a' returning
> int4range) from test_scalar1 \watch count=5
> 362.148 ms
>
> explain(costs off,analyze) select (js->>'a')::int4range from
> test_scalar1 \watch count=5
> 301.089 ms
>
> explain(costs off,analyze) select trim(both '"' from
> jsonb_path_query_first(js,'$.a')::text)::int4range from test_scalar1
> \watch count=5
> 643.337 ms
> ---------------------------------
> overall, json_value is faster than json_query. but json_value can not
> deal with arrays in some cases.
I think that may be explained by the fact that JsonPathQuery() has
this step, which JsonPathValue() does not:
if (singleton)
return JsonbPGetDatum(JsonbValueToJsonb(singleton));
I can see JsonbValueToJsonb() in perf profile when running the
benchmark you shared. I don't know if there's any way to make that
better.
> but as you can see, in some cases, json_value and json_query are not
> as fast as our current implementation
Yeah, there *is* some expected overhead to using the new functions;
ExecEvalJsonExprPath() appears in the top 5 frames of perf profile,
for example. The times I see are similar to yours and I don't find
the difference to be very drastic.
postgres=# \o /dev/null
postgres=# explain(costs off,analyze) select (js->>'a') from
test_scalar1 \watch count=3
Time: 21.581 ms
Time: 18.838 ms
Time: 21.589 ms
postgres=# explain(costs off,analyze) select json_query(js,'$.a') from
test_scalar1 \watch count=3
Time: 38.562 ms
Time: 34.251 ms
Time: 32.681 ms
postgres=# explain(costs off,analyze) select json_value(js,'$.a') from
test_scalar1 \watch count=3
Time: 28.595 ms
Time: 23.947 ms
Time: 25.334 ms
postgres=# explain(costs off,analyze) select item from test_scalar1,
json_table(js, '$.a' columns (item int4range path '$')); \watch
count=3
Time: 52.739 ms
Time: 53.996 ms
Time: 50.774 ms
Attached v34 of all of the patches. 0008 may be considered to be WIP
given the points I mentioned above -- need to add a bit more
commentary about JSON_TABLE plan implementation and other
miscellaneous fixes.
As said in my previous email, I'd like to commit 0001-0007 next week.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
Вложения
- v34-0005-Add-a-jsonpath-support-function-jspIsMutable.patch
- v34-0001-Add-soft-error-handling-to-some-expression-nodes.patch
- v34-0003-Refactor-code-used-by-jsonpath-executor-to-fetch.patch
- v34-0004-Add-jsonpath_exec-APIs-to-use-in-SQL-JSON-query-.patch
- v34-0002-Add-json_populate_type-with-support-for-soft-err.patch
- v34-0006-Add-jsonb-support-function-JsonbUnquote.patch
- v34-0007-SQL-JSON-query-functions.patch
- v34-0008-JSON_TABLE.patch
On Thu, Jan 18, 2024 at 10:12 PM Amit Langote <amitlangote09@gmail.com> wrote: > Attached v34 of all of the patches. 0008 may be considered to be WIP > given the points I mentioned above -- need to add a bit more > commentary about JSON_TABLE plan implementation and other > miscellaneous fixes. Oops, I had forgotten to update the ECPG test's expected output in 0008. Fixed in the attached. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
- v35-0003-Refactor-code-used-by-jsonpath-executor-to-fetch.patch
- v35-0001-Add-soft-error-handling-to-some-expression-nodes.patch
- v35-0005-Add-a-jsonpath-support-function-jspIsMutable.patch
- v35-0002-Add-json_populate_type-with-support-for-soft-err.patch
- v35-0004-Add-jsonpath_exec-APIs-to-use-in-SQL-JSON-query-.patch
- v35-0006-Add-jsonb-support-function-JsonbUnquote.patch
- v35-0007-SQL-JSON-query-functions.patch
- v35-0008-JSON_TABLE.patch
On 2024-Jan-18, Alvaro Herrera wrote: > commands/explain.c (Hmm, I think this is a preexisting bug actually) > > 3893 18 : case T_TableFuncScan: > 3894 18 : Assert(rte->rtekind == RTE_TABLEFUNC); > 3895 18 : if (rte->tablefunc) > 3896 0 : if (rte->tablefunc->functype == TFT_XMLTABLE) > 3897 0 : objectname = "xmltable"; > 3898 : else /* Must be TFT_JSON_TABLE */ > 3899 0 : objectname = "json_table"; > 3900 : else > 3901 18 : objectname = NULL; > 3902 18 : objecttag = "Table Function Name"; > 3903 18 : break; Indeed -- the problem seems to be that add_rte_to_flat_rtable is creating a new RTE and zaps the ->tablefunc pointer for it. So when EXPLAIN goes to examine the struct, there's a NULL pointer there and nothing is printed. One simple fix is to change add_rte_to_flat_rtable so that it doesn't zero out the tablefunc pointer, but this is straight against what that function is trying to do, namely to remove substructure. Which means that we need to preserve the name somewhere else. I added a new member to RangeTblEntry for this, which perhaps is a little ugly. So here's the patch for that. (I also added an alias to one XMLTABLE invocation under EXPLAIN, to show what it looks like when an alias is specified. Otherwise they're always shown as "XMLTABLE" "xmltable" which is a bit dumb). Another possible way out is to decide that we don't want the "objectname" to be reported here. I admit it's perhaps redundant. In this case we'd just remove lines 3896-3899 shown above and let it be NULL. Thoughts? -- Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/
Вложения
On Fri, Jan 19, 2024 at 2:11 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > On 2024-Jan-18, Alvaro Herrera wrote: > > > commands/explain.c (Hmm, I think this is a preexisting bug actually) > > > > 3893 18 : case T_TableFuncScan: > > 3894 18 : Assert(rte->rtekind == RTE_TABLEFUNC); > > 3895 18 : if (rte->tablefunc) > > 3896 0 : if (rte->tablefunc->functype == TFT_XMLTABLE) > > 3897 0 : objectname = "xmltable"; > > 3898 : else /* Must be TFT_JSON_TABLE */ > > 3899 0 : objectname = "json_table"; > > 3900 : else > > 3901 18 : objectname = NULL; > > 3902 18 : objecttag = "Table Function Name"; > > 3903 18 : break; > > Indeed -- the problem seems to be that add_rte_to_flat_rtable is > creating a new RTE and zaps the ->tablefunc pointer for it. So when > EXPLAIN goes to examine the struct, there's a NULL pointer there and > nothing is printed. Ah yes. > One simple fix is to change add_rte_to_flat_rtable so that it doesn't > zero out the tablefunc pointer, but this is straight against what that > function is trying to do, namely to remove substructure. Yes. > Which means > that we need to preserve the name somewhere else. I added a new member > to RangeTblEntry for this, which perhaps is a little ugly. So here's > the patch for that. > > (I also added an alias to one XMLTABLE invocation > under EXPLAIN, to show what it looks like when an alias is specified. > Otherwise they're always shown as "XMLTABLE" "xmltable" which is a bit > dumb). Thanks for the patch. Seems alright to me. > Another possible way out is to decide that we don't want the > "objectname" to be reported here. I admit it's perhaps redundant. In > this case we'd just remove lines 3896-3899 shown above and let it be > NULL. Showing the function's name spelled out in the query (XMLTABLE / JSON_TABLE) seems fine to me, even though maybe a bit redundant, yes. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
play with domain types.
in ExecEvalJsonCoercion, seems func json_populate_type cannot cope
with domain type.
tests:
drop domain test;
create domain test as int[] check ( array_length(value,1) =2 and
(value[1] = 1 or value[2] = 2));
SELECT * from JSON_QUERY(jsonb'{"rec": "{1,2,3}"}', '$.rec' returning
test omit quotes);
SELECT * from JSON_QUERY(jsonb'{"rec": "{1,11}"}', '$.rec' returning
test keep quotes);
SELECT * from JSON_QUERY(jsonb'{"rec": "{2,11}"}', '$.rec' returning
test omit quotes error on error);
SELECT * from JSON_QUERY(jsonb'{"rec": "{2,2}"}', '$.rec' returning
test keep quotes error on error);
SELECT * from JSON_QUERY(jsonb'{"rec": [1,2,3]}', '$.rec' returning
test omit quotes );
SELECT * from JSON_QUERY(jsonb'{"rec": [1,2,3]}', '$.rec' returning
test omit quotes null on error);
SELECT * from JSON_QUERY(jsonb'{"rec": [1,2,3]}', '$.rec' returning
test null on error);
SELECT * from JSON_QUERY(jsonb'{"rec": [1,11]}', '$.rec' returning
test omit quotes);
SELECT * from JSON_QUERY(jsonb'{"rec": [2,2]}', '$.rec' returning test
omit quotes);
Many domain related tests seem not right.
like the following, i think it should just return null.
+SELECT JSON_QUERY(jsonb '{"a": 1}', '$.b' RETURNING sqljsonb_int_not_null);
+ERROR: domain sqljsonb_int_not_null does not allow null values
--another example
SELECT JSON_QUERY(jsonb '{"a": 1}', '$.b' RETURNING
sqljsonb_int_not_null null on error);
Maybe in node JsonCoercion, we don't need both via_io and
via_populate, but we can have one bool to indicate either call
InputFunctionCallSafe or json_populate_type in ExecEvalJsonCoercion.
based on v35.
Now I only applied from 0001 to 0007.
For {DEFAULT expression ON EMPTY} | {DEFAULT expression ON ERROR}
restrict DEFAULT expression be either Const node or FuncExpr node.
so these 3 SQL/JSON functions can be used in the btree expression index.
I made some big changes on the doc. (see attachment)
list (json_query, json_exists, json_value) as a new <section2> may be
a good idea.
follow these two links, we can see the difference.
only apply v35, 0001 to 0007: https://v35-functions-json-html.vercel.app
apply v35, 0001 to 0007 plus my changes:
https://html-starter-seven-pied.vercel.app
minor issues:
+ Note that if the <replaceable>path_expression</replaceable>
+ is <literal>strict</literal>, an error is generated if it yields no
+ items, provided the specified <literal>ON ERROR</literal> behavior is
+ <literal>ERROR</literal>.
how about something like this:
+ Note that if the <replaceable>path_expression</replaceable>
+ is <literal>strict</literal> and <literal>ON ERROR</literal>
behavior is specified
+ <literal>ERROR</literal>, an error is generated if it yields no
+ items
+ <note>
+ <para>
+ SQL/JSON path expression can currently only accept values of the
+ <type>jsonb</type> type, so it might be necessary to cast the
+ <replaceable>context_item</replaceable> argument of these functions to
+ <type>jsonb</type>.
+ </para>
+ </note>
here should it be "SQL/JSON query functions"?
Вложения
2024-01 Commitfest. Hi, This patch has a CF status of "Needs Review" [1], but it seems there were CFbot test failures last time it was run [2]. Please have a look and post an updated version if necessary. ====== [1] https://commitfest.postgresql.org/46/4377/ [2] https://cirrus-ci.com/github/postgresql-cfbot/postgresql/commitfest/46/4377 Kind Regards, Peter Smith.
I found two main issues regarding cocece SQL/JSON function output to
other data types.
* returning typmod influence the returning result of JSON_VALUE | JSON_QUERY.
* JSON_VALUE | JSON_QUERY handles returning type domains allowing null
and not allowing null inconsistencies.
in ExecInitJsonExprCoercion, there is IsA(coercion,JsonCoercion) or
not difference.
for the returning of (JSON_VALUE | JSON_QUERY),
"coercion" is a JsonCoercion or not is set in coerceJsonFuncExprOutput.
this influence returning type with typmod is not -1.
if set "coercion" as JsonCoercion Node then it may call the
InputFunctionCallSafe to do the coercion.
If not, it may call ExecInitFunc related code which is wrapped in
ExecEvalCoerceViaIOSafe.
for example:
SELECT JSON_QUERY(jsonb '[1,2]', '$' RETURNING char(3));
will ExecInitFunc, will init function bpchar(character, integer,
boolean). it will set the third argument to true.
so it will initiate related instructions like: `select
bpchar('[,2]',7,true); ` which in the end will make the result be
`[,2`
However, InputFunctionCallSafe cannot handle that.
simple demo:
create table t(a char(3));
--fail.
INSERT INTO t values ('test');
--ok
select 'test'::char(3);
however current ExecEvalCoerceViaIOSafe cannot handle omit quotes.
even if I made the changes, still not bullet-proof.
for example:
create domain char3_domain_not_null as char(3) NOT NULL;
create domain hello as text NOT NULL check (value = 'hello');
create domain int42 as int check (value = 42);
CREATE TYPE comp_domain_with_typmod AS (a char3_domain_not_null, b int42);
SELECT JSON_VALUE(jsonb'{"rec": "(abcd,42)"}', '$.rec' returning
comp_domain_with_typmod);
will return NULL
however
SELECT JSON_VALUE(jsonb'{"rec": "abcd"}', '$.rec' returning
char3_domain_not_null);
will return `abc`.
I made the modification, you can see the difference.
attached is test_coerce.sql is the test file.
test_coerce_only_v35.out is the test output of only applying v35 0001
to 0007 plus my previous changes[0].
test_coerce_v35_plus_change.out is the test output of applying to v35
0001 to 0007 plus changes (attachment) and previous changes[0].
[0] https://www.postgresql.org/message-id/CACJufxHo1VVk_0th3AsFxqdMgjaUDz6s0F7%2Bj9rYA3d%3DURw97A%40mail.gmail.com
Вложения
On Mon, Nov 27, 2023 at 9:06 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > At this point one thing that IMO we cannot afford to do, is stop feature > progress work on the name of parser speed. I mean, parser speed is > important, and we need to be mindful that what we add is reasonable. > But at some point we'll probably have to fix that by parsing > differently (a top-down parser, perhaps? Split the parser in smaller > pieces that each deal with subsets of the whole thing?) I was reorganizing some old backups and rediscovered an experiment I did four years ago when I had some extra time on my hands, to use a lexer generator that emits a state machine driven by code, rather than a table. It made parsing 12% faster on the above info-schema test, but only (maybe) 3% on parsing pgbench-like queries. My quick hack ended up a bit uglier and more verbose than Flex, but that could be improved, and in fact small components could be shared across the whole code base. I might work on it again; I might not.
Hi,
On Fri, Jan 19, 2024 at 7:46 PM jian he <jian.universality@gmail.com> wrote:
> play with domain types.
> in ExecEvalJsonCoercion, seems func json_populate_type cannot cope
> with domain type.
>
> tests:
> drop domain test;
> create domain test as int[] check ( array_length(value,1) =2 and
> (value[1] = 1 or value[2] = 2));
> SELECT * from JSON_QUERY(jsonb'{"rec": "{1,2,3}"}', '$.rec' returning
> test omit quotes);
> SELECT * from JSON_QUERY(jsonb'{"rec": "{1,11}"}', '$.rec' returning
> test keep quotes);
> SELECT * from JSON_QUERY(jsonb'{"rec": "{2,11}"}', '$.rec' returning
> test omit quotes error on error);
> SELECT * from JSON_QUERY(jsonb'{"rec": "{2,2}"}', '$.rec' returning
> test keep quotes error on error);
>
> SELECT * from JSON_QUERY(jsonb'{"rec": [1,2,3]}', '$.rec' returning
> test omit quotes );
> SELECT * from JSON_QUERY(jsonb'{"rec": [1,2,3]}', '$.rec' returning
> test omit quotes null on error);
> SELECT * from JSON_QUERY(jsonb'{"rec": [1,2,3]}', '$.rec' returning
> test null on error);
> SELECT * from JSON_QUERY(jsonb'{"rec": [1,11]}', '$.rec' returning
> test omit quotes);
> SELECT * from JSON_QUERY(jsonb'{"rec": [2,2]}', '$.rec' returning test
> omit quotes);
>
> Many domain related tests seem not right.
> like the following, i think it should just return null.
> +SELECT JSON_QUERY(jsonb '{"a": 1}', '$.b' RETURNING sqljsonb_int_not_null);
> +ERROR: domain sqljsonb_int_not_null does not allow null values
>
> --another example
> SELECT JSON_QUERY(jsonb '{"a": 1}', '$.b' RETURNING
> sqljsonb_int_not_null null on error);
Hmm, yes, I've thought the same thing, but the patch since it has
existed appears to have made an exception for the case when the
RETURNING type is a domain for some reason; I couldn't find any
mention of why in the old discussions. I suspect it might be because
a domain's constraints should always be enforced, irrespective of what
the SQL/JSON's ON ERROR says.
Though, I'm inclined to classify the domain constraint failure errors
into the same class as any other error as far as the ON ERROR clause
is concerned, so have adjusted the code to do so.
Please check if the attached looks fine.
> Maybe in node JsonCoercion, we don't need both via_io and
> via_populate, but we can have one bool to indicate either call
> InputFunctionCallSafe or json_populate_type in ExecEvalJsonCoercion.
I'm not sure if there's a way to set such a bool statically, because
the decision between calling input function or json_populate_type()
must be made at run-time based on whether the input jsonb datum is a
scalar or not. That said, I think we should ideally be able to always
use json_populate_type(), but it can't handle OMIT QUOTES for scalars
and I haven't been able to refactor it to do so
On Mon, Jan 22, 2024 at 9:00 AM jian he <jian.universality@gmail.com> wrote:
>
> based on v35.
> Now I only applied from 0001 to 0007.
> For {DEFAULT expression ON EMPTY} | {DEFAULT expression ON ERROR}
> restrict DEFAULT expression be either Const node or FuncExpr node.
> so these 3 SQL/JSON functions can be used in the btree expression index.
I'm not really excited about adding these restrictions into the
transformJsonFuncExpr() path. Index or any other code that wants to
put restrictions already have those in place, no need to add them
here. Moreover, by adding these restrictions, we might end up
preventing users from doing useful things with this like specify
column references. If there are semantic issues with allowing that,
we should discuss them.
> I made some big changes on the doc. (see attachment)
> list (json_query, json_exists, json_value) as a new <section2> may be
> a good idea.
>
> follow these two links, we can see the difference.
> only apply v35, 0001 to 0007: https://v35-functions-json-html.vercel.app
> apply v35, 0001 to 0007 plus my changes:
> https://html-starter-seven-pied.vercel.app
Thanks for your patch. I've adapted some of your proposed changes.
> minor issues:
> + Note that if the <replaceable>path_expression</replaceable>
> + is <literal>strict</literal>, an error is generated if it yields no
> + items, provided the specified <literal>ON ERROR</literal> behavior is
> + <literal>ERROR</literal>.
>
> how about something like this:
> + Note that if the <replaceable>path_expression</replaceable>
> + is <literal>strict</literal> and <literal>ON ERROR</literal>
> behavior is specified
> + <literal>ERROR</literal>, an error is generated if it yields no
> + items
Sure.
> + <note>
> + <para>
> + SQL/JSON path expression can currently only accept values of the
> + <type>jsonb</type> type, so it might be necessary to cast the
> + <replaceable>context_item</replaceable> argument of these functions to
> + <type>jsonb</type>.
> + </para>
> + </note>
> here should it be "SQL/JSON query functions"?
"path expressions" is not wrong but I agree that "query functions"
might be better, so changed. I've also mentioned that the restriction
arises from the fact that SQL/JSON path langage expects the input
document to be passed as jsonb.
On Mon, Jan 22, 2024 at 3:14 PM jian he <jian.universality@gmail.com> wrote:
> I found two main issues regarding cocece SQL/JSON function output to
> other data types.
> * returning typmod influence the returning result of JSON_VALUE | JSON_QUERY.
> * JSON_VALUE | JSON_QUERY handles returning type domains allowing null
> and not allowing null inconsistencies.
>
> in ExecInitJsonExprCoercion, there is IsA(coercion,JsonCoercion) or
> not difference.
> for the returning of (JSON_VALUE | JSON_QUERY),
> "coercion" is a JsonCoercion or not is set in coerceJsonFuncExprOutput.
>
> this influence returning type with typmod is not -1.
> if set "coercion" as JsonCoercion Node then it may call the
> InputFunctionCallSafe to do the coercion.
> If not, it may call ExecInitFunc related code which is wrapped in
> ExecEvalCoerceViaIOSafe.
>
> for example:
> SELECT JSON_QUERY(jsonb '[1,2]', '$' RETURNING char(3));
> will ExecInitFunc, will init function bpchar(character, integer,
> boolean). it will set the third argument to true.
> so it will initiate related instructions like: `select
> bpchar('[,2]',7,true); ` which in the end will make the result be
> `[,2`
> However, InputFunctionCallSafe cannot handle that.
> simple demo:
> create table t(a char(3));
> --fail.
> INSERT INTO t values ('test');
> --ok
> select 'test'::char(3);
>
> however current ExecEvalCoerceViaIOSafe cannot handle omit quotes.
>
> even if I made the changes, still not bullet-proof.
> for example:
> create domain char3_domain_not_null as char(3) NOT NULL;
> create domain hello as text NOT NULL check (value = 'hello');
> create domain int42 as int check (value = 42);
> CREATE TYPE comp_domain_with_typmod AS (a char3_domain_not_null, b int42);
>
> SELECT JSON_VALUE(jsonb'{"rec": "(abcd,42)"}', '$.rec' returning
> comp_domain_with_typmod);
> will return NULL
>
> however
> SELECT JSON_VALUE(jsonb'{"rec": "abcd"}', '$.rec' returning
> char3_domain_not_null);
> will return `abc`.
>
> I made the modification, you can see the difference.
> attached is test_coerce.sql is the test file.
> test_coerce_only_v35.out is the test output of only applying v35 0001
> to 0007 plus my previous changes[0].
> test_coerce_v35_plus_change.out is the test output of applying to v35
> 0001 to 0007 plus changes (attachment) and previous changes[0].
>
> [0] https://www.postgresql.org/message-id/CACJufxHo1VVk_0th3AsFxqdMgjaUDz6s0F7%2Bj9rYA3d%3DURw97A%40mail.gmail.com
I'll think about this tomorrow.
In the meantime, here are the updated/reorganized patches with the
following changes:
* I started having second thoughts about introducing
json_populate_type(), jspIsMutable, and JsonbUnquote() in commits
separate from the commit introducing the SQL/JSON query functions
patch where they are needed, so I moved them back into that patch. So
there are 2 fewer patches -- 0005, 0006 squashed into 0007.
* Boke the test file jsonb_sqljson into 2 files named
sqljson_queryfuncs and sqljson_jsontable. Also, the test files under
ECPG to sql_jsontable
* Some cosmetic improvements in the JSON_TABLE() patch
I'll push 0001-0004 tomorrow, barring objections.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
Вложения
- v36-0004-Add-jsonpath_exec-APIs-to-use-in-SQL-JSON-query-.patch
- v36-0002-Adjust-populate_record_field-to-handle-errors-so.patch
- v36-0001-Add-soft-error-handling-to-some-expression-nodes.patch
- v36-0003-Refactor-code-used-by-jsonpath-executor-to-fetch.patch
- v36-0005-SQL-JSON-query-functions.patch
- v36-0006-JSON_TABLE.patch
On Mon, Jan 22, 2024 at 10:28 PM Amit Langote <amitlangote09@gmail.com> wrote:
>
> > based on v35.
> > Now I only applied from 0001 to 0007.
> > For {DEFAULT expression ON EMPTY} | {DEFAULT expression ON ERROR}
> > restrict DEFAULT expression be either Const node or FuncExpr node.
> > so these 3 SQL/JSON functions can be used in the btree expression index.
>
> I'm not really excited about adding these restrictions into the
> transformJsonFuncExpr() path. Index or any other code that wants to
> put restrictions already have those in place, no need to add them
> here. Moreover, by adding these restrictions, we might end up
> preventing users from doing useful things with this like specify
> column references. If there are semantic issues with allowing that,
> we should discuss them.
>
after applying v36.
The following index creation and query operation works. I am not 100%
sure about these cases.
just want confirmation, sorry for bothering you....
drop table t;
create table t(a jsonb, b int);
insert into t select '{"hello":11}',1;
insert into t select '{"hello":12}',2;
CREATE INDEX t_idx2 ON t (JSON_query(a, '$.hello1' RETURNING int
default b + random() on error));
CREATE INDEX t_idx3 ON t (JSON_query(a, '$.hello1' RETURNING int
default random()::int on error));
SELECT JSON_query(a, '$.hello1' RETURNING int default ret_setint() on
error) from t;
SELECT JSON_query(a, '$.hello1' RETURNING int default sum(b) over()
on error) from t;
SELECT JSON_query(a, '$.hello1' RETURNING int default sum(b) on
error) from t group by a;
but the following cases will fail related to index and default expression.
create table zz(a int, b int);
CREATE INDEX zz_idx1 ON zz ( (b + random()::int));
create table ssss(a int, b int default ret_setint());
create table ssss(a int, b int default sum(b) over());
On 2024-Jan-18, Alvaro Herrera wrote: > > commands/explain.c (Hmm, I think this is a preexisting bug actually) > > > > 3893 18 : case T_TableFuncScan: > > 3894 18 : Assert(rte->rtekind == RTE_TABLEFUNC); > > 3895 18 : if (rte->tablefunc) > > 3896 0 : if (rte->tablefunc->functype == TFT_XMLTABLE) > > 3897 0 : objectname = "xmltable"; > > 3898 : else /* Must be TFT_JSON_TABLE */ > > 3899 0 : objectname = "json_table"; > > 3900 : else > > 3901 18 : objectname = NULL; > > 3902 18 : objecttag = "Table Function Name"; > > 3903 18 : break; > > Indeed I was completely wrong about this, and in order to gain coverage the only thing we needed was to add an EXPLAIN that uses the JSON format. I did that just now. I think your addition here works just fine. -- Álvaro Herrera 48°01'N 7°57'E — https://www.EnterpriseDB.com/
On Mon, Jan 22, 2024 at 11:46 PM jian he <jian.universality@gmail.com> wrote:
>
> On Mon, Jan 22, 2024 at 10:28 PM Amit Langote <amitlangote09@gmail.com> wrote:
> >
> > > based on v35.
> > > Now I only applied from 0001 to 0007.
> > > For {DEFAULT expression ON EMPTY} | {DEFAULT expression ON ERROR}
> > > restrict DEFAULT expression be either Const node or FuncExpr node.
> > > so these 3 SQL/JSON functions can be used in the btree expression index.
> >
> > I'm not really excited about adding these restrictions into the
> > transformJsonFuncExpr() path. Index or any other code that wants to
> > put restrictions already have those in place, no need to add them
> > here. Moreover, by adding these restrictions, we might end up
> > preventing users from doing useful things with this like specify
> > column references. If there are semantic issues with allowing that,
> > we should discuss them.
> >
>
> after applying v36.
> The following index creation and query operation works. I am not 100%
> sure about these cases.
> just want confirmation, sorry for bothering you....
>
> drop table t;
> create table t(a jsonb, b int);
> insert into t select '{"hello":11}',1;
> insert into t select '{"hello":12}',2;
> CREATE INDEX t_idx2 ON t (JSON_query(a, '$.hello1' RETURNING int
> default b + random() on error));
> CREATE INDEX t_idx3 ON t (JSON_query(a, '$.hello1' RETURNING int
> default random()::int on error));
> SELECT JSON_query(a, '$.hello1' RETURNING int default ret_setint() on
> error) from t;
I forgot to attach ret_setint defition.
create or replace function ret_setint() returns setof integer as
$$
begin
-- perform pg_sleep(0.1);
return query execute 'select 1 union all select 1';
end;
$$
language plpgsql IMMUTABLE;
-----------------------------------------
In the function transformJsonExprCommon, we have
`JsonExpr *jsexpr = makeNode(JsonExpr);`
then the following 2 assignments are not necessary.
/* Both set in the caller. */
jsexpr->result_coercion = NULL;
jsexpr->omit_quotes = false;
So I removed it.
JSON_VALUE OMIT QUOTES by default, so I set it accordingly.
I also changed coerceJsonFuncExprOutput accordingly
Вложения
On Tue, Jan 23, 2024 at 1:19 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > On 2024-Jan-18, Alvaro Herrera wrote: > > > commands/explain.c (Hmm, I think this is a preexisting bug actually) > > > > > > 3893 18 : case T_TableFuncScan: > > > 3894 18 : Assert(rte->rtekind == RTE_TABLEFUNC); > > > 3895 18 : if (rte->tablefunc) > > > 3896 0 : if (rte->tablefunc->functype == TFT_XMLTABLE) > > > 3897 0 : objectname = "xmltable"; > > > 3898 : else /* Must be TFT_JSON_TABLE */ > > > 3899 0 : objectname = "json_table"; > > > 3900 : else > > > 3901 18 : objectname = NULL; > > > 3902 18 : objecttag = "Table Function Name"; > > > 3903 18 : break; > > > > Indeed > > I was completely wrong about this, and in order to gain coverage the > only thing we needed was to add an EXPLAIN that uses the JSON format. > I did that just now. I think your addition here works just fine. I think we'd still need your RangeTblFunc.tablefunc_name in order for the new code (with JSON_TABLE) to be able to set objectname to either "XMLTABLE" or "JSON_TABLE", no? As you pointed out, rte->tablefunc is always NULL in ExplainTargetRel() due to setrefs.c setting it to NULL, so the JSON_TABLE additions to explain.c in my patch as they were won't work. I've included your patch in the attached set and adjusted the JSON_TABLE patch to set tablefunc_name in the parser. I had intended to push 0001-0004 today, but held off to add a SQL-callable testing function for the changes in 0002. On that note, I'm now not so sure about committing jsonpath_exec.c functions JsonPathExists/Query/Value() from their SQL/JSON counterparts, so inclined to squash that one into the SQL/JSON query functions patch from a testability standpoint. I haven't looked at Jian He's comments yet. -- Thanks, Amit Langote EDB: http://www.enterprisedb.com
Вложения
- v37-0006-Show-function-name-in-TableFuncScan.patch
- v37-0004-Add-jsonpath_exec-APIs-to-use-in-SQL-JSON-query-.patch
- v37-0003-Refactor-code-used-by-jsonpath-executor-to-fetch.patch
- v37-0007-JSON_TABLE.patch
- v37-0005-SQL-JSON-query-functions.patch
- v37-0001-Add-soft-error-handling-to-some-expression-nodes.patch
- v37-0002-Adjust-populate_record_field-to-handle-errors-so.patch
On Tue, Jan 23, 2024 at 10:46 PM Amit Langote <amitlangote09@gmail.com> wrote:
> On Tue, Jan 23, 2024 at 1:19 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote:
> > On 2024-Jan-18, Alvaro Herrera wrote:
> > > > commands/explain.c (Hmm, I think this is a preexisting bug actually)
> > > >
> > > > 3893 18 : case T_TableFuncScan:
> > > > 3894 18 : Assert(rte->rtekind == RTE_TABLEFUNC);
> > > > 3895 18 : if (rte->tablefunc)
> > > > 3896 0 : if (rte->tablefunc->functype == TFT_XMLTABLE)
> > > > 3897 0 : objectname = "xmltable";
> > > > 3898 : else /* Must be TFT_JSON_TABLE */
> > > > 3899 0 : objectname = "json_table";
> > > > 3900 : else
> > > > 3901 18 : objectname = NULL;
> > > > 3902 18 : objecttag = "Table Function Name";
> > > > 3903 18 : break;
> > >
> > > Indeed
> >
> > I was completely wrong about this, and in order to gain coverage the
> > only thing we needed was to add an EXPLAIN that uses the JSON format.
> > I did that just now. I think your addition here works just fine.
>
> I think we'd still need your RangeTblFunc.tablefunc_name in order for
> the new code (with JSON_TABLE) to be able to set objectname to either
> "XMLTABLE" or "JSON_TABLE", no?
>
> As you pointed out, rte->tablefunc is always NULL in
> ExplainTargetRel() due to setrefs.c setting it to NULL, so the
> JSON_TABLE additions to explain.c in my patch as they were won't work.
> I've included your patch in the attached set and adjusted the
> JSON_TABLE patch to set tablefunc_name in the parser.
>
> I had intended to push 0001-0004 today, but held off to add a
> SQL-callable testing function for the changes in 0002. On that note,
> I'm now not so sure about committing jsonpath_exec.c functions
> JsonPathExists/Query/Value() from their SQL/JSON counterparts, so
> inclined to squash that one into the SQL/JSON query functions patch
> from a testability standpoint.
Pushed 0001-0003 for now.
Rebased patches attached. I merged 0004 into the query functions
patch after all.
> I haven't looked at Jian He's comments yet.
See below...
On Tue, Jan 23, 2024 at 12:46 AM jian he <jian.universality@gmail.com> wrote:
> On Mon, Jan 22, 2024 at 10:28 PM Amit Langote <amitlangote09@gmail.com> wrote:
> >
> > > based on v35.
> > > Now I only applied from 0001 to 0007.
> > > For {DEFAULT expression ON EMPTY} | {DEFAULT expression ON ERROR}
> > > restrict DEFAULT expression be either Const node or FuncExpr node.
> > > so these 3 SQL/JSON functions can be used in the btree expression index.
> >
> > I'm not really excited about adding these restrictions into the
> > transformJsonFuncExpr() path. Index or any other code that wants to
> > put restrictions already have those in place, no need to add them
> > here. Moreover, by adding these restrictions, we might end up
> > preventing users from doing useful things with this like specify
> > column references. If there are semantic issues with allowing that,
> > we should discuss them.
> >
>
> after applying v36.
> The following index creation and query operation works. I am not 100%
> sure about these cases.
> just want confirmation, sorry for bothering you....
No worries; I really appreciate your testing and suggestions.
> drop table t;
> create table t(a jsonb, b int);
> insert into t select '{"hello":11}',1;
> insert into t select '{"hello":12}',2;
> CREATE INDEX t_idx2 ON t (JSON_query(a, '$.hello1' RETURNING int
> default b + random() on error));
> CREATE INDEX t_idx3 ON t (JSON_query(a, '$.hello1' RETURNING int
> default random()::int on error));
> create or replace function ret_setint() returns setof integer as
> $$
> begin
> -- perform pg_sleep(0.1);
> return query execute 'select 1 union all select 1';
> end;
> $$
> language plpgsql IMMUTABLE;
> SELECT JSON_query(a, '$.hello1' RETURNING int default ret_setint() on
> error) from t;
> SELECT JSON_query(a, '$.hello1' RETURNING int default sum(b) over()
> on error) from t;
> SELECT JSON_query(a, '$.hello1' RETURNING int default sum(b) on
> error) from t group by a;
>
> but the following cases will fail related to index and default expression.
> create table zz(a int, b int);
> CREATE INDEX zz_idx1 ON zz ( (b + random()::int));
> create table ssss(a int, b int default ret_setint());
> create table ssss(a int, b int default sum(b) over());
I think your suggestion to add restrictions on what is allowed for
DEFAULT makes sense. Also, immutability shouldn't be checked in
transformJsonBehavior(), but in contain_mutable_functions() as done in
the attached. Added some tests too.
I still need to take a look at your other report regarding typmod but
I'm out of energy today.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
Вложения
On Wed, Jan 24, 2024 at 10:11 PM Amit Langote <amitlangote09@gmail.com> wrote:
> On Tue, Jan 23, 2024 at 12:46 AM jian he <jian.universality@gmail.com> wrote:
> > On Mon, Jan 22, 2024 at 10:28 PM Amit Langote <amitlangote09@gmail.com> wrote:
> > >
> > > > based on v35.
> > > > Now I only applied from 0001 to 0007.
> > > > For {DEFAULT expression ON EMPTY} | {DEFAULT expression ON ERROR}
> > > > restrict DEFAULT expression be either Const node or FuncExpr node.
> > > > so these 3 SQL/JSON functions can be used in the btree expression index.
> > >
> > > I'm not really excited about adding these restrictions into the
> > > transformJsonFuncExpr() path. Index or any other code that wants to
> > > put restrictions already have those in place, no need to add them
> > > here. Moreover, by adding these restrictions, we might end up
> > > preventing users from doing useful things with this like specify
> > > column references. If there are semantic issues with allowing that,
> > > we should discuss them.
> > >
> >
> > after applying v36.
> > The following index creation and query operation works. I am not 100%
> > sure about these cases.
> > just want confirmation, sorry for bothering you....
>
> No worries; I really appreciate your testing and suggestions.
>
> > drop table t;
> > create table t(a jsonb, b int);
> > insert into t select '{"hello":11}',1;
> > insert into t select '{"hello":12}',2;
> > CREATE INDEX t_idx2 ON t (JSON_query(a, '$.hello1' RETURNING int
> > default b + random() on error));
> > CREATE INDEX t_idx3 ON t (JSON_query(a, '$.hello1' RETURNING int
> > default random()::int on error));
> > create or replace function ret_setint() returns setof integer as
> > $$
> > begin
> > -- perform pg_sleep(0.1);
> > return query execute 'select 1 union all select 1';
> > end;
> > $$
> > language plpgsql IMMUTABLE;
> > SELECT JSON_query(a, '$.hello1' RETURNING int default ret_setint() on
> > error) from t;
> > SELECT JSON_query(a, '$.hello1' RETURNING int default sum(b) over()
> > on error) from t;
> > SELECT JSON_query(a, '$.hello1' RETURNING int default sum(b) on
> > error) from t group by a;
> >
> > but the following cases will fail related to index and default expression.
> > create table zz(a int, b int);
> > CREATE INDEX zz_idx1 ON zz ( (b + random()::int));
> > create table ssss(a int, b int default ret_setint());
> > create table ssss(a int, b int default sum(b) over());
>
> I think your suggestion to add restrictions on what is allowed for
> DEFAULT makes sense. Also, immutability shouldn't be checked in
> transformJsonBehavior(), but in contain_mutable_functions() as done in
> the attached. Added some tests too.
>
> I still need to take a look at your other report regarding typmod but
> I'm out of energy today.
The attached updated patch should address one of the concerns --
JSON_QUERY() should now work appropriately with RETURNING type with
typmod whether or OMIT QUOTES is specified.
But I wasn't able to address the problems with RETURNING
record_type_with_typmod, that is, the following example you shared
upthread:
create domain char3_domain_not_null as char(3) NOT NULL;
create domain hello as text not null check (value = 'hello');
create domain int42 as int check (value = 42);
create type comp_domain_with_typmod AS (a char3_domain_not_null, b int42);
select json_value(jsonb'{"rec": "(abcd,42)"}', '$.rec' returning
comp_domain_with_typmod);
json_value
------------
(1 row)
select json_value(jsonb'{"rec": "(abcd,42)"}', '$.rec' returning
comp_domain_with_typmod error on error);
ERROR: value too long for type character(3)
select json_value(jsonb'{"rec": "abcd"}', '$.rec' returning
char3_domain_not_null error on error);
json_value
------------
abc
(1 row)
The problem with returning comp_domain_with_typmod from json_value()
seems to be that it's using a text-to-record CoerceViaIO expression
picked from JsonExpr.item_coercions, which behaves differently than
the expression tree that the following uses:
select ('abcd', 42)::comp_domain_with_typmod;
row
----------
(abc,42)
(1 row)
I don't see a good way to make RETURNING record_type_with_typmod to
work cleanly, so I am inclined to either simply disallow the feature
or live with the limitation.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
Вложения
On 9.16.4. JSON_TABLE ` name type FORMAT JSON [ENCODING UTF8] [ PATH json_path_specification ] Inserts a composite SQL/JSON item into the output row ` i am not sure "Inserts a composite SQL/JSON item into the output row" I think it means, for any type's typecategory is TYPCATEGORY_STRING, if FORMAT JSON is specified explicitly, the output value (text type) will be legal json type representation. I also did a minor refactor on JSON_VALUE_OP, jsexpr->omit_quotes.
Вложения
On Thu, Jan 25, 2024 at 6:09 PM Amit Langote <amitlangote09@gmail.com> wrote:
> On Wed, Jan 24, 2024 at 10:11 PM Amit Langote <amitlangote09@gmail.com> wrote:
> > I still need to take a look at your other report regarding typmod but
> > I'm out of energy today.
>
> The attached updated patch should address one of the concerns --
> JSON_QUERY() should now work appropriately with RETURNING type with
> typmod whether or OMIT QUOTES is specified.
>
> But I wasn't able to address the problems with RETURNING
> record_type_with_typmod, that is, the following example you shared
> upthread:
>
> create domain char3_domain_not_null as char(3) NOT NULL;
> create domain hello as text not null check (value = 'hello');
> create domain int42 as int check (value = 42);
> create type comp_domain_with_typmod AS (a char3_domain_not_null, b int42);
> select json_value(jsonb'{"rec": "(abcd,42)"}', '$.rec' returning
> comp_domain_with_typmod);
> json_value
> ------------
>
> (1 row)
>
> select json_value(jsonb'{"rec": "(abcd,42)"}', '$.rec' returning
> comp_domain_with_typmod error on error);
> ERROR: value too long for type character(3)
>
> select json_value(jsonb'{"rec": "abcd"}', '$.rec' returning
> char3_domain_not_null error on error);
> json_value
> ------------
> abc
> (1 row)
>
> The problem with returning comp_domain_with_typmod from json_value()
> seems to be that it's using a text-to-record CoerceViaIO expression
> picked from JsonExpr.item_coercions, which behaves differently than
> the expression tree that the following uses:
>
> select ('abcd', 42)::comp_domain_with_typmod;
> row
> ----------
> (abc,42)
> (1 row)
Oh, it hadn't occurred to me to check what trying to coerce a "string"
containing the record literal would do:
select '(''abcd'', 42)'::comp_domain_with_typmod;
ERROR: value too long for type character(3)
LINE 1: select '(''abcd'', 42)'::comp_domain_with_typmod;
which is the same thing as what the JSON_QUERY() and JSON_VALUE() are
running into. So, it might be fair to think that the error is not a
limitation of the SQL/JSON patch but an underlying behavior that it
has to accept as is.
--
Thanks, Amit Langote
EDB: http://www.enterprisedb.com
On Thu, Jan 25, 2024 at 7:54 PM Amit Langote <amitlangote09@gmail.com> wrote:
>
> >
> > The problem with returning comp_domain_with_typmod from json_value()
> > seems to be that it's using a text-to-record CoerceViaIO expression
> > picked from JsonExpr.item_coercions, which behaves differently than
> > the expression tree that the following uses:
> >
> > select ('abcd', 42)::comp_domain_with_typmod;
> > row
> > ----------
> > (abc,42)
> > (1 row)
>
> Oh, it hadn't occurred to me to check what trying to coerce a "string"
> containing the record literal would do:
>
> select '(''abcd'', 42)'::comp_domain_with_typmod;
> ERROR: value too long for type character(3)
> LINE 1: select '(''abcd'', 42)'::comp_domain_with_typmod;
>
> which is the same thing as what the JSON_QUERY() and JSON_VALUE() are
> running into. So, it might be fair to think that the error is not a
> limitation of the SQL/JSON patch but an underlying behavior that it
> has to accept as is.
>
Hi, I reconciled with these cases.
What bugs me now is the first query of the following 4 cases (for comparison).
SELECT JSON_QUERY(jsonb '[1,2]', '$' RETURNING char(3) omit quotes);
SELECT JSON_QUERY(jsonb '[1,2]', '$' RETURNING char(3) keep quotes);
SELECT JSON_QUERY(jsonb '[1,2]', '$' RETURNING text omit quotes);
SELECT JSON_QUERY(jsonb '[1,2]', '$' RETURNING text keep quotes);
I did some minor refactoring on the function coerceJsonFuncExprOutput.
it will make the following queries return null instead of error. NULL
is the return of json_value.
SELECT JSON_QUERY(jsonb '"123"', '$' RETURNING int2);
SELECT JSON_QUERY(jsonb '"123"', '$' RETURNING int4);
SELECT JSON_QUERY(jsonb '"123"', '$' RETURNING int8);
SELECT JSON_QUERY(jsonb '"123"', '$' RETURNING bool);
SELECT JSON_QUERY(jsonb '"123"', '$' RETURNING numeric);
SELECT JSON_QUERY(jsonb '"123"', '$' RETURNING real);
SELECT JSON_QUERY(jsonb '"123"', '$' RETURNING float8);
Вложения
Hi. minor issues. I am wondering do we need add `pg_node_attr(query_jumble_ignore)` to some of our created structs in src/include/nodes/parsenodes.h in v39-0001-Add-SQL-JSON-query-functions.patch diff --git a/src/backend/parser/parse_jsontable.c b/src/backend/parser/parse_jsontable.c new file mode 100644 index 0000000000..25b8204dc6 --- /dev/null +++ b/src/backend/parser/parse_jsontable.c @@ -0,0 +1,718 @@ +/*------------------------------------------------------------------------- + * + * parse_jsontable.c + * parsing of JSON_TABLE + * + * Portions Copyright (c) 1996-2022, PostgreSQL Global Development Group + * Portions Copyright (c) 1994, Regents of the University of California + * + * + * IDENTIFICATION + * src/backend/parser/parse_jsontable.c + * + *------------------------------------------------------------------------- + */ 2022 should change to 2024.
based on this query: begin; SET LOCAL TIME ZONE 10.5; with cte(s) as (select jsonb '"2023-08-15 12:34:56 +05:30"') select JSON_QUERY(s, '$.timestamp_tz()')::text,'+10.5'::text, 'timestamp_tz'::text from cte union all select JSON_QUERY(s, '$.time()')::text,'+10.5'::text, 'time'::text from cte union all select JSON_QUERY(s, '$.timestamp()')::text,'+10.5'::text, 'timestamp'::text from cte union all select JSON_QUERY(s, '$.date()')::text,'+10.5'::text, 'date'::text from cte union all select JSON_QUERY(s, '$.time_tz()')::text,'+10.5'::text, 'time_tz'::text from cte; SET LOCAL TIME ZONE -8; with cte(s) as (select jsonb '"2023-08-15 12:34:56 +05:30"') select JSON_QUERY(s, '$.timestamp_tz()')::text,'+10.5'::text, 'timestamp_tz'::text from cte union all select JSON_QUERY(s, '$.time()')::text,'+10.5'::text, 'time'::text from cte union all select JSON_QUERY(s, '$.timestamp()')::text,'+10.5'::text, 'timestamp'::text from cte union all select JSON_QUERY(s, '$.date()')::text,'+10.5'::text, 'date'::text from cte union all select JSON_QUERY(s, '$.time_tz()')::text,'+10.5'::text, 'time_tz'::text from cte; commit; I made some changes on jspIsMutableWalker. various new jsonpath methods added: https://git.postgresql.org/cgit/postgresql.git/commit/?id=66ea94e8e606529bb334515f388c62314956739e so we need to change jspIsMutableWalker accordingly. based on v39.
Вложения
On Thu, Jan 25, 2024 at 10:39 PM jian he <jian.universality@gmail.com> wrote:
>
> On Thu, Jan 25, 2024 at 7:54 PM Amit Langote <amitlangote09@gmail.com> wrote:
> >
> > >
> > > The problem with returning comp_domain_with_typmod from json_value()
> > > seems to be that it's using a text-to-record CoerceViaIO expression
> > > picked from JsonExpr.item_coercions, which behaves differently than
> > > the expression tree that the following uses:
> > >
> > > select ('abcd', 42)::comp_domain_with_typmod;
> > > row
> > > ----------
> > > (abc,42)
> > > (1 row)
> >
> > Oh, it hadn't occurred to me to check what trying to coerce a "string"
> > containing the record literal would do:
> >
> > select '(''abcd'', 42)'::comp_domain_with_typmod;
> > ERROR: value too long for type character(3)
> > LINE 1: select '(''abcd'', 42)'::comp_domain_with_typmod;
> >
> > which is the same thing as what the JSON_QUERY() and JSON_VALUE() are
> > running into. So, it might be fair to think that the error is not a
> > limitation of the SQL/JSON patch but an underlying behavior that it
> > has to accept as is.
> >
>
> Hi, I reconciled with these cases.
> What bugs me now is the first query of the following 4 cases (for comparison).
> SELECT JSON_QUERY(jsonb '[1,2]', '$' RETURNING char(3) omit quotes);
> SELECT JSON_QUERY(jsonb '[1,2]', '$' RETURNING char(3) keep quotes);
> SELECT JSON_QUERY(jsonb '[1,2]', '$' RETURNING text omit quotes);
> SELECT JSON_QUERY(jsonb '[1,2]', '$' RETURNING text keep quotes);
>
based on v39.
in ExecEvalJsonCoercion
coercion->targettypmod related function calls:
json_populate_type calls populate_record_field, then populate_scalar,
later will eventually call InputFunctionCallSafe.
so I make the following change:
--- a/src/backend/executor/execExprInterp.c
+++ b/src/backend/executor/execExprInterp.c
@@ -4533,7 +4533,7 @@ ExecEvalJsonCoercion(ExprState *state, ExprEvalStep *op,
* deed ourselves by calling the input function, that is, after removing
* the quotes.
*/
- if (jb && JB_ROOT_IS_SCALAR(jb) && coercion->omit_quotes)
+ if ((jb && JB_ROOT_IS_SCALAR(jb) && coercion->omit_quotes) ||
coercion->targettypmod != -1)
now the following two return the same result: `[1,`
SELECT JSON_QUERY(jsonb '[1,2]', '$' RETURNING char(3) omit quotes);
SELECT JSON_QUERY(jsonb '[1,2]', '$' RETURNING char(3) keep quotes);
This part is already committed.
ereport(ERROR,
(errcode(ERRCODE_UNDEFINED_OBJECT),
errmsg("could not find jsonpath variable \"%s\"",
pnstrdup(varName, varNameLength))));
but, you can simply use:
ereport(ERROR,
(errcode(ERRCODE_UNDEFINED_OBJECT),
errmsg("could not find jsonpath variable \"%s\"",varName)));
maybe not worth the trouble.
I kind of want to know, using `pnstrdup`, when the malloc related
memory will be freed?
json_query and json_query doc explanation is kind of crammed together.
Do you think it's a good idea to use </listitem> and </itemizedlist>?
it will look like bullet points. but the distance between the bullet
point and the first text in the same line is a little bit long, so it
may not look elegant.
I've attached the picture, json_query is using `</listitem> and
</itemizedlist>`, json_value is as of the v39.
other than this and previous points, v39, 0001 looks good to go.
Вложения
{kind=link}
Hi Jian,
Thanks for the reviews and sorry for the late reply. Replying to all
emails in one.
On Thu, Jan 25, 2024 at 11:39 PM jian he <jian.universality@gmail.com> wrote:
> On Thu, Jan 25, 2024 at 7:54 PM Amit Langote <amitlangote09@gmail.com> wrote:
> > > The problem with returning comp_domain_with_typmod from json_value()
> > > seems to be that it's using a text-to-record CoerceViaIO expression
> > > picked from JsonExpr.item_coercions, which behaves differently than
> > > the expression tree that the following uses:
> > >
> > > select ('abcd', 42)::comp_domain_with_typmod;
> > > row
> > > ----------
> > > (abc,42)
> > > (1 row)
> >
> > Oh, it hadn't occurred to me to check what trying to coerce a "string"
> > containing the record literal would do:
> >
> > select '(''abcd'', 42)'::comp_domain_with_typmod;
> > ERROR: value too long for type character(3)
> > LINE 1: select '(''abcd'', 42)'::comp_domain_with_typmod;
> >
> > which is the same thing as what the JSON_QUERY() and JSON_VALUE() are
> > running into. So, it might be fair to think that the error is not a
> > limitation of the SQL/JSON patch but an underlying behavior that it
> > has to accept as is.
>
> Hi, I reconciled with these cases.
> What bugs me now is the first query of the following 4 cases (for comparison).
> SELECT JSON_QUERY(jsonb '[1,2]', '$' RETURNING char(3) omit quotes);
> SELECT JSON_QUERY(jsonb '[1,2]', '$' RETURNING char(3) keep quotes);
> SELECT JSON_QUERY(jsonb '[1,2]', '$' RETURNING text omit quotes);
> SELECT JSON_QUERY(jsonb '[1,2]', '$' RETURNING text keep quotes);
Fixed:
SELECT JSON_QUERY(jsonb '"[1,2]"', '$' RETURNING char(3) omit quotes);
json_query
------------
[1,
(1 row)
SELECT JSON_QUERY(jsonb '"[1,2]"', '$' RETURNING char(3) keep quotes);
json_query
------------
"[1
(1 row)
SELECT JSON_QUERY(jsonb '"[1,2]"', '$' RETURNING text omit quotes);
json_query
------------
[1,2]
(1 row)
SELECT JSON_QUERY(jsonb '"[1,2]"', '$' RETURNING text keep quotes);
json_query
------------
"[1,2]"
(1 row)
I didn't go with your proposed solution to check targettypmod in
ExecEvalJsonCoercion() though.
> I did some minor refactoring on the function coerceJsonFuncExprOutput.
> it will make the following queries return null instead of error. NULL
> is the return of json_value.
>
> SELECT JSON_QUERY(jsonb '"123"', '$' RETURNING int2);
> SELECT JSON_QUERY(jsonb '"123"', '$' RETURNING int4);
> SELECT JSON_QUERY(jsonb '"123"', '$' RETURNING int8);
> SELECT JSON_QUERY(jsonb '"123"', '$' RETURNING bool);
> SELECT JSON_QUERY(jsonb '"123"', '$' RETURNING numeric);
> SELECT JSON_QUERY(jsonb '"123"', '$' RETURNING real);
> SELECT JSON_QUERY(jsonb '"123"', '$' RETURNING float8);
I didn't really want to add an exception in the parser for these
specific types, but I agree that it's not great that the current code
doesn't respect the default NULL ON ERROR behavior, so I've adopted
your fix. I'm not sure if we'll do so in the future but the code can
be removed if we someday make the non-IO cast functions handle errors
softly too.
On Wed, Jan 31, 2024 at 11:52 PM jian he <jian.universality@gmail.com> wrote:
>
> Hi.
> minor issues.
> I am wondering do we need add `pg_node_attr(query_jumble_ignore)`
> to some of our created structs in src/include/nodes/parsenodes.h in
> v39-0001-Add-SQL-JSON-query-functions.patch
We haven't added those to the node structs of other SQL/JSON
functions, so I'm inclined to skip adding them in this patch.
> diff --git a/src/backend/parser/parse_jsontable.c
> b/src/backend/parser/parse_jsontable.c
> new file mode 100644
> index 0000000000..25b8204dc6
> --- /dev/null
> +++ b/src/backend/parser/parse_jsontable.c
> @@ -0,0 +1,718 @@
> +/*-------------------------------------------------------------------------
> + *
> + * parse_jsontable.c
> + * parsing of JSON_TABLE
> + *
> + * Portions Copyright (c) 1996-2022, PostgreSQL Global Development Group
> + * Portions Copyright (c) 1994, Regents of the University of California
> + *
> + *
> + * IDENTIFICATION
> + * src/backend/parser/parse_jsontable.c
> + *
> + *-------------------------------------------------------------------------
> + */
> 2022 should change to 2024.
Oops, fixed.
On Mon, Feb 5, 2024 at 9:28 PM jian he <jian.universality@gmail.com> wrote:
>
> based on this query:
> begin;
> SET LOCAL TIME ZONE 10.5;
> with cte(s) as (select jsonb '"2023-08-15 12:34:56 +05:30"')
> select JSON_QUERY(s, '$.timestamp_tz()')::text,'+10.5'::text,
> 'timestamp_tz'::text from cte
> union all
> select JSON_QUERY(s, '$.time()')::text,'+10.5'::text, 'time'::text from cte
> union all
> select JSON_QUERY(s, '$.timestamp()')::text,'+10.5'::text,
> 'timestamp'::text from cte
> union all
> select JSON_QUERY(s, '$.date()')::text,'+10.5'::text, 'date'::text from cte
> union all
> select JSON_QUERY(s, '$.time_tz()')::text,'+10.5'::text,
> 'time_tz'::text from cte;
>
> SET LOCAL TIME ZONE -8;
> with cte(s) as (select jsonb '"2023-08-15 12:34:56 +05:30"')
> select JSON_QUERY(s, '$.timestamp_tz()')::text,'+10.5'::text,
> 'timestamp_tz'::text from cte
> union all
> select JSON_QUERY(s, '$.time()')::text,'+10.5'::text, 'time'::text from cte
> union all
> select JSON_QUERY(s, '$.timestamp()')::text,'+10.5'::text,
> 'timestamp'::text from cte
> union all
> select JSON_QUERY(s, '$.date()')::text,'+10.5'::text, 'date'::text from cte
> union all
> select JSON_QUERY(s, '$.time_tz()')::text,'+10.5'::text,
> 'time_tz'::text from cte;
> commit;
>
> I made some changes on jspIsMutableWalker.
> various new jsonpath methods added:
> https://git.postgresql.org/cgit/postgresql.git/commit/?id=66ea94e8e606529bb334515f388c62314956739e
> so we need to change jspIsMutableWalker accordingly.
Thanks for the heads up about that, merged.
On Wed, Feb 14, 2024 at 9:00 AM jian he <jian.universality@gmail.com> wrote:
>
> This part is already committed.
> ereport(ERROR,
> (errcode(ERRCODE_UNDEFINED_OBJECT),
> errmsg("could not find jsonpath variable \"%s\"",
> pnstrdup(varName, varNameLength))));
>
> but, you can simply use:
> ereport(ERROR,
> (errcode(ERRCODE_UNDEFINED_OBJECT),
> errmsg("could not find jsonpath variable \"%s\"",varName)));
>
> maybe not worth the trouble.
Yeah, maybe the pnstrdup is unnecessary. I'm inclined to leave that
alone for now and fix it later, not as part of this patch.
> I kind of want to know, using `pnstrdup`, when the malloc related
> memory will be freed?
That particular pnstrdup() will allocate somewhere in the
ExecutorState memory context, which gets reset during the transaction
abort processing, releasing that memory.
> json_query and json_query doc explanation is kind of crammed together.
> Do you think it's a good idea to use </listitem> and </itemizedlist>?
> it will look like bullet points. but the distance between the bullet
> point and the first text in the same line is a little bit long, so it
> may not look elegant.
> I've attached the picture, json_query is using `</listitem> and
> </itemizedlist>`, json_value is as of the v39.
Yeah, the bullet point list layout looks kind of neat, and is not
unprecedented because we have a list in the description of
json_poulate_record() for one. Though I wasn't able to come up with a
good breakdown of the points into sentences of appropriate length.
I'm inclined to leave that beautification project to another day.
> other than this and previous points, v39, 0001 looks good to go.
I've attached the updated patches. I would like to get 0001 committed
after I spent a couple more days staring at it.
Alvaro, do you still think that 0002 is a good idea and would you like
to push it yourself?
--
Thanks, Amit Langote
Вложения
Op 3/4/24 om 10:40 schreef Amit Langote: > Hi Jian, > > Thanks for the reviews and sorry for the late reply. Replying to all > emails in one. > [v40-0001-Add-SQL-JSON-query-functions.patch] > [v40-0002-Show-function-name-in-TableFuncScan.patch] > [v40-0003-JSON_TABLE.patch] In my hands (applying with patch), the patches, esp. 0001, do not apply. But I see the cfbot builds without problem so maybe just ignore these FAILED lines. Better get them merged - so I can test there... Erik checking file doc/src/sgml/func.sgml checking file src/backend/catalog/sql_features.txt checking file src/backend/executor/execExpr.c Hunk #1 succeeded at 48 with fuzz 2 (offset -1 lines). Hunk #2 succeeded at 88 (offset -1 lines). Hunk #3 succeeded at 2419 (offset -1 lines). Hunk #4 succeeded at 4195 (offset -1 lines). checking file src/backend/executor/execExprInterp.c Hunk #1 succeeded at 72 (offset -1 lines). Hunk #2 succeeded at 180 (offset -1 lines). Hunk #3 succeeded at 485 (offset -1 lines). Hunk #4 succeeded at 1560 (offset -1 lines). Hunk #5 succeeded at 4242 (offset -1 lines). checking file src/backend/jit/llvm/llvmjit_expr.c checking file src/backend/jit/llvm/llvmjit_types.c checking file src/backend/nodes/makefuncs.c Hunk #1 succeeded at 856 (offset -1 lines). checking file src/backend/nodes/nodeFuncs.c Hunk #1 succeeded at 233 (offset -1 lines). Hunk #2 succeeded at 517 (offset -1 lines). Hunk #3 succeeded at 1019 (offset -1 lines). Hunk #4 succeeded at 1276 (offset -1 lines). Hunk #5 succeeded at 1617 (offset -1 lines). Hunk #6 succeeded at 2381 (offset -1 lines). Hunk #7 succeeded at 3429 (offset -1 lines). Hunk #8 succeeded at 4164 (offset -1 lines). checking file src/backend/optimizer/path/costsize.c Hunk #1 succeeded at 4878 (offset -1 lines). checking file src/backend/optimizer/util/clauses.c Hunk #1 succeeded at 50 (offset -3 lines). Hunk #2 succeeded at 415 (offset -3 lines). checking file src/backend/parser/gram.y checking file src/backend/parser/parse_expr.c checking file src/backend/parser/parse_target.c Hunk #1 succeeded at 1988 (offset -1 lines). checking file src/backend/utils/adt/formatting.c Hunk #1 succeeded at 4465 (offset -1 lines). checking file src/backend/utils/adt/jsonb.c Hunk #1 succeeded at 2159 (offset -4 lines). checking file src/backend/utils/adt/jsonfuncs.c checking file src/backend/utils/adt/jsonpath.c Hunk #1 FAILED at 68. Hunk #2 succeeded at 1239 (offset -1 lines). 1 out of 2 hunks FAILED checking file src/backend/utils/adt/jsonpath_exec.c Hunk #1 succeeded at 229 (offset -5 lines). Hunk #2 succeeded at 2866 (offset -5 lines). Hunk #3 succeeded at 3751 (offset -5 lines). checking file src/backend/utils/adt/ruleutils.c Hunk #1 succeeded at 474 (offset -1 lines). Hunk #2 succeeded at 518 (offset -1 lines). Hunk #3 succeeded at 8303 (offset -1 lines). Hunk #4 succeeded at 8475 (offset -1 lines). Hunk #5 succeeded at 8591 (offset -1 lines). Hunk #6 succeeded at 9808 (offset -1 lines). Hunk #7 succeeded at 9858 (offset -1 lines). Hunk #8 succeeded at 10039 (offset -1 lines). Hunk #9 succeeded at 10909 (offset -1 lines). checking file src/include/executor/execExpr.h checking file src/include/nodes/execnodes.h checking file src/include/nodes/makefuncs.h checking file src/include/nodes/parsenodes.h checking file src/include/nodes/primnodes.h checking file src/include/parser/kwlist.h checking file src/include/utils/formatting.h checking file src/include/utils/jsonb.h checking file src/include/utils/jsonfuncs.h checking file src/include/utils/jsonpath.h checking file src/interfaces/ecpg/preproc/ecpg.trailer checking file src/test/regress/expected/sqljson_queryfuncs.out checking file src/test/regress/parallel_schedule checking file src/test/regress/sql/sqljson_queryfuncs.sql checking file src/tools/pgindent/typedefs.list
On 2024-Mar-04, Erik Rijkers wrote: > In my hands (applying with patch), the patches, esp. 0001, do not apply. > But I see the cfbot builds without problem so maybe just ignore these FAILED > lines. Better get them merged - so I can test there... It's because of dbbca2cf299b. It should apply cleanly if you do "git checkout dbbca2cf299b^" first ... That commit is so recent that evidently the cfbot hasn't had a chance to try this patch again since it went in, which is why it's still green. -- Álvaro Herrera 48°01'N 7°57'E — https://www.EnterpriseDB.com/ "If you have nothing to say, maybe you need just the right tool to help you not say it." (New York Times, about Microsoft PowerPoint)
On Tue, Mar 5, 2024 at 12:03 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > On 2024-Mar-04, Erik Rijkers wrote: > > > In my hands (applying with patch), the patches, esp. 0001, do not apply. > > But I see the cfbot builds without problem so maybe just ignore these FAILED > > lines. Better get them merged - so I can test there... > > It's because of dbbca2cf299b. It should apply cleanly if you do "git > checkout dbbca2cf299b^" first ... That commit is so recent that > evidently the cfbot hasn't had a chance to try this patch again since it > went in, which is why it's still green. Thanks for the heads up. Attaching rebased patches. -- Thanks, Amit Langote
Вложения
Hi, > On Tue, Mar 5, 2024 at 12:03 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: >> On 2024-Mar-04, Erik Rijkers wrote: >> >> > In my hands (applying with patch), the patches, esp. 0001, do not apply. >> > But I see the cfbot builds without problem so maybe just ignore these FAILED >> > lines. Better get them merged - so I can test there... >> >> It's because of dbbca2cf299b. It should apply cleanly if you do "git >> checkout dbbca2cf299b^" first ... That commit is so recent that >> evidently the cfbot hasn't had a chance to try this patch again since it >> went in, which is why it's still green. > > Thanks for the heads up. Attaching rebased patches. In the commit message of 0001, we have: """ Both JSON_VALUE() and JSON_QUERY() functions have options for handling EMPTY and ERROR conditions, which can be used to specify the behavior when no values are matched and when an error occurs during evaluation, respectively. All of these functions only operate on jsonb values. The workaround for now is to cast the argument to jsonb. """ which is not clear for me why we introduce JSON_VALUE() function, is it for handling EMPTY or ERROR conditions? I think the existing cast workaround have a similar capacity? Then I think if it is introduced as a performance improvement like [1], then the test at [1] might be interesting. If this is the case, the method in [1] can avoid the user to modify these queries for the using the new function. [1] https://www.postgresql.org/message-id/8734t6c5rh.fsf@163.com -- Best Regards Andy Fan
On Tue, Mar 5, 2024 at 9:22 AM Amit Langote <amitlangote09@gmail.com> wrote:
>
> Thanks for the heads up. Attaching rebased patches.
>
Walking through the v41-0001-Add-SQL-JSON-query-functions.patch documentation.
I found some minor cosmetic issues.
+ <para>
+ <literal>select json_query(jsonb '{"a": "[1, 2]"}', 'lax $.a'
RETURNING int[] OMIT QUOTES);</literal>
+ <returnvalue></returnvalue>
+ </para>
this example is not so good, it returns NULL, makes it harder to
render the result.
+ <replaceable>context_item</replaceable> (the document); seen
+ <xref linkend="functions-sqljson-path"/> for more details on what
+ <replaceable>path_expression</replaceable> can contain.
"seen" should be "see"?
+ <para>
+ This function must return a JSON string, so if the path expression
+ returns multiple SQL/JSON items, you must wrap the result using the
+ <literal>WITH WRAPPER</literal> clause. If the wrapper is
"must" may be not correct?
since we have a RETURNING clause.
"generally" may be more accurate, I think.
maybe we can rephrase the sentence:
+ This function generally return a JSON string, so if the path expression
+ yield multiple SQL/JSON items, you must wrap the result using the
+ <literal>WITH WRAPPER</literal> clause
+ is spcified, the returned value will be of type <type>text</type>.
+ If no <literal>RETURNING</literal> is spcified, the returned value will
two typos, and should be "specified".
+ Note that if the <replaceable>path_expression</replaceable>
+ is <literal>strict</literal> and <literal>ON ERROR</literal> behavior
+ is <literal>ON ERROR</literal>, an error is generated if it yields no
+ items.
may be the following:
+ Note that if the <replaceable>path_expression</replaceable>
+ is <literal>strict</literal> and <literal>ON ERROR</literal> behavior
+ is <literal>ERROR</literal>, an error is generated if it yields no
+ items.
most of the place, you use
<replaceable>path_expression</replaceable>
but there are two place you use:
<type>path_expression</type>
I guess that's ok, but the appearance is different.
<replaceable> more prominent. Anyway, it is a minor issue.
+ <function>json_query</function>. Note that scalar strings returned
+ by <function>json_value</function> always have their quotes removed,
+ equivalent to what one would get with <literal>OMIT QUOTES</literal>
+ when using <function>json_query</function>.
I think we can simplify it like the following:
+ <function>json_query</function>. Note that scalar strings returned
+ by <function>json_value</function> always have their quotes removed,
+ equivalent to <literal>OMIT QUOTES</literal>
+ when using <function>json_query</function>.
Hi,
I know very little about sql/json and all the json internals, but I
decided to do some black box testing. I built a large JSONB table
(single column, ~7GB of data after loading). And then I did a query
transforming the data into tabular form using JSON_TABLE.
The JSON_TABLE query looks like this:
SELECT jt.* FROM
title_jsonb t,
json_table(t.info, '$'
COLUMNS (
"id" text path '$."id"',
"type" text path '$."type"',
"title" text path '$."title"',
"original_title" text path '$."original_title"',
"is_adult" text path '$."is_adult"',
"start_year" text path '$."start_year"',
"end_year" text path '$."end_year"',
"minutes" text path '$."minutes"',
"genres" text path '$."genres"',
"aliases" text path '$."aliases"',
"directors" text path '$."directors"',
"writers" text path '$."writers"',
"ratings" text path '$."ratings"',
NESTED PATH '$."aliases"[*]'
COLUMNS (
"alias_title" text path '$."title"',
"alias_region" text path '$."region"'
),
NESTED PATH '$."directors"[*]'
COLUMNS (
"director_name" text path '$."name"',
"director_birth_year" text path '$."birth_year"',
"director_death_year" text path '$."death_year"'
),
NESTED PATH '$."writers"[*]'
COLUMNS (
"writer_name" text path '$."name"',
"writer_birth_year" text path '$."birth_year"',
"writer_death_year" text path '$."death_year"'
),
NESTED PATH '$."ratings"[*]'
COLUMNS (
"rating_average" text path '$."average"',
"rating_votes" text path '$."votes"'
)
)
) as jt;
again, not particularly complex. But if I run this, it consumes multiple
gigabytes of memory, before it gets killed by OOM killer. This happens
even when ran using
COPY (...) TO '/dev/null'
so there's nothing sent to the client. I did catch memory context info,
where it looks like this (complete stats attached):
------
TopMemoryContext: 97696 total in 5 blocks; 13056 free (11 chunks);
84640 used
...
TopPortalContext: 8192 total in 1 blocks; 7680 free (0 chunks); ...
PortalContext: 1024 total in 1 blocks; 560 free (0 chunks); ...
ExecutorState: 2541764672 total in 314 blocks; 6528176 free
(1208 chunks); 2535236496 used
printtup: 8192 total in 1 blocks; 7952 free (0 chunks); ...
...
...
Grand total: 2544132336 bytes in 528 blocks; 7484504 free
(1340 chunks); 2536647832 used
------
I'd say 2.5GB in ExecutorState seems a bit excessive ... Seems there's
some memory management issue? My guess is we're not releasing memory
allocated while parsing the JSON or building JSON output.
I'm not attaching the data, but I can provide that if needed - it's
about 600MB compressed. The structure is not particularly complex, it's
movie info from [1] combined into a JSON document (one per movie).
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Вложения
Hi Tomas, On Wed, Mar 6, 2024 at 6:30 AM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > > Hi, > > I know very little about sql/json and all the json internals, but I > decided to do some black box testing. I built a large JSONB table > (single column, ~7GB of data after loading). And then I did a query > transforming the data into tabular form using JSON_TABLE. > > The JSON_TABLE query looks like this: > > SELECT jt.* FROM > title_jsonb t, > json_table(t.info, '$' > COLUMNS ( > "id" text path '$."id"', > "type" text path '$."type"', > "title" text path '$."title"', > "original_title" text path '$."original_title"', > "is_adult" text path '$."is_adult"', > "start_year" text path '$."start_year"', > "end_year" text path '$."end_year"', > "minutes" text path '$."minutes"', > "genres" text path '$."genres"', > "aliases" text path '$."aliases"', > "directors" text path '$."directors"', > "writers" text path '$."writers"', > "ratings" text path '$."ratings"', > NESTED PATH '$."aliases"[*]' > COLUMNS ( > "alias_title" text path '$."title"', > "alias_region" text path '$."region"' > ), > NESTED PATH '$."directors"[*]' > COLUMNS ( > "director_name" text path '$."name"', > "director_birth_year" text path '$."birth_year"', > "director_death_year" text path '$."death_year"' > ), > NESTED PATH '$."writers"[*]' > COLUMNS ( > "writer_name" text path '$."name"', > "writer_birth_year" text path '$."birth_year"', > "writer_death_year" text path '$."death_year"' > ), > NESTED PATH '$."ratings"[*]' > COLUMNS ( > "rating_average" text path '$."average"', > "rating_votes" text path '$."votes"' > ) > ) > ) as jt; > > again, not particularly complex. But if I run this, it consumes multiple > gigabytes of memory, before it gets killed by OOM killer. This happens > even when ran using > > COPY (...) TO '/dev/null' > > so there's nothing sent to the client. I did catch memory context info, > where it looks like this (complete stats attached): > > ------ > TopMemoryContext: 97696 total in 5 blocks; 13056 free (11 chunks); > 84640 used > ... > TopPortalContext: 8192 total in 1 blocks; 7680 free (0 chunks); ... > PortalContext: 1024 total in 1 blocks; 560 free (0 chunks); ... > ExecutorState: 2541764672 total in 314 blocks; 6528176 free > (1208 chunks); 2535236496 used > printtup: 8192 total in 1 blocks; 7952 free (0 chunks); ... > ... > ... > Grand total: 2544132336 bytes in 528 blocks; 7484504 free > (1340 chunks); 2536647832 used > ------ > > I'd say 2.5GB in ExecutorState seems a bit excessive ... Seems there's > some memory management issue? My guess is we're not releasing memory > allocated while parsing the JSON or building JSON output. > > I'm not attaching the data, but I can provide that if needed - it's > about 600MB compressed. The structure is not particularly complex, it's > movie info from [1] combined into a JSON document (one per movie). Thanks for the report. Yeah, I'd like to see the data to try to drill down into what's piling up in ExecutorState. I want to be sure of if the 1st, query functions patch, is not implicated in this, because I'd like to get that one out of the way sooner than later. -- Thanks, Amit Langote
On Tue, Mar 5, 2024 at 6:52 AM Amit Langote <amitlangote09@gmail.com> wrote:
Hi,
I am doing some random testing with the latest patch and found one scenario that I wanted to share.
consider a below case.
‘postgres[102531]=#’SELECT * FROM JSON_TABLE(jsonb '{
"id" : 12345678901,
"FULL_NAME" : "JOHN DOE"}',
'$'
COLUMNS(
name varchar(20) PATH 'lax $.FULL_NAME',
id int PATH 'lax $.id'
)
)
;
ERROR: 22003: integer out of range
LOCATION: numeric_int4_opt_error, numeric.c:4385
‘postgres[102531]=#’SELECT * FROM JSON_TABLE(jsonb '{
"id" : "12345678901",
"FULL_NAME" : "JOHN DOE"}',
'$'
COLUMNS(
name varchar(20) PATH 'lax $.FULL_NAME',
id int PATH 'lax $.id'
)
)
;
name | id
----------+----
JOHN DOE |
(1 row)
"id" : 12345678901,
"FULL_NAME" : "JOHN DOE"}',
'$'
COLUMNS(
name varchar(20) PATH 'lax $.FULL_NAME',
id int PATH 'lax $.id'
)
)
;
ERROR: 22003: integer out of range
LOCATION: numeric_int4_opt_error, numeric.c:4385
‘postgres[102531]=#’SELECT * FROM JSON_TABLE(jsonb '{
"id" : "12345678901",
"FULL_NAME" : "JOHN DOE"}',
'$'
COLUMNS(
name varchar(20) PATH 'lax $.FULL_NAME',
id int PATH 'lax $.id'
)
)
;
name | id
----------+----
JOHN DOE |
(1 row)
The first query throws an error that the integer is "out of range" and is quite expected but in the second case(when the value is enclosed with ") it is able to process the JSON object but does not return any relevant error(in fact processes the JSON but returns it with empty data for "id" field). I think second query should fail with a similar error.
--
On Wed, Mar 6, 2024 at 12:07 PM Amit Langote <amitlangote09@gmail.com> wrote:
>
> Hi Tomas,
>
> On Wed, Mar 6, 2024 at 6:30 AM Tomas Vondra
> <tomas.vondra@enterprisedb.com> wrote:
> >
> > Hi,
> >
> > I know very little about sql/json and all the json internals, but I
> > decided to do some black box testing. I built a large JSONB table
> > (single column, ~7GB of data after loading). And then I did a query
> > transforming the data into tabular form using JSON_TABLE.
> >
> > The JSON_TABLE query looks like this:
> >
> > SELECT jt.* FROM
> > title_jsonb t,
> > json_table(t.info, '$'
> > COLUMNS (
> > "id" text path '$."id"',
> > "type" text path '$."type"',
> > "title" text path '$."title"',
> > "original_title" text path '$."original_title"',
> > "is_adult" text path '$."is_adult"',
> > "start_year" text path '$."start_year"',
> > "end_year" text path '$."end_year"',
> > "minutes" text path '$."minutes"',
> > "genres" text path '$."genres"',
> > "aliases" text path '$."aliases"',
> > "directors" text path '$."directors"',
> > "writers" text path '$."writers"',
> > "ratings" text path '$."ratings"',
> > NESTED PATH '$."aliases"[*]'
> > COLUMNS (
> > "alias_title" text path '$."title"',
> > "alias_region" text path '$."region"'
> > ),
> > NESTED PATH '$."directors"[*]'
> > COLUMNS (
> > "director_name" text path '$."name"',
> > "director_birth_year" text path '$."birth_year"',
> > "director_death_year" text path '$."death_year"'
> > ),
> > NESTED PATH '$."writers"[*]'
> > COLUMNS (
> > "writer_name" text path '$."name"',
> > "writer_birth_year" text path '$."birth_year"',
> > "writer_death_year" text path '$."death_year"'
> > ),
> > NESTED PATH '$."ratings"[*]'
> > COLUMNS (
> > "rating_average" text path '$."average"',
> > "rating_votes" text path '$."votes"'
> > )
> > )
> > ) as jt;
> >
> > again, not particularly complex. But if I run this, it consumes multiple
> > gigabytes of memory, before it gets killed by OOM killer. This happens
> > even when ran using
> >
> > COPY (...) TO '/dev/null'
> >
> > so there's nothing sent to the client. I did catch memory context info,
> > where it looks like this (complete stats attached):
> >
> > ------
> > TopMemoryContext: 97696 total in 5 blocks; 13056 free (11 chunks);
> > 84640 used
> > ...
> > TopPortalContext: 8192 total in 1 blocks; 7680 free (0 chunks); ...
> > PortalContext: 1024 total in 1 blocks; 560 free (0 chunks); ...
> > ExecutorState: 2541764672 total in 314 blocks; 6528176 free
> > (1208 chunks); 2535236496 used
> > printtup: 8192 total in 1 blocks; 7952 free (0 chunks); ...
> > ...
> > ...
> > Grand total: 2544132336 bytes in 528 blocks; 7484504 free
> > (1340 chunks); 2536647832 used
> > ------
> >
> > I'd say 2.5GB in ExecutorState seems a bit excessive ... Seems there's
> > some memory management issue? My guess is we're not releasing memory
> > allocated while parsing the JSON or building JSON output.
> >
> > I'm not attaching the data, but I can provide that if needed - it's
> > about 600MB compressed. The structure is not particularly complex, it's
> > movie info from [1] combined into a JSON document (one per movie).
>
> Thanks for the report.
>
> Yeah, I'd like to see the data to try to drill down into what's piling
> up in ExecutorState. I want to be sure of if the 1st, query functions
> patch, is not implicated in this, because I'd like to get that one out
> of the way sooner than later.
>
I did some tests. it generally looks like:
create or replace function random_text() returns text
as $$select string_agg(md5(random()::text),'') from
generate_Series(1,8) s $$ LANGUAGE SQL;
DROP TABLE if exists s;
create table s(a jsonb);
INSERT INTO s SELECT (
'{"id": "' || random_text() || '",'
'"type": "' || random_text() || '",'
'"title": "' || random_text() || '",'
'"original_title": "' || random_text() || '",'
'"is_adult": "' || random_text() || '",'
'"start_year": "' || random_text() || '",'
'"end_year": "' || random_text() || '",'
'"minutes": "' || random_text() || '",'
'"genres": "' || random_text() || '",'
'"aliases": "' || random_text() || '",'
'"genres": "' || random_text() || '",'
'"directors": "' || random_text() || '",'
'"writers": "' || random_text() || '",'
'"ratings": "' || random_text() || '",'
'"director_name": "' || random_text() || '",'
'"alias_title": "' || random_text() || '",'
'"alias_region": "' || random_text() || '",'
'"director_birth_year": "' || random_text() || '",'
'"director_death_year": "' || random_text() || '",'
'"rating_average": "' || random_text() || '",'
'"rating_votes": "' || random_text() || '"'
||'}' )::jsonb
FROM generate_series(1, 1e6);
SELECT pg_size_pretty(pg_table_size('s')); -- 5975 MB
It's less complex than Tomas's version.
attached, 3 test files:
1e5 rows, each key's value is small. Total table size is 598 MB.
1e6 rows, each key's value is small. Total table size is 5975 MB.
27 rows, total table size is 5066 MB.
The test file's comment is the output I extracted using
pg_log_backend_memory_contexts,
mainly ExecutorState and surrounding big number memory context.
Conclusion, I come from the test:
if each json is big (5066 MB/27) , then it will take a lot of memory.
if each json is small(here is 256 byte), then it won't take a lot of
memory to process.
Another case, I did test yet: more keys in a single json, but the
value is small.
Вложения
On 3/6/24 12:58, Himanshu Upadhyaya wrote:
> On Tue, Mar 5, 2024 at 6:52 AM Amit Langote <amitlangote09@gmail.com> wrote:
>
> Hi,
>
> I am doing some random testing with the latest patch and found one scenario
> that I wanted to share.
> consider a below case.
>
> ‘postgres[102531]=#’SELECT * FROM JSON_TABLE(jsonb '{
> "id" : 12345678901,
> "FULL_NAME" : "JOHN DOE"}',
> '$'
> COLUMNS(
> name varchar(20) PATH 'lax $.FULL_NAME',
> id int PATH 'lax $.id'
> )
> )
> ;
> ERROR: 22003: integer out of range
> LOCATION: numeric_int4_opt_error, numeric.c:4385
> ‘postgres[102531]=#’SELECT * FROM JSON_TABLE(jsonb '{
> "id" : "12345678901",
> "FULL_NAME" : "JOHN DOE"}',
> '$'
> COLUMNS(
> name varchar(20) PATH 'lax $.FULL_NAME',
> id int PATH 'lax $.id'
> )
> )
> ;
> name | id
> ----------+----
> JOHN DOE |
> (1 row)
>
> The first query throws an error that the integer is "out of range" and is
> quite expected but in the second case(when the value is enclosed with ") it
> is able to process the JSON object but does not return any relevant
> error(in fact processes the JSON but returns it with empty data for "id"
> field). I think second query should fail with a similar error.
>
I'm pretty sure this is the correct & expected behavior. The second
query treats the value as string (because that's what should happen for
values in double quotes).
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Wed, Mar 6, 2024 at 9:22 PM jian he <jian.universality@gmail.com> wrote:
>
> Another case, I did test yet: more keys in a single json, but the
> value is small.
Another case attached. see the attached SQL file's comments.
a single simple jsonb, with 33 keys, each key's value with fixed length: 256.
total table size: SELECT pg_size_pretty(pg_table_size('json33keys')); --5369 MB
number of rows: 600001.
using the previously mentioned method: pg_log_backend_memory_contexts.
all these tests under:
-Dcassert=true \
-Db_coverage=true \
-Dbuildtype=debug \
I hope someone will tell me if the test method is correct or not.
Вложения
On Tue, Mar 5, 2024 at 12:38 PM Andy Fan <zhihuifan1213@163.com> wrote: > > > In the commit message of 0001, we have: > > """ > Both JSON_VALUE() and JSON_QUERY() functions have options for > handling EMPTY and ERROR conditions, which can be used to specify > the behavior when no values are matched and when an error occurs > during evaluation, respectively. > > All of these functions only operate on jsonb values. The workaround > for now is to cast the argument to jsonb. > """ > > which is not clear for me why we introduce JSON_VALUE() function, is it > for handling EMPTY or ERROR conditions? I think the existing cast > workaround have a similar capacity? > I guess because it's in the standard. but I don't see individual sql standard Identifier, JSON_VALUE in sql_features.txt I do see JSON_QUERY. mysql also have JSON_VALUE, [1] EMPTY, ERROR: there is a standard Identifier: T825: SQL/JSON: ON EMPTY and ON ERROR clauses [1] https://dev.mysql.com/doc/refman/8.0/en/json-search-functions.html#function_json-value
two cosmetic minor issues.
+/*
+ * JsonCoercion
+ * Information about coercing a SQL/JSON value to the specified
+ * type at runtime
+ *
+ * A node of this type is created if the parser cannot find a cast expression
+ * using coerce_type() or OMIT QUOTES is specified for JSON_QUERY. If the
+ * latter, 'expr' may contain the cast expression; if not, the quote-stripped
+ * scalar string will be coerced by calling the target type's input function.
+ * See ExecEvalJsonCoercion.
+ */
+typedef struct JsonCoercion
+{
+ NodeTag type;
+
+ Oid targettype;
+ int32 targettypmod;
+ bool omit_quotes; /* OMIT QUOTES specified for JSON_QUERY? */
+ Node *cast_expr; /* coercion cast expression or NULL */
+ Oid collation;
+} JsonCoercion;
comment: 'expr' may contain the cast expression;
here "exr" should be "cast_expr"?
"a SQL/JSON" should be " an SQL/JSON"?
On Wed, Mar 6, 2024 at 9:04 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote:
I'm pretty sure this is the correct & expected behavior. The second
query treats the value as string (because that's what should happen for
values in double quotes).
ok, Then why does the below query provide the correct conversion, even if we enclose that in double quotes?
‘postgres[102531]=#’SELECT * FROM JSON_TABLE(jsonb '{
"id" : "1234567890",
"FULL_NAME" : "JOHN DOE"}',
'$'
COLUMNS(
name varchar(20) PATH 'lax $.FULL_NAME',
id int PATH 'lax $.id'
)
)
;
"id" : "1234567890",
"FULL_NAME" : "JOHN DOE"}',
'$'
COLUMNS(
name varchar(20) PATH 'lax $.FULL_NAME',
id int PATH 'lax $.id'
)
)
;
name | id
----------+------------
JOHN DOE | 1234567890
----------+------------
JOHN DOE | 1234567890
(1 row)
and for bigger input(string) it will leave as empty as below.
‘postgres[102531]=#’SELECT * FROM JSON_TABLE(jsonb '{
"id" : "12345678901",
"FULL_NAME" : "JOHN DOE"}',
'$'
COLUMNS(
name varchar(20) PATH 'lax $.FULL_NAME',
id int PATH 'lax $.id'
)
)
;
name | id
----------+----
JOHN DOE |
(1 row)
"id" : "12345678901",
"FULL_NAME" : "JOHN DOE"}',
'$'
COLUMNS(
name varchar(20) PATH 'lax $.FULL_NAME',
id int PATH 'lax $.id'
)
)
;
name | id
----------+----
JOHN DOE |
(1 row)
seems it is not something to do with data enclosed in double quotes but somehow related with internal casting it to integer and I think in case of bigger input it is not able to cast it to integer(as defined under COLUMNS as id int PATH 'lax $.id')
‘postgres[102531]=#’SELECT * FROM JSON_TABLE(jsonb '{
"id" : "12345678901","FULL_NAME" : "JOHN DOE"}',
'$'
COLUMNS(
name varchar(20) PATH 'lax $.FULL_NAME',
id int PATH 'lax $.id'
)
)
;
name | id
----------+----
JOHN DOE |
(1 row)
)
if it is not able to represent it to integer because of bigger input, it should error out with a similar error message instead of leaving it empty.
Thoughts?
On Wed, Mar 6, 2024 at 1:07 PM Amit Langote <amitlangote09@gmail.com> wrote: > Hi Tomas, > > On Wed, Mar 6, 2024 at 6:30 AM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: > > I'd say 2.5GB in ExecutorState seems a bit excessive ... Seems there's > > some memory management issue? My guess is we're not releasing memory > > allocated while parsing the JSON or building JSON output. > > > > I'm not attaching the data, but I can provide that if needed - it's > > about 600MB compressed. The structure is not particularly complex, it's > > movie info from [1] combined into a JSON document (one per movie). > > Thanks for the report. > > Yeah, I'd like to see the data to try to drill down into what's piling > up in ExecutorState. I want to be sure of if the 1st, query functions > patch, is not implicated in this, because I'd like to get that one out > of the way sooner than later. I tracked this memory-hogging down to a bug in the query functions patch (0001) after all. The problem was with a query-lifetime cache variable that was never set to point to the allocated memory. So a struct was allocated and then not freed for every row where it should have only been allocated once. I've fixed that bug in the attached. I've also addressed some of Jian's comments and made quite a few cleanups of my own. Now I'll go look if Himanshu's concerns are a blocker for committing 0001. ;) -- Thanks, Amit Langote
Вложения
On 3/7/24 08:26, Amit Langote wrote: > On Wed, Mar 6, 2024 at 1:07 PM Amit Langote <amitlangote09@gmail.com> wrote: >> Hi Tomas, >> >> On Wed, Mar 6, 2024 at 6:30 AM Tomas Vondra >> <tomas.vondra@enterprisedb.com> wrote: >>> I'd say 2.5GB in ExecutorState seems a bit excessive ... Seems there's >>> some memory management issue? My guess is we're not releasing memory >>> allocated while parsing the JSON or building JSON output. >>> >>> I'm not attaching the data, but I can provide that if needed - it's >>> about 600MB compressed. The structure is not particularly complex, it's >>> movie info from [1] combined into a JSON document (one per movie). >> >> Thanks for the report. >> >> Yeah, I'd like to see the data to try to drill down into what's piling >> up in ExecutorState. I want to be sure of if the 1st, query functions >> patch, is not implicated in this, because I'd like to get that one out >> of the way sooner than later. > > I tracked this memory-hogging down to a bug in the query functions > patch (0001) after all. The problem was with a query-lifetime cache > variable that was never set to point to the allocated memory. So a > struct was allocated and then not freed for every row where it should > have only been allocated once. > Thanks! I can confirm the query works with the new patches. Exporting the 7GB table takes ~250 seconds (the result is ~10.6GB). That seems maybe a bit much, but I'm not sure it's the fault of this patch. Attached is a flamegraph for the export, and clearly most of the time is spent in jsonpath. I wonder if there's a way to improve this, but I don't think it's up to this patch. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Вложения
{kind=link}
On 3/7/24 06:18, Himanshu Upadhyaya wrote:
> On Wed, Mar 6, 2024 at 9:04 PM Tomas Vondra <tomas.vondra@enterprisedb.com>
> wrote:
>
>>
>>
>> I'm pretty sure this is the correct & expected behavior. The second
>> query treats the value as string (because that's what should happen for
>> values in double quotes).
>>
>> ok, Then why does the below query provide the correct conversion, even if
> we enclose that in double quotes?
> ‘postgres[102531]=#’SELECT * FROM JSON_TABLE(jsonb '{
> "id" : "1234567890",
> "FULL_NAME" : "JOHN DOE"}',
> '$'
> COLUMNS(
> name varchar(20) PATH 'lax $.FULL_NAME',
> id int PATH 'lax $.id'
> )
> )
> ;
> name | id
> ----------+------------
> JOHN DOE | 1234567890
> (1 row)
>
> and for bigger input(string) it will leave as empty as below.
> ‘postgres[102531]=#’SELECT * FROM JSON_TABLE(jsonb '{
> "id" : "12345678901",
> "FULL_NAME" : "JOHN DOE"}',
> '$'
> COLUMNS(
> name varchar(20) PATH 'lax $.FULL_NAME',
> id int PATH 'lax $.id'
> )
> )
> ;
> name | id
> ----------+----
> JOHN DOE |
> (1 row)
>
> seems it is not something to do with data enclosed in double quotes but
> somehow related with internal casting it to integer and I think in case of
> bigger input it is not able to cast it to integer(as defined under COLUMNS
> as id int PATH 'lax $.id')
>
> ‘postgres[102531]=#’SELECT * FROM JSON_TABLE(jsonb '{
> "id" : "12345678901",
> "FULL_NAME" : "JOHN DOE"}',
> '$'
> COLUMNS(
> name varchar(20) PATH 'lax $.FULL_NAME',
> id int PATH 'lax $.id'
> )
> )
> ;
> name | id
> ----------+----
> JOHN DOE |
> (1 row)
> )
>
> if it is not able to represent it to integer because of bigger input, it
> should error out with a similar error message instead of leaving it empty.
>
> Thoughts?
>
Ah, I see! Yes, that's a bit weird. Put slightly differently:
test=# SELECT * FROM JSON_TABLE(jsonb '{"id" : "2000000000"}',
'$' COLUMNS(id int PATH '$.id'));
id
------------
2000000000
(1 row)
Time: 0.248 ms
test=# SELECT * FROM JSON_TABLE(jsonb '{"id" : "3000000000"}',
'$' COLUMNS(id int PATH '$.id'));
id
----
(1 row)
Clearly, when converting the string literal into int value, there's some
sort of error handling that realizes 3B overflows, and returns NULL
instead. I'm not sure if this is intentional.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Thu, Mar 7, 2024 at 8:13 PM Tomas Vondra
<tomas.vondra@enterprisedb.com> wrote:
> On 3/7/24 06:18, Himanshu Upadhyaya wrote:
Thanks Himanshu for the testing.
> > On Wed, Mar 6, 2024 at 9:04 PM Tomas Vondra <tomas.vondra@enterprisedb.com>
> > wrote:
> >>
> >> I'm pretty sure this is the correct & expected behavior. The second
> >> query treats the value as string (because that's what should happen for
> >> values in double quotes).
> >>
> >> ok, Then why does the below query provide the correct conversion, even if
> > we enclose that in double quotes?
> > ‘postgres[102531]=#’SELECT * FROM JSON_TABLE(jsonb '{
> > "id" : "1234567890",
> > "FULL_NAME" : "JOHN DOE"}',
> > '$'
> > COLUMNS(
> > name varchar(20) PATH 'lax $.FULL_NAME',
> > id int PATH 'lax $.id'
> > )
> > )
> > ;
> > name | id
> > ----------+------------
> > JOHN DOE | 1234567890
> > (1 row)
> >
> > and for bigger input(string) it will leave as empty as below.
> > ‘postgres[102531]=#’SELECT * FROM JSON_TABLE(jsonb '{
> > "id" : "12345678901",
> > "FULL_NAME" : "JOHN DOE"}',
> > '$'
> > COLUMNS(
> > name varchar(20) PATH 'lax $.FULL_NAME',
> > id int PATH 'lax $.id'
> > )
> > )
> > ;
> > name | id
> > ----------+----
> > JOHN DOE |
> > (1 row)
> >
> > seems it is not something to do with data enclosed in double quotes but
> > somehow related with internal casting it to integer and I think in case of
> > bigger input it is not able to cast it to integer(as defined under COLUMNS
> > as id int PATH 'lax $.id')
> >
> > ‘postgres[102531]=#’SELECT * FROM JSON_TABLE(jsonb '{
> > "id" : "12345678901",
> > "FULL_NAME" : "JOHN DOE"}',
> > '$'
> > COLUMNS(
> > name varchar(20) PATH 'lax $.FULL_NAME',
> > id int PATH 'lax $.id'
> > )
> > )
> > ;
> > name | id
> > ----------+----
> > JOHN DOE |
> > (1 row)
> > )
> >
> > if it is not able to represent it to integer because of bigger input, it
> > should error out with a similar error message instead of leaving it empty.
> >
> > Thoughts?
> >
>
> Ah, I see! Yes, that's a bit weird. Put slightly differently:
>
> test=# SELECT * FROM JSON_TABLE(jsonb '{"id" : "2000000000"}',
> '$' COLUMNS(id int PATH '$.id'));
> id
> ------------
> 2000000000
> (1 row)
>
> Time: 0.248 ms
> test=# SELECT * FROM JSON_TABLE(jsonb '{"id" : "3000000000"}',
> '$' COLUMNS(id int PATH '$.id'));
> id
> ----
>
> (1 row)
>
> Clearly, when converting the string literal into int value, there's some
> sort of error handling that realizes 3B overflows, and returns NULL
> instead. I'm not sure if this is intentional.
Indeed.
This boils down to the difference in the cast expression chosen to
convert the source value to int in the two cases.
The case where the source value has no quotes, the chosen cast
expression is a FuncExpr for function numeric_int4(), which has no way
to suppress errors. When the source value has quotes, the cast
expression is a CoerceViaIO expression, which can suppress the error.
The default behavior is to suppress the error and return NULL, so the
correct behavior is when the source value has quotes.
I think we'll need either:
* fix the code in 0001 to avoid getting numeric_int4() in this case,
and generally cast functions that don't have soft-error handling
support, in favor of using IO coercion.
* fix FuncExpr (like CoerceViaIO) to respect SQL/JSON's request to
suppress errors and fix downstream functions like numeric_int4() to
comply by handling errors softly.
I'm inclined to go with the 1st option as we already have the
infrastructure in place -- input functions can all handle errors
softly.
For the latter, it uses numeric_int4() which doesn't support
soft-error handling, so throws the error. With quotes, the
--
Thanks, Amit Langote
--
Thanks, Amit Langote
On Thu, Mar 7, 2024 at 8:06 PM Amit Langote <amitlangote09@gmail.com> wrote: > > > Indeed. > > This boils down to the difference in the cast expression chosen to > convert the source value to int in the two cases. > > The case where the source value has no quotes, the chosen cast > expression is a FuncExpr for function numeric_int4(), which has no way > to suppress errors. When the source value has quotes, the cast > expression is a CoerceViaIO expression, which can suppress the error. > The default behavior is to suppress the error and return NULL, so the > correct behavior is when the source value has quotes. > > I think we'll need either: > > * fix the code in 0001 to avoid getting numeric_int4() in this case, > and generally cast functions that don't have soft-error handling > support, in favor of using IO coercion. > * fix FuncExpr (like CoerceViaIO) to respect SQL/JSON's request to > suppress errors and fix downstream functions like numeric_int4() to > comply by handling errors softly. > > I'm inclined to go with the 1st option as we already have the > infrastructure in place -- input functions can all handle errors > softly. not sure this is the right way. but attached patches solved this problem. Also, can you share the previous memory-hogging bug issue when you are free, I want to know which part I am missing.....
Вложения
Hi,
I was experimenting with the v42 patches, and I think the handling of ON
EMPTY / ON ERROR clauses may need some improvement. The grammar is
currently defined like this:
| json_behavior ON EMPTY_P json_behavior ON ERROR_P
This means the clauses have to be defined exactly in this order, and if
someone does
NULL ON ERROR NULL ON EMPTY
it results in syntax error. I'm not sure what the SQL standard says
about this, but it seems other databases don't agree on the order. Is
there a particular reason to not allow both orderings?
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Thu, Mar 7, 2024 at 22:46 jian he <jian.universality@gmail.com> wrote:
On Thu, Mar 7, 2024 at 8:06 PM Amit Langote <amitlangote09@gmail.com> wrote:
>
>
> Indeed.
>
> This boils down to the difference in the cast expression chosen to
> convert the source value to int in the two cases.
>
> The case where the source value has no quotes, the chosen cast
> expression is a FuncExpr for function numeric_int4(), which has no way
> to suppress errors. When the source value has quotes, the cast
> expression is a CoerceViaIO expression, which can suppress the error.
> The default behavior is to suppress the error and return NULL, so the
> correct behavior is when the source value has quotes.
>
> I think we'll need either:
>
> * fix the code in 0001 to avoid getting numeric_int4() in this case,
> and generally cast functions that don't have soft-error handling
> support, in favor of using IO coercion.
> * fix FuncExpr (like CoerceViaIO) to respect SQL/JSON's request to
> suppress errors and fix downstream functions like numeric_int4() to
> comply by handling errors softly.
>
> I'm inclined to go with the 1st option as we already have the
> infrastructure in place -- input functions can all handle errors
> softly.
not sure this is the right way.
but attached patches solved this problem.
Also, can you share the previous memory-hogging bug issue
when you are free, I want to know which part I am missing.....
Take a look at the json_populate_type() call in ExecEvalJsonCoercion() or specifically compare the new way of passing its void *cache parameter with the earlier patches.
On 2024-Mar-07, Tomas Vondra wrote:
> I was experimenting with the v42 patches, and I think the handling of ON
> EMPTY / ON ERROR clauses may need some improvement.
Well, the 2023 standard says things like
<JSON value function> ::=
JSON_VALUE <left paren>
<JSON API common syntax>
[ <JSON returning clause> ]
[ <JSON value empty behavior> ON EMPTY ]
[ <JSON value error behavior> ON ERROR ]
<right paren>
which implies that if you specify it the other way around, it's a syntax
error.
> I'm not sure what the SQL standard says about this, but it seems other
> databases don't agree on the order. Is there a particular reason to
> not allow both orderings?
I vaguely recall that trying to also support the other ordering leads to
having more rules. Now maybe we do want that because of compatibility
with other DBMSs, but frankly at this stage I wouldn't bother.
--
Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/
"I am amazed at [the pgsql-sql] mailing list for the wonderful support, and
lack of hesitasion in answering a lost soul's question, I just wished the rest
of the mailing list could be like this." (Fotis)
https://postgr.es/m/200606261359.k5QDxE2p004593@auth-smtp.hol.gr
On Thu, Mar 7, 2024 at 23:14 Alvaro Herrera <alvherre@alvh.no-ip.org> wrote:
On 2024-Mar-07, Tomas Vondra wrote:
> I was experimenting with the v42 patches, and I think the handling of ON
> EMPTY / ON ERROR clauses may need some improvement.
Well, the 2023 standard says things like
<JSON value function> ::=
JSON_VALUE <left paren>
<JSON API common syntax>
[ <JSON returning clause> ]
[ <JSON value empty behavior> ON EMPTY ]
[ <JSON value error behavior> ON ERROR ]
<right paren>
which implies that if you specify it the other way around, it's a syntax
error.
> I'm not sure what the SQL standard says about this, but it seems other
> databases don't agree on the order. Is there a particular reason to
> not allow both orderings?
I vaguely recall that trying to also support the other ordering leads to
having more rules.
Yeah, I think that was it. At one point, I removed rules supporting syntax that wasn’t documented.
Now maybe we do want that because of compatibility
with other DBMSs, but frankly at this stage I wouldn't bother.
+1.
I looked at the documentation again.
one more changes for JSON_QUERY:
diff --git a/doc/src/sgml/func.sgml b/doc/src/sgml/func.sgml
index 3e58ebd2..0c49b321 100644
--- a/doc/src/sgml/func.sgml
+++ b/doc/src/sgml/func.sgml
@@ -18715,8 +18715,8 @@ ERROR: jsonpath array subscript is out of bounds
be of type <type>jsonb</type>.
</para>
<para>
- The <literal>ON EMPTY</literal> clause specifies the behavior if the
- <replaceable>path_expression</replaceable> yields no value at all; the
+ The <literal>ON EMPTY</literal> clause specifies the behavior
if applying the
+ <replaceable>path_expression</replaceable> to the
<replaceable>context_item</replaceable> yields no value at all; the
default when <literal>ON EMPTY</literal> is not specified is to return
a null value.
</para>
jian he <jian.universality@gmail.com> writes: > On Tue, Mar 5, 2024 at 12:38 PM Andy Fan <zhihuifan1213@163.com> wrote: >> >> >> In the commit message of 0001, we have: >> >> """ >> Both JSON_VALUE() and JSON_QUERY() functions have options for >> handling EMPTY and ERROR conditions, which can be used to specify >> the behavior when no values are matched and when an error occurs >> during evaluation, respectively. >> >> All of these functions only operate on jsonb values. The workaround >> for now is to cast the argument to jsonb. >> """ >> >> which is not clear for me why we introduce JSON_VALUE() function, is it >> for handling EMPTY or ERROR conditions? I think the existing cast >> workaround have a similar capacity? >> > > I guess because it's in the standard. > but I don't see individual sql standard Identifier, JSON_VALUE in > sql_features.txt > I do see JSON_QUERY. > mysql also have JSON_VALUE, [1] > > EMPTY, ERROR: there is a standard Identifier: T825: SQL/JSON: ON EMPTY > and ON ERROR clauses > > [1] https://dev.mysql.com/doc/refman/8.0/en/json-search-functions.html#function_json-value Thank you for this informatoin! -- Best Regards Andy Fan
one more issue.
+ case JSON_VALUE_OP:
+ /* Always omit quotes from scalar strings. */
+ jsexpr->omit_quotes = (func->quotes == JS_QUOTES_OMIT);
+
+ /* JSON_VALUE returns text by default. */
+ if (!OidIsValid(jsexpr->returning->typid))
+ {
+ jsexpr->returning->typid = TEXTOID;
+ jsexpr->returning->typmod = -1;
+ }
by default, makeNode(JsonExpr), node initialization,
jsexpr->omit_quotes will initialize to false,
Even though there was no implication to the JSON_TABLE patch (probably
because coerceJsonFuncExprOutput), all tests still passed.
based on the above comment, and the regress test, you still need do (i think)
`
jsexpr->omit_quotes = true;
`
On Sun, Mar 10, 2024 at 10:57 PM jian he <jian.universality@gmail.com> wrote:
>
> one more issue.
Hi
one more documentation issue.
after applied V42, 0001 to 0003,
there are 11 appearance of `FORMAT JSON` in functions-json.html
still not a single place explained what it is for.
json_query ( context_item, path_expression [ PASSING { value AS
varname } [, ...]] [ RETURNING data_type [ FORMAT JSON [ ENCODING UTF8
] ] ] [ { WITHOUT | WITH { CONDITIONAL | [UNCONDITIONAL] } } [ ARRAY ]
WRAPPER ] [ { KEEP | OMIT } QUOTES [ ON SCALAR STRING ] ] [ { ERROR |
NULL | EMPTY { [ ARRAY ] | OBJECT } | DEFAULT expression } ON EMPTY ]
[ { ERROR | NULL | EMPTY { [ ARRAY ] | OBJECT } | DEFAULT expression }
ON ERROR ])
FORMAT JSON seems just a syntax sugar or for compatibility in json_query.
but it returns an error when the returning type category is not
TYPCATEGORY_STRING.
for example, even the following will return an error.
`
CREATE TYPE regtest_comptype AS (b text);
SELECT JSON_QUERY(jsonb '{"a":{"b":"c"}}', '$.a' RETURNING
regtest_comptype format json);
`
seems only types in[0] will not generate an error, when specifying
FORMAT JSON in JSON_QUERY.
so it actually does something, not a syntax sugar?
[0] https://www.postgresql.org/docs/current/datatype-character.html
one more issue.....
+-- Extension: non-constant JSON path
+SELECT JSON_EXISTS(jsonb '{"a": 123}', '$' || '.' || 'a');
+SELECT JSON_VALUE(jsonb '{"a": 123}', '$' || '.' || 'a');
+SELECT JSON_VALUE(jsonb '{"a": 123}', '$' || '.' || 'b' DEFAULT 'foo'
ON EMPTY);
+SELECT JSON_QUERY(jsonb '{"a": 123}', '$' || '.' || 'a');
+SELECT JSON_QUERY(jsonb '{"a": 123}', '$' || '.' || 'a' WITH WRAPPER);
json path may not be a plain Const.
does the following code in expression_tree_walker_impl need to consider
cases when the `jexpr->path_spec` part is not a Const?
+ case T_JsonExpr:
+ {
+ JsonExpr *jexpr = (JsonExpr *) node;
+
+ if (WALK(jexpr->formatted_expr))
+ return true;
+ if (WALK(jexpr->result_coercion))
+ return true;
+ if (WALK(jexpr->item_coercions))
+ return true;
+ if (WALK(jexpr->passing_values))
+ return true;
+ /* we assume walker doesn't care about passing_names */
+ if (WALK(jexpr->on_empty))
+ return true;
+ if (WALK(jexpr->on_error))
+ return true;
+ }
Hi.
more minor issues.
by searching `elog(ERROR, "unrecognized node type: %d"`
I found that generally enum is cast to int, before printing it out.
I also found a related post at [1].
So I add the typecast to int, before printing it out.
most of the refactored code is unlikely to be reachable, but still.
I also refactored ExecPrepareJsonItemCoercion error message, to make
the error message more explicit.
@@ -4498,7 +4498,9 @@ ExecPrepareJsonItemCoercion(JsonbValue *item,
JsonExprState *jsestate,
if (throw_error)
ereport(ERROR,
errcode(ERRCODE_SQL_JSON_ITEM_CANNOT_BE_CAST_TO_TARGET_TYPE),
- errmsg("SQL/JSON item cannot
be cast to target type"));
+
errcode(ERRCODE_SQL_JSON_ITEM_CANNOT_BE_CAST_TO_TARGET_TYPE),
+ errmsg("SQL/JSON item cannot
be cast to type %s",
+
format_type_be(jsestate->jsexpr->returning->typid)));
+ /*
+ * We abuse CaseTestExpr here as placeholder to pass the result of
+ * evaluating the JSON_VALUE/QUERY jsonpath expression as input to the
+ * coercion expression.
+ */
+ CaseTestExpr *placeholder = makeNode(CaseTestExpr);
typo in comment, should it be `JSON_VALUE/JSON_QUERY`?
[1] https://stackoverflow.com/questions/8012647/can-we-typecast-a-enum-variable-in-c
Вложения
Hi,
I was experimenting with the v42 patches, and I tried testing without providing the path explicitly. There is one difference between the two test cases that I have highlighted in blue.
The full_name column is empty in the second test case result. Let me know if this is an issue or expected behaviour.
CASE 1:
-----------
SELECT * FROM JSON_TABLE(jsonb '{
"id" : 901,
"age" : 30,
"full_name" : "KATE DANIEL"}',
'$'
COLUMNS(
FULL_NAME varchar(20),
ID int,
AGE int
)
) as t;
RESULT:
full_name | id | age
-------------+-----+-----
KATE DANIEL | 901 | 30
(1 row)
CASE 2:
------------------
SELECT * FROM JSON_TABLE(jsonb '{
"id" : 901,
"age" : 30,
"FULL_NAME" : "KATE DANIEL"}',
'$'
COLUMNS(
FULL_NAME varchar(20),
ID int,
AGE int
)
) as t;
-----------
SELECT * FROM JSON_TABLE(jsonb '{
"id" : 901,
"age" : 30,
"full_name" : "KATE DANIEL"}',
'$'
COLUMNS(
FULL_NAME varchar(20),
ID int,
AGE int
)
) as t;
RESULT:
full_name | id | age
-------------+-----+-----
KATE DANIEL | 901 | 30
(1 row)
CASE 2:
------------------
SELECT * FROM JSON_TABLE(jsonb '{
"id" : 901,
"age" : 30,
"FULL_NAME" : "KATE DANIEL"}',
'$'
COLUMNS(
FULL_NAME varchar(20),
ID int,
AGE int
)
) as t;
RESULT:
full_name | id | age
-----------+-----+-----
| 901 | 30
(1 row)
Thanks & Regards,
full_name | id | age
-----------+-----+-----
| 901 | 30
(1 row)
Thanks & Regards,
Shruthi K C
EnterpriseDB: http://www.enterprisedb.com
On 2024-Mar-11, Shruthi Gowda wrote:
> *CASE 2:*
> ------------------
> SELECT * FROM JSON_TABLE(jsonb '{
> "id" : 901,
> "age" : 30,
> "*FULL_NAME*" : "KATE DANIEL"}',
> '$'
> COLUMNS(
> FULL_NAME varchar(20),
> ID int,
> AGE int
> )
> ) as t;
I think this is expected: when you use FULL_NAME as a SQL identifier, it
is down-cased, so it no longer matches the uppercase identifier in the
JSON data. You'd have to do it like this:
SELECT * FROM JSON_TABLE(jsonb '{
"id" : 901,
"age" : 30,
"*FULL_NAME*" : "KATE DANIEL"}',
'$'
COLUMNS(
"FULL_NAME" varchar(20),
ID int,
AGE int
)
) as t;
so that the SQL identifier is not downcased.
--
Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/
Thanka Alvaro. It works fine when quotes are used around the column name.
On Mon, Mar 11, 2024 at 9:04 PM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote:
On 2024-Mar-11, Shruthi Gowda wrote:
> *CASE 2:*
> ------------------
> SELECT * FROM JSON_TABLE(jsonb '{
> "id" : 901,
> "age" : 30,
> "*FULL_NAME*" : "KATE DANIEL"}',
> '$'
> COLUMNS(
> FULL_NAME varchar(20),
> ID int,
> AGE int
> )
> ) as t;
I think this is expected: when you use FULL_NAME as a SQL identifier, it
is down-cased, so it no longer matches the uppercase identifier in the
JSON data. You'd have to do it like this:
SELECT * FROM JSON_TABLE(jsonb '{
"id" : 901,
"age" : 30,
"*FULL_NAME*" : "KATE DANIEL"}',
'$'
COLUMNS(
"FULL_NAME" varchar(20),
ID int,
AGE int
)
) as t;
so that the SQL identifier is not downcased.
--
Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/
Hi,
wanted to share the below case:
‘postgres[146443]=#’SELECT JSON_EXISTS(jsonb '{"customer_name": "test", "salary":1000, "department_id":1}', '$.* ? (@== $dept_id && @ == $sal)' PASSING 1000 AS sal, 1 as dept_id);
json_exists
-------------
f
(1 row)
json_exists
-------------
f
(1 row)
isn't it supposed to return "true" as json in input is matching with both the condition dept_id and salary?
Hi Himanshu,
On Tue, Mar 12, 2024 at 6:42 PM Himanshu Upadhyaya
<upadhyaya.himanshu@gmail.com> wrote:
>
> Hi,
>
> wanted to share the below case:
>
> ‘postgres[146443]=#’SELECT JSON_EXISTS(jsonb '{"customer_name": "test", "salary":1000, "department_id":1}', '$.* ?
(@==$dept_id && @ == $sal)' PASSING 1000 AS sal, 1 as dept_id);
> json_exists
> -------------
> f
> (1 row)
>
> isn't it supposed to return "true" as json in input is matching with both the condition dept_id and salary?
I think you meant to use || in your condition, not &&, because 1000 != 1.
See:
SELECT JSON_EXISTS(jsonb '{"customer_name": "test", "salary":1000,
"department_id":1}', '$.* ? (@ == $dept_id || @ == $sal)' PASSING 1000
AS sal, 1 as dept_id);
json_exists
-------------
t
(1 row)
Or you could've written the query as:
SELECT JSON_EXISTS(jsonb '{"customer_name": "test", "salary":1000,
"department_id":1}', '$ ? (@.department_id == $dept_id && @.salary ==
$sal)' PASSING 1000 AS sal, 1 as dept_id);
json_exists
-------------
t
(1 row)
Does that make sense?
In any case, JSON_EXISTS() added by the patch here returns whatever
the jsonpath executor returns. The latter is not touched by this
patch. PASSING args, which this patch adds, seem to be working
correctly too.
--
Thanks, Amit Langote
About 0002:
I think we should just drop it. Look at the changes it produces in the
plans for aliases XMLTABLE:
> @@ -1556,7 +1556,7 @@ SELECT f.* FROM xmldata, LATERAL xmltable('/ROWS/ROW[COUNTRY_NAME="Japan" or COU
> Output: f."COUNTRY_NAME", f."REGION_ID"
> -> Seq Scan on public.xmldata
> Output: xmldata.data
> - -> Table Function Scan on "xmltable" f
> + -> Table Function Scan on "XMLTABLE" f
> Output: f."COUNTRY_NAME", f."REGION_ID"
> Table Function Call: XMLTABLE(('/ROWS/ROW[COUNTRY_NAME="Japan" or COUNTRY_NAME="India"]'::text) PASSING
(xmldata.data)COLUMNS "COUNTRY_NAME" text, "REGION_ID" integer)
> Filter: (f."COUNTRY_NAME" = 'Japan'::text)
Here in text-format EXPLAIN, we already have the alias next to the
"xmltable" moniker, when an alias is present. This matches the
query itself as well as the labels used in the "Output:" display.
If an alias is not present, then this says just 'Table Function Scan on "xmltable"'
and the rest of the plans refers to this as "xmltable", so it's also
fine.
> @@ -1591,7 +1591,7 @@ SELECT f.* FROM xmldata, LATERAL xmltable('/ROWS/ROW[COUNTRY_NAME="Japan" or COU
> "Parent Relationship": "Inner",
+
> "Parallel Aware": false,
+
> "Async Capable": false,
+
> - "Table Function Name": "xmltable",
+
> + "Table Function Name": "XMLTABLE",
+
> "Alias": "f",
+
> "Output": ["f.\"COUNTRY_NAME\"", "f.\"REGION_ID\""],
+
> "Table Function Call": "XMLTABLE(('/ROWS/ROW[COUNTRY_NAME=\"Japan\" or COUNTRY_NAME=\"India\"]'::text)
PASSING(xmldata.data) COLUMNS \"COUNTRY_NAME\" text, \"REGION_ID\" integer)",+
This is the JSON-format explain. Notice that the "Alias" member already
shows the alias "f", so the only thing this change is doing is
uppercasing the "xmltable" to "XMLTABLE". We're not really achieving
anything here.
I think the only salvageable piece from this, **if anything**, is making
the "xmltable" literal string into uppercase. That might bring a little
clarity to the fact that this is a keyword and not a user-introduced
name.
In your 0003 I think this would only have relevance in this query,
+-- JSON_TABLE() with alias
+EXPLAIN (COSTS OFF, VERBOSE)
+SELECT * FROM
+ JSON_TABLE(
+ jsonb 'null', 'lax $[*]' PASSING 1 + 2 AS a, json '"foo"' AS "b c"
+ COLUMNS (
+ id FOR ORDINALITY,
+ "int" int PATH '$',
+ "text" text PATH '$'
+ )) json_table_func;
+ QUERY PLAN
+--------------------------------------------------------------------------------------------------------------------------------------------------------------
----------------------------------------------------------
+ Table Function Scan on "JSON_TABLE" json_table_func
+ Output: id, "int", text
+ Table Function Call: JSON_TABLE('null'::jsonb, '$[*]' AS json_table_path_0 PASSING 3 AS a, '"foo"'::jsonb AS "b c"
COLUMNS(id FOR ORDINALITY, "int" integer PATH '$', text text PATH '$') PLAN (json_table_path_0))
+(3 rows)
and I'm curious to see what this would output if this was to be run
without the 0002 patch. If I understand things correctly, the alias
would be displayed anyway, meaning 0002 doesn't get us anything.
Please do add a test with EXPLAIN (FORMAT JSON) in 0003.
Thanks
--
Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/
"La vida es para el que se aventura"
On Tue, Mar 12, 2024 at 5:37 PM Amit Langote <amitlangote09@gmail.com> wrote:
SELECT JSON_EXISTS(jsonb '{"customer_name": "test", "salary":1000,
"department_id":1}', '$ ? (@.department_id == $dept_id && @.salary ==
$sal)' PASSING 1000 AS sal, 1 as dept_id);
json_exists
-------------
t
(1 row)
Does that make sense?
Yes, got it. Thanks for the clarification.
one more question...
SELECT JSON_value(NULL::int, '$' returning int);
ERROR: cannot use non-string types with implicit FORMAT JSON clause
LINE 1: SELECT JSON_value(NULL::int, '$' returning int);
^
SELECT JSON_query(NULL::int, '$' returning int);
ERROR: cannot use non-string types with implicit FORMAT JSON clause
LINE 1: SELECT JSON_query(NULL::int, '$' returning int);
^
SELECT * FROM JSON_TABLE(NULL::int, '$' COLUMNS (foo text));
ERROR: cannot use non-string types with implicit FORMAT JSON clause
LINE 1: SELECT * FROM JSON_TABLE(NULL::int, '$' COLUMNS (foo text));
^
SELECT JSON_value(NULL::text, '$' returning int);
ERROR: JSON_VALUE() is not yet implemented for the json type
LINE 1: SELECT JSON_value(NULL::text, '$' returning int);
^
HINT: Try casting the argument to jsonb
SELECT JSON_query(NULL::text, '$' returning int);
ERROR: JSON_QUERY() is not yet implemented for the json type
LINE 1: SELECT JSON_query(NULL::text, '$' returning int);
^
HINT: Try casting the argument to jsonb
in all these cases, the error message seems strange.
we already mentioned:
<note>
<para>
SQL/JSON query functions currently only accept values of the
<type>jsonb</type> type, because the SQL/JSON path language only
supports those, so it might be necessary to cast the
<replaceable>context_item</replaceable> argument of these functions to
<type>jsonb</type>.
</para>
</note>
we can simply say, only accept the first argument to be jsonb data type.
On Mon, Mar 11, 2024 at 11:30 AM jian he <jian.universality@gmail.com> wrote:
>
> On Sun, Mar 10, 2024 at 10:57 PM jian he <jian.universality@gmail.com> wrote:
> >
> > one more issue.
>
> Hi
> one more documentation issue.
> after applied V42, 0001 to 0003,
> there are 11 appearance of `FORMAT JSON` in functions-json.html
> still not a single place explained what it is for.
>
> json_query ( context_item, path_expression [ PASSING { value AS
> varname } [, ...]] [ RETURNING data_type [ FORMAT JSON [ ENCODING UTF8
> ] ] ] [ { WITHOUT | WITH { CONDITIONAL | [UNCONDITIONAL] } } [ ARRAY ]
> WRAPPER ] [ { KEEP | OMIT } QUOTES [ ON SCALAR STRING ] ] [ { ERROR |
> NULL | EMPTY { [ ARRAY ] | OBJECT } | DEFAULT expression } ON EMPTY ]
> [ { ERROR | NULL | EMPTY { [ ARRAY ] | OBJECT } | DEFAULT expression }
> ON ERROR ])
>
> FORMAT JSON seems just a syntax sugar or for compatibility in json_query.
> but it returns an error when the returning type category is not
> TYPCATEGORY_STRING.
>
> for example, even the following will return an error.
> `
> CREATE TYPE regtest_comptype AS (b text);
> SELECT JSON_QUERY(jsonb '{"a":{"b":"c"}}', '$.a' RETURNING
> regtest_comptype format json);
> `
>
> seems only types in[0] will not generate an error, when specifying
> FORMAT JSON in JSON_QUERY.
>
> so it actually does something, not a syntax sugar?
>
SELECT * FROM JSON_TABLE(jsonb'[{"aaa": 123}]', 'lax $[*]' COLUMNS
(js2 text format json PATH '$' omit quotes));
SELECT * FROM JSON_TABLE(jsonb'[{"aaa": 123}]', 'lax $[*]' COLUMNS
(js2 text format json PATH '$' keep quotes));
SELECT * FROM JSON_TABLE(jsonb'[{"aaa": 123}]', 'lax $[*]' COLUMNS
(js2 text PATH '$' keep quotes)); -- JSON_QUERY_OP
SELECT * FROM JSON_TABLE(jsonb'[{"aaa": 123}]', 'lax $[*]' COLUMNS
(js2 text PATH '$' omit quotes)); -- JSON_QUERY_OP
SELECT * FROM JSON_TABLE(jsonb'[{"aaa": 123}]', 'lax $[*]' COLUMNS
(js2 text PATH '$')); -- JSON_VALUE_OP
SELECT * FROM JSON_TABLE(jsonb'[{"aaa": 123}]', 'lax $[*]' COLUMNS
(js2 json PATH '$')); -- JSON_QUERY_OP
comparing these queries, I think 'FORMAT JSON' main usage is in json_table.
CREATE TYPE regtest_comptype AS (b text);
SELECT JSON_QUERY(jsonb '{"a":{"b":"c"}}', '$.a' RETURNING
regtest_comptype format json);
ERROR: cannot use JSON format with non-string output types
LINE 1: ..."a":{"b":"c"}}', '$.a' RETURNING regtest_comptype format jso...
^
the error message is not good, but that's a minor issue. we can pursue it later.
-----------------------------------------------------------------------------------------
SELECT JSON_QUERY(jsonb 'true', '$' RETURNING int KEEP QUOTES );
SELECT JSON_QUERY(jsonb 'true', '$' RETURNING int omit QUOTES );
SELECT JSON_VALUE(jsonb 'true', '$' RETURNING int);
the third query returns integer 1, not sure this is the desired behavior.
it obviously has an implication for json_table.
-----------------------------------------------------------------------------------------
in jsonb_get_element, we have something like:
if (jbvp->type == jbvBinary)
{
container = jbvp->val.binary.data;
have_object = JsonContainerIsObject(container);
have_array = JsonContainerIsArray(container);
Assert(!JsonContainerIsScalar(container));
}
+ res = JsonValueListHead(&found);
+ if (res->type == jbvBinary && JsonContainerIsScalar(res->val.binary.data))
+ JsonbExtractScalar(res->val.binary.data, res);
So in JsonPathValue, the above (res->type == jbvBinary) is unreachable?
also see the comment in jbvBinary.
maybe we can just simply do:
if (res->type == jbvBinary)
Assert(!JsonContainerIsScalar(res->val.binary.data));
-----------------------------------------------------------------------------------------
+<synopsis>
+JSON_TABLE (
+ <replaceable>context_item</replaceable>,
<replaceable>path_expression</replaceable> <optional> AS
<replaceable>json_path_name</replaceable> </optional> <optional>
PASSING { <replaceable>value</replaceable> AS
<replaceable>varname</replaceable> } <optional>, ...</optional>
</optional>
+ COLUMNS ( <replaceable
class="parameter">json_table_column</replaceable> <optional>,
...</optional> )
+ <optional> { <literal>ERROR</literal> | <literal>EMPTY</literal> }
<literal>ON ERROR</literal> </optional>
+ <optional>
+ PLAN ( <replaceable class="parameter">json_table_plan</replaceable> ) |
+ PLAN DEFAULT ( { INNER | OUTER } <optional> , { CROSS | UNION } </optional>
+ | { CROSS | UNION } <optional> , { INNER | OUTER }
</optional> )
+ </optional>
+)
based on the synopsis
the following query should not be allowed?
SELECT *FROM (VALUES ('"11"'), ('"err"')) vals(js)
LEFT OUTER JOIN JSON_TABLE(vals.js::jsonb, '$' COLUMNS (a int PATH
'$') default '11' ON ERROR) jt ON true;
aslo the synopsis need to reflect case like:
SELECT *FROM (VALUES ('"11"'), ('"err"')) vals(js)
LEFT OUTER JOIN JSON_TABLE(vals.js::jsonb, '$' COLUMNS (a int PATH
'$') NULL ON ERROR) jt ON true;
On Wed, Mar 13, 2024 at 5:47 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote:
> About 0002:
>
> I think we should just drop it. Look at the changes it produces in the
> plans for aliases XMLTABLE:
>
> > @@ -1556,7 +1556,7 @@ SELECT f.* FROM xmldata, LATERAL xmltable('/ROWS/ROW[COUNTRY_NAME="Japan" or COU
> > Output: f."COUNTRY_NAME", f."REGION_ID"
> > -> Seq Scan on public.xmldata
> > Output: xmldata.data
> > - -> Table Function Scan on "xmltable" f
> > + -> Table Function Scan on "XMLTABLE" f
> > Output: f."COUNTRY_NAME", f."REGION_ID"
> > Table Function Call: XMLTABLE(('/ROWS/ROW[COUNTRY_NAME="Japan" or COUNTRY_NAME="India"]'::text) PASSING
(xmldata.data)COLUMNS "COUNTRY_NAME" text, "REGION_ID" integer)
> > Filter: (f."COUNTRY_NAME" = 'Japan'::text)
>
> Here in text-format EXPLAIN, we already have the alias next to the
> "xmltable" moniker, when an alias is present. This matches the
> query itself as well as the labels used in the "Output:" display.
> If an alias is not present, then this says just 'Table Function Scan on "xmltable"'
> and the rest of the plans refers to this as "xmltable", so it's also
> fine.
>
> > @@ -1591,7 +1591,7 @@ SELECT f.* FROM xmldata, LATERAL xmltable('/ROWS/ROW[COUNTRY_NAME="Japan" or COU
> > "Parent Relationship": "Inner",
+
> > "Parallel Aware": false,
+
> > "Async Capable": false,
+
> > - "Table Function Name": "xmltable",
+
> > + "Table Function Name": "XMLTABLE",
+
> > "Alias": "f",
+
> > "Output": ["f.\"COUNTRY_NAME\"", "f.\"REGION_ID\""],
+
> > "Table Function Call": "XMLTABLE(('/ROWS/ROW[COUNTRY_NAME=\"Japan\" or COUNTRY_NAME=\"India\"]'::text)
PASSING(xmldata.data) COLUMNS \"COUNTRY_NAME\" text, \"REGION_ID\" integer)",+
>
> This is the JSON-format explain. Notice that the "Alias" member already
> shows the alias "f", so the only thing this change is doing is
> uppercasing the "xmltable" to "XMLTABLE". We're not really achieving
> anything here.
>
> I think the only salvageable piece from this, **if anything**, is making
> the "xmltable" literal string into uppercase. That might bring a little
> clarity to the fact that this is a keyword and not a user-introduced
> name.
>
>
> In your 0003 I think this would only have relevance in this query,
>
> +-- JSON_TABLE() with alias
> +EXPLAIN (COSTS OFF, VERBOSE)
> +SELECT * FROM
> + JSON_TABLE(
> + jsonb 'null', 'lax $[*]' PASSING 1 + 2 AS a, json '"foo"' AS "b c"
> + COLUMNS (
> + id FOR ORDINALITY,
> + "int" int PATH '$',
> + "text" text PATH '$'
> + )) json_table_func;
> + QUERY PLAN
>
>
+--------------------------------------------------------------------------------------------------------------------------------------------------------------
> ----------------------------------------------------------
> + Table Function Scan on "JSON_TABLE" json_table_func
> + Output: id, "int", text
> + Table Function Call: JSON_TABLE('null'::jsonb, '$[*]' AS json_table_path_0 PASSING 3 AS a, '"foo"'::jsonb AS "b
c"COLUMNS (id FOR ORDINALITY, "int" integer PATH '$', text text PATH '$') PLAN (json_table_path_0))
> +(3 rows)
>
> and I'm curious to see what this would output if this was to be run
> without the 0002 patch. If I understand things correctly, the alias
> would be displayed anyway, meaning 0002 doesn't get us anything.
Patch 0002 came about because old versions of json_table patch were
changing ExplainTargetRel() incorrectly to use rte->tablefunc to get
the function type to set objectname, but rte->tablefunc is NULL
because add_rte_to_flat_rtable() zaps it. You pointed that out in
[1].
However, we can get the TableFunc to get the function type from the
Plan node instead of the RTE, as follows:
- Assert(rte->rtekind == RTE_TABLEFUNC);
- objectname = "xmltable";
- objecttag = "Table Function Name";
+ {
+ TableFunc *tablefunc = ((TableFuncScan *) plan)->tablefunc;
+
+ Assert(rte->rtekind == RTE_TABLEFUNC);
+ switch (tablefunc->functype)
+ {
+ case TFT_XMLTABLE:
+ objectname = "xmltable";
+ break;
+ case TFT_JSON_TABLE:
+ objectname = "json_table";
+ break;
+ default:
+ elog(ERROR, "invalid TableFunc type %d",
+ (int) tablefunc->functype);
+ }
+ objecttag = "Table Function Name";
+ }
So that gets us what we need here.
Given that, 0002 does seem like an overkill and unnecessary, so I'll drop it.
> Please do add a test with EXPLAIN (FORMAT JSON) in 0003.
OK, will do.
--
Thanks, Amit Langote
[1] https://www.postgresql.org/message-id/202401181711.qxjxpnl3ohnw%40alvherre.pgsql
I have tested a nested case but why is the negative number allowed in subscript(NESTED '$.phones[-1]'COLUMNS), it should error out if the number is negative.
‘postgres[170683]=#’SELECT * FROM JSON_TABLE(jsonb '{
‘...>’ "id" : "0.234567897890",
‘...>’ "name" : { "first":"Johnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnn", "last":"Doe" },
‘...>’ "phones" : [{"type":"home", "number":"555-3762"},
‘...>’ {"type":"work", "number":"555-7252", "test":123}]}',
‘...>’ '$'
‘...>’ COLUMNS(
‘...>’ id numeric(2,2) PATH 'lax $.id',
‘...>’ last_name varCHAR(10) PATH 'lax $.name.last', first_name VARCHAR(10) PATH 'lax $.name.first',
‘...>’ NESTED '$.phones[-1]'COLUMNS (
‘...>’ "type" VARCHAR(10),
‘...>’ "number" VARCHAR(10)
‘...>’ )
‘...>’ )
‘...>’ ) as t;
id | last_name | first_name | type | number
------+-----------+------------+------+--------
0.23 | Doe | Johnnnnnnn | |
(1 row)
‘...>’ "id" : "0.234567897890",
‘...>’ "name" : { "first":"Johnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnn", "last":"Doe" },
‘...>’ "phones" : [{"type":"home", "number":"555-3762"},
‘...>’ {"type":"work", "number":"555-7252", "test":123}]}',
‘...>’ '$'
‘...>’ COLUMNS(
‘...>’ id numeric(2,2) PATH 'lax $.id',
‘...>’ last_name varCHAR(10) PATH 'lax $.name.last', first_name VARCHAR(10) PATH 'lax $.name.first',
‘...>’ NESTED '$.phones[-1]'COLUMNS (
‘...>’ "type" VARCHAR(10),
‘...>’ "number" VARCHAR(10)
‘...>’ )
‘...>’ )
‘...>’ ) as t;
id | last_name | first_name | type | number
------+-----------+------------+------+--------
0.23 | Doe | Johnnnnnnn | |
(1 row)
Thanks,
Himanshu
Himanshu,
On Mon, Mar 18, 2024 at 4:57 PM Himanshu Upadhyaya
<upadhyaya.himanshu@gmail.com> wrote:
> I have tested a nested case but why is the negative number allowed in subscript(NESTED '$.phones[-1]'COLUMNS), it
shoulderror out if the number is negative.
>
> ‘postgres[170683]=#’SELECT * FROM JSON_TABLE(jsonb '{
> ‘...>’ "id" : "0.234567897890",
> ‘...>’ "name" : { "first":"Johnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnn", "last":"Doe" },
> ‘...>’ "phones" : [{"type":"home", "number":"555-3762"},
> ‘...>’ {"type":"work", "number":"555-7252", "test":123}]}',
> ‘...>’ '$'
> ‘...>’ COLUMNS(
> ‘...>’ id numeric(2,2) PATH 'lax $.id',
> ‘...>’ last_name varCHAR(10) PATH 'lax $.name.last', first_name VARCHAR(10) PATH 'lax
$.name.first',
> ‘...>’ NESTED '$.phones[-1]'COLUMNS (
> ‘...>’ "type" VARCHAR(10),
> ‘...>’ "number" VARCHAR(10)
> ‘...>’ )
> ‘...>’ )
> ‘...>’ ) as t;
> id | last_name | first_name | type | number
> ------+-----------+------------+------+--------
> 0.23 | Doe | Johnnnnnnn | |
> (1 row)
You're not getting an error because the default mode of handling
structural errors in SQL/JSON path expressions is "lax". If you say
"strict" in the path string, you will get an error:
SELECT * FROM JSON_TABLE(jsonb '{
"id" : "0.234567897890",
"name" : {
"first":"Johnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnn",
"last":"Doe" },
"phones" : [{"type":"home", "number":"555-3762"},
{"type":"work", "number":"555-7252", "test":123}]}',
'$'
COLUMNS(
id numeric(2,2) PATH 'lax $.id',
last_name varCHAR(10) PATH 'lax $.name.last',
first_name VARCHAR(10) PATH 'lax $.name.first',
NESTED 'strict $.phones[-1]'COLUMNS (
"type" VARCHAR(10),
"number" VARCHAR(10)
)
) error on error
) as t;
ERROR: jsonpath array subscript is out of bounds
--
Thanks, Amit Langote
On Mon, Mar 18, 2024 at 3:33 PM Amit Langote <amitlangote09@gmail.com> wrote:
Himanshu,
On Mon, Mar 18, 2024 at 4:57 PM Himanshu Upadhyaya
<upadhyaya.himanshu@gmail.com> wrote:
> I have tested a nested case but why is the negative number allowed in subscript(NESTED '$.phones[-1]'COLUMNS), it should error out if the number is negative.
>
> ‘postgres[170683]=#’SELECT * FROM JSON_TABLE(jsonb '{
> ‘...>’ "id" : "0.234567897890",
> ‘...>’ "name" : { "first":"Johnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnn", "last":"Doe" },
> ‘...>’ "phones" : [{"type":"home", "number":"555-3762"},
> ‘...>’ {"type":"work", "number":"555-7252", "test":123}]}',
> ‘...>’ '$'
> ‘...>’ COLUMNS(
> ‘...>’ id numeric(2,2) PATH 'lax $.id',
> ‘...>’ last_name varCHAR(10) PATH 'lax $.name.last', first_name VARCHAR(10) PATH 'lax $.name.first',
> ‘...>’ NESTED '$.phones[-1]'COLUMNS (
> ‘...>’ "type" VARCHAR(10),
> ‘...>’ "number" VARCHAR(10)
> ‘...>’ )
> ‘...>’ )
> ‘...>’ ) as t;
> id | last_name | first_name | type | number
> ------+-----------+------------+------+--------
> 0.23 | Doe | Johnnnnnnn | |
> (1 row)
You're not getting an error because the default mode of handling
structural errors in SQL/JSON path expressions is "lax". If you say
"strict" in the path string, you will get an error:
ok, got it, thanks.
SELECT * FROM JSON_TABLE(jsonb '{
"id" : "0.234567897890",
"name" : {
"first":"Johnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnn",
"last":"Doe" },
"phones" : [{"type":"home", "number":"555-3762"},
{"type":"work", "number":"555-7252", "test":123}]}',
'$'
COLUMNS(
id numeric(2,2) PATH 'lax $.id',
last_name varCHAR(10) PATH 'lax $.name.last',
first_name VARCHAR(10) PATH 'lax $.name.first',
NESTED 'strict $.phones[-1]'COLUMNS (
"type" VARCHAR(10),
"number" VARCHAR(10)
)
) error on error
) as t;
ERROR: jsonpath array subscript is out of bounds
--
Thanks, Amit Langote
Hi,
On Thu, Mar 7, 2024 at 9:06 PM Amit Langote <amitlangote09@gmail.com> wrote:
> This boils down to the difference in the cast expression chosen to
> convert the source value to int in the two cases.
>
> The case where the source value has no quotes, the chosen cast
> expression is a FuncExpr for function numeric_int4(), which has no way
> to suppress errors. When the source value has quotes, the cast
> expression is a CoerceViaIO expression, which can suppress the error.
> The default behavior is to suppress the error and return NULL, so the
> correct behavior is when the source value has quotes.
>
> I think we'll need either:
>
> * fix the code in 0001 to avoid getting numeric_int4() in this case,
> and generally cast functions that don't have soft-error handling
> support, in favor of using IO coercion.
> * fix FuncExpr (like CoerceViaIO) to respect SQL/JSON's request to
> suppress errors and fix downstream functions like numeric_int4() to
> comply by handling errors softly.
>
> I'm inclined to go with the 1st option as we already have the
> infrastructure in place -- input functions can all handle errors
> softly.
I've adjusted the coercion-handling code to deal with this and similar
cases to use coercion by calling the target type's input function in
more cases. The resulting refactoring allowed me to drop a bunch of
code and node structs, notably, the JsonCoercion and JsonItemCoercion
nodes. Going with input function based coercion as opposed to using
casts means the coercion may fail in more cases than before but I
think that's acceptable. For example, the following case did not fail
before because they'd use numeric_int() cast function to convert 1.234
to an integer:
select json_value('{"a": 1.234}', '$.a' returning int error on error);
ERROR: invalid input syntax for type integer: "1.234"
It is same error as this case, where the source numerical value is
specified as a string:
select json_value('{"a": "1.234"}', '$.a' returning int error on error);
ERROR: invalid input syntax for type integer: "1.234"
I had hoped to get rid of all instances of using casts and standardize
on coercion at runtime using input functions and json_populate_type(),
but there are a few cases where casts produce saner results and also
harmless (error-safe), such as cases where the target types are
domains or are types with typmod.
I've also tried to address most of Jian He's comments and a bunch of
cleanups of my own. Attaching 0002 as the delta over v42 containing
all of those changes.
I intend to commit 0001+0002 after a bit more polishing.
--
Thanks, Amit Langote
Вложения
On Tue, Mar 19, 2024 at 6:46 PM Amit Langote <amitlangote09@gmail.com> wrote:
>
> I intend to commit 0001+0002 after a bit more polishing.
>
V43 is far more intuitive! thanks!
if (isnull ||
(exprType(expr) == JSONBOID &&
btype == default_behavior))
coerce = true;
else
coerced_expr =
coerce_to_target_type(pstate, expr, exprType(expr),
returning->typid, returning->typmod,
COERCION_EXPLICIT, COERCE_EXPLICIT_CAST,
exprLocation((Node *) behavior));
obviously, there are cases where "coerce" is false, and "coerced_expr"
is not null.
so I think the bool "coerce" variable naming is not very intuitive.
maybe we can add some comments or change to a better name.
JsonPathVariableEvalContext
JsonPathVarCallback
JsonItemType
JsonExprPostEvalState
these should remove from src/tools/pgindent/typedefs.list
+/*
+ * Performs JsonPath{Exists|Query|Value}() for a given context_item and
+ * jsonpath.
+ *
+ * Result is set in *op->resvalue and *op->resnull. Return value is the
+ * step address to be performed next.
+ *
+ * On return, JsonExprPostEvalState is populated with the following details:
+ * - error.value: true if an error occurred during JsonPath evaluation
+ * - empty.value: true if JsonPath{Query|Value}() found no matching item
+ *
+ * No return if the ON ERROR/EMPTY behavior is ERROR.
+ */
+int
+ExecEvalJsonExprPath(ExprState *state, ExprEvalStep *op,
+ ExprContext *econtext)
" No return if the ON ERROR/EMPTY behavior is ERROR." is wrong?
counter example:
SELECT JSON_QUERY(jsonb '{"a":[12,2]}', '$.a' RETURNING int4RANGE omit
quotes error on error);
also "JsonExprPostEvalState" does not exist any more.
overall feel like ExecEvalJsonExprPath comments need to be rephrased.
minor issues I found while looking through it.
other than these issues, looks good!
/*
* Convert the a given JsonbValue to its C string representation
*
* Returns the string as a Datum setting *resnull if the JsonbValue is a
* a jbvNull.
*/
static char *
ExecGetJsonValueItemString(JsonbValue *item, bool *resnull)
{
}
I think the comments are not right?
/*
* Checks if the coercion evaluation led to an error. If an error did occur,
* this sets post_eval->error to trigger the ON ERROR handling steps.
*/
void
ExecEvalJsonCoercionFinish(ExprState *state, ExprEvalStep *op)
{
}
these comments on ExecEvalJsonCoercionFinish also need to be updated?
+ /*
+ * Coerce the result value by calling the input function coercion.
+ * *op->resvalue must point to C string in this case.
+ */
+ if (!*op->resnull && jsexpr->use_io_coercion)
+ {
+ FunctionCallInfo fcinfo;
+
+ fcinfo = jsestate->input_fcinfo;
+ Assert(fcinfo != NULL);
+ Assert(val_string != NULL);
+ fcinfo->args[0].value = PointerGetDatum(val_string);
+ fcinfo->args[0].isnull = *op->resnull;
+ /* second and third arguments are already set up */
+
+ fcinfo->isnull = false;
+ *op->resvalue = FunctionCallInvoke(fcinfo);
+ if (SOFT_ERROR_OCCURRED(&jsestate->escontext))
+ error = true;
+
+ jump_eval_coercion = -1;
+ }
+ /* second and third arguments are already set up */
change to
/* second and third arguments are already set up in ExecInitJsonExpr */
would be great.
commit message
<<<<
All of these functions only operate on jsonb values. The workaround
for now is to cast the argument to jsonb.
<<<<
should be removed?
+ case T_JsonFuncExpr:
+ {
+ JsonFuncExpr *jfe = (JsonFuncExpr *) node;
+
+ if (WALK(jfe->context_item))
+ return true;
+ if (WALK(jfe->pathspec))
+ return true;
+ if (WALK(jfe->passing))
+ return true;
+ if (jfe->output && WALK(jfe->output))
+ return true;
+ if (jfe->on_empty)
+ return true;
+ if (jfe->on_error)
+ return true;
+ }
+ if (jfe->output && WALK(jfe->output))
+ return true;
can be simplified:
+ if (WALK(jfe->output))
+ return true;
looking at documentation again. one very minor question (issue) + <para> + The <literal>ON EMPTY</literal> clause specifies the behavior if the + <replaceable>path_expression</replaceable> yields no value at all; the + default when <literal>ON EMPTY</literal> is not specified is to return + a null value. + </para> I think it should be: applying <replaceable>path_expression</replaceable> or evaluating <replaceable>path_expression</replaceable> not "the <replaceable>path_expression</replaceable>" ?
On Wed, Mar 20, 2024 at 8:46 PM jian he <jian.universality@gmail.com> wrote: > > looking at documentation again. > one very minor question (issue) > > + <para> > + The <literal>ON EMPTY</literal> clause specifies the behavior if the > + <replaceable>path_expression</replaceable> yields no value at all; the > + default when <literal>ON EMPTY</literal> is not specified is to return > + a null value. > + </para> > > I think it should be: > > applying <replaceable>path_expression</replaceable> > or > evaluating <replaceable>path_expression</replaceable> > > not "the <replaceable>path_expression</replaceable>" > ? Thanks. Fixed this, the other issues you mentioned, a bunch of typos and obsolete comments, etc. I'll push 0001 tomorrow. -- Thanks, Amit Langote
Вложения
On Wed, Mar 20, 2024 at 9:53 PM Amit Langote <amitlangote09@gmail.com> wrote: > I'll push 0001 tomorrow. Pushed that one. Here's the remaining JSON_TABLE() patch. -- Thanks, Amit Langote
Вложения
At Wed, 20 Mar 2024 21:53:52 +0900, Amit Langote <amitlangote09@gmail.com> wrote in
> I'll push 0001 tomorrow.
This patch (v44-0001-Add-SQL-JSON-query-functions.patch) introduced the following new erro message:
+ errmsg("can only specify constant, non-aggregate"
+ " function, or operator expression for"
+ " DEFAULT"),
I believe that our convention here is to write an error message in a
single string literal, not split into multiple parts, for better
grep'ability.
regards.
--
Kyotaro Horiguchi
NTT Open Source Software Center
Hi Horiguchi-san,
On Fri, Mar 22, 2024 at 9:51 AM Kyotaro Horiguchi
<horikyota.ntt@gmail.com> wrote:
> At Wed, 20 Mar 2024 21:53:52 +0900, Amit Langote <amitlangote09@gmail.com> wrote in
> > I'll push 0001 tomorrow.
>
> This patch (v44-0001-Add-SQL-JSON-query-functions.patch) introduced the following new erro message:
>
> + errmsg("can only specify constant, non-aggregate"
> + " function, or operator expression for"
> + " DEFAULT"),
>
> I believe that our convention here is to write an error message in a
> single string literal, not split into multiple parts, for better
> grep'ability.
Thanks for the heads up.
My bad, will push a fix shortly.
--
Thanks, Amit Langote
At Fri, 22 Mar 2024 11:44:08 +0900, Amit Langote <amitlangote09@gmail.com> wrote in > Thanks for the heads up. > > My bad, will push a fix shortly. No problem. Thank you for the prompt correction. regards. -- Kyotaro Horiguchi NTT Open Source Software Center
On Fri, Mar 22, 2024 at 12:08 AM Amit Langote <amitlangote09@gmail.com> wrote:
>
> On Wed, Mar 20, 2024 at 9:53 PM Amit Langote <amitlangote09@gmail.com> wrote:
> > I'll push 0001 tomorrow.
>
> Pushed that one. Here's the remaining JSON_TABLE() patch.
>
hi. minor issues i found json_table patch.
+ if (!IsA($5, A_Const) ||
+ castNode(A_Const, $5)->val.node.type != T_String)
+ ereport(ERROR,
+ errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
+ errmsg("only string constants are supported in JSON_TABLE"
+ " path specification"),
+ parser_errposition(@5));
as mentioned in upthread, this error message should be one line.
+const TableFuncRoutine JsonbTableRoutine =
+{
+ JsonTableInitOpaque,
+ JsonTableSetDocument,
+ NULL,
+ NULL,
+ NULL,
+ JsonTableFetchRow,
+ JsonTableGetValue,
+ JsonTableDestroyOpaque
+};
should be:
const TableFuncRoutine JsonbTableRoutine =
{
.InitOpaque = JsonTableInitOpaque,
.SetDocument = JsonTableSetDocument,
.SetNamespace = NULL,
.SetRowFilter = NULL,
.SetColumnFilter = NULL,
.FetchRow = JsonTableFetchRow,
.GetValue = JsonTableGetValue,
.DestroyOpaque = JsonTableDestroyOpaque
};
+/*
+ * JsonTablePathSpec
+ * untransformed specification of JSON path expression with an optional
+ * name
+ */
+typedef struct JsonTablePathSpec
+{
+ NodeTag type;
+
+ Node *string;
+ char *name;
+ int name_location;
+ int location; /* location of 'string' */
+} JsonTablePathSpec;
the comment still does not explain the distinction between "location"
and "name_location"?
JsonTablePathSpec needs to be added to typedefs.list.
JsonPathSpec should be removed from typedefs.list.
+/*
+ * JsonTablePlanType -
+ * flags for JSON_TABLE plan node types representation
+ */
+typedef enum JsonTablePlanType
+{
+ JSTP_DEFAULT,
+ JSTP_SIMPLE,
+ JSTP_JOINED,
+} JsonTablePlanType;
+
+/*
+ * JsonTablePlanJoinType -
+ * JSON_TABLE join types for JSTP_JOINED plans
+ */
+typedef enum JsonTablePlanJoinType
+{
+ JSTP_JOIN_INNER,
+ JSTP_JOIN_OUTER,
+ JSTP_JOIN_CROSS,
+ JSTP_JOIN_UNION,
+} JsonTablePlanJoinType;
I can guess the enum value meaning of JsonTablePlanJoinType,
but I can't guess the meaning of "JSTP_SIMPLE" or "JSTP_JOINED".
adding some comments in JsonTablePlanType would make it more clear.
I think I can understand JsonTableScanNextRow.
but i don't understand JsonTablePlanNextRow.
maybe we can add some comments on JsonTableJoinState.
+-- unspecified plan (outer, union)
+select
+ jt.*
+from
+ jsonb_table_test jtt,
+ json_table (
+ jtt.js,'strict $[*]' as p
+ columns (
+ n for ordinality,
+ a int path 'lax $.a' default -1 on empty,
+ nested path 'strict $.b[*]' as pb columns ( b int path '$' ),
+ nested path 'strict $.c[*]' as pc columns ( c int path '$' )
+ )
+ ) jt;
+ n | a | b | c
+---+----+---+----
+ 1 | 1 | |
+ 2 | 2 | 1 |
+ 2 | 2 | 2 |
+ 2 | 2 | 3 |
+ 2 | 2 | | 10
+ 2 | 2 | |
+ 2 | 2 | | 20
+ 3 | 3 | 1 |
+ 3 | 3 | 2 |
+ 4 | -1 | 1 |
+ 4 | -1 | 2 |
+(11 rows)
+
+-- default plan (outer, union)
+select
+ jt.*
+from
+ jsonb_table_test jtt,
+ json_table (
+ jtt.js,'strict $[*]' as p
+ columns (
+ n for ordinality,
+ a int path 'lax $.a' default -1 on empty,
+ nested path 'strict $.b[*]' as pb columns ( b int path '$' ),
+ nested path 'strict $.c[*]' as pc columns ( c int path '$' )
+ )
+ plan default (outer, union)
+ ) jt;
+ n | a | b | c
+---+----+---+----
+ 1 | 1 | |
+ 2 | 2 | 1 | 10
+ 2 | 2 | 1 |
+ 2 | 2 | 1 | 20
+ 2 | 2 | 2 | 10
+ 2 | 2 | 2 |
+ 2 | 2 | 2 | 20
+ 2 | 2 | 3 | 10
+ 2 | 2 | 3 |
+ 2 | 2 | 3 | 20
+ 3 | 3 | |
+ 4 | -1 | |
+(12 rows)
these two query results should be the same, if i understand it correctly.
On Tue, Mar 26, 2024 at 6:16 PM jian he <jian.universality@gmail.com> wrote: > > On Fri, Mar 22, 2024 at 12:08 AM Amit Langote <amitlangote09@gmail.com> wrote: > > > > On Wed, Mar 20, 2024 at 9:53 PM Amit Langote <amitlangote09@gmail.com> wrote: > > > I'll push 0001 tomorrow. > > > > Pushed that one. Here's the remaining JSON_TABLE() patch. > > hi. I don't fully understand all the code in json_table patch. maybe we can split it into several patches, like: * no nested json_table_column. * nested json_table_column, with PLAN DEFAULT * nested json_table_column, with PLAN ( json_table_plan ) i can understand the "no nested json_table_column" part, which seems to be how oracle[1] implemented it. I think we can make the "no nested json_table_column" part into v17. i am not sure about other complex parts. lack of comment, makes it kind of hard to fully understand. [1] https://docs.oracle.com/en/database/oracle/oracle-database/19/sqlrf/img_text/json_table.html +/* Reset context item of a scan, execute JSON path and reset a scan */ +static void +JsonTableResetContextItem(JsonTableScanState *scan, Datum item) +{ + MemoryContext oldcxt; + JsonPathExecResult res; + Jsonb *js = (Jsonb *) DatumGetJsonbP(item); + + JsonValueListClear(&scan->found); + + MemoryContextResetOnly(scan->mcxt); + + oldcxt = MemoryContextSwitchTo(scan->mcxt); + + res = executeJsonPath(scan->path, scan->args, + GetJsonPathVar, CountJsonPathVars, + js, scan->errorOnError, &scan->found, + false /* FIXME */ ); + + MemoryContextSwitchTo(oldcxt); + + if (jperIsError(res)) + { + Assert(!scan->errorOnError); + JsonValueListClear(&scan->found); /* EMPTY ON ERROR case */ + } + + JsonTableRescan(scan); +} "FIXME". set the last argument in executeJsonPath to true also works as expected. also there is no test related to the "FIXME" i am not 100% sure about the "FIXME". see demo (after set the executeJsonPath's "useTz" argument to true). create table ss(js jsonb); INSERT into ss select '{"a": "2018-02-21 12:34:56 +10"}'; INSERT into ss select '{"b": "2018-02-21 12:34:56 "}'; PREPARE q2 as SELECT jt.* FROM ss, JSON_TABLE(js, '$.a.datetime()' COLUMNS ("int7" timestamptz PATH '$')) jt; PREPARE qb as SELECT jt.* FROM ss, JSON_TABLE(js, '$.b.datetime()' COLUMNS ("tstz" timestamptz PATH '$')) jt; PREPARE q3 as SELECT jt.* FROM ss, JSON_TABLE(js, '$.a.datetime()' COLUMNS ("ts" timestamp PATH '$')) jt; begin; set time zone +10; EXECUTE q2; set time zone -10; EXECUTE q2; rollback; begin; set time zone +10; SELECT JSON_VALUE(js, '$.a' returning timestamptz) from ss; set time zone -10; SELECT JSON_VALUE(js, '$.a' returning timestamptz) from ss; rollback; --------------------------------------------------------------------- begin; set time zone +10; EXECUTE qb; set time zone -10; EXECUTE qb; rollback; begin; set time zone +10; SELECT JSON_VALUE(js, '$.b' returning timestamptz) from ss; set time zone -10; SELECT JSON_VALUE(js, '$.b' returning timestamptz) from ss; rollback; --------------------------------------------------------------------- begin; set time zone +10; EXECUTE q3; set time zone -10; EXECUTE q3; rollback; begin; set time zone +10; SELECT JSON_VALUE(js, '$.b' returning timestamp) from ss; set time zone -10; SELECT JSON_VALUE(js, '$.b' returning timestamp) from ss; rollback;
On Wed, Mar 27, 2024 at 12:42 PM jian he <jian.universality@gmail.com> wrote: > hi. > I don't fully understand all the code in json_table patch. > maybe we can split it into several patches, I'm working on exactly that atm. > like: > * no nested json_table_column. > * nested json_table_column, with PLAN DEFAULT > * nested json_table_column, with PLAN ( json_table_plan ) Yes, I think it will end up something like this. I'll try to post the breakdown tomorrow. -- Thanks, Amit Langote
On Wed, Mar 27, 2024 at 1:34 PM Amit Langote <amitlangote09@gmail.com> wrote: > On Wed, Mar 27, 2024 at 12:42 PM jian he <jian.universality@gmail.com> wrote: > > hi. > > I don't fully understand all the code in json_table patch. > > maybe we can split it into several patches, > > I'm working on exactly that atm. > > > like: > > * no nested json_table_column. > > * nested json_table_column, with PLAN DEFAULT > > * nested json_table_column, with PLAN ( json_table_plan ) > > Yes, I think it will end up something like this. I'll try to post the > breakdown tomorrow. Here's patch 1 for the time being that implements barebones JSON_TABLE(), that is, without NESTED paths/columns and PLAN clause. I've tried to shape the interfaces so that those features can be added in future commits without significant rewrite of the code that implements barebones JSON_TABLE() functionality. I'll know whether that's really the case when I rebase the full patch over it. I'm still reading and polishing it and would be happy to get feedback and testing. -- Thanks, Amit Langote
Вложения
On 2024-Mar-28, Amit Langote wrote: > Here's patch 1 for the time being that implements barebones > JSON_TABLE(), that is, without NESTED paths/columns and PLAN clause. > I've tried to shape the interfaces so that those features can be added > in future commits without significant rewrite of the code that > implements barebones JSON_TABLE() functionality. I'll know whether > that's really the case when I rebase the full patch over it. I think this barebones patch looks much closer to something that can be committed for pg17, given the current commitfest timeline. Maybe we should just slip NESTED and PLAN to pg18 to focus current efforts into getting the basic functionality in 17. When I looked at the JSON_TABLE patch last month, it appeared far too large to be reviewable in reasonable time. The fact that this split now exists gives me hope that we can get at least the first part of it. (A note that PLAN seems to correspond to separate features T824+T838, so leaving that one out would still let us claim T821 "Basic SQL/JSON query operators" ... however, the NESTED clause does not appear to be a separate SQL feature; in particular it does not appear to correspond to T827, though I may be reading the standard wrong. So if we don't have NESTED, apparently we could not claim to support T821.) -- Álvaro Herrera PostgreSQL Developer — https://www.EnterpriseDB.com/ "La fuerza no está en los medios físicos sino que reside en una voluntad indomable" (Gandhi)
On Thu, Mar 28, 2024 at 1:23 PM Amit Langote <amitlangote09@gmail.com> wrote:
>
> On Wed, Mar 27, 2024 at 1:34 PM Amit Langote <amitlangote09@gmail.com> wrote:
> > On Wed, Mar 27, 2024 at 12:42 PM jian he <jian.universality@gmail.com> wrote:
> > > hi.
> > > I don't fully understand all the code in json_table patch.
> > > maybe we can split it into several patches,
> >
> > I'm working on exactly that atm.
> >
> > > like:
> > > * no nested json_table_column.
> > > * nested json_table_column, with PLAN DEFAULT
> > > * nested json_table_column, with PLAN ( json_table_plan )
> >
> > Yes, I think it will end up something like this. I'll try to post the
> > breakdown tomorrow.
>
> Here's patch 1 for the time being that implements barebones
> JSON_TABLE(), that is, without NESTED paths/columns and PLAN clause.
> I've tried to shape the interfaces so that those features can be added
> in future commits without significant rewrite of the code that
> implements barebones JSON_TABLE() functionality. I'll know whether
> that's really the case when I rebase the full patch over it.
>
> I'm still reading and polishing it and would be happy to get feedback
> and testing.
>
+static void
+JsonValueListClear(JsonValueList *jvl)
+{
+ jvl->singleton = NULL;
+ jvl->list = NULL;
+}
jvl->list is a List structure, do we need to set it like "jvl->list = NIL"?
+ if (jperIsError(res))
+ {
+ /* EMPTY ON ERROR case */
+ Assert(!planstate->plan->errorOnError);
+ JsonValueListClear(&planstate->found);
+ }
i am not sure the comment is right.
`SELECT * FROM JSON_TABLE(jsonb'"1.23"', 'strict $.a' COLUMNS (js2 int
PATH '$') );`
will execute jperIsError branch.
also
SELECT * FROM JSON_TABLE(jsonb'"1.23"', 'strict $.a' COLUMNS (js2 int
PATH '$') default '1' on error);
I think it means applying path_expression, if the top level on_error
behavior is not on error
then ` if (jperIsError(res))` part may be executed.
--- a/src/include/utils/jsonpath.h
+++ b/src/include/utils/jsonpath.h
@@ -15,6 +15,7 @@
#define JSONPATH_H
#include "fmgr.h"
+#include "executor/tablefunc.h"
#include "nodes/pg_list.h"
#include "nodes/primnodes.h"
#include "utils/jsonb.h"
should be:
+#include "executor/tablefunc.h"
#include "fmgr.h"
+<synopsis>
+JSON_TABLE (
+ <replaceable>context_item</replaceable>,
<replaceable>path_expression</replaceable> <optional> AS
<replaceable>json_path_name</replaceable> </optional> <optional>
PASSING { <replaceable>value</replaceable> AS
<replaceable>varname</replaceable> } <optional>, ...</optional>
</optional>
+ COLUMNS ( <replaceable
class="parameter">json_table_column</replaceable> <optional>,
...</optional> )
+ <optional> { <literal>ERROR</literal> | <literal>EMPTY</literal>
} <literal>ON ERROR</literal> </optional>
+)
top level (not in the COLUMN clause) also allows
<literal>NULL</literal> <literal>ON ERROR</literal>.
SELECT JSON_VALUE(jsonb'"1.23"', 'strict $.a' null on error);
returns one value.
SELECT * FROM JSON_TABLE(jsonb'"1.23"', 'strict $.a' COLUMNS (js2 int
PATH '$') NULL on ERROR);
return zero rows.
Is this what we expected?
main changes are in jsonpath_exec.c, parse_expr.c, parse_jsontable.c
overall the coverage seems pretty good.
I added some tests to improve the coverage.
Вложения
On Fri, Mar 29, 2024 at 11:20 AM jian he <jian.universality@gmail.com> wrote:
>
>
> +<synopsis>
> +JSON_TABLE (
> + <replaceable>context_item</replaceable>,
> <replaceable>path_expression</replaceable> <optional> AS
> <replaceable>json_path_name</replaceable> </optional> <optional>
> PASSING { <replaceable>value</replaceable> AS
> <replaceable>varname</replaceable> } <optional>, ...</optional>
> </optional>
> + COLUMNS ( <replaceable
> class="parameter">json_table_column</replaceable> <optional>,
> ...</optional> )
> + <optional> { <literal>ERROR</literal> | <literal>EMPTY</literal>
> } <literal>ON ERROR</literal> </optional>
> +)
> top level (not in the COLUMN clause) also allows
> <literal>NULL</literal> <literal>ON ERROR</literal>.
>
we can also specify <literal>DEFAULT expression</literal> <literal>ON
ERROR</literal>.
like:
SELECT * FROM JSON_TABLE(jsonb'"1.23"', 'strict $.a' COLUMNS (js2 int
PATH '$') default '1' on error);
+ <varlistentry>
+ <term>
+ <replaceable>name</replaceable> <replaceable>type</replaceable>
<literal>FORMAT JSON</literal> <optional>ENCODING
<literal>UTF8</literal></optional>
+ <optional> <literal>PATH</literal>
<replaceable>json_path_specification</replaceable> </optional>
+ </term>
+ <listitem>
+ <para>
+ Inserts a composite SQL/JSON item into the output row.
+ </para>
+ <para>
+ The provided <literal>PATH</literal> expression is evaluated and
+ the column is filled with the produced SQL/JSON item. If the
+ <literal>PATH</literal> expression is omitted, path expression
+ <literal>$.<replaceable>name</replaceable></literal> is used,
+ where <replaceable>name</replaceable> is the provided column name.
+ In this case, the column name must correspond to one of the
+ keys within the SQL/JSON item produced by the row pattern.
+ </para>
+ <para>
+ Optionally, you can specify <literal>WRAPPER</literal>,
+ <literal>QUOTES</literal> clauses to format the output and
+ <literal>ON EMPTY</literal> and <literal>ON ERROR</literal> to handle
+ those scenarios appropriately.
+ </para>
Similarly, I am not sure of the description of "composite SQL/JSON item".
by observing the following 3 examples:
SELECT * FROM JSON_TABLE(jsonb'{"a": "z"}', '$.a' COLUMNS (js2 text
format json PATH '$' omit quotes));
SELECT * FROM JSON_TABLE(jsonb'{"a": "z"}', '$.a' COLUMNS (js2 text
format json PATH '$'));
SELECT * FROM JSON_TABLE(jsonb'{"a": "z"}', '$.a' COLUMNS (js2 text PATH '$'));
i think, FORMAT JSON specification means that,
if your specified type is text or varchar related AND didn't specify
quotes behavior
then FORMAT JSON produced output can be casted to json data type.
so FORMAT JSON seems not related to array and records data type.
also the last para can be:
+ <para>
+ Optionally, you can specify <literal>WRAPPER</literal>,
+ <literal>QUOTES</literal> clauses to format the output and
+ <literal>ON EMPTY</literal> and <literal>ON ERROR</literal> to handle
+ those missing values and structural errors, respectively.
+ </para>
+ ereport(ERROR,
+ errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
+ errmsg("only string constants are supported in JSON_TABLE"
+ " path specification"),
should be:
+ ereport(ERROR,
+ errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
+ errmsg("only string constants are supported in JSON_TABLE path
specification"),
+ <varlistentry>
+ <term>
+ <literal>AS</literal> <replaceable>json_path_name</replaceable>
+ </term>
+ <listitem>
+
+ <para>
+ The optional <replaceable>json_path_name</replaceable> serves as an
+ identifier of the provided
<replaceable>json_path_specification</replaceable>.
+ The path name must be unique and distinct from the column names.
+ When using the <literal>PLAN</literal> clause, you must specify the names
+ for all the paths, including the row pattern. Each path name can appear in
+ the <literal>PLAN</literal> clause only once.
+ </para>
+ </listitem>
+ </varlistentry>
as of v46, we don't have PLAN clause.
also "must be unique and distinct from the column names." seems incorrect.
for example:
SELECT * FROM JSON_TABLE(jsonb'"1.23"', '$.a' as js2 COLUMNS (js2 int
PATH '$'));
On Fri, Mar 29, 2024 at 6:59 PM jian he <jian.universality@gmail.com> wrote:
> On Fri, Mar 29, 2024 at 11:20 AM jian he <jian.universality@gmail.com> wrote:
Thanks for the reviews and the patch to add new test cases.
> Similarly, I am not sure of the description of "composite SQL/JSON item".
> by observing the following 3 examples:
> SELECT * FROM JSON_TABLE(jsonb'{"a": "z"}', '$.a' COLUMNS (js2 text
> format json PATH '$' omit quotes));
> SELECT * FROM JSON_TABLE(jsonb'{"a": "z"}', '$.a' COLUMNS (js2 text
> format json PATH '$'));
> SELECT * FROM JSON_TABLE(jsonb'{"a": "z"}', '$.a' COLUMNS (js2 text PATH '$'));
>
> i think, FORMAT JSON specification means that,
> if your specified type is text or varchar related AND didn't specify
> quotes behavior
> then FORMAT JSON produced output can be casted to json data type.
> so FORMAT JSON seems not related to array and records data type.
Hmm, yes, "composite" can sound confusing. Maybe just drop the word?
I've taken care of most of your other comments.
I'm also attaching 0002 showing an attempt to salvage only NESTED PATH
but not the PLAN clause. Still needs some polishing, like adding a
detailed explanation in JsonTablePlanNextRow() of when the nested
plans are involved, but thought it might be worth sharing at this
point.
I'll continue polishing 0001 with the hope to commit it early next week.
--
Thanks, Amit Langote
Вложения
Hi Alvaro, On Fri, Mar 29, 2024 at 2:04 AM Alvaro Herrera <alvherre@alvh.no-ip.org> wrote: > On 2024-Mar-28, Amit Langote wrote: > > > Here's patch 1 for the time being that implements barebones > > JSON_TABLE(), that is, without NESTED paths/columns and PLAN clause. > > I've tried to shape the interfaces so that those features can be added > > in future commits without significant rewrite of the code that > > implements barebones JSON_TABLE() functionality. I'll know whether > > that's really the case when I rebase the full patch over it. > > I think this barebones patch looks much closer to something that can be > committed for pg17, given the current commitfest timeline. Maybe we > should just slip NESTED and PLAN to pg18 to focus current efforts into > getting the basic functionality in 17. When I looked at the JSON_TABLE > patch last month, it appeared far too large to be reviewable in > reasonable time. The fact that this split now exists gives me hope that > we can get at least the first part of it. Thanks for chiming in. I agree that 0001 looks more manageable. > (A note that PLAN seems to correspond to separate features T824+T838, so > leaving that one out would still let us claim T821 "Basic SQL/JSON query > operators" ... however, the NESTED clause does not appear to be a > separate SQL feature; in particular it does not appear to correspond to > T827, though I may be reading the standard wrong. So if we don't have > NESTED, apparently we could not claim to support T821.) I've posted 0002 just now, which shows that adding just NESTED but not PLAN might be feasible. -- Thanks, Amit Langote
FAILED: src/interfaces/ecpg/test/sql/sqljson_jsontable.c
/home/jian/postgres/buildtest6/src/interfaces/ecpg/preproc/ecpg
--regression -I../../Desktop/pg_src/src6/postgres/src/interfaces/ecpg/test/sql
-I../../Desktop/pg_src/src6/postgres/src/interfaces/ecpg/include/ -o
src/interfaces/ecpg/test/sql/sqljson_jsontable.c
../../Desktop/pg_src/src6/postgres/src/interfaces/ecpg/test/sql/sqljson_jsontable.pgc
../../Desktop/pg_src/src6/postgres/src/interfaces/ecpg/test/sql/sqljson_jsontable.pgc:21:
WARNING: unsupported feature will be passed to server
../../Desktop/pg_src/src6/postgres/src/interfaces/ecpg/test/sql/sqljson_jsontable.pgc:32:
ERROR: syntax error at or near ";"
need an extra closing parenthesis?
<para>
The rows produced by <function>JSON_TABLE</function> are laterally
joined to the row that generated them, so you do not have to explicitly join
the constructed view with the original table holding <acronym>JSON</acronym>
- data.
need closing para.
SELECT * FROM JSON_TABLE('[]', 'strict $.a' COLUMNS (js2 text PATH
'$' error on empty error on error) EMPTY ON ERROR);
should i expect it return one row?
is there any example to make it return one row from top level "EMPTY ON ERROR"?
+ {
+ JsonTablePlan *scan = (JsonTablePlan *) plan;
+
+ JsonTableInitPathScan(cxt, planstate, args, mcxt);
+
+ planstate->nested = scan->child ?
+ JsonTableInitPlan(cxt, scan->child, planstate, args, mcxt) : NULL;
+ }
first line seems strange, do we just simply change from "plan" to "scan"?
+ case JTC_REGULAR:
+ typenameTypeIdAndMod(pstate, rawc->typeName, &typid, &typmod);
+
+ /*
+ * Use implicit FORMAT JSON for composite types (arrays and
+ * records) or if a non-default WRAPPER / QUOTES behavior is
+ * specified.
+ */
+ if (typeIsComposite(typid) ||
+ rawc->quotes != JS_QUOTES_UNSPEC ||
+ rawc->wrapper != JSW_UNSPEC)
+ rawc->coltype = JTC_FORMATTED;
per previous discussion, should we refactor the above comment?
+/* Recursively set 'reset' flag of planstate and its child nodes */
+static void
+JsonTablePlanReset(JsonTablePlanState *planstate)
+{
+ if (IsA(planstate->plan, JsonTableSiblingJoin))
+ {
+ JsonTablePlanReset(planstate->left);
+ JsonTablePlanReset(planstate->right);
+ planstate->advanceRight = false;
+ }
+ else
+ {
+ planstate->reset = true;
+ planstate->advanceNested = false;
+
+ if (planstate->nested)
+ JsonTablePlanReset(planstate->nested);
+ }
per coverage, the first part of the IF branch never executed.
i also found out that JsonTablePlanReset is quite similar to JsonTableRescan,
i don't fully understand these two functions though.
SELECT * FROM JSON_TABLE(jsonb'{"a": {"z":[1111]}, "b": 1,"c": 2, "d":
91}', '$' COLUMNS (
c int path '$.c',
d int path '$.d',
id1 for ordinality,
NESTED PATH '$.a.z[*]' columns (z int path '$', id for ordinality)
));
doc seems to say that duplicated ordinality columns in different nest
levels are not allowed?
"currentRow" naming seems misleading, generally, when we think of "row",
we think of several (not one) datums, or several columns.
but here, we only have one datum.
I don't have good optional naming though.
+ case JTC_FORMATTED:
+ case JTC_EXISTS:
+ {
+ Node *je;
+ CaseTestExpr *param = makeNode(CaseTestExpr);
+
+ param->collation = InvalidOid;
+ param->typeId = contextItemTypid;
+ param->typeMod = -1;
+
+ je = transformJsonTableColumn(rawc, (Node *) param,
+ NIL, errorOnError);
+
+ colexpr = transformExpr(pstate, je, EXPR_KIND_FROM_FUNCTION);
+ assign_expr_collations(pstate, colexpr);
+
+ typid = exprType(colexpr);
+ typmod = exprTypmod(colexpr);
+ break;
+ }
+
+ default:
+ elog(ERROR, "unknown JSON_TABLE column type: %d", rawc->coltype);
+ break;
+ }
+
+ tf->coltypes = lappend_oid(tf->coltypes, typid);
+ tf->coltypmods = lappend_int(tf->coltypmods, typmod);
+ tf->colcollations = lappend_oid(tf->colcollations, get_typcollation(typid));
+ tf->colvalexprs = lappend(tf->colvalexprs, colexpr);
why not use exprCollation(colexpr) for tf->colcollations, similar to
exprType(colexpr)?
+-- Should fail (JSON arguments are not passed to column paths)
+SELECT *
+FROM JSON_TABLE(
+ jsonb '[1,2,3]',
+ '$[*] ? (@ < $x)'
+ PASSING 10 AS x
+ COLUMNS (y text FORMAT JSON PATH '$ ? (@ < $x)')
+ ) jt;
+ERROR: could not find jsonpath variable "x"
the error message does not correspond to the comments intention.
also "y text FORMAT JSON" should be fine?
only the second last example really using the PASSING clause.
should the following query work just fine in this context?
create table s(js jsonb);
insert into s select '{"a":{"za":[{"z1": [11,2222]},{"z21": [22,
234,2345]}]},"c": 3}';
SELECT sub.* FROM s,JSON_TABLE(js, '$' passing 11 AS "b c", 1 + 2 as y
COLUMNS (xx int path '$.c ? (@ == $y)')) sub;
I thought the json and text data type were quite similar.
should these following two queries return the same result?
SELECT sub.* FROM s, JSON_TABLE(js, '$' COLUMNS(
xx int path '$.c',
nested PATH '$.a.za[1]' columns (NESTED PATH '$.z21[*]' COLUMNS (a12
jsonb path '$'))
))sub;
SELECT sub.* FROM s,JSON_TABLE(js, '$' COLUMNS (
c int path '$.c',
NESTED PATH '$.a.za[1]' columns (z json path '$')
)) sub;
typedef struct JsonTableExecContext
{
int magic;
JsonTablePlanState *rootplanstate;
JsonTablePlanState **colexprplans;
} JsonTableExecContext;
imho, this kind of naming is kind of inconsistent.
"state" and "plan" are mixed together.
maybe
typedef struct JsonTableExecContext
{
int magic;
JsonTablePlanState *rootplanstate;
JsonTablePlanState **colexprstates;
} JsonTableExecContext;
+ cxt->colexprplans = palloc(sizeof(JsonTablePlanState *) *
+ list_length(tf->colvalexprs));
+
/* Initialize plan */
- cxt->rootplanstate = JsonTableInitPlan(cxt, rootplan, args,
+ cxt->rootplanstate = JsonTableInitPlan(cxt, (Node *) rootplan, NULL, args,
CurrentMemoryContext);
I think, the comments "Initialize plan" is not right, here we
initialize the rootplanstate (JsonTablePlanState)
and also for each (no ordinality) columns, we also initialized the
specific JsonTablePlanState.
static void JsonTableRescan(JsonTablePlanState *planstate);
@@ -331,6 +354,9 @@ static Datum JsonTableGetValue(TableFuncScanState
*state, int colnum,
Oid typid, int32 typmod, bool *isnull);
static void JsonTableDestroyOpaque(TableFuncScanState *state);
static bool JsonTablePlanNextRow(JsonTablePlanState *planstate);
+static bool JsonTablePlanPathNextRow(JsonTablePlanState *planstate);
+static void JsonTableRescan(JsonTablePlanState *planstate);
JsonTableRescan included twice?
On Mon, Apr 1, 2024 at 8:00 AM jian he <jian.universality@gmail.com> wrote:
>
> +-- Should fail (JSON arguments are not passed to column paths)
> +SELECT *
> +FROM JSON_TABLE(
> + jsonb '[1,2,3]',
> + '$[*] ? (@ < $x)'
> + PASSING 10 AS x
> + COLUMNS (y text FORMAT JSON PATH '$ ? (@ < $x)')
> + ) jt;
> +ERROR: could not find jsonpath variable "x"
>
> the error message does not correspond to the comments intention.
> also "y text FORMAT JSON" should be fine?
sorry for the noise, i've figured out why.
> only the second last example really using the PASSING clause.
> should the following query work just fine in this context?
>
> create table s(js jsonb);
> insert into s select '{"a":{"za":[{"z1": [11,2222]},{"z21": [22,
> 234,2345]}]},"c": 3}';
> SELECT sub.* FROM s,JSON_TABLE(js, '$' passing 11 AS "b c", 1 + 2 as y
> COLUMNS (xx int path '$.c ? (@ == $y)')) sub;
>
>
> I thought the json and text data type were quite similar.
> should these following two queries return the same result?
>
> SELECT sub.* FROM s, JSON_TABLE(js, '$' COLUMNS(
> xx int path '$.c',
> nested PATH '$.a.za[1]' columns (NESTED PATH '$.z21[*]' COLUMNS (a12
> jsonb path '$'))
> ))sub;
>
> SELECT sub.* FROM s,JSON_TABLE(js, '$' COLUMNS (
> c int path '$.c',
> NESTED PATH '$.a.za[1]' columns (z json path '$')
> )) sub;
sorry for the noise, i've figured out why.
there are 12 appearances of "NESTED PATH" in sqljson_jsontable.sql.
but we don't have a real example of NESTED PATH nested with NESTED PATH.
so I added some real tests on it.
i also added some tests about the PASSING clause.
please check the attachment.
/*
* JsonTableInitPlan
* Initialize information for evaluating a jsonpath given in
* JsonTablePlan
*/
static void
JsonTableInitPathScan(JsonTableExecContext *cxt,
JsonTablePlanState *planstate,
List *args, MemoryContext mcxt)
{
JsonTablePlan *plan = (JsonTablePlan *) planstate->plan;
int i;
planstate->path = DatumGetJsonPathP(plan->path->value->constvalue);
planstate->args = args;
planstate->mcxt = AllocSetContextCreate(mcxt, "JsonTableExecContext",
ALLOCSET_DEFAULT_SIZES);
/* No row pattern evaluated yet. */
planstate->currentRow = PointerGetDatum(NULL);
planstate->currentRowIsNull = true;
for (i = plan->colMin; i <= plan->colMax; i++)
cxt->colexprplans[i] = planstate;
}
JsonTableInitPathScan's work is to init/assign struct
JsonTablePlanState's elements.
maybe we should just put JsonTableInitPathScan's work into JsonTableInitPlan
and also rename JsonTableInitPlan to "JsonTableInitPlanState" or
"InitJsonTablePlanState".
JsonTableSiblingJoin *join = (JsonTableSiblingJoin *) plan;
just rename the variable name, seems unnecessary?
Вложения
hi.
+/*
+ * Recursively transform child JSON_TABLE plan.
+ *
+ * Default plan is transformed into a cross/union join of its nested columns.
+ * Simple and outer/inner plans are transformed into a JsonTablePlan by
+ * finding and transforming corresponding nested column.
+ * Sibling plans are recursively transformed into a JsonTableSibling.
+ */
+static Node *
+transformJsonTableChildPlan(JsonTableParseContext *cxt,
+ List *columns)
this comment is not the same as the function intention for now.
maybe we need to refactor it.
/*
* Each call to fetch a new set of rows - of which there may be very many
* if XMLTABLE is being used in a lateral join - will allocate a possibly
* substantial amount of memory, so we cannot use the per-query context
* here. perTableCxt now serves the same function as "argcontext" does in
* FunctionScan - a place to store per-one-call (i.e. one result table)
* lifetime data (as opposed to per-query or per-result-tuple).
*/
MemoryContextSwitchTo(tstate->perTableCxt);
maybe we can replace "XMLTABLE" to "XMLTABLE or JSON_TABLE"?
/* Transform and coerce the PASSING arguments to to jsonb. */
there should be only one "to"?
-----------------------------------------------------------------------------------------------------------------------
json_table_column clause doesn't have a passing clause.
we can only have one passing clause in json_table.
but during JsonTableInitPathScan, for each output columns associated
JsonTablePlanState
we already initialized the PASSING arguments via `planstate->args = args;`
also transformJsonTableColumn already has a passingArgs argument.
technically we can use the jsonpath variable for every output column
regardless of whether it's nested or not.
JsonTable already has the "passing" clause,
we just need to pass it to function transformJsonTableColumns and it's callees.
based on that, I implemented it. seems quite straightforward.
I also wrote several contrived, slightly complicated tests.
It seems to work just fine.
simple explanation:
previously the following sql will fail, error message is that "could
not find jsonpath variable %s".
now it will work.
SELECT sub.* FROM
JSON_TABLE(jsonb '{"a":{"za":[{"z1": [11,2222]},{"z21": [22,
234,2345]}]},"c": 3}',
'$' PASSING 22 AS x, 234 AS y
COLUMNS(
xx int path '$.c',
NESTED PATH '$.a.za[1]' as n1 columns
(NESTED PATH '$.z21[*]' as n2
COLUMNS (z21 int path '$?(@ == $"x" || @ == $"y" )' default 0 on empty)),
NESTED PATH '$.a.za[0]' as n4 columns
(NESTED PATH '$.z1[*]' as n3
COLUMNS (z1 int path '$?(@ > $"y" + 1988)' default 0 on empty)))
)sub;
Вложения
On Fri, Mar 22, 2024 at 12:08 AM Amit Langote <amitlangote09@gmail.com> wrote: > > On Wed, Mar 20, 2024 at 9:53 PM Amit Langote <amitlangote09@gmail.com> wrote: > > I'll push 0001 tomorrow. > > Pushed that one. Here's the remaining JSON_TABLE() patch. > I know v45 is very different from v47. but v45 contains all the remaining features to be implemented. I've attached 2 files. v45-0001-propagate-passing-clause-to-every-json_ta.based_on_v45 after_apply_jsonpathvar.sql. the first file should be applied after v45-0001-JSON_TABLE.patch the second file has all kinds of tests to prove that applying JsonPathVariable to the NESTED PATH is ok. I know that v45 is not the whole patch we are going to push for postgres17. I just want to point out that applying the PASSING clause to the NESTED PATH works fine with V45. that means, I think, we can safely apply PASSING clause to NESTED PATH for feature "PLAN DEFAULT clause", "specific PLAN clause" and "sibling NESTED COLUMNS clauses".
Вложения
Hi Jian,
Thanks for your time on this.
On Mon, Apr 1, 2024 at 9:00 AM jian he <jian.universality@gmail.com> wrote:
> SELECT * FROM JSON_TABLE('[]', 'strict $.a' COLUMNS (js2 text PATH
> '$' error on empty error on error) EMPTY ON ERROR);
> should i expect it return one row?
> is there any example to make it return one row from top level "EMPTY ON ERROR"?
I think that's expected. You get 0 rows instead of a single row with
one column containing an empty array, because the NULL returned by the
error-handling part of JSON_TABLE's top-level path is not returned
directly to the user, but instead passed as an input document for the
TableFunc.
I think it suffices to add a note to the documentation of table-level
(that is, not column-level) ON ERROR clause that EMPTY means an empty
"table", not empty array, which is what you get with JSON_QUERY().
> + {
> + JsonTablePlan *scan = (JsonTablePlan *) plan;
> +
> + JsonTableInitPathScan(cxt, planstate, args, mcxt);
> +
> + planstate->nested = scan->child ?
> + JsonTableInitPlan(cxt, scan->child, planstate, args, mcxt) : NULL;
> + }
> first line seems strange, do we just simply change from "plan" to "scan"?
Mostly to complement the "join" variable in the other block.
Anyway, I've reworked this to make JsonTablePlan an abstract struct
and make JsonTablePathScan and JsonTableSiblingJoin "inherit" from it.
> + case JTC_REGULAR:
> + typenameTypeIdAndMod(pstate, rawc->typeName, &typid, &typmod);
> +
> + /*
> + * Use implicit FORMAT JSON for composite types (arrays and
> + * records) or if a non-default WRAPPER / QUOTES behavior is
> + * specified.
> + */
> + if (typeIsComposite(typid) ||
> + rawc->quotes != JS_QUOTES_UNSPEC ||
> + rawc->wrapper != JSW_UNSPEC)
> + rawc->coltype = JTC_FORMATTED;
> per previous discussion, should we refactor the above comment?
Done. Instead of saying "use implicit FORMAT JSON" I've reworked the
comment to mention instead that we do this so that the column uses
JSON_QUERY() as implementation for these cases.
> +/* Recursively set 'reset' flag of planstate and its child nodes */
> +static void
> +JsonTablePlanReset(JsonTablePlanState *planstate)
> +{
> + if (IsA(planstate->plan, JsonTableSiblingJoin))
> + {
> + JsonTablePlanReset(planstate->left);
> + JsonTablePlanReset(planstate->right);
> + planstate->advanceRight = false;
> + }
> + else
> + {
> + planstate->reset = true;
> + planstate->advanceNested = false;
> +
> + if (planstate->nested)
> + JsonTablePlanReset(planstate->nested);
> + }
> per coverage, the first part of the IF branch never executed.
> i also found out that JsonTablePlanReset is quite similar to JsonTableRescan,
> i don't fully understand these two functions though.
Working on improving the documentation of the recursive algorithm,
though I want to focus on finishing 0001 first.
> SELECT * FROM JSON_TABLE(jsonb'{"a": {"z":[1111]}, "b": 1,"c": 2, "d":
> 91}', '$' COLUMNS (
> c int path '$.c',
> d int path '$.d',
> id1 for ordinality,
> NESTED PATH '$.a.z[*]' columns (z int path '$', id for ordinality)
> ));
> doc seems to say that duplicated ordinality columns in different nest
> levels are not allowed?
Both the documentation and the code in JsonTableGetValue() to
calculate a FOR ORDINALITY column were wrong. A nested path's columns
should be able to have its own ordinal counter that runs separately
from the other paths, including the parent path, all the way up to the
root path.
I've fixed both. Added a test case too.
> "currentRow" naming seems misleading, generally, when we think of "row",
> we think of several (not one) datums, or several columns.
> but here, we only have one datum.
> I don't have good optional naming though.
Yeah, I can see the confusion. I've created a new struct called
JsonTablePlanRowSource and different places now use a variable named
just 'current' to refer to the currently active row source. It's
hopefully clear from the context that the datum containing the JSON
object is acting as a source of values for evaluating column paths.
> + case JTC_FORMATTED:
> + case JTC_EXISTS:
> + {
> + Node *je;
> + CaseTestExpr *param = makeNode(CaseTestExpr);
> +
> + param->collation = InvalidOid;
> + param->typeId = contextItemTypid;
> + param->typeMod = -1;
> +
> + je = transformJsonTableColumn(rawc, (Node *) param,
> + NIL, errorOnError);
> +
> + colexpr = transformExpr(pstate, je, EXPR_KIND_FROM_FUNCTION);
> + assign_expr_collations(pstate, colexpr);
> +
> + typid = exprType(colexpr);
> + typmod = exprTypmod(colexpr);
> + break;
> + }
> +
> + default:
> + elog(ERROR, "unknown JSON_TABLE column type: %d", rawc->coltype);
> + break;
> + }
> +
> + tf->coltypes = lappend_oid(tf->coltypes, typid);
> + tf->coltypmods = lappend_int(tf->coltypmods, typmod);
> + tf->colcollations = lappend_oid(tf->colcollations, get_typcollation(typid));
> + tf->colvalexprs = lappend(tf->colvalexprs, colexpr);
>
> why not use exprCollation(colexpr) for tf->colcollations, similar to
> exprType(colexpr)?
Yes, maybe.
On Tue, Apr 2, 2024 at 3:54 PM jian he <jian.universality@gmail.com> wrote:
> +/*
> + * Recursively transform child JSON_TABLE plan.
> + *
> + * Default plan is transformed into a cross/union join of its nested columns.
> + * Simple and outer/inner plans are transformed into a JsonTablePlan by
> + * finding and transforming corresponding nested column.
> + * Sibling plans are recursively transformed into a JsonTableSibling.
> + */
> +static Node *
> +transformJsonTableChildPlan(JsonTableParseContext *cxt,
> + List *columns)
> this comment is not the same as the function intention for now.
> maybe we need to refactor it.
Fixed.
> /*
> * Each call to fetch a new set of rows - of which there may be very many
> * if XMLTABLE is being used in a lateral join - will allocate a possibly
> * substantial amount of memory, so we cannot use the per-query context
> * here. perTableCxt now serves the same function as "argcontext" does in
> * FunctionScan - a place to store per-one-call (i.e. one result table)
> * lifetime data (as opposed to per-query or per-result-tuple).
> */
> MemoryContextSwitchTo(tstate->perTableCxt);
>
> maybe we can replace "XMLTABLE" to "XMLTABLE or JSON_TABLE"?
Good catch, done.
>
> /* Transform and coerce the PASSING arguments to to jsonb. */
> there should be only one "to"?
Will need to fix that separately.
>
-----------------------------------------------------------------------------------------------------------------------
> json_table_column clause doesn't have a passing clause.
> we can only have one passing clause in json_table.
> but during JsonTableInitPathScan, for each output columns associated
> JsonTablePlanState
> we already initialized the PASSING arguments via `planstate->args = args;`
> also transformJsonTableColumn already has a passingArgs argument.
> technically we can use the jsonpath variable for every output column
> regardless of whether it's nested or not.
>
> JsonTable already has the "passing" clause,
> we just need to pass it to function transformJsonTableColumns and it's callees.
> based on that, I implemented it. seems quite straightforward.
> I also wrote several contrived, slightly complicated tests.
> It seems to work just fine.
>
> simple explanation:
> previously the following sql will fail, error message is that "could
> not find jsonpath variable %s".
> now it will work.
>
> SELECT sub.* FROM
> JSON_TABLE(jsonb '{"a":{"za":[{"z1": [11,2222]},{"z21": [22,
> 234,2345]}]},"c": 3}',
> '$' PASSING 22 AS x, 234 AS y
> COLUMNS(
> xx int path '$.c',
> NESTED PATH '$.a.za[1]' as n1 columns
> (NESTED PATH '$.z21[*]' as n2
> COLUMNS (z21 int path '$?(@ == $"x" || @ == $"y" )' default 0 on empty)),
> NESTED PATH '$.a.za[0]' as n4 columns
> (NESTED PATH '$.z1[*]' as n3
> COLUMNS (z1 int path '$?(@ > $"y" + 1988)' default 0 on empty)))
> )sub;
Thanks for the patch. Yeah, not allowing column paths (including
nested ones) to use top-level PASSING args seems odd, so I wanted to
fix it too.
Please let me know if you have further comments on 0001. I'd like to
get that in before spending more energy on 0002.
--
Thanks, Amit Langote
Вложения
On Tue, Apr 2, 2024 at 9:57 PM Amit Langote <amitlangote09@gmail.com> wrote:
>
> Please let me know if you have further comments on 0001. I'd like to
> get that in before spending more energy on 0002.
>
hi. some issues with the doc.
i think, some of the "path expression" can be replaced by
"<replaceable>path_expression</replaceable>".
maybe not all of them.
+ <variablelist>
+ <varlistentry>
+ <term>
+ <literal><replaceable>context_item</replaceable>,
<replaceable>path_expression</replaceable> <optional>
<literal>AS</literal> <replaceable>json_path_name</replaceable>
</optional> <optional> <literal>PASSING</literal> {
<replaceable>value</replaceable> <literal>AS</literal>
<replaceable>varname</replaceable> } <optional>,
...</optional></optional></literal>
+ </term>
+ <listitem>
+ <para>
+ The input data to query, the JSON path expression defining the query,
+ and an optional <literal>PASSING</literal> clause, which can provide data
+ values to the <replaceable>path_expression</replaceable>.
+ The result of the input data
+ evaluation is called the <firstterm>row pattern</firstterm>. The row
+ pattern is used as the source for row values in the constructed view.
+ </para>
+ </listitem>
+ </varlistentry>
maybe
change this part "The input data to query, the JSON path expression
defining the query,"
to
`
<replaceable>context_item</replaceable> is the input data to query,
<replaceable>path_expression</replaceable> is the JSON path expression
defining the query,
`
+ <para>
+ Specifying <literal>FORMAT JSON</literal> makes it explcit that you
+ expect that the value to be a valid <type>json</type> object.
+ </para>
"explcit" change to "explicit", or should it be "explicitly"?
also FORMAT JSON can be override by OMIT QUOTES.
SELECT sub.* FROM JSON_TABLE('{"a":{"z1": "a"}}', '$.a' COLUMNS(xx
TEXT format json path '$.z1' omit quotes))sub;
it return not double quoted literal 'a', which cannot be a valid json.
create or replace FUNCTION test_format_json() returns table (thetype
text, is_ok bool) AS $$
declare
part1_sql text := $sql$SELECT sub.* FROM JSON_TABLE('{"a":{"z1":
"a"}}', '$.a' COLUMNS(xx $sql$;
part2_sql text := $sql$ format json path '$.z1' omit quotes))sub $sql$;
run_status bool := true;
r record;
fin record;
BEGIN
for r in
select format_type(oid, -1) as aa
from pg_type where typtype = 'b' and typarray != 0 and
typnamespace = 11 and typnotnull is false
loop
begin
-- raise notice '%',CONCAT_WS(' ', part1_sql, r.aa, part2_sql);
-- raise notice 'r.aa %', r.aa;
run_status := true;
execute CONCAT_WS(' ', part1_sql, r.aa, part2_sql) into fin;
return query select r.aa, run_status;
exception when others then
begin
run_status := false;
return query select r.aa, run_status;
end;
end;
end loop;
END;
$$ language plpgsql;
create table sss_1 as select * from test_format_json();
select * from sss_1 where is_ok is true;
use the above query, I've figure out that FORMAT JSON can apply to the
following types:
bytea
name
text
json
bpchar
character varying
jsonb
and these type's customized domain type.
overall, the idea is that:
Specifying <literal>FORMAT JSON</literal> makes it explicitly that you
expect that the value to be a valid <type>json</type> object.
<literal>FORMAT JSON</literal> can be overridden by OMIT QUOTES
specification, which can make the return value not a valid
<type>json</type>.
<literal>FORMAT JSON</literal> can only work with certain kinds of
data types.
-----------------------------------------------------------------------------------------------
+ <para>
+ Optionally, you can add <literal>ON ERROR</literal> clause to define
+ error behavior.
+ </para>
I think "error behavior" may refer to "what kind of error message it will omit"
but here, it's about what to do when an error happens.
so I guess it's misleading.
maybe we can explain it similar to json_exist.
+ <para>
+ Optionally, you can add <literal>ON ERROR</literal> clause to define
+ the behavior if an error occurs.
+ </para>
+ <para>
+ The specified <parameter>type</parameter> should have a cast from the
+ <type>boolean</type>.
+ </para>
should be
+ <para>
+ The specified <replaceable>type</replaceable> should have a cast from the
+ <type>boolean</type>.
+ </para>
+ <para>
+ Inserts a SQL/JSON value into the output row.
+ </para>
maybe
+ <para>
+ Inserts a value that the data type is
<replaceable>type</replaceable> into the output row.
+ </para>
+ <para>
+ Inserts a boolean item into each output row.
+ </para>
maybe changed to:
+ <para>
+ Inserts a value that the data type is
<replaceable>type</replaceable> into the output row.
+ </para>
"name type EXISTS" branch mentioned: "The specified type should have a
cast from the boolean."
but "name type [FORMAT JSON [ENCODING UTF8]] [ PATH path_expression ]"
never mentioned the "type"parameter.
maybe add one para, something like:
"after apply path_expression, the yield value cannot be coerce to
<replaceable>type</replaceable> it will return null"
On Wed, Apr 3, 2024 at 11:30 AM jian he <jian.universality@gmail.com> wrote: > > On Tue, Apr 2, 2024 at 9:57 PM Amit Langote <amitlangote09@gmail.com> wrote: > > > > Please let me know if you have further comments on 0001. I'd like to > > get that in before spending more energy on 0002. > > -- a/src/backend/parser/parse_target.c +++ b/src/backend/parser/parse_target.c @@ -2019,6 +2019,9 @@ FigureColnameInternal(Node *node, char **name) case JSON_VALUE_OP: *name = "json_value"; return 2; + case JSON_TABLE_OP: + *name = "json_table"; + return 2; default: elog(ERROR, "unrecognized JsonExpr op: %d", (int) ((JsonFuncExpr *) node)->op); "case JSON_TABLE_OP part", no need? json_table output must provide column name and type? I did some minor refactor transformJsonTableColumns, make the comments align with the function intention. in v48-0001, in transformJsonTableColumns we can `Assert(rawc->name);`. since non-nested JsonTableColumn must specify column name. in v48-0002, we can change to `if (rawc->coltype != JTC_NESTED) Assert(rawc->name);` SELECT * FROM JSON_TABLE(jsonb '1', '$' COLUMNS (a int PATH '$.a' ) ERROR ON ERROR) jt; ERROR: no SQL/JSON item I thought it should just return NULL. In this case, I thought that (not column-level) ERROR ON ERROR should not interfere with "COLUMNS (a int PATH '$.a' )". +-- Other miscellanous checks "miscellanous" should be "miscellaneous". overall the coverage is pretty high. the current test output looks fine.
Вложения
On Wed, Apr 3, 2024 at 3:15 PM jian he <jian.universality@gmail.com> wrote:
>
> On Wed, Apr 3, 2024 at 11:30 AM jian he <jian.universality@gmail.com> wrote:
> >
> > On Tue, Apr 2, 2024 at 9:57 PM Amit Langote <amitlangote09@gmail.com> wrote:
> > >
> > > Please let me know if you have further comments on 0001. I'd like to
> > > get that in before spending more energy on 0002.
> > >
more doc issue with v48. 0001, 0002.
<para>
The optional <replaceable>json_path_name</replaceable> serves as an
identifier of the provided <replaceable>path_expression</replaceable>.
The path name must be unique and distinct from the column names.
</para>
"path name" should be
<replaceable>json_path_name</replaceable>
git diff --check
doc/src/sgml/func.sgml:19192: trailing whitespace.
+ id | kind | title | director
+ <para>
+ JSON data stored at a nested level of the row pattern can be extracted using
+ the <literal>NESTED PATH</literal> clause. Each
+ <literal>NESTED PATH</literal> clause can be used to generate one or more
+ columns using the data from a nested level of the row pattern, which can be
+ specified using a <literal>COLUMNS</literal> clause. Rows constructed from
+ such columns are called <firstterm>child rows</firstterm> and are joined
+ agaist the row constructed from the columns specified in the parent
+ <literal>COLUMNS</literal> clause to get the row in the final view. Child
+ columns may themselves contain a <literal>NESTED PATH</literal>
+ specifification thus allowing to extract data located at arbitrary nesting
+ levels. Columns produced by <literal>NESTED PATH</literal>s at the same
+ level are considered to be <firstterm>siblings</firstterm> and are joined
+ with each other before joining to the parent row.
+ </para>
"agaist" should be "against".
"specifification" should be "specification".
+ Rows constructed from
+ such columns are called <firstterm>child rows</firstterm> and are joined
+ agaist the row constructed from the columns specified in the parent
+ <literal>COLUMNS</literal> clause to get the row in the final view.
this sentence is long, not easy to comprehend, maybe we can rephrase it
or split it into two.
+ | NESTED PATH <replaceable>json_path_specification</replaceable>
<optional> AS <replaceable>path_name</replaceable> </optional>
+ COLUMNS ( <replaceable>json_table_column</replaceable>
<optional>, ...</optional> )
v48, 0002 patch.
in the json_table synopsis section, put these two lines into one line,
I think would make it more readable.
also the following sgml code will render the html into one line.
<term>
<literal>NESTED PATH</literal>
<replaceable>json_path_specification</replaceable> <optional>
<literal>AS</literal> <replaceable>json_path_name</replaceable>
</optional>
<literal>COLUMNS</literal> (
<replaceable>json_table_column</replaceable> <optional>,
...</optional> )
</term>
also <replaceable>path_name</replaceable> should be
<replaceable>json_path_name</replaceable>.
+ <para>
+ The <literal>NESTED PATH</literal> syntax is recursive,
+ so you can go down multiple nested levels by specifying several
+ <literal>NESTED PATH</literal> subclauses within each other.
+ It allows to unnest the hierarchy of JSON objects and arrays
+ in a single function invocation rather than chaining several
+ <function>JSON_TABLE</function> expressions in an SQL statement.
+ </para>
"The <literal>NESTED PATH</literal> syntax is recursive"
should be
`
The <literal>NESTED PATH</literal> syntax can be recursive,
you can go down multiple nested levels by specifying several
<literal>NESTED PATH</literal> subclauses within each other.
`
On Wed, Apr 3, 2024 at 4:16 PM jian he <jian.universality@gmail.com> wrote: > On Wed, Apr 3, 2024 at 11:30 AM jian he <jian.universality@gmail.com> wrote: > > > > On Tue, Apr 2, 2024 at 9:57 PM Amit Langote <amitlangote09@gmail.com> wrote: > > > > > > Please let me know if you have further comments on 0001. I'd like to > > > get that in before spending more energy on 0002. > > > > > -- a/src/backend/parser/parse_target.c > +++ b/src/backend/parser/parse_target.c > @@ -2019,6 +2019,9 @@ FigureColnameInternal(Node *node, char **name) > case JSON_VALUE_OP: > *name = "json_value"; > return 2; > + case JSON_TABLE_OP: > + *name = "json_table"; > + return 2; > default: > elog(ERROR, "unrecognized JsonExpr op: %d", > (int) ((JsonFuncExpr *) node)->op); > > "case JSON_TABLE_OP part", no need? > json_table output must provide column name and type? That seems to be the case, so removed. > I did some minor refactor transformJsonTableColumns, make the comments > align with the function intention. Thanks, but that seems a bit verbose. I've reduced it down to what gives enough information. > in v48-0001, in transformJsonTableColumns we can `Assert(rawc->name);`. > since non-nested JsonTableColumn must specify column name. > in v48-0002, we can change to `if (rawc->coltype != JTC_NESTED) > Assert(rawc->name);` Ok, done. > SELECT * FROM JSON_TABLE(jsonb '1', '$' COLUMNS (a int PATH '$.a' ) > ERROR ON ERROR) jt; > ERROR: no SQL/JSON item > > I thought it should just return NULL. > In this case, I thought that > (not column-level) ERROR ON ERROR should not interfere with "COLUMNS > (a int PATH '$.a' )". I think it does in another database's implementation, which must be why the original authors decided that the table-level ERROR should also be used for columns unless overridden. But I agree that keeping the two separate is better, so changed that way. Attached updated patches. I have addressed your doc comments on 0001, but not 0002 yet. > > +-- Other miscellanous checks > "miscellanous" should be "miscellaneous". > > > overall the coverage is pretty high. > the current test output looks fine. -- Thanks, Amit Langote
Вложения
hi.
+ <para>
+ <function>json_table</function> is an SQL/JSON function which
+ queries <acronym>JSON</acronym> data
+ and presents the results as a relational view, which can be accessed as a
+ regular SQL table. You can only use
<function>json_table</function> inside the
+ <literal>FROM</literal> clause of a <literal>SELECT</literal>,
+ <literal>UPDATE</literal>, <literal>DELETE</literal>, or
<literal>MERGE</literal>
+ statement.
+ </para>
the only issue is that <literal>MERGE</literal> Synopsis don't have
<literal>FROM</literal> clause.
other than that, it's quite correct.
see following tests demo:
drop table ss;
create table ss(a int);
insert into ss select 1;
delete from ss using JSON_TABLE(jsonb '1', '$' COLUMNS (a int PATH '$'
) ERROR ON ERROR) jt where jt.a = 1;
insert into ss select 2;
update ss set a = 1 from JSON_TABLE(jsonb '2', '$' COLUMNS (a int PATH
'$')) jt where jt.a = 2;
DROP TABLE IF EXISTS target;
CREATE TABLE target (tid integer, balance integer) WITH
(autovacuum_enabled=off);
INSERT INTO target VALUES (1, 10),(2, 20),(3, 30);
MERGE INTO target USING JSON_TABLE(jsonb '2', '$' COLUMNS (a int PATH
'$' ) ERROR ON ERROR) source(sid)
ON target.tid = source.sid
WHEN MATCHED THEN UPDATE SET balance = 0
returning *;
--------------------------------------------------------------------------------------------------
+ <para>
+ To split the row pattern into columns, <function>json_table</function>
+ provides the <literal>COLUMNS</literal> clause that defines the
+ schema of the created view. For each column, a separate path expression
+ can be specified to be evaluated against the row pattern to get a
+ SQL/JSON value that will become the value for the specified column in
+ a given output row.
+ </para>
should be "an SQL/JSON".
+ <para>
+ Inserts a SQL/JSON value obtained by applying
+ <replaceable>path_expression</replaceable> against the row pattern into
+ the view's output row after coercing it to specified
+ <replaceable>type</replaceable>.
+ </para>
should be "an SQL/JSON".
"coercing it to specified <replaceable>type</replaceable>"
should be
"coercing it to the specified <replaceable>type</replaceable>"?
---------------------------------------------------------------------------------------------------------------
+ <para>
+ The value corresponds to whether evaluating the <literal>PATH</literal>
+ expression yields any SQL/JSON values.
+ </para>
maybe we can change to
+ <para>
+ The value corresponds to whether applying the
<replaceable>path_expression</replaceable>
+ expression yields any SQL/JSON values.
+ </para>
so it looks more consistent with the preceding paragraph.
+ <para>
+ Optionally, <literal>ON ERROR</literal> can be used to specify whether
+ to throw an error or return the specified value to handle structural
+ errors, respectively. The default is to return a boolean value
+ <literal>FALSE</literal>.
+ </para>
we don't need "respectively" here?
+ if (jt->on_error &&
+ jt->on_error->btype != JSON_BEHAVIOR_ERROR &&
+ jt->on_error->btype != JSON_BEHAVIOR_EMPTY &&
+ jt->on_error->btype != JSON_BEHAVIOR_EMPTY_ARRAY)
+ ereport(ERROR,
+ errcode(ERRCODE_SYNTAX_ERROR),
+ errmsg("invalid ON ERROR behavior"),
+ errdetail("Only EMPTY or ERROR is allowed for ON ERROR in JSON_TABLE()."),
+ parser_errposition(pstate, jt->on_error->location));
errdetail("Only EMPTY or ERROR is allowed for ON ERROR in JSON_TABLE()."),
maybe change to something like:
`
errdetail("Only EMPTY or ERROR is allowed for ON ERROR in the
top-level JSON_TABLE() ").
`
i guess mentioning "top-level" is fine.
since "top-level", we have 19 appearances in functions-json.html.
On Wed, Apr 3, 2024 at 8:39 PM Amit Langote <amitlangote09@gmail.com> wrote: > > Attached updated patches. I have addressed your doc comments on 0001, > but not 0002 yet. > in v49, 0002. +\sv jsonb_table_view1 +CREATE OR REPLACE VIEW public.jsonb_table_view1 AS + SELECT id, + a1, + b1, + a11, + a21, + a22 + FROM JSON_TABLE( + 'null'::jsonb, '$[*]' AS json_table_path_0 + PASSING + 1 + 2 AS a, + '"foo"'::json AS "b c" + COLUMNS ( + id FOR ORDINALITY, + a1 integer PATH '$."a1"', + b1 text PATH '$."b1"', + a11 text PATH '$."a11"', + a21 text PATH '$."a21"', + a22 text PATH '$."a22"', + NESTED PATH '$[1]' AS p1 + COLUMNS ( + id FOR ORDINALITY, + a1 integer PATH '$."a1"', + b1 text PATH '$."b1"', + a11 text PATH '$."a11"', + a21 text PATH '$."a21"', + a22 text PATH '$."a22"', + NESTED PATH '$[*]' AS "p1 1" + COLUMNS ( + id FOR ORDINALITY, + a1 integer PATH '$."a1"', + b1 text PATH '$."b1"', + a11 text PATH '$."a11"', + a21 text PATH '$."a21"', + a22 text PATH '$."a22"' + ) + ), + NESTED PATH '$[2]' AS p2 + COLUMNS ( + id FOR ORDINALITY, + a1 integer PATH '$."a1"', + b1 text PATH '$."b1"', + a11 text PATH '$."a11"', + a21 text PATH '$."a21"', + a22 text PATH '$."a22"' + NESTED PATH '$[*]' AS "p2:1" + COLUMNS ( + id FOR ORDINALITY, + a1 integer PATH '$."a1"', + b1 text PATH '$."b1"', + a11 text PATH '$."a11"', + a21 text PATH '$."a21"', + a22 text PATH '$."a22"' + ), + NESTED PATH '$[*]' AS p22 + COLUMNS ( + id FOR ORDINALITY, + a1 integer PATH '$."a1"', + b1 text PATH '$."b1"', + a11 text PATH '$."a11"', + a21 text PATH '$."a21"', + a22 text PATH '$."a22"' + ) + ) + ) + ) execute this view definition (not the "create view") will have syntax error. That means the changes in v49,0002 ruleutils.c are wrong. also \sv the output is quite long, not easy to validate it. we need a way to validate that the view definition is equivalent to "select * from view". so I added a view validate function to it. we can put it in v49, 0001. since json data type don't equality operator, so I did some minor change to make the view validate function works with jsonb_table_view2 jsonb_table_view3 jsonb_table_view4 jsonb_table_view5 jsonb_table_view6
Вложения
On Thu, Apr 4, 2024 at 2:41 PM jian he <jian.universality@gmail.com> wrote:
>
> On Wed, Apr 3, 2024 at 8:39 PM Amit Langote <amitlangote09@gmail.com> wrote:
> >
> > Attached updated patches. I have addressed your doc comments on 0001,
> > but not 0002 yet.
> >
>
about v49, 0002.
--tests setup.
drop table if exists s cascade;
create table s(js jsonb);
insert into s values
('{"a":{"za":[{"z1": [11,2222]},{"z21": [22, 234,2345]},{"z22": [32,
204,145]}]},"c": 3}'),
('{"a":{"za":[{"z1": [21,4222]},{"z21": [32, 134,1345]}]},"c": 10}');
after playing around, I found, the non-nested column will be sorted first,
and the nested column will be ordered as is.
the below query, column "xx1" will be the first column, "xx" will be
the second column.
SELECT sub.* FROM s,(values(23)) x(x),generate_series(13, 13) y,
JSON_TABLE(js, '$' as c1 PASSING x AS x, y AS y COLUMNS(
NESTED PATH '$.a.za[2]' as n3 columns (NESTED PATH '$.z22[*]' as z22
COLUMNS (c int path '$')),
NESTED PATH '$.a.za[1]' as n4 columns (d int[] PATH '$.z21'),
NESTED PATH '$.a.za[0]' as n1 columns (NESTED PATH '$.z1[*]' as z1
COLUMNS (a int path '$')),
xx1 int path '$.c',
NESTED PATH '$.a.za[1]' as n2 columns (NESTED PATH '$.z21[*]' as z21
COLUMNS (b int path '$')),
xx int path '$.c'
))sub;
maybe this behavior is fine. but there is no explanation?
--------------------------------------------------------------------------------
--- a/src/tools/pgindent/typedefs.list
+++ b/src/tools/pgindent/typedefs.list
@@ -1327,6 +1327,7 @@ JsonPathMutableContext
JsonPathParseItem
JsonPathParseResult
JsonPathPredicateCallback
+JsonPathSpec
this change is no need.
--------------------------------------------------------------------------------
+ if (scan->child)
+ get_json_table_nested_columns(tf, scan->child, context, showimplicit,
+ scan->colMax >= scan->colMin);
except parse_jsontable.c, we only use colMin, colMax in get_json_table_columns.
aslo in parse_jsontable.c, we do it via:
+ /* Start of column range */
+ colMin = list_length(tf->colvalexprs);
....
+ /* End of column range */
+ colMax = list_length(tf->colvalexprs) - 1;
maybe we can use (bool *) to tag whether this JsonTableColumn is nested or not
in transformJsonTableColumns.
currently colMin, colMax seems to make parsing back json_table (nested
path only) not working.
--------------------------------------------------------------------------------
I also added some slightly complicated tests to prove that the PASSING
clause works
with every level, aslo the multi level nesting clause works as intended.
As mentioned in the previous mail, parsing back nest columns
json_table expression
not working as we expected.
so the last view (jsonb_table_view7) I added, the view definition is WRONG!!
the good news is the output is what we expected, the coverage is pretty high.
Вложения
On Thu, Apr 4, 2024 at 3:50 PM jian he <jian.universality@gmail.com> wrote: > > On Thu, Apr 4, 2024 at 2:41 PM jian he <jian.universality@gmail.com> wrote: > > > > On Wed, Apr 3, 2024 at 8:39 PM Amit Langote <amitlangote09@gmail.com> wrote: > > > > > > Attached updated patches. I have addressed your doc comments on 0001, > > > but not 0002 yet. hi some doc issue about v49, 0002. + Each + <literal>NESTED PATH</literal> clause can be used to generate one or more + columns using the data from a nested level of the row pattern, which can be + specified using a <literal>COLUMNS</literal> clause. maybe change to + Each + <literal>NESTED PATH</literal> clause can be used to generate one or more + columns using the data from an upper nested level of the row pattern, which can be + specified using a <literal>COLUMNS</literal> clause + Child + columns may themselves contain a <literal>NESTED PATH</literal> + specifification thus allowing to extract data located at arbitrary nesting + levels. maybe change to + Child + columns themselves may contain a <literal>NESTED PATH</literal> + specification thus allowing to extract data located at any arbitrary nesting + level. +</screen> + </para> + <para> + The following is a modified version of the above query to show the usage + of <literal>NESTED PATH</literal> for populating title and director + columns, illustrating how they are joined to the parent columns id and + kind: +<screen> +SELECT jt.* FROM + my_films, + JSON_TABLE ( js, '$.favorites[*] ? (@.films[*].director == $filter)' + PASSING 'Alfred Hitchcock' AS filter + COLUMNS ( + id FOR ORDINALITY, + kind text PATH '$.kind', + NESTED PATH '$.films[*]' COLUMNS ( + title text FORMAT JSON PATH '$.title' OMIT QUOTES, + director text PATH '$.director' KEEP QUOTES))) AS jt; + id | kind | title | director +----+----------+---------+-------------------- + 1 | horror | Psycho | "Alfred Hitchcock" + 2 | thriller | Vertigo | "Alfred Hitchcock" +(2 rows) +</screen> + </para> + <para> + The following is the same query but without the filter in the root + path: +<screen> +SELECT jt.* FROM + my_films, + JSON_TABLE ( js, '$.favorites[*]' + COLUMNS ( + id FOR ORDINALITY, + kind text PATH '$.kind', + NESTED PATH '$.films[*]' COLUMNS ( + title text FORMAT JSON PATH '$.title' OMIT QUOTES, + director text PATH '$.director' KEEP QUOTES))) AS jt; + id | kind | title | director +----+----------+-----------------+-------------------- + 1 | comedy | Bananas | "Woody Allen" + 1 | comedy | The Dinner Game | "Francis Veber" + 2 | horror | Psycho | "Alfred Hitchcock" + 3 | thriller | Vertigo | "Alfred Hitchcock" + 4 | drama | Yojimbo | "Akira Kurosawa" +(5 rows) </screen> just found out that the query and the query's output condensed together. in https://www.postgresql.org/docs/current/tutorial-window.html the query we use <programlisting>, the output we use <screen>. maybe we can do it the same way, or we could just have one or two empty new lines separate them. we have the similar problem in v49, 0001.
On Wed, Apr 3, 2024 at 11:48 PM jian he <jian.universality@gmail.com> wrote:
> hi.
> + <para>
> + <function>json_table</function> is an SQL/JSON function which
> + queries <acronym>JSON</acronym> data
> + and presents the results as a relational view, which can be accessed as a
> + regular SQL table. You can only use
> <function>json_table</function> inside the
> + <literal>FROM</literal> clause of a <literal>SELECT</literal>,
> + <literal>UPDATE</literal>, <literal>DELETE</literal>, or
> <literal>MERGE</literal>
> + statement.
> + </para>
>
> the only issue is that <literal>MERGE</literal> Synopsis don't have
> <literal>FROM</literal> clause.
> other than that, it's quite correct.
> see following tests demo:
>
> drop table ss;
> create table ss(a int);
> insert into ss select 1;
> delete from ss using JSON_TABLE(jsonb '1', '$' COLUMNS (a int PATH '$'
> ) ERROR ON ERROR) jt where jt.a = 1;
> insert into ss select 2;
> update ss set a = 1 from JSON_TABLE(jsonb '2', '$' COLUMNS (a int PATH
> '$')) jt where jt.a = 2;
> DROP TABLE IF EXISTS target;
> CREATE TABLE target (tid integer, balance integer) WITH
> (autovacuum_enabled=off);
> INSERT INTO target VALUES (1, 10),(2, 20),(3, 30);
> MERGE INTO target USING JSON_TABLE(jsonb '2', '$' COLUMNS (a int PATH
> '$' ) ERROR ON ERROR) source(sid)
> ON target.tid = source.sid
> WHEN MATCHED THEN UPDATE SET balance = 0
> returning *;
> --------------------------------------------------------------------------------------------------
>
> + <para>
> + To split the row pattern into columns, <function>json_table</function>
> + provides the <literal>COLUMNS</literal> clause that defines the
> + schema of the created view. For each column, a separate path expression
> + can be specified to be evaluated against the row pattern to get a
> + SQL/JSON value that will become the value for the specified column in
> + a given output row.
> + </para>
> should be "an SQL/JSON".
>
> + <para>
> + Inserts a SQL/JSON value obtained by applying
> + <replaceable>path_expression</replaceable> against the row pattern into
> + the view's output row after coercing it to specified
> + <replaceable>type</replaceable>.
> + </para>
> should be "an SQL/JSON".
>
> "coercing it to specified <replaceable>type</replaceable>"
> should be
> "coercing it to the specified <replaceable>type</replaceable>"?
> ---------------------------------------------------------------------------------------------------------------
> + <para>
> + The value corresponds to whether evaluating the <literal>PATH</literal>
> + expression yields any SQL/JSON values.
> + </para>
> maybe we can change to
> + <para>
> + The value corresponds to whether applying the
> <replaceable>path_expression</replaceable>
> + expression yields any SQL/JSON values.
> + </para>
> so it looks more consistent with the preceding paragraph.
>
> + <para>
> + Optionally, <literal>ON ERROR</literal> can be used to specify whether
> + to throw an error or return the specified value to handle structural
> + errors, respectively. The default is to return a boolean value
> + <literal>FALSE</literal>.
> + </para>
> we don't need "respectively" here?
>
> + if (jt->on_error &&
> + jt->on_error->btype != JSON_BEHAVIOR_ERROR &&
> + jt->on_error->btype != JSON_BEHAVIOR_EMPTY &&
> + jt->on_error->btype != JSON_BEHAVIOR_EMPTY_ARRAY)
> + ereport(ERROR,
> + errcode(ERRCODE_SYNTAX_ERROR),
> + errmsg("invalid ON ERROR behavior"),
> + errdetail("Only EMPTY or ERROR is allowed for ON ERROR in JSON_TABLE()."),
> + parser_errposition(pstate, jt->on_error->location));
>
> errdetail("Only EMPTY or ERROR is allowed for ON ERROR in JSON_TABLE()."),
> maybe change to something like:
> `
> errdetail("Only EMPTY or ERROR is allowed for ON ERROR in the
> top-level JSON_TABLE() ").
> `
> i guess mentioning "top-level" is fine.
> since "top-level", we have 19 appearances in functions-json.html.
Thanks for checking.
Pushed after fixing these and a few other issues. I didn't include
the testing function you proposed in your other email. It sounds
useful for testing locally but will need some work before we can
include it in the tree.
I'll post the rebased 0002 tomorrow after addressing your comments.
--
Thanks, Amit Langote
Hello Amit,
04.04.2024 15:02, Amit Langote wrote:
> Pushed after fixing these and a few other issues. I didn't include
> the testing function you proposed in your other email. It sounds
> useful for testing locally but will need some work before we can
> include it in the tree.
>
> I'll post the rebased 0002 tomorrow after addressing your comments.
Please look at an assertion failure:
TRAP: failed Assert("count <= tupdesc->natts"), File: "parse_relation.c", Line: 3048, PID: 1325146
triggered by the following query:
SELECT * FROM JSON_TABLE('0', '$' COLUMNS (js int PATH '$')),
COALESCE(row(1)) AS (a int, b int);
Without JSON_TABLE() I get:
ERROR: function return row and query-specified return row do not match
DETAIL: Returned row contains 1 attribute, but query expects 2.
Best regards,
Alexander
On Fri, Apr 05, 2024 at 09:00:00AM +0300, Alexander Lakhin wrote:
> Please look at an assertion failure:
> TRAP: failed Assert("count <= tupdesc->natts"), File: "parse_relation.c", Line: 3048, PID: 1325146
>
> triggered by the following query:
> SELECT * FROM JSON_TABLE('0', '$' COLUMNS (js int PATH '$')),
> COALESCE(row(1)) AS (a int, b int);
>
> Without JSON_TABLE() I get:
> ERROR: function return row and query-specified return row do not match
> DETAIL: Returned row contains 1 attribute, but query expects 2.
I've added an open item on this one. We need to keep track of all
that.
--
Michael
Вложения
Hi Alexander,
On Fri, Apr 5, 2024 at 3:00 PM Alexander Lakhin <exclusion@gmail.com> wrote:
>
> Hello Amit,
>
> 04.04.2024 15:02, Amit Langote wrote:
> > Pushed after fixing these and a few other issues. I didn't include
> > the testing function you proposed in your other email. It sounds
> > useful for testing locally but will need some work before we can
> > include it in the tree.
> >
> > I'll post the rebased 0002 tomorrow after addressing your comments.
>
> Please look at an assertion failure:
> TRAP: failed Assert("count <= tupdesc->natts"), File: "parse_relation.c", Line: 3048, PID: 1325146
>
> triggered by the following query:
> SELECT * FROM JSON_TABLE('0', '$' COLUMNS (js int PATH '$')),
> COALESCE(row(1)) AS (a int, b int);
>
> Without JSON_TABLE() I get:
> ERROR: function return row and query-specified return row do not match
> DETAIL: Returned row contains 1 attribute, but query expects 2.
Thanks for the report.
Seems like it might be a pre-existing issue, because I can also
reproduce the crash with:
SELECT * FROM COALESCE(row(1)) AS (a int, b int);
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
The connection to the server was lost. Attempting reset: Failed.
!>
Backtrace:
#0 __pthread_kill_implementation (threadid=281472845250592,
signo=signo@entry=6, no_tid=no_tid@entry=0) at pthread_kill.c:44
#1 0x0000ffff806c4334 in __pthread_kill_internal (signo=6,
threadid=<optimized out>) at pthread_kill.c:78
#2 0x0000ffff8067c73c in __GI_raise (sig=sig@entry=6) at
../sysdeps/posix/raise.c:26
#3 0x0000ffff80669034 in __GI_abort () at abort.c:79
#4 0x0000000000ad9d4c in ExceptionalCondition (conditionName=0xcbb368
"!(tupdesc->natts >= colcount)", errorType=0xcbb278 "FailedAssertion",
fileName=0xcbb2c8 "nodeFunctionscan.c",
lineNumber=379) at assert.c:54
#5 0x000000000073edec in ExecInitFunctionScan (node=0x293d4ed0,
estate=0x293d51b8, eflags=16) at nodeFunctionscan.c:379
#6 0x0000000000724bc4 in ExecInitNode (node=0x293d4ed0,
estate=0x293d51b8, eflags=16) at execProcnode.c:248
#7 0x000000000071b1cc in InitPlan (queryDesc=0x292f5d78, eflags=16)
at execMain.c:1006
#8 0x0000000000719f6c in standard_ExecutorStart
(queryDesc=0x292f5d78, eflags=16) at execMain.c:252
#9 0x0000000000719cac in ExecutorStart (queryDesc=0x292f5d78,
eflags=0) at execMain.c:134
#10 0x0000000000945520 in PortalStart (portal=0x29399458, params=0x0,
eflags=0, snapshot=0x0) at pquery.c:527
#11 0x000000000093ee50 in exec_simple_query (query_string=0x29332d38
"SELECT * FROM COALESCE(row(1)) AS (a int, b int);") at
postgres.c:1175
#12 0x0000000000943cb8 in PostgresMain (argc=1, argv=0x2935d610,
dbname=0x2935d450 "postgres", username=0x2935d430 "amit") at
postgres.c:4297
#13 0x000000000087e978 in BackendRun (port=0x29356c00) at postmaster.c:4517
#14 0x000000000087e0bc in BackendStartup (port=0x29356c00) at postmaster.c:4200
#15 0x0000000000879638 in ServerLoop () at postmaster.c:1725
#16 0x0000000000878eb4 in PostmasterMain (argc=3, argv=0x292eeac0) at
postmaster.c:1398
#17 0x0000000000791db8 in main (argc=3, argv=0x292eeac0) at main.c:228
Backtrace looks a bit different with a query similar to yours:
SELECT * FROM generate_series(1, 1), COALESCE(row(1)) AS (a int, b int);
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
The connection to the server was lost. Attempting reset: Failed.
!>
#0 __pthread_kill_implementation (threadid=281472845250592,
signo=signo@entry=6, no_tid=no_tid@entry=0) at pthread_kill.c:44
#1 0x0000ffff806c4334 in __pthread_kill_internal (signo=6,
threadid=<optimized out>) at pthread_kill.c:78
#2 0x0000ffff8067c73c in __GI_raise (sig=sig@entry=6) at
../sysdeps/posix/raise.c:26
#3 0x0000ffff80669034 in __GI_abort () at abort.c:79
#4 0x0000000000ad9d4c in ExceptionalCondition (conditionName=0xc903b0
"!(count <= tupdesc->natts)", errorType=0xc8f8c8 "FailedAssertion",
fileName=0xc8f918 "parse_relation.c",
lineNumber=2649) at assert.c:54
#5 0x0000000000649664 in expandTupleDesc (tupdesc=0x293da188,
eref=0x293d7318, count=2, offset=0, rtindex=2, sublevels_up=0,
location=-1, include_dropped=true, colnames=0x0,
colvars=0xffffc39253c8) at parse_relation.c:2649
#6 0x0000000000648d08 in expandRTE (rte=0x293d7390, rtindex=2,
sublevels_up=0, location=-1, include_dropped=true, colnames=0x0,
colvars=0xffffc39253c8) at parse_relation.c:2361
#7 0x0000000000849bd0 in build_physical_tlist (root=0x293d5318,
rel=0x293d88e8) at plancat.c:1681
#8 0x0000000000806ad0 in create_scan_plan (root=0x293d5318,
best_path=0x293cd888, flags=0) at createplan.c:605
#9 0x000000000080666c in create_plan_recurse (root=0x293d5318,
best_path=0x293cd888, flags=0) at createplan.c:389
#10 0x000000000080c4e8 in create_nestloop_plan (root=0x293d5318,
best_path=0x293d96f0) at createplan.c:4056
#11 0x0000000000807464 in create_join_plan (root=0x293d5318,
best_path=0x293d96f0) at createplan.c:1037
#12 0x0000000000806680 in create_plan_recurse (root=0x293d5318,
best_path=0x293d96f0, flags=1) at createplan.c:394
#13 0x000000000080658c in create_plan (root=0x293d5318,
best_path=0x293d96f0) at createplan.c:326
#14 0x0000000000816534 in standard_planner (parse=0x293d3728,
cursorOptions=256, boundParams=0x0) at planner.c:413
#15 0x00000000008162b4 in planner (parse=0x293d3728,
cursorOptions=256, boundParams=0x0) at planner.c:275
#16 0x000000000093e984 in pg_plan_query (querytree=0x293d3728,
cursorOptions=256, boundParams=0x0) at postgres.c:877
#17 0x000000000093eb04 in pg_plan_queries (querytrees=0x293d8018,
cursorOptions=256, boundParams=0x0) at postgres.c:967
#18 0x000000000093edc4 in exec_simple_query (query_string=0x29332d38
"SELECT * FROM generate_series(1, 1), COALESCE(row(1)) AS (a int, b
int);") at postgres.c:1142
#19 0x0000000000943cb8 in PostgresMain (argc=1, argv=0x2935d4f8,
dbname=0x2935d338 "postgres", username=0x2935d318 "amit") at
postgres.c:4297
#20 0x000000000087e978 in BackendRun (port=0x29356dd0) at postmaster.c:4517
#21 0x000000000087e0bc in BackendStartup (port=0x29356dd0) at postmaster.c:4200
#22 0x0000000000879638 in ServerLoop () at postmaster.c:1725
#23 0x0000000000878eb4 in PostmasterMain (argc=3, argv=0x292eeac0) at
postmaster.c:1398
#24 0x0000000000791db8 in main (argc=3, argv=0x292eeac0) at main.c:228
I suspect the underlying issue is the same, though I haven't figured
out what it is, except a guess that addRangeTableEntryForFunction()
might be missing something to handle this sanely.
Reproducible down to v12.
--
Thanks, Amit Langote
05.04.2024 10:09, Amit Langote wrote: > Seems like it might be a pre-existing issue, because I can also > reproduce the crash with: > > SELECT * FROM COALESCE(row(1)) AS (a int, b int); > server closed the connection unexpectedly > This probably means the server terminated abnormally > before or while processing the request. > The connection to the server was lost. Attempting reset: Failed. > !> > > Backtrace: > > #0 __pthread_kill_implementation (threadid=281472845250592, > signo=signo@entry=6, no_tid=no_tid@entry=0) at pthread_kill.c:44 > #1 0x0000ffff806c4334 in __pthread_kill_internal (signo=6, > threadid=<optimized out>) at pthread_kill.c:78 > #2 0x0000ffff8067c73c in __GI_raise (sig=sig@entry=6) at > ../sysdeps/posix/raise.c:26 > #3 0x0000ffff80669034 in __GI_abort () at abort.c:79 > #4 0x0000000000ad9d4c in ExceptionalCondition (conditionName=0xcbb368 > "!(tupdesc->natts >= colcount)", errorType=0xcbb278 "FailedAssertion", > fileName=0xcbb2c8 "nodeFunctionscan.c", > lineNumber=379) at assert.c:54 That's strange, because I get the error (on master, 6f132ed69). With backtrace_functions = 'tupledesc_match', I see 2024-04-05 10:48:27.827 MSK client backend[2898632] regress ERROR: function return row and query-specified return row do not match 2024-04-05 10:48:27.827 MSK client backend[2898632] regress DETAIL: Returned row contains 1 attribute, but query expects2. 2024-04-05 10:48:27.827 MSK client backend[2898632] regress BACKTRACE: tupledesc_match at execSRF.c:948:3 ExecMakeTableFunctionResult at execSRF.c:427:13 FunctionNext at nodeFunctionscan.c:94:5 ExecScanFetch at execScan.c:131:10 ExecScan at execScan.c:180:10 ExecFunctionScan at nodeFunctionscan.c:272:1 ExecProcNodeFirst at execProcnode.c:465:1 ExecProcNode at executor.h:274:9 (inlined by) ExecutePlan at execMain.c:1646:10 standard_ExecutorRun at execMain.c:363:3 ExecutorRun at execMain.c:305:1 PortalRunSelect at pquery.c:926:26 PortalRun at pquery.c:775:8 exec_simple_query at postgres.c:1282:3 PostgresMain at postgres.c:4684:27 BackendMain at backend_startup.c:57:2 pgarch_die at pgarch.c:847:1 BackendStartup at postmaster.c:3593:8 ServerLoop at postmaster.c:1674:6 main at main.c:184:3 /lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0x80) [0x7f37127f0e40] 2024-04-05 10:48:27.827 MSK client backend[2898632] regress STATEMENT: SELECT * FROM COALESCE(row(1)) AS (a int, b int); That's why I had attributed the failure to JSON_TABLE(). Though SELECT * FROM generate_series(1, 1), COALESCE(row(1)) AS (a int, b int); really triggers the assert too. Sorry for the noise... Best regards, Alexander
On Fri, Apr 5, 2024 at 5:00 PM Alexander Lakhin <exclusion@gmail.com> wrote: > 05.04.2024 10:09, Amit Langote wrote: > > Seems like it might be a pre-existing issue, because I can also > > reproduce the crash with: > > That's strange, because I get the error (on master, 6f132ed69). > With backtrace_functions = 'tupledesc_match', I see > 2024-04-05 10:48:27.827 MSK client backend[2898632] regress ERROR: function return row and query-specified return row do > not match > 2024-04-05 10:48:27.827 MSK client backend[2898632] regress DETAIL: Returned row contains 1 attribute, but query expects2. > 2024-04-05 10:48:27.827 MSK client backend[2898632] regress BACKTRACE: > tupledesc_match at execSRF.c:948:3 > ExecMakeTableFunctionResult at execSRF.c:427:13 > FunctionNext at nodeFunctionscan.c:94:5 > ExecScanFetch at execScan.c:131:10 > ExecScan at execScan.c:180:10 > ExecFunctionScan at nodeFunctionscan.c:272:1 > ExecProcNodeFirst at execProcnode.c:465:1 > ExecProcNode at executor.h:274:9 > (inlined by) ExecutePlan at execMain.c:1646:10 > standard_ExecutorRun at execMain.c:363:3 > ExecutorRun at execMain.c:305:1 > PortalRunSelect at pquery.c:926:26 > PortalRun at pquery.c:775:8 > exec_simple_query at postgres.c:1282:3 > PostgresMain at postgres.c:4684:27 > BackendMain at backend_startup.c:57:2 > pgarch_die at pgarch.c:847:1 > BackendStartup at postmaster.c:3593:8 > ServerLoop at postmaster.c:1674:6 > main at main.c:184:3 > /lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0x80) [0x7f37127f0e40] > 2024-04-05 10:48:27.827 MSK client backend[2898632] regress STATEMENT: SELECT * FROM COALESCE(row(1)) AS (a int, b int); > > That's why I had attributed the failure to JSON_TABLE(). > > Though SELECT * FROM generate_series(1, 1), COALESCE(row(1)) AS (a int, b int); > really triggers the assert too. > Sorry for the noise... No worries. Let's start another thread so that this gets more attention. -- Thanks, Amit Langote
On Thu, Apr 4, 2024 at 9:02 PM Amit Langote <amitlangote09@gmail.com> wrote: > I'll post the rebased 0002 tomorrow after addressing your comments. Here's one. Main changes: * Fixed a bug in get_table_json_columns() which caused nested columns to be deparsed incorrectly, something Jian reported upthread. * Simplified the algorithm in JsonTablePlanNextRow() I'll post another revision or two maybe tomorrow, but posting what I have now in case Jian wants to do more testing. -- Thanks, Amit Langote
Вложения
On Fri, Apr 5, 2024 at 8:35 PM Amit Langote <amitlangote09@gmail.com> wrote:
> Here's one. Main changes:
>
> * Fixed a bug in get_table_json_columns() which caused nested columns
> to be deparsed incorrectly, something Jian reported upthread.
> * Simplified the algorithm in JsonTablePlanNextRow()
>
> I'll post another revision or two maybe tomorrow, but posting what I
> have now in case Jian wants to do more testing.
i am using the upthread view validation function.
by comparing `execute the view definition` and `select * from the_view`,
I did find 2 issues.
* problem in transformJsonBehavior, JSON_BEHAVIOR_DEFAULT branch.
I think we can fix this problem later, since sql/json query function
already committed?
CREATE DOMAIN jsonb_test_domain AS text CHECK (value <> 'foo');
normally, we do:
SELECT JSON_VALUE(jsonb '{"d1": "H"}', '$.a2' returning
jsonb_test_domain DEFAULT 'foo' ON ERROR);
but parsing back view def, we do:
SELECT JSON_VALUE(jsonb '{"d1": "H"}', '$.a2' returning
jsonb_test_domain DEFAULT 'foo'::text::jsonb_test_domain ON ERROR);
then I found the following two queries should not be error out.
SELECT JSON_VALUE(jsonb '{"d1": "H"}', '$.a2' returning
jsonb_test_domain DEFAULT 'foo1'::text::jsonb_test_domain ON ERROR);
SELECT JSON_VALUE(jsonb '{"d1": "H"}', '$.a2' returning
jsonb_test_domain DEFAULT 'foo1'::jsonb_test_domain ON ERROR);
--------------------------------------------------------------------------------------------------------------------
* problem with type "char". the view def output is not the same as
the select * from v1.
create or replace view v1 as
SELECT col FROM s,
JSON_TABLE(jsonb '{"d": ["hello", "hello1"]}', '$' as c1
COLUMNS(col "char" path '$.d' without wrapper keep quotes))sub;
\sv v1
CREATE OR REPLACE VIEW public.v1 AS
SELECT sub.col
FROM s,
JSON_TABLE(
'{"d": ["hello", "hello1"]}'::jsonb, '$' AS c1
COLUMNS (
col "char" PATH '$."d"'
)
) sub
one under the hood called JSON_QUERY_OP, another called JSON_VALUE_OP.
I will do extensive checking for other types later, so far, other than
these two issues,
get_json_table_columns is pretty solid, I've tried nested columns with
nested columns, it just works.
Hi Michael,
On Fri, Apr 5, 2024 at 3:07 PM Michael Paquier <michael@paquier.xyz> wrote:
> On Fri, Apr 05, 2024 at 09:00:00AM +0300, Alexander Lakhin wrote:
> > Please look at an assertion failure:
> > TRAP: failed Assert("count <= tupdesc->natts"), File: "parse_relation.c", Line: 3048, PID: 1325146
> >
> > triggered by the following query:
> > SELECT * FROM JSON_TABLE('0', '$' COLUMNS (js int PATH '$')),
> > COALESCE(row(1)) AS (a int, b int);
> >
> > Without JSON_TABLE() I get:
> > ERROR: function return row and query-specified return row do not match
> > DETAIL: Returned row contains 1 attribute, but query expects 2.
>
> I've added an open item on this one. We need to keep track of all
> that.
We figured out that this is an existing bug unrelated to JSON_TABLE(),
which Alexander reported to -bugs:
https://postgr.es/m/18422-89ca86c8eac5246d@postgresql.org
I have moved the item to Older Bugs:
https://wiki.postgresql.org/wiki/PostgreSQL_17_Open_Items#Live_issues
--
Thanks, Amit Langote
On Sat, Apr 6, 2024 at 12:31 PM jian he <jian.universality@gmail.com> wrote:
> On Fri, Apr 5, 2024 at 8:35 PM Amit Langote <amitlangote09@gmail.com> wrote:
> > Here's one. Main changes:
> >
> > * Fixed a bug in get_table_json_columns() which caused nested columns
> > to be deparsed incorrectly, something Jian reported upthread.
> > * Simplified the algorithm in JsonTablePlanNextRow()
> >
> > I'll post another revision or two maybe tomorrow, but posting what I
> > have now in case Jian wants to do more testing.
>
> i am using the upthread view validation function.
> by comparing `execute the view definition` and `select * from the_view`,
> I did find 2 issues.
>
> * problem in transformJsonBehavior, JSON_BEHAVIOR_DEFAULT branch.
> I think we can fix this problem later, since sql/json query function
> already committed?
>
> CREATE DOMAIN jsonb_test_domain AS text CHECK (value <> 'foo');
> normally, we do:
> SELECT JSON_VALUE(jsonb '{"d1": "H"}', '$.a2' returning
> jsonb_test_domain DEFAULT 'foo' ON ERROR);
>
> but parsing back view def, we do:
> SELECT JSON_VALUE(jsonb '{"d1": "H"}', '$.a2' returning
> jsonb_test_domain DEFAULT 'foo'::text::jsonb_test_domain ON ERROR);
>
> then I found the following two queries should not be error out.
> SELECT JSON_VALUE(jsonb '{"d1": "H"}', '$.a2' returning
> jsonb_test_domain DEFAULT 'foo1'::text::jsonb_test_domain ON ERROR);
> SELECT JSON_VALUE(jsonb '{"d1": "H"}', '$.a2' returning
> jsonb_test_domain DEFAULT 'foo1'::jsonb_test_domain ON ERROR);
Yeah, added an open item for this:
https://wiki.postgresql.org/wiki/PostgreSQL_17_Open_Items#Open_Issues
> --------------------------------------------------------------------------------------------------------------------
>
> * problem with type "char". the view def output is not the same as
> the select * from v1.
>
> create or replace view v1 as
> SELECT col FROM s,
> JSON_TABLE(jsonb '{"d": ["hello", "hello1"]}', '$' as c1
> COLUMNS(col "char" path '$.d' without wrapper keep quotes))sub;
>
> \sv v1
> CREATE OR REPLACE VIEW public.v1 AS
> SELECT sub.col
> FROM s,
> JSON_TABLE(
> '{"d": ["hello", "hello1"]}'::jsonb, '$' AS c1
> COLUMNS (
> col "char" PATH '$."d"'
> )
> ) sub
> one under the hood called JSON_QUERY_OP, another called JSON_VALUE_OP.
Hmm, I don't see a problem as long as both are equivalent or produce
the same result. Though, perhaps we could make
get_json_expr_options() also deparse JSW_NONE explicitly into "WITHOUT
WRAPPER" instead of a blank. But that's existing code, so will take
care of it as part of the above open item.
> I will do extensive checking for other types later, so far, other than
> these two issues,
> get_json_table_columns is pretty solid, I've tried nested columns with
> nested columns, it just works.
Thanks for checking.
--
Thanks, Amit Langote
On Sat, Apr 6, 2024 at 2:03 PM Amit Langote <amitlangote09@gmail.com> wrote:
>
> >
> > * problem with type "char". the view def output is not the same as
> > the select * from v1.
> >
> > create or replace view v1 as
> > SELECT col FROM s,
> > JSON_TABLE(jsonb '{"d": ["hello", "hello1"]}', '$' as c1
> > COLUMNS(col "char" path '$.d' without wrapper keep quotes))sub;
> >
> > \sv v1
> > CREATE OR REPLACE VIEW public.v1 AS
> > SELECT sub.col
> > FROM s,
> > JSON_TABLE(
> > '{"d": ["hello", "hello1"]}'::jsonb, '$' AS c1
> > COLUMNS (
> > col "char" PATH '$."d"'
> > )
> > ) sub
> > one under the hood called JSON_QUERY_OP, another called JSON_VALUE_OP.
>
> Hmm, I don't see a problem as long as both are equivalent or produce
> the same result. Though, perhaps we could make
> get_json_expr_options() also deparse JSW_NONE explicitly into "WITHOUT
> WRAPPER" instead of a blank. But that's existing code, so will take
> care of it as part of the above open item.
>
> > I will do extensive checking for other types later, so far, other than
> > these two issues,
> > get_json_table_columns is pretty solid, I've tried nested columns with
> > nested columns, it just works.
>
> Thanks for checking.
>
After applying v50, this type also has some issues.
CREATE OR REPLACE VIEW t1 as
SELECT sub.* FROM JSON_TABLE(jsonb '{"d": ["hello", "hello1"]}',
'$' AS c1 COLUMNS (
"tsvector0" tsvector path '$.d' without wrapper omit quotes,
"tsvector1" tsvector path '$.d' without wrapper keep quotes))sub;
table t1;
return
tsvector0 | tsvector1
-------------------------+-------------------------
'"hello1"]' '["hello",' | '"hello1"]' '["hello",'
(1 row)
src5=# \sv t1
CREATE OR REPLACE VIEW public.t1 AS
SELECT tsvector0,
tsvector1
FROM JSON_TABLE(
'{"d": ["hello", "hello1"]}'::jsonb, '$' AS c1
COLUMNS (
tsvector0 tsvector PATH '$."d"' OMIT QUOTES,
tsvector1 tsvector PATH '$."d"'
)
) sub
but
SELECT tsvector0,
tsvector1
FROM JSON_TABLE(
'{"d": ["hello", "hello1"]}'::jsonb, '$' AS c1
COLUMNS (
tsvector0 tsvector PATH '$."d"' OMIT QUOTES,
tsvector1 tsvector PATH '$."d"'
)
) sub
only return
tsvector0 | tsvector1
-------------------------+-----------
'"hello1"]' '["hello",' |
On Fri, Apr 5, 2024 at 8:35 PM Amit Langote <amitlangote09@gmail.com> wrote:
>
> On Thu, Apr 4, 2024 at 9:02 PM Amit Langote <amitlangote09@gmail.com> wrote:
> > I'll post the rebased 0002 tomorrow after addressing your comments.
>
> Here's one. Main changes:
>
> * Fixed a bug in get_table_json_columns() which caused nested columns
> to be deparsed incorrectly, something Jian reported upthread.
> * Simplified the algorithm in JsonTablePlanNextRow()
>
> I'll post another revision or two maybe tomorrow, but posting what I
> have now in case Jian wants to do more testing.
>
+ else
+ {
+ /*
+ * Parent and thus the plan has no more rows.
+ */
+ return false;
+ }
in JsonTablePlanNextRow, the above comment seems strange to me.
+ /*
+ * Re-evaluate a nested plan's row pattern using the new parent row
+ * pattern, if present.
+ */
+ Assert(parent != NULL);
+ if (!parent->current.isnull)
+ JsonTableResetRowPattern(planstate, parent->current.value);
Is this assertion useful?
if parent is null, then parent->current.isnull will cause segmentation fault.
I tested with 3 NESTED PATH, it works! (I didn't fully understand
JsonTablePlanNextRow though).
the doc needs some polish work.
Hi,
On Sat, Apr 6, 2024 at 3:55 PM jian he <jian.universality@gmail.com> wrote:
> On Sat, Apr 6, 2024 at 2:03 PM Amit Langote <amitlangote09@gmail.com> wrote:
> >
> > >
> > > * problem with type "char". the view def output is not the same as
> > > the select * from v1.
> > >
> > > create or replace view v1 as
> > > SELECT col FROM s,
> > > JSON_TABLE(jsonb '{"d": ["hello", "hello1"]}', '$' as c1
> > > COLUMNS(col "char" path '$.d' without wrapper keep quotes))sub;
> > >
> > > \sv v1
> > > CREATE OR REPLACE VIEW public.v1 AS
> > > SELECT sub.col
> > > FROM s,
> > > JSON_TABLE(
> > > '{"d": ["hello", "hello1"]}'::jsonb, '$' AS c1
> > > COLUMNS (
> > > col "char" PATH '$."d"'
> > > )
> > > ) sub
> > > one under the hood called JSON_QUERY_OP, another called JSON_VALUE_OP.
> >
> > Hmm, I don't see a problem as long as both are equivalent or produce
> > the same result. Though, perhaps we could make
> > get_json_expr_options() also deparse JSW_NONE explicitly into "WITHOUT
> > WRAPPER" instead of a blank. But that's existing code, so will take
> > care of it as part of the above open item.
> >
> > > I will do extensive checking for other types later, so far, other than
> > > these two issues,
> > > get_json_table_columns is pretty solid, I've tried nested columns with
> > > nested columns, it just works.
> >
> > Thanks for checking.
> >
> After applying v50, this type also has some issues.
> CREATE OR REPLACE VIEW t1 as
> SELECT sub.* FROM JSON_TABLE(jsonb '{"d": ["hello", "hello1"]}',
> '$' AS c1 COLUMNS (
> "tsvector0" tsvector path '$.d' without wrapper omit quotes,
> "tsvector1" tsvector path '$.d' without wrapper keep quotes))sub;
> table t1;
>
> return
> tsvector0 | tsvector1
> -------------------------+-------------------------
> '"hello1"]' '["hello",' | '"hello1"]' '["hello",'
> (1 row)
>
> src5=# \sv t1
> CREATE OR REPLACE VIEW public.t1 AS
> SELECT tsvector0,
> tsvector1
> FROM JSON_TABLE(
> '{"d": ["hello", "hello1"]}'::jsonb, '$' AS c1
> COLUMNS (
> tsvector0 tsvector PATH '$."d"' OMIT QUOTES,
> tsvector1 tsvector PATH '$."d"'
> )
> ) sub
>
> but
>
> SELECT tsvector0,
> tsvector1
> FROM JSON_TABLE(
> '{"d": ["hello", "hello1"]}'::jsonb, '$' AS c1
> COLUMNS (
> tsvector0 tsvector PATH '$."d"' OMIT QUOTES,
> tsvector1 tsvector PATH '$."d"'
> )
> ) sub
>
> only return
> tsvector0 | tsvector1
> -------------------------+-----------
> '"hello1"]' '["hello",' |
Yep, we *should* fix get_json_expr_options() to emit KEEP QUOTES and
WITHOUT WRAPPER options so that transformJsonTableColumns() does the
correct thing when you execute the \sv output. Like this:
diff --git a/src/backend/utils/adt/ruleutils.c
b/src/backend/utils/adt/ruleutils.c
index 283ca53cb5..5a6aabe100 100644
--- a/src/backend/utils/adt/ruleutils.c
+++ b/src/backend/utils/adt/ruleutils.c
@@ -8853,9 +8853,13 @@ get_json_expr_options(JsonExpr *jsexpr,
deparse_context *context,
appendStringInfo(context->buf, " WITH CONDITIONAL WRAPPER");
else if (jsexpr->wrapper == JSW_UNCONDITIONAL)
appendStringInfo(context->buf, " WITH UNCONDITIONAL WRAPPER");
+ else if (jsexpr->wrapper == JSW_NONE)
+ appendStringInfo(context->buf, " WITHOUT WRAPPER");
if (jsexpr->omit_quotes)
appendStringInfo(context->buf, " OMIT QUOTES");
+ else
+ appendStringInfo(context->buf, " KEEP QUOTES");
}
Will get that pushed tomorrow. Thanks for the test case.
--
Thanks, Amit Langote
hi.
about v50.
+/*
+ * JsonTableSiblingJoin -
+ * Plan to union-join rows of nested paths of the same level
+ */
+typedef struct JsonTableSiblingJoin
+{
+ JsonTablePlan plan;
+
+ JsonTablePlan *lplan;
+ JsonTablePlan *rplan;
+} JsonTableSiblingJoin;
"Plan to union-join rows of nested paths of the same level"
same level problem misleading?
I think it means
"Plan to union-join rows of top level columns clause is a nested path"
+ if (IsA(planstate->plan, JsonTableSiblingJoin))
+ {
+ /* Fetch new from left sibling. */
+ if (!JsonTablePlanNextRow(planstate->left))
+ {
+ /*
+ * Left sibling ran out of rows, fetch new from right sibling.
+ */
+ if (!JsonTablePlanNextRow(planstate->right))
+ {
+ /* Right sibling and thus the plan has now more rows. */
+ return false;
+ }
+ }
+ }
/* Right sibling and thus the plan has now more rows. */
I think you mean:
/* Right sibling ran out of rows and thus the plan has no more rows. */
in <synopsis> section,
+ | NESTED PATH <replaceable>json_path_specification</replaceable>
<optional> AS <replaceable>path_name</replaceable> </optional>
+ COLUMNS ( <replaceable>json_table_column</replaceable>
<optional>, ...</optional> )
maybe make it into one line.
| NESTED PATH <replaceable>json_path_specification</replaceable>
<optional> AS <replaceable>path_name</replaceable> </optional> COLUMNS
( <replaceable>json_table_column</replaceable> <optional>,
...</optional> )
since the surrounding pattern is the next line beginning with "[",
meaning that next line is optional.
+ at arbitrary nesting levels.
maybe
+ at arbitrary nested level.
in src/tools/pgindent/typedefs.list, "JsonPathSpec" is unnecessary.
other than that, it looks good to me.
On Sun, Apr 7, 2024 at 12:30 PM jian he <jian.universality@gmail.com> wrote:
>
> other than that, it looks good to me.
while looking at it again.
+ | NESTED path_opt Sconst
+ COLUMNS '(' json_table_column_definition_list ')'
+ {
+ JsonTableColumn *n = makeNode(JsonTableColumn);
+
+ n->coltype = JTC_NESTED;
+ n->pathspec = (JsonTablePathSpec *)
+ makeJsonTablePathSpec($3, NULL, @3, -1);
+ n->columns = $6;
+ n->location = @1;
+ $$ = (Node *) n;
+ }
+ | NESTED path_opt Sconst AS name
+ COLUMNS '(' json_table_column_definition_list ')'
+ {
+ JsonTableColumn *n = makeNode(JsonTableColumn);
+
+ n->coltype = JTC_NESTED;
+ n->pathspec = (JsonTablePathSpec *)
+ makeJsonTablePathSpec($3, $5, @3, @5);
+ n->columns = $8;
+ n->location = @1;
+ $$ = (Node *) n;
+ }
+ ;
+
+path_opt:
+ PATH
+ | /* EMPTY */
;
for `NESTED PATH`, `PATH` is optional.
So for the doc, many places we need to replace `NESTED PATH` to `NESTED [PATH]`?
On Sun, Apr 7, 2024 at 10:21 PM jian he <jian.universality@gmail.com> wrote:
> On Sun, Apr 7, 2024 at 12:30 PM jian he <jian.universality@gmail.com> wrote:
> >
> > other than that, it looks good to me.
> while looking at it again.
>
> + | NESTED path_opt Sconst
> + COLUMNS '(' json_table_column_definition_list ')'
> + {
> + JsonTableColumn *n = makeNode(JsonTableColumn);
> +
> + n->coltype = JTC_NESTED;
> + n->pathspec = (JsonTablePathSpec *)
> + makeJsonTablePathSpec($3, NULL, @3, -1);
> + n->columns = $6;
> + n->location = @1;
> + $$ = (Node *) n;
> + }
> + | NESTED path_opt Sconst AS name
> + COLUMNS '(' json_table_column_definition_list ')'
> + {
> + JsonTableColumn *n = makeNode(JsonTableColumn);
> +
> + n->coltype = JTC_NESTED;
> + n->pathspec = (JsonTablePathSpec *)
> + makeJsonTablePathSpec($3, $5, @3, @5);
> + n->columns = $8;
> + n->location = @1;
> + $$ = (Node *) n;
> + }
> + ;
> +
> +path_opt:
> + PATH
> + | /* EMPTY */
> ;
>
> for `NESTED PATH`, `PATH` is optional.
> So for the doc, many places we need to replace `NESTED PATH` to `NESTED [PATH]`?
Thanks for checking.
I've addressed most of your comments in the recent days including
today's. Thanks for the patches for adding new test cases. That was
very helpful.
I've changed the recursive structure of JsonTablePlanNextRow(). While
it still may not be perfect, I think it's starting to look good now.
0001 is a patch to fix up get_json_expr_options() so that it now emits
WRAPPER and QUOTES such that they work correctly.
0002 needs an expanded commit message but I've run out of energy today.
--
Thanks, Amit Langote
Вложения
On Sun, Apr 7, 2024 at 9:36 PM Amit Langote <amitlangote09@gmail.com> wrote:
>
>
> 0002 needs an expanded commit message but I've run out of energy today.
>
some cosmetic issues in v51, 0002.
in struct JsonTablePathScan,
/* ERROR/EMPTY ON ERROR behavior */
bool errorOnError;
the comments seem not right.
I think "errorOnError" means
while evaluating the top level JSON path expression, whether "error on
error" is specified or not?
+ | NESTED <optional> PATH </optional> ]
<replaceable>json_path_specification</replaceable> <optional> AS
<replaceable>json_path_name</replaceable> </optional> COLUMNS (
<replaceable>json_table_column</replaceable> <optional>,
...</optional> )
</synopsis>
"NESTED <optional> PATH </optional> ] "
no need the closing bracket.
+ /* Update the nested plan(s)'s row(s) using this new row. */
+ if (planstate->nested)
+ {
+ JsonTableResetNestedPlan(planstate->nested);
+ if (JsonTablePlanNextRow(planstate->nested))
+ return true;
+ }
+
return true;
}
this part can be simplified as:
+ if (planstate->nested)
+{
+ JsonTableResetNestedPlan(planstate->nested);
+ JsonTablePlanNextRow(planstate->nested));
+}
since the last part, if it returns false, eventually it returns true.
also the comments seem slightly confusing?
v51 recursion function(JsonTablePlanNextRow, JsonTablePlanScanNextRow)
is far clearer than v50!
thanks. I think I get it.
On Mon, Apr 8, 2024 at 12:34 AM jian he <jian.universality@gmail.com> wrote: > > On Sun, Apr 7, 2024 at 9:36 PM Amit Langote <amitlangote09@gmail.com> wrote: > > 0002 needs an expanded commit message but I've run out of energy today. > > > +/* + * Fetch next row from a JsonTablePlan's path evaluation result and from + * any child nested path(s). + * + * Returns true if the any of the paths (this or the nested) has more rows to + * return. + * + * By fetching the nested path(s)'s rows based on the parent row at each + * level, this essentially joins the rows of different levels. If any level + * has no matching rows, the columns at that level will compute to NULL, + * making it an OUTER join. + */ +static bool +JsonTablePlanScanNextRow(JsonTablePlanState *planstate) "if the any" should be "if any" ? also I think, + If any level + * has no matching rows, the columns at that level will compute to NULL, + * making it an OUTER join. means + If any level rows do not match, the rows at that level will compute to NULL, + making it an OUTER join. other than that, it looks good to me.
On Mon, Apr 8, 2024 at 11:21 AM jian he <jian.universality@gmail.com> wrote: > > On Mon, Apr 8, 2024 at 12:34 AM jian he <jian.universality@gmail.com> wrote: > > > > On Sun, Apr 7, 2024 at 9:36 PM Amit Langote <amitlangote09@gmail.com> wrote: > > > 0002 needs an expanded commit message but I've run out of energy today. > > > > > other than that, it looks good to me. one more tiny issue. +EXPLAIN (COSTS OFF, VERBOSE) SELECT * FROM jsonb_table_view1; +ERROR: relation "jsonb_table_view1" does not exist +LINE 1: EXPLAIN (COSTS OFF, VERBOSE) SELECT * FROM jsonb_table_view1... + ^ maybe you want EXPLAIN (COSTS OFF, VERBOSE) SELECT * FROM jsonb_table_view7; at the end of the sqljson_jsontable.sql. I guess it will be fine, but the format json explain's out is quite big. you also need to `drop table s cascade;` at the end of the test?
On Mon, Apr 8, 2024 at 2:02 PM jian he <jian.universality@gmail.com> wrote: > On Mon, Apr 8, 2024 at 11:21 AM jian he <jian.universality@gmail.com> wrote: > > > > On Mon, Apr 8, 2024 at 12:34 AM jian he <jian.universality@gmail.com> wrote: > > > > > > On Sun, Apr 7, 2024 at 9:36 PM Amit Langote <amitlangote09@gmail.com> wrote: > > > > 0002 needs an expanded commit message but I've run out of energy today. > > > > > > > > other than that, it looks good to me. > > one more tiny issue. > +EXPLAIN (COSTS OFF, VERBOSE) SELECT * FROM jsonb_table_view1; > +ERROR: relation "jsonb_table_view1" does not exist > +LINE 1: EXPLAIN (COSTS OFF, VERBOSE) SELECT * FROM jsonb_table_view1... > + ^ > maybe you want > EXPLAIN (COSTS OFF, VERBOSE) SELECT * FROM jsonb_table_view7; > at the end of the sqljson_jsontable.sql. > I guess it will be fine, but the format json explain's out is quite big. > > you also need to `drop table s cascade;` at the end of the test? Pushed after fixing this and other issues. Thanks a lot for your careful reviews. I've marked the CF entry for this as committed now: https://commitfest.postgresql.org/47/4377/ Let's work on the remaining PLAN clause with a new entry in the next CF, possibly in a new email thread. -- Thanks, Amit Langote
On Mon, 8 Apr 2024 at 10:09, Amit Langote <amitlangote09@gmail.com> wrote:
On Mon, Apr 8, 2024 at 2:02 PM jian he <jian.universality@gmail.com> wrote:
> On Mon, Apr 8, 2024 at 11:21 AM jian he <jian.universality@gmail.com> wrote:
> >
> > On Mon, Apr 8, 2024 at 12:34 AM jian he <jian.universality@gmail.com> wrote:
> > >
> > > On Sun, Apr 7, 2024 at 9:36 PM Amit Langote <amitlangote09@gmail.com> wrote:
> > > > 0002 needs an expanded commit message but I've run out of energy today.
> > > >
> >
> > other than that, it looks good to me.
>
> one more tiny issue.
> +EXPLAIN (COSTS OFF, VERBOSE) SELECT * FROM jsonb_table_view1;
> +ERROR: relation "jsonb_table_view1" does not exist
> +LINE 1: EXPLAIN (COSTS OFF, VERBOSE) SELECT * FROM jsonb_table_view1...
> + ^
> maybe you want
> EXPLAIN (COSTS OFF, VERBOSE) SELECT * FROM jsonb_table_view7;
> at the end of the sqljson_jsontable.sql.
> I guess it will be fine, but the format json explain's out is quite big.
>
> you also need to `drop table s cascade;` at the end of the test?
Pushed after fixing this and other issues. Thanks a lot for your
careful reviews.
I've marked the CF entry for this as committed now:
https://commitfest.postgresql.org/47/4377/
Let's work on the remaining PLAN clause with a new entry in the next
CF, possibly in a new email thread.
I've just taken a look at the doc changes, and I think we need to either remove the leading "select" keyword, or uppercase it in the examples.
json_exists ( context_item, path_expression [ PASSING { value AS varname } [, ...]] [ { TRUE | FALSE | UNKNOWN | ERROR } ON ERROR ])
Returns true if the SQL/JSON path_expression applied to the context_item using the PASSING values yields any items.
The ON ERROR clause specifies the behavior if an error occurs; the default is to return the boolean FALSE value. Note that if the path_expression is strict and ON ERROR behavior is ERROR, an error is generated if it yields no items.
Examples:
select json_exists(jsonb '{"key1": [1,2,3]}', 'strict $.key1[*] ? (@ > 2)') → t
select json_exists(jsonb '{"a": [1,2,3]}', 'lax $.a[5]' ERROR ON ERROR) → f
select json_exists(jsonb '{"a": [1,2,3]}', 'strict $.a[5]' ERROR ON ERROR) →
ERROR: jsonpath array subscript is out of bounds
Examples are more difficult to read when keywords appear to be at the same level as predicates. Plus other examples within tables on the same page don't start with "select", and further down, block examples uppercase keywords. Either way, I don't like it as it is.
Separate from this, I think these tables don't scan well (see json_query for an example of what I'm referring to). There is no clear separation of the syntax definition, the description, and the example. This is more a matter for the website mailing list, but I'm expressing it here to check whether others agree.
Thom
Hi Thom, On Thu, May 16, 2024 at 8:50 AM Thom Brown <thom@linux.com> wrote: > On Mon, 8 Apr 2024 at 10:09, Amit Langote <amitlangote09@gmail.com> wrote: >> >> On Mon, Apr 8, 2024 at 2:02 PM jian he <jian.universality@gmail.com> wrote: >> > On Mon, Apr 8, 2024 at 11:21 AM jian he <jian.universality@gmail.com> wrote: >> > > >> > > On Mon, Apr 8, 2024 at 12:34 AM jian he <jian.universality@gmail.com> wrote: >> > > > >> > > > On Sun, Apr 7, 2024 at 9:36 PM Amit Langote <amitlangote09@gmail.com> wrote: >> > > > > 0002 needs an expanded commit message but I've run out of energy today. >> > > > > >> > > >> > > other than that, it looks good to me. >> > >> > one more tiny issue. >> > +EXPLAIN (COSTS OFF, VERBOSE) SELECT * FROM jsonb_table_view1; >> > +ERROR: relation "jsonb_table_view1" does not exist >> > +LINE 1: EXPLAIN (COSTS OFF, VERBOSE) SELECT * FROM jsonb_table_view1... >> > + ^ >> > maybe you want >> > EXPLAIN (COSTS OFF, VERBOSE) SELECT * FROM jsonb_table_view7; >> > at the end of the sqljson_jsontable.sql. >> > I guess it will be fine, but the format json explain's out is quite big. >> > >> > you also need to `drop table s cascade;` at the end of the test? >> >> Pushed after fixing this and other issues. Thanks a lot for your >> careful reviews. >> >> I've marked the CF entry for this as committed now: >> https://commitfest.postgresql.org/47/4377/ >> >> Let's work on the remaining PLAN clause with a new entry in the next >> CF, possibly in a new email thread. > > > I've just taken a look at the doc changes, Thanks for taking a look. > and I think we need to either remove the leading "select" keyword, or uppercase it in the examples. > > For example (on https://www.postgresql.org/docs/devel/functions-json.html#SQLJSON-QUERY-FUNCTIONS): > > json_exists ( context_item, path_expression [ PASSING { value AS varname } [, ...]] [ { TRUE | FALSE | UNKNOWN | ERROR} ON ERROR ]) > > Returns true if the SQL/JSON path_expression applied to the context_item using the PASSING values yields any items. > The ON ERROR clause specifies the behavior if an error occurs; the default is to return the boolean FALSE value. Note thatif the path_expression is strict and ON ERROR behavior is ERROR, an error is generated if it yields no items. > Examples: > select json_exists(jsonb '{"key1": [1,2,3]}', 'strict $.key1[*] ? (@ > 2)') → t > select json_exists(jsonb '{"a": [1,2,3]}', 'lax $.a[5]' ERROR ON ERROR) → f > select json_exists(jsonb '{"a": [1,2,3]}', 'strict $.a[5]' ERROR ON ERROR) → > ERROR: jsonpath array subscript is out of bounds > > Examples are more difficult to read when keywords appear to be at the same level as predicates. Plus other examples withintables on the same page don't start with "select", and further down, block examples uppercase keywords. Either way,I don't like it as it is. I agree that the leading SELECT should be removed from these examples. Also, the function names should be capitalized both in the syntax description and in the examples, even though other functions appearing on this page aren't. > Separate from this, I think these tables don't scan well (see json_query for an example of what I'm referring to). Thereis no clear separation of the syntax definition, the description, and the example. This is more a matter for the websitemailing list, but I'm expressing it here to check whether others agree. Hmm, yes, I think I forgot to put <synopsis> around the syntax like it's done for a few other functions listed on the page. How about the attached? Other than the above points, it removes the <para> tags from the description text of each function to turn it into a single paragraph, because the multi-paragraph style only seems to appear in this table and it's looking a bit weird now. Though it's also true that the functions in this table have the longest descriptions. -- Thanks, Amit Langote
Вложения
On Mon, May 20, 2024 at 7:51 PM Amit Langote <amitlangote09@gmail.com> wrote: > > Hi Thom, >> > > and I think we need to either remove the leading "select" keyword, or uppercase it in the examples. > > > > For example (on https://www.postgresql.org/docs/devel/functions-json.html#SQLJSON-QUERY-FUNCTIONS): > > > > json_exists ( context_item, path_expression [ PASSING { value AS varname } [, ...]] [ { TRUE | FALSE | UNKNOWN | ERROR} ON ERROR ]) > > > > Returns true if the SQL/JSON path_expression applied to the context_item using the PASSING values yields any items. > > The ON ERROR clause specifies the behavior if an error occurs; the default is to return the boolean FALSE value. Notethat if the path_expression is strict and ON ERROR behavior is ERROR, an error is generated if it yields no items. > > Examples: > > select json_exists(jsonb '{"key1": [1,2,3]}', 'strict $.key1[*] ? (@ > 2)') → t > > select json_exists(jsonb '{"a": [1,2,3]}', 'lax $.a[5]' ERROR ON ERROR) → f > > select json_exists(jsonb '{"a": [1,2,3]}', 'strict $.a[5]' ERROR ON ERROR) → > > ERROR: jsonpath array subscript is out of bounds > > > > Examples are more difficult to read when keywords appear to be at the same level as predicates. Plus other exampleswithin tables on the same page don't start with "select", and further down, block examples uppercase keywords. Eitherway, I don't like it as it is. > > I agree that the leading SELECT should be removed from these examples. > Also, the function names should be capitalized both in the syntax > description and in the examples, even though other functions appearing > on this page aren't. > > > Separate from this, I think these tables don't scan well (see json_query for an example of what I'm referring to). Thereis no clear separation of the syntax definition, the description, and the example. This is more a matter for the websitemailing list, but I'm expressing it here to check whether others agree. > > Hmm, yes, I think I forgot to put <synopsis> around the syntax like > it's done for a few other functions listed on the page. > > How about the attached? Other than the above points, it removes the > <para> tags from the description text of each function to turn it into > a single paragraph, because the multi-paragraph style only seems to > appear in this table and it's looking a bit weird now. Though it's > also true that the functions in this table have the longest > descriptions. > Note that scalar strings returned by <function>json_value</function> always have their quotes removed, equivalent to specifying - <literal>OMIT QUOTES</literal> in <function>json_query</function>. + <literal>OMIT QUOTES</literal> in <function>JSON_QUERY</function>. "Note that scalar strings returned by <function>json_value</function>" should be "Note that scalar strings returned by <function>JSON_VALUE</function>" generally <synopsis> section no need indentation? you removed <para> tag for description of JSON_QUERY, JSON_VALUE, JSON_EXISTS. JSON_EXISTS is fine, but for JSON_QUERY, JSON_VALUE, the description section is very long. splitting it to 2 paragraphs should be better than just a single paragraph. since we are in the top level table section: <table id="functions-sqljson-querying"> so there will be no ambiguity of what we are referring to. one para explaining what this function does, and its return value, one para having a detailed explanation should be just fine?
Hello, I'm not sure I've chosen the most appropriate thread for reporting the issue, but maybe you would like to look at code comments related to SQL/JSON constructors: * Transform JSON_ARRAY() constructor. * * JSON_ARRAY() is transformed into json[b]_build_array[_ext]() call * depending on the output JSON format. The first argument of * json[b]_build_array_ext() is absent_on_null. * Transform JSON_OBJECT() constructor. * * JSON_OBJECT() is transformed into json[b]_build_object[_ext]() call * depending on the output JSON format. The first two arguments of * json[b]_build_object_ext() are absent_on_null and check_unique. But the referenced functions were removed at [1]; Nikita Glukhov wrote: > I have removed json[b]_build_object_ext() and json[b]_build_array_ext(). (That thread seems too old for the current discussion.) Also, a comment above transformJsonObjectAgg() references json[b]_objectagg[_unique][_strict](key, value), but I could find json_objectagg() only. [1] https://www.postgresql.org/message-id/be40362b-7821-7422-d33f-fbf1c61bb3e3%40postgrespro.ru Best regards, Alexander
Hi Alexander, On Wed, Jun 26, 2024 at 8:00 PM Alexander Lakhin <exclusion@gmail.com> wrote: > > Hello, > > I'm not sure I've chosen the most appropriate thread for reporting the > issue, but maybe you would like to look at code comments related to > SQL/JSON constructors: > > * Transform JSON_ARRAY() constructor. > * > * JSON_ARRAY() is transformed into json[b]_build_array[_ext]() call > * depending on the output JSON format. The first argument of > * json[b]_build_array_ext() is absent_on_null. > > > * Transform JSON_OBJECT() constructor. > * > * JSON_OBJECT() is transformed into json[b]_build_object[_ext]() call > * depending on the output JSON format. The first two arguments of > * json[b]_build_object_ext() are absent_on_null and check_unique. > > But the referenced functions were removed at [1]; Nikita Glukhov wrote: > > I have removed json[b]_build_object_ext() and json[b]_build_array_ext(). > > (That thread seems too old for the current discussion.) > > Also, a comment above transformJsonObjectAgg() references > json[b]_objectagg[_unique][_strict](key, value), but I could find > json_objectagg() only. > > [1] https://www.postgresql.org/message-id/be40362b-7821-7422-d33f-fbf1c61bb3e3%40postgrespro.ru Thanks for the report. Yeah, those comments that got added in 7081ac46ace are obsolete. Attached is a patch to fix that. Should be back-patched to v16. -- Thanks, Amit Langote
Вложения
Hi Amit, 28.06.2024 09:15, Amit Langote wrote: > Hi Alexander, > > > Thanks for the report. Yeah, those comments that got added in > 7081ac46ace are obsolete. > Thanks for paying attention to that! Could you also look at comments for transformJsonObjectAgg() and transformJsonArrayAgg(), aren't they obsolete too? Best regards, Alexander
Hi Alexander,
On Fri, Jun 28, 2024 at 5:00 PM Alexander Lakhin <exclusion@gmail.com> wrote:
>
> Hi Amit,
>
> 28.06.2024 09:15, Amit Langote wrote:
> > Hi Alexander,
> >
> >
> > Thanks for the report. Yeah, those comments that got added in
> > 7081ac46ace are obsolete.
> >
>
> Thanks for paying attention to that!
>
> Could you also look at comments for transformJsonObjectAgg() and
> transformJsonArrayAgg(), aren't they obsolete too?
You're right. I didn't think they needed to be similarly fixed,
because I noticed the code like the following in in
transformJsonObjectAgg() which sets the OID of the function to call
from, again, JsonConstructorExpr:
{
if (agg->absent_on_null)
if (agg->unique)
aggfnoid = F_JSONB_OBJECT_AGG_UNIQUE_STRICT;
else
aggfnoid = F_JSONB_OBJECT_AGG_STRICT;
else if (agg->unique)
aggfnoid = F_JSONB_OBJECT_AGG_UNIQUE;
else
aggfnoid = F_JSONB_OBJECT_AGG;
aggtype = JSONBOID;
}
So, yes, the comments for them should be fixed too like the other two
to also mention JsonConstructorExpr.
Updated patch attached.
Wonder if Alvaro has any thoughts on this.
--
Thanks, Amit Langote